
Em 2019, testemunhamos o brilhante uso do aprendizado de máquina. O modelo OpenAI GPT-2 demonstrou uma capacidade impressionante de escrever textos coerentes e emocionais superiores à nossa compreensão do que os modelos de linguagem modernos podem gerar. O GPT-2 não é uma arquitetura particularmente nova - lembra muito o Transformer-Decoder (Transformer somente decodificador). A diferença entre o GPT-2 é que ele é um modelo de linguagem verdadeiramente enorme, baseado no Transformer, treinado em um conjunto de dados impressionante. Neste artigo, examinaremos a arquitetura do modelo que nos permite obter tais resultados: examinaremos detalhadamente a camada de atenção e o uso do Transformer decodificador para tarefas que vão além da modelagem de linguagem.
Conteúdo
1: GPT-2
?
Word2vec , – , , . – , .
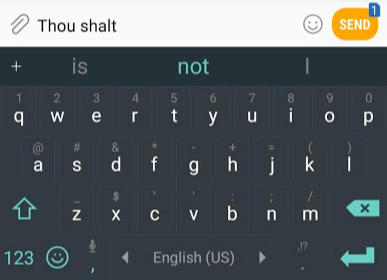
, GPT-2 , , , . GPT-2 40 (WebText), OpenAI . , , SwiftKey, 78 , GPT-2 500 , GPT-2 – 13 ( 6,5 ).

GPT-2 AllenAI GPT-2 Explorer. GPT-2 ( ), .
, – .. . – , - .
, , , , ( AlphaStar).
? , GPT-2 :
BERT'
:
, .
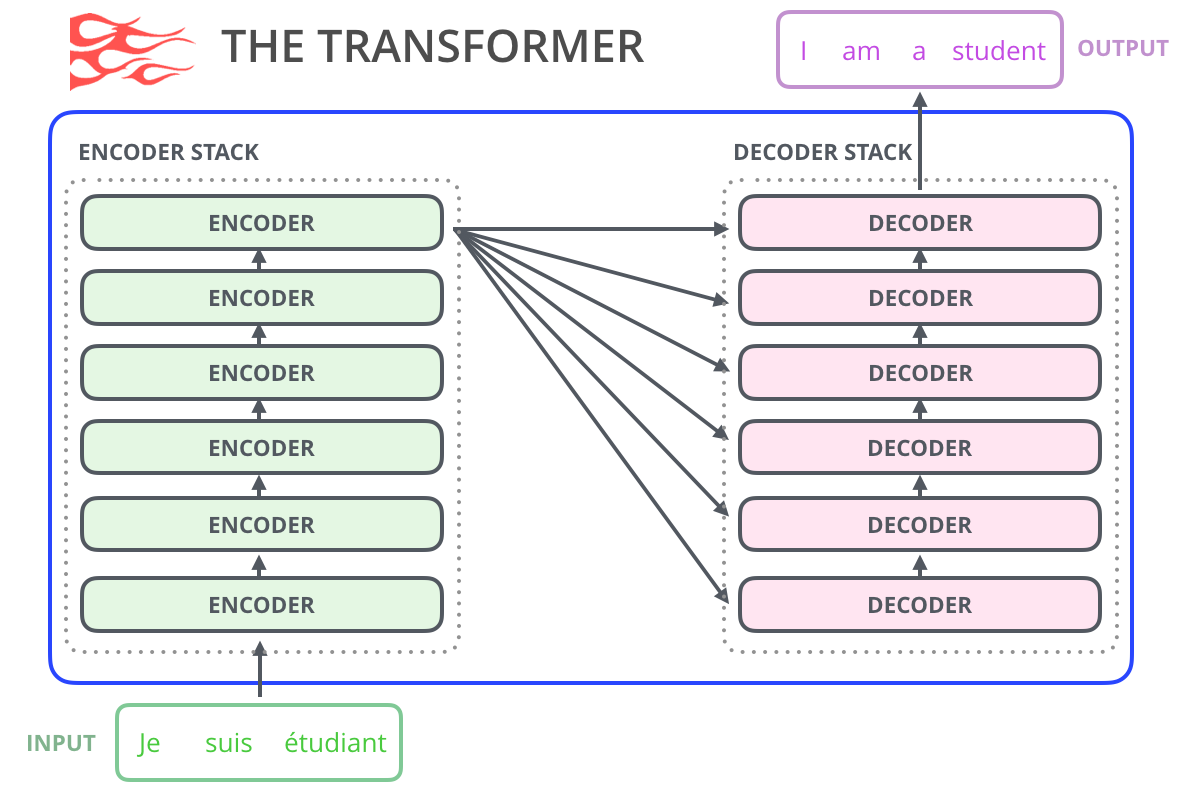
GPT-2 . BERT , , . . , GPT-2, , . , GPT-2 :
: , , . . «» (auto-regression) RNN .

GPT-2 TransformerXL XLNet . BERT . . , BERT . XLNet , .
.
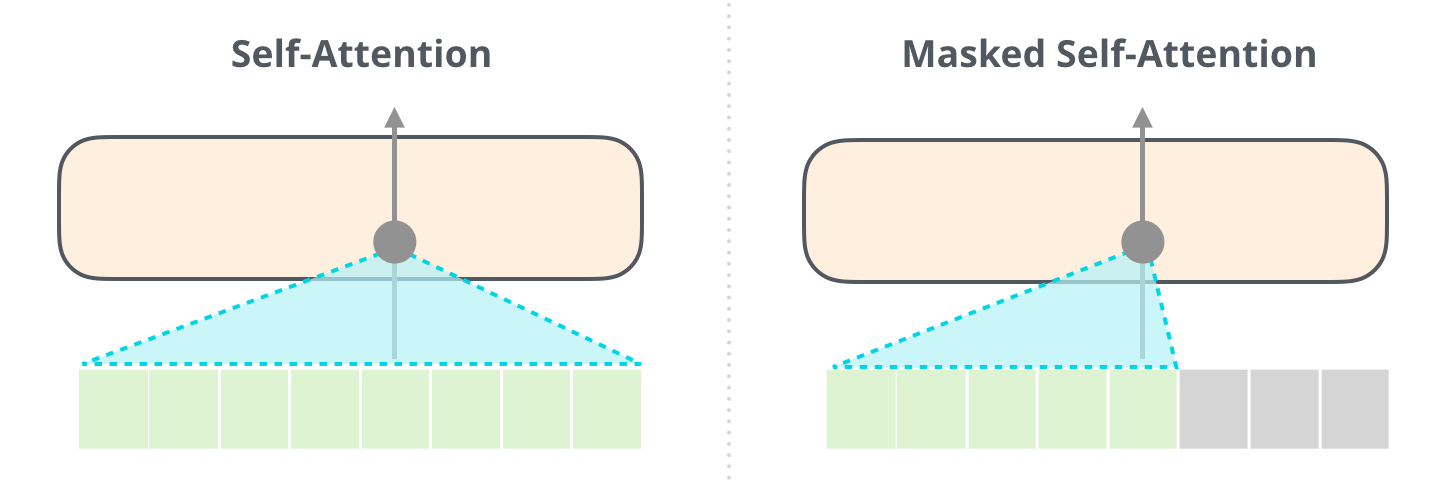
– :

(, 512 ). , .
– , . :

, [mask] , BERT', , , .
, , #4, , :
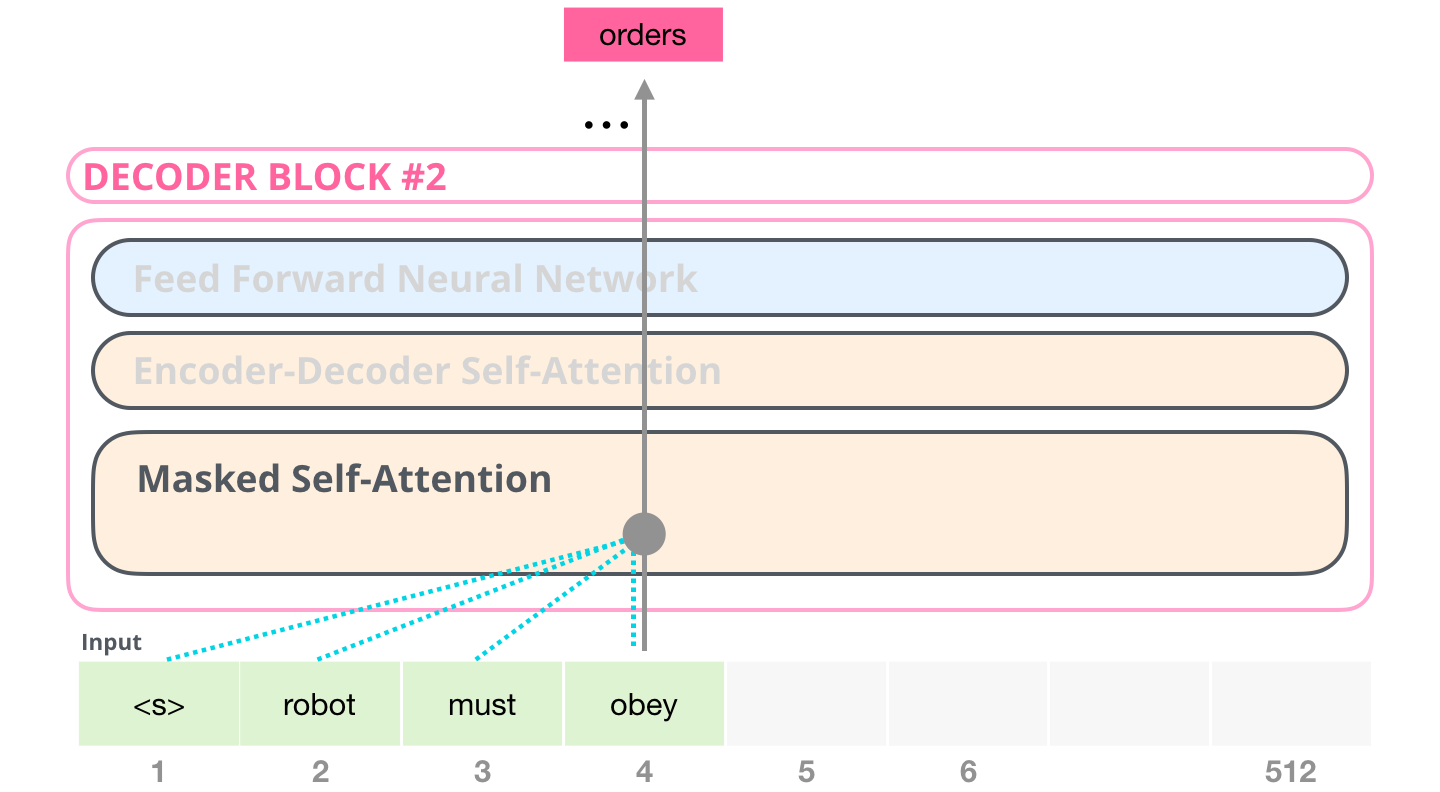
, BERT, GPT-2. . :
, «Generating Wikipedia by Summarizing Long Sequences» , : . «-». 6 :
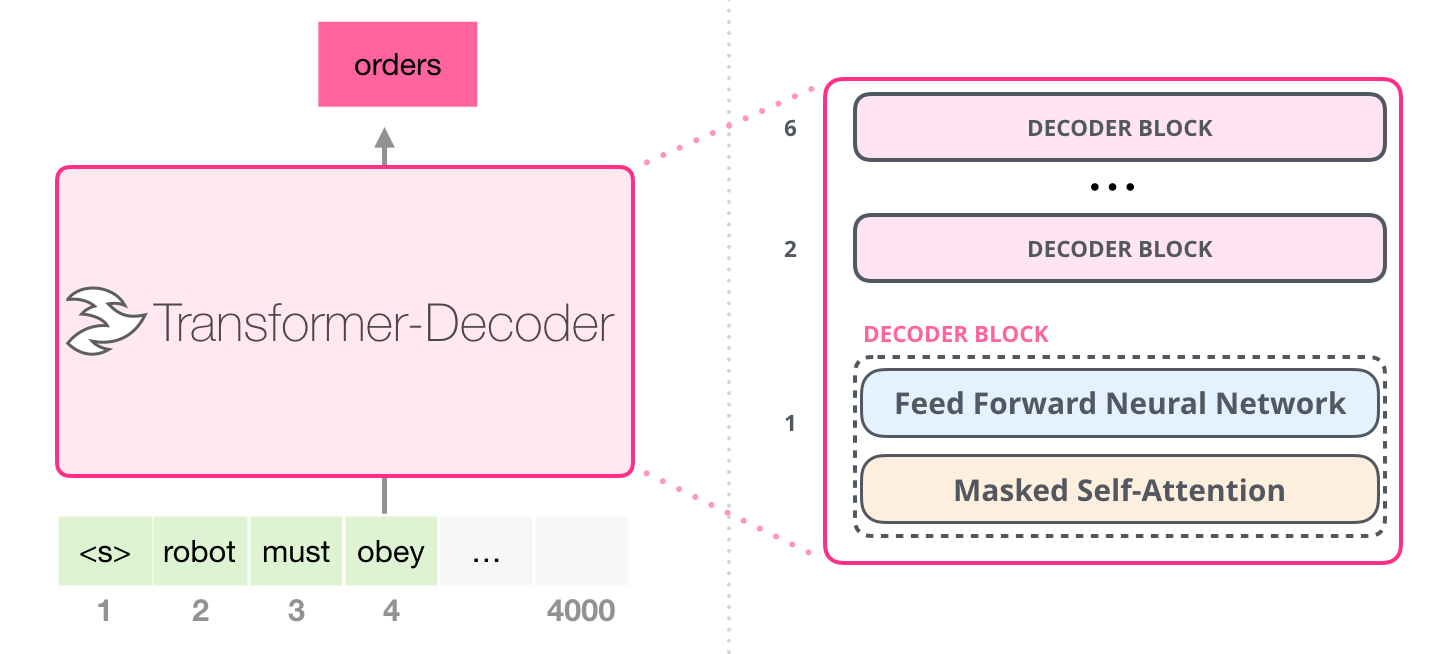
. , . , 4000 – 512 .
, , . « », / .
GPT-2 OpenAI .
- : GPT-2
, , . , , , , . (Budgie)
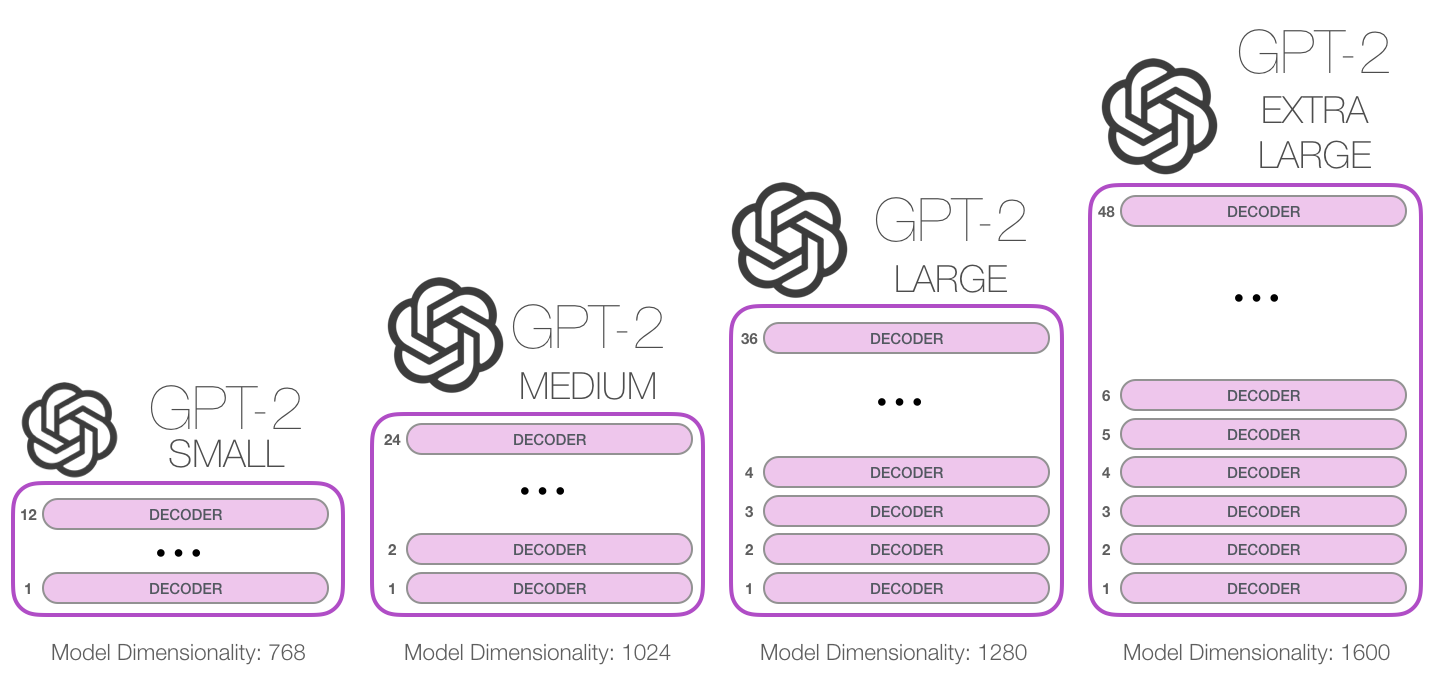
GPT-2 , .

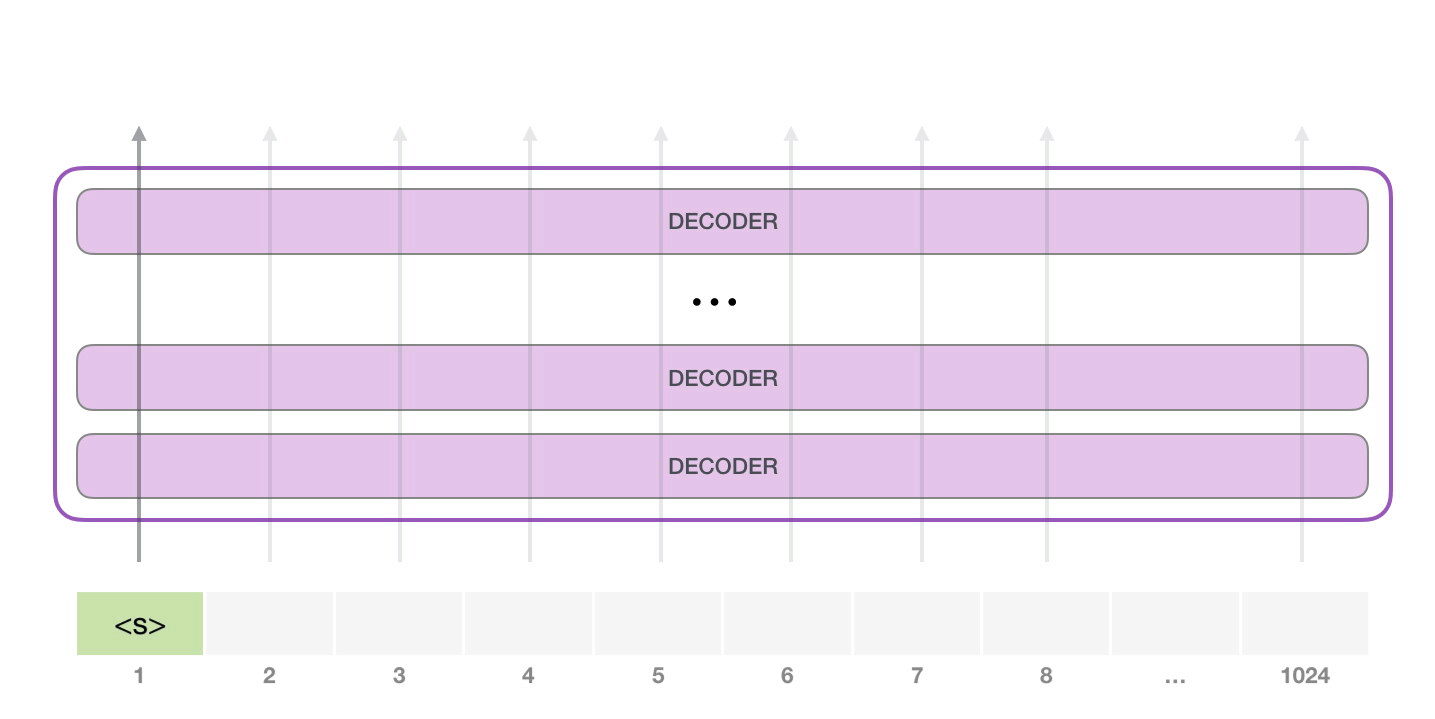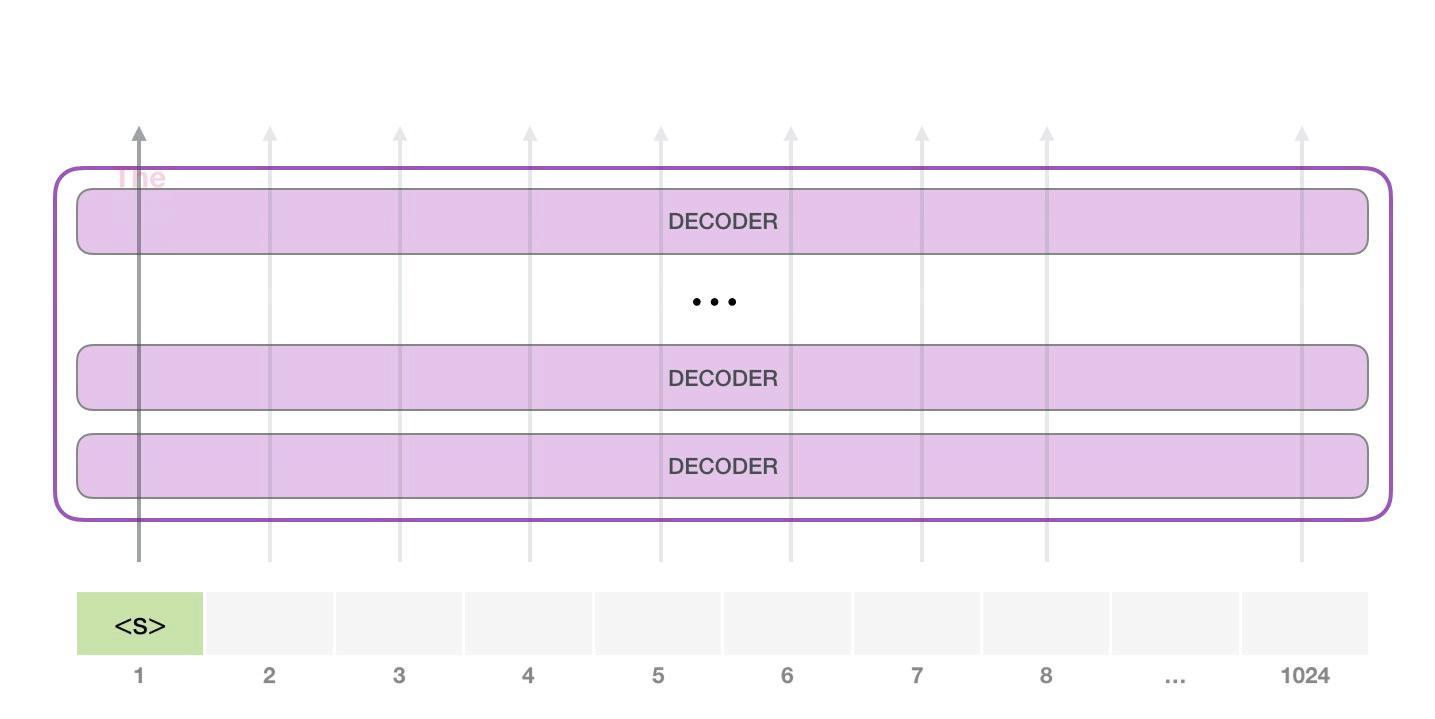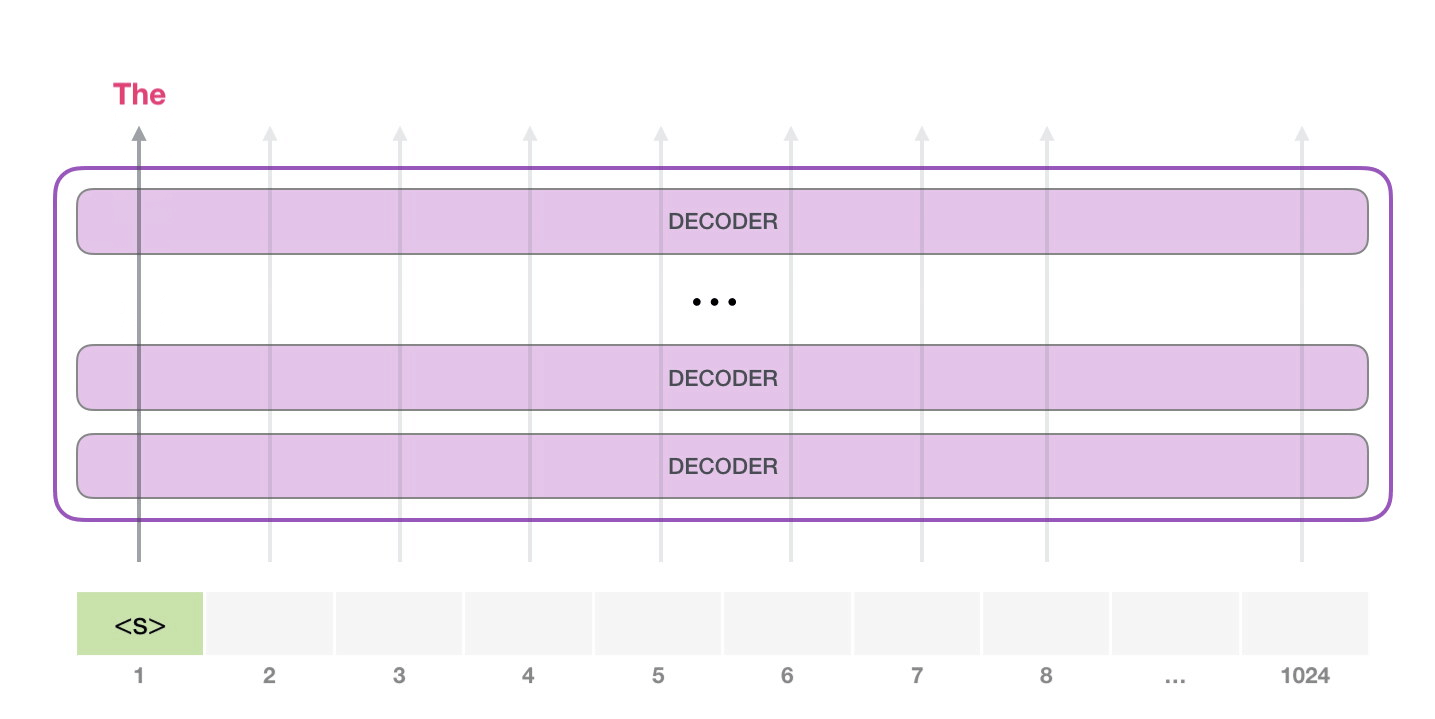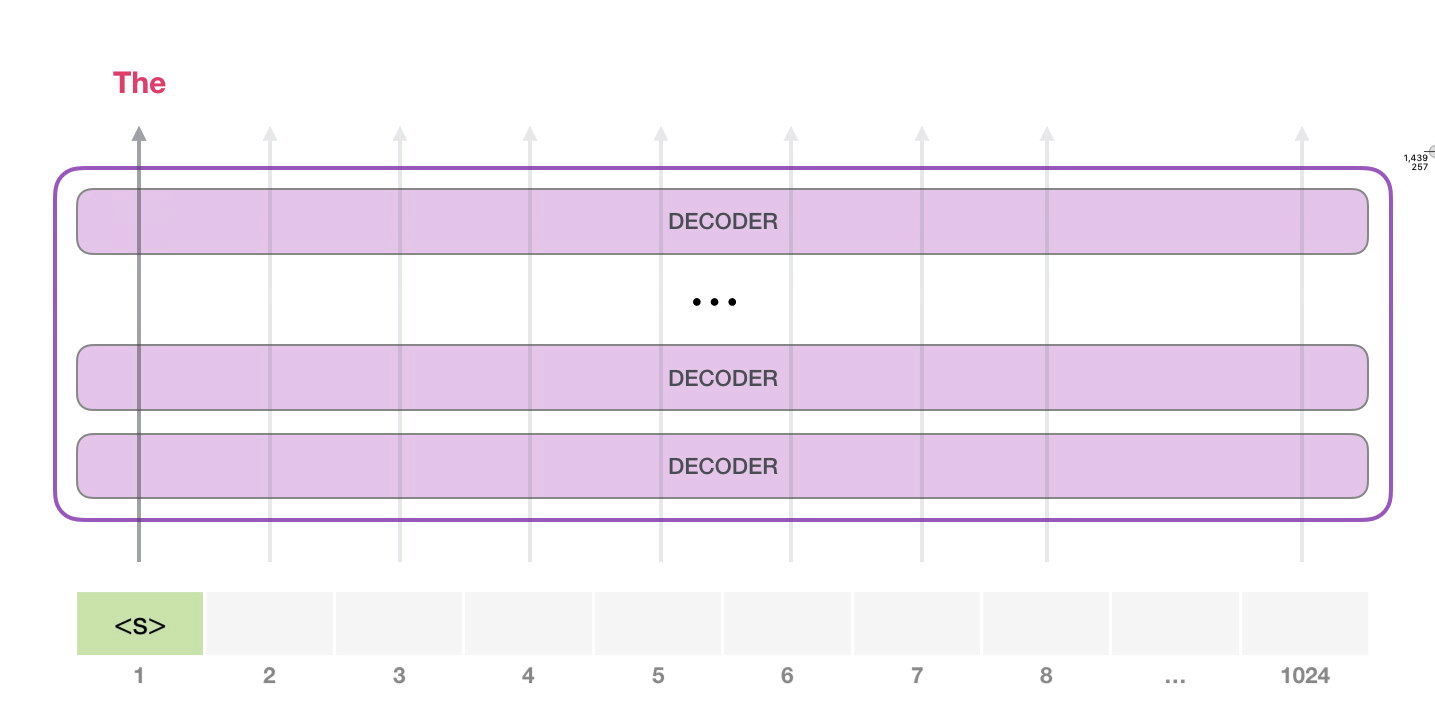
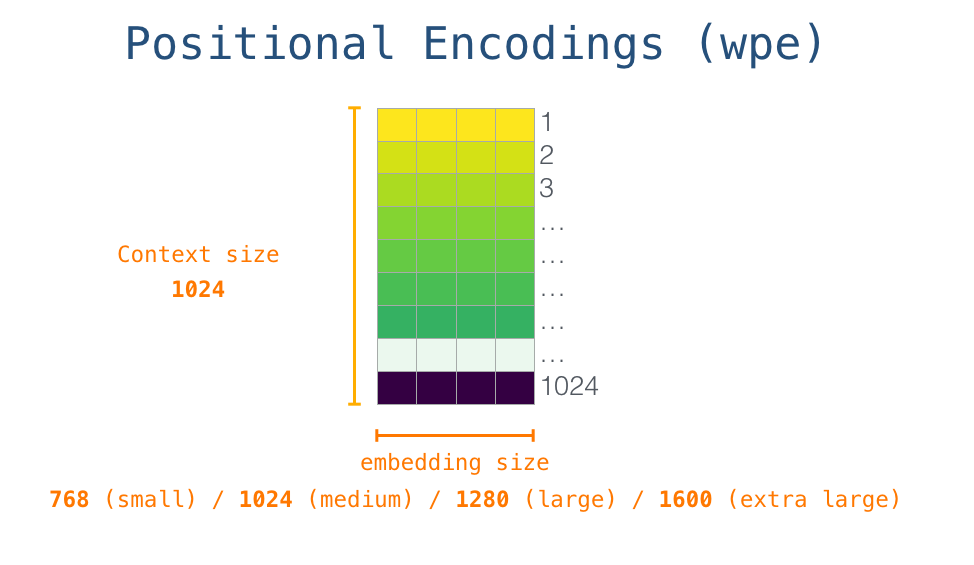
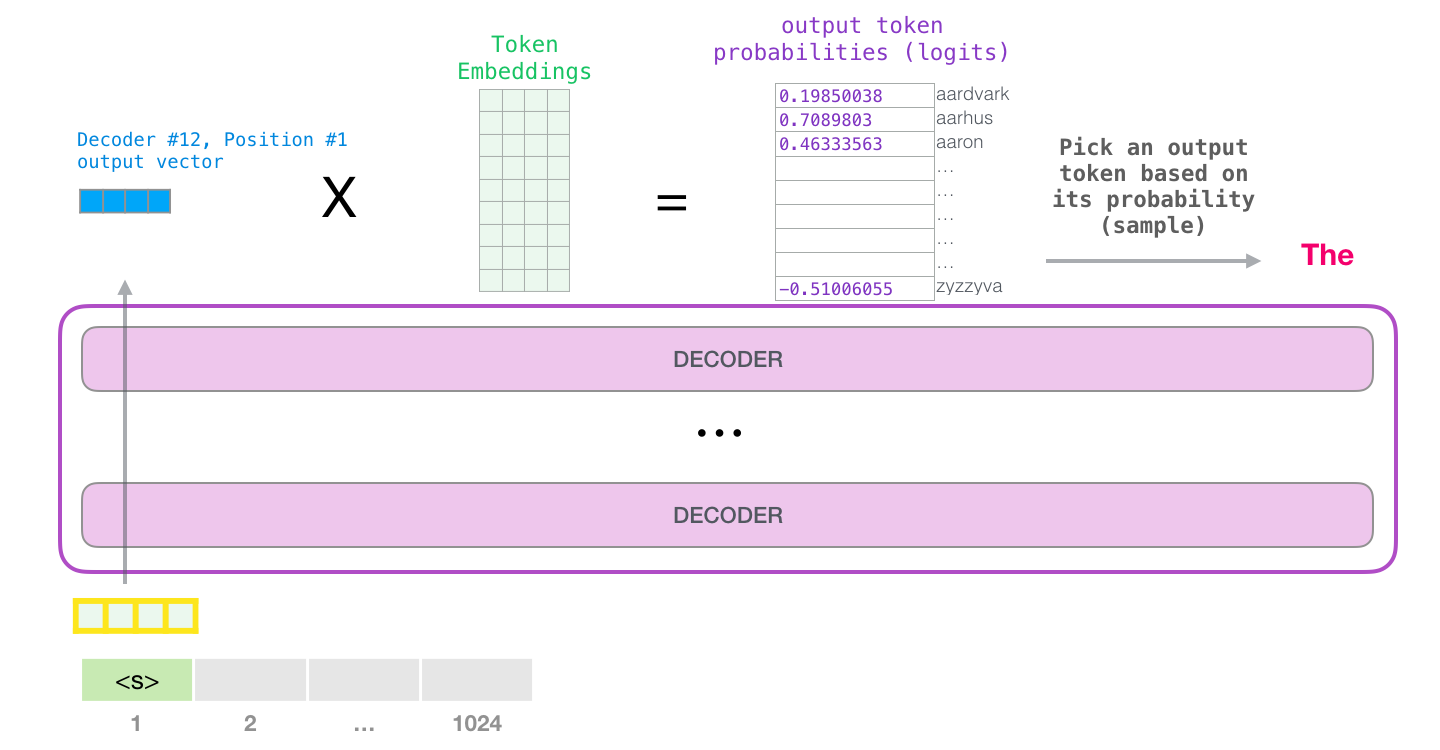
GPT-2 1024 . .
GPT-2 – ( ) (), (.. ). , ( <|endoftext|>; <|s|>).
, . , (score) – , (50 GPT-2). – «the». - – , , , , – . . GPT-2 top-k, , , (, , top-k = 1).
:
, . GPT-2 ( ). GPT-2 .
. . NLP-, , – , .
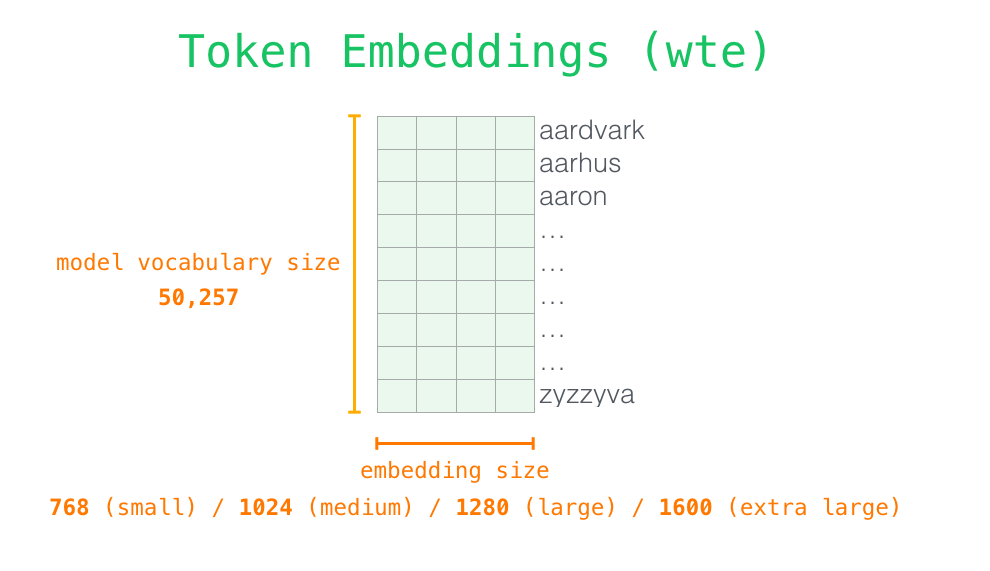
– , - . GPT-2. 768 /.
, <|s|> . , – , . , 1024 .
. , GPT-2.

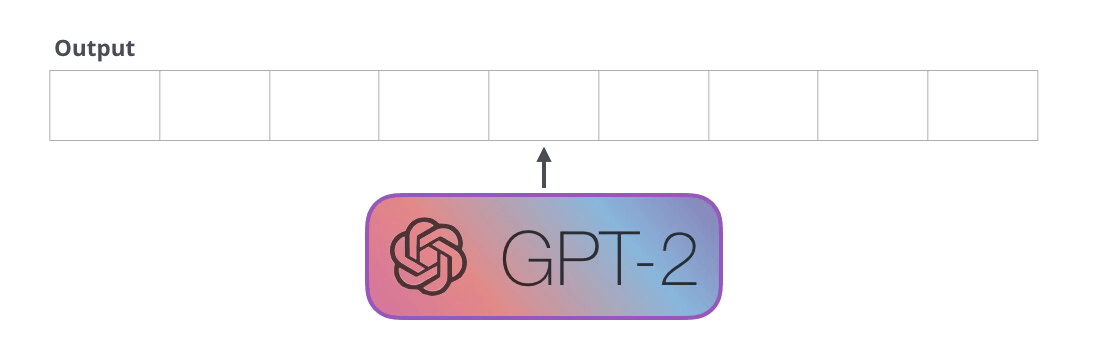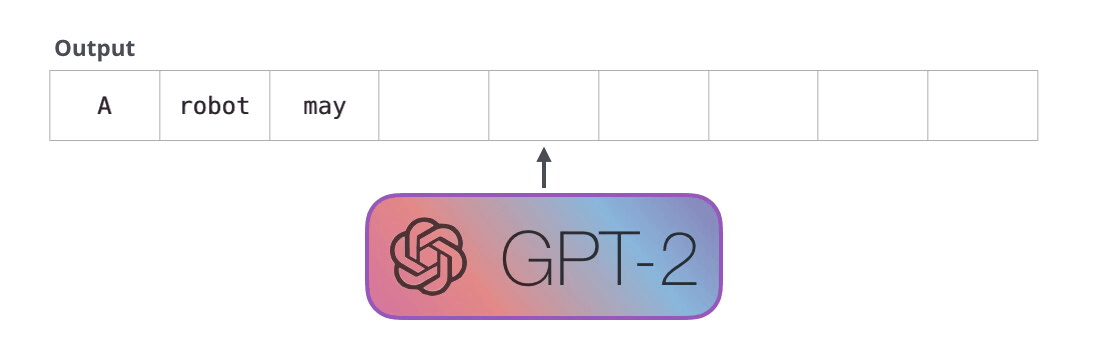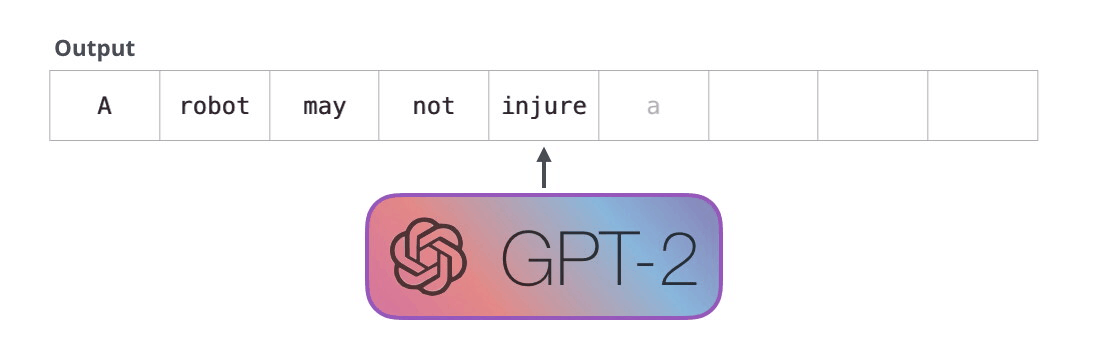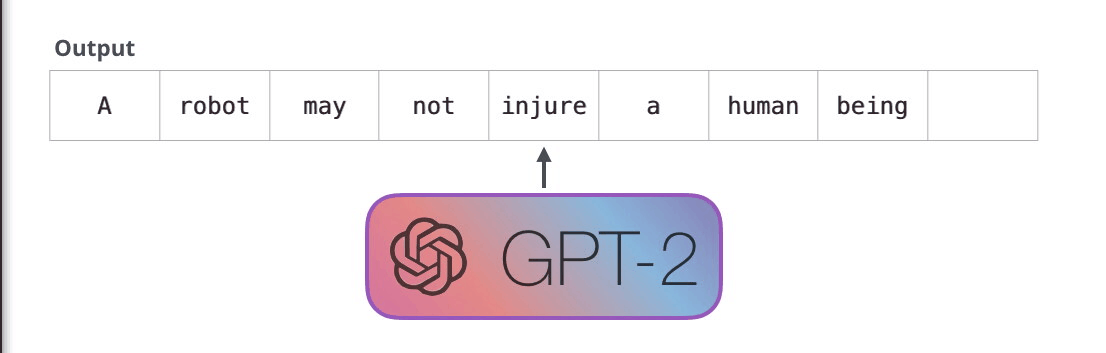
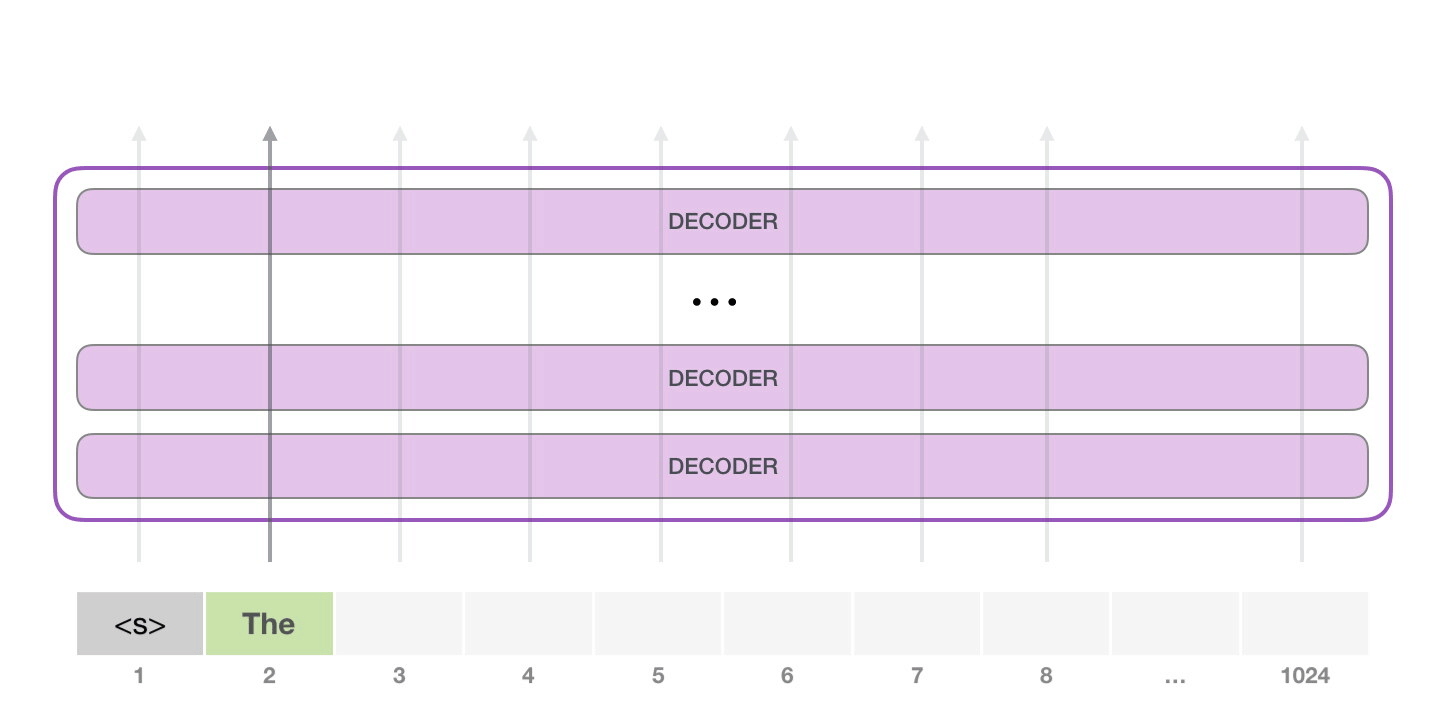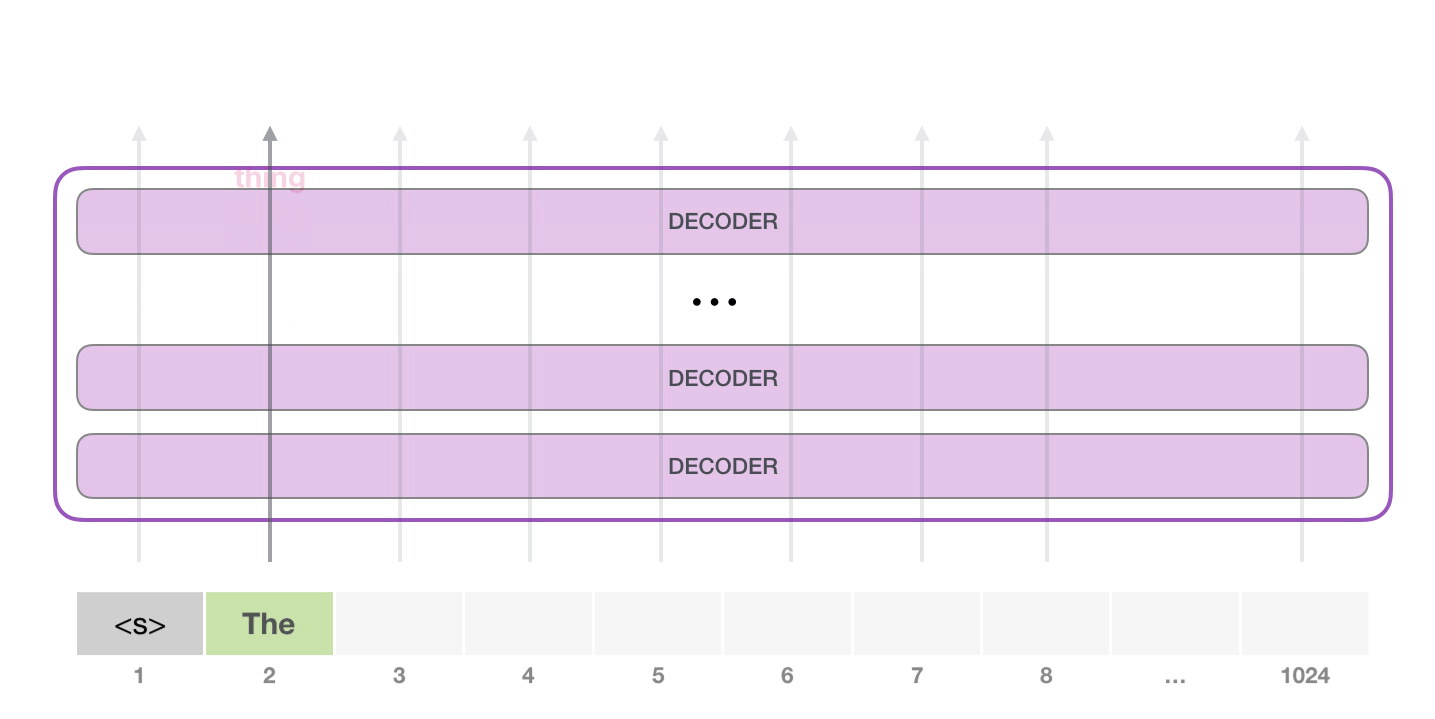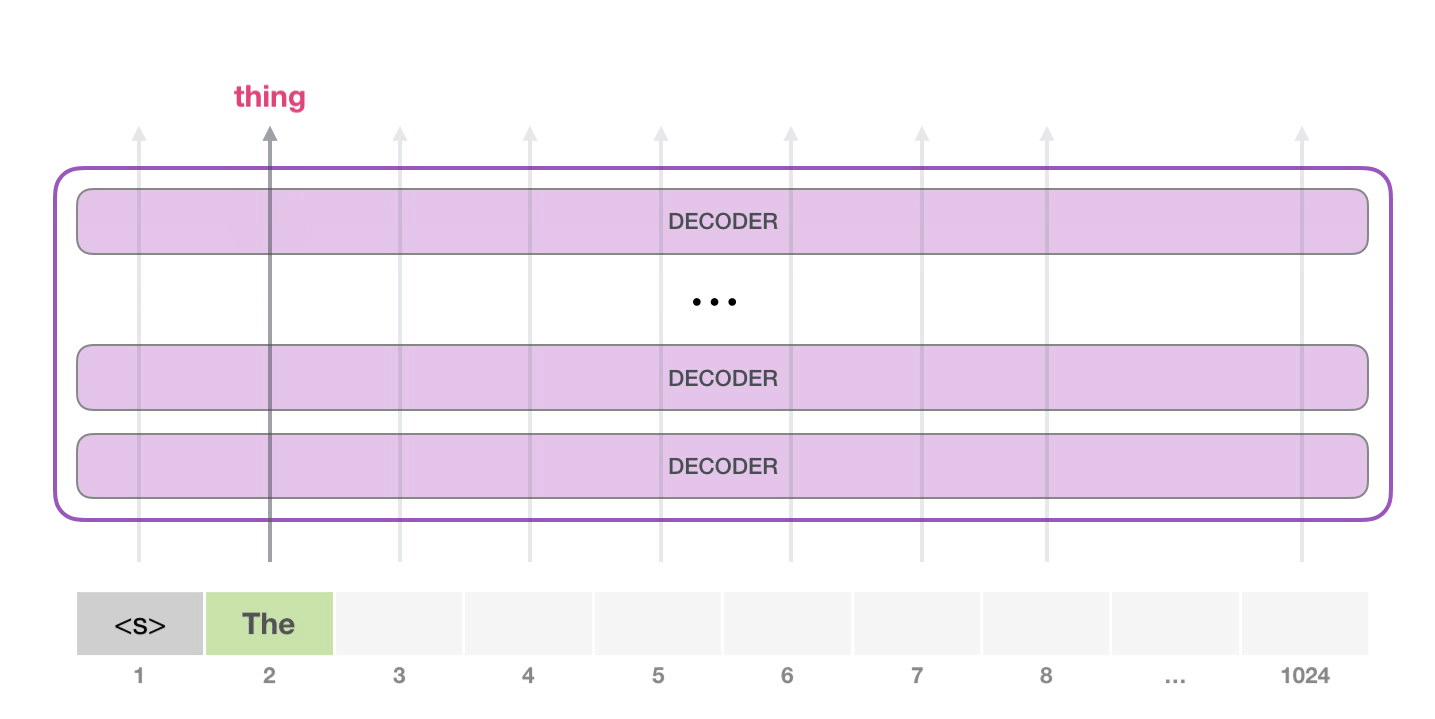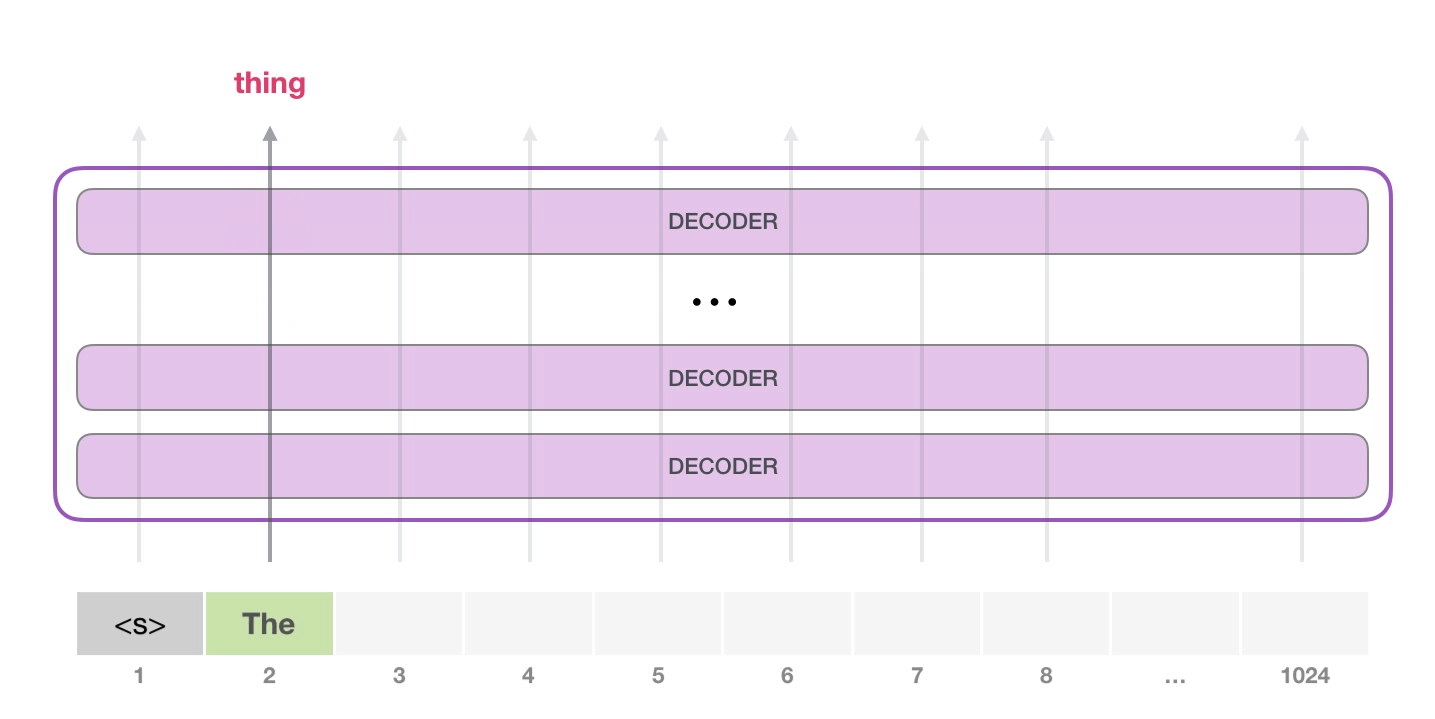
#1.
, , . , . , , .

. , :
, , , .
, . , . , , :
: , , ( ). , , .
, «a robot» «it». , , , .

. :
- – , ( ). , ;
- – . ;
- – ; , , .

. – , . . , – . , .
(: ).
, .
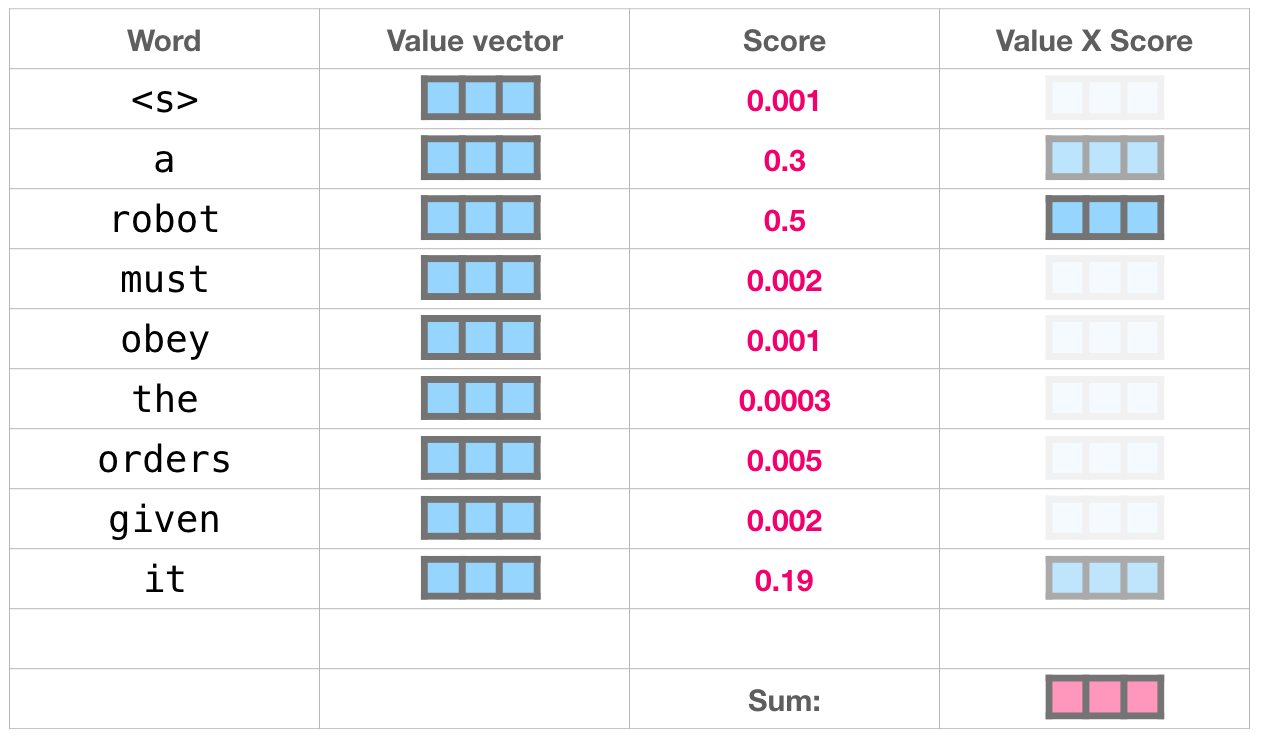
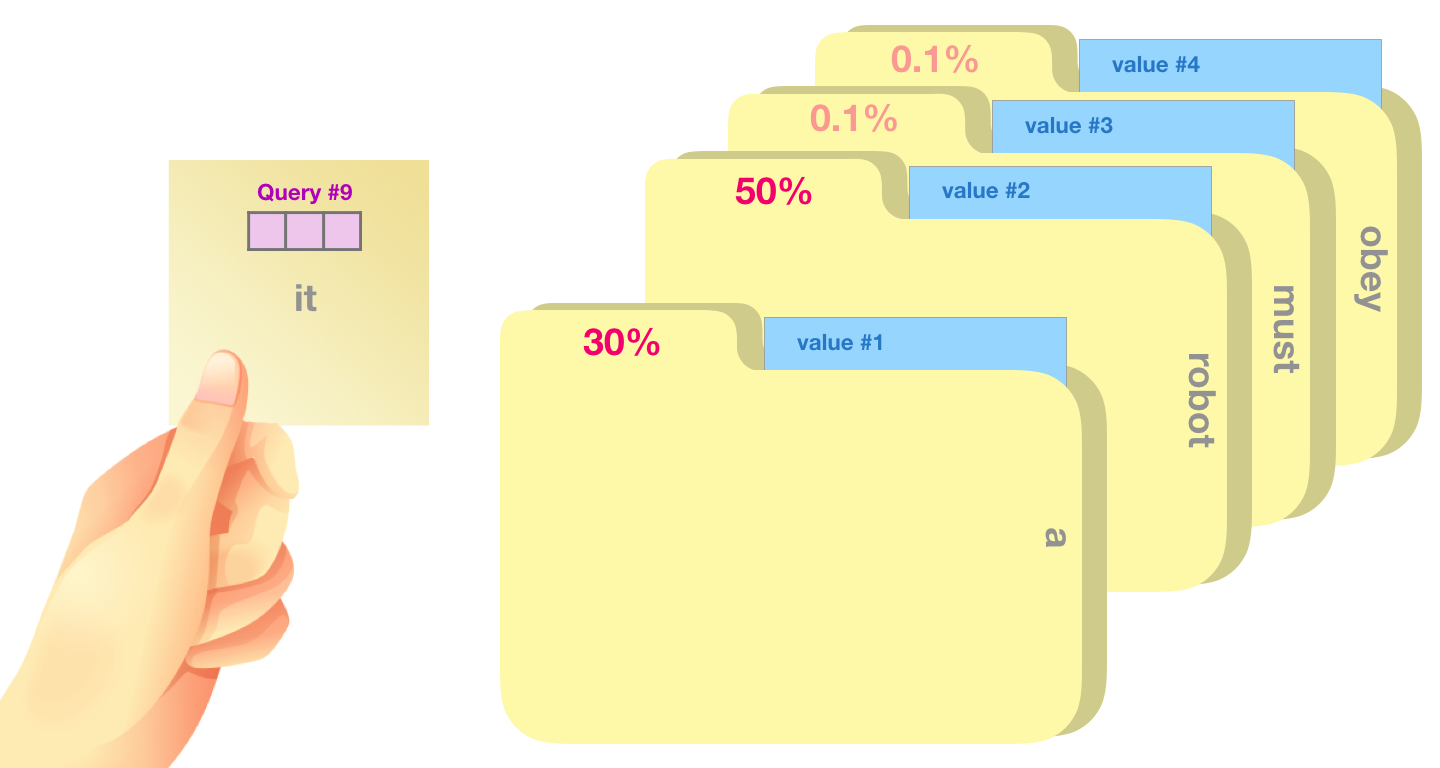
, 50% «robot», 30% «a» 19% – «it». . .
( ), .
, . .
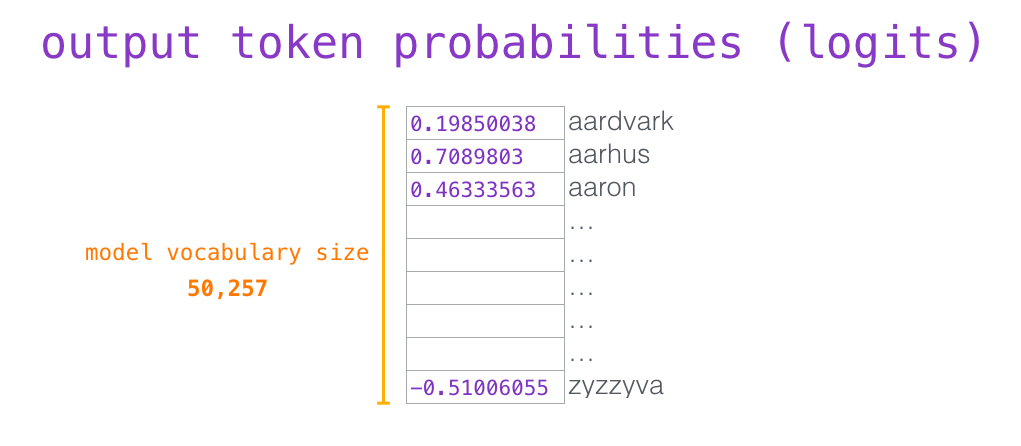
(top_k = 1). , . , , ( ). – top_k 40: 40 .
, . , (1024 ) .
: GPT-2,
, , GPT-2. , , . , ( TransformerXL XLNet).
, :
- «» «» ; GPT-2 (Byte Pair Encoding) . , .
- GPT-2 / (inference/evaluation mode). . . (512), 1, .
- / . .
- , . Transformer , .
- . «zoom in», :
2:
, «it»:

, . , , . , , .
( )
, . , 4 .
:
- , ;
- ;
- .
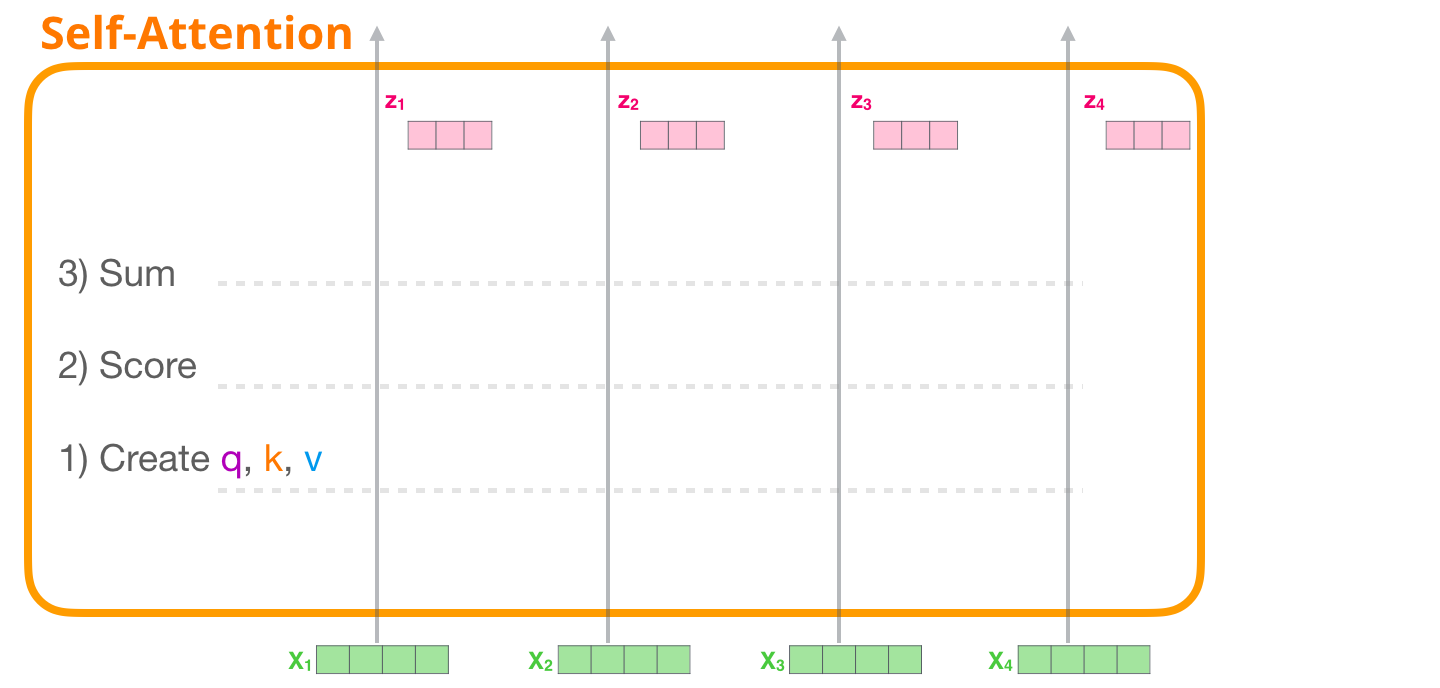
1 – ,
. . . ( «» ):

, WQ, WK, WV
2 –
, , №2: .
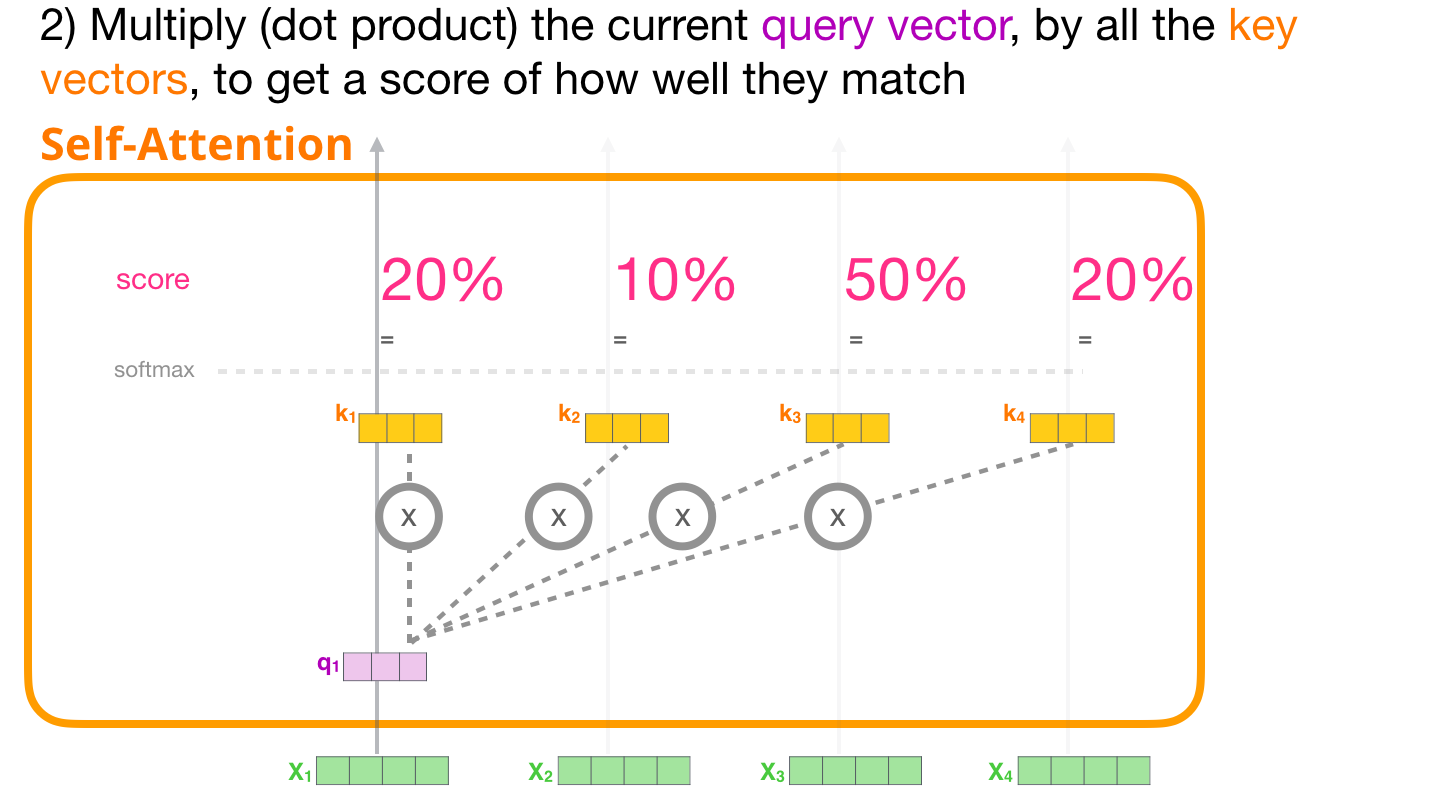
( ) ,
3 –
. , .
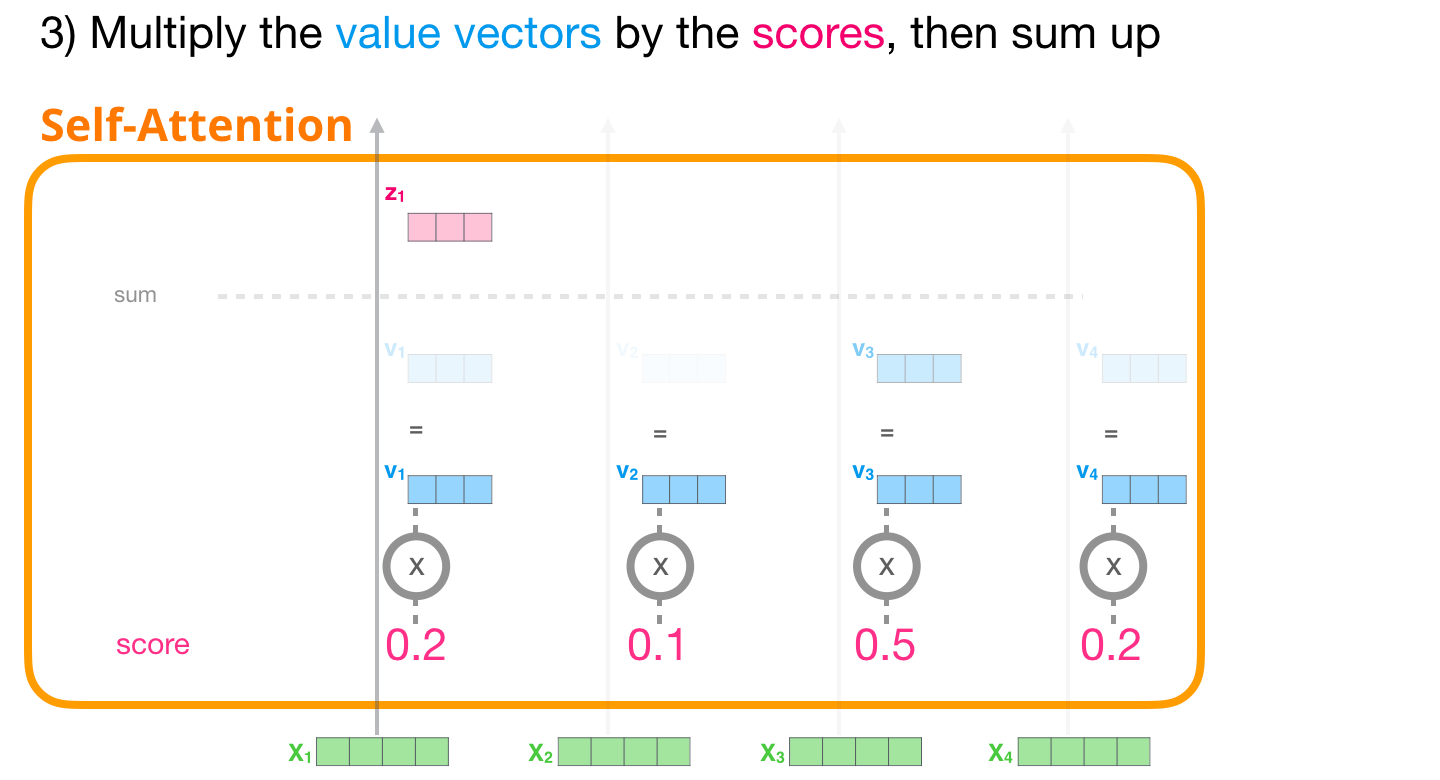
, – , .
, , . ( ).
, , , . №2. , . . , :
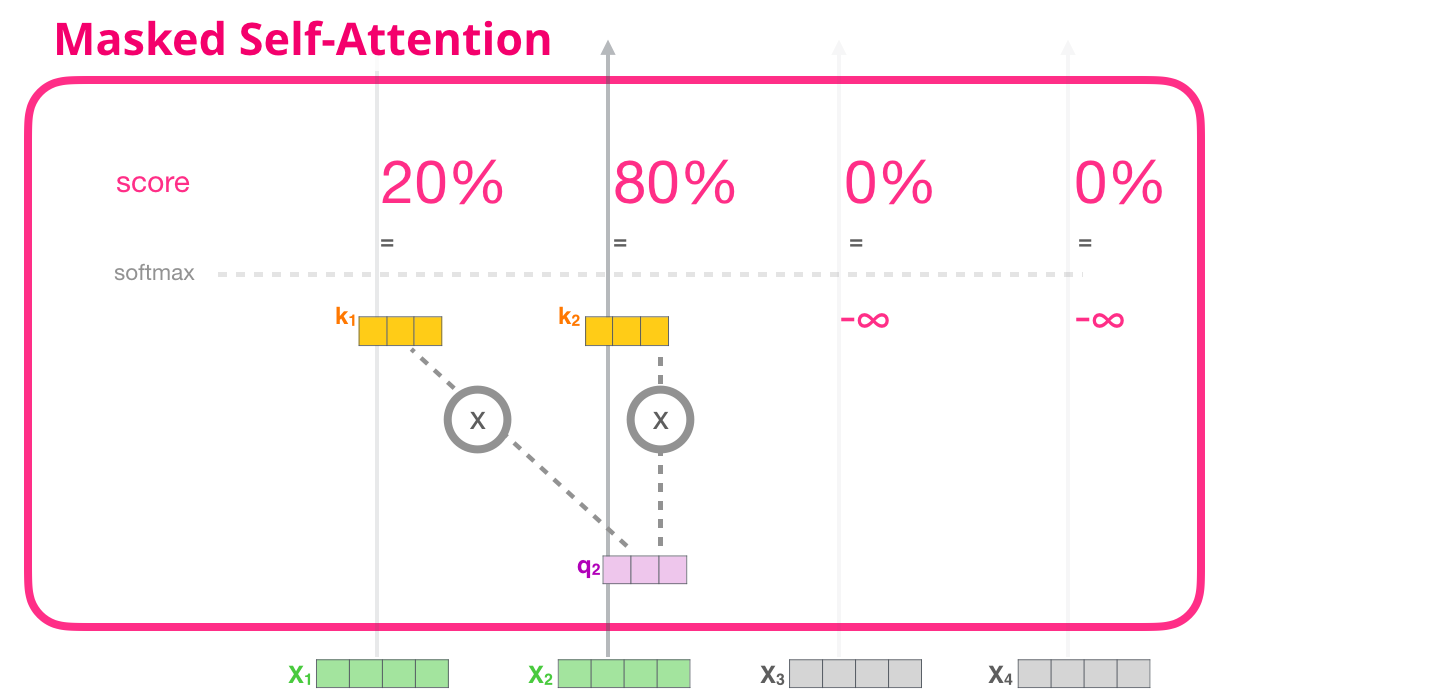
, (attention mask). , , («robot must obey orders»). 4 : ( , – ). .. , 4 , ( 4 ) .

, . , , ( ), :
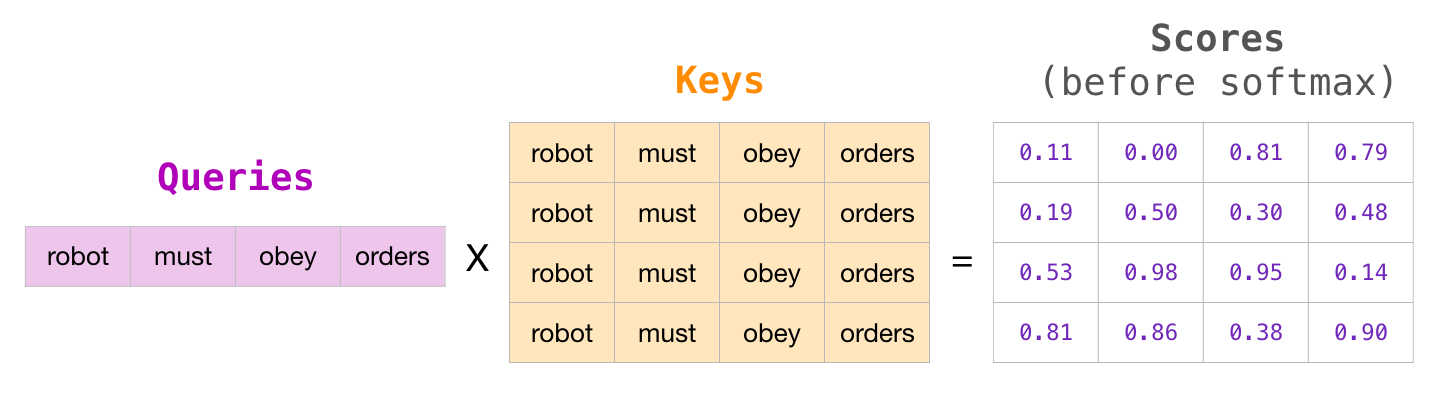
«» . , , – (-inf) (, -1 GPT-2):

, , , :

:
- ( №1), («robot»), 100% .
- ( №2), («robot must»), «must» 48% «robot» 52% «must».
- ..
GPT-2
GPT-2.
:
, GPT-2 , . , , , .
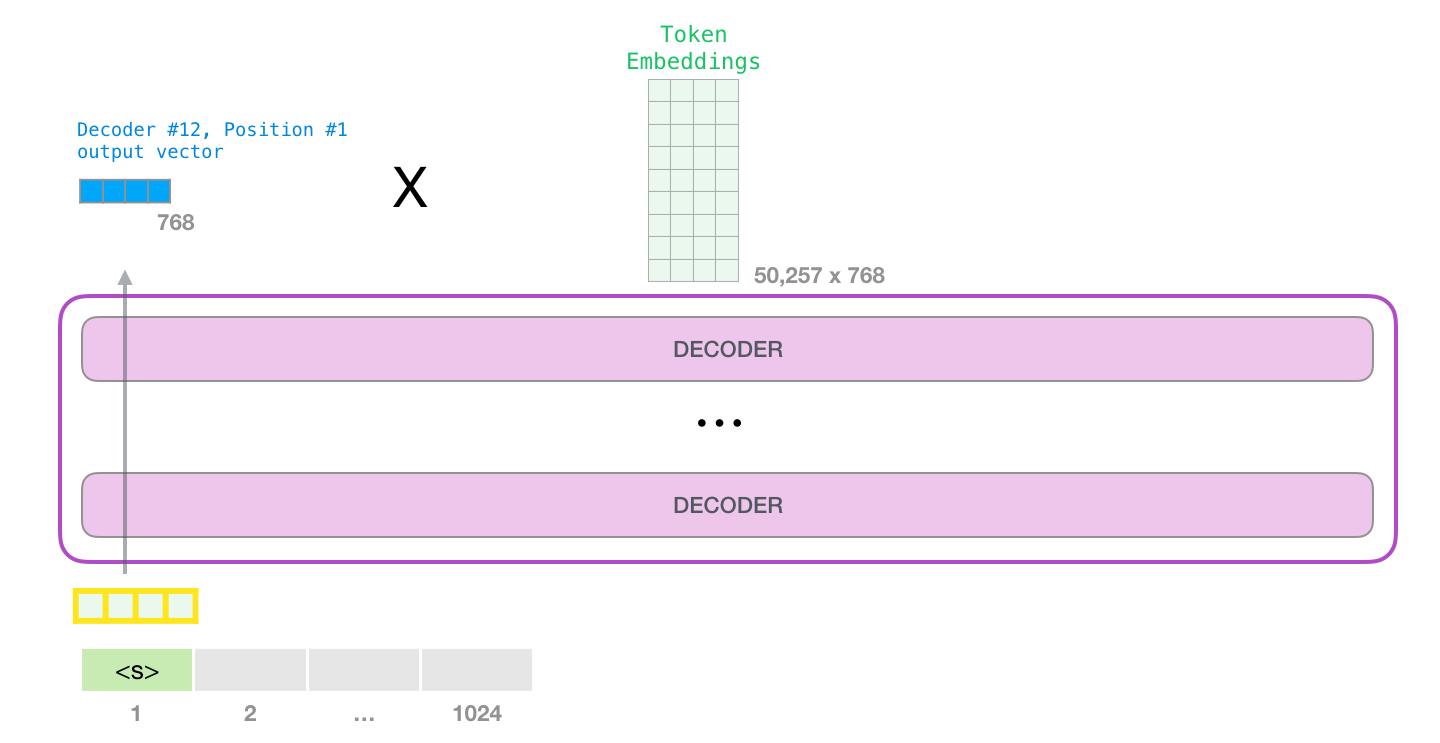
( <|s|>).
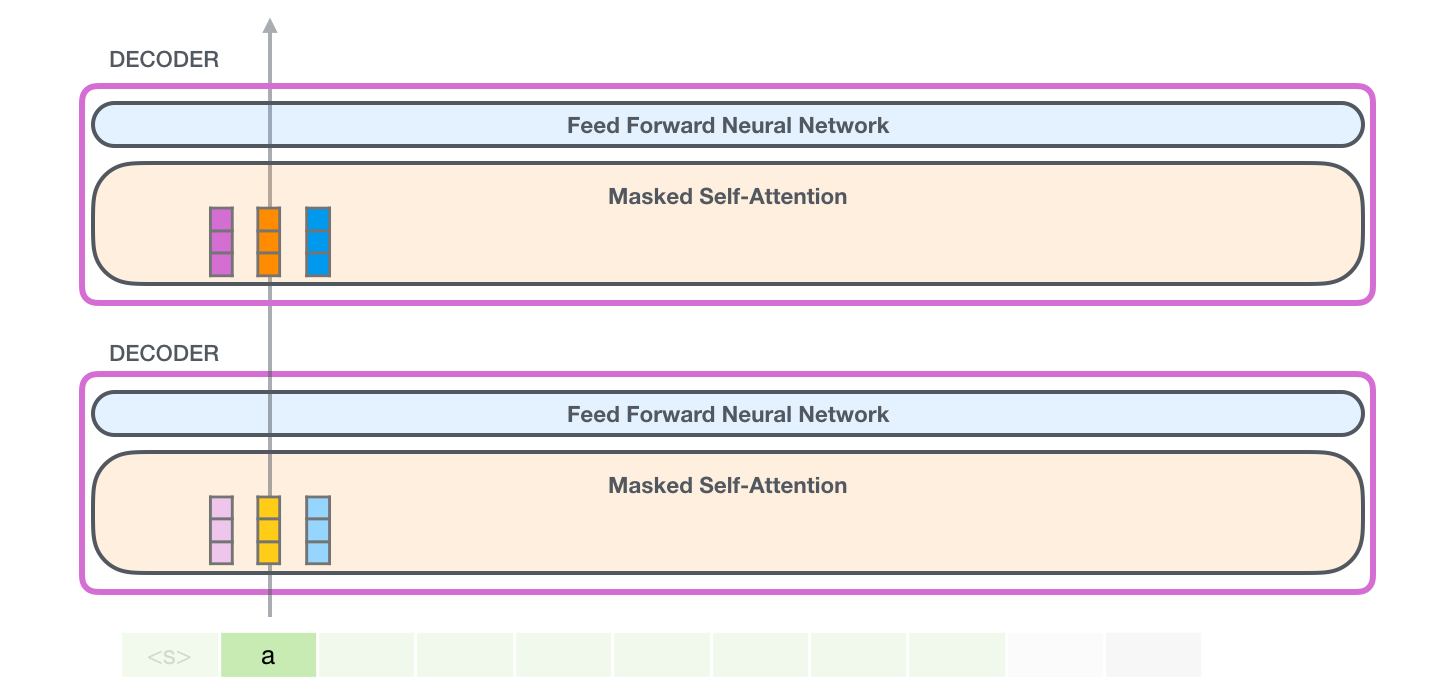
GPT-2 «a». :

, «robot», , «a» – , :

GPT-2: 1 – ,
, «it». , «it» + #9:
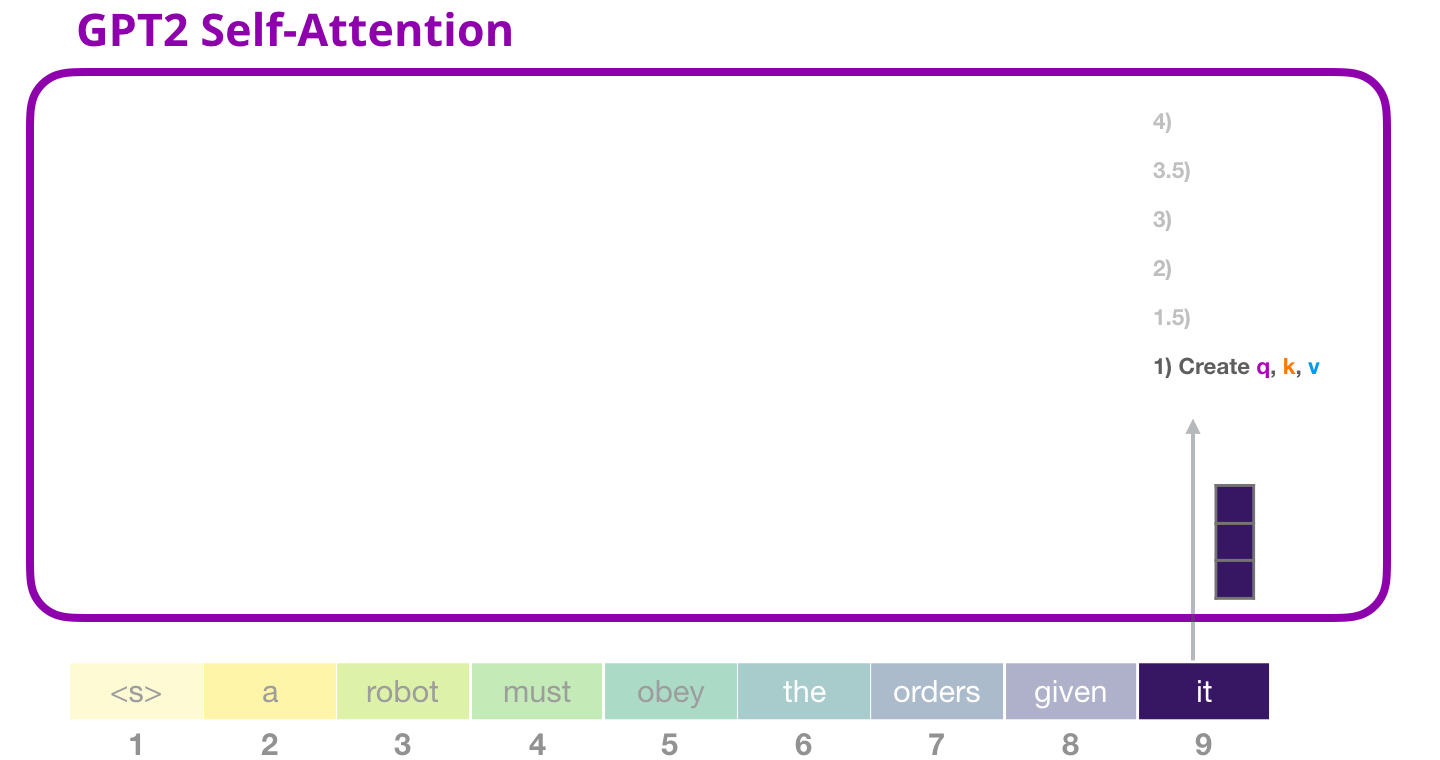
( ), , .

(bias vector),
, , «it».
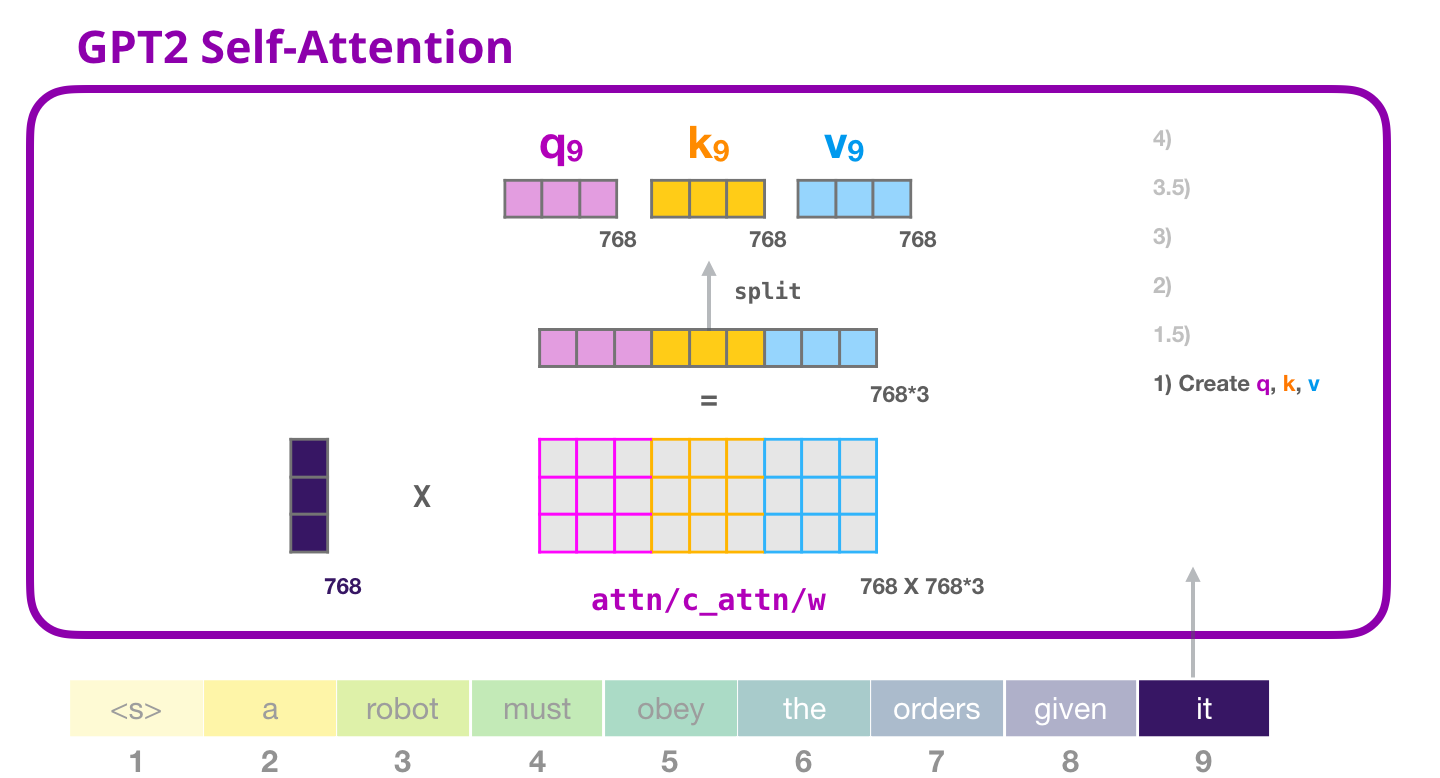
( ) ,
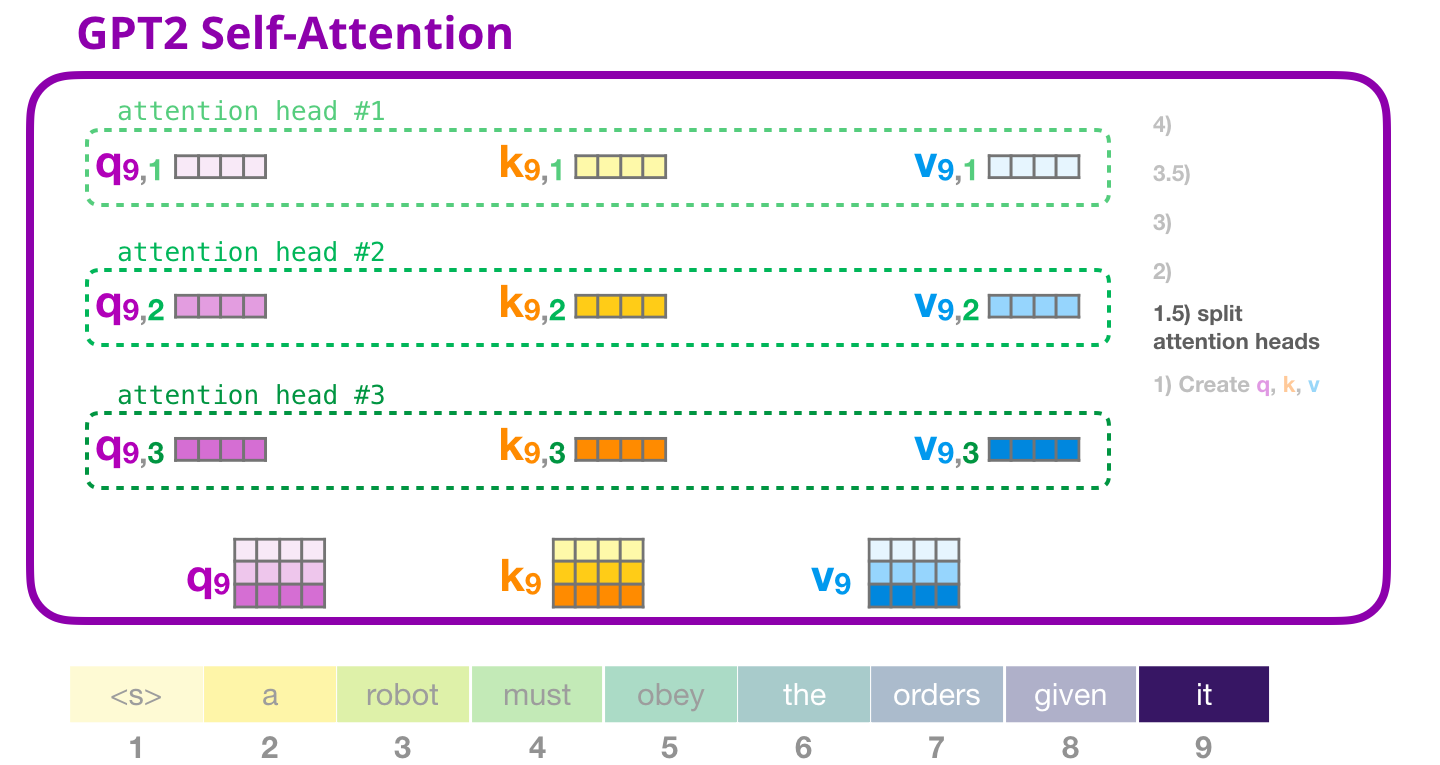
GPT-2: 1.5 – «»
, «» . . (Q), (K) (V). «» – . GPT-2 12 «» , :
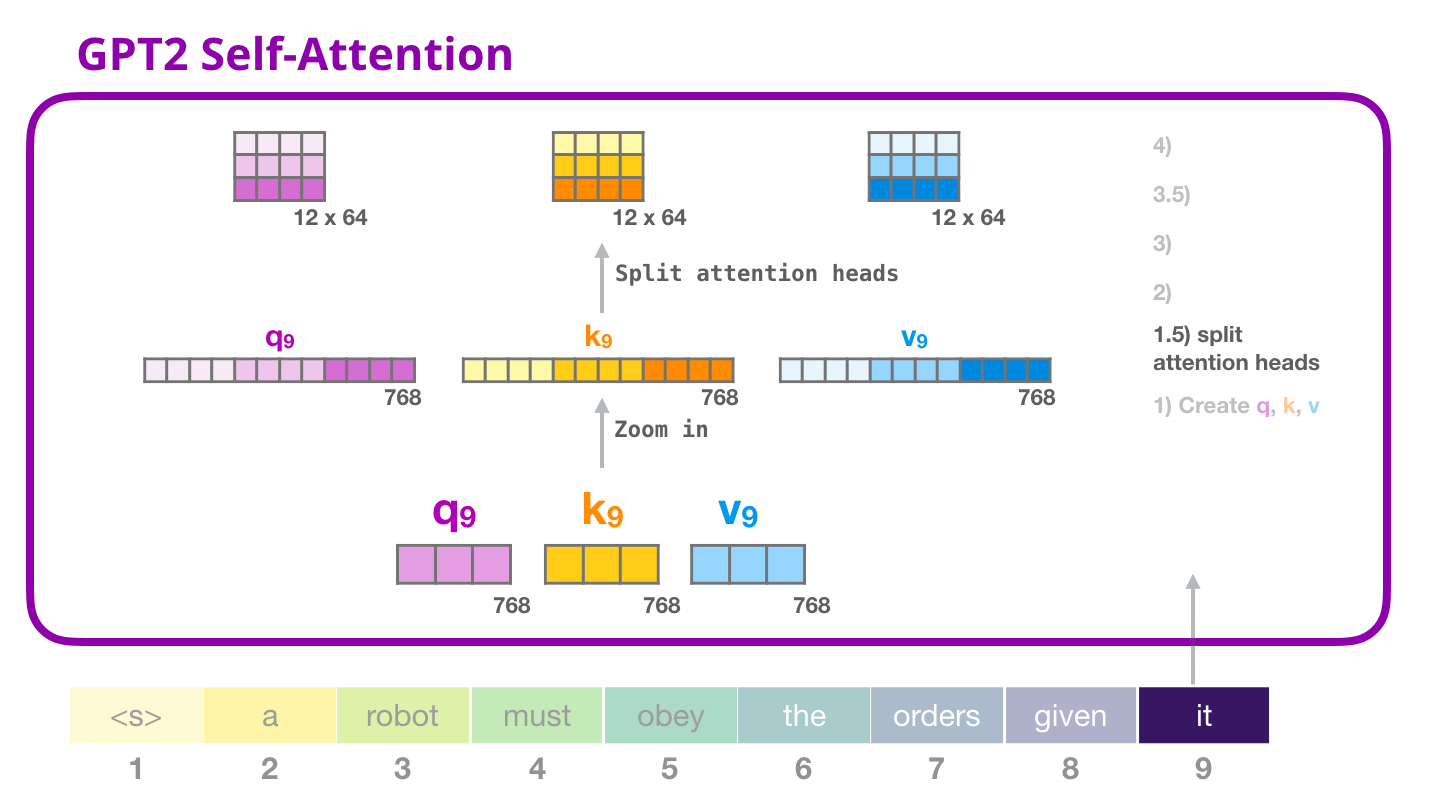
, «» . «» , ( 12 «» ):
GPT-2: 2 –
( , «» ):
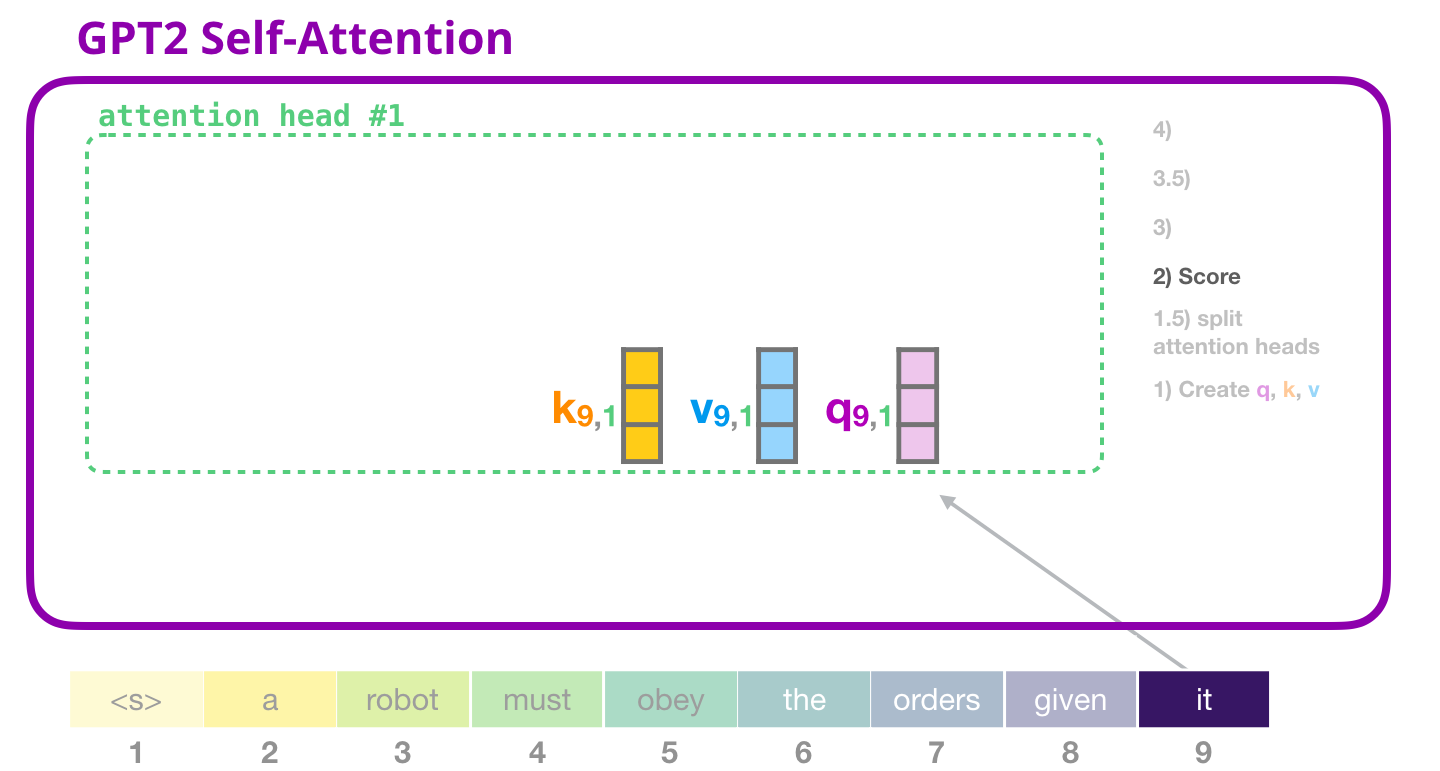
( «» #1 ):
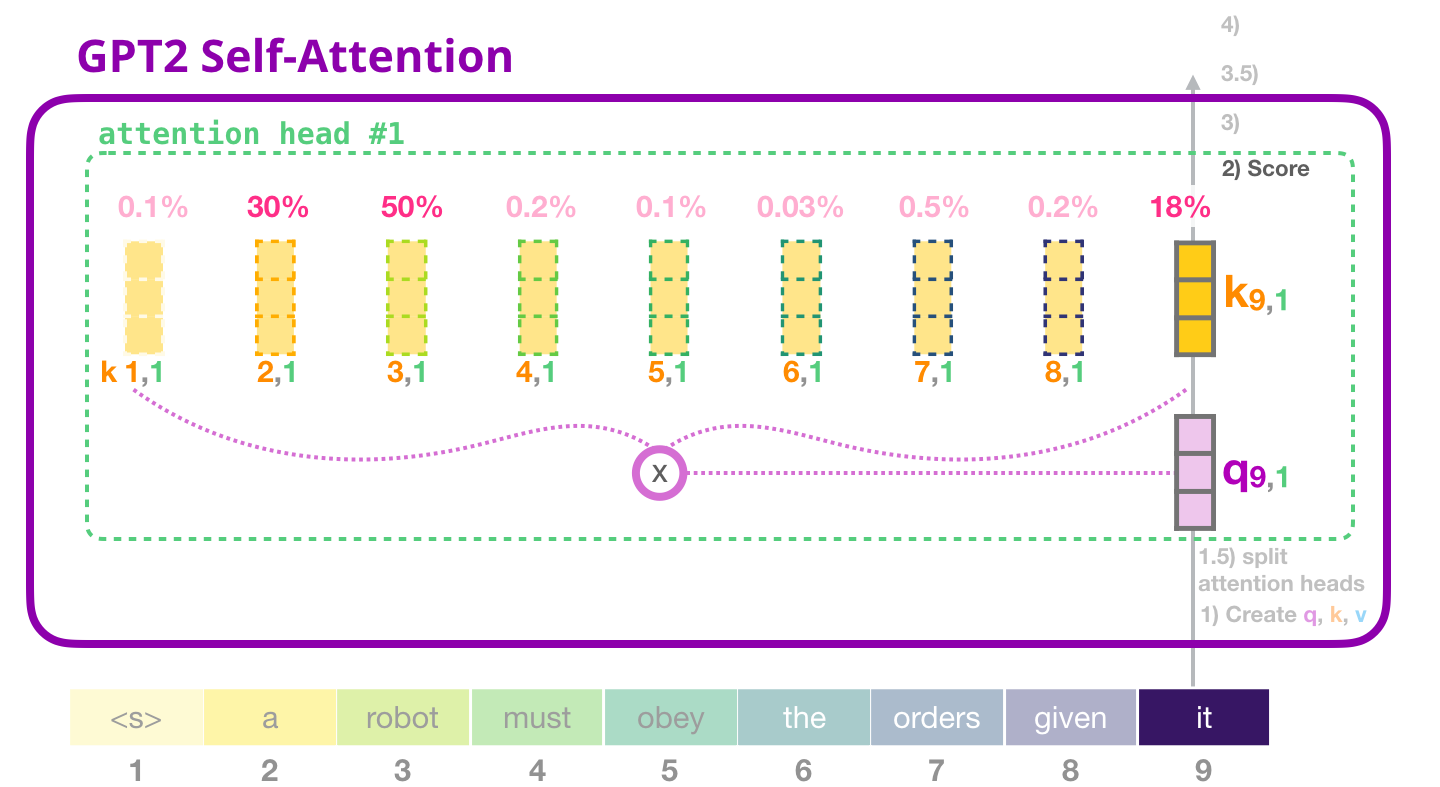
GPT-2: 3 –
, , , «» #1:

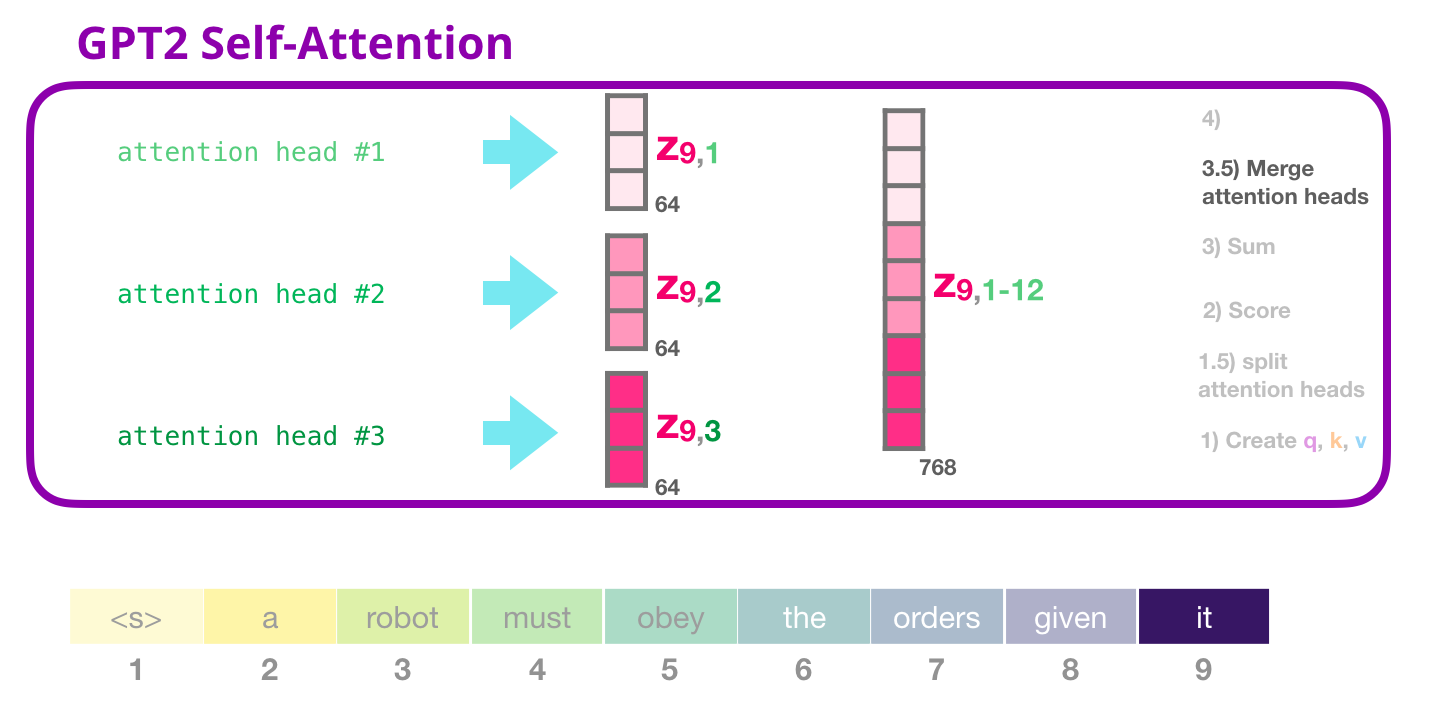
GPT-2: 3.5 – «»
«» , , :
. .
GPT-2: 4 –
, , . , «» :

, , :
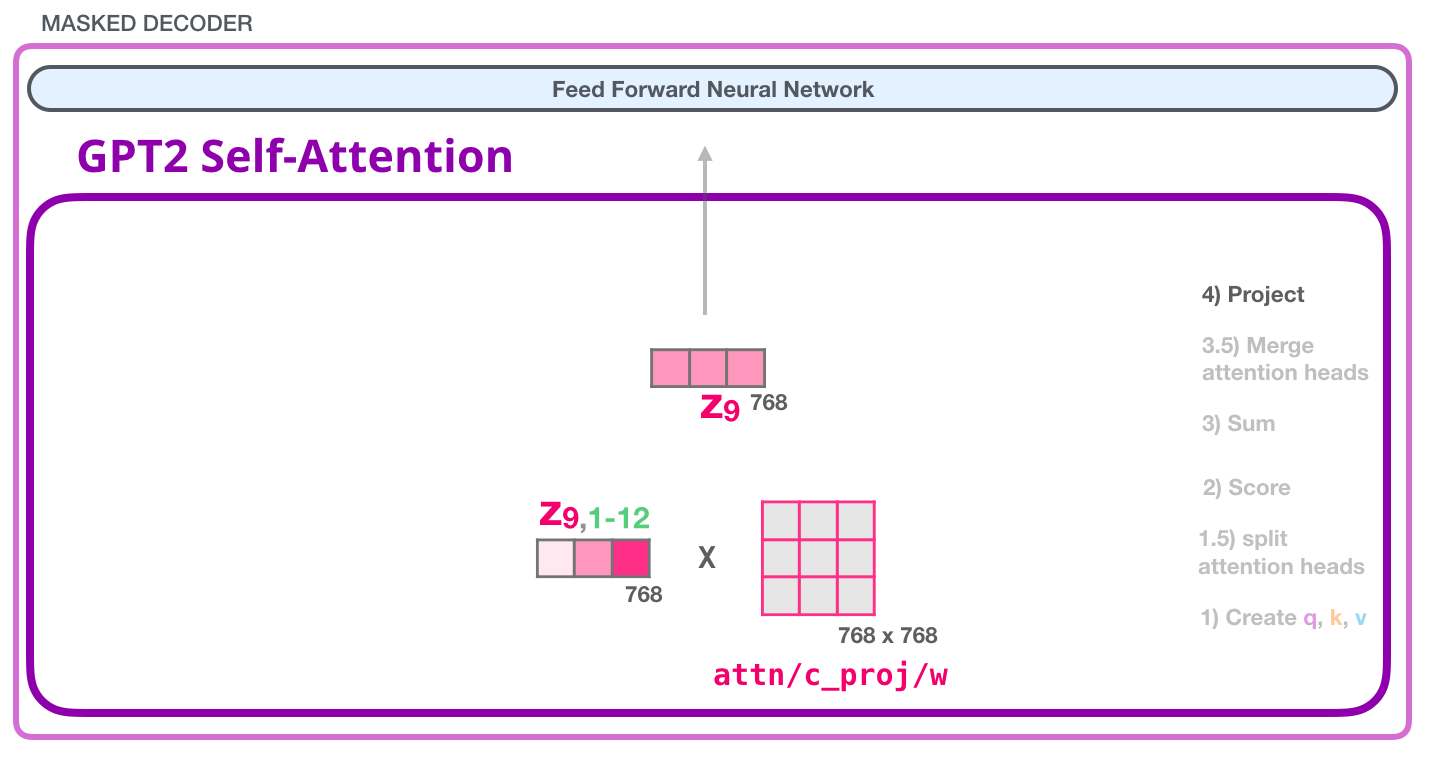
GPT-2: #1
– , , . . 4 ( GPT-2 768, 768*4 = 3072 ). ? ( 512 #1 – 2048). , , .
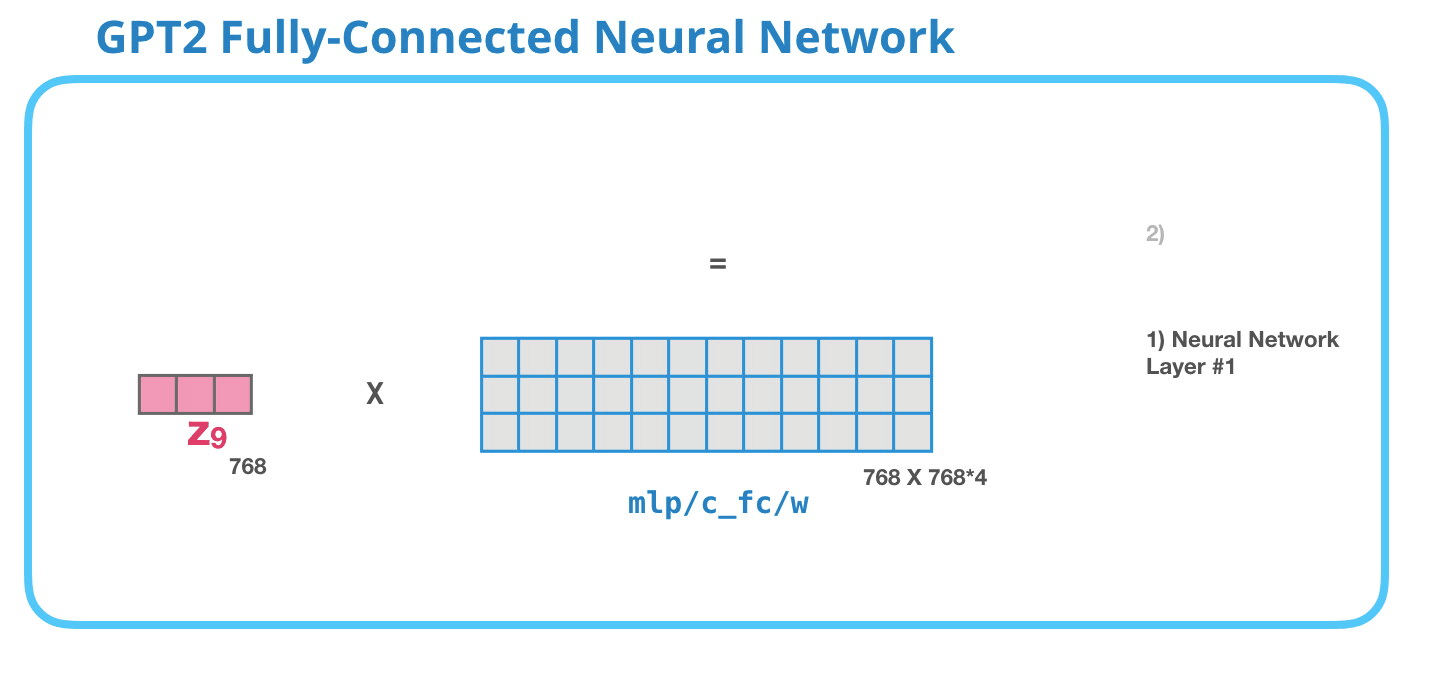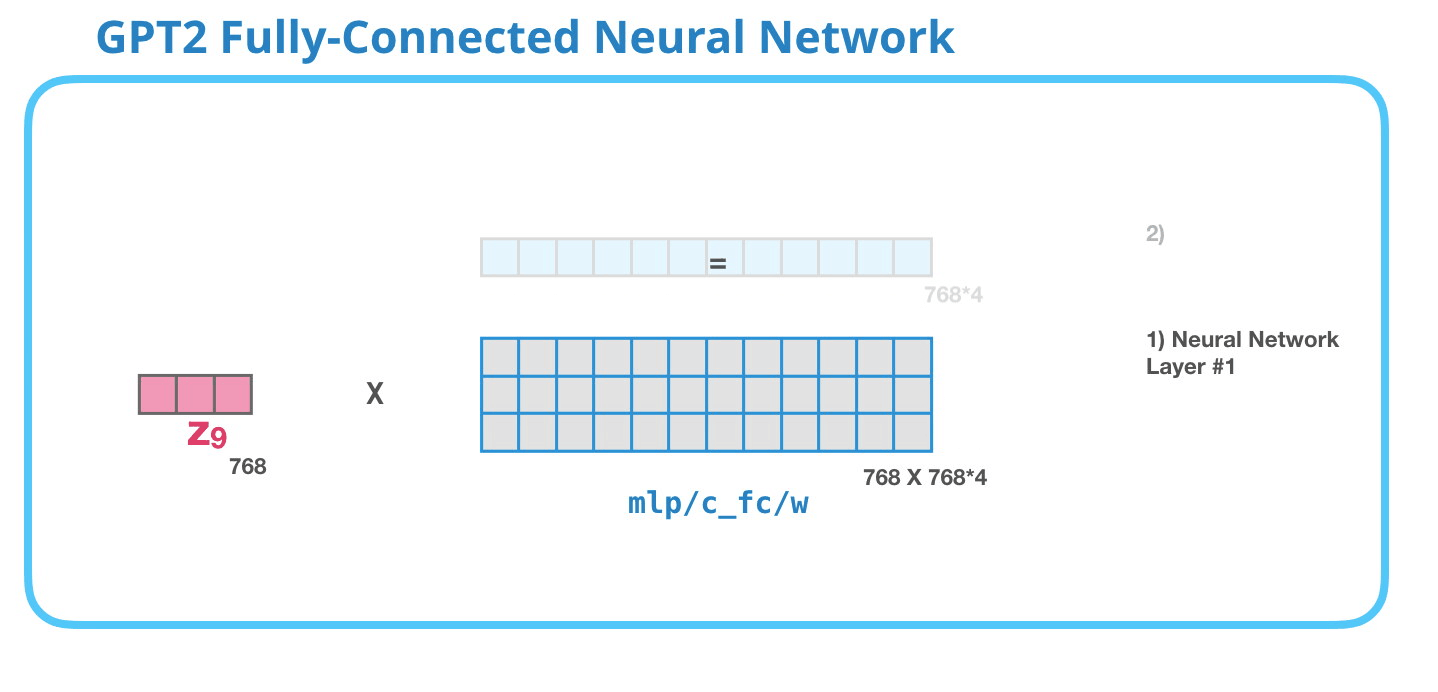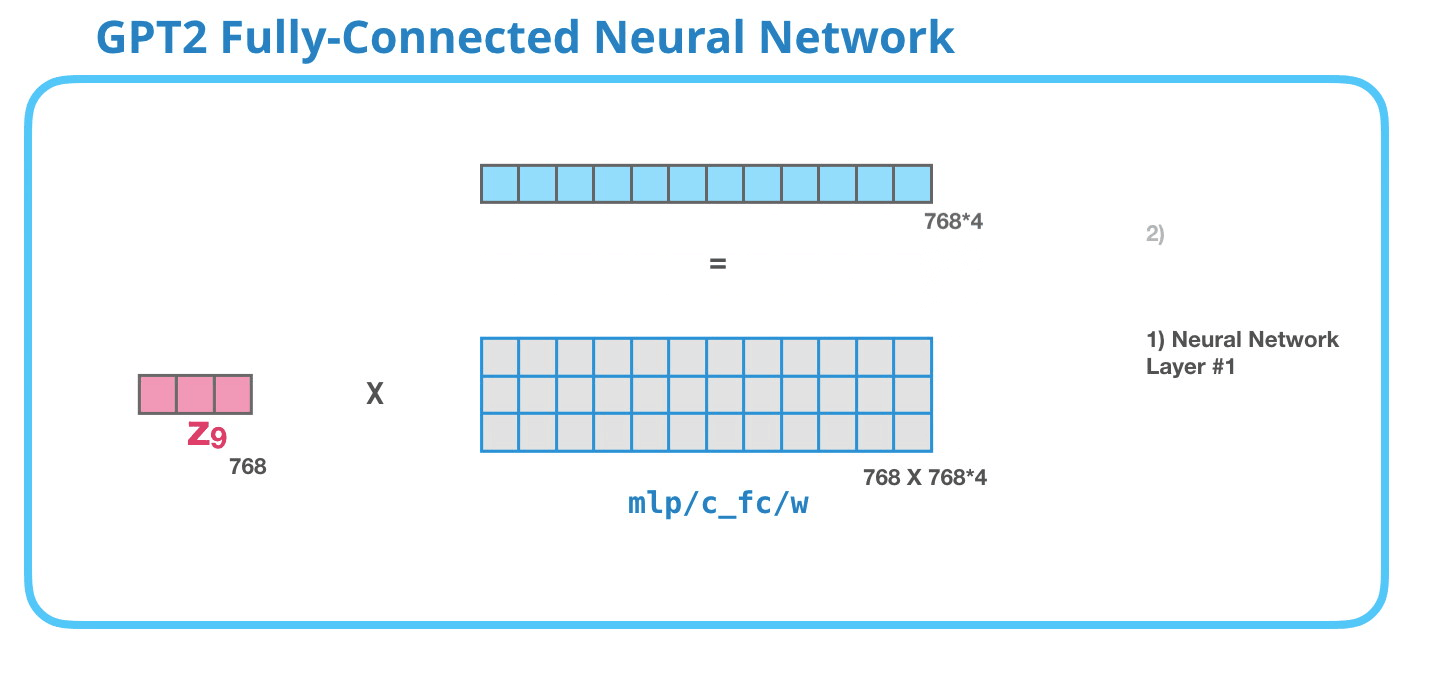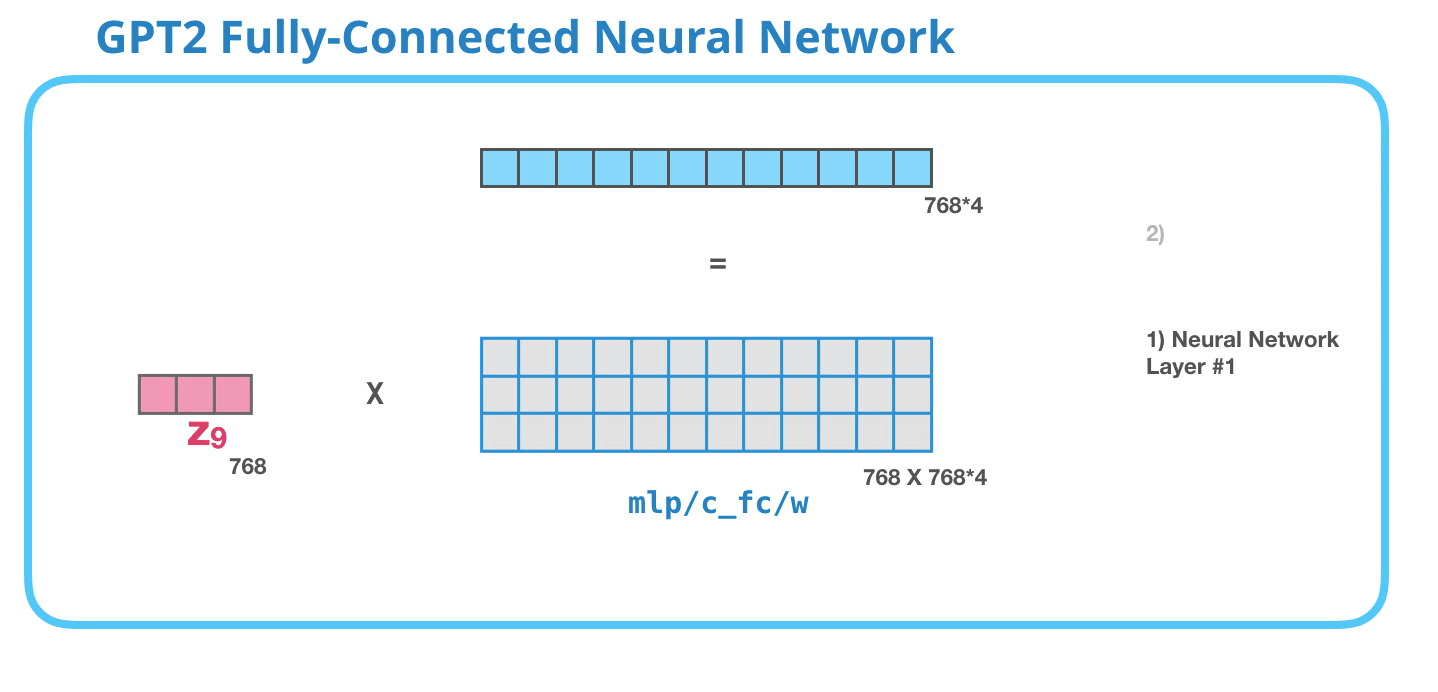
( )
GPT-2:
(768 GPT-2). .

( )
!
, - . , . , , :
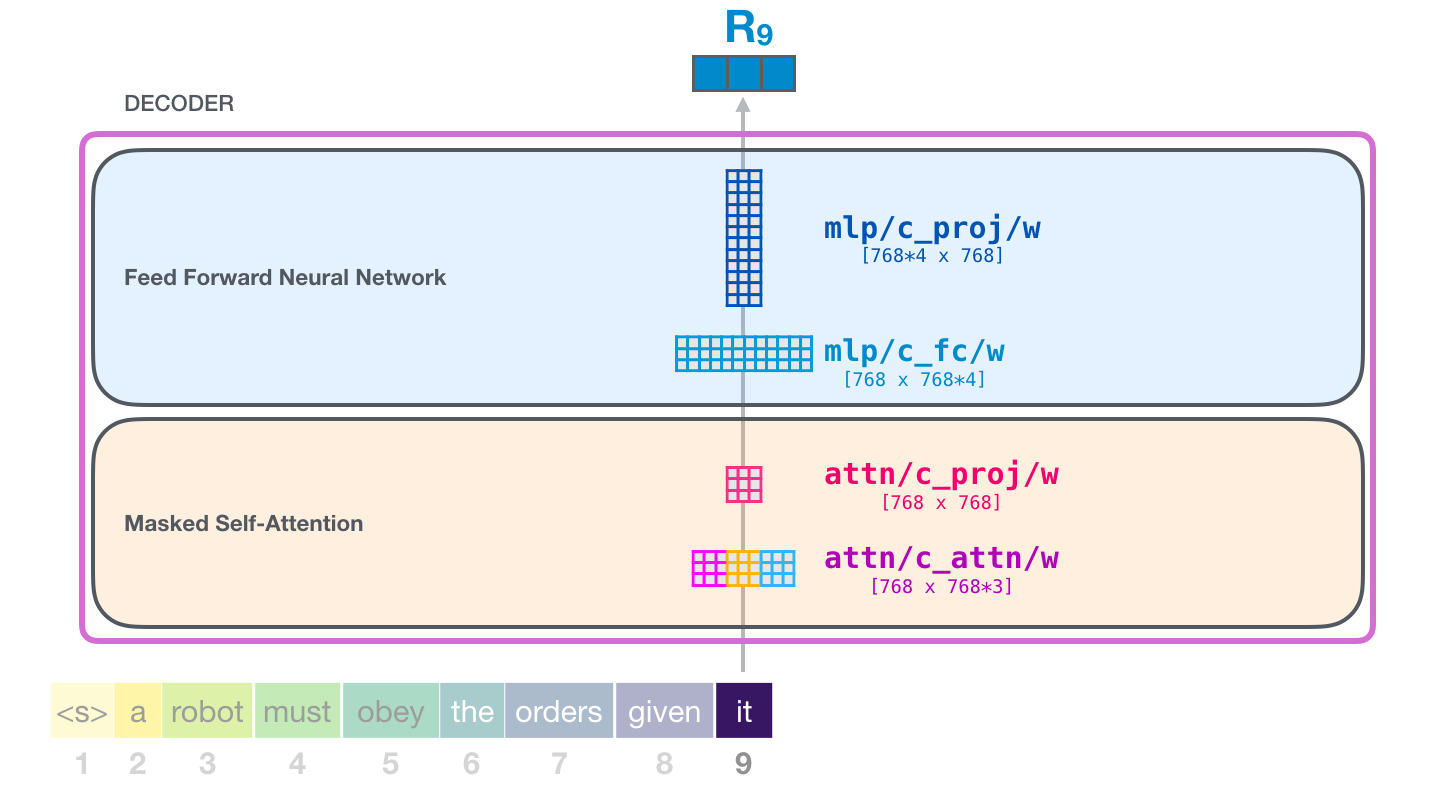
. , :
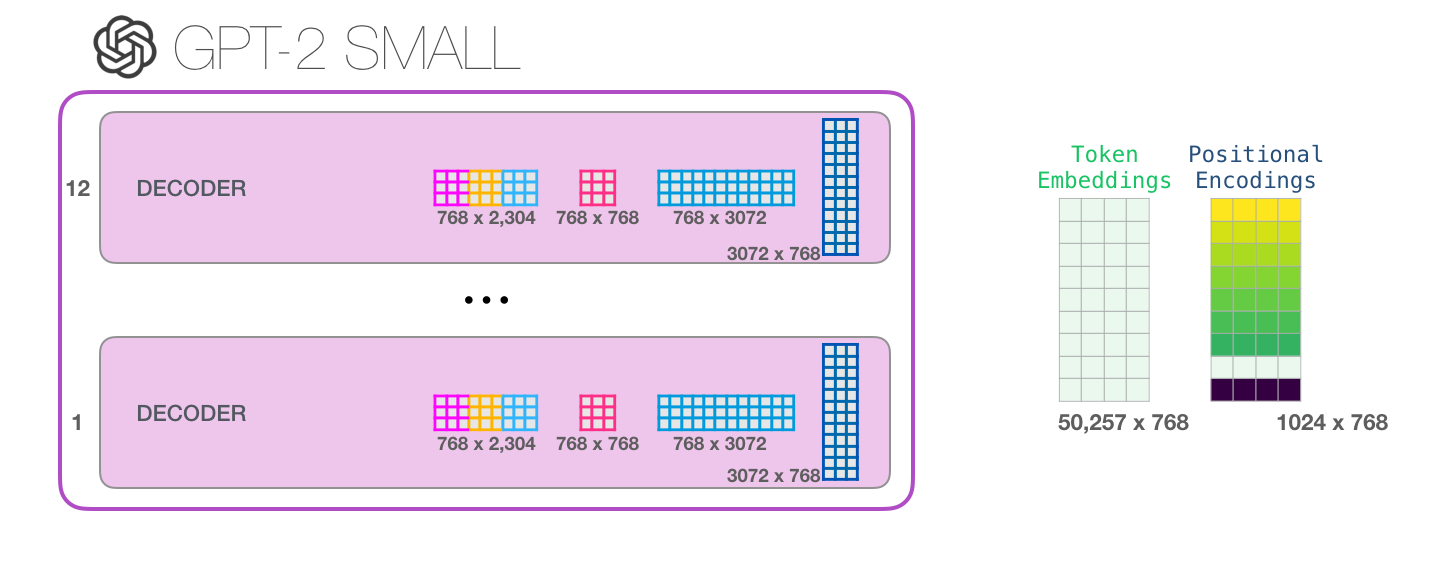
, :
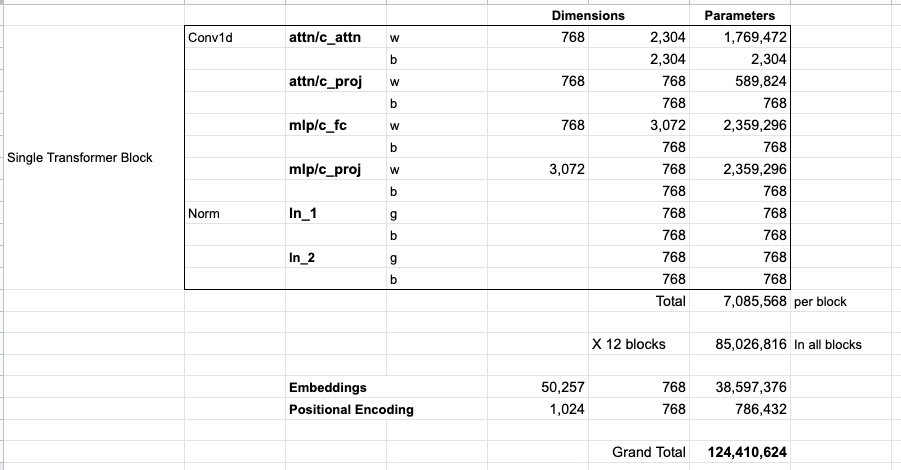
- 124 117. , , (, ).
3:
, . , . .
. :
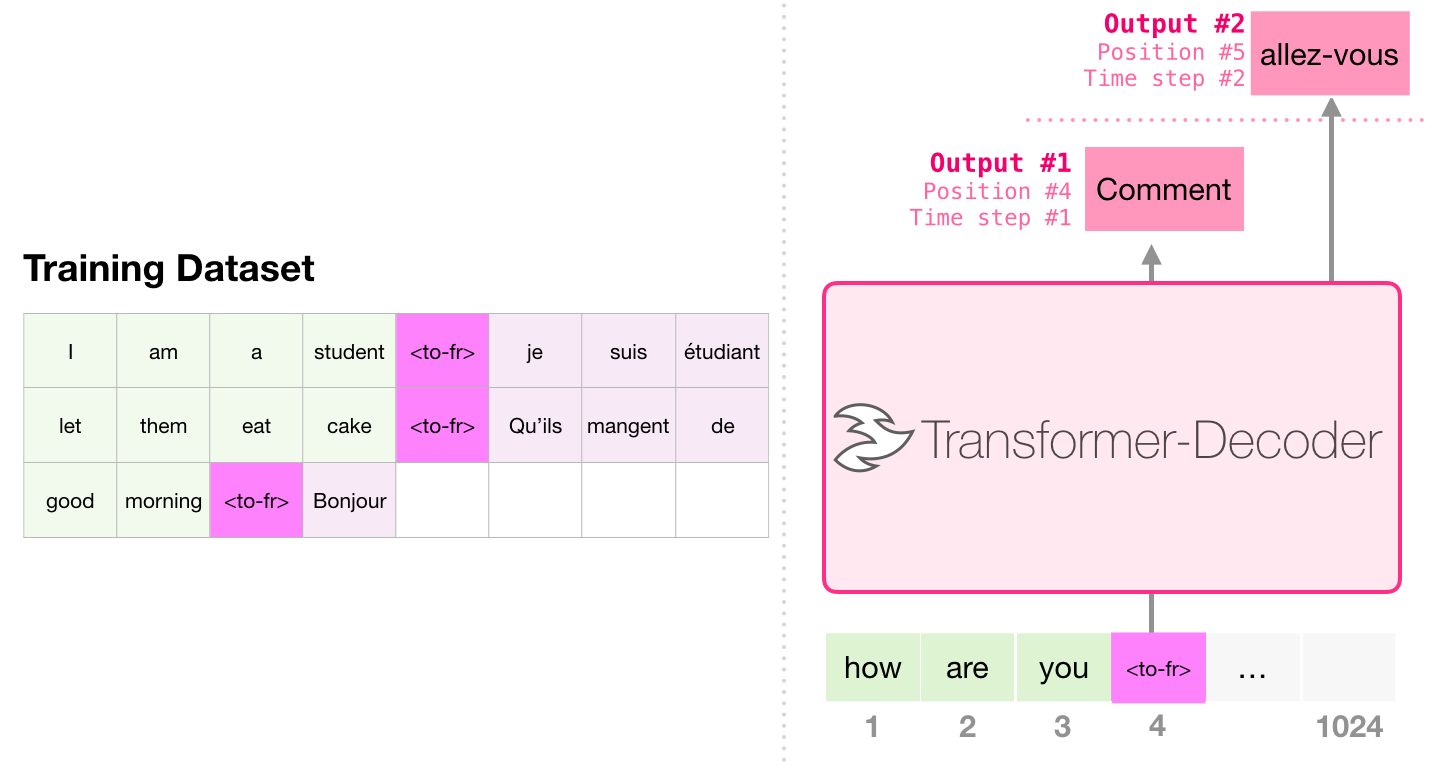
, . , ( , ) . :
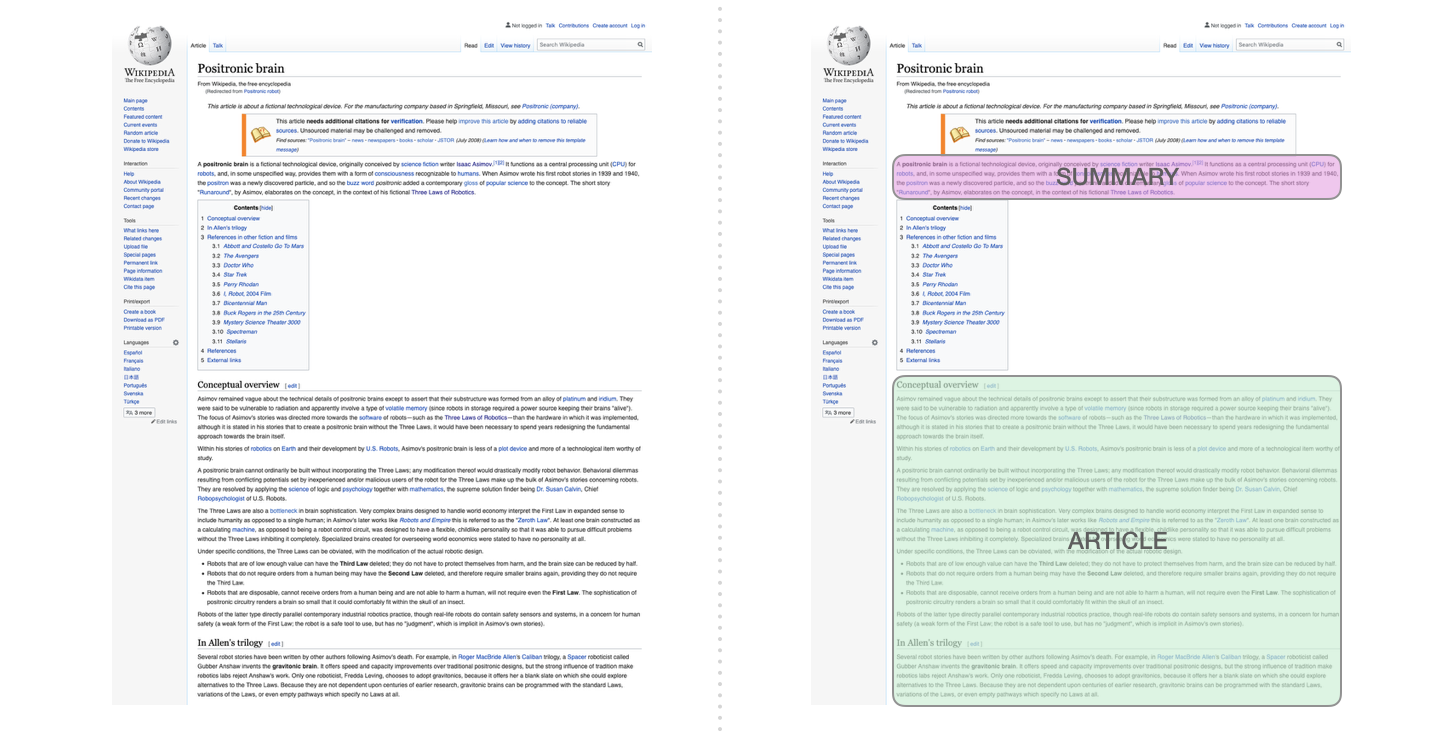
.
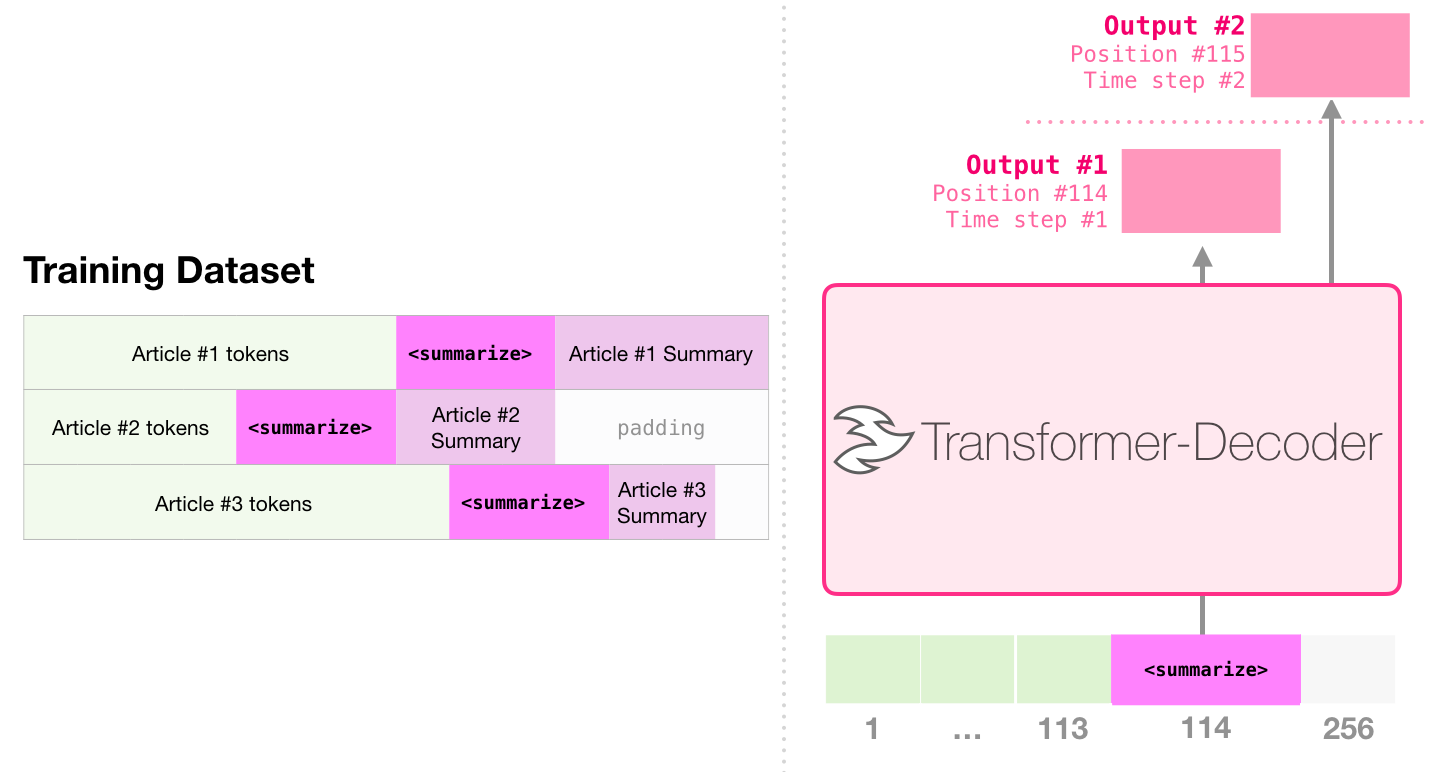
Sample Efficient Text Summarization Using a Single Pre-Trained Transformer , . , , - .
GPT-2 .
. « » – (, « »).
, . , (), ( ). (, , ) «» – , .
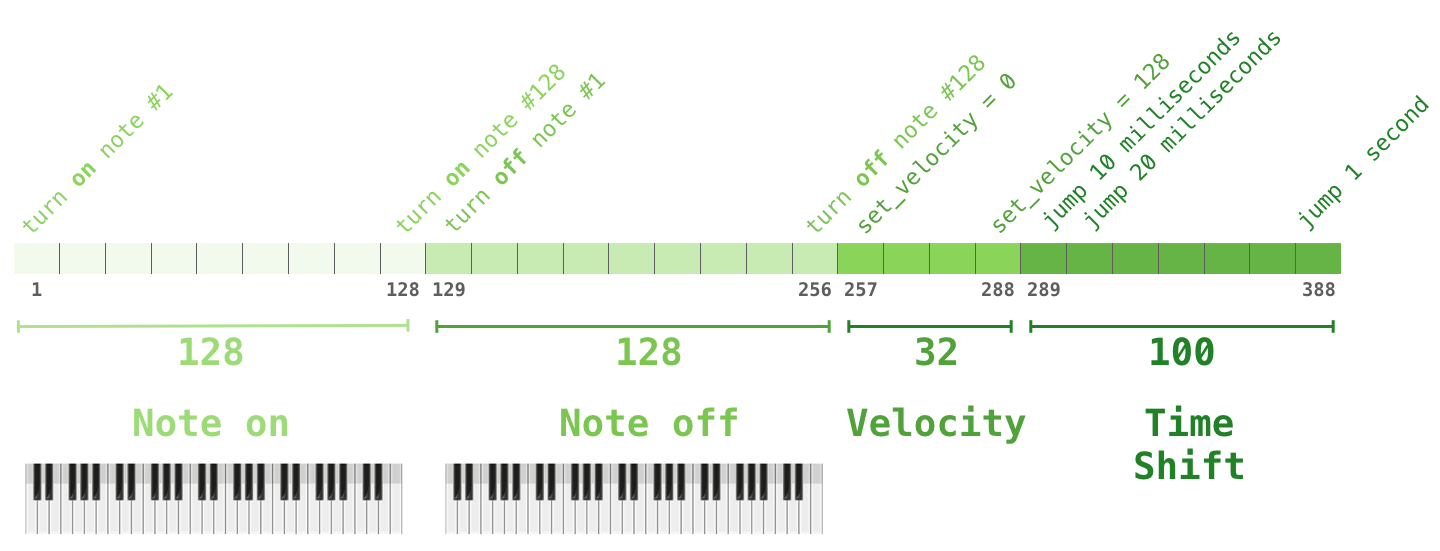
– one-hot . midi . :

one-hot :
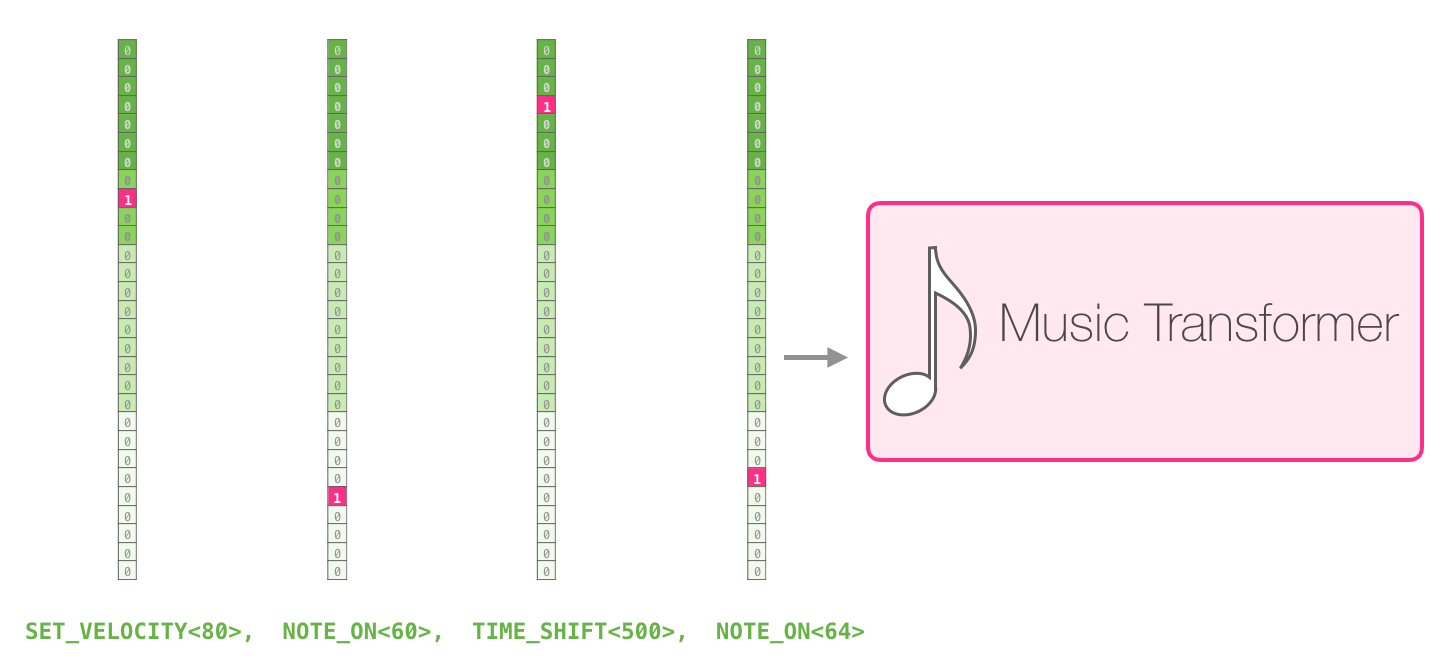
:
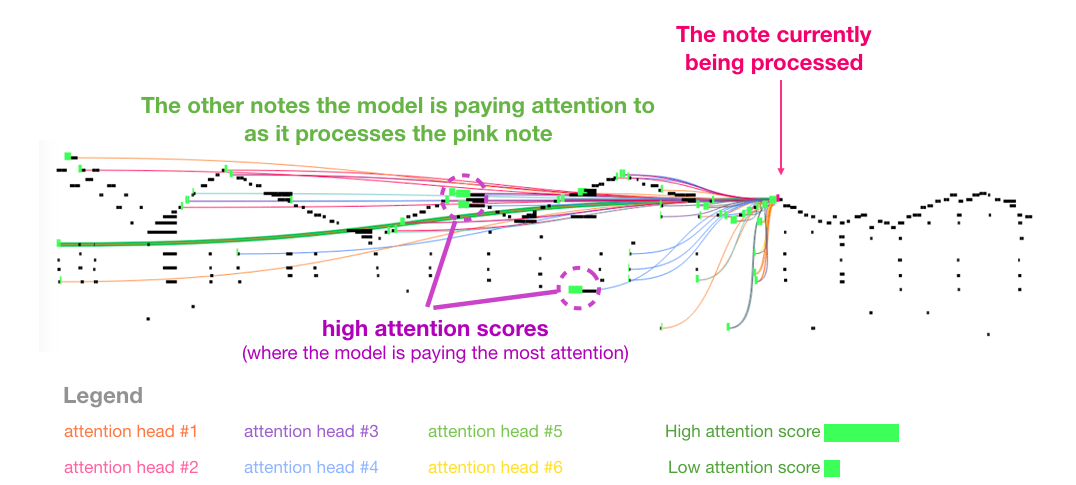
, . .
GPT-2 – . , , , , .
Autores