Milhares de gerentes de escritórios de vendas em todo o país registram dezenas de milhares de contatos em nosso sistema de CRM todos os dias - fatos de comunicação com clientes em potencial ou que já trabalham conosco. E para esse cliente, você deve primeiro encontrar, e de preferência muito rapidamente. E isso acontece com mais frequência pelo nome.Portanto, não surpreende que, mais uma vez analisando solicitações "pesadas" em um dos bancos de dados mais carregados - nossa própria conta VLSI corporativa , encontrei "no topo" uma solicitação de uma pesquisa "rápida" por nome de cartões de empresa.Além disso, uma investigação adicional revelou um exemplo interessante de otimização e, em seguida, degradação do desempenho pedido em seu refinamento subsequente por várias equipes, cada uma das quais agiu unicamente de bem-intencionado.0: o que o usuário queria
[KDPV a partir daqui ]O que o usuário geralmente quer dizer quando diz "pesquisa rápida" por nome? Quase nunca acaba sendo uma pesquisa "honesta" em uma substring do tipo ... LIKE '%%'- porque, então, não apenas e , mas até mesmo obtém o resultado . O usuário implica, no nível doméstico, que você forneça a ele uma pesquisa no início de uma palavra no título e mostre mais relevante o que começa com a entrada. E faça isso quase instantaneamente - com entrada interlinear.''' '''' '1: limitar a tarefa
E ainda mais, uma pessoa não entra especificamente ' 'para que você tenha que procurar por cada prefixo de palavra. Não, é muito mais fácil para o usuário responder a uma dica rápida da última palavra do que deliberadamente "errar" as anteriores - veja como funciona qualquer mecanismo de pesquisa.Em geral, formular corretamente os requisitos para uma tarefa é mais da metade da solução. Às vezes, uma análise cuidadosa do caso de uso pode afetar significativamente o resultado .O que o desenvolvedor abstrato faz?1.0: mecanismo de pesquisa externo
Oh, pesquisar é difícil, não quero fazer nada - vamos dar aos devops! Deixe-os implantar para nós um mecanismo de pesquisa externo em relação ao banco de dados: Sphinx, ElasticSearch, ... Uma opçãofuncional, embora demorada, em termos de sincronização e velocidade da mudança. Mas não no nosso caso, uma vez que a pesquisa é realizada para cada cliente apenas dentro da estrutura dos dados de sua conta. E os dados têm uma variabilidade bastante alta - e se o gerente inseriu o cartão ' ', depois de 5 a 10 segundos, ele já se lembra de que esqueceu de indicar o e-mail e deseja encontrá-lo e corrigi-lo.Portanto - vamos procurar "diretamente no banco de dados" . Felizmente, o PostgreSQL nos permite fazer isso, e não apenas uma opção - nós as consideraremos.1.1: substring "honesto"
Nos apegamos à palavra "substring". Mas exatamente para pesquisa de índice por substring (e até por expressões regulares!) Existe um excelente módulo pg_trgm ! Somente então será necessário classificar corretamente.Vamos tentar pegar uma placa para simplificar o modelo:CREATE TABLE firms(
id
serial
PRIMARY KEY
, name
text
);
Nós preenchemos lá 7,8 milhões de registros de organizações reais e indexamos:CREATE EXTENSION pg_trgm;
CREATE INDEX ON firms USING gin(lower(name) gin_trgm_ops);
Vamos procurar as 10 primeiras entradas para a pesquisa entre linhas:SELECT
*
FROM
firms
WHERE
lower(name) ~ ('(^|\s)' || '')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
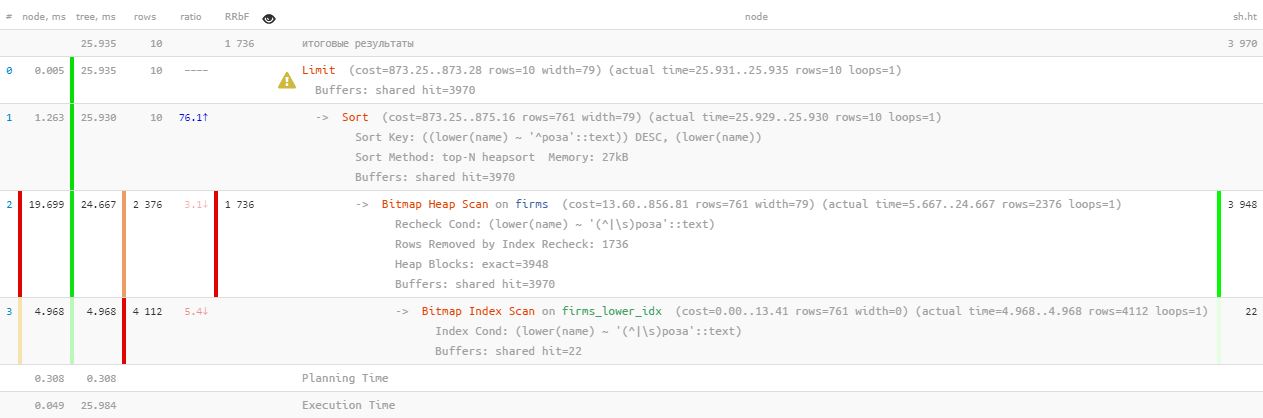 [dê uma olhada em explica.tensor.ru]Bem, são 26 ms, 31 MB de dados lidos e mais de 1,7 mil registros filtrados - para 10 pessoas. A sobrecarga é muito alta, é possível ser de alguma forma mais eficiente?
