Ele não tinha certeza de que ouviu corretamente. Tanta coisa dependia disso! Mas não pergunte de novo? (c) Boris Akunin. O mundo inteiro é um teatro.
Enquanto trabalhava no assistente de voz mencionado no artigo anterior , percebi que não posso deixar de compartilhar a bela biblioteca do FuzzyWuzzy com você .Em suma, graças a ela, é possível fazer uma comparação de cordas difusas sem nenhum sofrimento.Primeiros passos
Para começar, você precisa executar duas etapas:/ IMPORTANTE! Python versão 2.7 e superior /Etapa 1. Instalação.Abra a linha de comandos e digite:pip install fuzzywuzzy
Pressione Enter.Em seguida, instale python-Levenshtein da mesma maneira para acelerar a correspondência de cadeias de 3 a 10 vezes.pip install python-Levenshtein
Após a conclusão da instalação, a biblioteca está pronta para importar.Etapa 2. Importando para o projeto.from fuzzywuzzy import fuzz
from fuzzywuzzy import process
Funcional
1. A comparação mais comum:a = fuzz.ratio(' ', ' ')
print(a)
Se mudarmos alguns caracteres, a saída terá um número diferente.a = fuzz.ratio(' ', ' ')
print(a)
2. Comparação parcial:esse tipo de comparação na segunda linha inteira procura uma correspondência com a inicial, por exemplo:a = fuzz.partial_ratio(' ', ' !')
print(a)
Oua = fuzz.partial_ratio(' ', ' , ')
print(a)
Mas você deve se lembrar do registro, já quea = fuzz.partial_ratio(' ', ' , ')
print(a)
3. Comparação detokens 1) Taxa de classificação de tokensAs palavras são comparadas entre si, independentemente do caso ou ordema = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio(' ', ' ')
print(a)
a = fuzz.token_sort_ratio('1 2 ', '1 2 ')
print(a)
2) Taxa de conjunto de tokensEssa comparação, ao contrário do passado, iguala strings, se a diferença é a repetição de palavras.a = fuzz.token_set_ratio(' ', ' ')
print(a)
4. Comparação regular avançadaEm muitos casos, é mais aconselhável usar exatamente o WRatio , pois faz distinção entre maiúsculas e minúsculas e pontuação (sem dividir a sequência)a = fuzz.WRatio(' ', '! !')
print(a)
a = fuzz.WRatio(' ', '!, !')
print(a)
5. Trabalhando com a listaPara comparar as linhas com as linhas da lista, o módulo de processo é usadocity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extract("", city, limit=2)
print(a)
Se apenas o primeiro da lista for necessário, é melhor usar extractOnecity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
Inscrição
Você decide como e onde aplicar todas as opções acima, mas aqui está um exemplo do meu trabalho :
try:
files = os.listdir('C:\\Users\\hartp\\Desktop\\')
filestart = process.extractOne(namerec, files)
if filestart[1] >= 80:
os.startfile('C:\\Users\\hartp\\Desktop\\' + filestart[0])
else:
speak(' ')
except FileNotFoundError:
speak(' ')
Vamos revisar o código e entender o que é o quê. Com ocomando os.listdir, obtemos uma lista de todos os arquivos presentes no final do caminho especificado (no nosso caso, para a área de trabalho).files = os.listdir('C:\\Users\\hartp\\Desktop\\')
print(files)
A seguir, é apresentada uma comparação das linhas da lista de arquivos com o nome do arquivo que o usuário nomeou (variável namerec ). Espero que você tenha notado que o resultado da função extractOne é uma tupla de string e número (índice de similaridade)Exemplo do último capítulocity = ["", "-", "", "", "", "", "", "", "", "", ""]
a = process.extractOne("", city)
print(a)
. Com base nisso, verificamos o índice de similaridade filestart [1]> = 80 ([1], pois a tupla é numerada de 0, como em uma matriz) e, se a condição for verdadeira, execute a função os.startfile com um arquivo chamado filestart [0 ] Caso contrário, se o índice de similaridade for menor que 80 ou ocorrer um erro de que o arquivo não foi encontrado, informaremos o usuário através da função de fala .Todas as estradas levam a Matan
Escondido de pessoas que têm medo de matemática, , ().
, .
( , ) — , .
S1 i S2 j
S1=vrhk
S2=rhgr
3 :
- : r → v
- : -r
- : rVhgr
:

0 1? ( — «0»), r , r ( , — «1»). v .
rh h, r ( ), , :
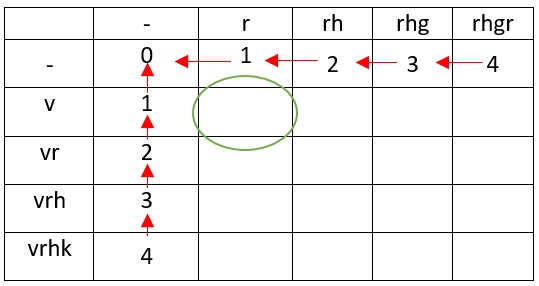
v r ( ).
, — v.
1. ? r , v. r , v, rv. , v v.
v rh
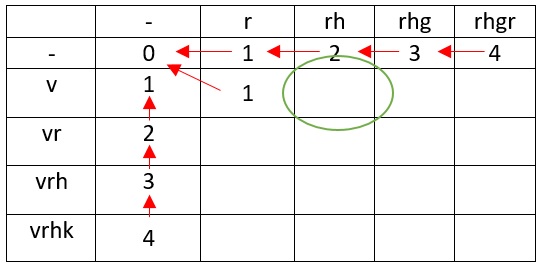
— v h r .
.
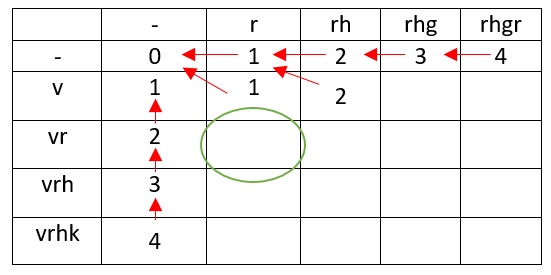
vr r , , , , .
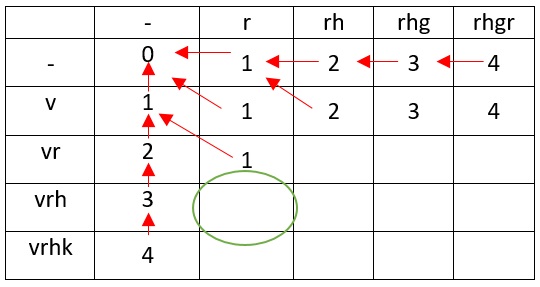
vrh r h ( vr r), 2

vr r vrh rh, , .
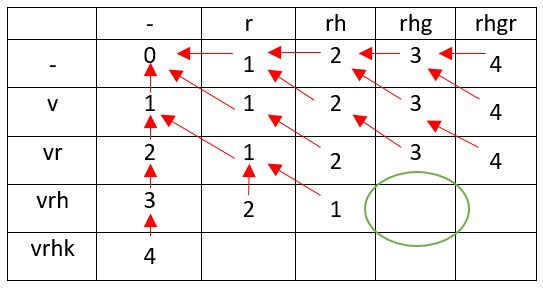
, vrh rhg , , , - ( ).
, , ( ) — vrhk rhgr.
Obrigado a todos pela atenção! Espero que este artigo seja útil para alguém.