 Olá a todos!Envolvido em testes de desempenho. E eu realmente gosto de configurar o monitoramento e aproveitar as métricas no Grafana . E o padrão para armazenar métricas em ferramentas de carregamento é o InfluxDB . No InfluxDB, você pode salvar métricas de ferramentas populares como:Trabalhando com ferramentas de teste de desempenho e suas métricas, acumulei uma seleção de receitas de programação para o pacote do Grafana e do InfluxDB . Proponho considerar um problema interessante que surge quando existe uma métrica com duas ou mais tags. Eu acho que isso não é incomum. E, no caso geral, a tarefa é a seguinte: calcular a métrica total para um grupo, que é dividido em subgrupos .
Olá a todos!Envolvido em testes de desempenho. E eu realmente gosto de configurar o monitoramento e aproveitar as métricas no Grafana . E o padrão para armazenar métricas em ferramentas de carregamento é o InfluxDB . No InfluxDB, você pode salvar métricas de ferramentas populares como:Trabalhando com ferramentas de teste de desempenho e suas métricas, acumulei uma seleção de receitas de programação para o pacote do Grafana e do InfluxDB . Proponho considerar um problema interessante que surge quando existe uma métrica com duas ou mais tags. Eu acho que isso não é incomum. E, no caso geral, a tarefa é a seguinte: calcular a métrica total para um grupo, que é dividido em subgrupos .Existem três opções:
- Apenas o valor agrupado pela tag Tipo
- Grafana-way. Nós usamos uma pilha de valores
- Soma de elevações com subconsulta
Como tudo começou
Configurou o monitoramento JVM MBean usando Jolokia , Telegraf , InfluxDB e Grafana . E ele visualizou métricas em conjuntos de memórias - quanta memória é alocada por cada conjunto de memórias no HEAP e além.Gráficos em conjuntos de memórias JVM e atividade do coletor de lixo das 13:00 do dia anterior às 01:00 da noite do dia atual (período de 12 horas). Aqui você pode ver que os conjuntos de memórias são divididos em dois grupos: HEAP e NON_HEAP . E que cerca de 17:00 não havia coleta de lixo, depois do que o tamanho dos pools de memória diminuiu: Para métricas coletar em pools de memória, I especificado as seguintes configurações no Telegraf arquivo de configuração : telegraf.conf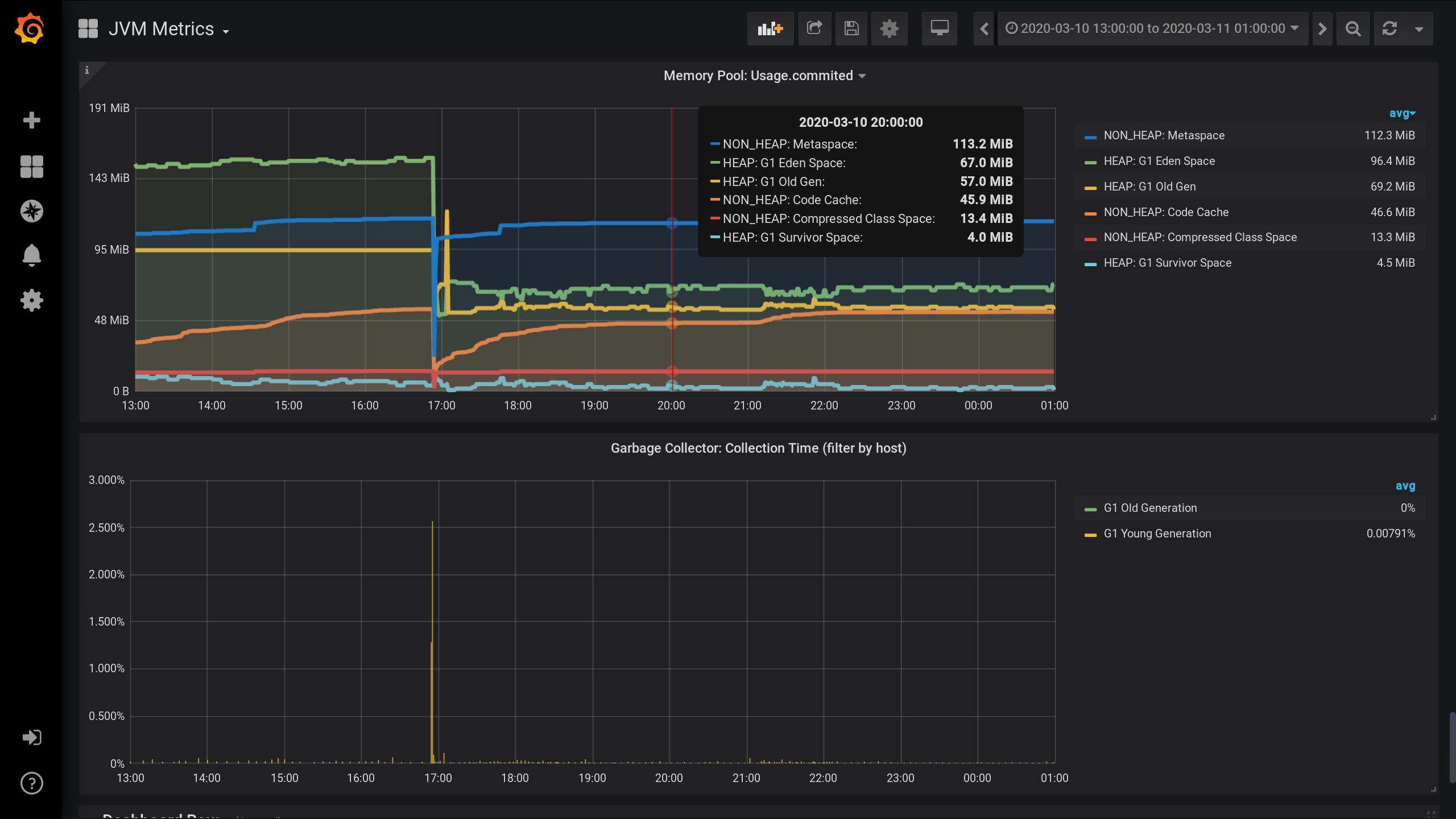
[outputs.influxdb]
urls = ["http://influxdb_server:8086"]
database = "telegraf"
username = "login-InfluxDb"
password = "*****"
retention_policy = "month"
influx_uint_support = false
[agent]
collection_jitter = "2s"
interval = "2s"
precision = "s"
[[inputs.jolokia2_agent]]
username = "login-Jolokia"
password = "*****"
urls = ["http://127.0.0.1:7777/jvm-service"]
[[inputs.jolokia2_agent.metric]]
paths = ["Usage","PeakUsage","CollectionUsage","Type"]
name = "java_memory_pool"
mbean = "java.lang:name=*,type=MemoryPool"
tag_keys = ["name"]
[[processors.converter]]
[processors.converter.fields]
integer = ["CollectionUsage.*", "PeakUsage.*", "Usage.*"]
tag = ["Type"]
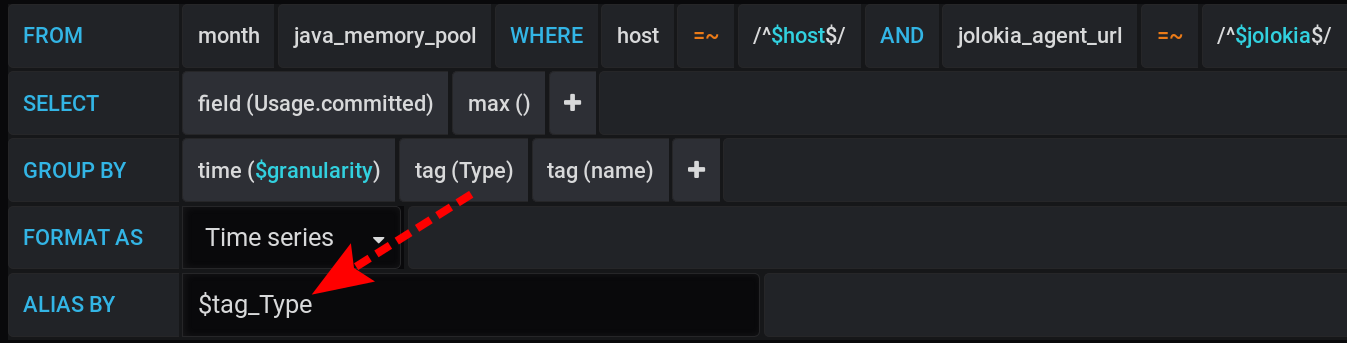
E no Grafana, construí uma consulta ao InfluxDB para exibir nos gráficos o valor métrico máximo Usage.Committedpor um período de tempo com uma etapa $granularity(1m) e agrupada por duas tags Type(HEAP ou NON_HEAP) e name(Metaspace, G1 Old Gen, ...): A mesma consulta em forma de texto, levando em consideração todas as variáveis do Grafana (preste atenção ao escape de valores de variáveis com - isso é importante para a consulta funcionar corretamente):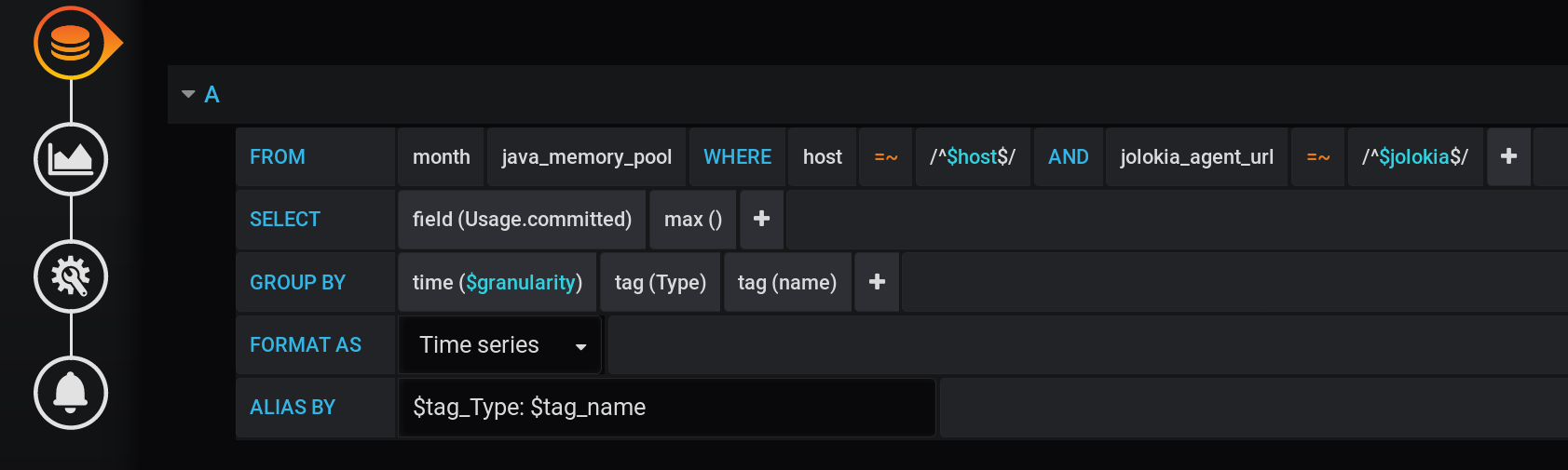
:regexSELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type", "name", time($granularity)
A mesma consulta em forma de texto, levando em consideração os valores específicos das variáveis Grafana :SELECT max("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^serverName$/ AND
jolokia_agent_url =~ /^http:\/\/127\.0\.0\.1:7777\/jvm-service$/ AND
time >= 1583834400000ms and time <= 1583877600000ms
GROUP BY
"Type", "name", time(1m)
Agrupar por tempo GROUP BY time($granularity)ou é GROUP BY time(1m)usado para reduzir o número de pontos no gráfico. Por um período de 12 horas e uma etapa de agrupamento de 1 minuto, obtemos: 12 x 60 = 720 vezes ou 721 pontos (o último ponto com valor nulo).Lembre-se de que 721 é o número esperado de pontos em resposta a solicitações ao InfluxDB nas configurações atuais para o intervalo de tempo (12 horas) e a etapa de agrupamento (1 minuto).
Conjunto de
memórias NON_HEAP: Metaspace (azul) lidera o consumo de memória às 20:00. E de acordo com o HEAP: G1 Old Gen (amarelo), houve um pequeno aumento local às 17:03. E, no horário das 20:00, no total, todos os pools NON_HEAP deixaram 172,5 MiB (113,2 + 45,9 + 13,4) e os pools HEAP 128 MiB (67 + 57 + 4).
Lembre-se os valores para 20:00: NON_HEAP piscinas 172,5 MiB e HEAP piscinas 128 MiB . Vamos nos concentrar nesses valores no futuro.
No contexto de Type : name , obtivemos o valor da métrica facilmente.No contexto apenas da tag name , também é fácil obter o valor da métrica, pois todos os nomes dos conjuntos de memórias são exclusivos e basta deixar o agrupamento dos resultados apenas por nome .A questão permanece: como obter qual tamanho é alocado para todos os conjuntos HEAP e todos os conjuntos NON_HEAP no total?
1. Apenas o valor agrupado pela tag Type
1.1 Soma agrupada por tag
A primeira solução que pode surgir é agrupar os valores pela tag Type e calcular a soma dos valores em cada grupo. Essa consulta terá a seguinte aparência: Uma representação textual de uma solicitação de cálculo de soma agrupada pela tag Type com todas as variáveis Grafana :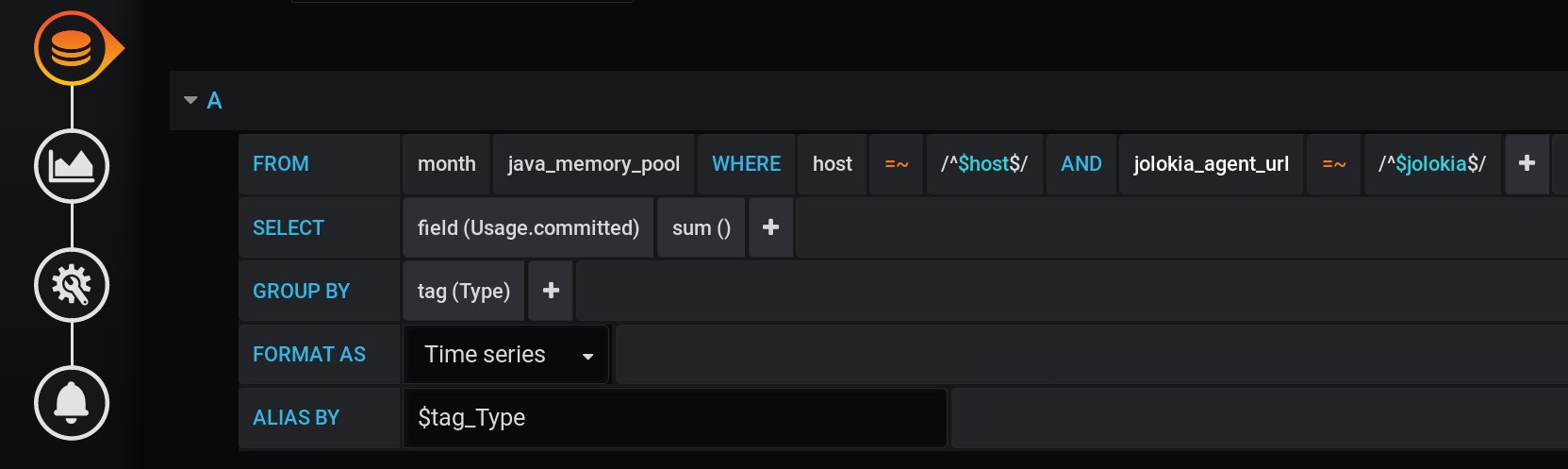
SELECT sum("Usage.committed")
FROM "telegraf"."month"."java_memory_pool"
WHERE
host =~ /^${host:regex}$/ AND
jolokia_agent_url =~ /^${jolokia:regex}$/ AND
$timeFilter
GROUP BY
"Type"
Esta é uma consulta válida, mas retornará apenas dois pontos: a soma será calculada com o agrupamento apenas pela tag Type com dois valores (HEAP e NON_HEAP). Nem veremos a programação. Haverá dois pontos autônomos com uma soma enorme em valores (mais de 3 TiB): Essa soma não é adequada, é necessária uma divisão em intervalos de tempo.
1.2 Quantidade agrupada por tag por minuto
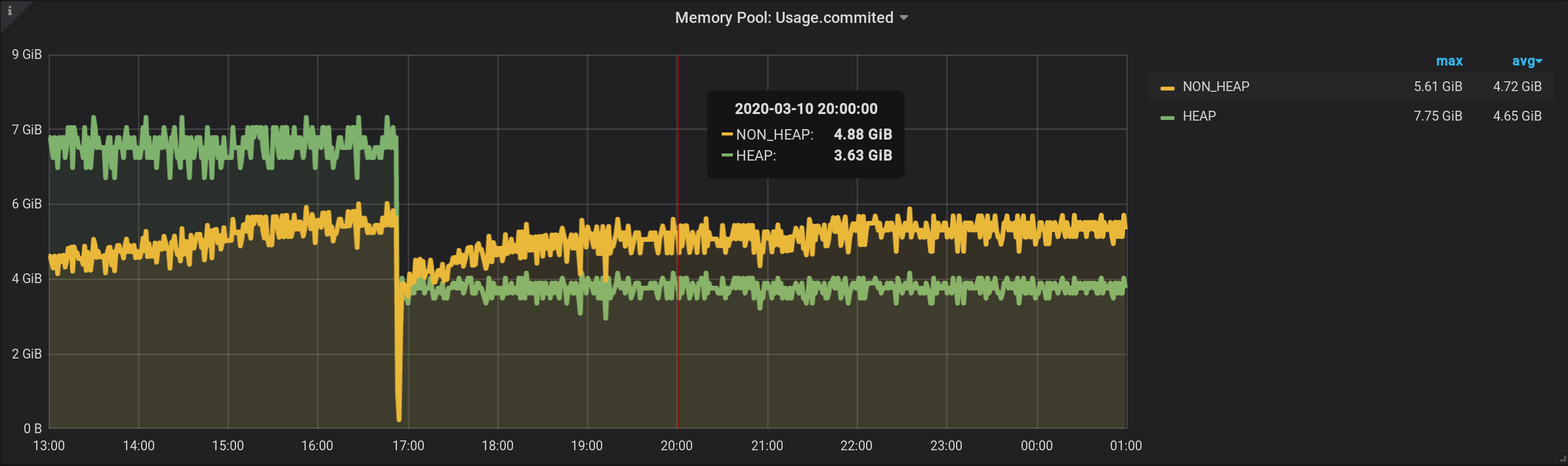
Na consulta original, agrupamos as métricas por um intervalo personalizado de $ granularidade . Vamos fazer o agrupamento agora por um intervalo personalizado.Essa consulta resultará, acrescentou GROUP BY time($granularity): obtemos valores inflados, em vez de 172,5 MiB por NON_HEAP , vemos 4,88 GiB: Como as métricas são enviadas ao InfluxDB a cada 2 segundos (veja telegraf.conf acima), a soma das leituras em um minuto não fornecerá o valor no momento, e a soma de trinta desses valores. Também não podemos dividir o resultado por 30 constantes . Como $ granularity é um parâmetro, ele pode ser definido para 1 e 10 minutos. E o valor da quantia mudará.
1.3 Etiqueta agrupada por segundo
Para obter corretamente o valor da métrica da intensidade atual da coleção de métricas (2 segundos), é necessário calcular a quantidade para um intervalo fixo que não exceda a intensidade da coleção de métricas.Vamos tentar exibir estatísticas com um agrupamento em segundos. Adicione ao GROUP BYagrupamento time(1s): com uma granularidade tão pequena, obtemos um grande número de pontos por nosso intervalo de 12 horas (12 horas * 60 minutos * 60 segundos = 43.200 intervalos, 43.201 pontos por linha, o último dos quais é nulo): 43.201 pontos em cada linha do gráfico. Há tantos pontos que o InfluxDB forma uma resposta por um longo tempo, o Grafana leva uma resposta por mais tempo e, em seguida, o navegador atrai um número tão grande de pontos por um longo tempo.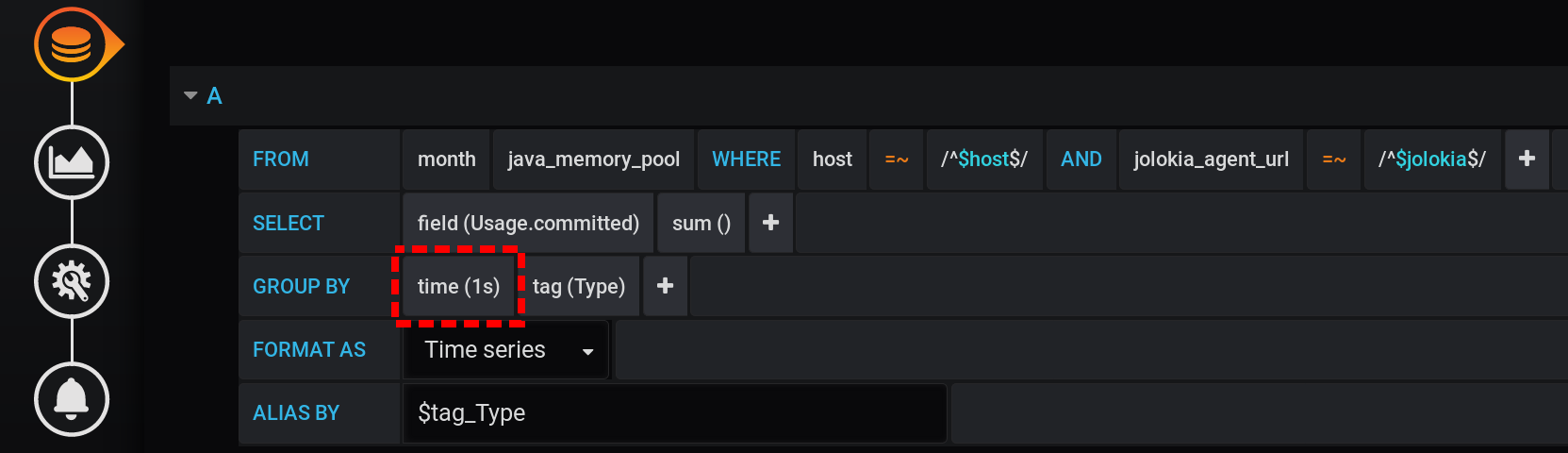
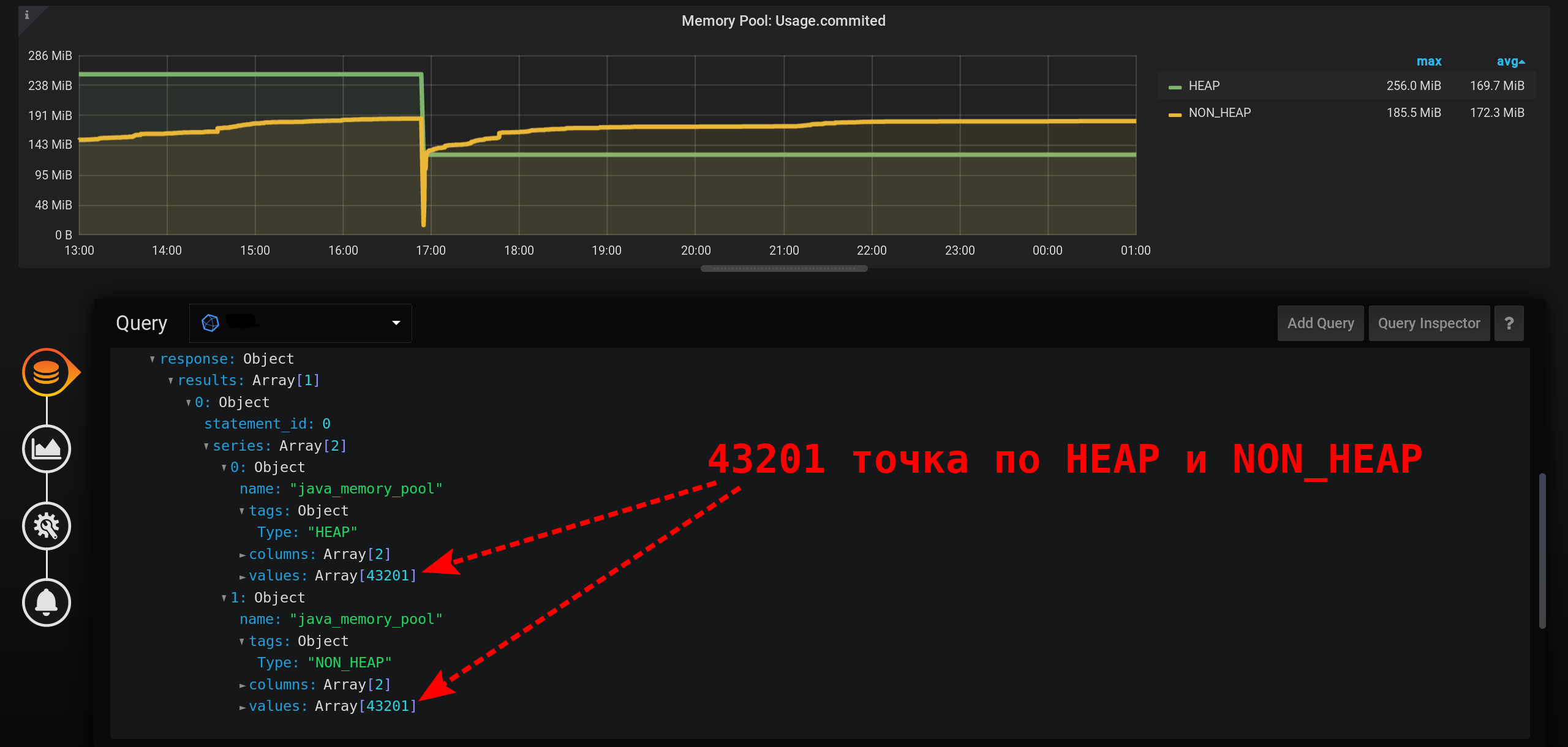 E a cada segundo não há pontos: as métricas foram coletadas a cada 2 segundos e agrupadas a cada segundo, o que significa que cada segundo ponto será nulo. Para ver uma linha suave, configure a conexão de valores não vazios. Caso contrário, não veremos os gráficos: Anteriormente, o Grafana era tal que o navegador travava durante o desenho de um grande número de pontos. Agora a versão do Grafana tem a capacidade de desenhar várias dezenas de milhares de pontos: o navegador simplesmente pula alguns deles, desenha um gráfico usando os dados simplificados. Mas o gráfico é suavizado. Os altos são exibidos como altos médios.
E a cada segundo não há pontos: as métricas foram coletadas a cada 2 segundos e agrupadas a cada segundo, o que significa que cada segundo ponto será nulo. Para ver uma linha suave, configure a conexão de valores não vazios. Caso contrário, não veremos os gráficos: Anteriormente, o Grafana era tal que o navegador travava durante o desenho de um grande número de pontos. Agora a versão do Grafana tem a capacidade de desenhar várias dezenas de milhares de pontos: o navegador simplesmente pula alguns deles, desenha um gráfico usando os dados simplificados. Mas o gráfico é suavizado. Os altos são exibidos como altos médios.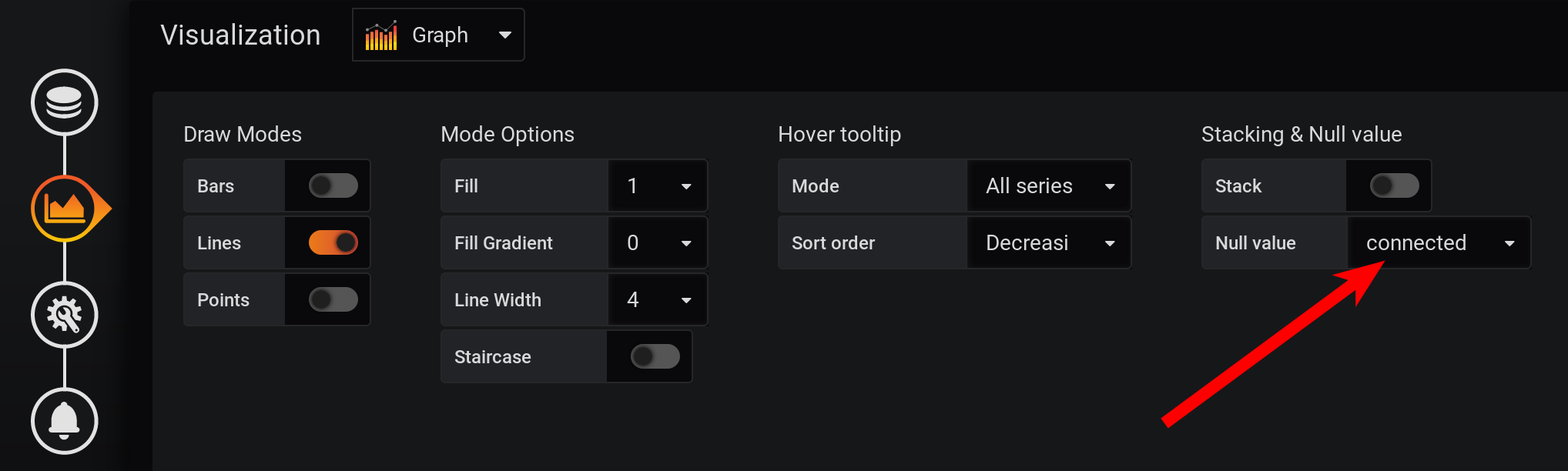 Como resultado, há um gráfico, é exibido com precisão, as métricas às 20:00 são calculadas corretamente, as métricas na legenda do gráfico são calculadas corretamente. Mas o gráfico é suavizado: as rajadas não são visíveis com precisão de 1 segundo. Em particular, o aumento do HEAP às 17:03 desapareceu do gráfico, o gráfico HEAP é muito suave: o desempenho negativo se manifestará claramente por um intervalo de tempo mais longo. Se você tentar criar um gráfico em um mês (720 horas) e não em 12 horas, tudo congelará com uma granularidade tão pequena (1 segundo), haverá muitos pontos. E há um sinal de menos na ausência de picos, um paradoxo - devido à alta precisão de obter métricas, obtemos uma baixa precisão de sua exibição .
Como resultado, há um gráfico, é exibido com precisão, as métricas às 20:00 são calculadas corretamente, as métricas na legenda do gráfico são calculadas corretamente. Mas o gráfico é suavizado: as rajadas não são visíveis com precisão de 1 segundo. Em particular, o aumento do HEAP às 17:03 desapareceu do gráfico, o gráfico HEAP é muito suave: o desempenho negativo se manifestará claramente por um intervalo de tempo mais longo. Se você tentar criar um gráfico em um mês (720 horas) e não em 12 horas, tudo congelará com uma granularidade tão pequena (1 segundo), haverá muitos pontos. E há um sinal de menos na ausência de picos, um paradoxo - devido à alta precisão de obter métricas, obtemos uma baixa precisão de sua exibição .
2. Grafana-way. Nós usamos uma pilha de valores
Não foi possível criar uma
solução simples e produtiva com o InfluxDB e o designer de consultas Grafana . Apenas tentaremos usar as ferramentas Grafana para resumir as métricas exibidas no gráfico original. E sim, isso é possível!2.1 Basta fazer a dica de ferramenta Passe o mouse / Valor empilhado: cumulativo
Deixaremos a solicitação de escolha de métricas inalterada, da mesma forma que na seção "Como tudo começou": as métricas serão agrupadas por Tipo e nome . Mas apenas exibiremos a tag Type nos nomes dos gráficos : e nas configurações de visualização, agruparemos as métricas por pilhas Grafana : primeiro, adicione a separação de duas tags em duas pilhas diferentes A e B, para que seus valores não se cruzem: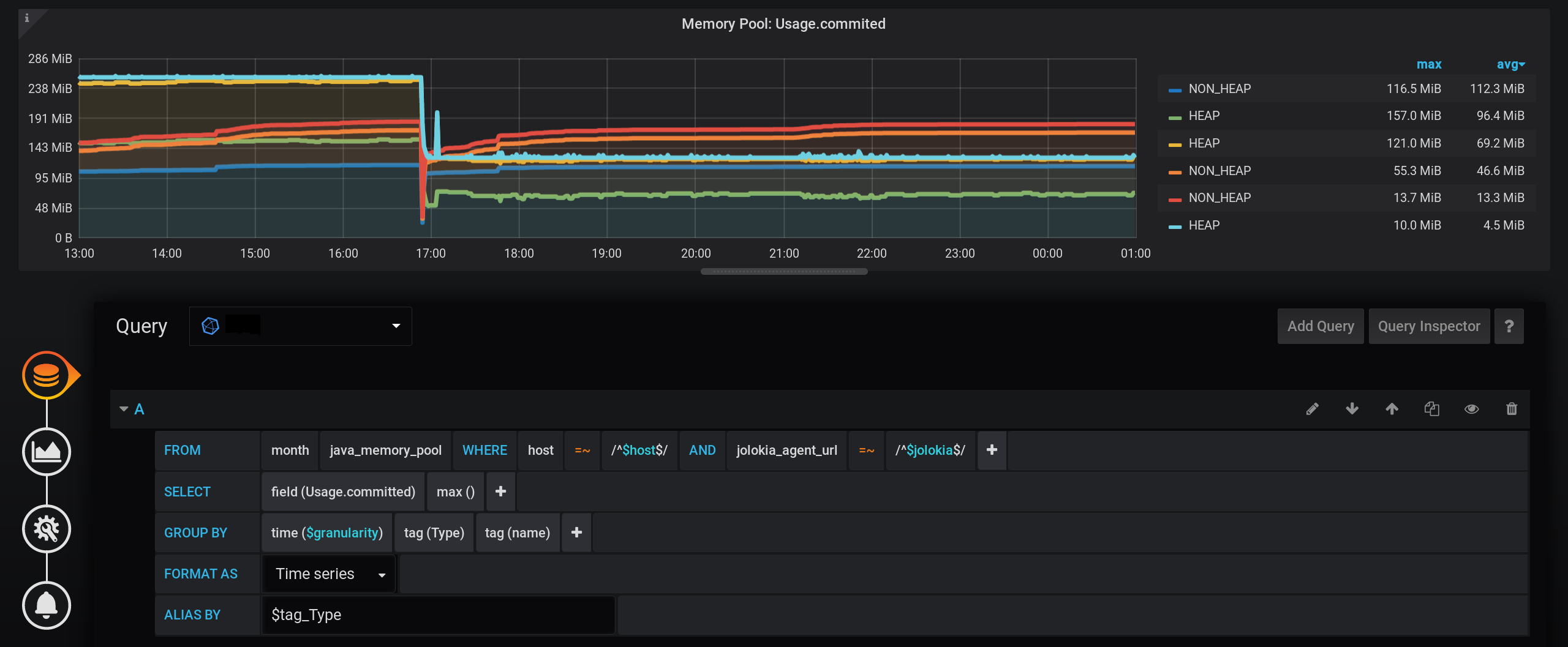
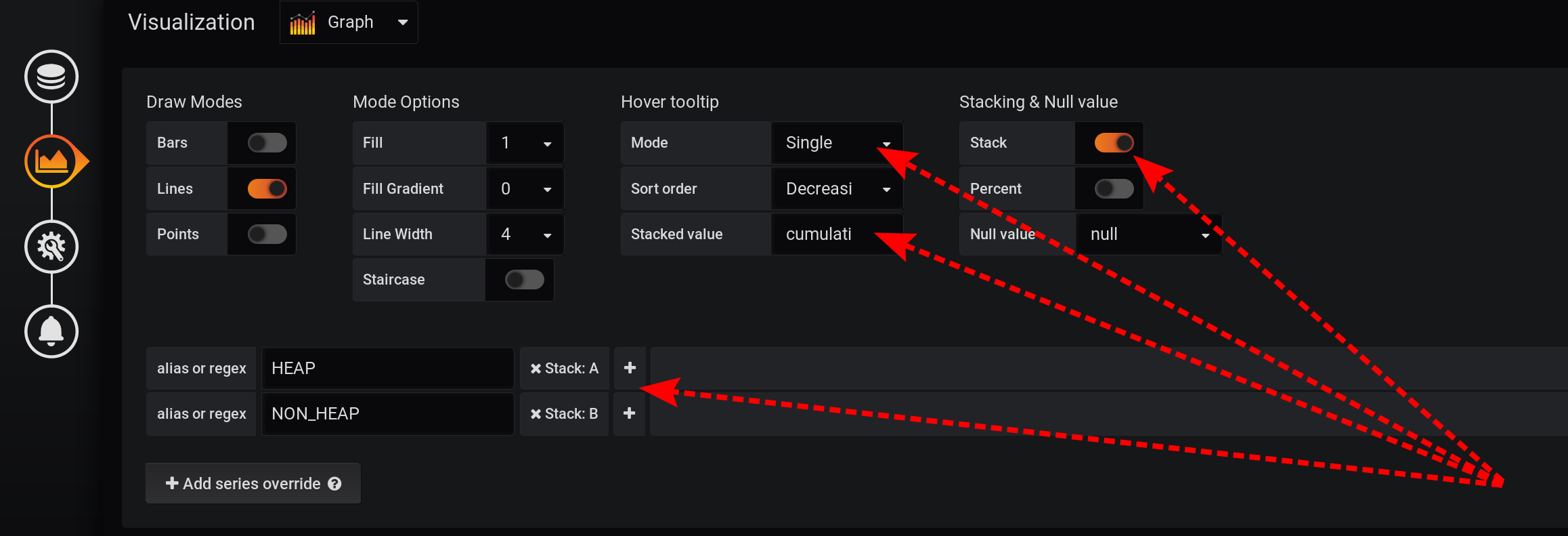
- Adicionar substituição de série / HEAP / Pilha : A
- Adicionar substituição de série / NON_HEAP / Pilha : B
Em seguida, configure a visualização de métricas para exibir os valores totais em uma dica de ferramenta com gráficos:- Empilhamento e valor nulo / Empilhamento : Ativado
- Dica da ferramenta Passe o mouse / valor empilhado : cumulativo
- Dica / modo de ferramenta ao passar o mouse : único
Devido aos diferentes recursos do Grafana, você precisa executar ações nessa ordem. Se você alterar a ordem das ações ou deixar alguns campos com as configurações padrão, algo não funcionará:- Stack A B Stacking & Null value / Stack: On, ;
- Hover tooltip / Mode , Single, Hover tooltip .
