Meu nome é Pavel Parkhomenko, sou desenvolvedor de ML. Neste artigo, gostaria de falar sobre o design do serviço Yandex.Zen e compartilhar melhorias técnicas, cuja introdução permitiu aumentar a qualidade das recomendações. Na publicação, você aprenderá como encontrar o mais relevante para o usuário entre milhões de documentos em apenas alguns milissegundos; como fazer a decomposição contínua de uma matriz grande (consistindo em milhões de colunas e dezenas de milhões de linhas) para que novos documentos recebam seu vetor em dezenas de minutos; como reutilizar a decomposição da matriz do artigo do usuário para obter uma boa representação vetorial do vídeo. Nosso banco de dados de recomendações contém milhões de documentos de vários formatos: artigos de texto criados em nossa plataforma e extraídos de sites externos, vídeos, narrativas e posts curtos. O desenvolvimento desse serviço está associado a um grande número de desafios técnicos. Aqui estão alguns deles:
Nosso banco de dados de recomendações contém milhões de documentos de vários formatos: artigos de texto criados em nossa plataforma e extraídos de sites externos, vídeos, narrativas e posts curtos. O desenvolvimento desse serviço está associado a um grande número de desafios técnicos. Aqui estão alguns deles:- Tarefas computacionais separadas: faça todas as operações pesadas offline e em tempo real execute apenas a aplicação rápida de modelos para ser responsável por 100-200 ms.
- Considere rapidamente as ações do usuário. Para isso, é necessário que todos os eventos sejam entregues instantaneamente ao recomendador e afetem o resultado dos modelos.
- Faça a fita para que os novos usuários se adaptem rapidamente ao seu comportamento. As pessoas que acabaram de entrar no sistema devem sentir que seus comentários influenciam as recomendações.
- Entenda rapidamente quem recomendar um novo artigo.
- Responda rapidamente ao surgimento constante de novos conteúdos. Dezenas de milhares de artigos são publicados todos os dias e muitos deles têm uma vida útil limitada (por exemplo, notícias). Essa é a diferença entre filmes, música e outros conteúdos de longa duração e caros.
- Transfira conhecimento de um domínio para outro. Se o sistema de recomendação tiver modelos treinados para artigos de texto e adicionarmos vídeo a ele, você poderá reutilizar os modelos existentes para que o novo tipo de conteúdo seja melhor classificado.
Vou lhe contar como resolvemos esses problemas.Seleção de Candidatos
Como, em alguns milissegundos, reduzir o conjunto de documentos em consideração em mil vezes, praticamente sem comprometer a qualidade da classificação?Suponhamos que treinamos muitos modelos de ML, geramos atributos com base neles e treinamos outro modelo que classifica documentos para o usuário. Tudo ficaria bem, mas você não pode simplesmente pegar e contar todos os sinais de todos os documentos em tempo real, se houver milhões desses documentos, e as recomendações precisam ser construídas em 100-200 ms. A tarefa é escolher entre milhões um determinado subconjunto que será classificado para o usuário. Essa etapa é chamada de seleção de candidato. Tem vários requisitos. Em primeiro lugar, a seleção deve ocorrer muito rapidamente, para que o máximo de tempo possível permaneça no próprio ranking. Em segundo lugar, ao reduzir bastante o número de documentos para classificação, devemos manter os documentos relevantes para o usuário o mais completo possível.Nosso princípio de seleção de candidatos evoluiu evolutivamente e, no momento, chegamos a um esquema de várias etapas: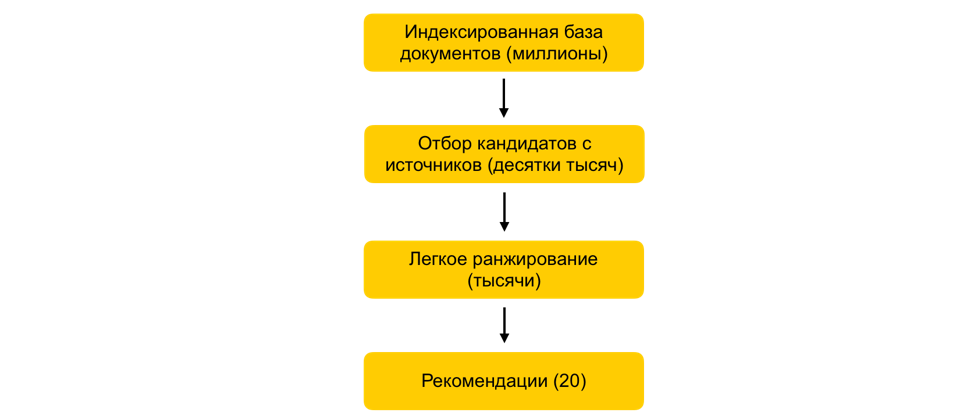 primeiro, todos os documentos são divididos em grupos e os documentos mais populares são retirados de cada grupo. Grupos podem ser sites, tópicos, clusters. Para cada usuário, com base em sua história, os grupos mais próximos a ele são selecionados e os melhores documentos já foram retirados deles. Também usamos o índice kNN para selecionar os documentos