Recentemente, em uma entrevista, perguntaram-me se eu trabalhava com transações distribuídas, no sentido de que eu precisava fazer a inserção / atualização desses registros, desde que:- Transação única.
- Pode haver vários bancos de dados diversos, como Oracle, MS SQL Server e PostgreSQL.
- A resposta a uma operação CRUD pode ser significativa.
- A sequência de inserção não é importante.
O que os colegas conseguiram ao fazer esta pergunta? Verifique minha experiência ou obtenha uma solução pronta? Na verdade, isso não é importante para mim, mas o que é importante - o problema na teoria da pergunta parecia interessante para mim e decidi escrever um artigo sobre como esse problema poderia ser resolvido.Antes de descrever minha solução, vamos lembrar como uma transação distribuída típica é implementada usando a plataforma Microsoft como exemplo.Opção número 1. Aplicativo C ++ e driver ODBC (de propriedade do MSDTC (Microsoft Distributed Transaction Coordinator) para SQL Server)O MSDTC (Microsoft Distributed Transaction Coordinator) permite que os aplicativos expandam ou distribuam transações entre duas ou mais instâncias do SQL Server. Uma transação distribuída funciona mesmo se duas instâncias estiverem localizadas em computadores diferentes.O MSDTC funciona apenas localmente para o Microsoft SQL Server e não está disponível para o serviço de banco de dados em nuvem SQL do Microsoft Azure.O MSDTC é chamado pelo driver do cliente nativo do SQL Server para ODBC (Open Database Connectivity) quando o programa C ++ gerencia uma transação distribuída. O driver ODBC do cliente nativo possui um gerenciador de transações compatível com XA Open Distributed Transaction Processing (DTP). Essa conformidade é exigida pelo MSDTC. Normalmente, todos os comandos de gerenciamento de transações são enviados por esse driver ODBC para o cliente nativo. A sequência é a seguinte:Um aplicativo ODBC para um cliente C ++ nativo inicia uma transação chamando SQLSetConnectAttr com a confirmação automática desativada.O aplicativo atualiza alguns dados no SQL Server X no computador A.O aplicativo atualiza alguns dados no SQL Server X no computador B.Se a atualização falhar no SQL Server Y, todas as atualizações não confirmadas nas duas instâncias do SQL Server serão revertidas.Por fim, o aplicativo conclui a transação chamando SQLEndTran (1) com a opção SQL_COMMIT ou SQL_ROLLBACK.(1) MSDTC pode ser chamado sem ODBC. Nesse caso, o MSDTC se torna um gerenciador de transações e o aplicativo não usa mais o SQLEndTran.Apenas uma transação distribuída.Suponha que seu aplicativo ODBC para um cliente C ++ nativo esteja registrado em uma transação distribuída. Em seguida, o aplicativo é creditado na segunda transação distribuída. Nesse caso, o driver ODBC do SQL Server Native Client deixa a transação distribuída original e é incluído na nova transação distribuída.Leia mais sobre o MSDTC aqui..Opção número 2. O aplicativo C #, como alternativa ao banco de dados SQL na nuvem Azur, oMSDTC não é suportado no Banco de Dados SQL do Azure ou no Azure SQL Data Warehouse.No entanto, você pode criar uma transação distribuída para um banco de dados SQL se o programa C # usar a classe .NET System.Transactions.TransactionScope.O exemplo a seguir mostra como usar a classe TransactionScope para definir um bloco de código para participar de uma transação.static public int CreateTransactionScope(
string connectString1, string connectString2,
string commandText1, string commandText2)
{
int returnValue = 0;
System.IO.StringWriter writer = new System.IO.StringWriter();
try
{
using (TransactionScope scope = new TransactionScope())
{
using (SqlConnection connection1 = new SqlConnection(connectString1))
{
connection1.Open();
SqlCommand command1 = new SqlCommand(commandText1, connection1);
returnValue = command1.ExecuteNonQuery();
writer.WriteLine(" command1: {0}", returnValue);
using (SqlConnection connection2 = new SqlConnection(connectString2))
{
connection2.Open();
returnValue = 0;
SqlCommand command2 = new SqlCommand(commandText2, connection2);
returnValue = command2.ExecuteNonQuery();
writer.WriteLine(" command2: {0}", returnValue);
}
}
scope.Complete();
}
}
catch (TransactionAbortedException ex)
{
writer.WriteLine(" : {0}", ex.Message);
}
Console.WriteLine(writer.ToString());
return returnValue;
}
