Neste artigo, mostrarei como configurar um ambiente de aprendizado de máquina em 30 minutos, criar uma rede neural para reconhecimento de imagens e executar a mesma rede em uma unidade de processamento gráfico (GPU).Primeiro, vamos definir o que é uma rede neural.No nosso caso, esse é um modelo matemático, bem como sua implementação de software ou hardware, construída com base no princípio de organização e funcionamento de redes neurais biológicas - redes de células nervosas de um organismo vivo. Esse conceito surgiu no estudo de processos que ocorrem no cérebro e na tentativa de simular esses processos.As redes neurais não são programadas no sentido usual da palavra, elas são treinadas. A capacidade de aprendizado é uma das principais vantagens das redes neurais em relação aos algoritmos tradicionais. Tecnicamente, o treinamento consiste em encontrar os coeficientes de conexões entre os neurônios. No processo de aprendizagem, a rede neural é capaz de identificar relações complexas entre entrada e saída, além de realizar generalizações.Do ponto de vista do aprendizado de máquina, uma rede neural é um caso especial de métodos de reconhecimento de padrões, análise discriminante, métodos de agrupamento e outros métodos.Equipamento
Primeiro, vamos lidar com o equipamento. Precisamos de um servidor com o sistema operacional Linux instalado. O equipamento para a operação de sistemas de aprendizado de máquina requer uma capacidade suficientemente poderosa e, como conseqüência, dispendiosa. Para aqueles que não têm um bom carro em mãos, recomendo prestar atenção à oferta dos provedores de nuvem. O servidor necessário pode ser alugado rapidamente e pagado apenas pelo tempo de uso.Nos projetos em que é necessário criar redes neurais, eu uso os servidores de um dos provedores de nuvem russos. A empresa oferece servidores de aluguel de nuvem especificamente para aprendizado de máquina com as poderosas unidades de processamento gráfico (GPUs) Tesla V100 da NVIDIA. Em resumo: o uso de um servidor com uma GPU pode ser dezenas de vezes mais eficiente (rápido) em comparação com um servidor com custo semelhante e que usa uma CPU (um processador central conhecido) para cálculos. Isso é alcançado devido às especificidades da arquitetura da GPU, que lida com os cálculos mais rapidamente.Para executar os exemplos descritos abaixo, adquirimos o seguinte servidor por vários dias:- SSD de 150 GB
- RAM 32 GB
- Processador Tesla V100 de 16 Gb com 4 núcleos
O Ubuntu 18.04 foi instalado na máquina.Defina o ambiente
Agora instale no servidor tudo o que você precisa para funcionar. Como nosso artigo é principalmente para iniciantes, falarei sobre alguns pontos que serão úteis para eles.Muito trabalho ao configurar o ambiente é feito através da linha de comando. A maioria dos usuários usa o Windows como um sistema operacional ativo. O console padrão neste sistema operacional deixa muito a desejar. Portanto, usaremos a conveniente Cmder / ferramenta . Baixe a versão mini e execute o Cmder.exe. Em seguida, você precisa se conectar ao servidor via SSH:ssh root@server-ip-or-hostname
Em vez de server-ip-or-hostname, especifique o endereço IP ou o nome DNS do seu servidor. Em seguida, digite a senha e, após uma conexão bem-sucedida, devemos obter algo parecido com isto.Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 4.15.0-74-generic x86_64)
A principal linguagem para o desenvolvimento de modelos de ML é o Python. E a plataforma mais popular para usá-lo no Linux é o Anaconda .Instale-o em nosso servidor.Começamos atualizando o gerenciador de pacotes local:sudo apt-get update
Instale o curl (utilitário de linha de comando):sudo apt-get install curl
Faça o download da versão mais recente do Anaconda Distribution:cd /tmp
curl –O https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh
Iniciamos a instalação:bash Anaconda3-2019.10-Linux-x86_64.sh
Durante o processo de instalação, você precisará confirmar o contrato de licença. Na instalação bem-sucedida, você deve ver o seguinte:Thank you for installing Anaconda3!
Para desenvolver modelos de ML, muitas estruturas foram criadas, trabalhamos com as mais populares: PyTorch e Tensorflow .O uso da estrutura permite aumentar a velocidade do desenvolvimento e usar ferramentas prontas para tarefas padrão.Neste exemplo, trabalharemos com o PyTorch. Instale-o:conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
Agora precisamos lançar o Jupyter Notebook - uma ferramenta de desenvolvimento popular entre os especialistas em ML. Permite escrever código e ver imediatamente os resultados de sua execução. O Jupyter Notebook faz parte do Anaconda e já está instalado em nosso servidor. Você precisa se conectar a ele no nosso sistema de desktop.Para fazer isso, primeiro executamos o Jupyter no servidor especificando a porta 8080:jupyter notebook --no-browser --port=8080 --allow-root
Em seguida, abrindo outra guia no console do Cmder (o menu superior é a caixa de diálogo Novo console), conecte na porta 8080 ao servidor via SSH:ssh -L 8080:localhost:8080 root@server-ip-or-hostname
Quando você digita o primeiro comando, serão oferecidos links para abrir o Jupyter em nosso navegador:To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-18788-open.html
Or copy and paste one of these URLs:
http://localhost:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
or http://127.0.0.1:8080/?token=cca0bd0b30857821194b9018a5394a4ed2322236f116d311
Use o link para localhost: 8080. Copie o caminho completo e cole na barra de endereços do navegador local do seu PC. O Caderno Jupyter é aberto.Vamos criar um novo laptop: Novo - Notebook - Python 3.Verifique a operação correta de todos os componentes que instalamos. Introduzimos um exemplo de código PyTorch no Jupyter e iniciamos a execução (botão Executar):from __future__ import print_function
import torch
x = torch.rand(5, 3)
print(x)
O resultado deve ser algo assim: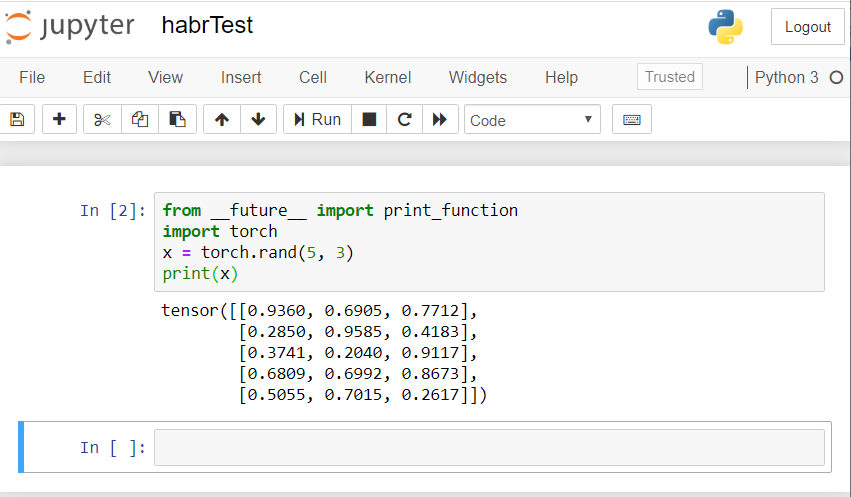 Se você tiver um resultado semelhante, todos nós configuramos corretamente e podemos começar a desenvolver uma rede neural!
Se você tiver um resultado semelhante, todos nós configuramos corretamente e podemos começar a desenvolver uma rede neural!Crie uma rede neural
Criaremos uma rede neural para reconhecimento de imagem. Tomamos este guia como base .Para treinar a rede, usaremos o conjunto de dados CIFAR10 disponível ao público. Ele tem aulas: “avião”, “carro”, “pássaro”, “gato”, “cervo”, “cachorro”, “sapo”, “cavalo”, “navio”, “caminhão”. As imagens no CIFAR10 têm um tamanho de 3x32x32, ou seja, imagens coloridas de 3 canais de 32x32 pixels.Para o trabalho, usaremos o pacote PyTorch criado para trabalhar com imagens - torchvision.Seguiremos as seguintes etapas em ordem:- Baixe e normalize conjuntos de dados de treinamento e teste
- Definição de rede neural
- Treinamento em rede sobre dados de treinamento
- Testando a rede com dados de teste
- Repita o treinamento e teste da GPU
Todo o código abaixo iremos executar no Jupyter Notebook.Baixe e normalize o CIFAR10
Copie e execute o seguinte código no Jupyter:
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
A resposta deve ser assim:Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
Obteremos várias imagens de treinamento para verificação:
import matplotlib.pyplot as plt
import numpy as np
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Definição de rede neural
Vamos primeiro examinar como funciona uma rede neural para reconhecimento de imagens. Esta é uma rede de conexão direta simples. Ele recebe entrada, passa por várias camadas, uma a uma e, finalmente, fornece a saída.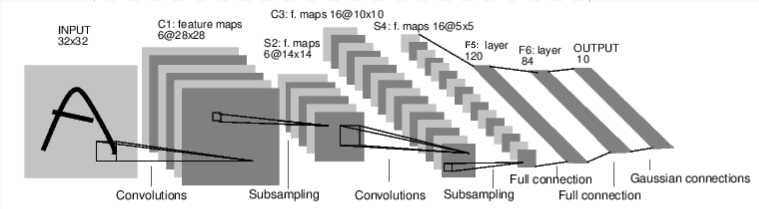 Vamos criar uma rede semelhante em nosso ambiente:
Vamos criar uma rede semelhante em nosso ambiente:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
Também definimos a função de perda e o otimizador
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Treinamento em rede sobre dados de treinamento
Começamos a treinar nossa rede neural. Chamo a atenção para o fato de que, depois disso, ao executar esse código, você precisará esperar um pouco até que o trabalho seja concluído. Levei 5 minutos. Rede leva tempo. for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Obtemos o seguinte resultado: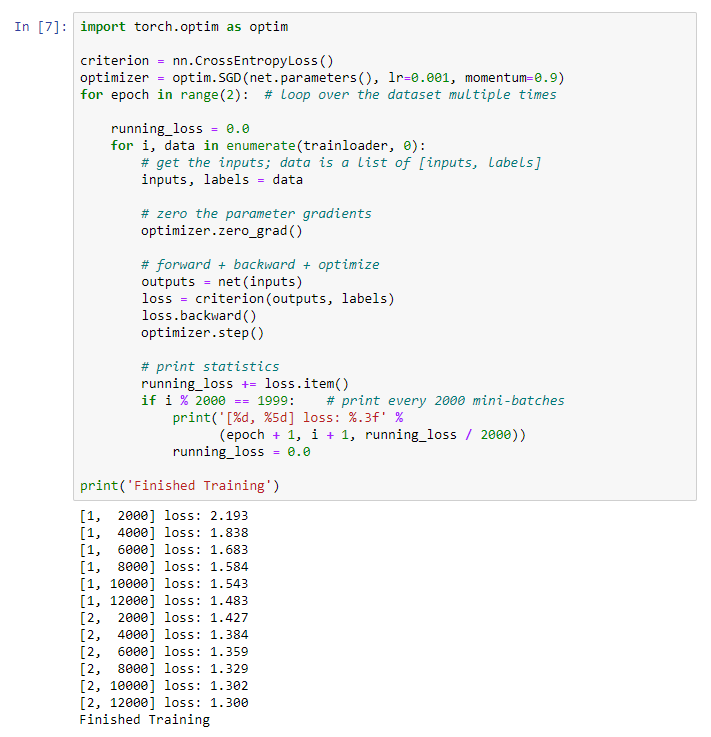 Salvamos nosso modelo treinado:
Salvamos nosso modelo treinado:PATH = './cifar_net.pth'
torch.save(net.state_dict(), PATH)
Testando a rede com dados de teste
Nós treinamos a rede usando um conjunto de dados de treinamento. Mas precisamos verificar se a rede aprendeu alguma coisa.Verificaremos isso prevendo o rótulo da classe que a rede neural gera e verificando a verdade. Se a previsão estiver correta, adicionamos a amostra à lista de previsões corretas.Vamos mostrar a imagem da suíte de testes:dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
 Agora peça à rede neural para nos dizer o que há nessas figuras:
Agora peça à rede neural para nos dizer o que há nessas figuras:
net = Net()
net.load_state_dict(torch.load(PATH))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))
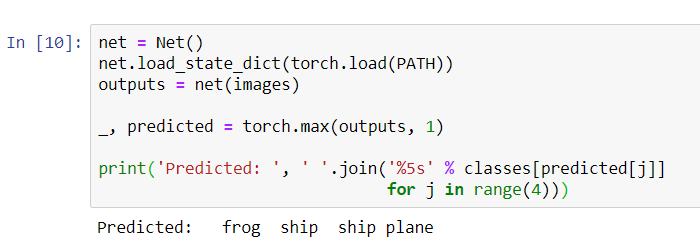 Os resultados parecem muito bons: a rede identificou corretamente três das quatro fotos.Vamos ver como a rede funciona em todo o conjunto de dados.
Os resultados parecem muito bons: a rede identificou corretamente três das quatro fotos.Vamos ver como a rede funciona em todo o conjunto de dados.
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
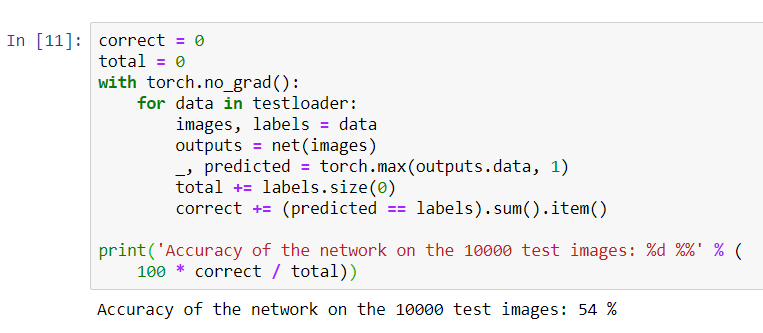 Parece que a rede conhece e funciona. Se ele definisse as aulas aleatoriamente, a precisão seria de 10%.Agora vamos ver quais classes a rede define melhor:
Parece que a rede conhece e funciona. Se ele definisse as aulas aleatoriamente, a precisão seria de 10%.Agora vamos ver quais classes a rede define melhor:class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
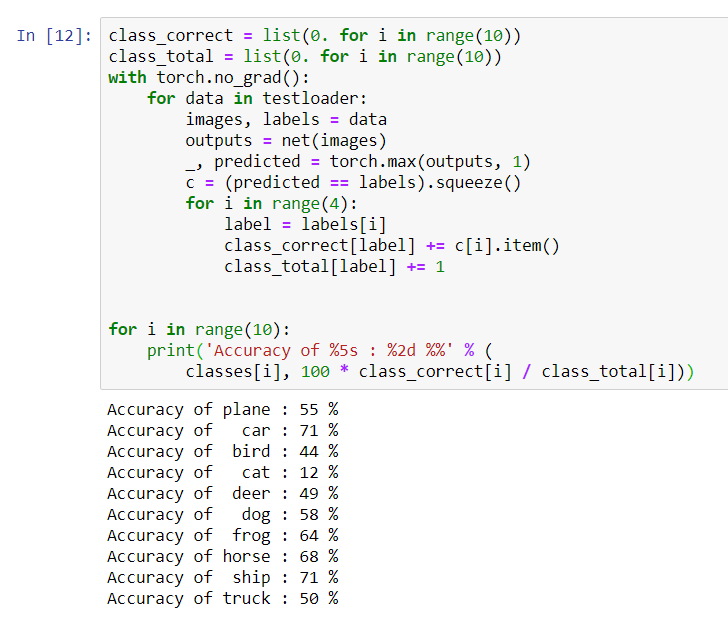 Parece que a rede determina melhor os carros e os navios: 71% de precisão.Então a rede está funcionando. Agora vamos tentar transferir seu trabalho para o processador gráfico (GPU) e ver o que muda.
Parece que a rede determina melhor os carros e os navios: 71% de precisão.Então a rede está funcionando. Agora vamos tentar transferir seu trabalho para o processador gráfico (GPU) e ver o que muda.Treinamento em rede neural da GPU
Primeiro, explicarei brevemente o que é CUDA. CUDA (Compute Unified Device Architecture) é uma plataforma de computação paralela desenvolvida pela NVIDIA para computação geral em GPUs. Com o CUDA, os desenvolvedores podem acelerar significativamente os aplicativos de computação usando os recursos das GPUs. No servidor que compramos, essa plataforma já está instalada.Vamos primeiro definir nossa GPU como o primeiro dispositivo cuda visível.device = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" )
print ( device )
 Envie a rede para a GPU:
Envie a rede para a GPU:net.to(device)
Também teremos que enviar insumos e metas a cada passo e para a GPU:inputs, labels = data[0].to(device), data[1].to(device)
Execute a reciclagem da rede já na GPU:import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2):
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
Desta vez, o treinamento em rede durou cerca de 3 minutos. Lembre-se de que o mesmo estágio em um processador regular durou 5 minutos. A diferença não é significativa, isso ocorre porque nossa rede não é tão grande. Ao usar matrizes grandes para treinamento, a diferença entre a velocidade da GPU e o processador tradicional aumentará.Isso parece ser tudo. O que conseguimos fazer:- Examinamos o que é a GPU e escolhemos o servidor em que está instalada;
- Criamos um ambiente de software para criar uma rede neural;
- Criamos uma rede neural para reconhecimento de imagens e a treinamos;
- Repetimos o treinamento da rede usando a GPU e recebemos um aumento na velocidade.
Ficarei feliz em responder às perguntas nos comentários.