Uma tradução do artigo foi preparada antes do início do curso Machine Learning da OTUS.
Tarefa
Neste guia, usamos o conjunto de dados Bitcoin x USD .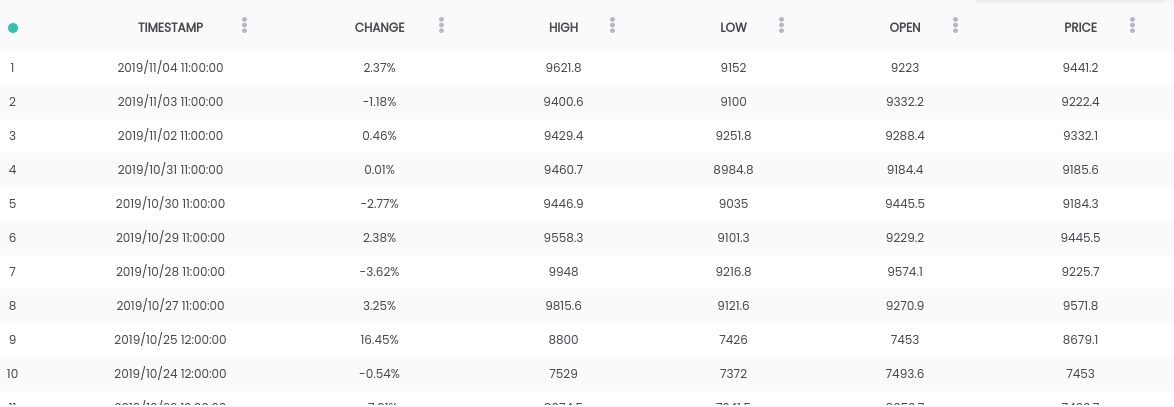 O conjunto de dados acima contém um resumo diário dos preços, em que a coluna CHANGE é a alteração do preço como uma porcentagem do preço do dia anterior ( PRICE ) versus o novo ( OPEN ).Objetivo: Para simplificar a tarefa, focaremos em prever se o preço aumentará ( CHANGE> 0 ) ou cairá ( CHANGE <0 ) no dia seguinte. (Para que possamos usar previsões "na vida real").Exigências
O conjunto de dados acima contém um resumo diário dos preços, em que a coluna CHANGE é a alteração do preço como uma porcentagem do preço do dia anterior ( PRICE ) versus o novo ( OPEN ).Objetivo: Para simplificar a tarefa, focaremos em prever se o preço aumentará ( CHANGE> 0 ) ou cairá ( CHANGE <0 ) no dia seguinte. (Para que possamos usar previsões "na vida real").Exigências- O Python 2.6+ ou 3.1+ deve estar instalado no sistema
- Instale pandas , sklearn e openblender (usando pip)
$ pip install pandas OpenBlender scikit-learn
Etapa 1. Obter dados de Bitcoin
Para começar, vamos importar as bibliotecas necessárias:import OpenBlender
import pandas as pd
import json
Agora puxe os dados pela API do OpenBlender .Primeiro, vamos definir os parâmetros (no nosso caso, este é apenas o ID do conjunto de dados bitcoin ):
parameters = {
'id_dataset':'5d4c3af79516290b01c83f51'
}
Nota: você precisará criar uma conta no openblender.io (gratuito) e adicionar um token (você o encontrará na guia "Conta"):parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51'
}
Agora vamos colocar os dados no Dataframe 'df' :
def pullObservationsToDF(parameters):
action = 'API_getObservationsFromDataset'
df = pd.read_json(json.dumps(OpenBlender.call(action,parameters)['sample']), convert_dates=False,convert_axes=False) .sort_values('timestamp', ascending=False)
df.reset_index(drop=True, inplace=True)
return df
df = pullObservationsToDF(parameters)
E observe-os: Nota: os valores podem variar, pois o conjunto de dados é atualizado diariamente !
Nota: os valores podem variar, pois o conjunto de dados é atualizado diariamente !Etapa 2. Preparação dos Dados
Para começar, precisamos criar uma meta de previsão, que será se " CHANGE " aumentará ou diminuirá. Para fazer isso, adicione 'success_thr_over': 0 aos parâmetros de limite de destino:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change', 'success_thr_over': 0}
}
Se extrairmos os dados da API novamente:df = pullObservationsToDF(parameters)
df.head()
 O atributo "CHANGE" foi substituído por um novo atributo 'change_over_0', que se torna 1 se "CHANGE" for positivo e 0 se não. Este será um objetivo de aprendizado de máquina.Se quisermos prever a observação para "amanhã", não poderemos usar as informações a partir de amanhã, portanto, vamos adicionar um atraso de um período.
O atributo "CHANGE" foi substituído por um novo atributo 'change_over_0', que se torna 1 se "CHANGE" for positivo e 0 se não. Este será um objetivo de aprendizado de máquina.Se quisermos prever a observação para "amanhã", não poderemos usar as informações a partir de amanhã, portanto, vamos adicionar um atraso de um período.parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold':{'feature':'change','success_thr_over' : 0},
'lag_target_feature':{'feature':'change_over_0', 'periods' : 1}
}
df = pullObservationsToDF(parameters)
df.head()
 Isso simplesmente alinha 'change_over_0' com os dados do dia anterior (período) e altera seu nome para 'TARGET_change_over_0' .Vejamos a dependência:
Isso simplesmente alinha 'change_over_0' com os dados do dia anterior (período) e altera seu nome para 'TARGET_change_over_0' .Vejamos a dependência:target_variable = 'TARGET_change_over_0'
df = df.dropna()
df.corr()[target_variable].sort_values()
 Eles são linearmente independentes e dificilmente serão úteis.
Eles são linearmente independentes e dificilmente serão úteis.Etapa 3. Obter dados de notícias de negócios
Depois de procurar dependências no OpenBlender , encontrei o conjunto de dados do Fox Business News que ajudará a gerar boas previsões para o nosso objetivo. Precisamos encontrar uma maneira de converter os valores da coluna 'title' em características numéricas, contando as repetições de palavras e grupos de palavras no resumo de notícias e comparando-os em tempo com nosso conjunto de dados bitcoin. É mais fácil do que parece.Primeiro, você precisa criar um TextVectorizer para o atributo 'title' das notícias:
Precisamos encontrar uma maneira de converter os valores da coluna 'title' em características numéricas, contando as repetições de palavras e grupos de palavras no resumo de notícias e comparando-os em tempo com nosso conjunto de dados bitcoin. É mais fácil do que parece.Primeiro, você precisa criar um TextVectorizer para o atributo 'title' das notícias:action = 'API_createTextVectorizer'
vectorizer_parameters = {
'token' : 'your_token',
'name' : 'Fox Business TextVectorizer',
'sources':[{'id_dataset' : '5d571f9e9516293a12ad4f6d',
'features' : ['title']}],
'ngram_range' : {'min' : 1, 'max' : 2},
'language' : 'en',
'remove_stop_words' : 'on',
'min_count_limit' : 2
}
Criaremos um vetorizador para obter todos os sinais como palavras simbólicas na forma de números. Acima, indicamos o seguinte:- nome : vamos chamá-lo de 'Fox Business TextVectorizer' ;
- anchor : id do conjunto de dados e o nome das características que precisaremos usar como fonte (no nosso caso, apenas a coluna 'title' );
- ngram_range : comprimento mínimo e máximo de um conjunto de palavras para tokenização;
- idioma : inglês
- remove_stop_words : para remover palavras de parada da fonte;
- min_count_limit : o número mínimo de repetições que devem ser consideradas como um token (ocorrências únicas raramente são úteis).
Agora execute isso:res = OpenBlender.call(action, vectorizer_parameters)
res
Responda:{
'message' : 'TextVectorizer created successfully.'
'id_textVectorizer' : '5dc1a404951629331f6359dd',
'num_ngrams': 4270
}
Foi criado o TextVectorizer , que gerou 4270 n-gramas de acordo com a nossa configuração. Um pouco mais tarde, precisaremos do ID gerado:5dc1a404951629331f6359ddEtapa 4. Resumo de notícias compatível com conjunto de dados bitcoin
Agora precisamos comparar o resumo das notícias e os dados da taxa de câmbio do bitcoin a tempo. Em geral, isso significa que você precisa combinar dois conjuntos de dados usando um carimbo de data / hora como chave. Vamos adicionar os dados combinados às nossas opções originais de extração de dados:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'specifications':{'time_interval_size' : 3600*12 }}]
}
Acima, indicamos o seguinte:- id_blend : id do nosso textVectorizer;
- blend_type : 'text_ts' para que o Python entenda que é uma mistura de texto e carimbo de data e hora;
- restrição : 'preditiva' , para que não haja "mistura" de notícias do futuro com todas as observações, mas apenas com aquelas publicadas antes do tempo especificado.
- blend_class : 'closest_observation' , para que apenas as observações mais próximas sejam "misturadas";
- especificações : a quantidade máxima possível de tempo decorrido para a transferência da observação, neste caso 12 horas (3600 * 12). Isso significa que todas as observações sobre o preço do bitcoin serão previstas com base nas notícias das últimas 12 horas.
Por fim, apenas adicionamos um filtro pela data 'date_filter' , a partir de 20 de agosto, porque foi quando o Fox News começou a coletar dados e 'drop_non_numeric' para obter apenas números:parameters = {
'token':'your_token',
'id_dataset':'5d4c3af79516290b01c83f51',
'target_threshold' : {'feature':'change','success_thr_over':0},
'lag_target_feature' : {'feature':'change_over_0', 'periods':1},
'blends':[{'id_blend':'5dc1a404951629331f6359dd',
'blend_type' : 'text_ts',
'restriction' : 'predictive',
'blend_class' : 'closest_observation',
'specifications':{'time_interval_size' : 3600*12 }}],
'date_filter':{'start_date':'2019-08-20T16:59:35.825Z',
'end_date':'2019-11-04T17:59:35.825Z'},
'drop_non_numeric' : 1
}
Nota : eu indiquei 4 de novembro como 'end_date' , pois foi no dia em que escrevi esse código, você pode alterar a data.Vamos obter os dados novamente:df = pullObservationsToDF(parameters)
print(df.shape)
df.head()
(57, 2115) Agora temos mais de 2000 sinais com tokens e 57 observações.
Agora temos mais de 2000 sinais com tokens e 57 observações.Etapa 5. Aplique ML ao destino de previsão
Agora, finalmente, temos um conjunto de dados limpo e parece exatamente o que precisamos, com um deslocamento de tempo do destino e dos dados numéricos associados.Vejamos as correlações mais altas com 'Target_change_over_0' : Agora, temos alguns atributos correlatos. Vamos dividir o conjunto de dados em treinamento e teste em ordem cronológica, para que possamos treinar o modelo em observações iniciais e testar em observações posteriores.
Agora, temos alguns atributos correlatos. Vamos dividir o conjunto de dados em treinamento e teste em ordem cronológica, para que possamos treinar o modelo em observações iniciais e testar em observações posteriores.X = df.loc[:, df.columns != target_variable].values
y = df.loc[:,[target_variable]].values
div = int(round(len(X) * 0.29))
X_test = X[:div]
y_test = y[:div]
print(X_test.shape)
print(y_test.shape)
X_train = X[div:]
y_train = y[div:]
print(X_train.shape)
print(y_train.shape)
 Temos 40 observações para treinamento e 17 para teste.Agora importamos as bibliotecas necessárias:
Temos 40 observações para treinamento e 17 para teste.Agora importamos as bibliotecas necessárias:from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.metrics import accuracy_score
from sklearn.metrics import roc_auc_score
from sklearn import metrics
Agora, vamos usar uma floresta aleatória (RandomForest) e fazer uma previsão:rf = RandomForestRegressor(n_estimators = 1000)
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
Para facilitar as coisas, vamos colocar as previsões e y_test no Dataframe:df_res = pd.DataFrame({'y_test':y_test[:,0], 'y_pred':y_pred})
df_res.head()
Nosso verdadeiro 'y_test' é binário, mas nossas previsões são do tipo float , então vamos arredondá-las, assumindo que se forem maiores que 0,5, isso significa um aumento no preço e, se menor que 0,5, uma diminuição.threshold = 0.5
preds = [1 if val > threshold else 0 for val in df_res['y_pred']]
Agora, para entender melhor os resultados, obtemos a AUC, matriz de erros e indicador de precisão:print(roc_auc_score(preds, df_res['y_test']))
print(metrics.confusion_matrix(preds, df_res['y_test']))
print(accuracy_score(preds, df_res['y_test']))
 Obtivemos 64,7% das previsões corretas com 0,65 AUC.
Obtivemos 64,7% das previsões corretas com 0,65 AUC.- 9 vezes previmos um declínio e o preço diminuiu (à direita);
- 5 vezes previmos uma queda e o preço aumentou (incorretamente);
- Uma vez previmos um aumento, mas o preço diminuiu incorretamente);
- Prevemos duas vezes um aumento e o preço aumentou (verdadeiro).
Saiba mais sobre o curso .