[dê uma olhada em explica.tensor.ru]Bem, são 26 ms, 31 MB de dados lidos e mais de 1,7 mil registros filtrados - para 10 pessoas. A sobrecarga é muito alta, é possível ser de alguma forma mais eficiente?1.2: pesquisa de texto? é STF!
De fato, o PostgreSQL fornece um mecanismo muito poderoso para a pesquisa de texto completo ( Pesquisa de texto completo), incluindo a possibilidade de pesquisa de prefixo. Uma ótima opção, mesmo as extensões não precisam ser instaladas! Vamos tentar:CREATE INDEX ON firms USING gin(to_tsvector('simple'::regconfig, lower(name)));
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10;
 [olhada explain.tensor.ru]Aqui paralelização de execução da consulta nos ajudou um pouco, reduzindo o tempo pela metade, para 11 ms . Sim, e tivemos que ler 1,5 vezes menos - apenas 20 MB . E aqui, quanto menor, melhor, porque quanto maior a quantidade que subtraímos, maiores as chances de perda de cache e cada página de dados extra lida em disco é um "freio" em potencial para a solicitação.
[olhada explain.tensor.ru]Aqui paralelização de execução da consulta nos ajudou um pouco, reduzindo o tempo pela metade, para 11 ms . Sim, e tivemos que ler 1,5 vezes menos - apenas 20 MB . E aqui, quanto menor, melhor, porque quanto maior a quantidade que subtraímos, maiores as chances de perda de cache e cada página de dados extra lida em disco é um "freio" em potencial para a solicitação.1.3: Ainda gosta?
A solicitação anterior é boa para todos, mas somente se você a extrair centenas de milhares de vezes por dia, 2 TB de dados de leitura serão executados . Na melhor das hipóteses - a partir da memória, mas se você não tiver sorte, então a partir do disco. Então, vamos tentar torná-lo menor.Lembre-se de que o usuário deseja ver primeiro "que começa com ..." . Portanto, esta é, na sua forma pura, uma pesquisa com prefixotext_pattern_ops ! E somente se "não for suficiente" até 10 registros necessários, teremos que lê-los usando a pesquisa do STF:CREATE INDEX ON firms(lower(name) text_pattern_ops);
SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
LIMIT 10;
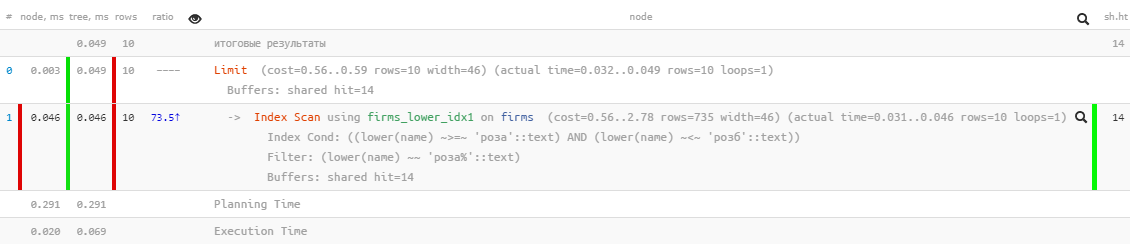 [veja em explan.tensor.ru]Excelente desempenho - apenas 0,05ms e um pouco mais de 100 KB de leitura! Só nos esquecemos de classificar por nome para que o usuário não se perca nos resultados:
[veja em explan.tensor.ru]Excelente desempenho - apenas 0,05ms e um pouco mais de 100 KB de leitura! Só nos esquecemos de classificar por nome para que o usuário não se perca nos resultados:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name)
