Olá, trabalho na equipe de projeto do RRP KP (registro de dados distribuídos para monitorar o ciclo de vida dos rodados). Aqui, quero compartilhar a experiência de nossa equipe no desenvolvimento de uma blockchain corporativa para este projeto, nas condições impostas pela tecnologia. Na maioria das vezes, falarei sobre o Hyperledger Fabric, mas a abordagem descrita aqui pode ser extrapolada para qualquer blockchain permitido. O objetivo final de nossa pesquisa é preparar soluções corporativas de blockchain para que o produto final seja agradável de usar e não muito difícil de manter.Não haverá descobertas, soluções inesperadas e nenhum desenvolvimento exclusivo será abordado aqui (porque eu não os tenho). Eu só quero compartilhar minha modesta experiência, mostrar que "era possível" e, talvez, ler sobre as experiências de outras pessoas na tomada de decisões boas e não tão boas nos comentários.Problema: as blockchains ainda não estão dimensionadas
Hoje, os esforços de muitos desenvolvedores visam tornar o blockchain uma tecnologia realmente conveniente, e não uma bomba-relógio em um belo invólucro. Canais de estado, agregação otimista, plasma e fragmentação podem se tornar todos os dias. Algum dia. Ou talvez a TON adie novamente o lançamento por seis meses, e o próximo Grupo de Plasma deixará de existir. Podemos acreditar em outro roteiro e ler white papers brilhantes para a noite, mas aqui e agora precisamos fazer algo com o que temos. Faça merda.A tarefa definida para nossa equipe no projeto atual se parece com isso em geral: existem muitas entidades atingindo vários milhares, não desejando construir relacionamentos com confiança; é necessário criar uma solução desse tipo no DLT que funcione em PCs comuns sem requisitos especiais de desempenho e forneça uma experiência do usuário não pior que qualquer sistema de contabilidade centralizado. A tecnologia subjacente à solução deve minimizar a possibilidade de manipulação maliciosa de dados - é por isso que o blockchain está aqui.Slogans de documentos técnicos e da mídia nos prometem que o próximo desenvolvimento permitirá que você faça milhões de transações por segundo. O que é realmente?O Mainnet Ethereum está agora rodando a ~ 30 tps. Já por causa disso, é difícil percebê-lo como qualquer blockchain adequado para as necessidades corporativas. Entre as soluções autorizadas, são conhecidos benchmarks, mostrando 2000 tps ( Quorum ) ou 3000 tps ( Hyperledger Fabric , a publicação é um pouco menor, mas é necessário considerar que o benchmark foi realizado no antigo mecanismo de consenso). Houve uma tentativa de revisar radicalmente o Fabric , que não deu os piores resultados, 20.000 tps, mas até agora essa é apenas uma pesquisa acadêmica aguardando sua implementação estável. É improvável que uma empresa que possa manter um departamento de desenvolvedores de blockchain atenda a esses indicadores. Mas o problema não é apenas a taxa de transferência, ainda há latência.Latência
O atraso a partir do momento em que a transação é iniciada até sua aprovação final pelo sistema depende não apenas da velocidade da mensagem que passa por todas as etapas de validação e pedido, mas também dos parâmetros de formação do bloco. Mesmo que nossa blockchain nos permita confirmar a uma velocidade de 1.000.000 tps, mas leva 10 minutos para formar um bloco de 488 MB, será mais fácil para nós?Vamos dar uma olhada no ciclo de vida da transação no Hyperledger Fabric para entender em que tempo é gasto e como ele se relaciona com os parâmetros de formação de blocos.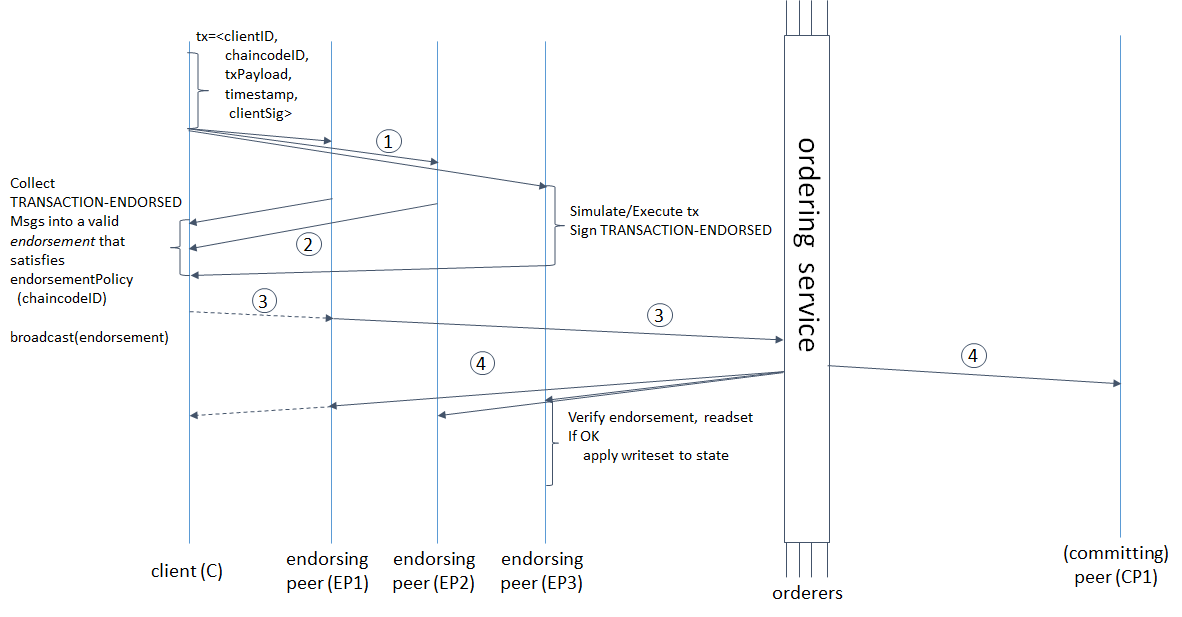 extraído daqui : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) O cliente gera uma transação, envia para endossar pares, este simula a transação (aplica as alterações feitas pelo código de código no estado atual, mas não se compromete com o razão) e obtém RWSet - nomes de chave, versões e valores retirados da coleção no CouchDB ( 2) os endossantes enviam de volta o RWSet assinado ao cliente; (3) o cliente verifica as assinaturas de todos os pares necessários (endossantes) e depois envia a transação ao serviço de pedidos ou a envia sem verificação (a verificação ainda ocorrerá posteriormente), o serviço de pedidos forma um bloco e ( 4) envia de volta a todos os pares, não apenas aos endossantes; os pares verificam se as versões principais do conjunto de leitura correspondem às versões no banco de dados, às assinaturas de todos os endossantes e, finalmente, confirmam o bloco.Mas isso não é tudo. As palavras "ordem forma um bloco" ocultam não apenas a ordem das transações, mas também 3 solicitações de rede consecutivas do líder para os seguidores e vice-versa: o líder adiciona uma mensagem ao log, envia seguidores, o último adiciona ao log, envia a confirmação da replicação bem-sucedida ao líder, o líder confirma uma mensagem , envia uma confirmação de confirmação aos seguidores, os seguidores confirmam. Quanto menor o tamanho e o tempo de formação do bloco, mais frequentemente será necessário que o serviço de pedidos estabeleça consenso. O Hyperledger Fabric possui dois parâmetros de formação de bloco: BatchTimeout - hora da formação do bloco e BatchSize - tamanho do bloco (número de transações e o tamanho do próprio bloco em bytes). Assim que um dos parâmetros atinge o limite, um novo bloco é liberado. Quanto mais nós de garantia, mais tempo levará. Portanto, você precisa aumentar o BatchTimeout e o BatchSize. Porém, como os RWSets são versionados, quanto mais criamos um bloco, maior a probabilidade de conflitos de MVCC. Além disso, com um aumento no BatchTimeout, o UX é catastroficamente degradante. Parece-me razoável e óbvio o seguinte esquema para resolver esses problemas.
extraído daqui : hyperledger-fabric.readthedocs.io/en/release-1.4/arch-deep-dive.html#swimlane(1) O cliente gera uma transação, envia para endossar pares, este simula a transação (aplica as alterações feitas pelo código de código no estado atual, mas não se compromete com o razão) e obtém RWSet - nomes de chave, versões e valores retirados da coleção no CouchDB ( 2) os endossantes enviam de volta o RWSet assinado ao cliente; (3) o cliente verifica as assinaturas de todos os pares necessários (endossantes) e depois envia a transação ao serviço de pedidos ou a envia sem verificação (a verificação ainda ocorrerá posteriormente), o serviço de pedidos forma um bloco e ( 4) envia de volta a todos os pares, não apenas aos endossantes; os pares verificam se as versões principais do conjunto de leitura correspondem às versões no banco de dados, às assinaturas de todos os endossantes e, finalmente, confirmam o bloco.Mas isso não é tudo. As palavras "ordem forma um bloco" ocultam não apenas a ordem das transações, mas também 3 solicitações de rede consecutivas do líder para os seguidores e vice-versa: o líder adiciona uma mensagem ao log, envia seguidores, o último adiciona ao log, envia a confirmação da replicação bem-sucedida ao líder, o líder confirma uma mensagem , envia uma confirmação de confirmação aos seguidores, os seguidores confirmam. Quanto menor o tamanho e o tempo de formação do bloco, mais frequentemente será necessário que o serviço de pedidos estabeleça consenso. O Hyperledger Fabric possui dois parâmetros de formação de bloco: BatchTimeout - hora da formação do bloco e BatchSize - tamanho do bloco (número de transações e o tamanho do próprio bloco em bytes). Assim que um dos parâmetros atinge o limite, um novo bloco é liberado. Quanto mais nós de garantia, mais tempo levará. Portanto, você precisa aumentar o BatchTimeout e o BatchSize. Porém, como os RWSets são versionados, quanto mais criamos um bloco, maior a probabilidade de conflitos de MVCC. Além disso, com um aumento no BatchTimeout, o UX é catastroficamente degradante. Parece-me razoável e óbvio o seguinte esquema para resolver esses problemas.Evite esperar pela finalização do bloco e não perca a capacidade de rastrear o status da transação
Quanto maior o tempo de formação e o tamanho do bloco, maior o rendimento da blockchain. Um dos outros não segue diretamente, mas deve-se lembrar que a construção de consenso na RAFT exige três solicitações de rede do líder aos seguidores e vice-versa. Quanto mais nós de pedidos, mais tempo será necessário. Quanto menor o tamanho e o tempo de formação do bloco, mais essas interações. Como aumentar o tempo de formação e o tamanho do bloco sem aumentar o tempo de espera de uma resposta do sistema para o usuário final?Em primeiro lugar, é necessário resolver de alguma forma os conflitos MVCC causados por um tamanho de bloco grande, que pode incluir RWSets diferentes com a mesma versão. Obviamente, no lado do cliente (em relação à rede blockchain, isso pode muito bem ser um back-end, e eu quero dizer isso), precisamos de um manipulador de conflitos MVCC, que pode ser um serviço separado ou um decorador regular em uma chamada de acionamento de transação com lógica de repetição.A nova tentativa pode ser implementada com uma estratégia exponencial, mas a latência diminuirá da mesma forma exponencial. Portanto, você deve usar uma nova tentativa aleatória dentro de certos limites pequenos ou uma permanente. De olho em possíveis conflitos na primeira modalidade.A próxima etapa é tornar a interação do cliente com o sistema assíncrona, para que não espere 15, 30 ou 10.000.000 segundos, que definiremos como BatchTimeout. Mas, ao mesmo tempo, você precisa salvar a oportunidade de garantir que as alterações iniciadas pela transação sejam gravadas / não gravadas no blockchain.Você pode usar um banco de dados para armazenar o status da transação. A opção mais fácil é o CouchDB devido à facilidade de uso: o banco de dados possui uma interface do usuário pronta para uso, uma API REST, e você pode configurar facilmente a replicação e o sharding. Você pode criar apenas uma coleção separada na mesma instância do CouchDB que o Fabric usa para armazenar seu estado mundial. Precisamos armazenar documentos desse tipo.{
Status string
TxID: string
Error: string
}
Este documento é gravado no banco de dados antes que a transação seja transferida para pares, um ID de entidade é retornado ao usuário (o mesmo ID é usado como chave) se esta for uma operação para criar algo e, em seguida, os campos Status, TxID e Erro são atualizados conforme as informações relevantes dos pares são recebidas. Nesse esquema, o usuário não espera o bloco finalmente se formar, observando a roda giratória na tela por 10 segundos, recebe uma resposta instantânea do sistema e continua a trabalhar.Escolhemos o BoltDB para armazenar status de transação, porque precisamos economizar memória e não queremos gastar tempo na interação de rede com um servidor de banco de dados independente, especialmente quando essa interação ocorre usando o protocolo de texto sem formatação. A propósito, você usa o CouchDB para implementar o esquema descrito acima ou apenas para armazenar o estado mundial; em qualquer caso, faz sentido otimizar a maneira como os dados são armazenados no CouchDB. Por padrão, no CouchDB, o tamanho dos nós da árvore b é de 1279 bytes, que é muito menor que o tamanho do setor no disco, o que significa que a leitura e o reequilíbrio da árvore exigirão mais acesso físico ao disco. O tamanho ideal está em conformidade com o padrão Advanced Format e é de 4 kilobytes. Para otimização, precisamos definir o parâmetro btree_chunk_size como 4096no arquivo de configuração do CouchDB. Para o BoltDB, essa intervenção manual não é necessária .
Nesse esquema, o usuário não espera o bloco finalmente se formar, observando a roda giratória na tela por 10 segundos, recebe uma resposta instantânea do sistema e continua a trabalhar.Escolhemos o BoltDB para armazenar status de transação, porque precisamos economizar memória e não queremos gastar tempo na interação de rede com um servidor de banco de dados independente, especialmente quando essa interação ocorre usando o protocolo de texto sem formatação. A propósito, você usa o CouchDB para implementar o esquema descrito acima ou apenas para armazenar o estado mundial; em qualquer caso, faz sentido otimizar a maneira como os dados são armazenados no CouchDB. Por padrão, no CouchDB, o tamanho dos nós da árvore b é de 1279 bytes, que é muito menor que o tamanho do setor no disco, o que significa que a leitura e o reequilíbrio da árvore exigirão mais acesso físico ao disco. O tamanho ideal está em conformidade com o padrão Advanced Format e é de 4 kilobytes. Para otimização, precisamos definir o parâmetro btree_chunk_size como 4096no arquivo de configuração do CouchDB. Para o BoltDB, essa intervenção manual não é necessária .Contrapressão: estratégia de buffer
Mas pode haver muitas mensagens. Mais do que o sistema é capaz de processar, compartilhando recursos com uma dúzia de outros serviços além dos mostrados no diagrama - e tudo isso deve funcionar sem falhas, mesmo em máquinas nas quais o lançamento do Intellij Idea será extremamente tedioso.O problema dos diferentes rendimentos dos sistemas de comunicação, produtor e consumidor, é resolvido de diferentes maneiras. Vamos ver o que poderíamos fazer.Eliminação : podemos afirmar que somos capazes de processar não mais que X transações em T segundos. Todas as solicitações que excedem esse limite são redefinidas. É bem simples, mas você pode esquecer o UX.Controlando: o consumidor deve ter alguma interface através da qual, dependendo da carga, ele poderá controlar os tps do produtor. Nada mal, mas impõe obrigações aos desenvolvedores do cliente, criando a carga para implementar essa interface. Para nós, isso é inaceitável, uma vez que a blockchain no futuro será integrada a um grande número de sistemas já existentes.Buffer : Em vez de tentar resistir ao fluxo de dados de entrada, podemos armazenar em buffer esse fluxo e processá-lo na velocidade necessária. Obviamente, essa é a melhor solução se queremos oferecer uma boa experiência ao usuário. Implementamos o buffer usando a fila no RabbitMQ. Duas novas ações foram adicionadas ao esquema: (1) depois de receber a solicitação da API, uma mensagem com os parâmetros necessários para chamar a transação é enfileirada e o cliente recebe uma mensagem de que a transação foi aceita pelo sistema; (2) o back-end lê os dados com a velocidade especificada na configuração da fila; inicia uma transação e atualiza os dados no armazenamento de status.Agora você pode aumentar o tempo de formação e bloquear a capacidade o quanto quiser, ocultando atrasos do usuário.
Duas novas ações foram adicionadas ao esquema: (1) depois de receber a solicitação da API, uma mensagem com os parâmetros necessários para chamar a transação é enfileirada e o cliente recebe uma mensagem de que a transação foi aceita pelo sistema; (2) o back-end lê os dados com a velocidade especificada na configuração da fila; inicia uma transação e atualiza os dados no armazenamento de status.Agora você pode aumentar o tempo de formação e bloquear a capacidade o quanto quiser, ocultando atrasos do usuário.Outras ferramentas
Nada foi dito aqui sobre o código de código, porque, como regra, não há nada para otimizar nele. O código de código deve ser o mais simples e seguro possível - isso é tudo o que é necessário. A gravação Cheynkod de maneira simples e segura nos ajuda a estruturar bastante o SSKit da S7 Techlab e o analisador estático Revive ^ CC .Além disso, nossa equipe está desenvolvendo um conjunto de utilitários para tornar o trabalho com o Fabric simples e agradável: um explorador de blockchain , um utilitário para alterar automaticamente a configuração de rede (adicionar / excluir organizações, nós RAFT), um utilitário para revogar certificados e remover identidade . Se você quiser contribuir - seja bem-vindo.Conclusão
Essa abordagem facilita a substituição do Hyperledger Fabric pelo Quorum, outras redes privadas Ethereum (PoA ou mesmo PoW), reduz significativamente a largura de banda real, mas ao mesmo tempo mantém o UX normal (tanto para usuários no navegador quanto para sistemas integrados). Ao substituir o Fabric pelo Ethereum no esquema, você precisará alterar apenas a lógica do serviço / decorador de nova tentativa de processar conflitos MVCC para o incremento atômico nonce e reenviar. O armazenamento em buffer e o status permitiram dissociar o tempo de resposta do tempo de formação do bloco. Agora você pode adicionar milhares de nós de pedidos e não ter medo de que os blocos sejam formados com muita frequência e carregar o serviço de pedidos.Em geral, é tudo o que eu quero compartilhar. Eu ficaria feliz se isso ajudar alguém em seu trabalho.