Quando outro ano frutífero chegar ao fim, quero olhar para trás, fazer um balanço e mostrar o que fomos capazes de fazer durante esse período. A biblioteca #DeepPavlov, por um minuto, já tem dois anos e estamos felizes por nossa comunidade estar crescendo todos os dias.Ao longo do ano de trabalho na biblioteca, alcançamos:- Os downloads de bibliotecas aumentaram um terço em comparação com o ano passado. Agora, o DeepPavlov tem mais de 100 mil instalações e mais de 10 mil instalações de contêineres.
- O número de soluções comerciais aumentou devido às tecnologias de ponta implementadas no DeepPavlov, em vários setores, de varejo para setor.
- A primeira versão do DeepPavlov Agent foi lançada .
- O número de membros ativos da comunidade aumentou 5 vezes.
- Nossa equipe de estudantes de graduação e pós-graduação foi selecionada para participar do Alexa Prize Socialbot Grand Challenge 3 .
- A biblioteca tornou-se vencedora do concurso da empresa Google «Powered by TensorFlow Challenge».
O que ajudou a alcançar esses resultados e por que o DeepPavlov é a melhor fonte aberta para a criação de IA de conversação? Vamos contar em nosso artigo.
#DeepPavlov visa o resultado
Recentemente, os sistemas de diálogo se tornaram o padrão para a interação homem-máquina. Os chatbots são usados em quase todos os setores, simplificando a interação entre pessoas e computadores. Eles se integram perfeitamente a sites, plataformas de mensagens e dispositivos. Atualmente, muitas empresas preferem delegar tarefas de rotina a sistemas interativos que podem lidar com várias solicitações de usuário ao mesmo tempo, economizando custos de mão-de-obra.No entanto, muitas vezes as empresas não sabem por onde começar ao desenvolver um bot para atender às necessidades de seus negócios. Historicamente, os chatbots podem ser divididos em dois grandes grupos: com base em regras e em dados. O primeiro tipo depende de comandos e modelos predefinidos. Cada um desses comandos deve ser escrito pelo desenvolvedor do chatbot usando expressões regulares e análise de dados de texto. Por outro lado, os bots de bate-papo baseados em dados dependem de modelos de aprendizado de máquina que foram pré-treinados em dados de diálogo.Biblioteca de código aberto - DeepPavlovoferece uma solução gratuita e fácil de usar para a construção de sistemas interativos. O DeepPavlov vem com vários componentes pré-treinados para resolver problemas associados ao processamento de linguagem natural (PNL). O DeepPavlov resolve problemas como: classificação de texto, correção de erros de digitação, reconhecimento de entidades nomeadas, respostas a perguntas na base de conhecimento e muitas outras. E você pode instalar o DeepPavlov em uma linha executando:pip install -q deeppavlov
* A estrutura permite treinar e testar modelos, bem como personalizar seus hiperparâmetros. A biblioteca suporta plataformas Linux e Windows. Você pode experimentar este e outros modelos na versão demo da biblioteca .Atualmente, resultados modernos em muitas tarefas foram alcançados através do uso de modelos baseados no BERT. A equipe do DeepPavlov integrou o BERT nas três tarefas a seguir: classificação de texto, reconhecimento de entidades nomeadas e respostas a perguntas. Como resultado, fizemos melhorias significativas em todas essas tarefas.1. Modelos BERT DeepPavlov
BERT para classificação de texto Um
modelo de classificação de texto baseado no BERT DeepPavlov serve, por exemplo, para resolver o problema de detecção de insultos. O modelo inclui prever se um comentário publicado em uma discussão pública é considerado ofensivo para um dos participantes. Para este caso, a classificação é realizada apenas em duas classes: insulto e não insulto.Qualquer modelo pré-treinado pode ser usado para saída através da interface da linha de comandos (CLI) e através do Python. Antes de usar o modelo, verifique se todos os pacotes necessários estão instalados usando o comando:python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
BERT para reconhecimento de entidade nomeada
Além dos modelos de classificação de texto, o DeepPavlov inclui um modelo baseado em BERT para reconhecimento de entidade nomeada (NER). Essa é uma das tarefas mais comuns da PNL e o modelo mais usado da nossa biblioteca. Ao mesmo tempo, o NER possui muitos aplicativos de negócios. Por exemplo, um modelo pode extrair informações importantes de um currículo para facilitar o trabalho de especialistas em recursos humanos. Além disso, o NER pode ser usado para identificar entidades relevantes nas solicitações dos clientes, como especificações do produto, nomes da empresa ou informações da filial da empresa.A equipe do DeepPavlov treinou o modelo NER no pacote OntoNotes em inglês, que possui 19 tipos de marcação, incluindo PER (pessoa), LOC (local), ORG (organização) e muitos outros. Para interagir, você deve instalá-lo com o comando:python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
BERT para responder a perguntas Uma
resposta contextual a uma pergunta é a tarefa de encontrar uma resposta para uma pergunta em um determinado contexto (por exemplo, um parágrafo da Wikipedia), onde a resposta para cada pergunta é um segmento de contexto. Por exemplo, o triplo de contexto, pergunta e resposta abaixo forma o trigêmeo correto para a tarefa de responder à pergunta.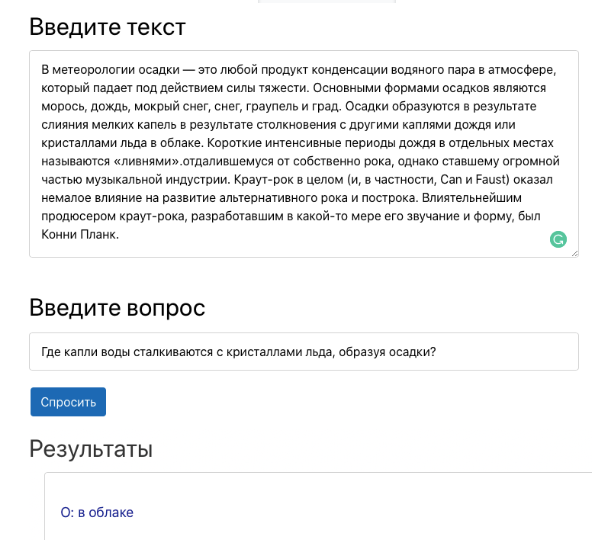 Apresentação do trabalho do sistema de perguntas e respostas em uma demonstração.Um sistema de respostas a perguntas pode automatizar muitos processos em um negócio. Por exemplo, isso pode ajudar os empregadores a obter respostas com base na documentação interna da empresa. Além disso, o modelo ajudará a testar a capacidade dos alunos de entender o texto no processo de aprendizagem. Recentemente, no entanto, a tarefa de responder perguntas com base no contexto atraiu grande atenção dos cientistas. Um dos principais pontos de virada nessa área foi o lançamento do Stanford Question Answer Set (SQuAD). O conjunto de dados do SQuAD levou a inúmeras abordagens para solucionar o problema do sistema de perguntas e respostas. Um dos mais bem sucedidos é o modelo DeepPavlov BERT. Ultrapassa todos os outros e atualmente produz resultados beirando as características humanas.Para usar o modelo de controle de qualidade baseado em BERT com o DeepPavlov, você deve:
Apresentação do trabalho do sistema de perguntas e respostas em uma demonstração.Um sistema de respostas a perguntas pode automatizar muitos processos em um negócio. Por exemplo, isso pode ajudar os empregadores a obter respostas com base na documentação interna da empresa. Além disso, o modelo ajudará a testar a capacidade dos alunos de entender o texto no processo de aprendizagem. Recentemente, no entanto, a tarefa de responder perguntas com base no contexto atraiu grande atenção dos cientistas. Um dos principais pontos de virada nessa área foi o lançamento do Stanford Question Answer Set (SQuAD). O conjunto de dados do SQuAD levou a inúmeras abordagens para solucionar o problema do sistema de perguntas e respostas. Um dos mais bem sucedidos é o modelo DeepPavlov BERT. Ultrapassa todos os outros e atualmente produz resultados beirando as características humanas.Para usar o modelo de controle de qualidade baseado em BERT com o DeepPavlov, você deve:python -m deeppavlov install squad_bert
python -m deeppavlov interact squad_bert -d
Mais modelos podem ser encontrados na documentação . E se você precisar de tutoriais sobre o uso de componentes de biblioteca, procure-os em nosso blog oficial .2. DeepPavlov Agent - uma plataforma para criar bots de bate-papo com várias tarefas
Hoje, existem várias abordagens para o desenvolvimento de agentes interativos. Ao desenvolver agentes de conversação, a arquitetura modular é usada principalmente para um diálogo focado no qual o script se desenvolve. No entanto, muitas vezes o usuário precisa combinar um diálogo focado, por exemplo, com outra funcionalidade - responder perguntas ou procurar informações, além de manter uma conversa. Assim, o agente de diálogo ideal é um assistente pessoal que combina diferentes tipos de agentes, alterna entre suas funcionalidades e caracteres, dependendo da tarefa em que é usado. Ao mesmo tempo, o agente deve acumular informações sobre sua essência, ajustar seus algoritmos a um usuário específico. Por outro lado, deve poder integrar-se com serviços externos. Por exemplo,faça consultas a bancos de dados externos, obtenha informações de lá, processe-as, destaque o importante e transmita-as ao usuário. Para resolver esse problema, em outubro de 2019, foi lançada a primeira versão do DeepPavlov Agent 1.0, uma plataforma para a criação de bots de bate-papo com várias tarefas. O agente ajuda os desenvolvedores de chatbots de produção a organizar vários modelos de PNL em um pipeline.Leia mais sobre a plataforma e os recursos na documentação .3. Implementação do DeepPavlov NLP SaaS
Para simplificar o trabalho com modelos de PNL pré-treinados da DeepPavlov, em setembro de 2019, foi lançado um serviço SaaS. O DeepPavlov Cloud permite analisar texto e armazenar documentos na nuvem. Para usar os modelos, você precisa se registrar em nosso serviço e obter um token na seção Tokens da sua conta pessoal. No momento, o serviço suporta vários modelos de PNL pré-treinados em russo e está em processo de teste do sistema.4. Participação no DSCT8 ou sistema de diálogo direcionado
O uso de assistentes virtuais como Amazon Alexa e Google Assistant abriu oportunidades para o desenvolvimento de aplicativos que nos permitem simplificar a implementação de muitas tarefas cotidianas, como pedir um táxi, reservar uma mesa em um restaurante e muitas outras.O rastreamento de estado de diálogo (DST) é um componente-chave em tais sistemas de diálogo. O DST é responsável por traduzir enunciados em linguagem humana em uma representação semântica do idioma, em particular, por extrair intenções e pares de valores de espaço correspondentes ao objetivo do usuário.Durante a participação da equipe no DSTC8Foi desenvolvido o modelo GOLOMB (rastreador de estado de diálogo baseado em BERT multitarefa orientada ao GOaL) - um modelo de multitarefa orientado a objetivos baseado no BERT para rastrear o estado do diálogo. Para prever o estado do diálogo, o modelo resolve vários problemas de classificação e a tarefa de encontrar uma substring. Em breve, este modelo aparecerá na biblioteca DeepPavlov. Enquanto isso, você pode ler o artigo completo aqui . Apresentação do pôster na conferência AAAI-20 em Nova York (EUA).
Apresentação do pôster na conferência AAAI-20 em Nova York (EUA).
5. Participação no Grande Prêmio Alexa Socialbot do Prêmio Alexa
A equipe do DeepPavlov, composta por estudantes e estudantes de pós-graduação do Instituto de Física e Tecnologia de Moscou, foi selecionada para participar do Alexa Prize Socialbot Grand Challenge 3 - uma competição internacional dedicada ao desenvolvimento da tecnologia de IA em conversação. O objetivo da competição é criar um bot que possa se comunicar livremente com as pessoas sobre tópicos relevantes. Das 375 inscrições, o comitê Alexa Prize selecionou 10 finalistas, incluindo nossa equipe - DREAM. No momento, a equipe passou para as quartas de final da competição e está lutando para chegar às semifinais. Você pode acompanhar as notícias e torcer pela nossa na página oficial e não se esqueça de se inscrever no Twitter . Composição da equipe Dream Team.
Composição da equipe Dream Team.
6. Participação no desafio Powered by TF
Como afirmado anteriormente, o DeepPavlov vem com vários componentes pré-treinados, equipados com TensorFlow e Keras. E este ano, a equipe DeepPavlov venceu o concurso Google Powered by TF Challenge pelo melhor projeto de aprendizado de máquina que usa a biblioteca TensorFlow. Dos mais de 600 participantes do concurso, o Google escolheu os cinco melhores projetos, um dos quais foi a biblioteca DeepPavlov. O projeto foi apresentado no blog oficial do TensorFlow . Vale ressaltar que a flexibilidade do TensorFlow nos permite criar qualquer arquitetura de rede neural em que possamos pensar. E, em particular, usamos o TensorFlow para integração perfeita com modelos baseados no BERT.
7. Desenvolvimento comunitário
O objetivo global do nosso projeto é permitir que desenvolvedores e pesquisadores no campo da inteligência artificial conversacional usem as ferramentas mais avançadas para criar sistemas interativos de próxima geração, além de se tornar uma plataforma internacionalmente significativa no campo da IA para troca de experiências e ensino de tecnologias de ponta.Para isso, os funcionários da DeepPavlovrealizar cursos de treinamento semestrais gratuitos para estudantes e funcionários envolvidos em Ciência da Computação. Um deles é o curso: “Deep learning in natural language processing” ”, que inclui seminários e workshops. As aulas incluem tópicos como: construção de sistemas de diálogo, métodos para avaliar um sistema de diálogo com capacidade de gerar uma resposta, várias estruturas para sistemas de diálogo, métodos para estimar a quantia de remuneração devido à otimização das políticas de diálogo, tipos de solicitações de usuários, consideração da modelagem de chamadas de call center. Em 2020, lançamos um novo recrutamento e já 900 alunos e funcionários passam por treinamento gratuito. Você pode acompanhar as notícias e o cenário para este e outros cursos em nosso site . E se você perdeu os cursos, mas quer aprender mais - então no nossocanal do youtube , você sempre pode encontrá-los no registro.Hoje, a biblioteca DeepPavlov fornece componentes prontos para IA para trabalhar com texto, usados em 92 países do mundo. Em fevereiro de 2020, o número de downloads da biblioteca atingiu 100.000 mil e a dinâmica das instalações está ganhando força. Além disso, mais de 30 empresas na Rússia já implementaram e estão usando com sucesso soluções baseadas no DeepPavlov. Isso mostra que essas soluções são muito populares em todo o mundo.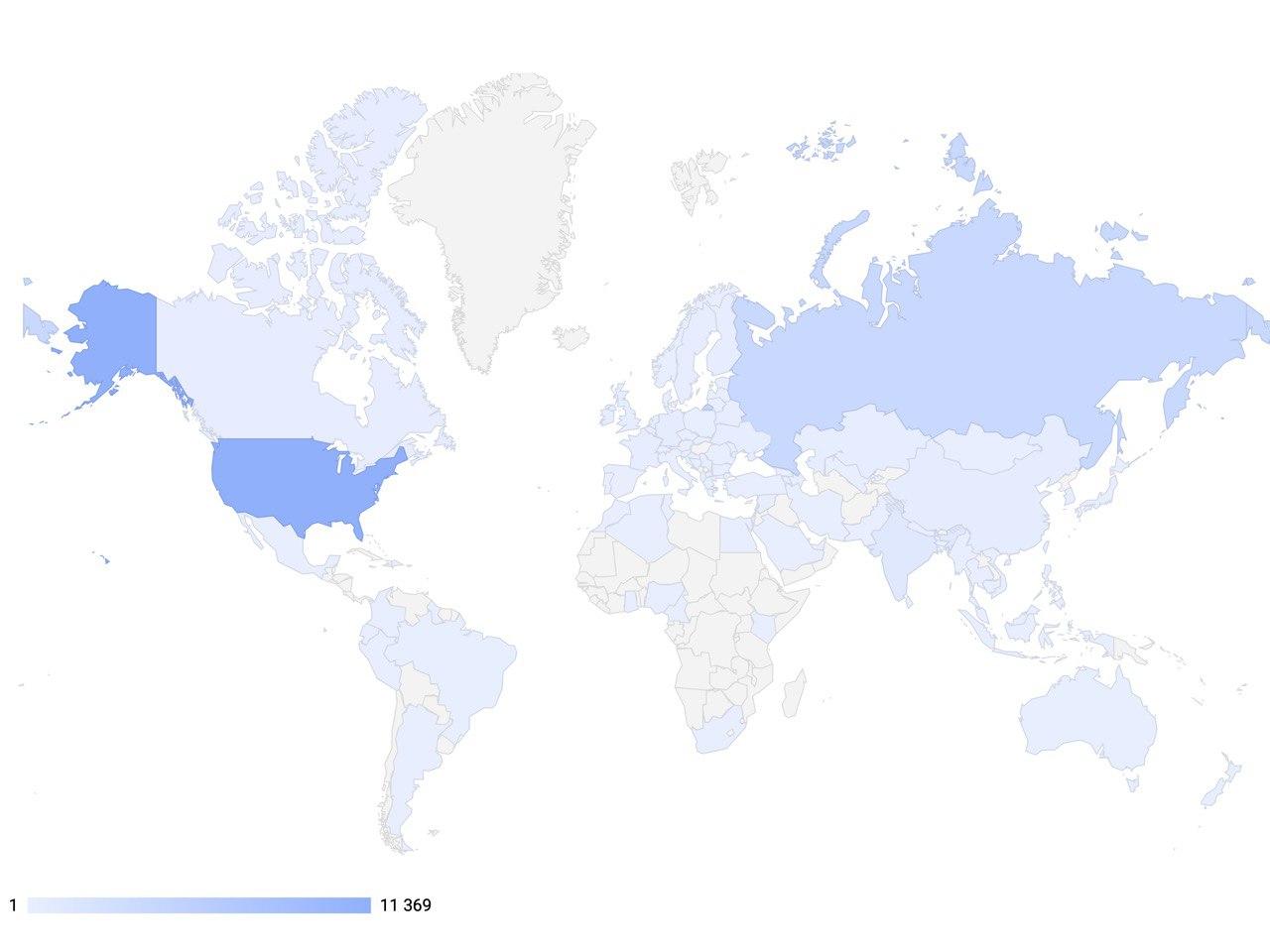
Qual é o próximo?
Temos o prazer de compartilhar nossos sucessos com você, por isso preparamos um evento para nossa comunidade. Queremos compartilhar experiências e conhecimentos de projetos de produção reais sobre como criar os melhores assistentes de IA. Participe da reunião de usuários e desenvolvedores da biblioteca aberta DeepPavlov em 28 de fevereiro para conversar sobre inteligência artificial e sua aplicação, além de conhecer outros membros da comunidade. O evento será realizado como parte da semana da IA, de 25 a 28 de fevereiro. Estamos esperando por todos que usam o DeepPavlov ou desejam conhecer nossa tecnologia.Todas as informações sobre os palestrantes e o programa podem ser encontradas no site, é necessária a inscrição para participar do evento.Registre-se: DeepPavlov 2 anos
O setor de IA continuará evoluindo e acreditamos que o DeepPavlov se tornará uma tecnologia avançada que todo desenvolvedor usará para entender a linguagem natural. No próximo ano, trabalharemos para dobrar nossa comunidade, aumentar as ferramentas de código aberto e melhorar a pesquisa de aprendizado de máquina. E não esqueça que o DeepPavlov tem um fórum - faça suas perguntas sobre a biblioteca e os modelos. Obrigado pela atenção!