LIMIT 10;
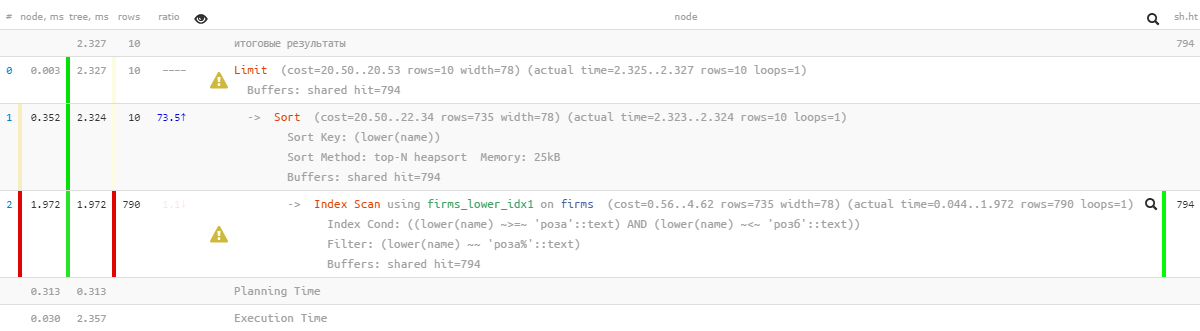 [veja explan.tensor.ru]Ah, algo não é mais tão bonito - parece que existe um índice, mas a classificação passa por ele ... É claro que já é várias vezes mais eficaz que a versão anterior, mas ...
[veja explan.tensor.ru]Ah, algo não é mais tão bonito - parece que existe um índice, mas a classificação passa por ele ... É claro que já é várias vezes mais eficaz que a versão anterior, mas ...1.4: “modificar com um arquivo”
Mas há um índice que permite pesquisar por faixa e é normal usar a classificação - btree normal !CREATE INDEX ON firms(lower(name));
Somente uma solicitação para isso terá que ser "montada manualmente":SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10;
 [veja explan.tensor.ru]Ótimo - tanto a triagem quanto o consumo de recursos permanecem "microscópicos", milhares de vezes mais eficientes que o STF "puro" ! Resta coletar em uma única solicitação:
[veja explan.tensor.ru]Ótimo - tanto a triagem quanto o consumo de recursos permanecem "microscópicos", milhares de vezes mais eficientes que o STF "puro" ! Resta coletar em uma única solicitação:(
SELECT
*
FROM
firms
WHERE
lower(name) >= '' AND
lower(name) <= ('' || chr(65535))
ORDER BY
lower(name)
LIMIT 10
)
UNION ALL
(
SELECT
*
FROM
firms
WHERE
to_tsvector('simple'::regconfig, lower(name)) @@ to_tsquery('simple', ':*') AND
lower(name) NOT LIKE ('' || '%')
ORDER BY
lower(name) ~ ('^' || '') DESC
, lower(name)
LIMIT 10
)
LIMIT 10;
Observo que a segunda subconsulta é executada apenas se a primeira retornar menos do que oLIMIT número de linhas esperado pela última . Eu já escrevi sobre esse método de otimização de consultas .Então, sim, agora temos btree e gin na mesa ao mesmo tempo, mas estatisticamente aconteceu que menos de 10% das solicitações atingem o segundo bloco . Ou seja, com tais limitações típicas conhecidas para a tarefa, conseguimos reduzir o consumo total de recursos do servidor em quase mil vezes!1.5 *: dispensar o arquivo
Acima LIKE, fomos impedidos de usar o tipo errado. Mas pode ser "definido no caminho verdadeiro" especificando a instrução USING:O padrão está implícito ASC. Além disso, você pode especificar o nome de um operador de classificação específico em uma frase USING. O operador de classificação deve ser um membro menor ou maior que uma determinada família de operadores de árvore B. ASCgeralmente equivalente USING <e DESCgeralmente equivalente USING >.
