Neste artigo, falarei sobre alguns truques simples que são úteis ao trabalhar com dados que não cabem na memória da máquina local, mas ainda são pequenos demais para serem chamados de Grandes. Seguindo a analogia em inglês (grande, mas não grande), chamaremos esses dados de grossos. Estamos falando de tamanhos de unidades e dezenas de gigabytes.[Isenção de responsabilidade] Se você gosta de SQL, tudo o que está escrito abaixo pode causar emoções negativas, provavelmente negativas, na Holanda existem 49262 Tesla, dos quais 427 são táxis, é melhor não ler mais [/ Isenção de responsabilidade]. O ponto de partida foi um artigo no hub com uma descrição de um conjunto de dados interessante - uma lista completa de veículos registrados na Holanda, 14 milhões de linhas, tudo, desde tratores de caminhão a bicicletas elétricas a velocidades acima de 25 km / h.O conjunto é interessante, leva 7 GB, você pode baixá- lo no site da organização responsável.A tentativa de conduzir os dados como estão nos pandas para filtrá-los e limpá-los terminou em um fiasco (senhores dos hussardos SQL, eu avisei!). Os pandas caíram devido à falta de memória na área de trabalho com 8 GB. Com um pouco de derramamento de sangue, a questão pode ser resolvida se você se lembrar de que os pandas podem ler arquivos csv em pedaços de tamanho moderado. O tamanho do fragmento nas linhas é determinado pelo parâmetro chunksize.Para ilustrar o trabalho, escreveremos uma função simples que faz uma solicitação e determina quantos carros Tesla existem no total e qual proporção deles trabalha em táxis. Sem truques com a leitura de fragmentos, esse pedido primeiro consome toda a memória, depois sofre por um longo tempo e, no final, a rampa cai.Com a leitura de fragmentos, nossa função será mais ou menos assim:
O ponto de partida foi um artigo no hub com uma descrição de um conjunto de dados interessante - uma lista completa de veículos registrados na Holanda, 14 milhões de linhas, tudo, desde tratores de caminhão a bicicletas elétricas a velocidades acima de 25 km / h.O conjunto é interessante, leva 7 GB, você pode baixá- lo no site da organização responsável.A tentativa de conduzir os dados como estão nos pandas para filtrá-los e limpá-los terminou em um fiasco (senhores dos hussardos SQL, eu avisei!). Os pandas caíram devido à falta de memória na área de trabalho com 8 GB. Com um pouco de derramamento de sangue, a questão pode ser resolvida se você se lembrar de que os pandas podem ler arquivos csv em pedaços de tamanho moderado. O tamanho do fragmento nas linhas é determinado pelo parâmetro chunksize.Para ilustrar o trabalho, escreveremos uma função simples que faz uma solicitação e determina quantos carros Tesla existem no total e qual proporção deles trabalha em táxis. Sem truques com a leitura de fragmentos, esse pedido primeiro consome toda a memória, depois sofre por um longo tempo e, no final, a rampa cai.Com a leitura de fragmentos, nossa função será mais ou menos assim:def pandas_chunky_query():
print('reading csv file with pandas in chunks')
filtered_chunk_list=[]
for chunk in pd.read_csv('C:\Open_data\RDW_full.CSV', chunksize=1E+6):
filtered_chunk=chunk[chunk['Merk'].isin(['TESLA MOTORS','TESLA'])]
filtered_chunk_list.append(filtered_chunk)
model_df = pd.concat(filtered_chunk_list)
print(model_df['Taxi indicator'].value_counts())
Especificando um milhão de linhas perfeitamente razoáveis, você pode executar a consulta em 1:46 e usando 1965 M de memória em seu pico. Todos os números de um desktop idiota com algo antigo, de oito núcleos, com cerca de 8 GB de memória e no sétimo Windows.
 Se você alterar o tamanho do pedaço, o consumo máximo de memória o seguirá literalmente, o tempo de execução não mudará muito. Para linhas de 0,5 M, a solicitação leva 1:44 e 1063 MB, para 2M 1:53 e 3762 MB.A velocidade não é muito agradável, ainda menos agradável é que a leitura do arquivo em fragmentos obriga a escrever adaptado para esta função, trabalhando com listas de fragmentos que devem ser coletados em um quadro de dados. Além disso, o formato csv em si não é muito feliz, o que ocupa muito espaço e é lido lentamente.Como podemos conduzir dados para uma rampa, um formato Apachev muito mais compacto pode ser usado para armazenamentoparquet onde há compressão e, graças ao esquema de dados, é muito mais rápido ler quando é lido. E a rampa é capaz de trabalhar com ele. Só agora não pode lê-los em fragmentos. O que fazer?- Vamos nos divertir, pegar o
Se você alterar o tamanho do pedaço, o consumo máximo de memória o seguirá literalmente, o tempo de execução não mudará muito. Para linhas de 0,5 M, a solicitação leva 1:44 e 1063 MB, para 2M 1:53 e 3762 MB.A velocidade não é muito agradável, ainda menos agradável é que a leitura do arquivo em fragmentos obriga a escrever adaptado para esta função, trabalhando com listas de fragmentos que devem ser coletados em um quadro de dados. Além disso, o formato csv em si não é muito feliz, o que ocupa muito espaço e é lido lentamente.Como podemos conduzir dados para uma rampa, um formato Apachev muito mais compacto pode ser usado para armazenamentoparquet onde há compressão e, graças ao esquema de dados, é muito mais rápido ler quando é lido. E a rampa é capaz de trabalhar com ele. Só agora não pode lê-los em fragmentos. O que fazer?- Vamos nos divertir, pegar o acordeão do botão Dask e acelerar!Dask! Um substituto para a rampa pronta para uso, capaz de ler arquivos grandes, capaz de trabalhar em paralelo em vários núcleos e usar cálculos preguiçosos. Para minha surpresa sobre Dask on Habré, existem apenas 4 publicações .Então, pegamos o traço, colocamos o csv original nele e, com uma conversão mínima, colocamos no chão. Ao ler, o dask jura pela ambiguidade dos tipos de dados em algumas colunas, por isso os definimos explicitamente (por uma questão de clareza, o mesmo foi feito para a rampa, o tempo de operação é mais alto levando em conta esse fator, o dicionário com tipos é cortado para todas as consultas para maior clareza), o resto é para si . Além disso, para verificação, fazemos pequenas melhorias no piso, ou seja, tentamos reduzir os tipos de dados aos mais compactos, substituir um par de colunas pelo texto sim / não pelos booleanos e converter outros dados para os tipos mais econômicos (para o número de cilindros do motor, o uint8 é definitivamente suficiente). Salvamos o piso otimizado separadamente e vemos o que obtemos.A primeira coisa que agrada ao trabalhar com o Dask é que não precisamos escrever nada supérfluo simplesmente porque temos dados espessos. Se você não prestar atenção ao fato de que o dask é importado, e não a rampa, tudo parece o mesmo que processar um arquivo com cem linhas na rampa (além de alguns apitos decorativos para criação de perfil).def dask_query():
print('reading CSV file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_csv('C:\Open_data\RDW_full.CSV')
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts().compute())
rprof.visualize()
Agora compare o impacto do arquivo de origem no desempenho ao trabalhar com o dasko. Primeiro, lemos o mesmo arquivo csv que ao trabalhar com a rampa. O mesmo cerca de dois minutos e dois gigabytes de memória (1:38 2096 Mb). Parece, valeu a pena beijar nos arbustos?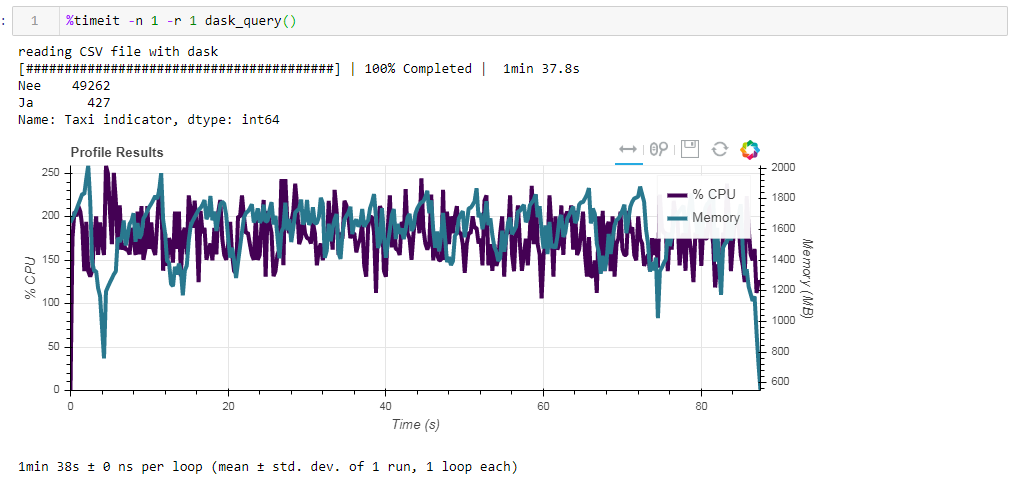 Agora alimente o arquivo de parquet não otimizado do quadro. A solicitação foi processada em aproximadamente 54 segundos, consumindo 1388 MB de memória, e o próprio arquivo da solicitação agora é 10 vezes menor (cerca de 700 MB). Aqui os bônus já são visíveis convexamente. A utilização da CPU de centenas de por cento é paralelização em vários núcleos.
Agora alimente o arquivo de parquet não otimizado do quadro. A solicitação foi processada em aproximadamente 54 segundos, consumindo 1388 MB de memória, e o próprio arquivo da solicitação agora é 10 vezes menor (cerca de 700 MB). Aqui os bônus já são visíveis convexamente. A utilização da CPU de centenas de por cento é paralelização em vários núcleos.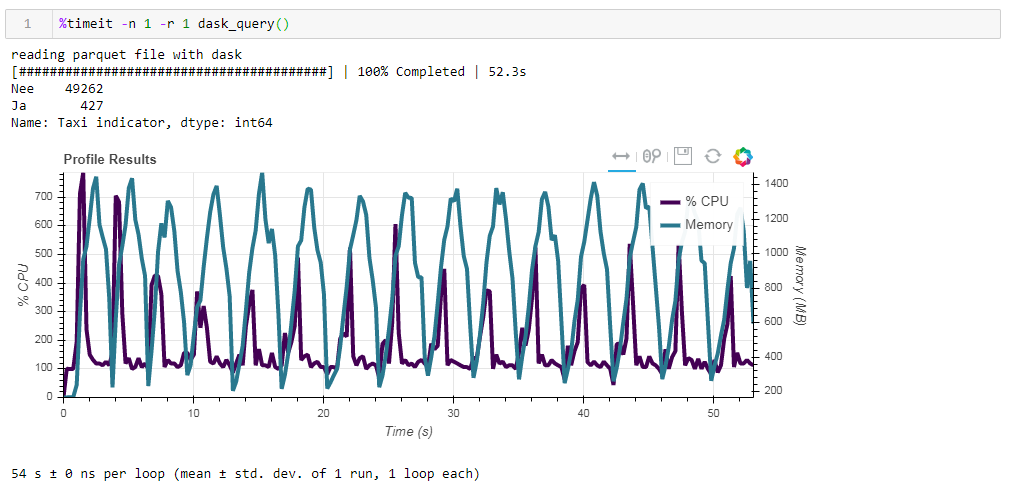 O parquet previamente otimizado com tipos de dados ligeiramente modificados na forma compactada é de apenas 1 MB a menos, o que significa que, sem dicas, tudo é compactado com bastante eficiência. O aumento da produtividade também não é particularmente significativo. A solicitação leva os mesmos 53 segundos e consome um pouco menos de memória - 1332 MB.Com base nos resultados de nossos exercícios, podemos dizer o seguinte:
O parquet previamente otimizado com tipos de dados ligeiramente modificados na forma compactada é de apenas 1 MB a menos, o que significa que, sem dicas, tudo é compactado com bastante eficiência. O aumento da produtividade também não é particularmente significativo. A solicitação leva os mesmos 53 segundos e consome um pouco menos de memória - 1332 MB.Com base nos resultados de nossos exercícios, podemos dizer o seguinte:- Se seus dados forem "gordos" e você estiver acostumado a uma rampa - o tamanho do pedaço ajudará a rampa a digerir esse volume, a velocidade será suportável.
- Se você deseja reduzir mais velocidade, economize espaço durante o armazenamento e não fique retido usando apenas uma rampa; então, o crepúsculo com parquet é uma boa combinação.
Finalmente, sobre computação preguiçosa. Um dos recursos do dask é que ele usa cálculos preguiçosos, ou seja, os cálculos não são executados imediatamente como são encontrados no código, mas quando são realmente necessários ou quando você o solicitou explicitamente usando o método de computação. Por exemplo, em nossa função, o dask não lê todos os dados na memória quando indicamos ler o arquivo. Ele os lê mais tarde, e apenas as colunas relacionadas à solicitação.Isso é facilmente visto no exemplo a seguir. Pegamos um arquivo pré-filtrado no qual deixamos apenas 12 colunas dos 64 iniciais; o parquet compactado leva 203 MB. Se você executar nossa solicitação regular, ela será executada em 8,8 segundos e o pico de uso da memória será de cerca de 300 MB, o que corresponde a um décimo do arquivo compactado se você o exceder em um csv simples.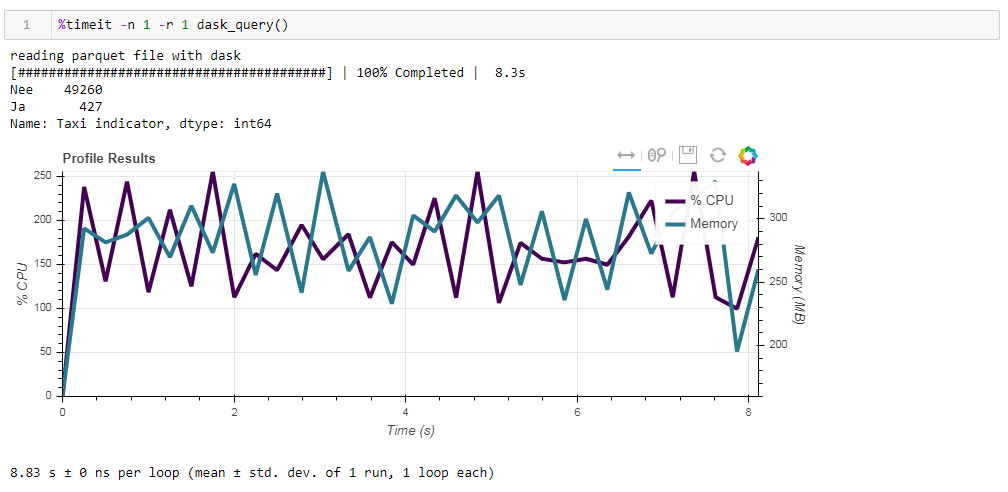 Se exigirmos explicitamente que você leia o arquivo e execute a solicitação, o consumo de memória será quase 10 vezes maior. Modificamos levemente nossa função lendo explicitamente o arquivo:
Se exigirmos explicitamente que você leia o arquivo e execute a solicitação, o consumo de memória será quase 10 vezes maior. Modificamos levemente nossa função lendo explicitamente o arquivo:def dask_query():
print('reading parquet file with dask')
with ProgressBar(), ResourceProfiler(dt=0.25) as rprof:
raw_data=dd.read_parquet('C:\Open_data\RDW_filtered.parquet' ).compute()
model_df=raw_data[raw_data['Merk'].isin(['TESLA MOTORS','TESLA'])]
print(model_df['Taxi indicator'].value_counts())
rprof.visualize()
E aqui está o que obtemos: 10,5 segundos e 3568 MB de memória (!)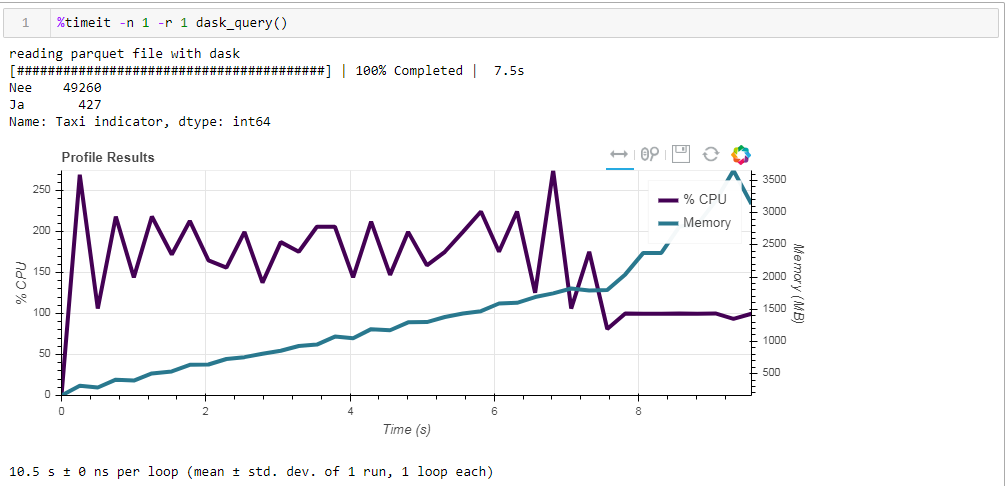 Mais uma vez, estamos convencidos de que o dask - é competente para lidar com suas próprias tarefas, e mais uma vez entrar nele com microgerenciamento não faz muito sentido.
Mais uma vez, estamos convencidos de que o dask - é competente para lidar com suas próprias tarefas, e mais uma vez entrar nele com microgerenciamento não faz muito sentido.