Nota perev. : Neste artigo, o Banzai Cloud compartilha um exemplo do uso de seus utilitários especiais para facilitar a operação do Kafka no Kubernetes. Estas instruções ilustram como você pode determinar o tamanho ideal da infraestrutura e configurar o próprio Kafka para alcançar a taxa de transferência necessária. O Apache Kafka é uma plataforma de streaming distribuída para criar sistemas de streaming confiáveis, escaláveis e de alto desempenho em tempo real. Seus recursos impressionantes podem ser expandidos com o Kubernetes. Para isso, desenvolvemos o operador Kafka Open Source e uma ferramenta chamada Supertubes. Eles permitem executar o Kafka no Kubernetes e usar suas várias funções, como ajustar a configuração do broker, escalar com base em métricas com rebalanceamento, reconhecimento do rack (conhecimento dos recursos de hardware), atualizações contínuas "suaves" (graciosas) , etc.
O Apache Kafka é uma plataforma de streaming distribuída para criar sistemas de streaming confiáveis, escaláveis e de alto desempenho em tempo real. Seus recursos impressionantes podem ser expandidos com o Kubernetes. Para isso, desenvolvemos o operador Kafka Open Source e uma ferramenta chamada Supertubes. Eles permitem executar o Kafka no Kubernetes e usar suas várias funções, como ajustar a configuração do broker, escalar com base em métricas com rebalanceamento, reconhecimento do rack (conhecimento dos recursos de hardware), atualizações contínuas "suaves" (graciosas) , etc.Experimente os Supertubes no seu cluster:
curl https://getsupertubes.sh | sh supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
Ou consulte a documentação . Você também pode ler sobre alguns dos recursos do Kafka, que são automatizados com a ajuda dos Supertubes e do operador Kafka. Já escrevemos sobre eles no blog:
Quando você decide implantar um cluster Kafka no Kubernetes, provavelmente encontrará o problema de determinar o tamanho ideal da infraestrutura subjacente e a necessidade de ajustar a configuração Kafka para atender aos requisitos de largura de banda. O desempenho máximo de cada broker é determinado pelo desempenho dos componentes da infraestrutura em seu núcleo, como memória, processador, velocidade do disco, largura de banda da rede etc.Idealmente, a configuração do broker deve ser tal que todos os elementos da infraestrutura sejam utilizados ao máximo de seus recursos. No entanto, na vida real, essa configuração é muito complicada. É mais provável que os usuários configurem os intermediários de forma a maximizar o uso de um ou dois componentes (disco, memória ou processador). De um modo geral, um broker mostra desempenho máximo quando sua configuração permite que você use o componente mais lento "na íntegra". Portanto, podemos ter uma idéia aproximada da carga que um corretor pode suportar.Teoricamente, também podemos estimar o número de corretores necessários para trabalhar com uma determinada carga. No entanto, na prática, existem tantas opções de configuração em vários níveis que é muito difícil (se não impossível) avaliar o desempenho potencial de uma determinada configuração. Em outras palavras, é muito difícil planejar a configuração, começando com um determinado desempenho.Para usuários do Supertubes, geralmente adotamos a seguinte abordagem: comece com algumas configurações (infraestrutura + configurações), depois avalie seu desempenho, ajuste as configurações do broker e repita o processo novamente. Isso acontece até que o potencial do componente mais lento da infraestrutura seja totalmente utilizado.Dessa forma, temos uma idéia mais clara de quantos intermediários um cluster precisa para lidar com uma certa carga (o número de intermediários também depende de outros fatores, como o número mínimo de réplicas de mensagens para garantir a estabilidade, o número de líderes de partição etc.). Além disso, temos uma idéia de qual escala vertical de componente de infraestrutura é desejada.Este artigo discutirá as etapas que tomamos para "espremer tudo" dos componentes mais lentos nas configurações iniciais e medir a taxa de transferência do cluster Kafka. Uma configuração altamente resiliente requer pelo menos três agentes de trabalho (min.insync.replicas=3) espaçados em três zonas de acessibilidade diferentes. Para configurar, dimensionar e monitorar a infraestrutura Kubernetes, usamos nossa própria plataforma de gerenciamento de contêiner de nuvem híbrida - Pipeline . Ele suporta no local (bare metal, VMware) e cinco tipos de nuvens (Alibaba, AWS, Azure, Google, Oracle), bem como qualquer combinação dos mesmos.Reflexões sobre a infraestrutura e a configuração do cluster Kafka
Para os exemplos abaixo, selecionamos a AWS como o provedor de serviços em nuvem e o EKS como a distribuição Kubernetes. Uma configuração semelhante pode ser implementada usando o PKE , uma distribuição Kubernetes da Banzai Cloud, certificada pelo CNCF.Disco
A Amazon oferece vários tipos de volumes EBS . Os SSDs são a base de gp2 e io1 , no entanto, para garantir alto rendimento, o gp2 consome empréstimos acumulados (créditos de E / S) ; portanto, preferimos o tipo io1 , que oferece alto rendimento estável.Tipos de Instância