No nosso caso, "menos" é ~<~:SELECT
*
FROM
firms
WHERE
lower(name) LIKE ('' || '%')
ORDER BY
lower(name) USING ~<~
LIMIT 10;
 [veja em explicar.tensor.ru]
[veja em explicar.tensor.ru]2: como "azedar" solicitações
Agora deixamos nosso pedido de "insistir" por meio ano ou um ano e, com surpresa, novamente o encontramos "no topo" com indicadores do total de "bombeamento" diário de memória ( buffers compartilhados ) em 5,5 TB - ou seja, ainda mais do que era originalmente.Não, é claro, nosso negócio cresceu e a carga aumentou, mas não tanto! Então, algo está sujo aqui - vamos descobrir.2.1: o nascimento da paginação
Em algum momento, outra equipe de desenvolvimento queria tornar possível “pular” no registro a partir de uma pesquisa rápida de subscrito com os mesmos resultados, mas ampliados. E qual registro sem navegação na página? Vamos estragar tudo!( ... LIMIT <N> + 10)
UNION ALL
( ... LIMIT <N> + 10)
LIMIT 10 OFFSET <N>;
Agora era possível, sem esforço, que o desenvolvedor mostrasse o registro dos resultados da pesquisa com o carregamento de "página de tipo".Certamente, de fato, para cada página seguinte de dados, cada vez mais está sendo lida (o tempo todo, que descartamos, mais a “cauda” desejada) - isto é, este é um antipadrão inequívoco. E seria mais correto iniciar a pesquisa na próxima iteração a partir da chave armazenada na interface, mas sobre isso - outra vez.2.2: quer exótico
Em algum momento, o desenvolvedor quis diversificar a seleção resultante com dados de outra tabela, para qual finalidade toda a solicitação anterior foi enviada ao CTE:WITH q AS (
...
LIMIT <N> + 10
)
SELECT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
E mesmo assim - nada mal, porque uma subconsulta é calculada apenas para 10 registros retornados, se não ...2.3: DISTINTA sem sentido e sem piedade
Em algum lugar do processo dessa evolução, uma condição foi perdidaNOT LIKE na 2ª subconsulta . É claro que depois disso UNION ALLcomecei a retornar alguns registros duas vezes - primeiro encontrados no início da linha e depois novamente - no início da primeira palavra dessa linha. No limite, todos os registros da 2ª subconsulta podem coincidir com os registros da primeira.O que um desenvolvedor faz em vez de procurar um motivo? .. Sem dúvida!- dobrar o tamanho das amostras originais
- coloque DISTINCT para obter apenas instâncias únicas de cada linha
WITH q AS (
( ... LIMIT <2 * N> + 10)
UNION ALL
( ... LIMIT <2 * N> + 10)
LIMIT <2 * N> + 10
)
SELECT DISTINCT
*
, (SELECT ...) sub_query
FROM
q
LIMIT 10 OFFSET <N>;
Ou seja, é claro que o resultado, no final, é exatamente o mesmo, mas a chance de "voar" para a 2ª subconsulta CTE se tornou muito maior e, sem isso, é claramente lida mais .Mas isso não é a coisa mais triste. Como o desenvolvedor me pediu para selecionar, DISTINCTnão por específico, mas imediatamente por todos os campos do registro, o campo sub_query, o resultado da subconsulta, também chegou lá automaticamente. Agora, para execução DISTINCT, o banco de dados precisava executar não 10 subconsultas, mas todas <2 * N> + 10 !2.4: cooperação acima de tudo!
Assim, os desenvolvedores viveram - eles não se incomodaram, porque no registro foram "corrigidos" para valores significativos de N com uma desaceleração crônica no recebimento de cada "página" seguinte.Até os desenvolvedores de outro departamento chegarem até eles e não desejarem usar um método tão conveniente para a pesquisa iterativa - ou seja, pegamos um pedaço de alguma amostra, filtramos por condições adicionais, desenhamos o resultado e depois o próximo (que, no nosso caso, é alcançado por aumentar N) e assim sucessivamente até preenchermos a tela.Em geral, no espécime capturado, N atingiu valores de quase 17K , e em apenas 24 horas pelo menos 4K esses pedidos foram executados “na cadeia”. O último deles já audaciosamente digitalizado1 GB de memória a cada iteração ...