Recentemente, a tarefa de reconhecimento de caracteres em programas aplicativos não é particularmente difícil - você pode usar muitas bibliotecas OCR prontas, muitas das quais estão quase perfeitas. Porém, às vezes, pode surgir uma tarefa para desenvolver seu próprio algoritmo de reconhecimento sem o uso de bibliotecas OCR "sofisticadas" de terceiros.
Essa é precisamente a tarefa que surgiu durante o meu trabalho, e há várias razões pelas quais é melhor não usar bibliotecas prontas: o projeto fechado, com sua certificação adicional, uma certa restrição no número de linhas de código e no tamanho das bibliotecas conectadas, ainda mais porque você precisa reconhecer o suficiente na área de assunto conjunto de caracteres específico.
O algoritmo de reconhecimento é simples e, é claro, não finge ser o mais preciso, rápido e eficaz, mas lida bem com sua pequena tarefa.
Suponha que tenhamos entrada na forma de imagens digitalizadas de documentos de forma estruturada. Esses documentos têm um código especial de um caractere localizado no canto superior esquerdo. Nossa tarefa é reconhecer esse símbolo e executar algumas ações, por exemplo, classificar o documento de origem de acordo com as regras fornecidas.

O diagrama do algoritmo é o seguinte:
 Como sabemos com antecedência onde nosso símbolo está localizado, cortar uma determinada área não é difícil. Para remover todas as “irregularidades” das bordas do símbolo, traduzimos a imagem em monocromático (preto e branco).
Como sabemos com antecedência onde nosso símbolo está localizado, cortar uma determinada área não é difícil. Para remover todas as “irregularidades” das bordas do símbolo, traduzimos a imagem em monocromático (preto e branco).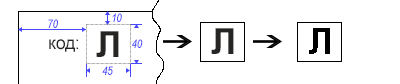
short width = 45, height = 40, offsetTop = -10, offsetLeft = -70;
BufferedImage image = ImageIO.read(file);
BufferedImage symbol = new BufferedImage(width, height, BufferedImage.TYPE_BYTE_BINARY);
Graphics2D g = symbol.createGraphics();
g.drawImage(image, offsetLeft, offsetTop, null);
Em seguida, você precisa converter o fragmento resultante “pixel por pixel” em uma sequência binária, ou seja, uma sequência em que, por exemplo, '*' corresponde a um pixel preto e um espaço em branco.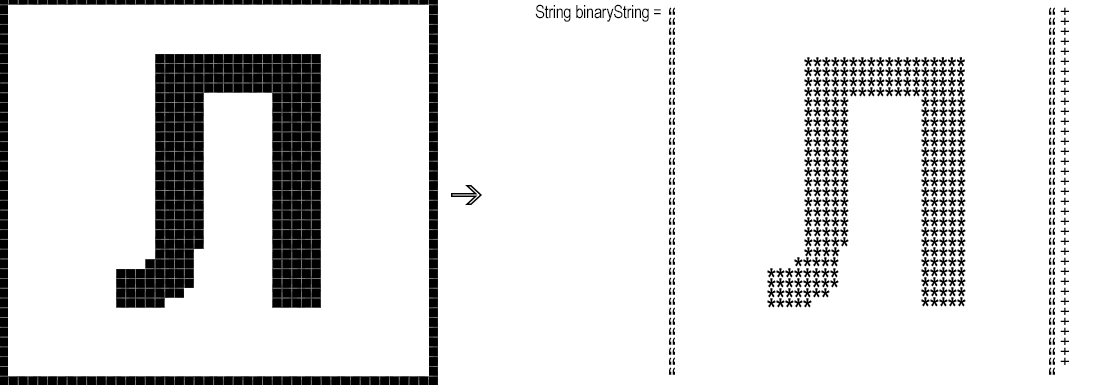
short whiteBg = -1;
StringBuilder binaryString = new StringBuilder();
for (short y = 1; y < height; y++)
for (short x = 1; x < width; x++) {
int rgb = symbol.getRGB(x, y);
binaryString.append(rgb == whiteBg ? " " : "*");
}
Em seguida, você precisa encontrar a distância mínima de Levenshtein entre a string recebida e as strings de referência pré-preparadas (na verdade, você pode usar qualquer método de comparação de strings).int min = 1000000;
char findSymbol = "";
for (Map.Entry<Character, String> entry : originalMap.entrySet()) {
int levenshtein = levenshtein(binaryString.toString(), entry.getValue());
if (levenshtein < min) {
min = levenshtein;
findSymbol = entry.getKey();
}
}
A função de encontrar a distância de Levenshtein é implementada como um método de acordo com o algoritmo padrão:public static int levenshtein(String targetStr, String sourceStr) {
int m = targetStr.length(), n = sourceStr.length();
int[][] delta = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++)
delta[i][0] = i;
for (int j = 1; j <= n; j++)
delta[0][j] = j;
for (int j = 1; j <= n; j++)
for (int i = 1; i <= m; i++) {
if (targetStr.charAt(i - 1) == sourceStr.charAt(j - 1))
delta[i][j] = delta[i - 1][j - 1];
else
delta[i][j] = Math.min(delta[i - 1][j] + 1,
Math.min(delta[i][j - 1] + 1, delta[i - 1][j - 1] + 1));
}
return delta[m][n];
}
O findSymbol resultante será nosso caractere reconhecido.Esse algoritmo pode ser otimizado para melhorar o desempenho e complementado com várias verificações para melhorar a eficiência do reconhecimento. Muitos indicadores dependem da área de assunto específica do problema que está sendo resolvido (número de caracteres, variedade de fontes, qualidade de imagem etc.)Foi verificado de forma prática que o método lida qualitativamente mesmo com questões problemáticas como "semelhança" de caracteres, por exemplo, "L" <-> "P", "5" <-> "S", "O" <-> "0". Como, por exemplo, a distância entre as cadeias binárias “L” e “P” será sempre maior do que entre a “L” reconhecida e a cadeia de referência “L”, mesmo com algumas “irregularidades”.Em geral, se você precisar resolver um problema semelhante (por exemplo, reconhecimento de cartas de jogar), com várias restrições ao uso de neurônios e outras soluções prontas, poderá usar e modificar esse método com segurança.