Opção número 3. Aplicativos principais de C # e Entity Framework para transações distribuídas.Por padrão, se o provedor de banco de dados suportar transações, todas as alterações em uma chamada para SaveChanges () serão aplicadas à transação. Se alguma das alterações não for executada, a transação será revertida e nenhuma das alterações será aplicada ao banco de dados. Isso significa que é garantido que SaveChanges () seja concluído com êxito ou mantenha o banco de dados inalterado em caso de erro.Para a maioria dos aplicativos, esse comportamento padrão é suficiente. Você deve controlar manualmente as transações somente se os requisitos do seu aplicativo considerarem necessário.Você pode usar a API DbContext.Databasepara iniciar, confirmar e reverter transações. O exemplo a seguir mostra duas operações SaveChanges () e uma consulta LINQ executada em uma única transação.Nem todos os provedores de banco de dados suportam transações. Alguns provedores podem ou não emitir transações ao invocar uma API de transação.using (var context = new BloggingContext())
{
using (var transaction = context.Database.BeginTransaction())
{
try
{
context.Blogs.Add(new Blog { Url = "http://blogs.msdn.com/dotnet" });
context.SaveChanges();
context.Blogs.Add(new Blog { Url = "http://blogs.msdn.com/visualstudio" });
context.SaveChanges();
var blogs = context.Blogs
.OrderBy(b => b.Url)
.ToList();
transaction.Commit();
}
catch (Exception)
{
}
}
}
Se você usa o EF Core no .NET Framework , a implementação do System.Transactions suporta transações distribuídas.Como você pode ver na documentação na estrutura da plataforma e na linha de produtos da Microsoft, as transações distribuídas não são um problema: MSDTC, a própria nuvem é tolerante a falhas, um monte de ADO .NET + EF Core para combinações exóticas (leia aqui ).Como a revisão de transações na plataforma Microsoft nos ajuda a resolver o problema? Muito simples, existe um entendimento claro de que simplesmente não existe um kit de ferramentas padrão para implementar uma transação distribuída entre bancos de dados heterogêneos em um aplicativo .NET.E, nesse caso, criamos nosso próprio coordenador de transações distribuídas (CRT) caseiro.Uma das opções de implementação são transações distribuídas com base em microsserviços (veja aqui ). Essa opção não é ruim, mas requer um refinamento sério da API da Web para todos os sistemas envolvidos na transação.Portanto, precisamos de um mecanismo ligeiramente diferente. A seguir, é apresentada uma abordagem geral para o desenvolvimento do MCT.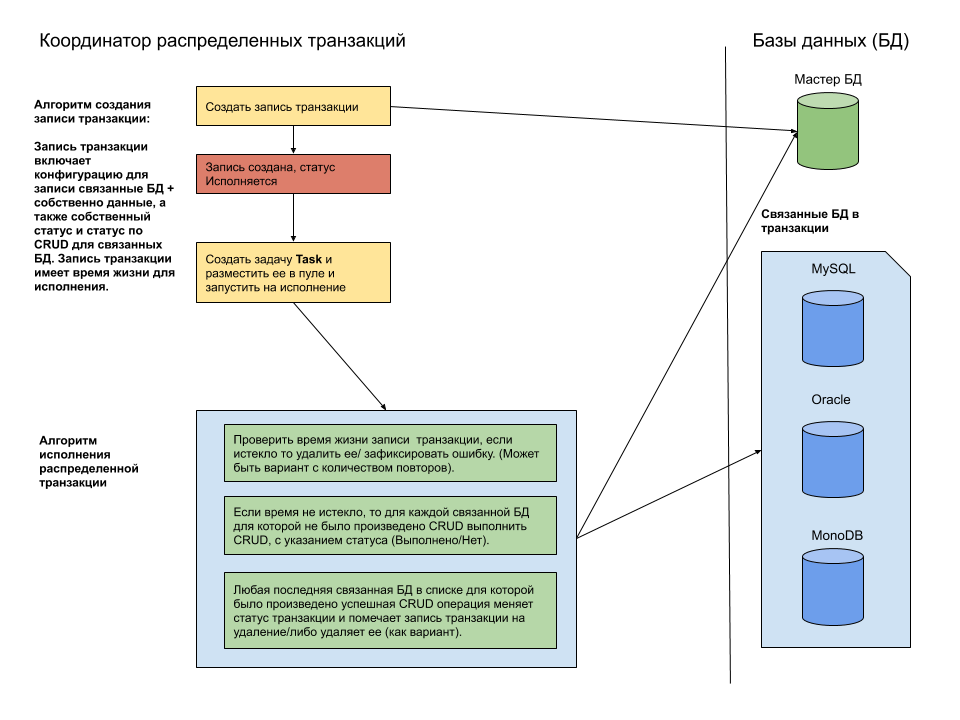 Como você pode ver no diagrama, a idéia principal é criar e armazenar com o status atualizado o registro da transação armazenado no banco de dados mestre (ou tabela). Este modelo de CRT permite implementar transações distribuídas que atendem aos requisitos de:
Como você pode ver no diagrama, a idéia principal é criar e armazenar com o status atualizado o registro da transação armazenado no banco de dados mestre (ou tabela). Este modelo de CRT permite implementar transações distribuídas que atendem aos requisitos de:- atomicidade
- coerência
- isolamento
- longevidade
- pode fazer parte do aplicativo em que o usuário criou um registro ou pode ser um aplicativo completamente separado na forma de um serviço do sistema. pode conter um subprocesso especial que gera transações em um pool para execução quando ocorrer uma queda de energia (não mostrada no diagrama). As regras de negócios para converter (mapear) os dados de origem gerados pelo usuário para bancos de dados relacionados podem ser adicionados e configurados dinamicamente via formato XML / JSON e armazenados na pasta do aplicativo local ou em um registro de transação (como opção). Portanto, nesse caso, é recomendável unificar a conversão para bancos de dados relacionados no nível do código, implementando a modularidade dos conversores na forma de DLLs. (E sim, o SRT implica acesso direto ao banco de dados sem a participação da API da Web.)Portanto, o SRT de forma simples pode ser implementado com sucesso como parte do aplicativo ou como uma solução separada, personalizável e independente (o que é melhor).Mais uma vez, vou esclarecer que uma transação distribuída é, por definição, um armazenamento único de informações sem alterá-las, mas com a capacidade de mapear vários bancos de dados em esquemas de dados. Portanto, se você precisar registrar dados em outras bases, por exemplo, no Ministério da Administração Interna, no FSB e nas companhias de seguros, ao registrar incidentes na sala de emergência do hospital (bala), essa abordagem certamente o ajudará. O mesmo mecanismo pode funcionar perfeitamente em instituições financeiras.Espero que essa abordagem tenha parecido interessante para você, escreva o que pensa, colegas e amigos!