Um algoritmo de classificação rápida foi desenvolvido recentemente cuja complexidade é definida como 2 * N (2 vezes N).Neste artigo, não analisaremos o próprio algoritmo de classificação, mas somente após a realização de uma série de testes, o compararemos com a classificação usada no Visual Studio (a função std :: sort). Como se costuma dizer: apenas fatos e um mínimo de emoções.Classificaremos as informações do texto, conforme as quais consideraremos uma variedade de palavras. Essa matriz será formada com base em obras literárias. Para fazer isso, colocamos todas as palavras desses trabalhos em ordem nesse array. A divisão da palavra ocorre sem modernização; um sinal do início de uma nova palavra é uma lacuna. As palavras na matriz correspondem totalmente às palavras no texto. Como sinais de pontuação (pontos, vírgulas etc.) e caracteres de controle são escritos atrás de palavras sem espaços, como resultado, eles fazem parte das palavras. Sinais de pontuação e caracteres de controle separados são tratados como palavras separadas. Os arquivos contêm os endereços dos sites em que esses arquivos estão localizados. Os dados do endereço são uma palavra. A palavra mais longa consiste em 95 caracteres. Nos trabalhos em consideração existem letras do alfabeto latino,Caracteres cirílicos, de pontuação e controle.As informações classificadas são arbitrárias, não ordenadas de forma alguma e, como resultado, classificações especiais não são aplicadas.Dois métodos de classificação são comparados: o algoritmo de classificação recentemente desenvolvido com complexidade 2 * N e o algoritmo usado no Visual Studio 2017 (função std :: sort). Eles estão interessados no tempo de classificação e na quantidade de cada método usado para essa memória em cada teste.Os programas são gravados no ambiente - Visual Studio 2017, na plataforma - Windows x64. O teste foi realizado em 2 configurações. Os resultados do teste nas configurações Debug e Release são apresentados nas tabelas 1 e 2, respectivamente. As tabelas mostram os resultados do teste de dois métodos de classificação.Como os resultados no tempo de cálculo são flutuantes (os valores variam em 10%), foi realizada uma série de cálculos para cada teste, dos quais os menores valores foram selecionados e esses valores foram colocados em tabelas. Os horários indicados nas colunas 4 e 6 são apenas horários de classificação. Processos adicionais (como leitura e gravação em um arquivo, formação de matriz) não são incluídos no tempo especificado.Eficiência de tempo e de memória calculado de acordo com as seguintes fórmulas, respectivamente:
Onde - o número de períodos para os quais a função std :: sort usada no Visual Studio é executada e um novo algoritmo de classificação, respectivamente; - a quantidade de memória usada para executar a função std :: sort usada no Visual Studio e o novo algoritmo de classificação, respectivamente.Tabela 1.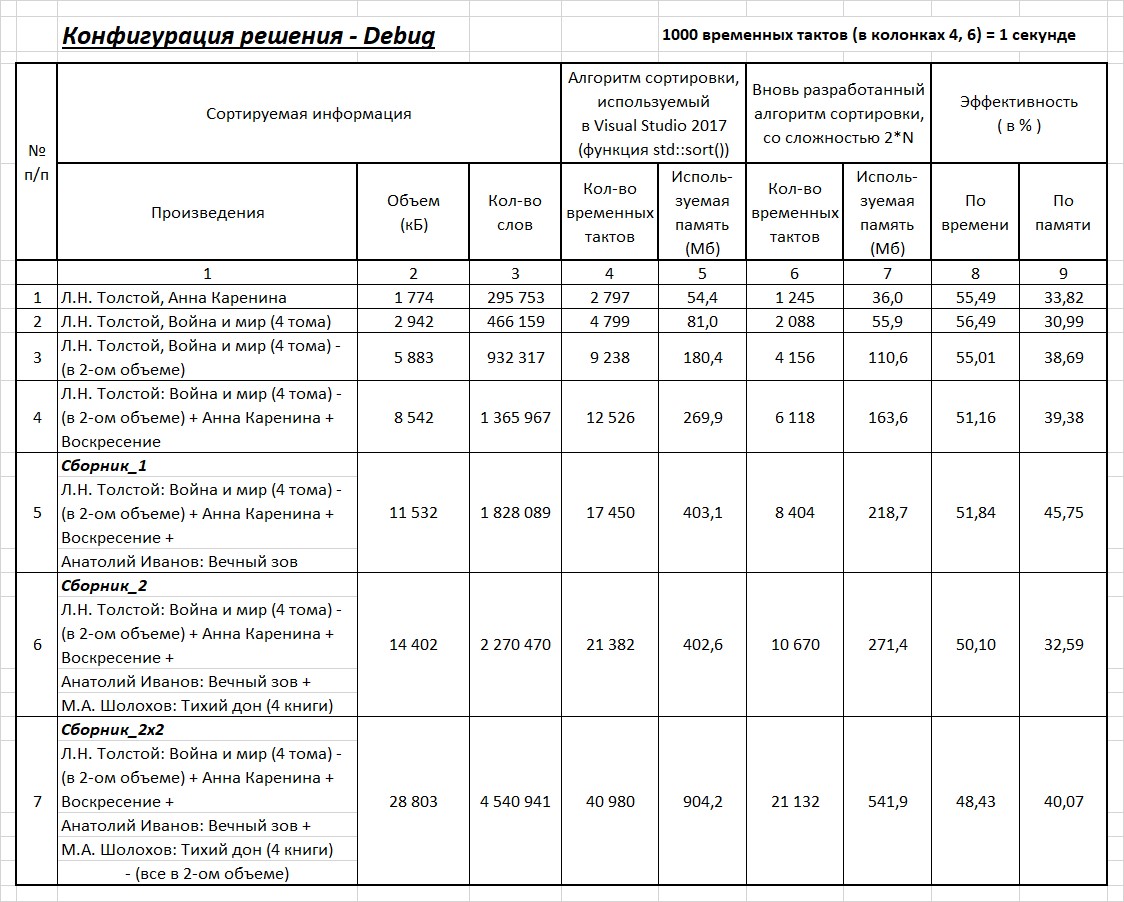 Tabela 2.
Tabela 2.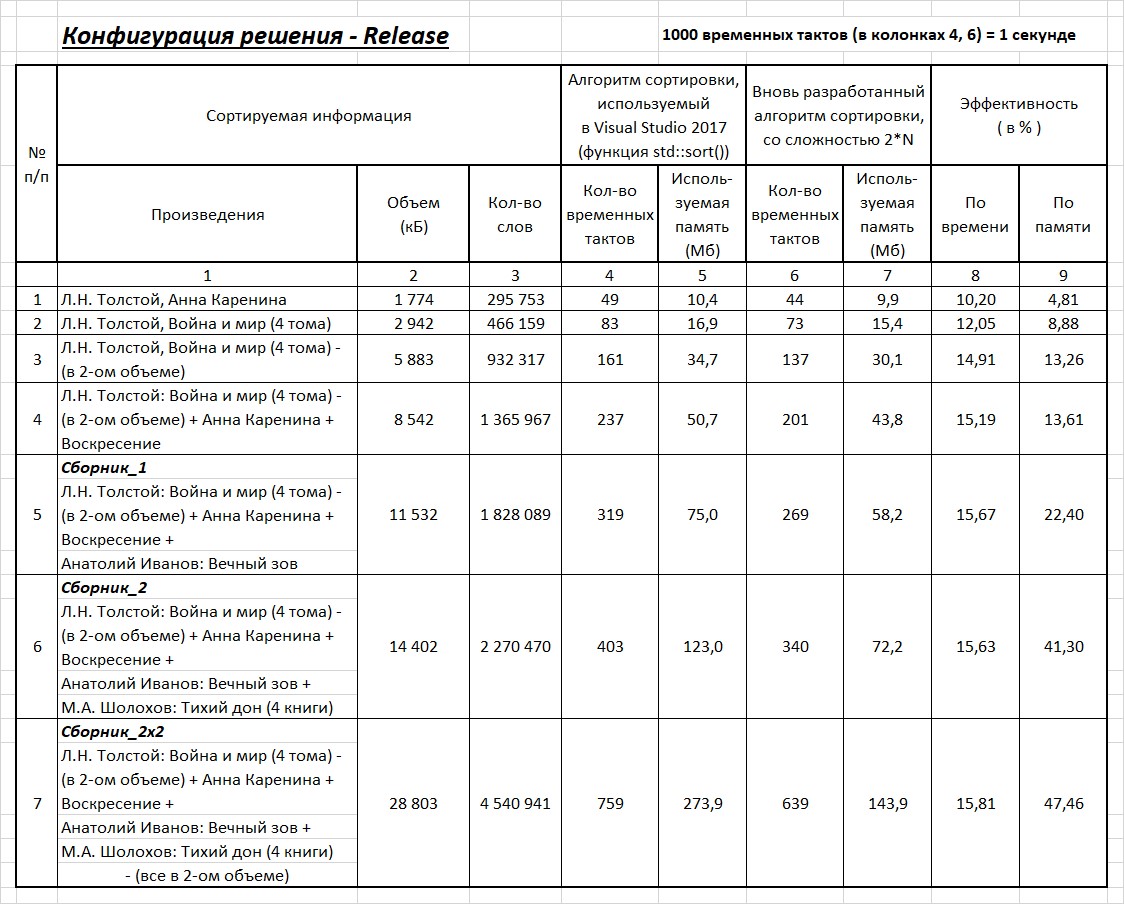 Quanto o algoritmo de classificação recentemente desenvolvido com complexidade 2 * N é mais eficiente (em tempo e uso de memória) do algoritmo usado no Visual Studio 2017 (função std :: sort) que você decide.
Quanto o algoritmo de classificação recentemente desenvolvido com complexidade 2 * N é mais eficiente (em tempo e uso de memória) do algoritmo usado no Visual Studio 2017 (função std :: sort) que você decide.