Quando o Facebook “mente”, as pessoas pensam que é por causa de hackers ou ataques DDoS, mas não é. Todas as "quedas" nos últimos anos foram causadas por mudanças ou avarias internas. Para ensinar aos novos funcionários a não quebrar o Facebook com exemplos, todos os principais incidentes recebem nomes, por exemplo, "Ligue para a polícia" ou "CAPSLOCK". O primeiro foi nomeado porque, quando um dia a rede social caiu, os usuários ligaram para a polícia de Los Angeles e pediram para corrigi-lo, e o xerife em desespero no Twitter pediu para não incomodá-los com isso. Durante o segundo incidente nas máquinas de cache, a interface de rede caiu e não subiu, e todas as máquinas foram reiniciadas manualmente.Elina Lobanovatrabalha no Facebook há 4 anos na equipe da Web Foundation. Os membros da equipe são chamados de engenheiros de produção e monitoram a confiabilidade e o desempenho de todo o back-end, publicam o Facebook quando ele está ativo, escrevem monitoramento e automação para facilitar a vida de si e dos outros. Em um artigo baseado no relatório da Elina no HighLoad ++ 2019 , mostraremos como os engenheiros de produção monitoram o back-end do Facebook, quais ferramentas eles usam, o que causa grandes falhas e como lidar com eles.Meu nome é Elina, há quase cinco anos, fui chamado no Facebook como desenvolvedor comum, onde encontrei sistemas realmente muito carregados - isso não é ensinado em institutos. A empresa não contrata uma equipe, mas um escritório, então cheguei a Londres, escolhi uma equipe que monitora o trabalho do facebook.com e estava entre os engenheiros de produção.
Em um artigo baseado no relatório da Elina no HighLoad ++ 2019 , mostraremos como os engenheiros de produção monitoram o back-end do Facebook, quais ferramentas eles usam, o que causa grandes falhas e como lidar com eles.Meu nome é Elina, há quase cinco anos, fui chamado no Facebook como desenvolvedor comum, onde encontrei sistemas realmente muito carregados - isso não é ensinado em institutos. A empresa não contrata uma equipe, mas um escritório, então cheguei a Londres, escolhi uma equipe que monitora o trabalho do facebook.com e estava entre os engenheiros de produção.Engenheiros de Produção
Para começar, vou lhe dizer o que estamos fazendo e por que somos chamados engenheiros de produção, e não o SRE como o Google, por exemplo.2009. SRE
O modelo padrão que ainda é usado em muitas empresas é "desenvolvedores - testadores - operação". Muitas vezes eles estão divididos: sentam-se em andares diferentes, às vezes até em países diferentes, e não se comunicam.Em 2009, o Facebook já possuía SRE. No Google, o SRE começou mais cedo, eles sabem como obter o DevOps e o escreveram em seu livro “ Site Reliability Engineering ”. No Facebook em 2009, não havia nada assim. Fomos chamados de SRE, mas fizemos o mesmo trabalho que Ops no resto do mundo: trabalho manual, sem automação, implantação de todos os serviços com as mãos, monitorando de alguma forma, ligando para tudo, um conjunto de scripts de shell.
No Facebook em 2009, não havia nada assim. Fomos chamados de SRE, mas fizemos o mesmo trabalho que Ops no resto do mundo: trabalho manual, sem automação, implantação de todos os serviços com as mãos, monitorando de alguma forma, ligando para tudo, um conjunto de scripts de shell.2010. SRO e AppOps
Tudo isso não foi dimensionado, porque o número de usuários naquela época estava crescendo 3 vezes por ano e o número de serviços cresceu de acordo. Em 2010, a decisão decidida Ops foi dividida em dois grupos.O primeiro grupo é SRO , onde "O" é "operações", envolvido no desenvolvimento, automação e monitoramento do site.O segundo grupo é AppOps , eles foram integrados em equipes, cada uma para grandes serviços. O AppOps já está próximo da idéia do DevOps.A separação por um tempo salvou a todos.2012. Engenheiros de Produção
Em 2012, o AppOps simplesmente renomeou os engenheiros de produção . Além do nome, nada mudou, mas ficou mais confortável. Como você chama um iate, ele navegará, e nós não queremos navegar como Ops.As SROs ainda existiam, o Facebook estava crescendo e o monitoramento de todos os serviços ao mesmo tempo era difícil. Uma pessoa que estava em chamada nem sequer foi autorizada a ir ao banheiro: ele pediu a alguém para substituí-lo, porque ele estava constantemente queimando.2014. SRO de fechamento
Em um ponto, as autoridades transferiram todos para a chamada. "Todo mundo" significa que os desenvolvedores também: escreva seu código, aqui está você e responda por esse código!Os engenheiros de produção já foram integrados às equipes mais importantes em busca de ajuda, e o restante está sem sorte. Começamos com grandes equipes e, em alguns anos, transferimos todos no Facebook para o oncall. Entre os desenvolvedores, houve uma grande empolgação: alguém desistiu, escreveu mensagens ruins. Mas tudo se acalmou e, em 2014, o SRO foi fechado porque não era mais necessário. Então, vivemos até hoje.A palavra "SRE" na empresa é notória, mas parecemos SRE no Google. Existem diferenças.- Estamos sempre integrados em equipes. Não temos a pesquisa SRE em geral, como no Google, é para cada serviço de pesquisa separadamente.
- Não estamos nos produtos , apenas na infraestrutura em que o produto se administra.
- Estamos oncall junto com os desenvolvedores.
- Como temos um pouco mais de experiência em sistemas e redes, nos concentramos em monitorar e extinguir serviços quando eles queimam intensamente. Corrigimos erros com antecedência que poderiam levar a falhas e influenciar a arquitetura de novos serviços desde o início, para que eles funcionassem sem problemas na produção.
Monitoramento
É o mais importante. Como vamos fazer isso? Como todo mundo: sem magia negra, em casa própria. Mas o diabo, como sempre, falará sobre eles em detalhes.ATOP
Vamos começar de baixo. Todo mundo conhece o TOP no Linux, e usamos o ATOP, onde "A" é "avançado" - um monitor de desempenho do sistema. O principal benefício do ATOP é que ele armazena o histórico: você pode configurá-lo para salvar instantâneos em disco. Nosso ATOP é executado em todas as máquinas a cada 5 segundos.Aqui está um servidor de exemplo executando o back-end do PHP para facebook.com. Nós escrevemos nossa máquina virtual para executar o código PHP, chamado HHVM (HipHop Virtual Machine). De acordo com as métricas exportadas, descobrimos que várias máquinas não processavam quase uma única solicitação em um minuto. Vamos ver o porquê, abra o ATOP 30 segundos antes de travar. Pode-se ver que, com os problemas do processador, carregamos demais. Também há problemas com a memória, apenas 1,5 GB são deixados no cache e, após 5 segundos, apenas 800 MB.
Pode-se ver que, com os problemas do processador, carregamos demais. Também há problemas com a memória, apenas 1,5 GB são deixados no cache e, após 5 segundos, apenas 800 MB. Após mais 5 segundos, a CPU é liberada, nada é executado. ATOP diz olhar para a linha de fundo, escrevemos para o disco, mas o que? Acontece que estamos escrevendo swap.
Após mais 5 segundos, a CPU é liberada, nada é executado. ATOP diz olhar para a linha de fundo, escrevemos para o disco, mas o que? Acontece que estamos escrevendo swap. Quem está fazendo isso? Processos que foram retirados da memória 0,5 GB e trocados. Em seu lugar, surgiram dois processos suspeitos de Python, que podem ser vistos como uma linha de comando.
Quem está fazendo isso? Processos que foram retirados da memória 0,5 GB e trocados. Em seu lugar, surgiram dois processos suspeitos de Python, que podem ser vistos como uma linha de comando.
