Antecipando o início do curso de Engenharia de Dados, preparamos uma tradução de um material pequeno, mas interessante.
Neste artigo, falarei sobre como o Parquet compacta grandes conjuntos de dados em um arquivo pequeno, e como podemos obter uma largura de banda que excede em muito a largura de banda do fluxo de E / S usando simultaneidade (multithreading).Apache Parquet: melhor com dados de baixa entropia
Como você pode entender pela especificação do formato Apache Parquet, ele contém vários níveis de codificação que podem alcançar uma redução significativa no tamanho do arquivo, entre os quais:- Codificação (compactação) usando um dicionário (semelhante ao pandas. Maneira categorizada de apresentar dados, mas os conceitos são diferentes);
- Compactação de páginas de dados (Snappy, Gzip, LZO ou Brotli);
- Codificação do comprimento de execução (para ponteiros nulos e índices do dicionário) e empacotamento de bits inteiros;
Para mostrar como isso funciona, vamos ver um conjunto de dados:['banana', 'banana', 'banana', 'banana', 'banana', 'banana',
'banana', 'banana', 'apple', 'apple', 'apple']
Quase todas as implementações do Parquet usam o dicionário padrão para compactação. Assim, os dados codificados são os seguintes:dictionary: ['banana', 'apple']
indices: [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1]
Os índices no dicionário também são compactados pelo algoritmo de codificação de repetição:dictionary: ['banana', 'apple']
indices (RLE): [(8, 0), (3, 1)]
Seguindo o caminho de retorno, você pode facilmente restaurar a matriz original de seqüências de caracteres.No meu artigo anterior , criei um conjunto de dados que se comprime muito bem dessa maneira. Ao trabalhar com pyarrow, podemos ativar e desativar a codificação usando o dicionário (que é ativado por padrão) para ver como isso afetará o tamanho do arquivo:import pyarrow.parquet as pq
pq.write_table(dataset, out_path, use_dictionary=True,
compression='snappy)
Um conjunto de dados que ocupa 1 GB (1024 MB) pandas.DataFrame, com compressão Snappy e compactação usando um dicionário, ocupa apenas 1.436 MB, ou seja, pode até ser gravado em um disquete. Sem compactação no dicionário, ele ocupará 44,4 MB.Leitura simultânea no parquet-cpp usando PyArrow
Na implementação do Apache Parquet em C ++ - parquet-cpp , que disponibilizamos para Python no PyArrow, foi adicionada a capacidade de ler colunas em paralelo.Para experimentar esse recurso, instale o PyArrow a partir do conda-forge :conda install pyarrow -c conda-forge
Agora, ao ler o arquivo Parquet, você pode usar o argumento nthreads:import pyarrow.parquet as pq
table = pq.read_table(file_path, nthreads=4)
Para dados de baixa entropia, a descompressão e decodificação estão fortemente ligadas ao processador. Como o C ++ faz todo o trabalho para nós, não há problemas com a simultaneidade do GIL e podemos obter um aumento significativo na velocidade. Veja o que consegui ao ler um conjunto de dados de 1 GB em um DataFrame do pandas em um laptop quad-core (Xeon E3-1505M, SSD NVMe):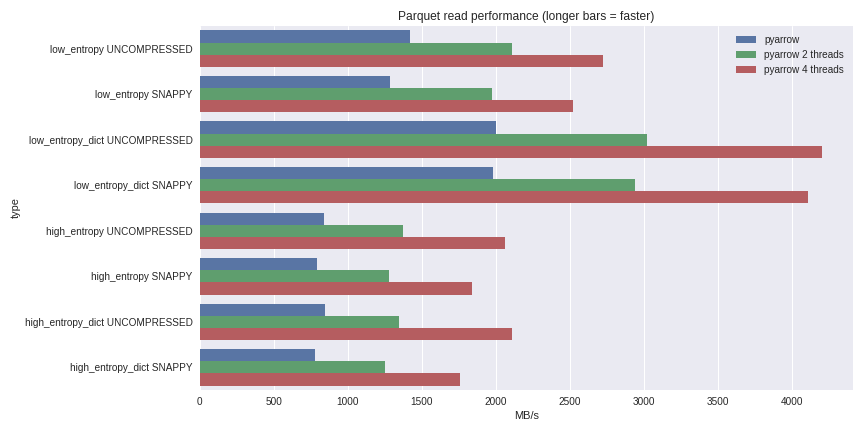 Você pode ver o cenário completo de benchmarking aqui .Eu incluí o desempenho aqui para casos de compactação usando um dicionário e casos sem usar um dicionário. Para dados com baixa entropia, apesar de todos os arquivos serem pequenos (~ 1,5 MB usando dicionários e ~ 45 MB sem), a compactação usando um dicionário afeta significativamente o desempenho. Com 4 threads, o desempenho de leitura dos pandas aumenta para 4 GB / s. Isso é muito mais rápido que o formato Feather ou qualquer outro que eu conheça.
Você pode ver o cenário completo de benchmarking aqui .Eu incluí o desempenho aqui para casos de compactação usando um dicionário e casos sem usar um dicionário. Para dados com baixa entropia, apesar de todos os arquivos serem pequenos (~ 1,5 MB usando dicionários e ~ 45 MB sem), a compactação usando um dicionário afeta significativamente o desempenho. Com 4 threads, o desempenho de leitura dos pandas aumenta para 4 GB / s. Isso é muito mais rápido que o formato Feather ou qualquer outro que eu conheça.Conclusão
Com o lançamento da versão 1.0 parquet-cpp (Apache Parquet em C ++), você pode ver por si mesmo o aumento do desempenho de E / S que agora está disponível para usuários do Python.Como todos os mecanismos básicos são implementados em C ++, em outras linguagens (por exemplo, R), é possível criar interfaces para o Apache Arrow (estruturas de dados colunares) e parquet-cpp . A ligação Python é um shell leve das principais bibliotecas libarrow e libparquet C ++.Isso é tudo. Se você quiser saber mais sobre o nosso curso, inscreva-se para um dia aberto , que será realizado hoje!