Uma condição típica para implementar o CI / CD no Kubernetes: um aplicativo deve poder parar de aceitar novas solicitações de clientes antes de parar e, o mais importante, concluir com êxito as existentes. A conformidade com essa condição permite atingir zero tempo de inatividade durante a implantação. No entanto, mesmo ao usar pacotes muito populares (como NGINX e PHP-FPM), você pode encontrar dificuldades que levarão a um aumento de erros a cada implantação ...
A conformidade com essa condição permite atingir zero tempo de inatividade durante a implantação. No entanto, mesmo ao usar pacotes muito populares (como NGINX e PHP-FPM), você pode encontrar dificuldades que levarão a um aumento de erros a cada implantação ...Teoria. Como o pod vive
Já publicamos este artigo em detalhes sobre o ciclo de vida do pod . No contexto deste tópico, estamos interessados no seguinte: no momento em que o pod entra no estado Terminating , novas solicitações deixam de ser enviadas a ele (o pod é removido da lista de pontos de extremidade do serviço). Assim, para evitar o tempo de inatividade durante a implantação, por nossa parte, basta resolver o problema do aplicativo parar corretamente.Também deve ser lembrado que o período de carência é de 30 segundos por padrão : depois disso, o pod será encerrado e o aplicativo deverá conseguir processar todas as solicitações antes desse período. Nota: embora qualquer solicitação executada por mais de 5 a 10 segundos já seja problemática e o desligamento normal não o ajudará mais ...Para entender melhor o que acontece quando o pod termina seu trabalho, basta estudar o seguinte esquema: A1, B1 - Obtendo alterações sobre estado do sub
A1, B1 - Obtendo alterações sobre estado do sub
A2: Enviando o SIGTERM
B2 - Removendo o pod dos endpoints
B3 - Obtendo alterações (a lista de endpoints foi alterada)
B4 - Atualizando as regras do iptablesNota: a remoção do pod do endpoint e o envio do SIGTERM não ocorrem sequencialmente, mas em paralelo. E devido ao fato do Ingress não receber uma lista atualizada de pontos de extremidade imediatamente, novas solicitações dos clientes serão enviadas ao pod, o que causará 500 erros durante o término do pod( traduzimos material mais detalhado sobre esse assunto ) . Você precisa resolver esse problema das seguintes maneiras:- Envie os cabeçalhos da conexão: resposta próxima (se se tratar de um aplicativo HTTP).
- Se não houver maneira de fazer alterações no código, o artigo descreve uma solução que permitirá processar solicitações até o final do período normal.
Teoria. Como NGINX e PHP-FPM terminam seus processos
Nginx
Vamos começar com o NGINX, pois tudo é mais ou menos óbvio. Imersos na teoria, aprendemos que o NGINX possui um processo mestre e vários "trabalhadores" - esses são processos filhos que processam solicitações de clientes. É fornecido um recurso conveniente: usando o comando para nginx -s <SIGNAL>finalizar processos no modo de desligamento rápido ou no desligamento normal. Obviamente, estamos interessados precisamente na última opção.Então tudo é simples: você precisa adicionar um comando ao gancho preStop que enviará um sinal sobre o desligamento normal . Isso pode ser feito em Implantação, no bloco de contêiner: lifecycle:
preStop:
exec:
command:
- /usr/sbin/nginx
- -s
- quit
Agora, no momento em que o pod concluir seu trabalho nos logs do contêiner NGINX, veremos o seguinte:2018/01/25 13:58:31 [notice] 1#1: signal 3 (SIGQUIT) received, shutting down
2018/01/25 13:58:31 [notice] 11#11: gracefully shutting down
E isso significará o que precisamos: o NGINX aguarda a conclusão das consultas e depois encerra o processo. No entanto, um problema comum será discutido abaixo, pelo qual, mesmo se houver um comando, o nginx -s quitprocesso não será concluído corretamente.E, nesse estágio, concluímos o NGINX: pelo menos você pode entender pelos registros que tudo funciona como deveria.E o PHP-FPM? Como ele lida com o desligamento normal? Vamos acertar.PHP-FPM
No caso do PHP-FPM, um pouco menos de informação. Se você se concentrar no manual oficial do PHP-FPM, ele informará que os seguintes sinais POSIX são recebidos:SIGINT, SIGTERM- desligamento rápido;SIGQUIT - desligamento normal (o que precisamos).