O desempenho do Kafka é altamente dependente do cache de páginas do sistema operacional, portanto, precisamos de instâncias com memória suficiente para JVMs e cache de páginas. A instância c5.2xlarge é um bom começo, pois possui 16 GB de memória e é otimizada para trabalhar com o EBS . Sua desvantagem é que ele é capaz de fornecer desempenho máximo por não mais de 30 minutos a cada 24 horas. Se sua carga de trabalho exigir desempenho máximo por um período maior, observe outros tipos de instâncias. Fizemos exatamente isso, parando em c5.4xlarge . Ele fornece uma taxa de transferência máxima de 593,75 Mb / s.. A taxa de transferência máxima do volume EBS io1 é maior que a da instância c5.4xlarge ; portanto, o elemento de infraestrutura mais lento é provavelmente a taxa de transferência de E / S desse tipo de instância (que também deve ser confirmada pelos resultados de nossos testes de carga).Rede
A largura de banda da rede deve ser muito grande em comparação com o desempenho da instância e do disco da VM, caso contrário, a rede se tornará um gargalo. No nosso caso, a interface de rede c5.4xlarge suporta velocidades de até 10 Gb / s, o que é significativamente maior que a largura de banda da instância de E / S da VM.Implantação do Broker
Os intermediários devem ser implantados (planejados no Kubernetes) em nós dedicados, a fim de evitar a concorrência com outros processos de recursos de processador, memória, rede e disco.Versão Java
A escolha lógica é Java 11, porque é compatível com o Docker no sentido de que a JVM determina corretamente os processadores e a memória disponível para o contêiner no qual o broker é executado. Sabendo que os limites do processador são importantes, a JVM define interna e transparentemente o número de threads do GC e do compilador JIT. Usamos uma imagem Kafka banzaicloud/kafka:2.13-2.4.0que inclui a versão 2.4.0 do Kafka (Scala 2.13) no Java 11.Se você quiser saber mais sobre Java / JVM no Kubernetes, consulte nossas publicações a seguir:
Configurações de memória do corretor
Há dois aspectos principais na configuração da memória do broker: configurações para a JVM e para o pod Kubernetes. O limite de memória definido para o pod deve ser maior que o tamanho máximo de heap para que a JVM tenha espaço suficiente para o metasspace de Java em sua própria memória e para o cache da página do sistema operacional que Kafka está usando ativamente. Em nossos testes, lançamos os corretores Kafka com parâmetros -Xmx4G -Xms2G, e o limite de memória para o pod era 10 Gi. Observe que as configurações de memória para a JVM podem ser obtidas automaticamente usando -XX:MaxRAMPercentagee -X:MinRAMPercentage, com base no limite de memória para o pod.Configurações do processador do intermediário
De um modo geral, você pode aumentar a produtividade aumentando a simultaneidade aumentando o número de threads usados pelo Kafka. Quanto mais processadores disponíveis para o Kafka, melhor. Em nosso teste, começamos com um limite de 6 processadores e gradualmente (iteramos) aumentamos seu número para 15. Além disso, definimos num.network.threads=12nas configurações do broker para aumentar o número de fluxos que recebem dados da rede e os enviam. Tendo descoberto imediatamente que os intermediários seguidores não podem receber réplicas com rapidez suficiente, eles aumentaram num.replica.fetcherspara 4 para aumentar a velocidade com que os intermediários replicadores replicavam mensagens dos líderes.Ferramenta de geração de carga
Certifique-se de que o potencial do gerador de carga selecionado não se esgote antes que o cluster Kafka (cujo benchmark esteja em execução) atinja sua carga máxima. Em outras palavras, é necessário realizar uma avaliação preliminar dos recursos da ferramenta de geração de carga, bem como selecionar tipos de instâncias para ela com um número suficiente de processadores e memória. Nesse caso, nossa ferramenta produzirá mais carga do que o cluster Kafka pode digerir. Após muitas experiências, decidimos por três cópias de c5.4xlarge , em cada uma das quais o gerador foi lançado.avaliação comparativa
A medição de desempenho é um processo iterativo que inclui as seguintes etapas:- configuração da infraestrutura (cluster EKS, cluster Kafka, ferramenta de geração de carga, além de Prometheus e Grafana);
- geração de carga por um determinado período para filtrar desvios aleatórios nos indicadores de desempenho coletados;
- ajuste fino da infraestrutura e configuração do broker com base nos indicadores de desempenho observados;
- repetindo o processo até que o nível necessário de largura de banda do cluster Kafka seja atingido. Ao mesmo tempo, deve ser reproduzível de forma estável e demonstrar variações mínimas de largura de banda.
A próxima seção descreve as etapas que foram executadas durante o cluster de teste de benchmark.Ferramentas
As seguintes ferramentas foram usadas para implantar rapidamente a configuração básica, geração de carga e medição de desempenho:- Banzai Cloud Pipeline EKS Amazon c Prometheus ( Kafka ) Grafana ( ). Pipeline , , , , , .
- Sangrenel — Kafka.
- Grafana Kafka : Kubernetes Kafka, Node Exporter.
- Supertubes CLI para a maneira mais fácil de configurar um cluster Kafka no Kubernetes. O Zookeeper, o operador Kafka, o Envoy e muitos outros componentes estão instalados e configurados adequadamente para executar o cluster Kafka pronto para produção no Kubernetes.
- Para instalar supertubes CLI, use as instruções fornecidas aqui .

