Olá a todos. Em 26 de fevereiro, as aulas começaram no OTUS em um novo grupo no curso "MS SQL Server Developer" . A esse respeito, quero compartilhar com você minha publicação sobre as funções da janela. A propósito, na próxima semana você ainda pode participar do grupo ;-).
As funções de janela são bem estabelecidas em nossa prática, mas poucas pessoas sabem como os quadros RANGE e ROWS funcionam.Talvez seja por isso que eles são um pouco menos comuns. O objetivo deste artigo é fornecer exemplos de uso para que você definitivamente não tenha perguntas "Quem é quem?" e "Como aplicá-lo?". A pergunta "Por quê?" O artigo permanecerá apagado.Vejamos o que é um quadro e como obter um efeito semelhante usando ORDER By na cláusula OVER ().Para demonstração, usaremos uma tabela simples para que você possa calcular exemplos sem usar um compilador. Em geral, eu recomendo - veja e pense sobre o que será o resultado da execução e depois verifique a si mesmo - para encontrar manchas brancas na percepção das funções da janela, o que pode não ser óbvio quando você ler os resultados finais.MesaCreate table sales
(sales_id INT PRIMARY KEY, sales_dt DATETIME2 DEFAULT GETUTCDATE(), customer_id INT, item_id INT, cnt INT, price_per_item DECIMAL(19,4));
INSERT INTO sales
(sales_id, sales_dt, customer_id, item_id, cnt, price_per_item)
VALUES
(1, '2020-01-10T10:00:00', 100, 200, 2, 30.15),
(2, '2020-01-11T11:00:00', 100, 311, 1, 5.00),
(3, '2020-01-12T14:00:00', 100, 400, 1, 50.00),
(4, '2020-01-12T20:00:00', 100, 311, 5, 5.00),
(5, '2020-01-13T10:00:00', 150, 311, 1, 5.00),
(6, '2020-01-13T11:00:00', 100, 315, 1, 17.00),
(7, '2020-01-14T10:00:00', 150, 200, 2, 30.15),
(8, '2020-01-14T15:00:00', 100, 380, 1, 8.00),
(9, '2020-01-14T18:00:00', 170, 380, 3, 8.00),
(10, '2020-01-15T09:30:00', 100, 311, 1, 5.00),
(11, '2020-01-15T12:45:00', 150, 311, 5, 5.00),
(12, '2020-01-15T21:30:00', 170, 200, 1, 30.15);
Vamos começar com um momento simples - as diferenças na função SUM com e sem classificaçãoSELECT sales_id, customer_id, count,
SUM(count) OVER () as total,
SUM(count) OVER (ORDER BY customer_id) AS cum,
SUM(count) OVER (ORDER BY customer_id, sales_id) AS cum_uniq
FROM sales
ORDER BY customer_id, sales_id;
 Vejamos o primeiro rake discreto, como você acha quantos desenvolvedores pensam que cum e cum_uniq são iguais ao ler o código? Pense um pouco? Talvez, mas porque aqui é óbvio, e é tão óbvio ao ler o código no aplicativo, e mesmo com a não singularidade não tão óbvia do campo de classificação.Agora abra nossa maravilhosa janela.A janela, ou melhor, o quadro tem 2 tipos de ROWS e RANGE, conheça o ROWS primeiro.Opções de restrição de quadro:
Vejamos o primeiro rake discreto, como você acha quantos desenvolvedores pensam que cum e cum_uniq são iguais ao ler o código? Pense um pouco? Talvez, mas porque aqui é óbvio, e é tão óbvio ao ler o código no aplicativo, e mesmo com a não singularidade não tão óbvia do campo de classificação.Agora abra nossa maravilhosa janela.A janela, ou melhor, o quadro tem 2 tipos de ROWS e RANGE, conheça o ROWS primeiro.Opções de restrição de quadro:- Tudo antes da linha / intervalo atual e o valor real da linha atual
ENTRE O PRECEDIMENTO NÃO LIMITADO
ENTRE O PRECEDIMENTO NÃO LIMITADO E A LINHA ATUAL
- Linha / intervalo atual e tudo mais a seguir
ENTRE A LINHA ATUAL E A SEGUINTE SEGUINTE - Especificando quantas linhas antes e depois a serem incluídas (não suportadas para RANGE)
ENTRE N Anterior e N Seguindo
ENTRE A LINHA ATUAL E N Seguindo
ENTRE N ANTERIOR E A LINHA ATUAL
Mas vamos ver o quadro em ação.Abrimos a “janela” na linha atual e todas as anteriores, para a função SUM, como você pode ver, isso coincide com a classificação ASCSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY customer_id, sales_id;
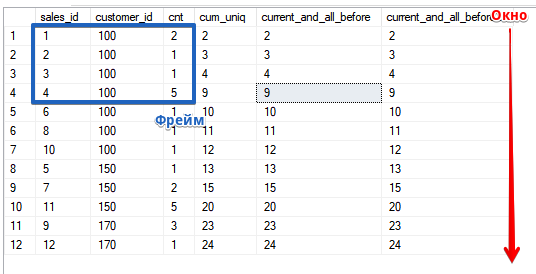 Quero lembrá-lo de que a ordem de classificação na janela (na cláusula OVER ()) não está relacionada à ordem de classificação na própria consulta, no exemplo é a mesma para simplificar o cálculo se você decidir verificar o cálculo e sua compreensão de como a função funciona
Quero lembrá-lo de que a ordem de classificação na janela (na cláusula OVER ()) não está relacionada à ordem de classificação na própria consulta, no exemplo é a mesma para simplificar o cálculo se você decidir verificar o cálculo e sua compreensão de como a função funcionaSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id) AS cum_uniq,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS current_and_all_before2
FROM sales
ORDER BY cnt;
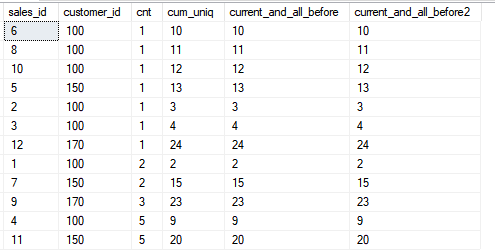 Agora, vejamos a funcionalidade do quadro quando incluímos todas as linhas subseqüentes.
Agora, vejamos a funcionalidade do quadro quando incluímos todas as linhas subseqüentes.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_frame,
SUM(cnt) OVER (ORDER BY customer_id DESC, sales_id DESC) AS current_and_all_order_desc
FROM sales
ORDER BY customer_id, sales_id;
 Como você pode ver aqui, também é possível obter o mesmo resultado para uma função agregada, se você usar a classificação reversa - mas o ROWS é um pouco mais estável, porque se seus campos de classificação não forem exclusivos, você poderá surpreender na forma dos mesmos valores.E, finalmente, uma opção que não pode mais ser imitada por tipos, quando especificamos um número específico de linhas que devem ser incluídas no quadro
Como você pode ver aqui, também é possível obter o mesmo resultado para uma função agregada, se você usar a classificação reversa - mas o ROWS é um pouco mais estável, porque se seus campos de classificação não forem exclusivos, você poderá surpreender na forma dos mesmos valores.E, finalmente, uma opção que não pode mais ser imitada por tipos, quando especificamos um número específico de linhas que devem ser incluídas no quadroSELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS before_and_current,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS current_and_1_next,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, sales_id ROWS BETWEEN 2 PRECEDING AND 2 FOLLOWING) AS before2_and_2_next
FROM sales
ORDER BY customer_id, sales_id;
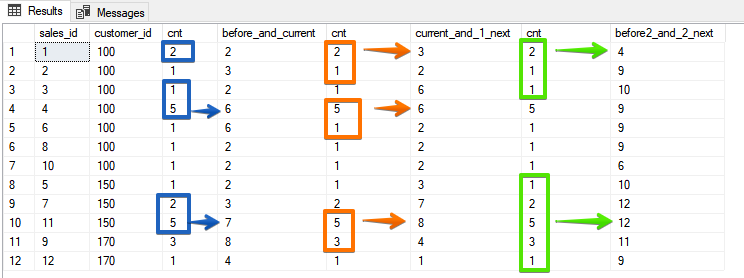 Nesta opção, você já indica especificamente quais linhas estão no intervalo e, na minha opinião, é mais óbvio a partir dos resultados.
Nesta opção, você já indica especificamente quais linhas estão no intervalo e, na minha opinião, é mais óbvio a partir dos resultados.A diferença entre ROWS e RANGE
A diferença é que o ROWS opera em uma linha e o RANGE em um intervalo. É verdade que isso é óbvio pelo nome, mas explica pouco na prática?Vejamos a figura (fonte na parte inferior do artigo)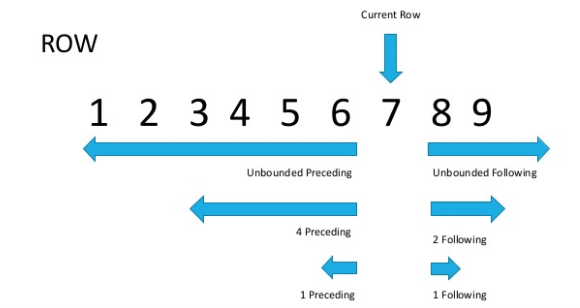
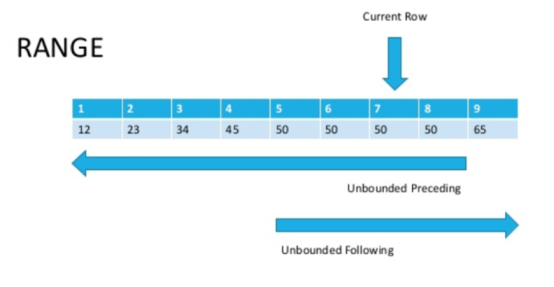 Agora, se observarmos com atenção, ficará óbvio que as linhas com o mesmo valor do parâmetro de classificação são chamadas de intervalo.Como mencionado acima, o ROWS é limitado a apenas uma sequência, enquanto o RANGE captura todo o intervalo de valores correspondentes que você especifica na função da janela ORDER BY.
Agora, se observarmos com atenção, ficará óbvio que as linhas com o mesmo valor do parâmetro de classificação são chamadas de intervalo.Como mencionado acima, o ROWS é limitado a apenas uma sequência, enquanto o RANGE captura todo o intervalo de valores correspondentes que você especifica na função da janela ORDER BY.SELECT sales_id, customer_id, cnt,
SUM(cnt) OVER (ORDER BY customer_id) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, sales_id;
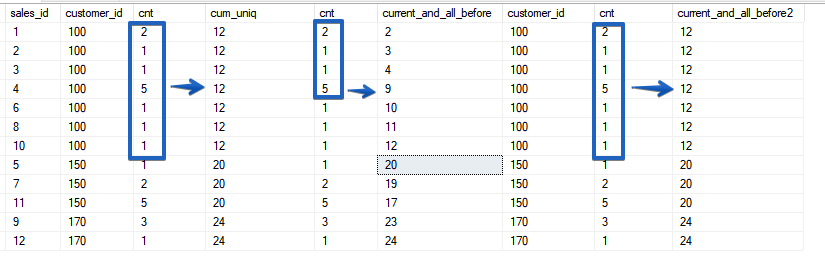 ROWS - sempre opera com uma linha específica, mesmo que a classificação não seja exclusiva, mas RANGE apenas combina períodos em intervalos com os valores correspondentes dos campos de classificação. Nesse sentido, a funcionalidade é muito semelhante ao comportamento da função SUM () com a classificação por um campo não exclusivo. Vamos ver outro exemplo.
ROWS - sempre opera com uma linha específica, mesmo que a classificação não seja exclusiva, mas RANGE apenas combina períodos em intervalos com os valores correspondentes dos campos de classificação. Nesse sentido, a funcionalidade é muito semelhante ao comportamento da função SUM () com a classificação por um campo não exclusivo. Vamos ver outro exemplo.SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS UNBOUNDED PRECEDING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE UNBOUNDED PRECEDING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item;
 Já existem 2 campos e o intervalo é determinado por um intervalo com valores correspondentes para ambos os campos.Ea opção é quando incluímos no cálculo todas as linhas subsequentes da atual, que no caso da função SUM coincide com o valor que pode ser obtido usando a classificação reversa:
Já existem 2 campos e o intervalo é determinado por um intervalo com valores correspondentes para ambos os campos.Ea opção é quando incluímos no cálculo todas as linhas subsequentes da atual, que no caso da função SUM coincide com o valor que pode ser obtido usando a classificação reversa:SELECT sales_id, customer_id, price_per_item, cnt,
SUM(cnt) OVER (ORDER BY customer_id DESC, price_per_item DESC) AS cum_uniq,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before,
customer_id,
cnt,
SUM(cnt) OVER (ORDER BY customer_id, price_per_item RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS current_and_all_before2
FROM sales
ORDER BY 2, price_per_item, sales_id desc;
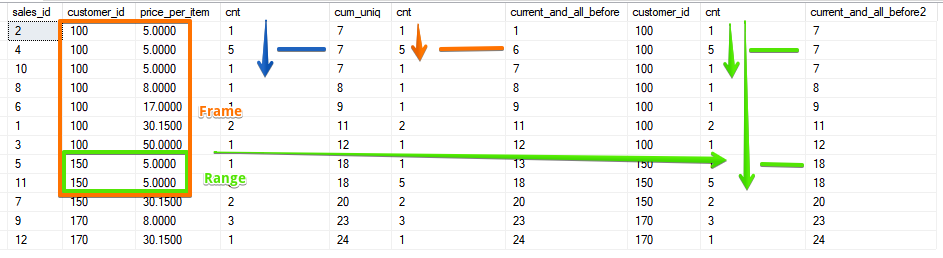 Como você pode ver, o RANGE novamente captura todo o intervalo de pares correspondentes.Apesar do fato de que a funcionalidade do ROWS e do RANGE está longe de ser nova a cada vez, surgem dúvidas sobre como usá-lo. Espero que este artigo tenha adicionado um entendimento de como o ROWS e o RANGE são diferentes, e agora você não duvidará de qual caso esse ou aquele quadro é necessário.Ilustração Fonte GAMA sobre a diferença e as ROWS quea janela funciona Com o SQL Server 2016, Mark Tabladillo chegou atempo do curso
Como você pode ver, o RANGE novamente captura todo o intervalo de pares correspondentes.Apesar do fato de que a funcionalidade do ROWS e do RANGE está longe de ser nova a cada vez, surgem dúvidas sobre como usá-lo. Espero que este artigo tenha adicionado um entendimento de como o ROWS e o RANGE são diferentes, e agora você não duvidará de qual caso esse ou aquele quadro é necessário.Ilustração Fonte GAMA sobre a diferença e as ROWS quea janela funciona Com o SQL Server 2016, Mark Tabladillo chegou atempo do curso