O restante dos sinais neste problema não é necessário, portanto, sua análise é omitida. Para concluir o processo corretamente, você precisará escrever o seguinte gancho preStop: lifecycle:
preStop:
exec:
command:
- /bin/kill
- -SIGQUIT
- "1"
À primeira vista, é tudo o que é necessário para executar um desligamento normal nos dois contêineres. No entanto, a tarefa é mais complicada do que parece. Em seguida, examinamos dois casos em que o desligamento normal não funcionou e causou uma inacessibilidade a curto prazo do projeto durante a implantação.Prática. Possíveis problemas com o desligamento normal
Nginx
Antes de tudo, é útil lembrar: além de executar o comando, nginx -s quithá outra etapa na qual você deve prestar atenção. Ocorreu um problema quando o NGINX, em vez de um sinal SIGQUIT, enviou o SIGTERM de qualquer maneira, devido ao qual as solicitações não foram concluídas corretamente. Casos semelhantes podem ser encontrados, por exemplo, aqui . Infelizmente, não foi possível estabelecer um motivo específico para esse comportamento: havia uma suspeita da versão do NGINX, mas ela não foi confirmada. A sintomatologia foi que, nos logs do contêiner NGINX, foram observadas as mensagens “soquete aberto nº 10 deixado na conexão 5” , após o que o pod parou.Podemos observar esse problema, por exemplo, pelas respostas necessárias ao Ingress: Indicadores de código de status no momento da implantaçãoNesse caso, obtemos apenas o código de erro 503 do próprio Ingress: ele não pode acessar o contêiner NGINX, pois não está mais disponível. Se você observar os logs do contêiner com NGINX, eles conterão o seguinte:
Indicadores de código de status no momento da implantaçãoNesse caso, obtemos apenas o código de erro 503 do próprio Ingress: ele não pode acessar o contêiner NGINX, pois não está mais disponível. Se você observar os logs do contêiner com NGINX, eles conterão o seguinte:[alert] 13939#0: *154 open socket #3 left in connection 16
[alert] 13939#0: *168 open socket #6 left in connection 13
Após alterar o sinal de parada, o contêiner começa a parar corretamente: isso é confirmado pelo fato de que um erro 503 não é mais observado.Se você encontrar um problema semelhante, faz sentido descobrir qual sinal de parada é usado no contêiner e qual a aparência exata do gancho preStop. É possível que a razão esteja exatamente nisso.PHP-FPM ... e mais
O problema com o PHP-FPM é descrito trivialmente: ele não espera a conclusão dos processos filhos, os encerra, por causa dos quais existem 502 erros durante a implantação e outras operações. Desde 2005, existem várias mensagens de erro no bugs.php.net (por exemplo, aqui e aqui ) que descrevem esse problema. Mas você provavelmente não verá nada nos logs: o PHP-FPM anunciará a conclusão do processo sem erros ou notificações de terceiros.Vale esclarecer que o problema em si pode, em menor ou maior grau, depender do próprio aplicativo e pode não aparecer, por exemplo, no monitoramento. Se você ainda o encontrar, uma solução simples será lembrada: adicione um gancho preStop comsleep(30). Ele permitirá que você conclua todas as solicitações anteriores (não aceitamos novas, pois o pod já está no estado de término ) e, após 30 segundos, o pod terminará com um sinal SIGTERM.Acontece que, lifecyclepara o contêiner, será assim: lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "30"
