 Ilustração criada para A Journey With Go de um Gopher original criado por Rene French.Em termos de desempenho, o uso sistemático de ponteiros em vez de copiar a própria estrutura para compartilhar estruturas para muitos desenvolvedores Go parece a melhor opção. Para entender o efeito de usar um ponteiro em vez de uma cópia da estrutura, consideraremos dois casos de uso.
Ilustração criada para A Journey With Go de um Gopher original criado por Rene French.Em termos de desempenho, o uso sistemático de ponteiros em vez de copiar a própria estrutura para compartilhar estruturas para muitos desenvolvedores Go parece a melhor opção. Para entender o efeito de usar um ponteiro em vez de uma cópia da estrutura, consideraremos dois casos de uso.Distribuição intensiva de dados
Vejamos um exemplo simples quando você deseja compartilhar uma estrutura para acessar seus valores:type S struct {
a, b, c int64
d, e, f string
g, h, i float64
}
Aqui está a estrutura básica, cujo acesso pode ser compartilhado por cópia ou ponteiro:func byCopy() S {
return S{
a: 1, b: 1, c: 1,
e: "foo", f: "foo",
g: 1.0, h: 1.0, i: 1.0,
}
}
func byPointer() *S {
return &S{
a: 1, b: 1, c: 1,
e: "foo", f: "foo",
g: 1.0, h: 1.0, i: 1.0,
}
}
Com base nesses dois métodos, podemos escrever 2 pontos de referência. O primeiro é onde a estrutura é passada com uma cópia:func BenchmarkMemoryStack(b *testing.B) {
var s S
f, err := os.Create("stack.out")
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
for i := 0; i < b.N; i++ {
s = byCopy()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
O segundo - muito semelhante ao primeiro - onde a estrutura é passada pelo ponteiro:func BenchmarkMemoryHeap(b *testing.B) {
var s *S
f, err := os.Create("heap.out")
if err != nil {
panic(err)
}
defer f.Close()
err = trace.Start(f)
if err != nil {
panic(err)
}
for i := 0; i < b.N; i++ {
s = byPointer()
}
trace.Stop()
b.StopTimer()
_ = fmt.Sprintf("%v", s.a)
}
Vamos executar os benchmarks:go test ./... -bench=BenchmarkMemoryHeap -benchmem -run=^$ -count=10 > head.txt && benchstat head.txt
go test ./... -bench=BenchmarkMemoryStack -benchmem -run=^$ -count=10 > stack.txt && benchstat stack.txt
Temos as seguintes estatísticas:name time/op
MemoryHeap-4 75.0ns ± 5%
name alloc/op
MemoryHeap-4 96.0B ± 0%
name allocs/op
MemoryHeap-4 1.00 ± 0%
------------------
name time/op
MemoryStack-4 8.93ns ± 4%
name alloc/op
MemoryStack-4 0.00B
name allocs/op
MemoryStack-4 0.00
Usar uma cópia da estrutura foi 8 vezes mais rápido do que usar um ponteiro para ela!Para entender o porquê, vejamos os gráficos gerados pelo rastreamento: o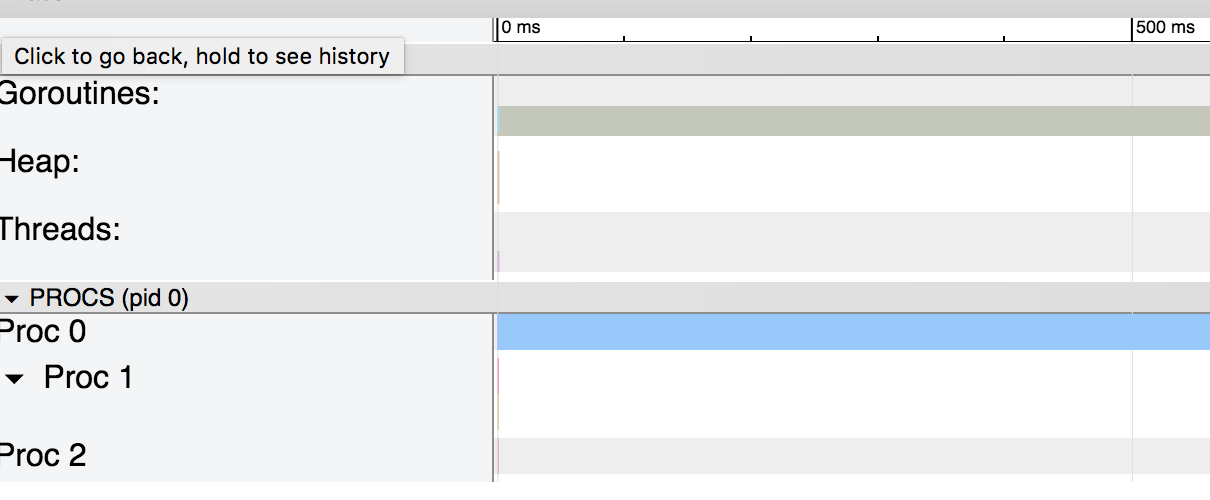 gráfico para a estrutura passada pela cópia e o
gráfico para a estrutura passada pela cópia e o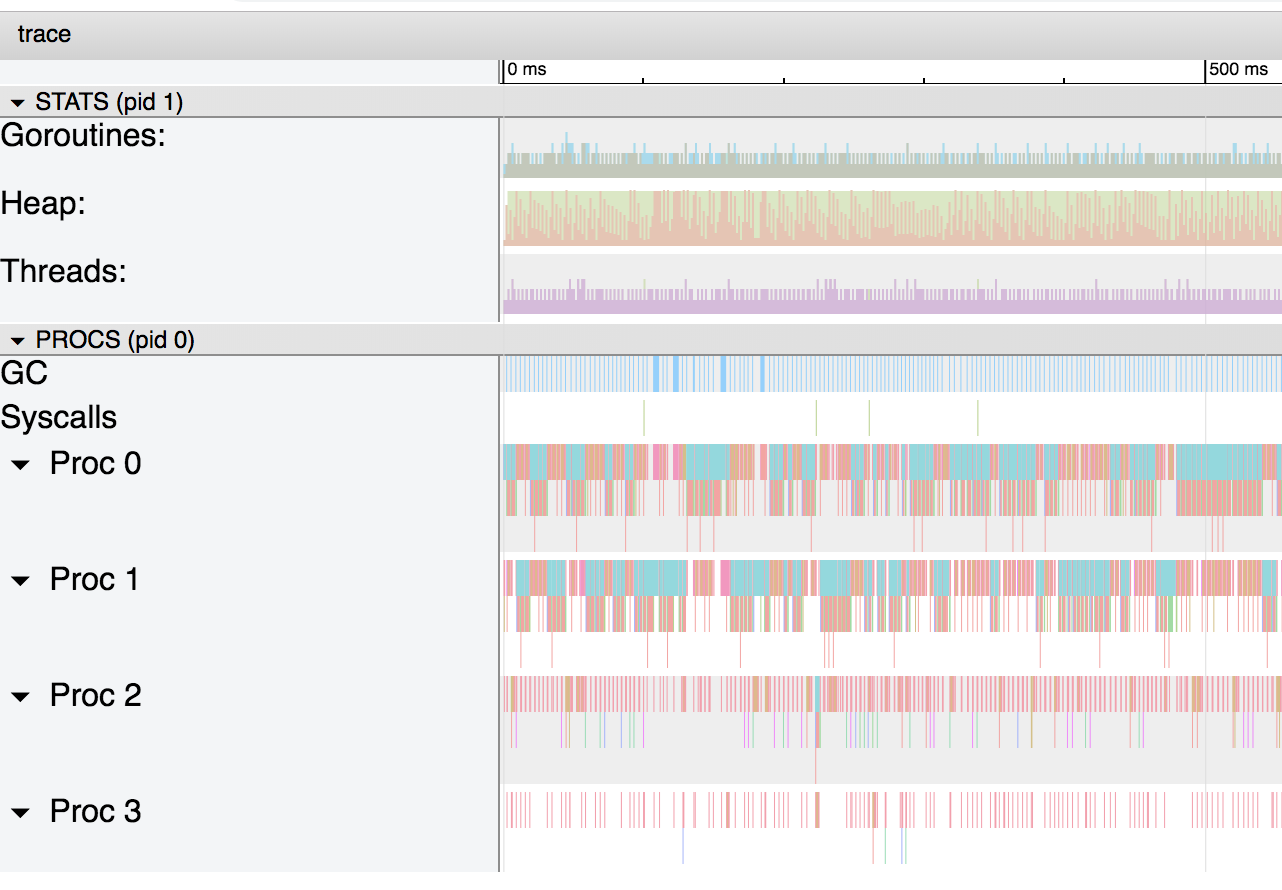 gráfico para a estrutura passada pelo ponteiroO primeiro gráfico é bastante simples. Como a pilha não é usada, não há coletor de lixo e excesso de gorutina.No segundo caso, o uso de ponteiros faz com que o compilador Go mova a variável para a pilha e funcione como coletor de lixo. Se aumentarmos a escala do gráfico, veremos que o coletor de lixo ocupa uma parte importante do processo:
gráfico para a estrutura passada pelo ponteiroO primeiro gráfico é bastante simples. Como a pilha não é usada, não há coletor de lixo e excesso de gorutina.No segundo caso, o uso de ponteiros faz com que o compilador Go mova a variável para a pilha e funcione como coletor de lixo. Se aumentarmos a escala do gráfico, veremos que o coletor de lixo ocupa uma parte importante do processo: Este gráfico mostra que o coletor de lixo é iniciado a cada 4 ms.Se aumentarmos o zoom novamente, podemos obter informações detalhadas sobre o que exatamente está acontecendo:
Este gráfico mostra que o coletor de lixo é iniciado a cada 4 ms.Se aumentarmos o zoom novamente, podemos obter informações detalhadas sobre o que exatamente está acontecendo: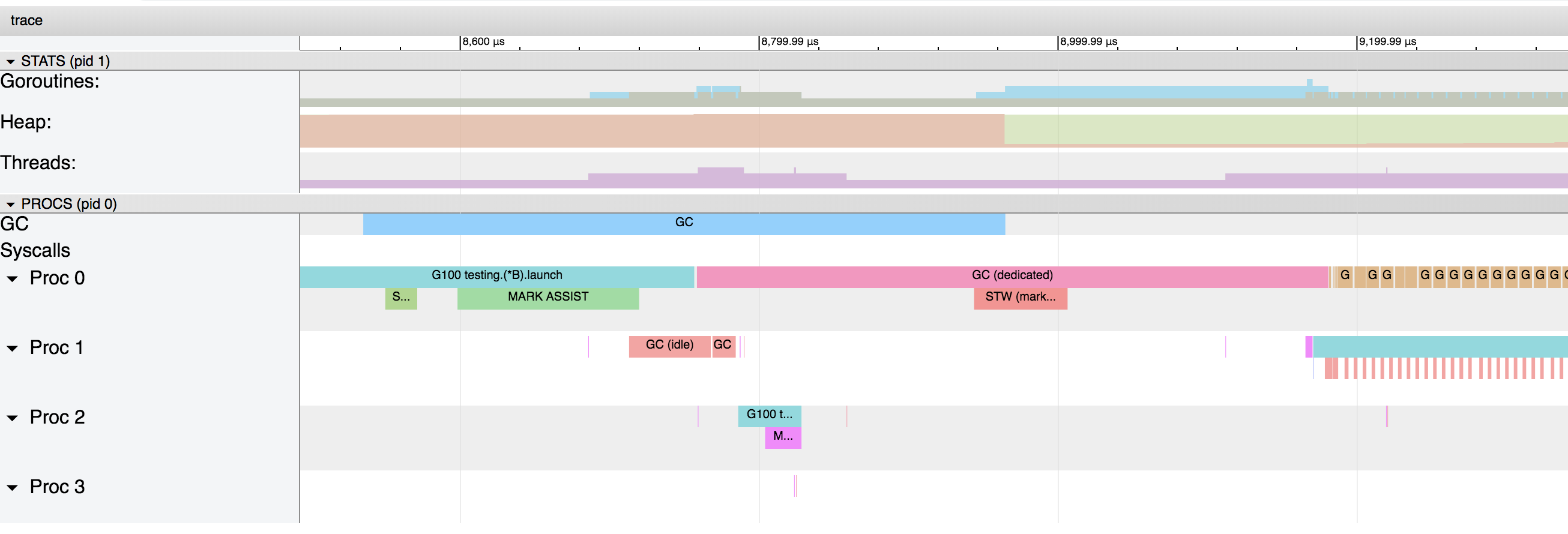 as listras azul, rosa e vermelha são as fases do coletor de lixo e as marrons são associadas à alocação no heap (marcado “runtime.bgsweep” no gráfico):
as listras azul, rosa e vermelha são as fases do coletor de lixo e as marrons são associadas à alocação no heap (marcado “runtime.bgsweep” no gráfico):Varrer é a liberação do heap de seções da memória relacionadas a dados que não são marcadas como usadas. Esta ação ocorre quando as goroutines tentam isolar novos valores na memória heap. O atraso de varredura é adicionado ao custo de executar a alocação na memória heap e não se aplica a atrasos associados à coleta de lixo.
www.ardanlabs.com/blog/2018/12/garbage-collection-in-go-part1-semantics.html
Mesmo que este exemplo seja um pouco extremo, vemos como pode ser caro alocar uma variável na pilha e não na pilha. Em nosso exemplo, a estrutura é alocada muito mais rapidamente na pilha e copiada do que criada na pilha e seu endereço é compartilhado.Se você não estiver familiarizado com a pilha / pilha e quiser saber mais sobre os detalhes internos, poderá encontrar muitas informações na Internet, por exemplo, este artigo de Paul Gribble.
As coisas podem ser ainda piores se limitarmos o processador a 1 usando GOMAXPROCS = 1:name time/op
MemoryHeap 114ns ± 4%
name alloc/op
MemoryHeap 96.0B ± 0%
name allocs/op
MemoryHeap 1.00 ± 0%
------------------
name time/op
MemoryStack 8.77ns ± 5%
name alloc/op
MemoryStack 0.00B
name allocs/op
MemoryStack 0.00
Se o valor de referência para colocar na pilha não mudou, o indicador no heap diminuiu de 75ns / op para 114ns / op.Chamadas de função intensivas
Adicionaremos dois métodos vazios à nossa estrutura e adaptaremos um pouco os nossos benchmarks:func (s S) stack(s1 S) {}
func (s *S) heap(s1 *S) {}
O benchmark com o posicionamento na pilha criará a estrutura e passará uma cópia para ela:func BenchmarkMemoryStack(b *testing.B) {
var s S
var s1 S
s = byCopy()
s1 = byCopy()
for i := 0; i < b.N; i++ {
for i := 0; i < 1000000; i++ {
s.stack(s1)
}
}
}
E a referência para o heap passará a estrutura pelo ponteiro:func BenchmarkMemoryHeap(b *testing.B) {
var s *S
var s1 *S
s = byPointer()
s1 = byPointer()
for i := 0; i < b.N; i++ {
for i := 0; i < 1000000; i++ {
s.heap(s1)
}
}
}
Como esperado, os resultados são completamente diferentes agora:name time/op
MemoryHeap-4 301µs ± 4%
name alloc/op
MemoryHeap-4 0.00B
name allocs/op
MemoryHeap-4 0.00
------------------
name time/op
MemoryStack-4 595µs ± 2%
name alloc/op
MemoryStack-4 0.00B
name allocs/op
MemoryStack-4 0.00
Conclusão
Usar um ponteiro em vez de uma cópia da estrutura em movimento nem sempre é bom. Para escolher uma boa semântica para seus dados, eu recomendo a leitura de uma postagem sobre semântica de valor / ponteiro escrita por Bill Kennedy . Isso lhe dará uma idéia melhor das estratégias que você pode usar com suas estruturas e tipos internos. Além disso, o uso de memória de criação de perfil definitivamente ajudará você a entender o que está acontecendo com suas alocações e heap.