Cluster EKS
Prepare um cluster EKS com nós de trabalho c5.4xlarge dedicados em várias zonas de disponibilidade para pods com intermediários Kafka, bem como nós dedicados para o gerador de carga e a infraestrutura de monitoramento.banzai cluster create -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/cluster_eks_202001.json
Quando o cluster EKS estiver operacional, ative seu serviço de monitoramento integrado - ele implementará o Prometheus e o Grafana no cluster.Componentes do sistema Kafka
Instale os componentes do sistema Kafka (Zookeeper, kafka-operator) no EKS usando CLI de supertubos:supertubes install -a --no-democluster --kubeconfig <path-to-eks-cluster-kubeconfig-file>
Kafka Cluster
Por padrão, o EKS usa volumes gp2 EBS , portanto, você precisa criar uma classe de armazenamento separada com base nos volumes io1 para o cluster Kafka:kubectl create -f - <<EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: io1
iopsPerGB: "50"
fsType: ext4
volumeBindingMode: WaitForFirstConsumer
EOF
Defina um parâmetro para intermediários min.insync.replicas=3e implemente pods de intermediários em nós em três zonas de disponibilidade diferentes:supertubes cluster create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f https://raw.githubusercontent.com/banzaicloud/kafka-operator/master/docs/benchmarks/infrastructure/kafka_202001_3brokers.yaml --wait --timeout 600
Tópicos
Lançamos simultaneamente três instâncias do gerador de carga. Cada um deles escreve em seu próprio tópico, ou seja, tudo o que precisamos é de três tópicos:supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest1
spec:
name: perftest1
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest2
spec:
name: perftest2
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
supertubes cluster topic create -n kafka --kubeconfig <path-to-eks-cluster-kubeconfig-file> -f -<<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: perftest3
spec:
name: perftest3
partitions: 12
replicationFactor: 3
retention.ms: '28800000'
cleanup.policy: delete
EOF
Para cada tópico, o fator de replicação é 3 - o valor mínimo recomendado para sistemas de produção altamente disponíveis.Ferramenta de geração de carga
Lançamos três instâncias do gerador de carga (cada uma escreveu em um tópico separado). Para pods do gerador de carga, é necessário registrar a afinidade do nó para que eles sejam planejados apenas nos nós alocados para eles:apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: loadtest
name: perf-load1
namespace: kafka
spec:
progressDeadlineSeconds: 600
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: loadtest
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
creationTimestamp: null
labels:
app: loadtest
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: nodepool.banzaicloud.io/name
operator: In
values:
- loadgen
containers:
- args:
- -brokers=kafka-0:29092,kafka-1:29092,kafka-2:29092,kafka-3:29092
- -topic=perftest1
- -required-acks=all
- -message-size=512
- -workers=20
image: banzaicloud/perfload:0.1.0-blog
imagePullPolicy: Always
name: sangrenel
resources:
limits:
cpu: 2
memory: 1Gi
requests:
cpu: 2
memory: 1Gi
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
dnsPolicy: ClusterFirst
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
terminationGracePeriodSeconds: 30
Alguns pontos para prestar atenção:- O gerador de carregamento gera mensagens de 512 bytes e as publica no Kafka em lotes de 500 mensagens.
-required-acks=all , Kafka. , , , , . (consumers) , , , .- 20 worker' (
-workers=20). worker 5 producer', worker' Kafka. 100 producer', Kafka.
Monitoramento de Cluster
Durante o teste de estresse do cluster Kafka, também monitoramos sua integridade para garantir que não houvesse reinicializações de pod, réplicas fora de sincronia e taxa de transferência máxima com flutuações mínimas:Resultados de medição
3 intermediários, tamanho da mensagem - 512 bytes
Com partições distribuídas igualmente entre três intermediários, conseguimos obter um desempenho de ~ 500 Mb / s (aproximadamente 990 mil mensagens por segundo) :

 O consumo de memória da máquina virtual da JVM não excedeu 2 GB:
O consumo de memória da máquina virtual da JVM não excedeu 2 GB:

 A largura de banda do disco atingiu a largura de banda máxima de E / S o nó nas três instâncias em que os intermediários trabalharam:
A largura de banda do disco atingiu a largura de banda máxima de E / S o nó nas três instâncias em que os intermediários trabalharam: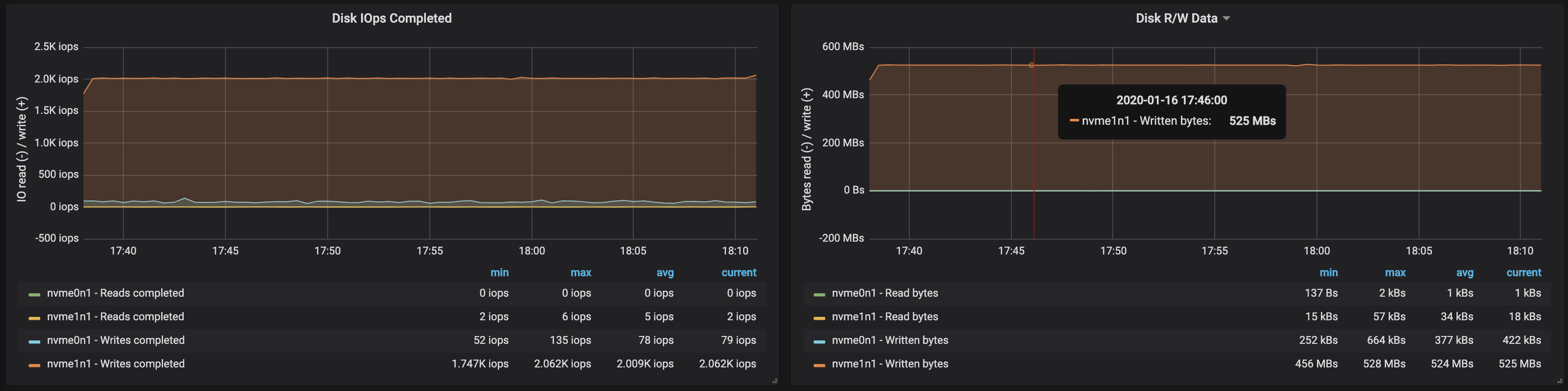

 A partir dos dados sobre o uso da memória pelos nós, segue-se que o buffer e o cache do sistema levaram de 10 a 15 GB:
A partir dos dados sobre o uso da memória pelos nós, segue-se que o buffer e o cache do sistema levaram de 10 a 15 GB:


3 intermediários, tamanho da mensagem - 100 bytes
Com uma diminuição no tamanho da mensagem, a taxa de transferência diminui de 15 a 20%: o tempo gasto no processamento de cada mensagem é afetado. Além disso, a carga do processador quase dobrou.

 Como os nós do broker ainda têm kernels não utilizados, você pode melhorar o desempenho alterando a configuração do Kafka. Esta não é uma tarefa fácil, portanto, para aumentar a taxa de transferência, é melhor trabalhar com mensagens maiores.
Como os nós do broker ainda têm kernels não utilizados, você pode melhorar o desempenho alterando a configuração do Kafka. Esta não é uma tarefa fácil, portanto, para aumentar a taxa de transferência, é melhor trabalhar com mensagens maiores.4 intermediários, tamanho da mensagem - 512 bytes
Você pode aumentar facilmente o desempenho do cluster Kafka simplesmente adicionando novos intermediários e mantendo o equilíbrio das partições (isso garante distribuição uniforme de carga entre os intermediários). No nosso caso, após adicionar um broker, a taxa de transferência do cluster aumentou para ~ 580 Mb / s (~ 1,1 milhão de mensagens por segundo) . O crescimento acabou sendo menor do que o esperado: isso se deve principalmente ao desequilíbrio das partições (nem todos os corretores trabalham no pico de oportunidades).


 O consumo de memória da máquina JVM permanece abaixo de 2 GB: O
O consumo de memória da máquina JVM permanece abaixo de 2 GB: O


 desequilíbrio de partição afetou a operação de intermediários com unidades:
desequilíbrio de partição afetou a operação de intermediários com unidades:



achados
A abordagem iterativa apresentada acima pode ser estendida para cobrir cenários mais complexos, incluindo centenas de consumidores, reparticionamento, atualizações contínuas, reinicializações de pods etc. Tudo isso nos permite avaliar os limites das capacidades do cluster Kafka em várias condições, identificar gargalos em seu trabalho e encontrar maneiras de lidar com eles.Desenvolvemos Supertubes para implantar de forma rápida e fácil um cluster, configurá-lo, adicionar / remover agentes e tópicos, responder a alertas e garantir que o Kafka funcione corretamente no Kubernetes como um todo. Nosso objetivo é ajudar a concentrar-se na tarefa principal (“gerar” e “consumir” mensagens Kafka) e fornecer todo o trabalho duro aos operadores de Supertubes e Kafka.Se você estiver interessado nas tecnologias Banzai Cloud e nos projetos de código aberto, assine a empresa no GitHub , LinkedIn ou Twitter .PS do tradutor
Leia também no nosso blog: