 Ilustração de melmagazine.com (Fonte: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Atualmente, redes públicas com canais que não estão protegidos contra o intruso são amplamente utilizadas para troca de informações. As mensagens nesses usuários conectados e em redes de computadores são forçadas a se proteger. Como o usuário não pode proteger os canais de mensagens, ele protege a mensagem.O que está protegido na mensagem? Em primeiro lugar, a sintaxe (integridade) para esse fim usacodificação(codificação e análise de códigos) e, em segundo lugar, a semântica (confidencialidade) para a qual acriptografia éusada(criptografia e análise criptográfica), em terceiro lugar, indiretamente, o infrator pode limitar a disponibilidade da mensagem, ocultando o fato de sua transmissão, que usa steganology (esteganografia e esteganálise).As possibilidades listadas são fornecidas teórica e praticamente em graus variados e, embora cada direção esteja em desenvolvimento há um longo tempo, elas ainda estão longe de serem completas. No presente trabalho, abordaremos apenas uma questão específica - a análise dos códigos de mensagens.
Ilustração de melmagazine.com (Fonte: melmagazine.com/wp-content/uploads/2019/11/DNA-1280x533.jpg )Atualmente, redes públicas com canais que não estão protegidos contra o intruso são amplamente utilizadas para troca de informações. As mensagens nesses usuários conectados e em redes de computadores são forçadas a se proteger. Como o usuário não pode proteger os canais de mensagens, ele protege a mensagem.O que está protegido na mensagem? Em primeiro lugar, a sintaxe (integridade) para esse fim usacodificação(codificação e análise de códigos) e, em segundo lugar, a semântica (confidencialidade) para a qual acriptografia éusada(criptografia e análise criptográfica), em terceiro lugar, indiretamente, o infrator pode limitar a disponibilidade da mensagem, ocultando o fato de sua transmissão, que usa steganology (esteganografia e esteganálise).As possibilidades listadas são fornecidas teórica e praticamente em graus variados e, embora cada direção esteja em desenvolvimento há um longo tempo, elas ainda estão longe de serem completas. No presente trabalho, abordaremos apenas uma questão específica - a análise dos códigos de mensagens.Introdução
O código genético (AH) foi escolhido como objeto de análise. Você pode se familiarizar com um exemplo curioso do uso do Código Civil no campo da segurança da informação (aparentemente não profissional e, portanto, sem êxito) aqui.Na teoria da codificação, duas direções importantes podem ser distinguidas: codificação da fonte de informação e codificação do canal. O primeiro deles é implementado, via de regra, pela parte transmissora e tem o objetivo de eliminar a redundância de mensagens (por exemplo, código Morse), o objetivo do segundo é detectar e eliminar erros nas mensagens. Antes do aparecimento dos códigos de correção, o problema de eliminar erros era resolvido pela retransmissão do fragmento distorcido da mensagem, a pedido do lado receptor.Aqui observamos o fato de que é impossível para o lado receptor descriptografar o cifragram corretamente se ocorrerem erros em seu texto. As cifras não permitem detectar erros, nem mesmo corrigi-los. Por esse motivo, no lado transmissor do sistema de comunicação, o cifragram da mensagem é codificado com um código de correção e, no lado receptor, o decodificador na mensagem recebida detecta (se houver) e corrige os erros.Depois disso, o sistema de criptografia entra em ação e o destinatário legítimo recebe uma mensagem descriptografada. Estes são, em termos gerais, o funcionamento das redes que trocam mensagens seguras.Neste trabalho, analisaremos detalhadamente o muito importante código genético, criado não pela mente humana, mas pela própria natureza (um caso raro).A história de uma descoberta e o prêmio Nobel
Perguntamo-nos como, no nível da genética e do metabolismo dos organismos (células), a natureza implementa essas disposições de troca de informações na vida das espécies e de seus representantes individuais?Antes da Segunda Guerra Mundial, o mundo científico sabia que nos organismos vivos a transmissão de características hereditárias de geração em geração é realizada através de unidades químicas (genes) relativamente simples, que incluem uma enorme quantidade de informações necessárias para continuar e reproduzir a vida.Todos os genes (não as proteínas) se ligam às cadeias (cromossomos) e se materializam no ácido desoxirribonucleico (DNA). Os especialistas não tinham clareza sobre como tudo acontece e como o próprio DNA está estruturado.Jovens pesquisadores, o físico inglês F. Crick e o biólogo americano J. Watson, em 1953 (25.4) publicaram na revista Nature o artigo "A estrutura do ácido desoxirribonucleico". No início de seu trabalho em 1949, James Watson tinha 23 anos, Francis Crick e Maurice Wilkins, 33.No artigo, os autores descreveram um modelo da estrutura espacial do DNA na forma de uma dupla hélice, duas vertentes torcidas para a direita. As próprias cadeias se mostraram conectadas por "degraus" transversais formados a partir de nucleotídeos.Definição . Os nucleotídeos são compostos constituídos por açúcar, bases contendo nitrogênio (purina ou pirimidina) e ácido fosfórico. Os nucleotídeos são os "blocos de construção" para DNA e RNA.
Essa hélice de DNA é portadora do código genético - o código de hereditariedade de características de organismos de animais e plantas. Este foi um novo trabalho completamente incomum sobre a estrutura e as propriedades de uma molécula de ácido desoxirribonucleico.O modelo de DNA de jovens autores foi confirmado comparando-o com um padrão de difração de raios X da estrutura cristalina do DNA do biofísico inglês Maurice Wilkins. Mais tarde, um código genético foi descoberto contendo e transmitindo informações sobre a síntese da estrutura e composição das proteínas - os principais componentes de cada célula de organismos vivos que implementam o ciclo celular.Definição . O ciclo celular é a alternância correta de períodos de descanso relativo com períodos de divisão celular.
No mesmo ano, os autores posteriormente publicaram outro artigo que descrevia um possível mecanismo para copiar DNA por síntese matricial na divisão de células vivas. A dupla hélice do DNA foi comparada a um "raio".Cada fio da espiral, depois de "desfazer a trava" e diluir os fios, tornou-se uma matriz sintetizadora e foi completado com um segundo fio de material do citoplasma da célula, de acordo com o princípio da complementaridade para completar o DNA. Ele também disse que uma certa sequência de bases (códons, trigêmeos) é um código que contém informações genéticas.A ideia de matematizar o código foi primeiramente expressa por G. Gamov em um artigo em 1954 como o problema de traduzir palavras de um alfabeto de quatro letras (sistema) em palavras de um alfabeto de vinte letras. Ele apresentou o problema de codificar os fenômenos da vida não como um bioquímico, mas como um problema matemático combinatório. Os esforços preliminares de longa duração dos autores deste trabalho estão bem descritos no livro de D. Watson, The Thread of Life.Em 1962, Watson, Crick e Wilkins receberam o Prêmio Nobel de Fisiologia ou Medicina "por descobertas na estrutura molecular dos ácidos nucléicos e por determinar seu papel na transferência de informações na matéria viva".Eles tinham informações sobre os seguintes fatos:- Em 1866, Gregor Mendel formulou as disposições que os "elementos", mais tarde chamados genes, determinam a herança das propriedades físicas dos indivíduos da espécie.
- , , () , , .
- 1869 . , . . () (). . 4- ( ): (), (), (G), (); (), (U) , (G), (), ( ) .
- , , – , .
- 1950 . , 4- .
- , , .
- , 20- , (), .
- 1944 « ? ». : « - , , ?».
- 1954 , () 4- 20- , , .
Os pesquisadores tiveram que dar o próximo passo, e foi dado.Não havia escassez de hipóteses e suposições, mas alguém tinha que verificar sua verdade.Códigos sobrepostos (uma letra nucleotídica faz parte de mais de um códon): triangular, maior-menor e seqüencial, proposto por Gamov e colegas;códigos não sobrepostos: combinação de Gamow e Ichas, o "código sem vírgula" de Scream, Griffith e Orgel. No código de combinação, os aminoácidos (20) são codificados por trigêmeos de 4 nucleotídeos, mas sua ordem não é importante, mas apenas sua composição: os trigêmeos TTA, TAT, ATT codificam o mesmo aminoácido nas proteínas.O código sem vírgula explica como o “quadro de leitura” é selecionado. Uma "janela deslizante" ao longo da cadeia de DNA, onde as letras se seguem, uma após a outra sem separadores (vírgulas) em palavras, sugere que as palavras são de alguma forma diferentes. De acordo com o modelo de F. Crick, foi feita uma suposição: todos os trigêmeos são divididos em significantes, isto é, correspondendo a aminoácidos específicos e sem significado.Se apenas trigêmeos significativos formam DNA, em outro "quadro de leitura", esses trigêmeos se tornarão sem sentido. Os autores deste código mostraram que é possível escolher trigêmeos que atendam a esses requisitos e que existem exatamente 20. Naturalmente, os autores não tinham total confiança em sua correção.De fato, após 1960, foi demonstrado que os códons, considerados por Crick sem sentido, realizavam a síntese protéica in vitro e, em 1965, foi estabelecido o significado de todos os 64 códons tripletos. Descobriu-se também que um número de aminoácidos é codificado por dois, três, quatro e até seis trigêmeos diferentes, ou seja, há uma certa redundância, cujo objetivo permanece a ser determinado.Código genético da vida. Informações herdadas
. – , ( , G, C, T), , . ( ) – . . .
Para codificar cada um dos 20 tipos de aminoácidos canônicos, a partir dos quais quase todas as proteínas são construídas e o sinal de parada terminal, é suficiente um conjunto de três nucleotídeos (letras) chamados trigêmeos (códon). A sequência de códons forma um gene na cadeia cromossômica e determina a sequência de aminoácidos na cadeia polipeptídica da proteína codificada por esse gene. Havia um conceito de "um gene - uma enzima".A apresentação clássica da informação (linearidade de sua gravação) é um texto em sentido amplo (fala, cartas, livros, imagens, filmes, música etc.) dessa palavra em alguma linguagem natural (EY). O idioma inclui um vocabulário extenso (vocabulário) e, se tiver um idioma escrito além do idioma falado, o alfabeto terá uma gramática.Para preservar as informações por um longo tempo e transferir cópias delas, é necessário um sistema de gravação e memória sólido e bem protegido. A informação hereditária dos organismos vivos é escrita pela AA da natureza em textos longos com palavras em um determinado alfabeto "molecular", que são armazenadas na forma de cromossomos nos núcleos de todas as células dos organismos vivos.Os processos e formas de transferência de informações registradas em suas moléculas transportadoras naturais são formulados por F. Crick (1958) na forma do dogma central da biologia molecular . Três processos principais fornecem controle de todos os outros processos do funcionamento celular e da vida dos organismos como um todo.Esses processos são: replicação , transcrição e tradução. Além disso, eles serão discutidos em mais detalhes. As informações nos organismos são transmitidas apenas em uma direção dos ácidos nucleicos (DNA → RNA → proteína) para uma proteína; a transmissão reversa não existe. Casos especiais de DNA → proteína, RNA → RNA, RNA → DNA são possíveis.A leitura de informações ao longo de cadeias moleculares é permitida apenas em uma direção direta. O termo "quadro de leitura" é usado.Definição . Um quadro de leitura (aberto) é uma sequência de códons não sobrepostos capazes de sintetizar uma proteína, começando com um códon de início e terminando com um códon de parada. O quadro é determinado pelo primeiro trigêmeo a partir do qual a transmissão começa.
Para iniciar a transmissão, um códon de início não é suficiente; você também precisa de um códon de iniciação (existem três deles: AUG, GUG, UUG). Após a leitura, a tradução ocorre pela leitura seqüencial dos códons do rRNA ribossômico e anexa os aminoácidos entre si pelo ribossomo até que o códon de parada seja atingido.Durante a tradução, os códons são sempre “lidos” a partir de algum símbolo de início de iniciação (AUG) e não se sobrepõem. A leitura após o início do trigêmeo após o trigêmeo vai para o códon de parada da conclusão da síntese da cadeia polipeptídica da proteína.Esses fatos estão resumidos em uma tabela de métodos para transmissão de informações genéticas.Tabela 1 - o dogma central da biologia molecular A história do estudo de textos da hereditariedade dos organismos, sua compreensão, uma longa e rica em descobertas, realizações, delírios e decepções. A lista de eventos na história da compreensão (cognição) dos textos da natureza é de interesse indiscutível, tanto para a ciência quanto para cada pessoa.As palavras dos textos são muito longas, mas o alfabeto para escrever “EYA nature” contém apenas quatro letras - estas são bases moleculares: no RNA é A (adenina), C (citosina), G (guanina), U (uracil) (no DNA, o uracil é substituído em T (timina)). A linguagem da vida selvagem é a linguagem das moléculas.Os biólogos estabeleceram que cada palavra do texto da hereditariedade é formada por uma molécula de DNA polimérico (ácido desoxirribonucleico, descoberta em 1868 pelo médico I.F. Misher), construída de 4 bases (nucleotídeos - nuclear - nuclear).As bases são unidas (conectadas) entre si em pares, A → → T, T → → A, G → → C, C → → G com ligações especiais de hidrogênio que implementam o princípio da complementaridade. Esses fatos foram estabelecidos em diferentes épocas, por diferentes cientistas e métodos de muitas ciências (física, química, biologia, citologia, genética etc.). Dificuldades na maneira de conhecer esse NJ encontravam-se constantemente.As moléculas de DNA não cristalizaram, mas quando isso foi feito, a tarefa de estabelecer a estrutura do DNA foi reduzida para resolver o problema inverso da análise de difração de raios X (transformação de Fourier do padrão de difração do cristal criado na tela pelos raios X).O modelo calculado e montado à mão por J. Watson e Francis Crick em 1953 é semelhante ao jogo infantil LEGO, onde os elementos eram bases moleculares e as distâncias interatômicas e ângulos de pivô eram mantidos com muita precisão, a estrutura cromossômica foi reproduzida em larga escala.Esse modelo praticamente confirmou as diversas hipóteses dos teóricos e comprovou de forma convincente a ausência de discrepâncias com experimentos práticos e os resultados da análise de difração de raios X do DNA cristalino.Os principais dados detalhados sobre a estrutura química do DNA e as características numéricas do modelo foram obtidos por Rosalinda Franklin e M. Wilkins no início de 1953 no laboratório de análise de raios-X. O conflito de cientistas é descrito no romance "Solidão na Rede", de Janusz Leon Wisniewski.A presença da estrutura visual do DNA e suas características quantitativas deram impulso ao desenvolvimento da genética e de todas as biociências, das quais surgiu a idéia do projeto Genoma Humano em 2000. Watson se tornou o primeiro líder desse projeto, o conjunto de cromossomos do Homo sapiens humano foi completamente decifrado no projeto. O mapa genético completo do 1º cromossomo foi concluído em 2006. O mapa contém 3141 genes e 991 pseudogenes.Do ponto de vista da matemática, quatro elementos do alfabeto podem ser atribuídos a quatro elementos de um campo Galois estendido finito GF (2 2 ) = ( 0, 1, α, β ), cujas operações são realizadas modulando o polinômio irredutível p (x) = x 2 + x + 1 . Então α + β = 1, α ∙ β = 1e o mapeamento dos elementos do campo para as letras assume a forma
A história do estudo de textos da hereditariedade dos organismos, sua compreensão, uma longa e rica em descobertas, realizações, delírios e decepções. A lista de eventos na história da compreensão (cognição) dos textos da natureza é de interesse indiscutível, tanto para a ciência quanto para cada pessoa.As palavras dos textos são muito longas, mas o alfabeto para escrever “EYA nature” contém apenas quatro letras - estas são bases moleculares: no RNA é A (adenina), C (citosina), G (guanina), U (uracil) (no DNA, o uracil é substituído em T (timina)). A linguagem da vida selvagem é a linguagem das moléculas.Os biólogos estabeleceram que cada palavra do texto da hereditariedade é formada por uma molécula de DNA polimérico (ácido desoxirribonucleico, descoberta em 1868 pelo médico I.F. Misher), construída de 4 bases (nucleotídeos - nuclear - nuclear).As bases são unidas (conectadas) entre si em pares, A → → T, T → → A, G → → C, C → → G com ligações especiais de hidrogênio que implementam o princípio da complementaridade. Esses fatos foram estabelecidos em diferentes épocas, por diferentes cientistas e métodos de muitas ciências (física, química, biologia, citologia, genética etc.). Dificuldades na maneira de conhecer esse NJ encontravam-se constantemente.As moléculas de DNA não cristalizaram, mas quando isso foi feito, a tarefa de estabelecer a estrutura do DNA foi reduzida para resolver o problema inverso da análise de difração de raios X (transformação de Fourier do padrão de difração do cristal criado na tela pelos raios X).O modelo calculado e montado à mão por J. Watson e Francis Crick em 1953 é semelhante ao jogo infantil LEGO, onde os elementos eram bases moleculares e as distâncias interatômicas e ângulos de pivô eram mantidos com muita precisão, a estrutura cromossômica foi reproduzida em larga escala.Esse modelo praticamente confirmou as diversas hipóteses dos teóricos e comprovou de forma convincente a ausência de discrepâncias com experimentos práticos e os resultados da análise de difração de raios X do DNA cristalino.Os principais dados detalhados sobre a estrutura química do DNA e as características numéricas do modelo foram obtidos por Rosalinda Franklin e M. Wilkins no início de 1953 no laboratório de análise de raios-X. O conflito de cientistas é descrito no romance "Solidão na Rede", de Janusz Leon Wisniewski.A presença da estrutura visual do DNA e suas características quantitativas deram impulso ao desenvolvimento da genética e de todas as biociências, das quais surgiu a idéia do projeto Genoma Humano em 2000. Watson se tornou o primeiro líder desse projeto, o conjunto de cromossomos do Homo sapiens humano foi completamente decifrado no projeto. O mapa genético completo do 1º cromossomo foi concluído em 2006. O mapa contém 3141 genes e 991 pseudogenes.Do ponto de vista da matemática, quatro elementos do alfabeto podem ser atribuídos a quatro elementos de um campo Galois estendido finito GF (2 2 ) = ( 0, 1, α, β ), cujas operações são realizadas modulando o polinômio irredutível p (x) = x 2 + x + 1 . Então α + β = 1, α ∙ β = 1e o mapeamento dos elementos do campo para as letras assume a forma , e o nucleotídeo adicional (complementar) é calculado de acordo com a regra ¬ → x + 1 , de onde T → A + 1, C → G + 1.Estruturalmente, o modelo de DNA representa duas cadeias poliméricas equidistantes de nucleotídeos conectados em pares (por o princípio de uma escada de corda) e torceu em uma espiral dupla direita. Abaixo no texto, pares de letras escritos verticalmente correspondem aos degraus da "escada":T A GGTTCG T ...
, e o nucleotídeo adicional (complementar) é calculado de acordo com a regra ¬ → x + 1 , de onde T → A + 1, C → G + 1.Estruturalmente, o modelo de DNA representa duas cadeias poliméricas equidistantes de nucleotídeos conectados em pares (por o princípio de uma escada de corda) e torceu em uma espiral dupla direita. Abaixo no texto, pares de letras escritos verticalmente correspondem aos degraus da "escada":T A GGTTCG T ...
ATCCAAGCA ...Duas cadeias repetem a sequência de letras, mas o início de uma fica no lado oposto à outra. As informações nas moléculas de DNA são registradas com um alto grau de redundância, o que, é claro, fornece um alto nível de confiabilidade ao ler e copiá-las (replicação: DNA → DNA). Mais uma palavra é atribuída à palavra original, mas em código adicional.Todos os cromossomos contêm genes em sua composição e estão contidos em cada célula em um volume muito pequeno (no núcleo da célula) e são curtos e muito longos. A distância entre as cadeias de DNA é de 2 nm, entre os "passos" - 0,31 nm, uma revolução completa da "hélice" a cada 10 pares. O comprimento total de todo o DNA esticado em uma fita atinge 2 m. A informação hereditária humana é registrada em 23 cromossomos. O comprimento do cromossomo é de cerca de 10 9nucleotídeos, e o diâmetro do núcleo é menor que um micrômetro. Assim, o DNA na célula é compactado.Definição . Gene (grego.γενοζ - gênero). A unidade estrutural e funcional da hereditariedade dos organismos vivos. Os genes (mais precisamente os alelos) determinam os traços hereditários dos organismos transmitidos dos pais aos filhos durante a reprodução.
Nas palavras do DNA, é possível isolar e considerar sub-partes (genes) individuais que carregam informações integrais sobre a estrutura de uma molécula de proteína ou de uma molécula de RNA. Além disso, os genes são caracterizados por sequências reguladoras (promotores).Os promotores podem ser localizados tanto nas proximidades de um quadro de leitura aberto que codifica uma proteína quanto no início de uma sequência de RNA e a uma distância de muitos milhões de pares de bases (nucleotídeos), por exemplo, em casos com intensificadores, isoladores e supressores.Cada gene é projetado e responsável pela criação de uma proteína específica necessária para a vida do corpo. O conceito de genótipo denota a constituição hereditária de gametas (células germinativas) e zigotos (células somáticas), em contraste com o fenótipo que descreve caracteres adquiridos que não são herdados.Códigos de bloco
Código é um conceito com vários valores. Primeiro de tudo, um código pode ser chamado de um conjunto de palavras que formam o próprio código. São essas palavras que o decodificador reconhece no lado receptor quando transmite mensagens e, no lado transmissor, o codificador as forma.Ao gerar palavras de código, é usado um mapeamento exclusivo de um conjunto finito de caracteres ordenados pertencentes a um determinado alfabeto finito para outro, não necessariamente ordenado, geralmente um conjunto mais amplo de caracteres para codificar a transmissão, armazenamento ou transformação de informações.Listamosas propriedades do código genético em consideração:- . . in Vitro ( ). () () .
- . , .
- . . ( ) – , , .
. . 4- , , 20 , , ( ) .
, (), 4; 2- (), 42 =16 ; () 43 = 64 > 20 . .
- . . , -, , - . .
. 64 1965 . , . , (). .
2 —

20 61 , . , . AUG – .
. . AGC, GCU, CUA,… , . , . .
- . - .
, . ( ) ( ) .
- . - , . : AUG ( ) , – .
- . . . 1961 . .
- – ;
- – ( ) .
Considere dois conjuntos discretos X e n contendo respectivamente | X | e | n elementos e mapeamento φ : n → X . Ao representar mapeamentos arbitrários de conjuntos com palavras no alfabeto X, obtemos um conjunto de X n palavras, cada um com n caracteres de comprimento a partir de q = | X | disponível, que formam o alfabeto das mensagens de texto. É conveniente organizar todas as palavras X n em ordem lexicográfica em uma lista geral.Nosso objetivo nesta parte do trabalho é gerar um código que forneça codificação (conversão) dos dados transmitidos em um formato conveniente para transmissão no espaço e no tempo e transmissão (tradução) de um idioma para outro, compreensível para o destinatário da mensagem.Gerar um código envolve escolher o alfabeto, determinar a regularidade e, ao escolher um código regular, determinar o comprimento da palavra-código, determinar o número de palavras-código, determinar a composição letra por palavra de cada palavra.Tabela 3 - O código genético consiste em 64 palavras de código de 3 letras cada, Tabela 4 - Valores inversos da sequência de código dos trigêmeos de RNA
Tabela 4 - Valores inversos da sequência de código dos trigêmeos de RNA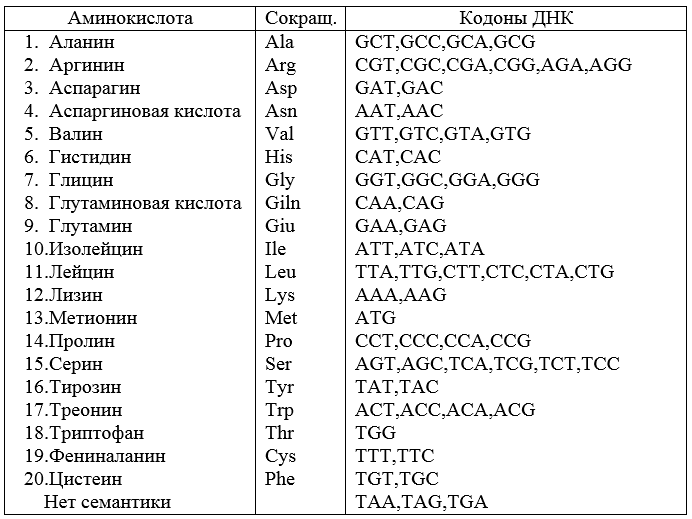 Propriedades adicionais do código, por exemplo, o código não deve ter vírgula, são determinadas por requisitos mais rigorosos para os parâmetros de código nomeado. Um código sem vírgula deve ter palavras com um período máximo. Tais requisitos estão focados na conveniência da síntese subsequente do codec. Intimamente relacionados a essas provisões de síntese de código estão os problemas de codificação da informação e sua decodificação.
Propriedades adicionais do código, por exemplo, o código não deve ter vírgula, são determinadas por requisitos mais rigorosos para os parâmetros de código nomeado. Um código sem vírgula deve ter palavras com um período máximo. Tais requisitos estão focados na conveniência da síntese subsequente do codec. Intimamente relacionados a essas provisões de síntese de código estão os problemas de codificação da informação e sua decodificação.Análise de código
A tarefa de análise de código parece completamente diferente quando o código já existe e é usado, mas pouco se sabe sobre ele. As mensagens codificadas estão disponíveis para visualização e estudo, mas são tão diversas e numerosas que o princípio de sua criação não é visível, mesmo com uma análise muito extensa.Na verdade, o próprio sistema de codificação também está disponível para observação e estudo, mas o nível de complexidade de sua construção e funcionamento não permite obter uma descrição qualitativa e confiável completa.Informação (dados) é uma mensagem, ou seja, uma cadeia de caracteres do alfabeto, que em alguma posição inicial pode ser dividida em segmentos (blocos) de comprimento n caracteres, e cada um desses segmentos é uma palavra de código. O código neste caso é bloco.No lado de recebimento do canal de mensagens, o destinatário deve poder dividir corretamente a sequência contínua de caracteres da mensagem em palavras separadas. O uso de delimitadores de palavras (vírgulas) é indesejável, pois requer recursos.Sincronização . Sem sincronização, a tradução correta da mensagem é impossível. Isso implica em um dos requisitos para o código gerado - o código deve ser projetado para que a sincronização seja fornecida exclusivamente pelos meios (propriedades) do próprio código e do dispositivo de recebimento de informações.Definição . O processo de estabelecer uma posição contendo o caractere inicial (inicial) de uma palavra de código é chamado de sincronização.
O problema de sincronização é resolvido simplesmente se o alfabeto usar um caractere separador de palavras especial, por exemplo, uma vírgula. O quadro de leitura da próxima palavra de código é definido imediatamente após o separador.
Esse separador é conveniente, mas indesejável por várias razões.- Em primeiro lugar, o código deve ser tal que, no ponto de chegada da mensagem, tenha exatamente a mesma forma que no ponto de partida (garantindo integridade);
- Em segundo lugar, o tempo de codificação, decodificação e duração da transmissão deve ser o mais curto possível, pois isso reduz a possibilidade de distorcer as influências ambientais no texto da mensagem;
- Em terceiro lugar, é desejável ter uma pequena quantidade de portador de mensagem, pois requer menos armazenamento, proteção e outros recursos.
Para melhor distinguibilidade das palavras de código, elas devem ser removidas umas das outras por uma certa distância na lista completa de palavras possíveis, ou seja, diferem na composição dos significados dos símbolos, pois os vetores do espaço vetorial são componentes.Portanto, as palavras de código podem não ser todas e nem todas as palavras do conjunto X n , mas apenas um subconjunto delas D є X n . A escolha da composição simbólica das palavras de código representa a principal tarefa de sua formação, pois é a composição das palavras de código que deve garantir a satisfação dos requisitos formulados para o código. Assim, consideraremos ainda o código sem vírgula.. , . = (1, 2, …, n) = (1, 2, …, n). || = (1, 2, …, n, 1, 2, …, n). n – 1 n n . .
. (2, …, n, 1), (3, …, n, 1, 2)…( n, 1,…, n-2, n-1), .
Se todas as sobreposições na concatenação para qualquer par de palavras de código não forem palavras de código, o mecanismo do lado receptor (decodificador) do canal de transmissão de informações poderá definir uma posição inicial exclusiva. Isso é possível se o decodificador da lista D tiver todas as palavras de código e a possibilidade de combiná-las com os caracteres n lidos da mensagem recebida.Mostramos como isso é feito. Deixe um símbolo ser selecionado e corrigido na sequência de caracteres recebida. Tendo contado n caracteres do fixo, o decodificador compara a palavra que saiu com as palavras da lista de códigos. Se houver uma correspondência com uma das palavras na lista de códigos, a sincronização será estabelecida. O símbolo fixo e sua posição estão iniciando.Se não houver correspondência com nenhuma das palavras da lista de códigos, ou seja, pressione a palavra sobreposta, isso significa que a posição inicial está localizada à esquerda da posição fixa.Movemos para a esquerda uma posição da fixa e repetimos as ações da etapa anterior até chegarmos a uma etapa em uma correspondência com uma das palavras de código. Esse processo necessariamente tem uma conclusão bem-sucedida na posição inicial correta, ou seja, a sincronização é estabelecida em média para o número de n / 2 etapas.. () D є n n , , єD .
Já estabelecemos que esse código garante a sincronização correta em longas cadeias de palavras de código sem separadores entre elas. Quais palavras do conjunto X n estão incluídas no subconjunto D є X n ? Se a cardinalidade do conjunto X n é dividida por números inteiros, a cardinalidade D pode ser um desses divisores (o teorema do grupo Lagrange) e o código é chamado de código de bloco de grupo sem ponto decimal ., , D. , D n ( n D), . , D.
Vamos passar à questão do número de palavras no código gerado.O poder do código está sem vírgula. Encontraremos o maior número possível de palavras no código D , que denotamos por | D = W n ( q) . Não é possível obter o significado exato, mas uma estimativa superior para o número de palavras pode ser obtida usando o conceito de período de palavras. Denote por T k x o deslocamento cíclico de uma palavra de comprimento n por k passos, k < n .. d ( ) k, k = d ≤ n, d | n. d = n (). .
, = (1, 2, 3, 1, 2, 3 ) d < n. || . || = (1, 2, 3 ; 1, 2, 3 , 1, 2, 3 ; 1, 2, 3). , (;) , . , n.
n(q) q . D Wn(q) ≤ n(q)/n .


 Assim, para os dados de origem do exemplo 1, de um conjunto de 64 palavras arbitrárias com um comprimento de 3 caracteres, você pode criar um código contendo 20 palavras e fornecer sincronização. Este código não está isento de falhas. Se um erro for introduzido em uma das palavras em um único caractere, o código não será sincronizado. Em outras palavras, o código é instável contra erros.O exemplo numérico dado pode ser usado para ilustrar e explicar o código genético dos organismos vivos, que foi criado pela natureza em um longo caminho de evolução e completamente decifrado pela ciência moderna em 1966. Está estabelecido que o código genético não se sobrepõe e o significado (interpretação) de cada códon é revelado.A mesa final é a seguinte (Fig. 2).Segue da tabela que o código é degenerado. Isso significa a existência de sinônimos no código, por exemplo, GUU = GUC = Val, CGG = AGA = Arg , etc. Três códons UAA, UAG, UGA não possuem sentido. Estes são códons de terminação; a aparência de qualquer um deles em uma sequência de caracteres significa o fim da tradução (transmissão). Um organismo morre se, como resultado de um erro, a letra do códon semântico for alterada para um códon de terminação.Tais mudanças são possíveis e são chamadas de mutações.
Assim, para os dados de origem do exemplo 1, de um conjunto de 64 palavras arbitrárias com um comprimento de 3 caracteres, você pode criar um código contendo 20 palavras e fornecer sincronização. Este código não está isento de falhas. Se um erro for introduzido em uma das palavras em um único caractere, o código não será sincronizado. Em outras palavras, o código é instável contra erros.O exemplo numérico dado pode ser usado para ilustrar e explicar o código genético dos organismos vivos, que foi criado pela natureza em um longo caminho de evolução e completamente decifrado pela ciência moderna em 1966. Está estabelecido que o código genético não se sobrepõe e o significado (interpretação) de cada códon é revelado.A mesa final é a seguinte (Fig. 2).Segue da tabela que o código é degenerado. Isso significa a existência de sinônimos no código, por exemplo, GUU = GUC = Val, CGG = AGA = Arg , etc. Três códons UAA, UAG, UGA não possuem sentido. Estes são códons de terminação; a aparência de qualquer um deles em uma sequência de caracteres significa o fim da tradução (transmissão). Um organismo morre se, como resultado de um erro, a letra do códon semântico for alterada para um códon de terminação.Tais mudanças são possíveis e são chamadas de mutações.Definição . Mutações são mudanças relativamente estáveis na substância hereditária.
Cada cromossomo contém os genes x1, x2, ..., xn , que formam uma característica complexa X do corpo. Um par de cromossomos em uma célula obtida pela fusão de células germinativas paternas e maternas é formado durante a reprodução: um cromossomo é obtido do pai e outro da mãe (par diplóide de cromossomos).Nos cromossomos homólogos, todos os genes coincidem em sua função, mas podem diferir em vários nucleotídeos. Tais diferenças geralmente resultam de mutações, que podem ser causadas por produtos químicos, radiação, exposição radioativa, temperatura e radiação ionizante.As doenças hereditárias são causadas por mutações semelhantes, fixadas no conjunto cromossômico de células germinativas de um dos pais. Um exemplo conhecido de um gene humano que codifica hemoglobina. Ao substituir a letra T pela letra A , uma forma alternativa de hemoglobina aparece em uma posição do gene. Isso se manifesta em uma doença chamada anemia falciforme.Quando o valor da característica coincide nos dois cromossomos homólogos, o indivíduo é chamado de homozigoto para esse gene. Em outros casos, ocorre heterozigosidade. A homozigose é caracterizada por pares diplóides do tipo a) e heterozigose por pares do tipo b) (Fig. 3) Figura 3 - pares diplóides de homozigotos e heterozigotosEm vez de um par diplóide , são formados quatro cromossomos homólogos A, A, a, ae eles são distribuídos igualmente entre os quatro gametas formados. Cada gameta também recebe um dos cromossomos B, B, b, b, correspondendo a uma característica complexa. Essa distribuição ocorre para os cromossomos independentemente entre quatro gametas e entre caracteres diferentes. Esses fatos foram estabelecidos por Mendel e em 1865 ele publicou.A característica mais impressionante do código genético é sua versatilidade. O esquema dado (Fig. 1) pode ser usado com sucesso para decodificar o RNA de animais e plantas. Em 1979, os resultados apareceram no código genético mitocondrial, que difere dos valores de alguns códons na tabela e com outras regras de reconhecimento de códons.A tradução é realizada pelo ribossomo - um órgão especial da célula. A sincronização (configuração do quadro de leitura) é realizada usando o prefixo AGGAGGU , que é chamado de sequência Shine-Dolgarno. Esta sequência purina está presente na palavra no singular, e a probabilidade de sua distorção é pequena. Mas se ocorrer distorção, o corpo estará em desastre.Figura 1 - Correspondência de palavras de código com aminoácidos Figura 2 - DNA, mRNA e hélice protéica A
Figura 3 - pares diplóides de homozigotos e heterozigotosEm vez de um par diplóide , são formados quatro cromossomos homólogos A, A, a, ae eles são distribuídos igualmente entre os quatro gametas formados. Cada gameta também recebe um dos cromossomos B, B, b, b, correspondendo a uma característica complexa. Essa distribuição ocorre para os cromossomos independentemente entre quatro gametas e entre caracteres diferentes. Esses fatos foram estabelecidos por Mendel e em 1865 ele publicou.A característica mais impressionante do código genético é sua versatilidade. O esquema dado (Fig. 1) pode ser usado com sucesso para decodificar o RNA de animais e plantas. Em 1979, os resultados apareceram no código genético mitocondrial, que difere dos valores de alguns códons na tabela e com outras regras de reconhecimento de códons.A tradução é realizada pelo ribossomo - um órgão especial da célula. A sincronização (configuração do quadro de leitura) é realizada usando o prefixo AGGAGGU , que é chamado de sequência Shine-Dolgarno. Esta sequência purina está presente na palavra no singular, e a probabilidade de sua distorção é pequena. Mas se ocorrer distorção, o corpo estará em desastre.Figura 1 - Correspondência de palavras de código com aminoácidos Figura 2 - DNA, mRNA e hélice protéica A Figura 2 mostra como a sequência de aminoácidos em uma molécula de proteína é codificada por uma sequência de códons em uma molécula de DNA. Aqui, o mRNA da matriz é uma molécula intermediária. Suas cadeias divergem de acordo com o princípio do “zíper”, no qual o papel da fechadura é desempenhado por uma enzima que quebra a molécula através de ligações de hidrogênio.Nas células, o código genético é realizado por três processos matriciais: replicação (ocorre no núcleo), transcrição e tradução .A transcrição (gravação em letras do DNA → mRNA) é um processo biológico em células eucarióticas que ocorre no núcleo celular (separado por uma membrana nuclear do citoplasma) e é uma síntese de moléculas de RNA i nas seções correspondentes do DNA. A sequência nucleotídica do DNA é "reescrita" na mesma sequência de RNA.A tradução (leitura e tradução de RNA → proteína) é um processo biológico em células procarióticas combinado com o processo de transcrição, ocorre no citoplasma celular, nos ribossomos; a sequência de nucleotídeos de mRNA é transportada do núcleo, traduzida na sequência de aminoácidos (síntese da cadeia polipeptídica na matriz de mRNA): essa etapa prossegue com a participação do RNA de transporte (tRNA) e das enzimas correspondentes.Assim, a tradução é uma síntese de proteínas pelo ribossomo com base nas informações registradas no mRNA da matriz. Para obter 20 aminoácidos, bem como um sinal de parada, significando o fim de uma sequência proteica, são suficientes três nucleotídeos consecutivos, chamados tripletos.Os organismos vivos são distribuídos entre plantas e animais por espécie.
Figura 2 mostra como a sequência de aminoácidos em uma molécula de proteína é codificada por uma sequência de códons em uma molécula de DNA. Aqui, o mRNA da matriz é uma molécula intermediária. Suas cadeias divergem de acordo com o princípio do “zíper”, no qual o papel da fechadura é desempenhado por uma enzima que quebra a molécula através de ligações de hidrogênio.Nas células, o código genético é realizado por três processos matriciais: replicação (ocorre no núcleo), transcrição e tradução .A transcrição (gravação em letras do DNA → mRNA) é um processo biológico em células eucarióticas que ocorre no núcleo celular (separado por uma membrana nuclear do citoplasma) e é uma síntese de moléculas de RNA i nas seções correspondentes do DNA. A sequência nucleotídica do DNA é "reescrita" na mesma sequência de RNA.A tradução (leitura e tradução de RNA → proteína) é um processo biológico em células procarióticas combinado com o processo de transcrição, ocorre no citoplasma celular, nos ribossomos; a sequência de nucleotídeos de mRNA é transportada do núcleo, traduzida na sequência de aminoácidos (síntese da cadeia polipeptídica na matriz de mRNA): essa etapa prossegue com a participação do RNA de transporte (tRNA) e das enzimas correspondentes.Assim, a tradução é uma síntese de proteínas pelo ribossomo com base nas informações registradas no mRNA da matriz. Para obter 20 aminoácidos, bem como um sinal de parada, significando o fim de uma sequência proteica, são suficientes três nucleotídeos consecutivos, chamados tripletos.Os organismos vivos são distribuídos entre plantas e animais por espécie.. – , . , , .
A divisão celular é de dois tipos: um para a formação de células somáticas (células do corpo) e outro para a formação de células germinativas (gametas). O tipo de organismo é determinado pela presença, número e composição dos cromossomos nas células dos organismos que são inalteradas (constantes). O crescimento e desenvolvimento normais do corpo são garantidos pela formação e crescimento de células somáticas como resultado da mitose. Durante a mitose, todos os cromossomos localizados no núcleo celular dobram antes do início da divisão celular (replicação do DNA) e são distribuídos igualmente entre duas células filhas. O conjunto de cromossomos 2n2c em cada célula somática é exatamente o mesmo. A mitose mantém um número diplóide constante de cromossomos nas células.Outro processo de meiose é a formação de gametas, necessários para a continuação do gênero de organismos. Na meiose, cada célula se divide duas vezes e o número de cromossomos dobra uma vez. A meiose leva à formação de células diplóides com gametas haplóides com um conjunto de n2c . Com a fertilização subsequente, os gametas formam um organismo de nova geração com um cariótipo diplóide (nc + nc = 2n2c) .Este mecanismo é realizado em todas as espécies que se reproduzem sexualmente. A meiose garante a constância dos conjuntos cromossômicos (cariótipos) - hereditariedade e a criação de novas combinações de genes paternos e maternos com variação genotípica.O trabalho proposto abre a possibilidade de usar o código genético para resolver as tarefas de proteção da informação. Uma correta compreensão do fenômeno da natureza e de seu uso só é possível com o esforço do pesquisador, que não é impedido por dificuldades no caminho do profundo conhecimento da natureza que nos cerca e de suas manifestações.
O crescimento e desenvolvimento normais do corpo são garantidos pela formação e crescimento de células somáticas como resultado da mitose. Durante a mitose, todos os cromossomos localizados no núcleo celular dobram antes do início da divisão celular (replicação do DNA) e são distribuídos igualmente entre duas células filhas. O conjunto de cromossomos 2n2c em cada célula somática é exatamente o mesmo. A mitose mantém um número diplóide constante de cromossomos nas células.Outro processo de meiose é a formação de gametas, necessários para a continuação do gênero de organismos. Na meiose, cada célula se divide duas vezes e o número de cromossomos dobra uma vez. A meiose leva à formação de células diplóides com gametas haplóides com um conjunto de n2c . Com a fertilização subsequente, os gametas formam um organismo de nova geração com um cariótipo diplóide (nc + nc = 2n2c) .Este mecanismo é realizado em todas as espécies que se reproduzem sexualmente. A meiose garante a constância dos conjuntos cromossômicos (cariótipos) - hereditariedade e a criação de novas combinações de genes paternos e maternos com variação genotípica.O trabalho proposto abre a possibilidade de usar o código genético para resolver as tarefas de proteção da informação. Uma correta compreensão do fenômeno da natureza e de seu uso só é possível com o esforço do pesquisador, que não é impedido por dificuldades no caminho do profundo conhecimento da natureza que nos cerca e de suas manifestações.