No entanto, devido à 30-segunda indicação, sleepque vai significativamente aumentar o tempo de implantação, uma vez que cada cápsula irá ser encerrado por , pelo menos, 30 segundos, o que é má. O que pode ser feito com isso?Vamos recorrer à parte responsável pela execução direta do aplicativo. No nosso caso, esse é o PHP-FPM , que por padrão não monitora a execução de seus processos filhos : o processo mestre é encerrado imediatamente. Esse comportamento pode ser alterado usando uma diretiva process_control_timeoutque especifica os prazos para a espera de sinais do mestre pelos processos filho. Se você definir o valor para 20 segundos, isso abrangerá a maioria das solicitações em execução no contêiner e, após a conclusão, o processo principal será interrompido.Com esse conhecimento, retornaremos ao nosso último problema. Como já mencionado, o Kubernetes não é uma plataforma monolítica: leva algum tempo para a interação entre seus vários componentes. Isso é especialmente verdadeiro quando consideramos o trabalho do Ingresss e outros componentes relacionados, porque, devido a esse atraso no momento da implantação, é fácil obter uma explosão de 500 erros. Por exemplo, um erro pode ocorrer no estágio de envio de uma solicitação para o upstream, mas o “intervalo de tempo” da interação entre os componentes é bastante curto - menos de um segundo.Portanto, em conjunto com a diretiva já mencionada process_control_timeout, a seguinte construção pode ser usada para lifecycle:lifecycle:
preStop:
exec:
command: ["/bin/bash","-c","/bin/sleep 1; kill -QUIT 1"]
Neste caso, compensar o atraso pela equipe sleepe não aumentar significativamente o tempo de implantação: há uma diferença notável entre 30 segundos e um .. Na verdade, o “trabalho principal” é cuidado? process_control_timeout, Mas é lifecycleusado apenas como uma “rede de segurança” em caso de lag.De um modo geral, o comportamento descrito e a solução alternativa correspondente dizem respeito não apenas ao PHP-FPM . Uma situação semelhante pode surgir de uma maneira ou de outra ao usar outros idiomas / estruturas. Se você não pode corrigir o desligamento normal de outras maneiras - por exemplo, reescreva o código para que o aplicativo processe corretamente os sinais de terminação - você pode usar o método descrito. Pode não ser o mais bonito, mas funciona.Prática. Teste de carga para verificar o desempenho do pod
O teste de carga é uma maneira de verificar como o contêiner funciona, pois esse procedimento o aproxima de condições reais de combate quando os usuários visitam o site. Você pode usar o Yandex.Tank para testar as recomendações acima : ele cobre perfeitamente todas as nossas necessidades. A seguir, dicas e truques para testar com clareza - graças aos gráficos do Grafana e do Yandex.Tank - um exemplo de nossa experiência.A coisa mais importante aqui é verificar se há mudanças nos estágios.. Após adicionar uma nova correção, execute o teste e verifique se os resultados foram alterados em comparação com o lançamento anterior. Caso contrário, será difícil identificar soluções ineficazes e, no futuro, você só poderá causar danos (por exemplo, aumentar o tempo de implantação).Outra advertência - observe os logs do contêiner durante seu término. As informações de desligamento normal são registradas lá? Existem erros nos logs ao acessar outros recursos (por exemplo, um contêiner PHP-FPM vizinho)? Erros do próprio aplicativo (como no caso do NGINX descrito acima)? Espero que as informações introdutórias deste artigo ajudem a entender melhor o que acontece com o contêiner durante seu término.Portanto, a primeira execução de teste ocorreu sem lifecyclee sem diretivas adicionais para o servidor de aplicativos (process_control_timeoutem PHP-FPM). O objetivo deste teste foi identificar o número aproximado de erros (e se eles existem). Além disso, a partir de informações adicionais, deve-se saber que o tempo médio de implantação de cada lareira foi de 5 a 10 segundos até o estado de prontidão total. Os resultados são os seguintes: Um respingo de 502 erros é visível no painel de informações do Yandex.Tank, que ocorreu no momento da implantação e durou em média 5 segundos. Presumivelmente, isso finalizou as solicitações existentes no pod antigo quando ele foi finalizado. Depois disso, 503 erros apareceram, o que foi o resultado de um contêiner NGINX parado, que também foi desconectado devido ao back-end (pelo qual o Ingress não pôde se conectar a ele).Vamos ver como
Um respingo de 502 erros é visível no painel de informações do Yandex.Tank, que ocorreu no momento da implantação e durou em média 5 segundos. Presumivelmente, isso finalizou as solicitações existentes no pod antigo quando ele foi finalizado. Depois disso, 503 erros apareceram, o que foi o resultado de um contêiner NGINX parado, que também foi desconectado devido ao back-end (pelo qual o Ingress não pôde se conectar a ele).Vamos ver comoprocess_control_timeoutno PHP-FPM nos ajudará a aguardar a conclusão dos processos filhos, ou seja, corrija esses erros. Implantação repetida usando esta diretiva: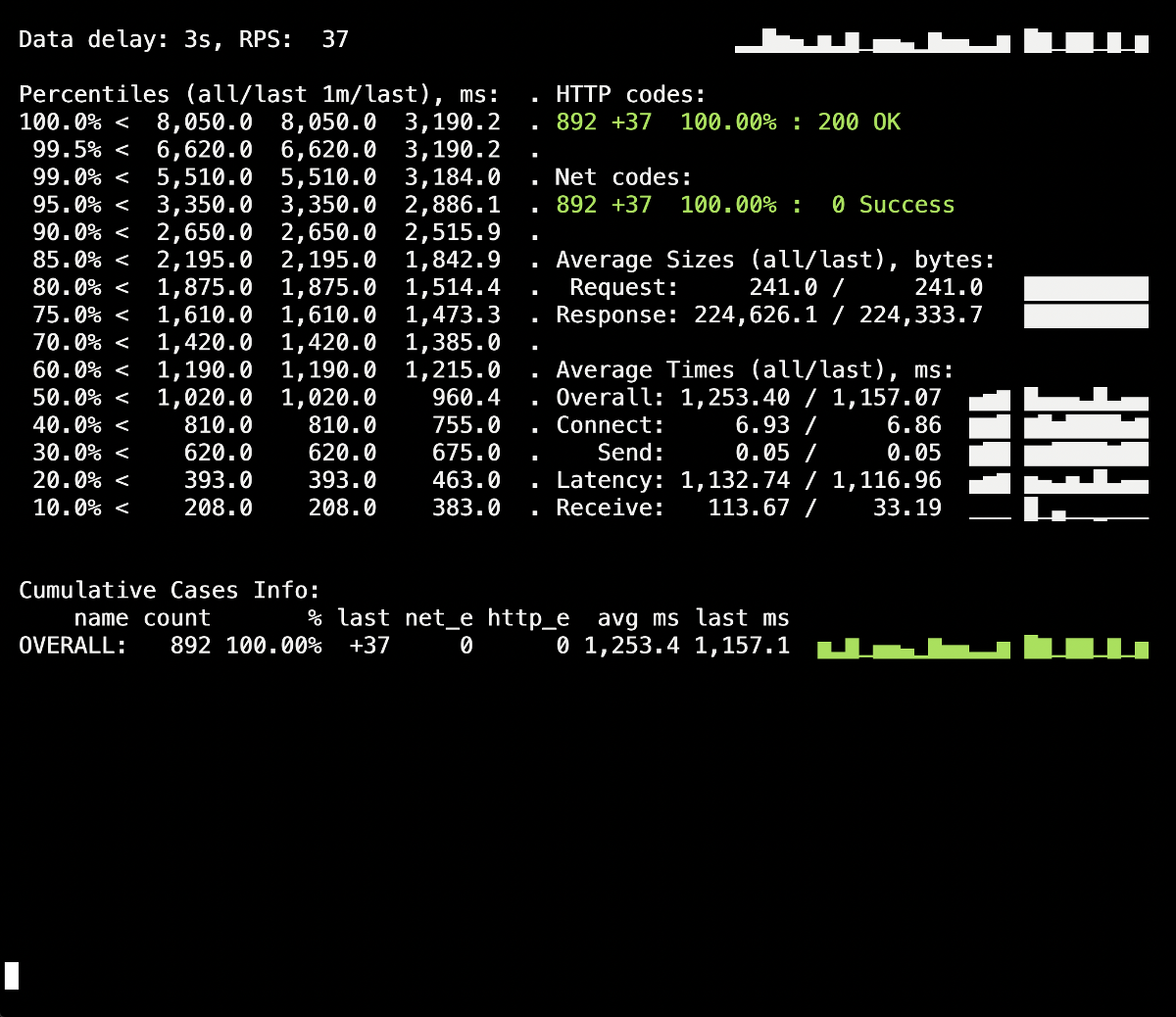 Não há mais erros durante a implantação dos anos 500! A implantação foi bem-sucedida, o desligamento normal funciona.No entanto, vale lembrar o momento com os contêineres do Ingress, uma pequena porcentagem de erros nos quais podemos obter devido a um atraso de tempo. Para evitá-los, resta adicionar a construção
Não há mais erros durante a implantação dos anos 500! A implantação foi bem-sucedida, o desligamento normal funciona.No entanto, vale lembrar o momento com os contêineres do Ingress, uma pequena porcentagem de erros nos quais podemos obter devido a um atraso de tempo. Para evitá-los, resta adicionar a construção sleepe repetir a implantação. No entanto, em nosso caso específico, nenhuma alteração foi visível (nenhum erro novamente).Conclusão
Para a conclusão correta do processo, esperamos o seguinte comportamento do aplicativo:- Aguarde alguns segundos e pare de aceitar novas conexões.
- Aguarde que todas as solicitações concluam e feche todas as conexões keepalive que não executam solicitações.
- Complete seu processo.
No entanto, nem todos os aplicativos podem funcionar dessa maneira. Uma solução para o problema nas realidades do Kubernetes é:- Adicionando um gancho pré-parada que esperará alguns segundos
- estudando o arquivo de configuração do nosso back-end para os parâmetros relevantes.
O exemplo NGINX nos permite entender que mesmo um aplicativo que inicialmente deve processar corretamente os sinais para conclusão pode não fazer isso, por isso é fundamental verificar se há 500 erros durante a implantação do aplicativo. Ele também permite que você analise o problema de maneira mais ampla e não se concentre em um pod ou contêiner separado, mas observe toda a infraestrutura como um todo.O Yandex.Tank pode ser usado como uma ferramenta de teste em conjunto com qualquer sistema de monitoramento (no nosso caso, os dados da Grafana com um back-end na forma de Prometheus foram feitos para o teste). Os problemas com o desligamento normal são claramente visíveis sob cargas pesadas que o benchmark pode gerar, e o monitoramento ajuda a analisar a situação com mais detalhes durante ou após o teste.Respondendo aos comentários sobre o artigo: vale ressaltar que os problemas e soluções são descritos aqui em relação ao NGINX Ingress. Para outros casos, existem outras soluções que, talvez, consideraremos nos seguintes materiais do ciclo.PS
Outro do ciclo de dicas e truques do K8s: