Eu regularmente me deparo com uma situação em que muitos desenvolvedores acreditam sinceramente que o índice no PostgreSQL é uma faca suíça que ajuda universalmente a qualquer problema de desempenho de consultas. Basta adicionar algum novo índice à tabela ou incluir o campo em algum lugar no existente e, em seguida (magic-magic!) Todas as consultas usarão esse índice efetivamente. Primeiro, é claro, eles não o farão, ou não serão eficientemente, ou não todos. Em segundo lugar, índices extras apenas adicionam problemas de desempenho ao escrever.Na maioria das vezes, essas situações ocorrem durante o desenvolvimento de "reprodução prolongada", quando não é feito um produto personalizado de acordo com o modelo "escrevi uma vez, dei, esqueci", mas, como no nosso caso, é criadoserviço com um longo ciclo de vida .As melhorias ocorrem iterativamente pelas forças de muitas equipes distribuídas , distribuídas não apenas no espaço, mas também no tempo. E então, sem conhecer todo o histórico do desenvolvimento do projeto ou os recursos da distribuição aplicada de dados em seu banco de dados, você pode facilmente "bagunçar" os índices. Porém, considerações e solicitações de teste detalhadas permitem prever e detectar parte dos problemas com antecedência:
Primeiro, é claro, eles não o farão, ou não serão eficientemente, ou não todos. Em segundo lugar, índices extras apenas adicionam problemas de desempenho ao escrever.Na maioria das vezes, essas situações ocorrem durante o desenvolvimento de "reprodução prolongada", quando não é feito um produto personalizado de acordo com o modelo "escrevi uma vez, dei, esqueci", mas, como no nosso caso, é criadoserviço com um longo ciclo de vida .As melhorias ocorrem iterativamente pelas forças de muitas equipes distribuídas , distribuídas não apenas no espaço, mas também no tempo. E então, sem conhecer todo o histórico do desenvolvimento do projeto ou os recursos da distribuição aplicada de dados em seu banco de dados, você pode facilmente "bagunçar" os índices. Porém, considerações e solicitações de teste detalhadas permitem prever e detectar parte dos problemas com antecedência:- índices não utilizados
- prefixo "clones"
- registro de data e hora "no meio"
- booleano indexável
- matrizes no índice
- Lixo nulo
O mais simples é encontrar índices para os quais não houve passes . Você só precisa se certificar de que a redefinição das estatísticas ( pg_stat_reset()) ocorreu há muito tempo e não deseja excluir a usada "raramente, mas adequadamente". Usamos a visualização do sistema pg_stat_user_indexes:SELECT * FROM pg_stat_user_indexes WHERE idx_scan = 0;
Mas mesmo que o índice seja usado e não se enquadre nessa seleção, isso não significa que seja adequado para suas consultas.Quais índices [não] são adequados
Para entender por que algumas consultas “não dão certo no índice”, vamos pensar na estrutura de um índice btree comum - a instância mais frequente da natureza. Os índices de um único campo geralmente não criam problemas; portanto, consideramos os problemas que surgem em um composto de um par de campos.Uma maneira extremamente simplificada, como se pode imaginar, é um “bolo em camadas”, onde em cada camada existem árvores ordenadas de acordo com os valores do campo correspondente em ordem.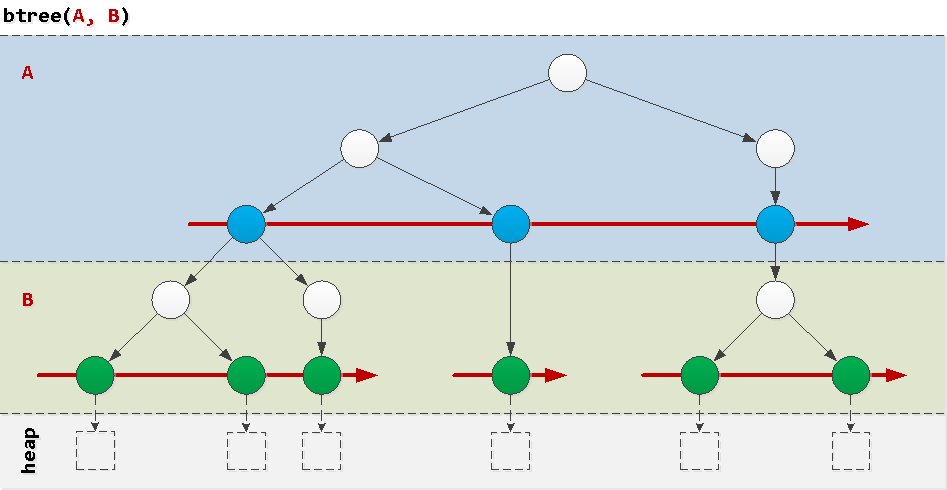 Agora é claro que o campo Um globalmente ordenou, e B - somente dentro de um valor específico A . Vejamos exemplos de condições que ocorrem em consultas reais e como elas "andam" pelo índice.
Agora é claro que o campo Um globalmente ordenou, e B - somente dentro de um valor específico A . Vejamos exemplos de condições que ocorrem em consultas reais e como elas "andam" pelo índice.Bom: condição do prefixo
Observe que o índice btree(A, B)inclui um "subíndice" btree(A). Isso significa que todas as regras descritas abaixo funcionarão para qualquer índice de prefixo.Ou seja, se você criar um índice mais complexo do que no nosso exemplo, algo do tipo btree(A, B, C)- você pode supor que seu banco de dados "apareça" automaticamente:btree(A, B, C)btree(A, B)btree(A)
E isso significa que a presença "física" do índice de prefixo no banco de dados é redundante na maioria dos casos. Afinal, quanto mais índices uma tabela precisa escrever - pior para o PostgreSQL, já que chama de Amplificação de Gravação - o Uber reclamou (e aqui você encontra uma análise de suas reivindicações ).E se algo impede a base de viver bem, vale a pena encontrá-la e eliminá-la. Vejamos um exemplo:CREATE TABLE tbl(A integer, B integer, val integer);
CREATE INDEX ON tbl(A, B)
WHERE val IS NULL;
CREATE INDEX ON tbl(A)
WHERE val IS NULL;
CREATE INDEX ON tbl(A, B, val);
CREATE INDEX ON tbl(A);
Consulta de pesquisa de índice de prefixoWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid AND
idx.indexprs IS NULL
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, pre AS (
SELECT
nmt
, wh
, nmf$
, tpf$
, nmi
, def
FROM
fld
ORDER BY
1, 2, 3
)
SELECT DISTINCT
Y.*
FROM
pre X
JOIN
pre Y
ON Y.nmi <> X.nmi AND
(Y.nmt, Y.wh) IS NOT DISTINCT FROM (X.nmt, X.wh) AND
(
Y.nmf$[1:array_length(X.nmf$, 1)] = X.nmf$ OR
X.nmf$[1:array_length(Y.nmf$, 1)] = Y.nmf$
)
ORDER BY
1, 2, 3;
Idealmente, você deve obter uma seleção vazia, mas veja - estes são nossos grupos de índices suspeitos:nmt | wh | nmf$ | tpf$ | nmi | def
---------------------------------------------------------------------------------------
tbl | (val IS NULL) | {a} | {int4} | tbl_a_idx | CREATE INDEX ...
tbl | (val IS NULL) | {a,b} | {int4,int4} | tbl_a_b_idx | CREATE INDEX ...
tbl | | {a} | {int4} | tbl_a_idx1 | CREATE INDEX ...
tbl | | {a,b,val} | {int4,int4,int4} | tbl_a_b_val_idx | CREATE INDEX ...
Depois, você decide por cada grupo se vale a pena remover o índice mais curto ou o mais longo, que não é necessário.Bom: todas as constantes, exceto o último campo
Se os valores de todos os campos do índice, exceto o último, forem definidos por constantes (no nosso exemplo, este é o campo A), o índice poderá ser usado normalmente. Nesse caso, o valor do último campo pode ser definido arbitrariamente: constante, desigualdade, intervalo, discagem por IN (...)ou = ANY(...). E também pode ser classificado por ele.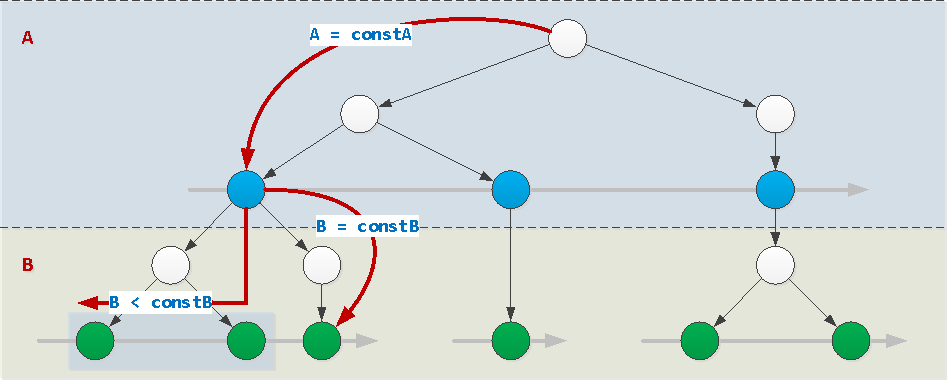
WHERE A = constA AND B [op] constB / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A = constA AND B BETWEEN constB1 AND constB2WHERE A = constA ORDER BY B
Com base nos índices de prefixo descritos acima, isso funcionará bem:WHERE A [op] const / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }WHERE A BETWEEN const1 AND const2ORDER BY AWHERE (A, B) [op] (constA, constB) / = ANY(...) / IN (...)
op : { =, >, >=, <, <= }ORDER BY A, B
Ruim: enumeração completa da "camada"
Com parte das consultas, a única enumeração do movimento no índice se torna uma enumeração completa de todos os valores em uma das "camadas". É uma sorte se houver uma unidade desses valores - e se houver milhares? ..Geralmente, esse problema ocorre se a desigualdade for usada na consulta , a condição não determina os campos anteriores na ordem do índice ou essa ordem é violada durante a classificação.WHERE A <> constWHERE B [op] const / = ANY(...) / IN (...)ORDER BY BORDER BY B, A
Ruim: intervalo ou conjunto não está no último campo
Como conseqüência do anterior - se você precisar encontrar vários valores ou seu intervalo em alguma "camada" intermediária e, em seguida, filtrar ou classificar pelos campos "mais profundos" no índice, haverá problemas se o número de valores exclusivos "no meio" do índice for ótimo.WHERE A BETWEEN constA1 AND constA2 AND B BETWEEN constB1 AND constB2WHERE A = ANY(...) AND B = constWHERE A = ANY(...) ORDER BY BWHERE A = ANY(...) AND B = ANY(...)
Ruim: expressão em vez de campo
Às vezes, um desenvolvedor inconscientemente transforma uma coluna em uma consulta em outra coisa - em alguma expressão para a qual não há índice. Isso pode ser corrigido criando um índice a partir da expressão desejada ou executando a transformação inversa:WHERE A - const1 [op] const2
consertar: WHERE A [op] const1 + const2WHERE A::typeOfConst = const
consertar: WHERE A = const::typeOfA
Levamos em consideração a cardinalidade dos campos
Suponha que você precisa de um índice (A, B), e você quer escolher apenas pela igualdade : (A, B) = (constA, constB). O uso de um índice de hash seria ideal , mas ... Além do não registro no diário (wal logging) de tais índices até a versão 10, eles também não podem existir em vários campos:CREATE INDEX ON tbl USING hash(A, B);
Em geral, você escolheu btree. Então, qual é a melhor maneira de organizar colunas nele - (A, B)ou (B, A)? Para responder a essa pergunta, é necessário levar em consideração um parâmetro como a cardinalidade dos dados na coluna correspondente - ou seja, quantos valores únicos ele contém.Vamos imaginar isso A = {1,2}, B = {1,2,3,4}e desenhar um esboço da árvore de índice para as duas opções: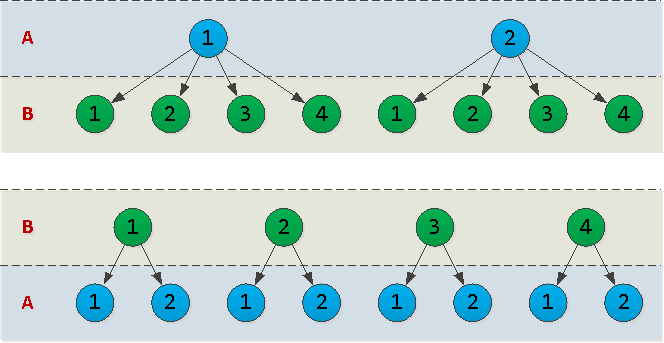 De fato, cada nó na árvore que desenhamos é uma página no índice. E quanto mais houver, mais espaço em disco o índice ocupará, mais tempo levará para ser lido.No nosso exemplo, a opção
De fato, cada nó na árvore que desenhamos é uma página no índice. E quanto mais houver, mais espaço em disco o índice ocupará, mais tempo levará para ser lido.No nosso exemplo, a opção (A, B)possui 10 nós e (B, A)- 12. Ou seja, é mais lucrativo colocar os "campos" com o menor número possível de valores possíveis "primeiro" .Ruim: muito e fora do lugar (registro de data e hora "no meio")
Exatamente por esse motivo, sempre parece suspeito se um campo com variabilidade obviamente grande como carimbo de data / hora [tz] não é o último no seu índice . Como regra, os valores do campo de carimbo de data / hora aumentam monotonicamente e os seguintes campos de índice têm apenas um valor em cada momento.CREATE TABLE tbl(A integer, B timestamp);
CREATE INDEX ON tbl(A, B);
CREATE INDEX ON tbl(B, A);

Consulta de pesquisa para índices de carimbo de data / hora não finais [tz]WITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
'timestamp' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamptz' = ANY(tpf$[1:array_length(tpf$, 1) - 1]) OR
'timestamp' = ANY(opc$[1:array_length(opc$, 1) - 1]) OR
'timestamptz' = ANY(opc$[1:array_length(opc$, 1) - 1])
ORDER BY
1, 2;
Aqui analisamos imediatamente os tipos dos campos de entrada em si e as classes de operadores aplicadas a eles - uma vez que algumas funções timestamptz como date_trunc podem se tornar um campo de índice.nmt | nmi | def | nmf$ | tpf$ | opc$
----------------------------------------------------------------------------------
tbl | tbl_b_a_idx | CREATE INDEX ... | {b,a} | {timestamp,int4} | {timestamp,int4}
Ruim: muito pouco (booleano)
O outro lado da mesma moeda, torna-se uma situação em que o índice é um campo booleano , que pode levar apenas 3 valores NULL, FALSE, TRUE. Obviamente, sua presença faz sentido se você deseja usá-lo para classificação aplicada - por exemplo, designando-o como o tipo de nó na hierarquia da árvore - seja uma pasta ou uma folha (“pastas primeiro”).CREATE TABLE tbl(
id
serial
PRIMARY KEY
, leaf_pid
integer
, leaf_type
boolean
, public
boolean
);
CREATE INDEX ON tbl(leaf_pid, leaf_type);
CREATE INDEX ON tbl(public, id);
Mas, na maioria dos casos, esse não é o caso, e as solicitações vêm com algum valor específico do campo booleano. E, em seguida, torna-se possível substituir o índice por esse campo por sua versão condicional:CREATE INDEX ON tbl(id) WHERE public;
Consulta de pesquisa booleana em índicesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
, (
SELECT
array_agg(replace(opcname::text, '_ops', '') ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indclass[i] ik
FROM
generate_subscripts(idx.indclass, 1) i
) f
JOIN
pg_opclass T
ON T.oid = f.ik
) opc$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, def
, nmf$
, tpf$
, opc$
FROM
fld
WHERE
(
'bool' = ANY(tpf$) OR
'bool' = ANY(opc$)
) AND
NOT(
ARRAY(
SELECT
nmf$[i:i+1]::text
FROM
generate_series(1, array_length(nmf$, 1) - 1) i
) &&
ARRAY[
'{leaf_pid,leaf_type}'
]
)
ORDER BY
1, 2;
nmt | nmi | def | nmf$ | tpf$ | opc$
------------------------------------------------------------------------------------
tbl | tbl_public_id_idx | CREATE INDEX ... | {public,id} | {bool,int4} | {bool,int4}
Matrizes em btree
Um ponto separado é a tentativa de "indexar a matriz" usando o índice btree. Isso é inteiramente possível, pois os operadores correspondentes se aplicam a eles :(<, >, = . .) , B-, , . ( ). , , .
Mas o problema é que usar algo que ele quer operadores de inclusão e intersecção : <@, @>, &&. Obviamente, isso não funciona - porque eles precisam de outros tipos de índices . Como essa btree não funciona para a função de acessar um elemento específico arr[i].Aprendemos a encontrar tais:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, pid
integer
, list
integer[]
);
CREATE INDEX ON tbl(pid);
CREATE INDEX ON tbl(list);
Consulta de pesquisa de matriz no btreeWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
, idx
, (
SELECT
array_agg(T::text ORDER BY f.i)
FROM
(
SELECT
clr.oid rel
, i
, idx.indkey[i] ik
FROM
generate_subscripts(idx.indkey, 1) i
) f
JOIN
pg_attribute T
ON (T.attrelid, T.attnum) = (f.rel, f.ik)
) fld$
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisunique AND
idx.indisready AND
idx.indisvalid AND
cli.relam = (
SELECT
oid
FROM
pg_am
WHERE
amname = 'btree'
LIMIT 1
)
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, ARRAY(
SELECT
(att::pg_attribute).attname
FROM
unnest(fld$) att
) nmf$
, ARRAY(
SELECT
(
SELECT
typname
FROM
pg_type
WHERE
oid = (att::pg_attribute).atttypid
)
FROM
unnest(fld$) att
) tpf$
FROM
def
)
SELECT
nmt
, nmi
, nmf$
, tpf$
, def
FROM
fld
WHERE
tpf$ && ARRAY(
SELECT
typname
FROM
pg_type
WHERE
typname ~ '^_'
)
ORDER BY
1, 2;
nmt | nmi | nmf$ | tpf$ | def
--------------------------------------------------------
tbl | tbl_list_idx | {list} | {_int4} | CREATE INDEX ...
Entradas de índice NULL
O último problema bastante comum é "desarrumar" o índice com entradas completamente NULL. Ou seja, registros em que a expressão indexada em cada uma das colunas é NULL . Esses registros não têm nenhum benefício prático, mas agregam danos a cada inserção.Geralmente eles aparecem quando você cria um campo FK ou um relacionamento de valor com preenchimento opcional na tabela. Em seguida, role o índice para que o FK funcione rapidamente ... e aqui estão eles. Quanto menos a conexão for preenchida, mais “lixo” cairá no índice. Simularemos:CREATE TABLE tbl(
id
serial
PRIMARY KEY
, fk
integer
);
CREATE INDEX ON tbl(fk);
INSERT INTO tbl(fk)
SELECT
CASE WHEN i % 10 = 0 THEN i END
FROM
generate_series(1, 1000000) i;
Na maioria dos casos, esse índice pode ser convertido em um condicional, o que também leva menos:CREATE INDEX ON tbl(fk) WHERE (fk) IS NOT NULL;
_tmp=# \di+ tbl*
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+----------------+-------+----------+----------+---------+-------------
public | tbl_fk_idx | index | postgres | tbl | 36 MB |
public | tbl_fk_idx1 | index | postgres | tbl | 2208 kB |
public | tbl_pkey | index | postgres | tbl | 21 MB |
Para encontrar esses índices, precisamos conhecer a distribuição real dos dados - afinal, leia todo o conteúdo das tabelas e sobreponha-o de acordo com as condições WHERE da ocorrência (faremos isso usando dblink ), o que pode demorar muito tempo .Consulta de pesquisa para entradas NULL em índicesWITH sch AS (
SELECT
'public'::text sch
)
, def AS (
SELECT
clr.relname nmt
, cli.relname nmi
, pg_get_indexdef(cli.oid) def
, cli.oid clioid
, clr
, cli
FROM
pg_class clr
JOIN
pg_index idx
ON idx.indrelid = clr.oid
JOIN
pg_class cli
ON cli.oid = idx.indexrelid
JOIN
pg_namespace nsp
ON nsp.oid = cli.relnamespace AND
nsp.nspname = (TABLE sch)
WHERE
NOT idx.indisprimary AND
idx.indisready AND
idx.indisvalid AND
NOT EXISTS(
SELECT
NULL
FROM
pg_constraint
WHERE
conindid = cli.oid
LIMIT 1
) AND
pg_relation_size(cli.oid) > 1 << 20
ORDER BY
clr.relname, cli.relname
)
, fld AS (
SELECT
*
, regexp_replace(
CASE
WHEN def ~ ' USING btree ' THEN
regexp_replace(def, E'.* USING btree (.*?)($| WHERE .*)', E'\\1')
END
, E' ([a-z]*_pattern_ops|(ASC|DESC)|NULLS\\s?(?:FIRST|LAST))'
, ''
, 'ig'
) fld
, CASE
WHEN def ~ ' WHERE ' THEN regexp_replace(def, E'.* WHERE ', '')
END wh
FROM
def
)
, q AS (
SELECT
nmt
, $q$
SET search_path = $q$ || quote_ident((TABLE sch)) || $q$, public;
SELECT
ARRAY[
count(*)
$q$ || string_agg(
', coalesce(sum((' || coalesce(wh, 'TRUE') || ')::integer), 0)' || E'\n' ||
', coalesce(sum(((' || coalesce(wh, 'TRUE') || ') AND (' || fld || ' IS NULL))::integer), 0)' || E'\n'
, '' ORDER BY nmi) || $q$
]
FROM
$q$ || quote_ident((TABLE sch)) || $q$.$q$ || quote_ident(nmt) || $q$
$q$ q
, array_agg(clioid ORDER BY nmi) oid$
, array_agg(nmi ORDER BY nmi) idx$
, array_agg(fld ORDER BY nmi) fld$
, array_agg(wh ORDER BY nmi) wh$
FROM
fld
WHERE
fld IS NOT NULL
GROUP BY
1
ORDER BY
1
)
, res AS (
SELECT
*
, (
SELECT
qty
FROM
dblink(
'dbname=' || current_database() || ' port=' || current_setting('port')
, q
) T(qty bigint[])
) qty
FROM
q
)
, iter AS (
SELECT
*
, generate_subscripts(idx$, 1) i
FROM
res
)
, stat AS (
SELECT
nmt table_name
, idx$[i] index_name
, pg_relation_size(oid$[i]) index_size
, pg_size_pretty(pg_relation_size(oid$[i])) index_size_humanize
, regexp_replace(fld$[i], E'^\\((.*)\\)$', E'\\1') index_fields
, regexp_replace(wh$[i], E'^\\((.*)\\)$', E'\\1') index_cond
, qty[1] table_rec_count
, qty[i * 2] index_rec_count
, qty[i * 2 + 1] index_rec_count_null
FROM
iter
)
SELECT
*
, CASE
WHEN table_rec_count > 0
THEN index_rec_count::double precision / table_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_cover_prc
, CASE
WHEN index_rec_count > 0
THEN index_rec_count_null::double precision / index_rec_count::double precision * 100
ELSE 0
END::numeric(32,2) index_null_prc
FROM
stat
WHERE
index_rec_count_null * 4 > index_rec_count
ORDER BY
1, 2;
-[ RECORD 1 ]--------+--------------
table_name | tbl
index_name | tbl_fk_idx
index_size | 37838848
index_size_humanize | 36 MB
index_fields | fk
index_cond |
table_rec_count | 1000000
index_rec_count | 1000000
index_rec_count_null | 900000
index_cover_prc | 100.00 -- 100%
index_null_prc | 90.00 -- 90% NULL-""
Espero que algumas das consultas deste artigo o ajudem.