ATOP é bonito, usamos constantemente.
Se você não o possui, eu recomendo usá-lo. Não tenha medo da unidade, o ATOP consome apenas 200 a 300 MB por dia a cada 5 segundos.Malloc HTTP
Às Bahamas e aos grandes incidentes, damos nomes. Há um bug divertido relacionado ao ATOP chamado Malloc HTTP. Nós estreou com ATOP e strace.Usamos Thrift em todos os lugares como um RPC. Nas versões anteriores de seu analisador, havia um bug incrível que funcionava assim: chegou uma mensagem na qual os primeiros 4 bytes são do tamanho dos dados, depois os próprios dados e os primeiros bytes são adicionados à próxima mensagem.Mas uma vez que um dos programas, em vez de ir para o serviço de Thrift, fui para HTTP, e recebeu uma resposta «a Bad HTTP o Pedido»: HTTP/1.1 400.Depois de pegar o HTTP e alocá-lo usando o malloc HTTP, o número de bytes.Thrift message
HTTP/1.1 400
"HTTP" == 0x48545450
Está tudo bem, nós nos comprometemos demais, vamos alocar mais memória! Alocamos com malloc, e até escrevermos e lermos lá, eles não nos darão memória real.Mas não estava lá! Se queremos bifurcar, a bifurcação retornará um erro - não há memória suficiente.malloc("HTTP")
pid = fork(); // errno = ENOMEM
Mas por que, há uma memória? Entendendo os manuais, descobrimos que tudo é muito simples: a atual configuração de supercomprometimento é tal que é uma heurística mágica, e o próprio kernel decide quando muito e quando não:malloc("HTTP")
pid = fork(); // errno = ENOMEM
// 0: heuristic overcommit
vm.overcommit_memory = 0
Para um processo de trabalho, isso é normal, você pode selecionar malloc até TB, mas para um novo processo - não. E parte do monitoramento em nós estava ligada ao fato de que o processo principal bifurcava pequenos scripts para coleta de dados. Como resultado, nossa parte de monitoramento quebrou, porque não podíamos mais bifurcar.FB303
O FB303 é o nosso sistema básico de monitoramento. Foi nomeado após o sintetizador de baixo padrão de 1982. O princípio é simples, portanto, ainda funciona: cada serviço implementa a interface Thrift getCounters.
O princípio é simples, portanto, ainda funciona: cada serviço implementa a interface Thrift getCounters.Service FacebookService {
map<string, i64> getCounters()
}
Na verdade, ele não o implementa, porque as bibliotecas já estão escritas, tudo é feito no código incrementou set.incrementCounter(string& key);
setCounter(string& key, int64_t value);
Como resultado, cada serviço exporta contadores na porta que registra no Service Discovery. Abaixo está um exemplo de uma máquina que gera um feed de notícias e exporta cerca de 5,5 mil pares (string, número): memória, produção, qualquer coisa. Cada máquina executa um processo binário que passa por todos os serviços, coleta esses contadores e os armazena.É assim que a GUI de armazenamento se parece .
Cada máquina executa um processo binário que passa por todos os serviços, coleta esses contadores e os armazena.É assim que a GUI de armazenamento se parece . Muito parecido com Prometeu e Grafana, mas não é. A primeira entrada do FB303 no GitHub foi em 2009 e no Prometheus em 2012. Esta é uma explicação de todos os produtos “caseiros” do Facebook: nós os fizemos quando nada era normal em código aberto.Por exemplo, há uma pesquisa pelos nomes dos contadores.
Muito parecido com Prometeu e Grafana, mas não é. A primeira entrada do FB303 no GitHub foi em 2009 e no Prometheus em 2012. Esta é uma explicação de todos os produtos “caseiros” do Facebook: nós os fizemos quando nada era normal em código aberto.Por exemplo, há uma pesquisa pelos nomes dos contadores. Os gráficos em si se parecem com isso.
Os gráficos em si se parecem com isso. Uma imagem do grupo interno em que publicamos belos gráficos.Uma diferença importante entre nossa pilha de monitoramento e Prometheus e Grafana é que armazenamos dados para sempre . Nosso monitoramento fará uma nova amostragem dos dados e, após 2 semanas, teremos um ponto a cada 5 minutos e depois de um ano a cada hora. Portanto, eles podem ser armazenados demais. Automaticamente, isso não está configurado em nenhum lugar.Mas se falarmos sobre os recursos de monitoramento do Facebook, eu o descreveria com uma palavra em inglês " observabilidade" .
Uma imagem do grupo interno em que publicamos belos gráficos.Uma diferença importante entre nossa pilha de monitoramento e Prometheus e Grafana é que armazenamos dados para sempre . Nosso monitoramento fará uma nova amostragem dos dados e, após 2 semanas, teremos um ponto a cada 5 minutos e depois de um ano a cada hora. Portanto, eles podem ser armazenados demais. Automaticamente, isso não está configurado em nenhum lugar.Mas se falarmos sobre os recursos de monitoramento do Facebook, eu o descreveria com uma palavra em inglês " observabilidade" .Observabilidade
Existe uma "caixa preta", existe uma "caixa branca" e temos uma "caixa" transparente de vidro. Isso significa que, quando escrevemos código, escrevemos tudo o que é possível nos logs, e não seletivamente. A amostragem é bem ajustada em todos os lugares, para que o back-end para armazenamento, contadores e tudo o mais funcione perfeitamente.Ao mesmo tempo, podemos criar nossos painéis em contadores existentes. No caso de estudar esses painéis, este não é o ponto final com 10 gráficos, mas o inicial, a partir do qual acessamos nossa interface do usuário e encontramos tudo o que é possível.Mergulho
Esse é o clímax da ideia de observabilidade. Esta é a nossa pilha ELK. O princípio é o mesmo: escrevemos em JSON sem um esquema específico, depois solicitamos na forma de uma tabela , séries temporais de dados ou mais 10 opções de visualização.O Scuba registra na ordem de centenas de gigabytes por segundo. Tudo é solicitado muito rapidamente, porque não é o Elasticsearch, e tudo está na memória em máquinas poderosas. Sim, o dinheiro é gasto com isso, mas como é maravilhoso!Por exemplo, abaixo da interface do usuário do Scuba, uma das tabelas mais populares é aberta nela, na qual todos os clientes de todos os serviços Thrift gravam logs.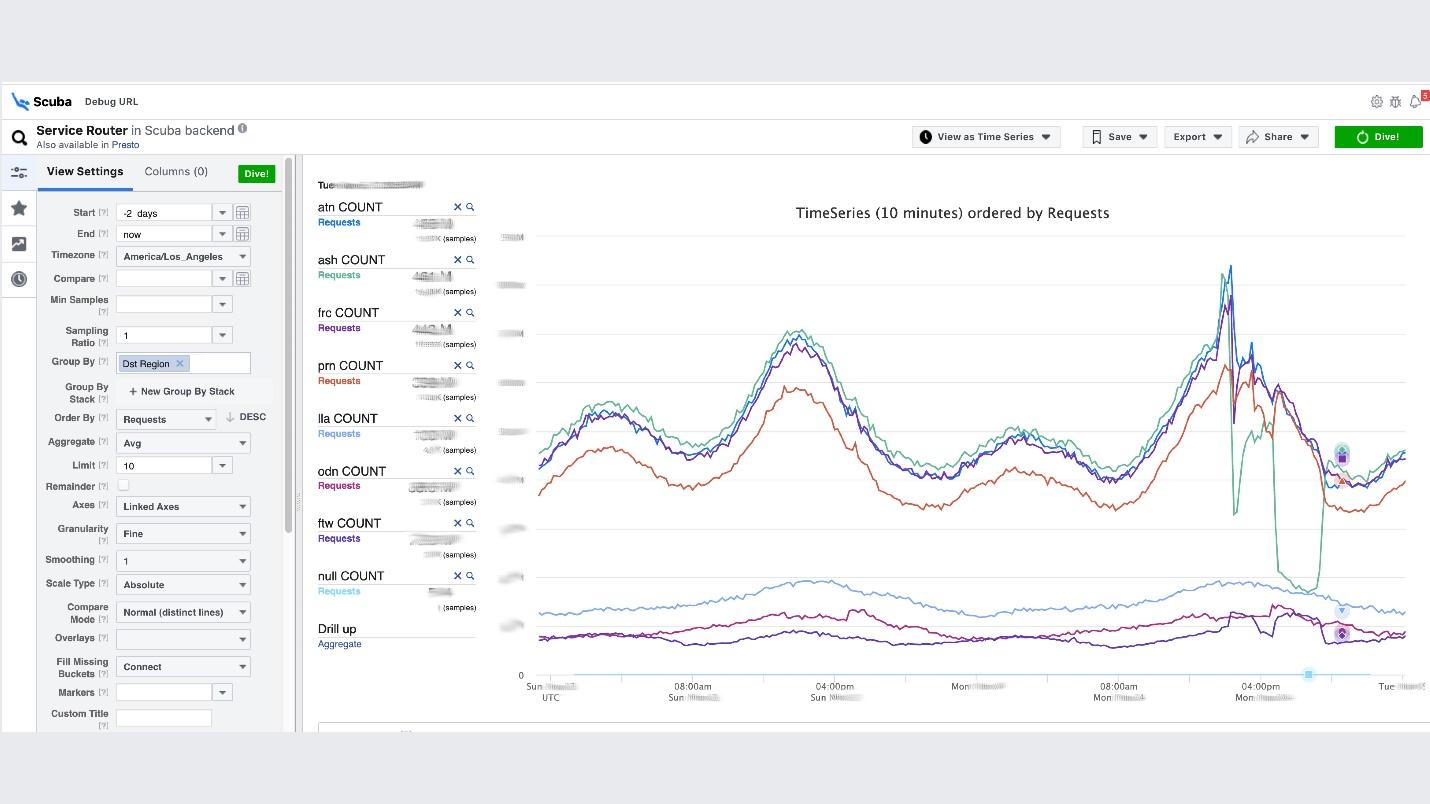 O gráfico mostra que, no final, algo deu errado no serviço. Para descobrir o atraso, vá para a lista de contadores, selecione o atraso, agregação, clique em "Mergulho".
O gráfico mostra que, no final, algo deu errado no serviço. Para descobrir o atraso, vá para a lista de contadores, selecione o atraso, agregação, clique em "Mergulho".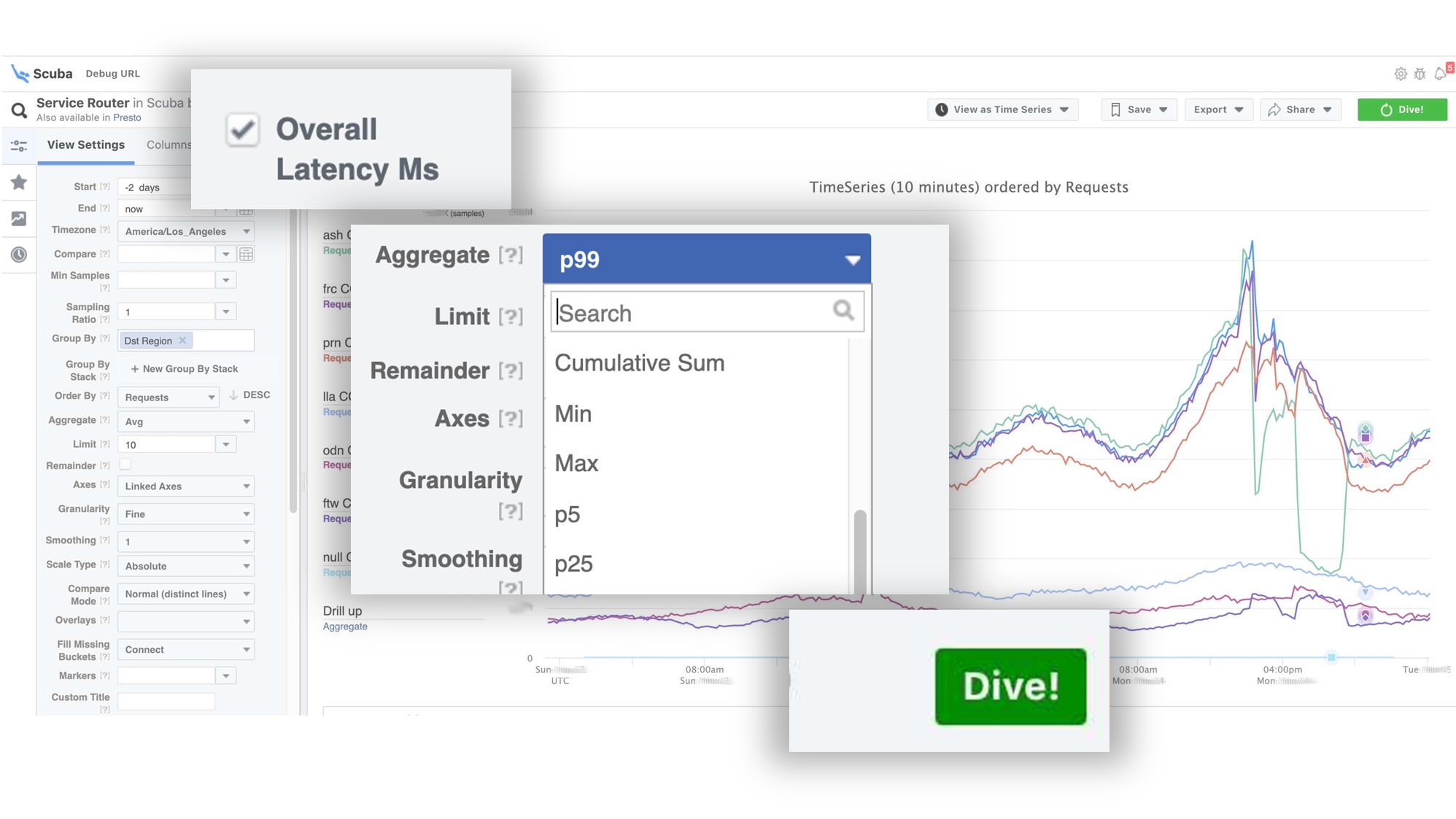 A resposta vem em 2 segundos.
A resposta vem em 2 segundos.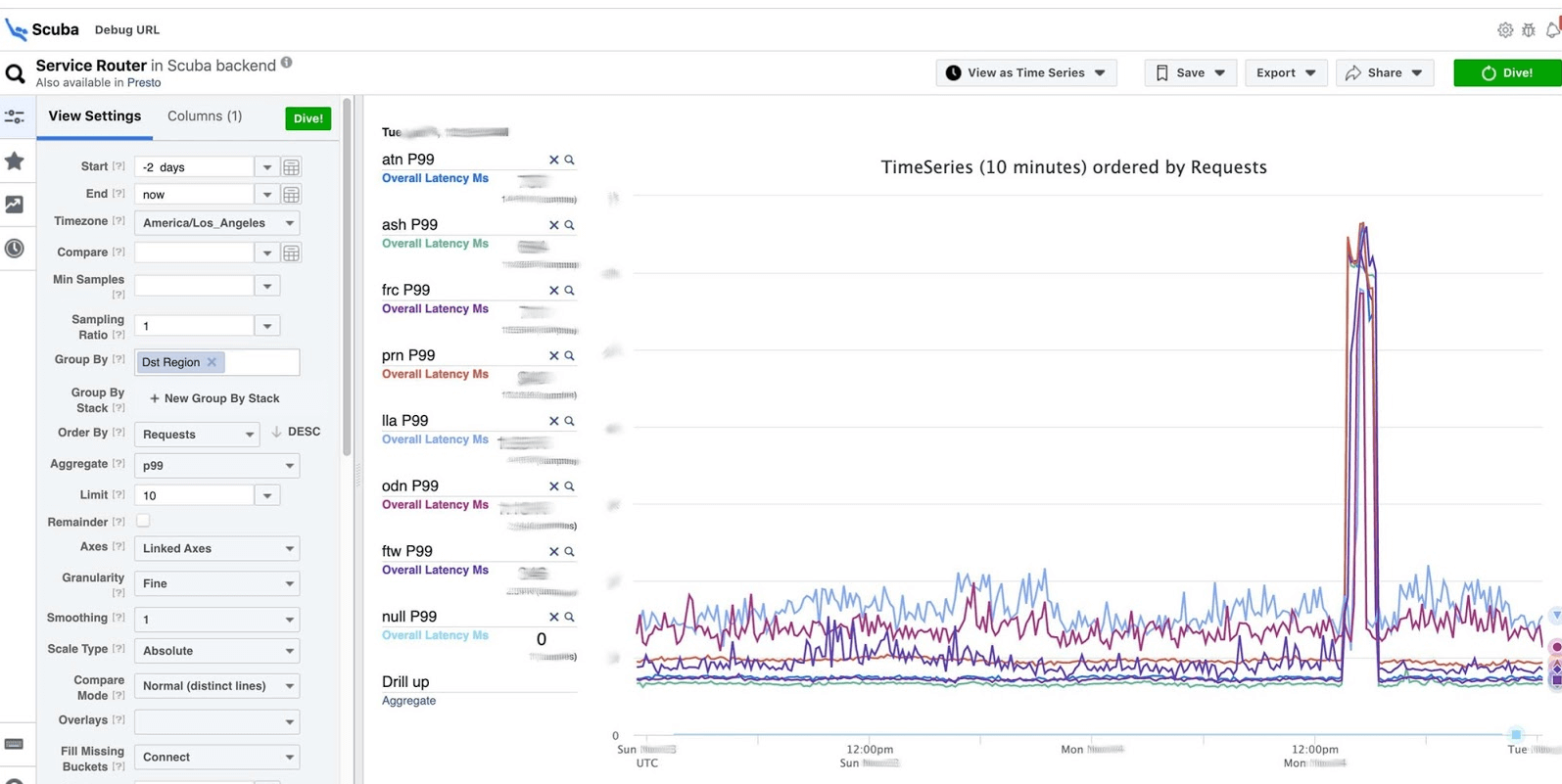 Pode-se ver que naquele momento algo aconteceu e o atraso aumentou significativamente. Para saber mais, você pode agrupar por diferentes parâmetros.Existem centenas dessas tabelas.
Pode-se ver que naquele momento algo aconteceu e o atraso aumentou significativamente. Para saber mais, você pode agrupar por diferentes parâmetros.Existem centenas dessas tabelas.- Uma tabela que mostra as versões de arquivos binários, pacotes e quanta memória é consumida em todos os milhões de máquinas. Em cada host, um PS é feito uma vez por hora e enviado ao Scuba.
- Todos os dmesg, todos os despejos de memória são enviados para outras tabelas. Executamos o Perf a cada 10 minutos em cada máquina, para saber quais rastreamentos de pilha temos no kernel e o que a CPU global pode carregar.
Depuração do PHP
O Scuba também fornece um back-end para nossa principal ferramenta de depuração do PHP. Milhares de engenheiros escrevem código PHP e, de alguma forma, você precisa salvar o repositório global de coisas ruins.Como funciona? O PHP também grava um rastreamento de pilha em cada log. O Scuba (nossa Elasticsearch) simplesmente não pode acomodar o rastreamento de pilha de todos os logs de todas as máquinas. Antes de colocar o log no Scuba, convertemos o rastreamento da pilha em um hash, amostra por hashes e os salvamos apenas. Os rastreamentos de pilha são enviados para o Memcached. Em seguida, na ferramenta interna, você pode obter rapidamente um rastreamento de pilha específico do Memcached. Visualização com agrupamento de hash de logs e rastreios de pilha.Depuramos o código usando o método de correspondência de padrões : abra o Scuba, veja como é o gráfico de erros.
Visualização com agrupamento de hash de logs e rastreios de pilha.Depuramos o código usando o método de correspondência de padrões : abra o Scuba, veja como é o gráfico de erros.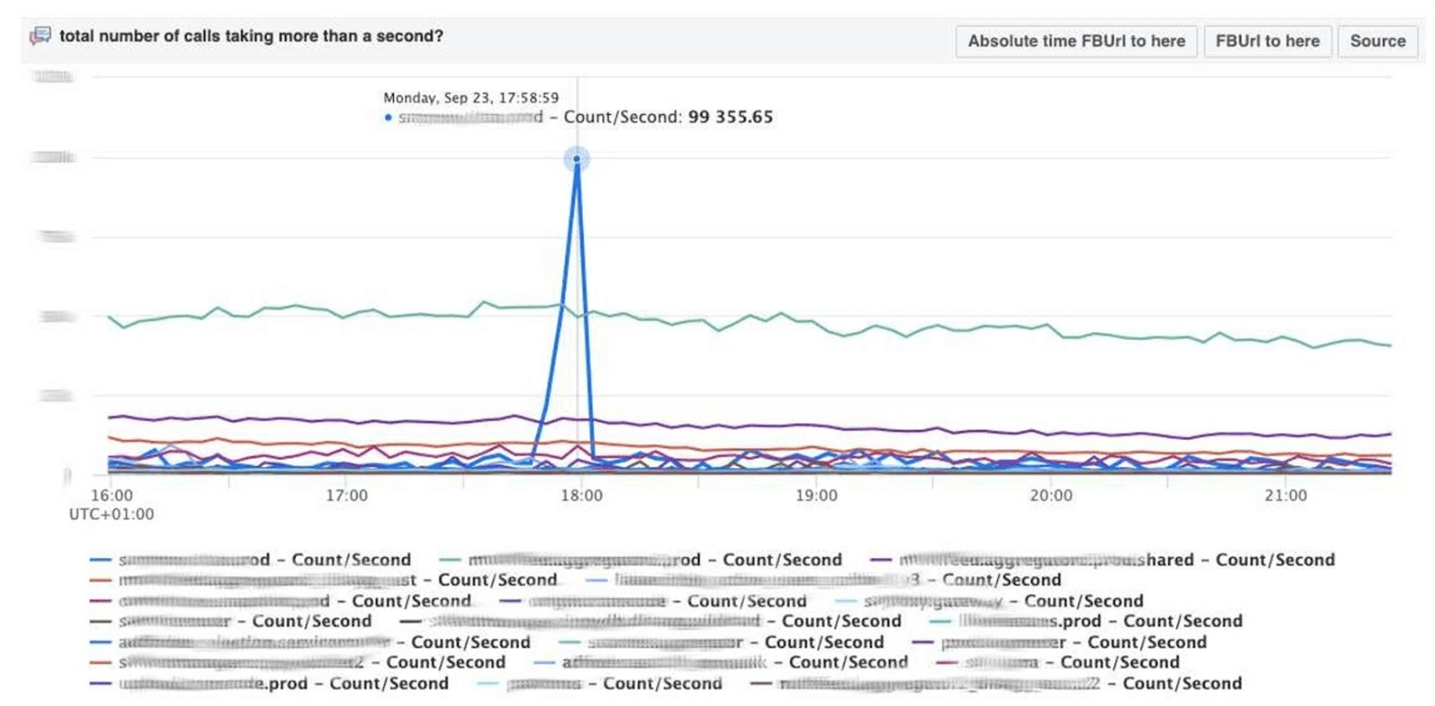 Vamos para o LogView, já existem erros agrupados por rastreamentos de pilha.
Vamos para o LogView, já existem erros agrupados por rastreamentos de pilha. Um rastreamento de pilha é carregado no Memcached e nele você já pode encontrar o diff (commit no repositório PHP), que foi postado aproximadamente ao mesmo tempo, e reverte-o. Qualquer um pode reverter e se comprometer conosco, não são necessárias permissões para isso.
Um rastreamento de pilha é carregado no Memcached e nele você já pode encontrar o diff (commit no repositório PHP), que foi postado aproximadamente ao mesmo tempo, e reverte-o. Qualquer um pode reverter e se comprometer conosco, não são necessárias permissões para isso.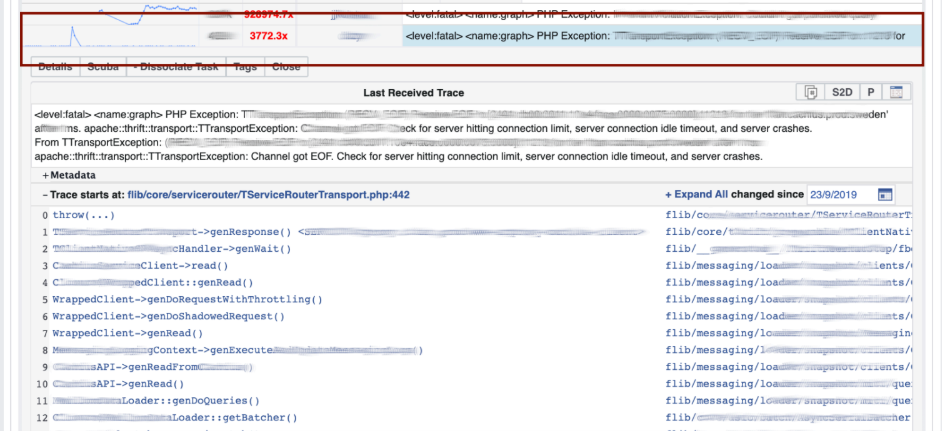
Dashboards
Terminarei o tópico de monitoramento com painéis. Temos alguns deles - apenas dois por três indicadores. O painel em si é bastante incomum. Eu gostaria de falar mais sobre ele. Abaixo está um painel padrão com um conjunto de gráficos.Infelizmente, não é tão simples com ele. O fato é que a linha roxa em um gráfico é o mesmo serviço que a linha azul corresponde no outro gráfico, e outro gráfico pode estar em um dia e outro em um mês.Usamos nosso painel baseado no Cubism - a biblioteca JS de código aberto. Foi escrito na Square e lançado sob a licença Apache. Eles têm suporte embutido para Graphite e Cube. Mas é fácil expandir, o que fizemos.O painel abaixo mostra um dia a um pixel por minuto. Cada linha é uma região: data centers próximos. Eles exibem o número de logs que o back-end do Facebook grava em bytes por segundo. Abaixo estão anotações para as equipes na América verem o que já corrigimos do que aconteceu durante o dia. É fácil procurar correlação nesta imagem.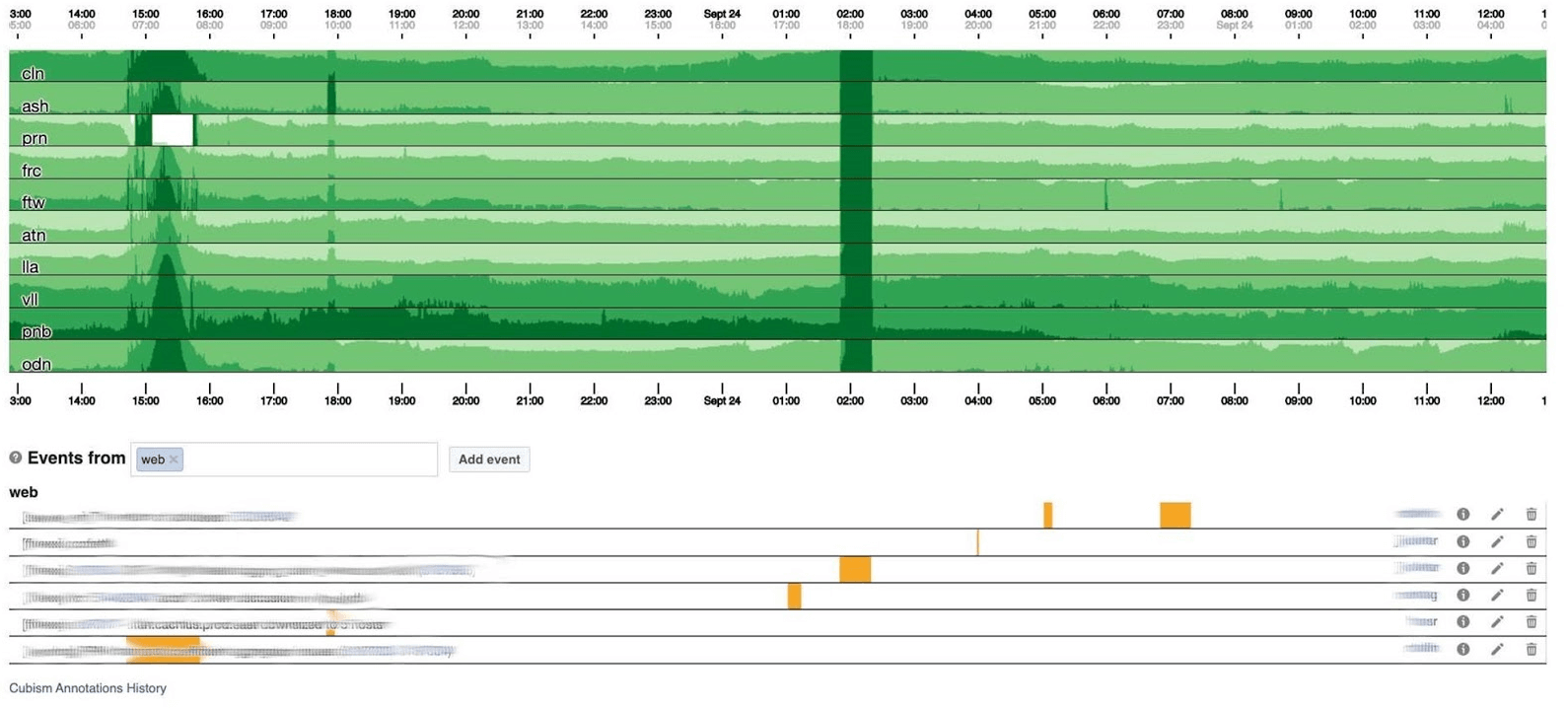 Abaixo está o número de erros 500. O que à esquerda não importava para os usuários e, obviamente, eles não gostavam da faixa verde escura no centro.
Abaixo está o número de erros 500. O que à esquerda não importava para os usuários e, obviamente, eles não gostavam da faixa verde escura no centro.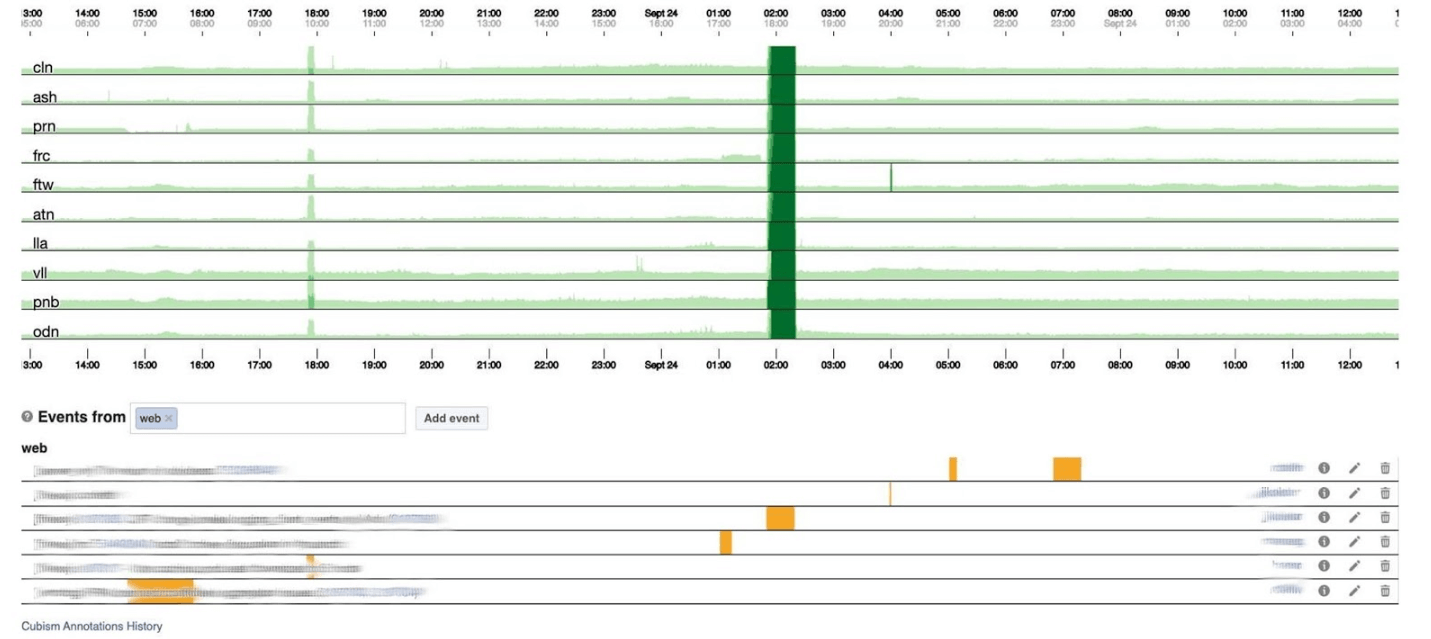 A seguir está a latência do 99º percentil. Ao mesmo tempo, como no gráfico acima, é possível observar que a latência diminuiu. Para retornar um erro, não é necessário gastar muito tempo.
A seguir está a latência do 99º percentil. Ao mesmo tempo, como no gráfico acima, é possível observar que a latência diminuiu. Para retornar um erro, não é necessário gastar muito tempo.
Como funciona
Em um gráfico de 120 pixels de altura, tudo é visível. Mas muitas delas não podem ser colocadas em um painel, então diminuiremos para 30. Infelizmente, temos algum tipo de jibóia. Vamos voltar e ver o que o cubismo faz com isso. Ele divide o gráfico em 4 partes: quanto maior, mais escuro e depois desmorona.
Infelizmente, temos algum tipo de jibóia. Vamos voltar e ver o que o cubismo faz com isso. Ele divide o gráfico em 4 partes: quanto maior, mais escuro e depois desmorona. Agora temos a mesma programação de antes, mas tudo é claramente visível: quanto mais escuro o verde, pior. Agora está muito mais claro o que está acontecendo.À esquerda, você pode ver a onda que subia e no centro, onde é verde escuro, tudo está muito ruim.
Agora temos a mesma programação de antes, mas tudo é claramente visível: quanto mais escuro o verde, pior. Agora está muito mais claro o que está acontecendo.À esquerda, você pode ver a onda que subia e no centro, onde é verde escuro, tudo está muito ruim.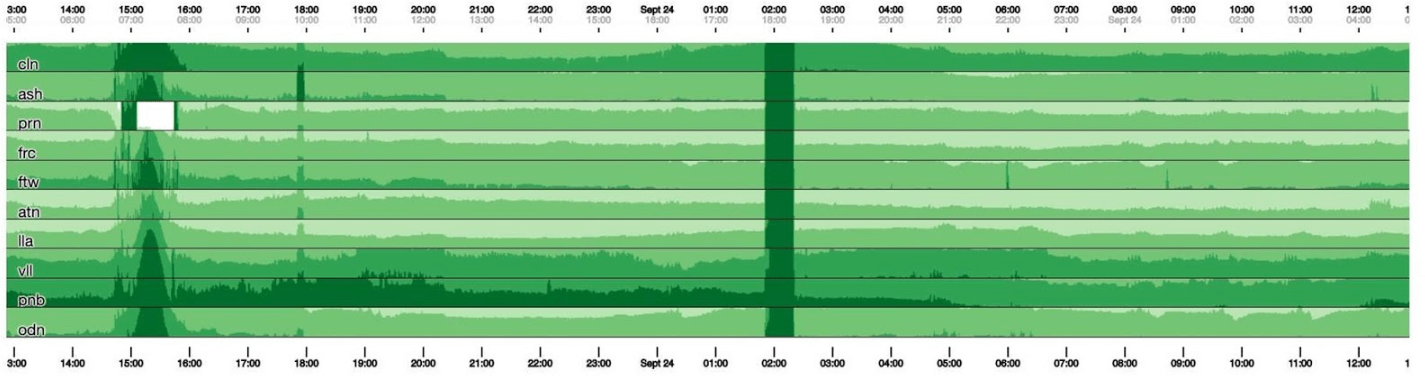 Cubismo é apenas o começo. É necessário para visualização, a fim de entender se tudo está ruim agora ou não. Para cada tabela, já existem painéis com gráficos detalhados.
Cubismo é apenas o começo. É necessário para visualização, a fim de entender se tudo está ruim agora ou não. Para cada tabela, já existem painéis com gráficos detalhados. O monitoramento por si só ajuda a entender o estado do sistema e responder se ele quebrar. No Facebook, todo funcionário oncall deve ser capaz de reparar tudo. Se queima intensamente, tudo acontece, mas especialmente os engenheiros de produção com a experiência de um administrador de sistemas, porque sabem como resolver o problema rapidamente.
O monitoramento por si só ajuda a entender o estado do sistema e responder se ele quebrar. No Facebook, todo funcionário oncall deve ser capaz de reparar tudo. Se queima intensamente, tudo acontece, mas especialmente os engenheiros de produção com a experiência de um administrador de sistemas, porque sabem como resolver o problema rapidamente.Quando o Facebook estava
Às vezes, incidentes acontecem e o Facebook mente. Geralmente, as pessoas pensam que o Facebook está mentindo por causa de DDoS ou hackers atacados, mas em 5 anos isso nunca aconteceu. A razão sempre foi nossos engenheiros. Eles não são de propósito: os sistemas são muito complexos e podem quebrar onde você não espera.Damos nomes a todos os incidentes importantes, para que seja conveniente mencionar e informar os recém-chegados sobre eles, para não repetir erros no futuro. O campeão com o nome mais engraçado é o incidente de chamar a polícia . As pessoas ligaram para a polícia de Los Angeles e pediram para consertar o Facebook porque estava mentindo. O xerife de Los Angeles estava tão cansado disso que ele twittou: "Por favor, não nos ligue!" Nós não somos responsáveis por isso! ” Meu incidente favorito do qual participei foi chamado CAPSLOCK.. É interessante, pois mostra que tudo pode acontecer. E isso é o que aconteceu. Ele endereço obychnyyIP:
Meu incidente favorito do qual participei foi chamado CAPSLOCK.. É interessante, pois mostra que tudo pode acontecer. E isso é o que aconteceu. Ele endereço obychnyyIP: fd3b:5679:92eb:9ce4::1.O Facebook usa o Chef para personalizar o sistema operacional. O Service Inventory armazena a configuração do host em seu banco de dados e o Chef recebe um arquivo de configuração do serviço. Depois que o serviço mudou sua versão, começou a ler endereços IP do banco de dados imediatamente no formato MySQL e colocá-los em um arquivo. O novo endereço agora está escrito no capital: FD3B:5679:92EB:9CE4::1.Shef examina o novo arquivo e vê que o endereço IP "mudou" porque ele se compara, não na forma binária, mas com uma string. O endereço IP é "novo", o que significa que você precisa abaixar a interface e aumentar a interface. Em todos os milhões de carros em 15 minutos, a interface caiu e subiu.Parece que está tudo bem - a capacidade diminuiu enquanto a rede estava em algumas máquinas. Mas de repente um bug foi aberto no driver de rede de nossas placas de rede personalizadas: na inicialização, eles exigiam 0,5 GB de memória física seqüencial. Nas máquinas de cache, esses 0,5 GB desapareceram enquanto abaixamos e aumentamos a interface. Portanto, nas máquinas de cache, a interface de rede caiu e não aumentou, e nada funciona sem caches. Sentamos e reiniciamos essas máquinas com as mãos. Foi divertido.Portal do Gerenciador de Incidentes
Quando o Facebook “queima”, é necessário organizar o trabalho da “brigada de incêndio” e, o mais importante, entender onde queima, porque em uma grande empresa ele pode “cheirar queimado” em um lugar, mas o problema estará em outro. A ferramenta de interface do usuário chamada Incident Manager Portal nos ajuda com isso . Foi escrito por engenheiros de produção e está aberto a todos. Assim que algo acontece, iniciamos um incidente: nome, começo, descrição.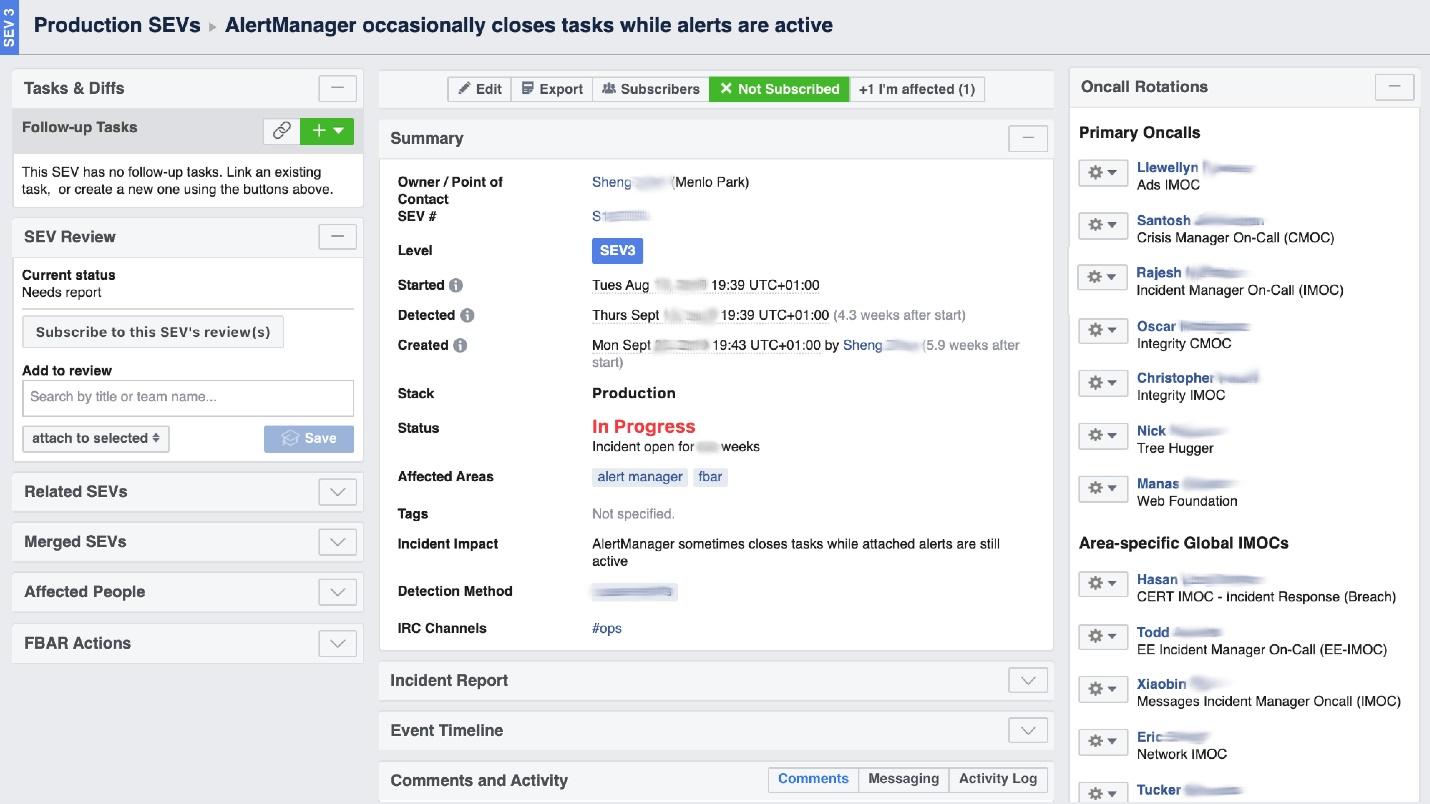 Temos uma pessoa especialmente treinada - Gerente de Incidentes On-Call (IMOC). Esta não é uma posição permanente, os gerentes mudam regularmente. Em caso de grandes incêndios, o IMOC organiza e coordena as pessoas para reparo, mas não precisa repará-lo. Assim que um incidente com um alto nível de perigo é criado, o IMOC recebe SMS e começa a ajudar a organizar tudo. Em um sistema grande, essas pessoas não podem ser dispensadas.
Temos uma pessoa especialmente treinada - Gerente de Incidentes On-Call (IMOC). Esta não é uma posição permanente, os gerentes mudam regularmente. Em caso de grandes incêndios, o IMOC organiza e coordena as pessoas para reparo, mas não precisa repará-lo. Assim que um incidente com um alto nível de perigo é criado, o IMOC recebe SMS e começa a ajudar a organizar tudo. Em um sistema grande, essas pessoas não podem ser dispensadas.Prevenção
O Facebook não é tão comum. Na maioria das vezes, não apagamos incêndios e não reiniciamos as máquinas de cache, mas corrigimos os erros antecipadamente e, se possível, para todos de uma vez.Uma vez que encontramos e corrigimos o "problema da fila". O número de solicitações aumenta em 50% e os erros em 100%, porque ninguém limita a implementação antecipada, especialmente em pequenos serviços.Nós descobrimos um exemplo de vários serviços e definimos aproximadamente um modelo de comportamento.- Sob carga normal, a solicitação chega, é processada e retornada ao cliente.
- Com uma carga alta, as solicitações estão aguardando em uma fila porque todos os encadeamentos para processamento de solicitações estão ocupados. O atraso está aumentando, mas até agora está tudo bem.
- A linha está crescendo, a carga está aumentando. Em algum momento, tudo o que o servidor executa no cliente termina com um tempo limite de resposta e o cliente cai com um erro. Nesse ponto, o resultado do servidor pode ser simplesmente descartado.
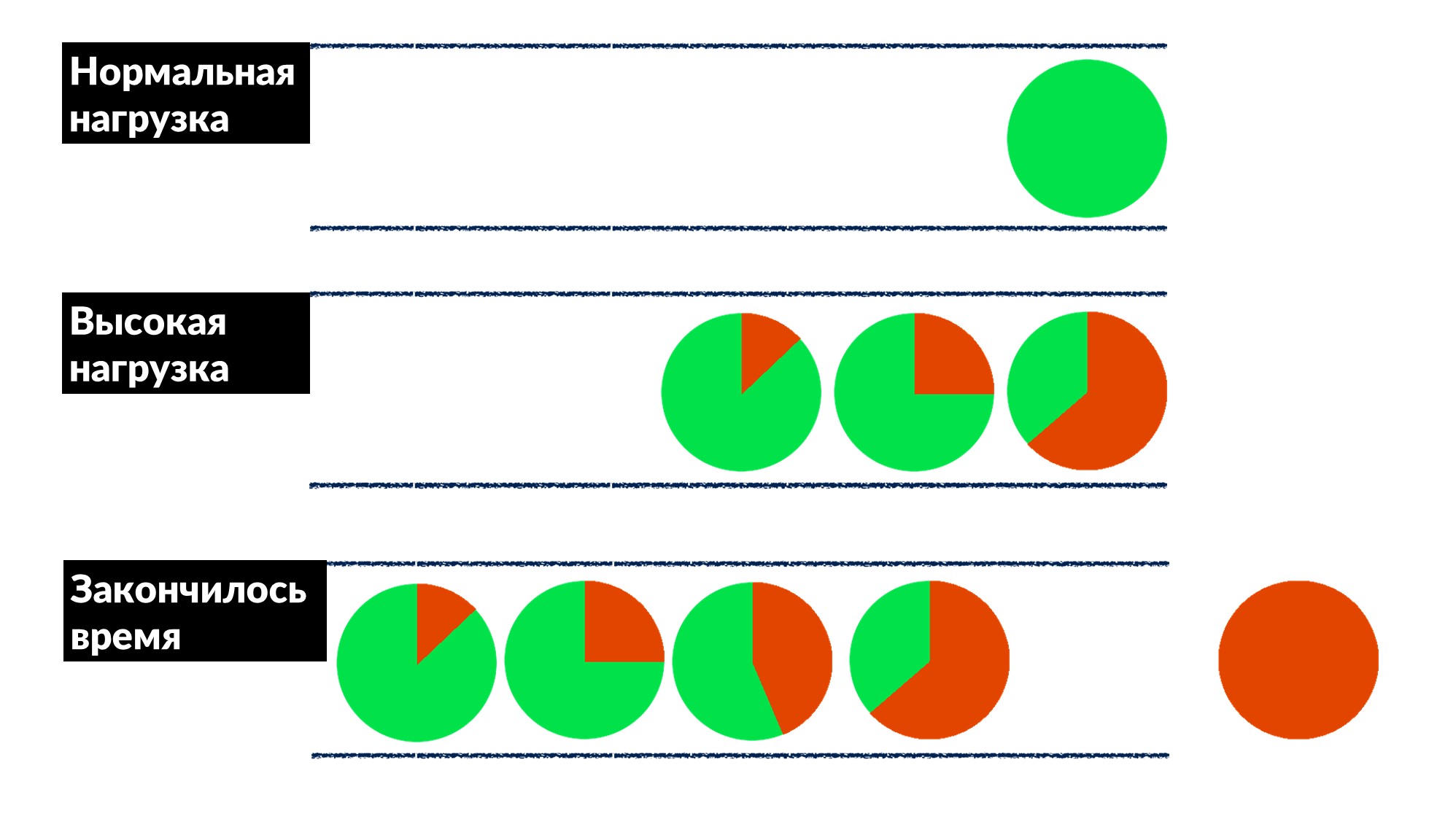 O tempo limite do cliente é destacado em vermelho.E o cliente repete novamente! Acontece que todos os pedidos que executamos são jogados no lixo e ninguém precisa mais dele.Como resolver esse problema para todos de uma vez? Introduzir um limite no tempo de espera na fila. Se a solicitação estiver na fila mais do que o esperado, a descartamos e não a processamos no servidor, não desperdiçamos CPU nela. Temos um jogo honesto: jogamos fora tudo o que não podemos processar e tudo o que podíamos - processado.A restrição tornou possível, ao aumentar a carga em 50% acima do máximo, ainda processar 66% das solicitações e receber apenas 33% dos erros. Os desenvolvedores da estrutura do Dispatch implementaram isso no lado do servidor, e nós, os engenheiros de produção, resolvemos gentilmente o tempo limite de 100 ms na fila para todos. Portanto, todos os serviços imediatamente obtiveram limitação básica barata.
O tempo limite do cliente é destacado em vermelho.E o cliente repete novamente! Acontece que todos os pedidos que executamos são jogados no lixo e ninguém precisa mais dele.Como resolver esse problema para todos de uma vez? Introduzir um limite no tempo de espera na fila. Se a solicitação estiver na fila mais do que o esperado, a descartamos e não a processamos no servidor, não desperdiçamos CPU nela. Temos um jogo honesto: jogamos fora tudo o que não podemos processar e tudo o que podíamos - processado.A restrição tornou possível, ao aumentar a carga em 50% acima do máximo, ainda processar 66% das solicitações e receber apenas 33% dos erros. Os desenvolvedores da estrutura do Dispatch implementaram isso no lado do servidor, e nós, os engenheiros de produção, resolvemos gentilmente o tempo limite de 100 ms na fila para todos. Portanto, todos os serviços imediatamente obtiveram limitação básica barata.Ferramentas
A ideologia do SRE diz que, se você tem uma grande frota de carros, vários serviços e nada a ver com suas mãos, precisa automatizar. Portanto, metade do tempo escrevemos código e construímos ferramentas.- Cubismo integrado no sistema.
- O FBAR é um "cavalo de batalha" que vem e conserta, para que ninguém se preocupe com um carro quebrado. Essa é a principal tarefa do FBAR, mas agora ele tem ainda mais tarefas.
- Coredumper , que escrevemos com dois colegas . Ele monitora coredumps em todas as máquinas e os coloca em um só lugar, juntamente com rastreamentos de pilha com todas as informações do host: onde está, como encontrar o tamanho. Mas o mais importante é que os rastreamentos de pilha são gratuitos, sem iniciar o GDB usando os programas BPF.
Pesquisas
A última coisa que fazemos é conversar com as pessoas, entrevistá-las. Parece-nos que isso é muito importante.Uma pesquisa útil é sobre confiabilidade. Perguntamos sobre os serviços já em execução nas principais aspas do nosso questionário:"A principal responsabilidade do software do sistema deve ser continuar executando. A prestação de serviços deve ser vista como um efeito colateral benéfico da operação continuada »
Isso significa que o principal dever do sistema é continuar funcionando, e o fato de fornecer algum tipo de serviço é um bônus adicional.As pesquisas são apenas para serviços médios, os próprios grandes entendem. Fornecemos um questionário no qual perguntamos coisas básicas sobre arquitetura, SLO, teste, por exemplo.- "O que acontece se o seu sistema receber 10% da carga?" Quando as pessoas pensam: "Mas sério, o que?" - insights aparecem e muitos até governam seus sistemas. Anteriormente, eles não pensavam sobre isso, mas após a pergunta há uma razão.
- "Quem é o primeiro a perceber problemas no seu serviço - você ou seus usuários?" Os desenvolvedores começam a se lembrar de quando isso aconteceu e: "... Talvez você precise adicionar alertas".
- "Qual é a sua maior dor oncall?" Isso é incomum para desenvolvedores, especialmente para novos. Eles imediatamente dizem: “Temos muitos alertas! Vamos limpá-los e remover aqueles que não são o caso ".
- "Qual a frequência de seus lançamentos?" Primeiro, eles lembram que o estão liberando com as mãos e, em seguida, eles têm sua própria implantação personalizada.
Não existe codificação no questionário, ele é padronizado e muda a cada seis meses. Este é um documento de duas páginas que ajudamos a preencher em 2-3 semanas. E então organizamos um comício de duas horas e encontramos soluções para muitas dores. Esta ferramenta simples funciona bem conosco e pode ajudá-lo.6-7 Saint HighLoad++, . (, , ).
telegram- . !