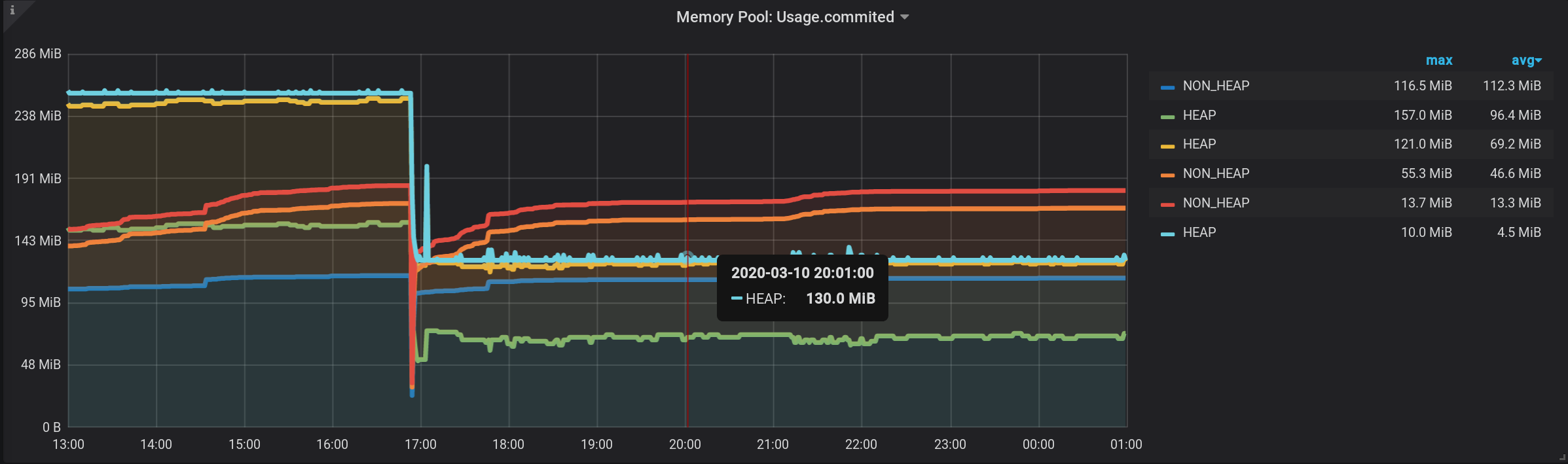
E agora, vemos muitas linhas, como para nós mesmos. Mas! Se você passar o mouse sobre o NON_HEAP mais alto , a dica de ferramenta mostrará a soma dos valores de todos os NON_HEAPs . A quantia é considerada verdadeira, já que a Grafana significa : E se você passar o mouse sobre o gráfico mais alto com o nome HEAP , veremos a quantia por HEAP . O gráfico é exibido corretamente. Até o aumento do HEAP às 17:03 é visível: formalmente, a tarefa está concluída. Mas há contras - muitos gráficos extras são exibidos. Você precisa colocar o cursor no topo deles. E na legenda do gráfico, não cumulativa, mas valores individuais são exibidos; portanto, a legenda se tornou inútil.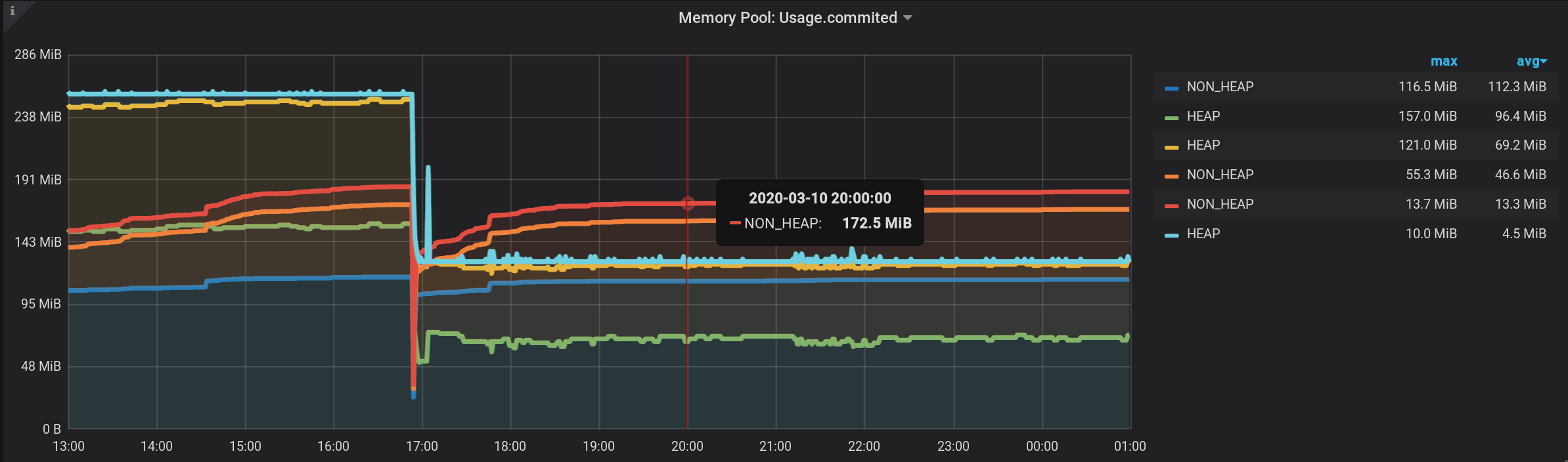
2.2 Valor empilhado: cumulativo com ocultação de linhas intermediárias
Vamos corrigir o primeiro ponto negativo da solução anterior: verifique se gráficos extras não são exibidos.Por esta:- Adicione novas métricas com um nome diferente e valor 0 aos resultados.
- Adicione novas métricas à Pilha A e à Pilha B , na parte superior da pilha.
- Ocultar da tela - as linhas originais de HEAP e NON_HEAP .
Adicionamos dois novos após a solicitação principal: solicitação B para receber uma série com valores 0 e nome [NON_HEAP] e solicitação C para receber uma série com valores 0 e nome [HEAP] . Para obter 0, pegamos o primeiro valor do campo "Usage.committed" em cada grupo de tempo e subtraímos : primeiro ("Usage.committed") - primeiro ("Usage.committed") - obtemos um 0. estável. Os nomes dos gráficos são alterados sem perder o significado devido aos colchetes: [NON_HEAP] e [HEAP] : [HEAP] e HEAP são combinados na pilha A e também ocultam todos os HEAP . [NON_HEAP]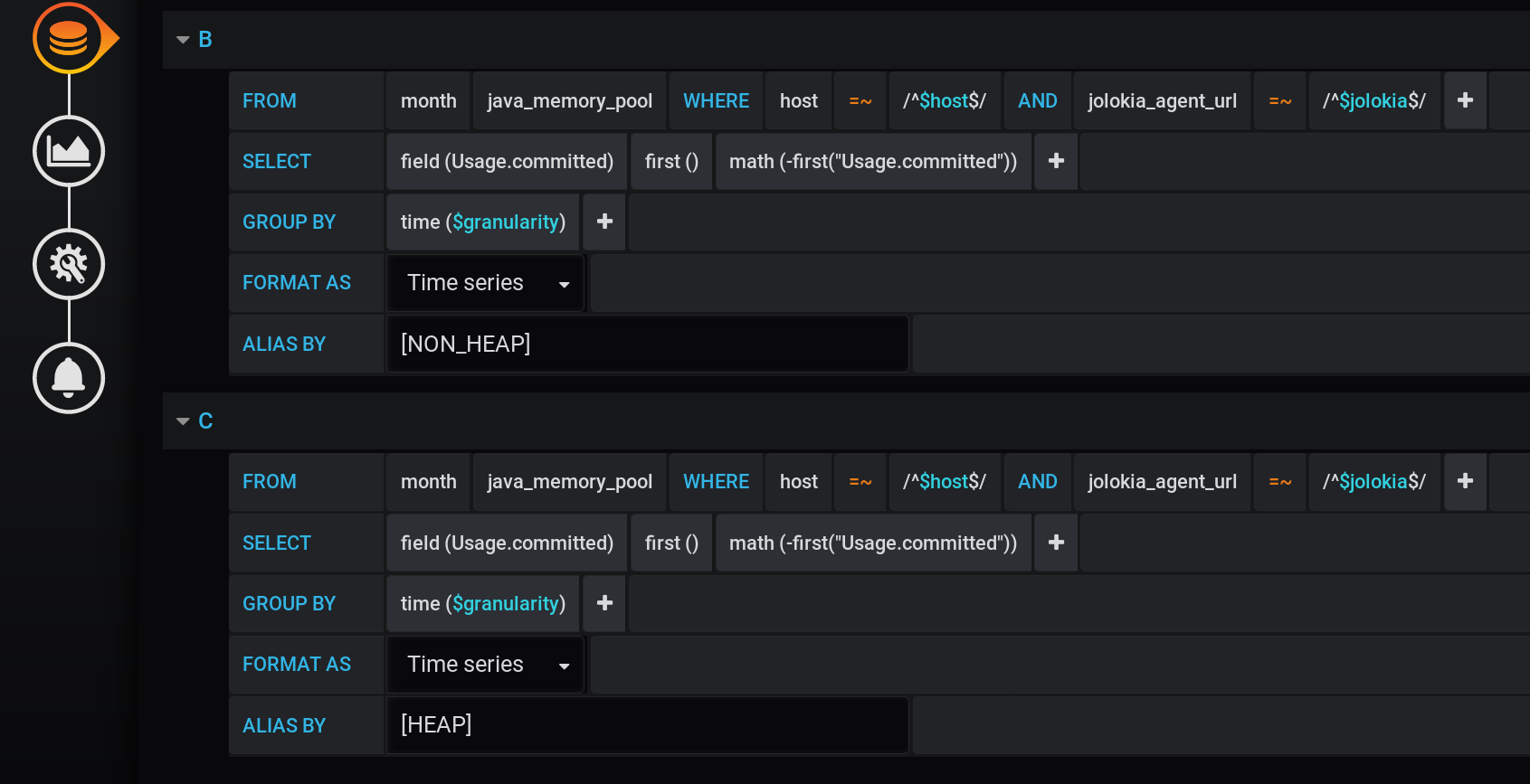 e combine NON_HEAP na pilha B e oculte NON_HEAP : obtenha a
quantidade correta em [NON_HEAP] na dica de ferramenta ao passar o mouse sobre o gráfico: Obtenha a quantidade correta em [HEAP] na dica de ferramenta ao passar o mouse sobre o gráfico. E até todas as explosões são visíveis: e a programação é formada rapidamente. Mas a legenda sempre exibe 0, a legenda se tornou inútil. Tudo deu certo! O verdadeiro desvio é através das pilhas Grafana . É por isso que o artigo foi adicionado à categoria Programação Anormal .
e combine NON_HEAP na pilha B e oculte NON_HEAP : obtenha a
quantidade correta em [NON_HEAP] na dica de ferramenta ao passar o mouse sobre o gráfico: Obtenha a quantidade correta em [HEAP] na dica de ferramenta ao passar o mouse sobre o gráfico. E até todas as explosões são visíveis: e a programação é formada rapidamente. Mas a legenda sempre exibe 0, a legenda se tornou inútil. Tudo deu certo! O verdadeiro desvio é através das pilhas Grafana . É por isso que o artigo foi adicionado à categoria Programação Anormal .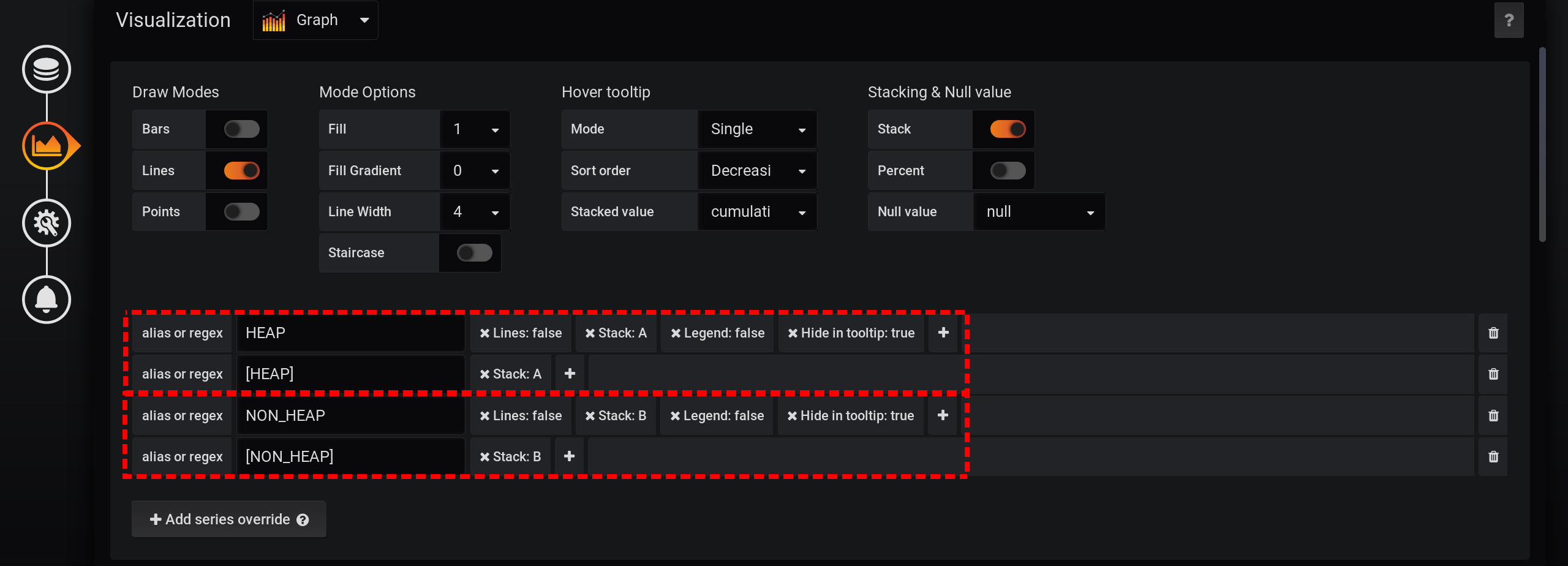


3. A soma dos máximos com a subconsulta
Como já iniciamos o caminho da programação anormal com um monte de Grafana e InfluxDB , vamos continuar. Vamos fazer com que o InfluxDB retorne um pequeno número de pontos e faça a legenda aparecer.3.1 Soma dos incrementos da soma acumulada dos máximos
Vamos nos aprofundar nas possibilidades do InfluxDB . Anteriormente, eu frequentemente ajudava usando a derivada do valor acumulado, então tentaremos aplicar essa abordagem agora. Vamos mudar para o modo de edição manual de solicitações: Vamos fazer uma solicitação:
SELECT sum("U") FROM (
SELECT non_negative_difference(cumulative_sum(max("Usage.committed"))) AS "U"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
GROUP BY "Type", time($granularity)
Aqui, o valor máximo da métrica no grupo por tempo é obtido e a soma desses valores a partir do momento em que a referência começa, agrupados pelas tags Tipo e nome . Como resultado, a cada momento haverá uma soma de todas as indicações por tipo ( HEAP ou NON_HEAP ) com separação pelo nome do conjunto, mas não serão somados 30 valores, como foi o caso na versão 1.2, mas apenas um é o máximo.E se fizermos o incremento non_negative_difference de uma soma acumulada para a última etapa, obteremos o valor da soma de todos os conjuntos de dados agrupados por tags Type e name no início do intervalo de tempo.Agora, para obter o valor somente por tagDigite , sem agrupar por tag de nome , você precisará fazer uma solicitação de nível superior com parâmetros de agrupamento semelhantes, mas sem agrupar por nome .Como resultado de uma consulta tão complexa, obtemos a soma de todos os tipos.Horário perfeito. A soma dos máximos é calculada corretamente. Há uma legenda com os valores corretos, diferentes de zero. Na dica de ferramenta, você pode exibir todas as métricas, não apenas Única. Até as explosões HEAP são exibidas : Uma coisa, mas - a solicitação acabou sendo difícil: a soma do incremento da soma acumulada dos máximos com uma alteração no nível de agrupamento.
3.2 Soma dos máximos com uma alteração no nível de agrupamento
Você pode fazer algo mais simples do que na versão 3.1? A caixa de Pandora já está aberta, mudamos para o modo de edição manual de consultas.Suspeita-se que o recebimento de um incremento do valor acumulado leve a um efeito zero - um extingue o outro. Livre-se da diferença não_negativa (soma cumulativa (...)) .Simplifique a solicitação.Simplesmente deixamos a soma dos máximos, com uma diminuição no nível de agrupamento:SELECT sum("A")
FROM (
SELECT max("Usage.committed") as "A"
FROM "month"."java_memory_pool"
WHERE
(
"host" =~ /^${host:regex}$/ AND
"jolokia_agent_url" =~ /^${jolokia:regex}$/
) AND
$timeFilter
GROUP BY time($granularity), "Type", "name"
)
WHERE $timeFilter
GROUP BY time($granularity), "Type"
Esta é uma consulta simples e rápida que retorna apenas 721 pontos por série em 12 horas, quando agrupada por minutos: 12 (horas) * 60 (minutos) = 720 intervalos, 721 pontos (último vazio). Observe que o filtro de tempo está duplicado. Está na subconsulta e na solicitação de agrupamento: sem $ timeFilter, na solicitação de agrupamento externo, o número de pontos retornados não será 721 em 12 horas, mas mais. Como a subconsulta é agrupada para o intervalo de ... a e o agrupamento de uma solicitação externa sem filtro será para o intervalo de ... agora . E se em Grafana um intervalo de tempo não for passado X-horas (não é tal que to = now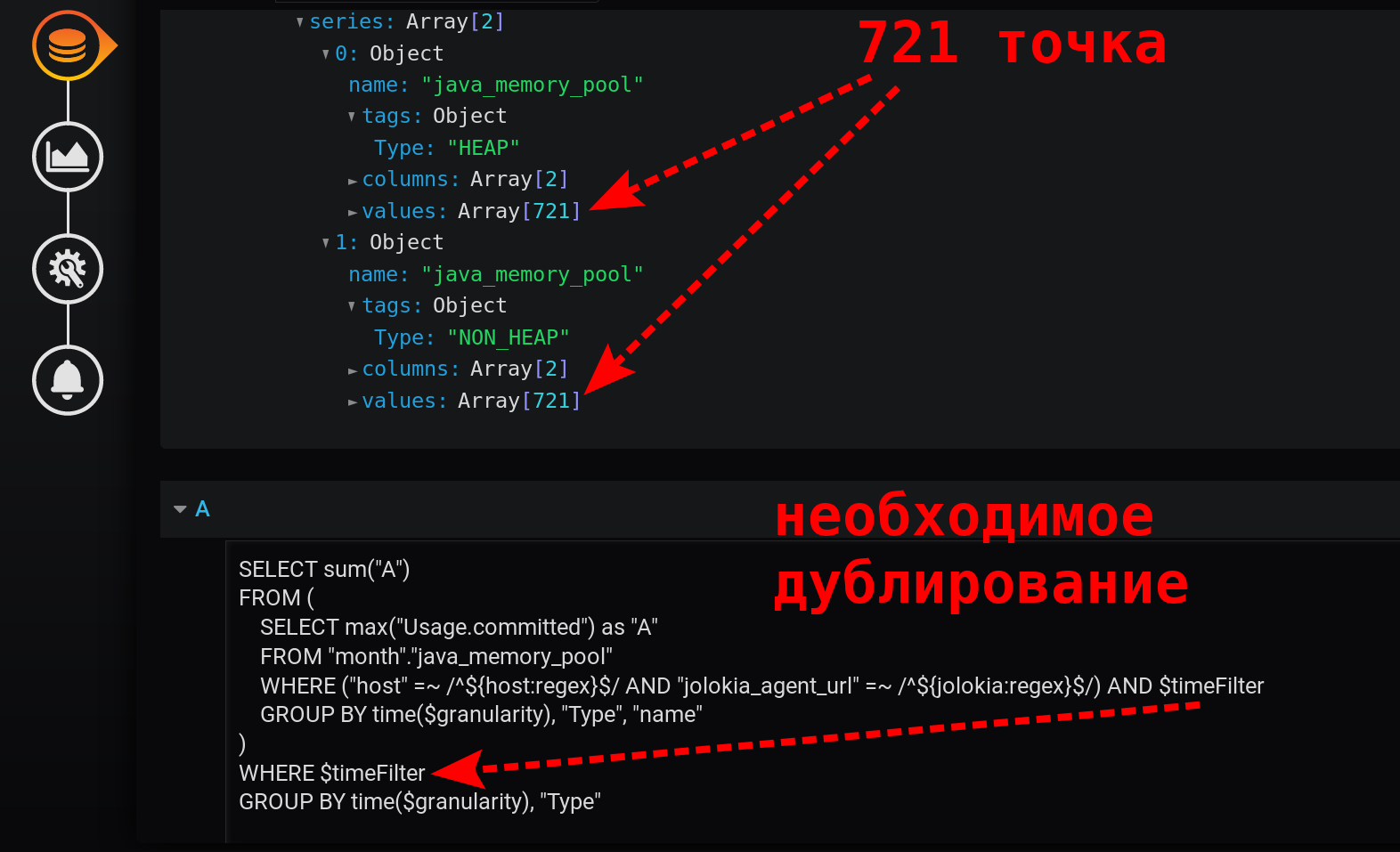 ), mas para o intervalo do passado ( até < agora ), serão exibidos pontos vazios com um valor nulo no final da seleção.O gráfico resultante acabou sendo simples, rápido, correto. Com uma legenda que exibe métricas de resumo. Com dica de ferramenta para várias linhas ao mesmo tempo. E também com a exibição de todas as explosões de valores: o resultado é alcançado!
), mas para o intervalo do passado ( até < agora ), serão exibidos pontos vazios com um valor nulo no final da seleção.O gráfico resultante acabou sendo simples, rápido, correto. Com uma legenda que exibe métricas de resumo. Com dica de ferramenta para várias linhas ao mesmo tempo. E também com a exibição de todas as explosões de valores: o resultado é alcançado!Referências (em vez de referências)
Distribuições das ferramentas usadas no artigo:Documentação sobre os recursos das ferramentas usadas no artigo:A combinação de Grafana e InfluxDB precisa ser bem conhecida pelos engenheiros de teste de desempenho. E neste pacote, muitas tarefas simples são muito interessantes e nem sempre podem ser resolvidas pelos métodos de programação normais.Às vezes habilidades de programação anormais podem ser necessários com as Grafana características e sutilezas do InfluxDB consulta idioma .No artigo, quatro etapas foram levadas em consideração na implementação do resumo de uma métrica com um agrupamento por uma tag, mas que possui várias tags. A tarefa foi interessante. E existem muitas dessas tarefas. Estoupreparando um relatório sobre as sutilezas da programação com Grafana e InfluxDB. Publicarei periodicamente materiais sobre esse tópico. Enquanto isso, ficarei feliz com suas perguntas no artigo atual.