O Kafka Streams é uma biblioteca Java para analisar e processar dados armazenados no Apache Kafka. Como em qualquer outra plataforma de processamento de streaming, ele é capaz de executar o processamento de dados com e / ou sem preservação de estado em tempo real. Neste post, tentarei descrever por que a alta disponibilidade (99,99%) é problemática no Kafka Streams e o que podemos fazer para alcançá-la.O que precisamos saber
Antes de descrever o problema e as possíveis soluções, vejamos os conceitos básicos do Kafka Streams. Se você trabalhou com APIs Kafka para consumidores / produtores, a maioria desses paradigmas é familiar para você. Nas seções a seguir, tentarei descrever em poucas palavras o armazenamento de dados em partições, o reequilíbrio de grupos de consumidores e como os conceitos básicos dos clientes Kafka se encaixam na biblioteca do Kafka Streams.Kafka: Particionando Dados
No mundo Kafka, os aplicativos produtores enviam dados como pares de valor-chave para um tópico específico. O tópico em si é dividido em uma ou mais partições nos corretores Kafka. Kafka usa uma chave de mensagem para indicar em qual partição os dados devem ser gravados. Conseqüentemente, as mensagens com a mesma chave sempre terminam na mesma partição.Os aplicativos de consumidor são organizados em grupos de consumidores e cada grupo pode ter uma ou mais instâncias de consumidores.Cada instância de um consumidor no grupo de consumidores é responsável pelo processamento de dados de um conjunto exclusivo de partições do tópico de entrada.
As instâncias do consumidor são essencialmente um meio de aumentar o processamento no seu grupo de consumidores.Kafka: reequilibrando o grupo de consumidores
Como dissemos anteriormente, cada instância do grupo de consumidores recebe um conjunto de partições exclusivas das quais consome dados. Sempre que um novo consumidor ingressa em um grupo, o reequilíbrio deve ocorrer para que ele obtenha uma partição. O mesmo acontece quando o consumidor morre, o restante deve levar suas partições para garantir que todas as partições sejam processadas.Kafka Streams: Streams
No início deste post, nos familiarizamos com o fato de que a biblioteca Kafka Streams é construída com base nas APIs de produtores e consumidores e o processamento de dados é organizado da mesma maneira que a solução padrão no Kafka. Na configuração do Kafka Streams, o campo application.id é equivalente a group.idna API do consumidor. O Kafka Streams pré-cria um certo número de threads e cada um deles executa o processamento de dados de uma ou mais partições dos tópicos de entrada. Falando na terminologia da API do Consumidor, os fluxos coincidem essencialmente com instâncias do Consumidor do mesmo grupo. Os encadeamentos são a principal maneira de dimensionar o processamento de dados no Kafka Streams. Isso pode ser feito verticalmente aumentando o número de encadeamentos para cada aplicativo Kafka Streams em uma máquina ou horizontalmente adicionando uma máquina adicional com o mesmo application.id.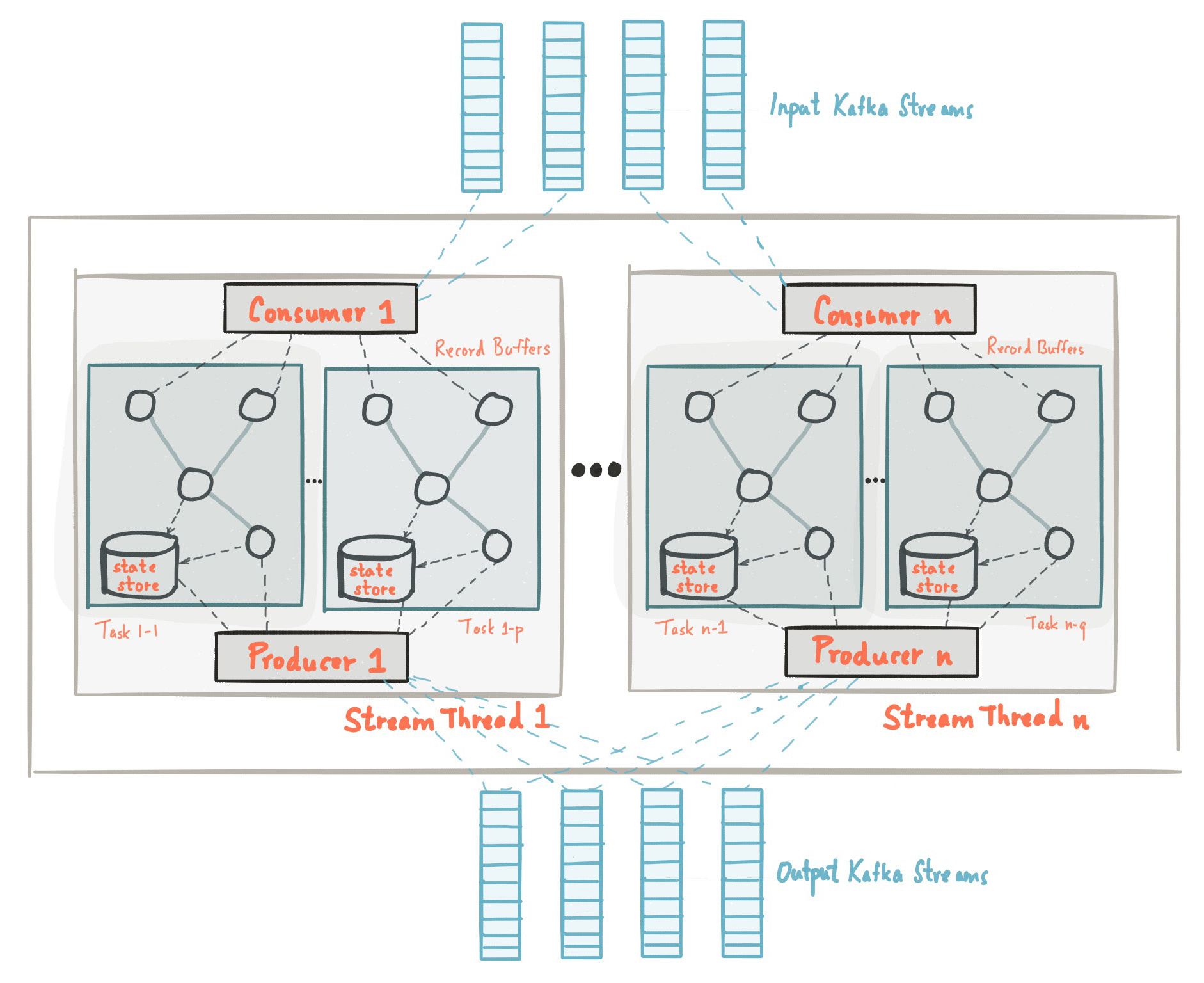 Fonte: kafka.apache.org/21/documentation/streams/architectureExistem muitos outros elementos no Kafka Streams, como tarefas, topologia de processamento, modelo de encadeamento etc., que não discutiremos nesta postagem. Mais informações podem ser encontradas aqui.
Fonte: kafka.apache.org/21/documentation/streams/architectureExistem muitos outros elementos no Kafka Streams, como tarefas, topologia de processamento, modelo de encadeamento etc., que não discutiremos nesta postagem. Mais informações podem ser encontradas aqui.Kafka Streams: armazenamento em estado
No processamento de fluxo, há operações com e sem preservação de estado. O estado é o que permite ao aplicativo lembrar as informações necessárias que vão além do escopo do registro atualmente sendo processado.Operações estaduais, como contagem, qualquer tipo de agregação, junções etc., são muito mais complicadas. Isso se deve ao fato de ter apenas um registro, não é possível determinar o último estado (por exemplo, contar) para uma determinada chave; portanto, você precisa armazenar o estado do seu fluxo no aplicativo. Como discutimos anteriormente, cada encadeamento processa um conjunto de partições exclusivas; portanto, um encadeamento processa apenas um subconjunto de todo o conjunto de dados. Isso significa que cada encadeamento de aplicativo Kafka Streams com o mesmo application.id mantém seu próprio estado isolado. Não entraremos em detalhes sobre como o estado é formado no Kafka Streams, mas é importante entender que o estado é restaurado usando o tópico do log de alterações e é salvo não apenas no disco local, mas também no Kafka Broker.Salvar o log de alterações de estado no Kafka Broker como um tópico separado é feito não apenas para tolerância a falhas, mas também para que você possa implantar facilmente novas instâncias do Kafka Streams com o mesmo application.id. Como o estado é armazenado como um tópico do log de alterações no lado do broker, uma nova instância pode carregar seu próprio estado a partir deste tópico.Mais informações sobre armazenamento de estado podem ser encontradas aqui .Por que a alta disponibilidade é problemática com o Kafka Streams?
Revisamos os conceitos e princípios básicos do processamento de dados com o Kafka Streams. Agora vamos tentar combinar todas as partes e analisar por que alcançar alta disponibilidade pode ser problemático. Nas seções anteriores, devemos lembrar:- Os dados no tópico Kafka são divididos em partições, que são distribuídas entre os fluxos do Kafka Streams.
- Os aplicativos Kafka Streams com o mesmo application.id são, de fato, um grupo de consumidores e cada um de seus encadeamentos é uma instância isolada e separada do consumidor.
- Para operações de estado, o encadeamento mantém seu próprio estado, que é "reservado" pelo tópico Kafka na forma de um log de alterações.
- , Kafka , .
TransferWise SPaaS (Stream Processing as a Service)
Antes de destacar a essência deste post, deixe-me contar primeiro o que criamos no TransferWise e por que a alta disponibilidade é muito importante para nós.No TransferWise, temos vários nós para processamento de streaming e cada nó contém várias instâncias do Kafka Streams para cada equipe de produto. As instâncias do Kafka Streams projetadas para uma equipe de desenvolvimento específica têm um application.id especial e geralmente têm mais de 5 threads. Em geral, as equipes geralmente têm de 10 a 20 threads (equivalente ao número de instâncias de consumidores) em todo o cluster. Os aplicativos implantados nos nós ouvem os tópicos de entrada e executam vários tipos de operações com e sem estado nos dados de entrada e fornecem atualizações de dados em tempo real para microsserviços posteriores subseqüentes.As equipes de produtos precisam atualizar os dados agregados em tempo real. Isso é necessário para fornecer aos nossos clientes a capacidade de transferir dinheiro instantaneamente. Nosso SLA habitual:Em qualquer dia, 99,99% dos dados agregados devem estar disponíveis em menos de 10 segundos.
Para se ter uma idéia, durante o teste de estresse, o Kafka Streams conseguiu processar e agregar 20.085 mensagens de entrada por segundo. Assim, 10 segundos de SLA sob carga normal pareciam bastante viáveis. Infelizmente, nosso SLA não foi atingido durante a atualização sem interrupção dos nós nos quais os aplicativos estão implantados, e abaixo descreverei por que isso aconteceu.Atualização do nó deslizante
Na TransferWise, acreditamos firmemente na entrega contínua de nosso software e geralmente lançamos novas versões de nossos serviços algumas vezes por dia. Vejamos um exemplo de uma simples atualização contínua de serviço e vejamos o que acontece durante o processo de lançamento. Novamente, devemos lembrar que:- Os dados no tópico Kafka são divididos em partições, que são distribuídas entre os fluxos do Kafka Streams.
- Os aplicativos Kafka Streams com o mesmo application.id são, de fato, um grupo de consumidores e cada um de seus encadeamentos é uma instância isolada e separada do consumidor.
- Para operações de estado, o encadeamento mantém seu próprio estado, que é "reservado" pelo tópico Kafka na forma de um log de alterações.
- , Kafka , .
Um processo de liberação em um único nó geralmente leva de oito a nove segundos. Durante o lançamento, as instâncias do Kafka Streams no nó "reinicializam suavemente". Portanto, para um único nó, o tempo necessário para reiniciar corretamente o serviço é de aproximadamente oito a nove segundos. Obviamente, desligar uma instância do Kafka Streams em um nó causa um reequilíbrio do grupo de consumidores. Como os dados são particionados, todas as partições pertencentes à instância inicializável devem ser distribuídas entre aplicativos ativos do Kafka Streams com o mesmo application.id. Isso também se aplica aos dados agregados que foram salvos no disco. Até que esse processo seja concluído, os dados não serão processados.Réplicas em espera
Para reduzir o tempo de reequilíbrio para aplicativos Kafka Streams, existe um conceito de réplicas de backup, definidas na configuração como num.standby.replicas. Réplicas de backup são cópias do armazenamento de estado local. Esse mecanismo torna possível replicar o armazenamento de estado de uma instância do Kafka Streams para outra. Quando o encadeamento Kafka Streams morre por qualquer motivo, a duração do processo de recuperação de estado pode ser minimizada. Infelizmente, pelos motivos que explicarei abaixo, mesmo as réplicas de backup não ajudarão com uma atualização do serviço sem interrupção.Suponha que tenhamos duas instâncias do Kafka Streams em duas máquinas diferentes: nó-a e nó-b. Para cada uma das instâncias do Kafka Streams, num.standby.replicas = 1 é indicado nesses 2. Nós. Com essa configuração, cada instância do Kafka Streams mantém sua própria cópia do repositório em outro nó. Durante uma atualização sem interrupção, temos a seguinte situação:- A nova versão do serviço foi implantada no nó-a.
- A instância do Kafka Streams no nó-a está desativada.
- O reequilíbrio começou.
- O repositório do nó-a já foi replicado para o nó-b, pois especificamos a configuração num.standby.replicas = 1.
- o nó-b já possui uma cópia de sombra do nó-a, portanto, o processo de reequilíbrio acontece quase instantaneamente.
- o nó-a é iniciado novamente.
- nó-a se junta a um grupo de consumidores.
- O broker Kafka vê uma nova instância do Kafka Streams e inicia o reequilíbrio.
Como podemos ver, num.standby.replicas ajuda apenas em cenários de um desligamento completo de um nó. Isso significa que, se o nó-a travar, o nó-b poderá continuar funcionando corretamente quase instantaneamente. Porém, em uma situação de atualização contínua, após a desconexão, o nó-a ingressará no grupo novamente e esta última etapa causará um reequilíbrio. Quando o nó-a ingressa no grupo de consumidores após uma reinicialização, será considerado como uma nova instância do consumidor. Novamente, devemos lembrar que o processamento de dados em tempo real é interrompido até que uma nova instância restaure seu estado do tópico do log de alterações.Observe que o reequilíbrio de partições quando uma nova instância é ingressada em um grupo não se aplica à API do Kafka Streams, pois é exatamente assim que o protocolo do grupo de consumidores Apache Kafka funciona.Conquista: Alta disponibilidade com Kafka Streams
Apesar de as bibliotecas cliente Kafka não fornecerem funcionalidade interna para o problema mencionado acima, existem alguns truques que podem ser usados para obter alta disponibilidade de cluster durante uma atualização sem interrupção. A idéia por trás das réplicas de backup permanece válida, e ter máquinas de backup na hora certa é uma boa solução que usamos para garantir alta disponibilidade em caso de falha da instância.O problema com nossa configuração inicial era que tínhamos um grupo de consumidores para todas as equipes em todos os nós. Agora, em vez de um grupo de consumidores, temos dois, e o segundo atua como um cluster "quente". No prod, os nós têm uma variável especial CLUSTER_ID, que é adicionada ao application.id das instâncias do Kafka Streams. Aqui está um exemplo de configuração do Spring Boot application.yml:application.ymlspring.profiles: production
streaming-pipelines:
team-a-stream-app-id: "${CLUSTER_ID}-team-a-stream-app"
team-b-stream-app-id: "${CLUSTER_ID}-team-b-stream-app"
Em um determinado momento, apenas um dos clusters está no modo ativo, respectivamente, o cluster de backup não envia mensagens em tempo real para microsserviços downstream. Durante a liberação da liberação, o cluster de backup se torna ativo, o que permite uma atualização sem interrupção no primeiro cluster. Como esse é um grupo completamente diferente de consumidores, nossos clientes nem percebem violações no processamento, e os serviços subsequentes continuam recebendo mensagens do cluster ativo recentemente. Uma das desvantagens óbvias do uso de um grupo de consumidores de backup é o consumo adicional de sobrecarga e recursos, mas, no entanto, essa arquitetura fornece garantias adicionais, controle e tolerância a falhas do nosso sistema de processamento de streaming.Além de adicionar um cluster adicional, também existem truques que podem atenuar o problema com o reequilíbrio frequente.Aumentar group.initial.rebalance.delay.ms
A partir do Kafka 0.11.0.0, a configuração group.initial.rebalance.delay.ms foi adicionada. De acordo com a documentação, essa configuração é responsável por:A quantidade de tempo em milissegundos que o GroupCoordinator atrasará o reequilíbrio inicial do consumidor do grupo.
Por exemplo, se definirmos 60.000 milissegundos nessa configuração, com uma atualização contínua, poderemos ter uma janela para o lançamento do lançamento. Se a instância do Kafka Streams reiniciar com êxito nessa janela de tempo, nenhum reequilíbrio será chamado. Observe que os dados pelos quais a instância reiniciada do Kafka Streams foi responsável continuarão indisponíveis até o nó retornar ao modo online. Por exemplo, se a reinicialização de uma instância demorar cerca de oito segundos, você terá oito segundos de tempo de inatividade para os dados pelos quais essa instância é responsável.Note-se que a principal desvantagem desse conceito é que, no caso de uma falha no nó, você receberá um atraso adicional de um minuto durante a restauração, levando em consideração a configuração atual.Diminuindo o tamanho do segmento nos tópicos do log de alterações
O grande atraso no reequilíbrio do Kafka Stream se deve à restauração das lojas do estado dos tópicos do log de alterações. Os tópicos do log de alterações são tópicos compactados, o que permite armazenar o registro mais recente de uma chave específica no tópico. Descreverei brevemente este conceito abaixo.Os tópicos do Kafka Broker estão organizados em segmentos. Quando um segmento atinge o tamanho do limite configurado, um novo segmento é criado e o anterior é compactado. Por padrão, esse limite é definido como 1 GB. Como você deve saber, a principal estrutura de dados subjacente aos tópicos do Kafka e suas partições é a estrutura de log com gravação direta, ou seja, quando as mensagens são enviadas para o tópico, elas sempre são adicionadas ao último segmento "ativo" e a compactação não é indo.Portanto, a maioria dos estados de armazenamento armazenados no changelog estão sempre no arquivo "segmento ativo" e nunca são compactados, resultando em milhões de mensagens de changelog não compactadas. Para o Kafka Streams, isso significa que, durante o reequilíbrio, quando a instância do Kafka Streams restaura seu estado a partir do tópico changelog, ela precisa ler muitas entradas redundantes no tópico changelog. Dado que os armazenamentos estaduais se preocupam apenas com o último estado, e não com o histórico, esse tempo de processamento é desperdiçado. Reduzir o tamanho do segmento causará uma compressão de dados mais agressiva, para que novas instâncias dos aplicativos Kafka Streams possam se recuperar muito mais rapidamente.Conclusão
Embora o Kafka Streams não forneça a capacidade interna de fornecer alta disponibilidade durante uma atualização do serviço sem interrupção, isso ainda pode ser feito no nível da infraestrutura. Devemos lembrar que o Kafka Streams não é uma "estrutura de cluster", diferente do Apache Flink ou Apache Spark. É uma biblioteca Java leve que permite que os desenvolvedores criem aplicativos escaláveis para streaming de dados. Apesar disso, ele fornece os blocos de construção necessários para atingir metas de streaming ambiciosas, como disponibilidade de "99,99%".