mais próximos do usuário em tempo real. Existem vários métodos para construir o índice kNN, temos o HNSW mais bem ganho(Gráficos de mundo pequeno navegável hierárquico). Este é um modelo hierárquico que permite encontrar N vetores mais próximos para um usuário em um milionésimo banco de dados em alguns milissegundos. Anteriormente, indexamos offline todo o banco de dados de documentos. Como a pesquisa no índice funciona muito rapidamente, se houver várias incorporações fortes, é possível criar vários índices (um índice para cada incorporação) e acessar cada um deles em tempo real.Ainda temos dezenas de milhares de documentos para cada usuário. Ainda é muito para contar todos os atributos, portanto, neste estágio, aplicamos uma classificação fácil - um modelo leve e pesado de classificação com menos atributos. A tarefa é prever quais documentos o modelo pesado terá na parte superior. Os documentos com a maior previsão serão utilizados no modelo pesado, ou seja, na última etapa do ranking. Essa abordagem permite que dezenas de milissegundos reduzam o banco de dados de documentos considerados para o usuário de milhões para milhares.
primeiro, todos os documentos são divididos em grupos e os documentos mais populares são retirados de cada grupo. Grupos podem ser sites, tópicos, clusters. Para cada usuário, com base em sua história, os grupos mais próximos a ele são selecionados e os melhores documentos já foram retirados deles. Também usamos o índice kNN para selecionar os documentos mais próximos do usuário em tempo real. Existem vários métodos para construir o índice kNN, temos o HNSW mais bem ganho(Gráficos de mundo pequeno navegável hierárquico). Este é um modelo hierárquico que permite encontrar N vetores mais próximos para um usuário em um milionésimo banco de dados em alguns milissegundos. Anteriormente, indexamos offline todo o banco de dados de documentos. Como a pesquisa no índice funciona muito rapidamente, se houver várias incorporações fortes, é possível criar vários índices (um índice para cada incorporação) e acessar cada um deles em tempo real.Ainda temos dezenas de milhares de documentos para cada usuário. Ainda é muito para contar todos os atributos, portanto, neste estágio, aplicamos uma classificação fácil - um modelo leve e pesado de classificação com menos atributos. A tarefa é prever quais documentos o modelo pesado terá na parte superior. Os documentos com a maior previsão serão utilizados no modelo pesado, ou seja, na última etapa do ranking. Essa abordagem permite que dezenas de milissegundos reduzam o banco de dados de documentos considerados para o usuário de milhões para milhares.Etapa do ALS em tempo de execução
Como levar em consideração o feedback do usuário imediatamente após um clique?Um fator importante nas recomendações é o tempo de resposta ao feedback do usuário. Isso é especialmente importante para novos usuários: quando uma pessoa está apenas começando a usar o sistema de recomendação, ela recebe um fluxo não personalizado de documentos de vários tópicos. Assim que ele der o primeiro clique, você deve imediatamente levar isso em conta e se adaptar aos interesses dele. Se todos os fatores forem calculados offline, uma resposta rápida do sistema se tornará impossível devido ao atraso. Portanto, você precisa processar as ações do usuário em tempo real. Para esses fins, usamos a etapa ALS no tempo de execução para criar uma representação vetorial do usuário.Suponha que tenhamos uma representação vetorial para todos os documentos. Por exemplo, podemos construir offline com base nas incorporações de texto do artigo usando ELMo, BERT ou outros modelos de aprendizado de máquina. Como se pode obter uma representação vetorial de usuários no mesmo espaço, com base em sua interação no sistema?O princípio geral da formação e decomposição da matriz de documentos do usuáriom n . . m x n: , — . , ́ , . (, , ) - — , 1, –1.
: P (m x d) Q (d x n), d — ( ). d- ( — P, — Q). . , , .

Uma das formas possíveis de decomposição da matriz é ALS (Mínimos Quadrados Alternados). Vamos otimizar a seguinte função de perda:
Aqui r ui é a interação do usuário u com o documento i, q i é o vetor do documento i, p u é o vetor do usuário u.Em seguida, o vetor de usuário ideal do ponto de vista do erro quadrático médio (para vetores de documentos fixos) é encontrado analiticamente, resolvendo a regressão linear correspondente.Isso é chamado de etapa da ALS. E o próprio algoritmo ALS consiste no fato de que fixamos alternadamente uma das matrizes (usuários e artigos) e atualizamos a outra, encontrando a solução ideal.Felizmente, encontrar uma representação vetorial de um usuário é uma operação bastante rápida que pode ser feita em tempo de execução usando instruções vetoriais. Esse truque permite que você leve imediatamente em consideração o feedback do usuário no ranking. A mesma incorporação pode ser usada no índice kNN para melhorar a seleção de candidatos.Filtragem Colaborativa Distribuída
Como fazer a fatoração de matriz distribuída incremental e encontrar rapidamente uma representação vetorial de novos artigos?O conteúdo não é a única fonte de sinais para recomendações. Informações colaborativas são outra fonte importante. Tradicionalmente, bons sinais de classificação podem ser obtidos a partir da decomposição da matriz de documentos do usuário. Mas, ao tentar fazer essa decomposição, tivemos problemas:1. Temos milhões de documentos e dezenas de milhões de usuários. A matriz não cabe inteiramente em uma máquina e a decomposição será muito longa.2. A maior parte do conteúdo do sistema tem uma vida útil curta: os documentos permanecem relevantes por apenas algumas horas. Portanto, é necessário construir sua representação vetorial o mais rápido possível.3. Se você criar a decomposição imediatamente após a publicação do documento, um número suficiente de usuários não terá tempo para avaliá-la. Portanto, é provável que sua representação vetorial não seja muito boa.4. Se o usuário gostar ou não, não poderemos levar isso imediatamente em consideração na expansão.Para resolver esses problemas, implementamos uma decomposição distribuída da matriz de documentos do usuário com uma atualização incremental frequente. Como exatamente isso funciona?Suponha que tenhamos um cluster de N máquinas (N nas centenas) e queremos fazer uma decomposição distribuída da matriz nelas, o que não cabe em uma máquina. A questão é como executar essa decomposição para que, por um lado, haja dados suficientes em cada máquina e, por outro, para que os cálculos sejam independentes?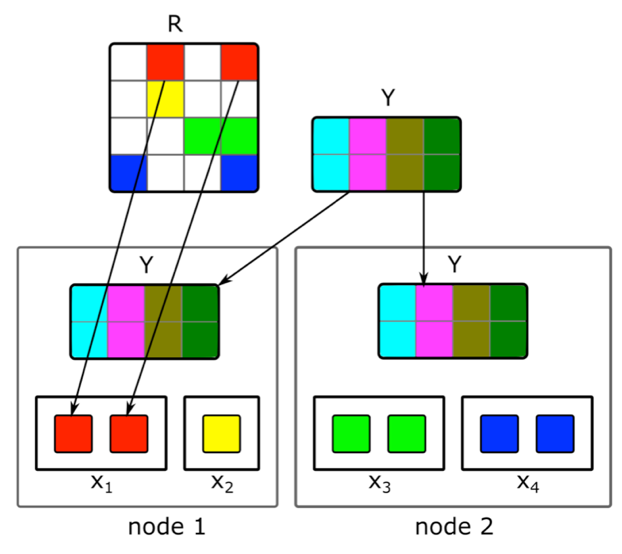 Usaremos o algoritmo de decomposição ALS descrito acima. Considere como executar uma etapa do ALS de maneira distribuída - o restante das etapas será semelhante. Suponha que temos uma matriz fixa de documentos e queremos criar uma matriz de usuários. Para fazer isso, dividimos em N partes em linhas, cada parte conterá aproximadamente o mesmo número de linhas. Enviaremos para cada máquina células não vazias das linhas correspondentes, bem como uma matriz de incorporação de documentos (no todo). Como não é muito grande, e a matriz de documentos do usuário geralmente é muito esparsa, esses dados cabem em uma máquina comum.Esse truque pode ser repetido por várias épocas até o modelo convergir, alterando alternadamente a matriz fixa. Mas, mesmo assim, a decomposição da matriz pode durar várias horas. E isso não resolve o problema da necessidade de receber rapidamente combinações de novos documentos e atualizar combinações daquelas sobre as quais havia pouca informação ao construir o modelo.A introdução de uma rápida atualização incremental do modelo nos ajudou. Suponha que tenhamos um modelo treinado atual. Desde seu treinamento, surgiram novos artigos com os quais nossos usuários interagiram, além de artigos que tiveram pouca interação com o treinamento. Para incorporar rapidamente esses artigos, usamos incorporações de usuários obtidas durante o primeiro grande treinamento do modelo e executamos uma etapa do ALS para calcular a matriz de documentos com uma matriz fixa de usuários. Isso permite que você receba casamentos rapidamente - alguns minutos após a publicação de um documento - e freqüentemente atualiza casamentos de novos documentos.Para considerar imediatamente as ações humanas de recomendações, em tempo de execução, não usamos incorporações de usuários recebidas offline. Em vez disso, seguimos a etapa do ALS e obtemos o vetor de usuário atual.
Usaremos o algoritmo de decomposição ALS descrito acima. Considere como executar uma etapa do ALS de maneira distribuída - o restante das etapas será semelhante. Suponha que temos uma matriz fixa de documentos e queremos criar uma matriz de usuários. Para fazer isso, dividimos em N partes em linhas, cada parte conterá aproximadamente o mesmo número de linhas. Enviaremos para cada máquina células não vazias das linhas correspondentes, bem como uma matriz de incorporação de documentos (no todo). Como não é muito grande, e a matriz de documentos do usuário geralmente é muito esparsa, esses dados cabem em uma máquina comum.Esse truque pode ser repetido por várias épocas até o modelo convergir, alterando alternadamente a matriz fixa. Mas, mesmo assim, a decomposição da matriz pode durar várias horas. E isso não resolve o problema da necessidade de receber rapidamente combinações de novos documentos e atualizar combinações daquelas sobre as quais havia pouca informação ao construir o modelo.A introdução de uma rápida atualização incremental do modelo nos ajudou. Suponha que tenhamos um modelo treinado atual. Desde seu treinamento, surgiram novos artigos com os quais nossos usuários interagiram, além de artigos que tiveram pouca interação com o treinamento. Para incorporar rapidamente esses artigos, usamos incorporações de usuários obtidas durante o primeiro grande treinamento do modelo e executamos uma etapa do ALS para calcular a matriz de documentos com uma matriz fixa de usuários. Isso permite que você receba casamentos rapidamente - alguns minutos após a publicação de um documento - e freqüentemente atualiza casamentos de novos documentos.Para considerar imediatamente as ações humanas de recomendações, em tempo de execução, não usamos incorporações de usuários recebidas offline. Em vez disso, seguimos a etapa do ALS e obtemos o vetor de usuário atual.Transferir para outra área de domínio
Como usar o feedback de um usuário em artigos de texto para criar uma representação vetorial de um vídeo?Inicialmente, recomendamos apenas artigos de texto; muitos de nossos algoritmos estão focados nesse tipo de conteúdo. Mas, ao adicionar conteúdo de um tipo diferente, fomos confrontados com a necessidade de adaptar modelos. Como resolvemos esse problema usando o vídeo de exemplo? Uma opção é treinar todos os modelos do zero. Mas isso é muito tempo, além disso, alguns dos algoritmos exigem o volume da amostra de treinamento, que ainda não está na quantidade certa para um novo tipo de conteúdo nos primeiros momentos de sua vida no serviço.Fomos para o outro lado e reutilizamos modelos de texto para o vídeo. Ao criar representações vetoriais do vídeo, o mesmo truque com o ALS nos ajudou. Fizemos uma representação vetorial de usuários com base em artigos de texto e seguimos a etapa do ALS usando informações sobre visualizações de vídeo. Então, conseguimos facilmente uma representação vetorial do vídeo. E em tempo de execução, simplesmente calculamos a proximidade entre o vetor de usuário obtido de artigos de texto e o vetor de vídeo.Conclusão
O desenvolvimento do núcleo de um sistema de recomendação em tempo real é repleto de muitas tarefas. É necessário processar rapidamente os dados e aplicar métodos de ML para usar efetivamente esses dados; Construa sistemas distribuídos complexos capazes de processar sinais do usuário e novas unidades de conteúdo em um período mínimo de tempo; e muitas outras tarefas.No sistema atual, cujo dispositivo descrevi, a qualidade das recomendações para o usuário aumenta com a atividade e a duração do serviço. Mas é claro, aqui está a principal dificuldade: é difícil para o sistema entender imediatamente os interesses de uma pessoa que pouco interagiu com o conteúdo. Melhorar as recomendações para novos usuários é nossa principal preocupação. Continuaremos a otimizar os algoritmos para que o conteúdo relevante para a pessoa entre no feed mais rapidamente e o irrelevante não apareça.