Há muito tempo que eu conheço o site Fui Pwned (HIBP) . É verdade que, até recentemente, ele nunca esteve lá. Eu sempre tive duas senhas. Um deles foi usado repetidamente para correio de lixo e algumas contas em sites estranhos. Mas tive que recusar, porque o correio foi hackeado. E, para ser sincero, sou grato ao hacker porque esse evento me fez revisar minhas senhas - a maneira como as uso e as armazeno.Obviamente, mudei senhas em todas as contas em que havia uma senha comprometida. Então me perguntei se a senha vazada estava no banco de dados HIBP. Como não quis inserir a senha no site, baixei o banco de dados (pwned-passwords-sha1-ordered-by-count-v5) A base é muito impressionante. Este é um arquivo de texto de 22,8 GB com um conjunto de hashes SHA-1, um em cada linha com um contador, quantas vezes a senha com esse hash ocorreu com vazamentos. Eu descobri o SHA-1 da minha senha quebrada e tentei encontrá-la.Conteúdo
[G] rep
Temos um arquivo de texto com um hash em cada linha. Provavelmente o melhor lugar para ir é grep.grep -m 1 '^XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' pwned-passwords-sha1-ordered-by-count-v5.txtMinha senha estava no topo da lista com uma frequência de mais de 1.500 vezes, então é realmente péssimo. Consequentemente, os resultados da pesquisa retornaram quase instantaneamente.Mas nem todo mundo tem senhas fracas. Eu queria verificar quanto tempo levaria para encontrar o pior cenário - o último hash do arquivo:time grep -m 1 '^4541A1E4605EEBF3F4C166329C18502DF75D348A' pwned-passwords-sha1-ordered-by-count-v5.txtResultado: 33,35s user 23,39s system 41% cpu 2:15,35 totalIsso é triste. Afinal, desde que meus emails foram invadidos, eu queria verificar a presença de todas as minhas senhas antigas e novas no banco de dados. Mas um grep de dois minutos simplesmente não permite que você faça isso confortavelmente. Claro, eu poderia escrever um script, executá-lo e dar um passeio, mas isso não é uma opção. Eu queria encontrar uma solução melhor e aprender alguma coisa.Estrutura Trie
A primeira ideia foi usar uma estrutura de dados trie. A estrutura parece ideal para armazenar hashes SHA-1. O alfabeto é pequeno, portanto os nós também serão pequenos, assim como o arquivo resultante. Talvez até caiba na RAM? A pesquisa de chaves deve ser muito rápida.Então eu implementei essa estrutura. Em seguida, ele pegou os primeiros 1.000.000 de hashes do banco de dados de origem para criar o arquivo resultante e verificar se tudo está no arquivo criado.Sim, eu consegui encontrar tudo no arquivo, então a estrutura funcionou bem. O problema era diferente.O arquivo resultante foi lançado no tamanho 2283686592B (2,2 GB). Isto não é bom. Vamos contar e ver o que acontece. Um nó é uma estrutura simples de dezesseis valores de 32 bits. Os valores são "ponteiros" para os seguintes nós com o símbolo de hash SHA-1 especificado. Portanto, um nó ocupa 16 * 4 bytes = 64 bytes. Parece ser um pouco? Mas se você pensar bem, um nó representa um caractere em um hash. Portanto, no pior dos casos, o hash SHA-1 terá 40 * 64 bytes = 2560 bytes. Isso é muito pior do que, por exemplo, uma representação textual de um hash que ocupa apenas 40 bytes.A estrutura trie tem a vantagem de reutilizar nós. Se você tiver duas palavras aaae abb, o nó para os primeiros caracteres será reutilizado, porque os caracteres são os mesmos - a.Vamos voltar ao nosso problema. Vamos calcular quantos nós estão armazenados no arquivo resultante: file_size / node_size = 2283686592 / 64 = 35682603Agora vamos ver quantos nós serão criados no pior caso a partir de um milhão de hashes: 1000000 * 40 = 40000000assim, a estrutura trie reutiliza apenas 40000000 - 35682603 = 4317397nós, o que representa 10,8% do pior cenário.Com esses indicadores, o arquivo resultante para todo o banco de dados HIBP levaria 1421513361920 bytes (1,02 TB). Eu nem tenho disco rígido suficiente para verificar a velocidade da pesquisa de chaves.Naquele dia, descobri que a estrutura trie não é adequada para dados relativamente aleatórios.Vamos procurar outra solução.Pesquisa binária
Os hashes SHA-1 têm dois recursos interessantes: são comparáveis entre si e têm o mesmo tamanho.Graças a isso, podemos processar o banco de dados HIBP original e criar um arquivo a partir dos valores SHA-1 classificados.Mas como classificar um arquivo de 22 GB?Questão. Por que classificar o arquivo de origem? HIBP retorna um arquivo com seqüências de caracteres já classificadas por hashes.
Responda. Eu simplesmente não pensei nisso. Naquele momento, eu não sabia sobre o arquivo classificado.Ordenação
Classificar todos os hashes na RAM não é uma opção; eu não tenho muita RAM. A solução foi esta:- Divida um arquivo grande em arquivos menores que cabem na RAM.
- Baixe dados de arquivos pequenos, classifique na RAM e escreva de volta para os arquivos.
- Combine todos os arquivos pequenos e classificados em um grande.
Com um arquivo classificado grande, você pode pesquisar nosso hash usando uma pesquisa binária. O acesso ao disco rígido é importante. Vamos calcular quantos hits são necessários em uma pesquisa binária: log2(555278657) = 29.0486367039ou seja, 30 hits. Não é tão ruim.No primeiro estágio, a otimização pode ser realizada. Converta hashes de texto em dados binários. Isso reduzirá o tamanho dos dados resultantes pela metade: de 22 para 11 GB. Bem.Por que voltar atrás?
Naquele momento, percebi que você pode ser mais esperto. E se você não combinar arquivos pequenos em um arquivo grande, mas realizar uma pesquisa binária em arquivos pequenos classificados na RAM? O problema é como encontrar o arquivo desejado para procurar a chave. A solução é muito simples. Nova abordagem:- Crie 256 arquivos com os nomes "00" ... "FF".
- Ao ler hashes de um arquivo grande, escreva hashes que começam com "00 .." em um arquivo chamado "00", hashes que começam com "01 .." em um arquivo "01" e assim por diante.
- Baixe dados de arquivos pequenos, classifique na RAM e escreva de volta para os arquivos.
Tudo é muito simples. Além disso, outra opção de otimização aparece. Se o hash estiver armazenado no arquivo "00", sabemos que começa com "00". Se o hash estiver armazenado no arquivo "F2", ele começará com "F2". Assim, ao escrever hashes em arquivos pequenos, podemos omitir o primeiro byte de cada hash! Isso representa 5% de todos os dados. 555 MB são salvos no total.Paralelismo
A separação em arquivos menores oferece outra oportunidade de otimização. Os arquivos são independentes um do outro, para que possamos classificá-los em paralelo. Lembramos que todos os seus processadores gostam de suar ao mesmo tempo;)Não seja um bastardo egoísta
Quando implementei a solução acima, percebi que outras pessoas provavelmente tinham um problema semelhante. Provavelmente muitos outros também baixam e pesquisam o banco de dados HIBP. Então eu decidi compartilhar meu trabalho.Antes disso, revisei minha abordagem novamente e encontrei alguns problemas que gostaria de corrigir antes de publicar o código e as ferramentas no Github.Em primeiro lugar, como usuário final, eu não gostaria de usar uma ferramenta que cria muitos arquivos estranhos com nomes estranhos, nos quais não está claro o que está armazenado, etc.Bem, isso pode ser resolvido combinando os arquivos "00" .. "FF" um arquivo grande.Infelizmente, ter um arquivo grande para classificação coloca um novo problema. E se eu quiser inserir um hash neste arquivo? Apenas um hash. Isso é apenas 20 bytes. Ah, o hash começa com "000000000 ..". OK. Vamos liberar espaço movendo 11 GB de outros hashes ...Você entende qual é o problema. Inserir dados no meio de um arquivo não é a operação mais rápida.Outra desvantagem dessa abordagem é que você precisa armazenar os primeiros bytes novamente - são 555 MB de dados.E por último, mas não menos importante, a pesquisa binária dos dados armazenados no disco rígido é muito mais lenta que o acesso à RAM. Quero dizer, são 30 leituras de disco versus 0 leituras de disco.B3
Novamente. O que temos e o que queremos alcançar.Temos 11 GB de valores binários. Todos os valores são comparáveis e têm o mesmo tamanho. Queremos descobrir se uma chave específica está presente nos dados armazenados e também queremos alterar o banco de dados. E para que tudo funcione rapidamente.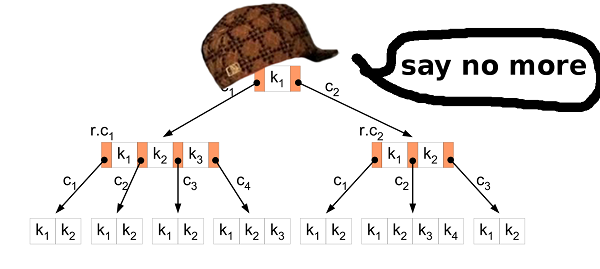 Árvore B? DireitaA árvore B permite minimizar o acesso ao disco ao pesquisar, modificar etc. Ele possui muito mais recursos, mas precisamos desses dois.
Árvore B? DireitaA árvore B permite minimizar o acesso ao disco ao pesquisar, modificar etc. Ele possui muito mais recursos, mas precisamos desses dois.Classificação de inserção
A primeira etapa é converter os dados do arquivo de origem HIBP na árvore B. Isso significa que você precisa extrair todos os hashes e inseri-los na estrutura. O algoritmo de inserção usual é adequado para isso. Mas no nosso caso, você pode fazer melhor.Inserir muitos dados brutos em uma árvore B é um cenário bem conhecido. Pessoas sábias inventaram uma abordagem melhor para isso do que a inserção usual. Primeiro de tudo, você precisa classificar os dados. Isso pode ser feito como descrito acima (divida o arquivo em arquivos menores e classifique-os na RAM). Em seguida, insira os dados na árvore.No algoritmo usual, se você encontrar o nó folha em que deseja inserir o valor e ele for preenchido, crie um novo nó (à direita) e distribua uniformemente os valores entre os dois nós, esquerdo e direito (mais um valor vai para o nó pai) mas não é importante aqui). Em resumo, os valores no nó esquerdo são sempre menores que os valores à direita. O fato é que, quando você insere os dados classificados, sabe que valores menores não serão mais inseridos na árvore e, portanto, nenhum outro valor irá para o nó esquerdo. O nó esquerdo permanece meio vazio o tempo todo. Além disso, se você inserir valores suficientes, poderá descobrir que o nó direito está cheio; portanto, é necessário mover metade dos valores para o novo nó direito. O nó de divisão permanece meio vazio, como no caso anterior. Etc…Como resultado, depois de todas as inserções, você obtém uma árvore na qual quase todos os nós estão meio vazios. Este não é um uso muito eficiente do espaço. Nós podemos fazer melhor.Separado ou não?
No caso de inserir dados classificados, você pode fazer uma pequena modificação no algoritmo de inserção. Se o nó no qual você deseja colar o valor estiver cheio, não o quebre. Apenas crie um novo nó vazio e cole o valor no nó pai. Em seguida, quando você insere os seguintes valores (maiores que os anteriores), insere-os em um nó novo e vazio.Para preservar as propriedades da árvore B, após todas as inserções, é necessário classificar os nós mais à direita em cada camada da árvore (exceto a raiz) e dividir igualmente os valores desse nó extremo e seu vizinho esquerdo. Então você obtém a menor árvore possível.Propriedades da árvore HIBP
Ao projetar uma árvore B, você precisa escolher sua ordem. Ele mostra quantos valores podem ser armazenados em um nó, bem como quantos filhos o nó pode ter. Ao manipular esse parâmetro, podemos manipular a altura da árvore, o tamanho binário do nó etc.No HIBP, temos 555278657hashes. Suponha que queremos uma árvore com três alturas de altura (portanto, não precisamos mais de três operações de leitura para verificar a presença de um hash). Precisamos encontrar um valor de M tal que logM(555278657) < 3. Eu escolhi 1024. Esse não é o menor valor possível, mas permite inserir mais hashes e preservar a altura da árvore.Arquivo de saída
O arquivo de origem HIBP tem um tamanho de 22,8 GB. O arquivo de saída com a árvore B é de 12,4 GB. Demora cerca de 11 minutos para criá-lo na minha máquina (Intel Core i7-6700, 3,4 GHz, 16 GB RAM), disco rígido (não SSD).Benchmarks
A opção da árvore B mostra um resultado muito bom:| | tempo [μs] | % |
| -----------------: | ------------: | ------------: |
| okon 49 100
| grep '^ hash' | 135'350'000 | 276'224'489 |
| grep | 135'480'000 | 276'489'795 |
| C ++ linha por linha | 135'720'201 | 276'980'002 |
okon - biblioteca e CLI
Como eu disse, queria compartilhar meu trabalho com o mundo. Eu implementei uma biblioteca e uma interface de linha de comando para processar o banco de dados HIBP e pesquisar rapidamente por hashes. A pesquisa é tão rápida que pode, por exemplo, ser integrada a um gerenciador de senhas e fornecer feedback ao usuário cada vez que uma tecla é pressionada. Existem muitos usos possíveis.A biblioteca possui uma interface C, portanto pode ser usada em quase todos os lugares. CLI é uma CLI. Você pode simplesmente criar e executar (:O código está no meu repositório .Isenção de responsabilidade: o okon ainda não fornece uma interface para inserir valores na árvore B criada. Ele só pode processar o arquivo HIBP, criar uma árvore B e pesquisar nele. Essas funções funcionam muito bem, então decidi compartilhar o código e continuar trabalhando na inserção e outras funções possíveis.Links e discussão
Obrigado pela leitura
(: