Em antecipação ao início de um novo fluxo no curso "Developer Golang" preparou uma tradução de material interessante.
Nosso servidor DNS autorizado é usado por dezenas de milhares de sites. Respondemos a milhões de consultas diariamente. Atualmente, os ataques de DNS estão se tornando cada vez mais comuns, o DNS é uma parte importante do nosso sistema e precisamos garantir que possamos trabalhar bem sob alta carga.O dnsflood é uma pequena ferramenta que pode gerar um grande número de solicitações de udp.# timeout 20s ./dnsflood example.com 127.0.0.1 -p 2053
O monitoramento do sistema mostrou que o uso de memória do nosso serviço cresceu tão rápido que tivemos que interrompê-lo, caso contrário, ocorreríamos erros de OOM. Era como um problema de vazamento de memória; Existem várias razões para vazamentos de memória "semelhantes" e "reais":- goroutines de suspensão
- uso indevido de adiamento e finalizador
- substrings e sub-cortes
- variáveis globais
Este post fornece uma explicação detalhada de vários vazamentos.Antes de tirar conclusões, primeiro vamos realizar um perfil.Godebug
Várias ferramentas de depuração podem ser ativadas usando uma variável de ambiente GODEBUG, passando uma lista de pares separados por vírgula name=value.Planejador de rastreamento
O rastreamento do planejador pode fornecer informações sobre o comportamento das goroutinas em tempo de execução. Para ativar o rastreamento do planejador, execute o programa com GODEBUG=schedtrace=100, o valor determina o período de saída em ms.$ GODEBUG=schedtrace=100 ./redins -c config.json
SCHED 2952ms: ... runqueue=3 [26 11 7 18 13 30 6 3 24 25 11 0]
SCHED 3053ms: ... runqueue=3 [0 0 0 0 0 0 0 0 4 0 21 0]
SCHED 3154ms: ... runqueue=0 [0 6 2 4 0 30 0 5 0 11 2 5]
SCHED 3255ms: ... runqueue=1 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3355ms: ... runqueue=0 [1 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3456ms: ... runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 3557ms: ... runqueue=0 [13 0 3 0 3 33 2 0 10 8 10 14]
SCHED 3657ms: ...runqueue=3 [14 1 0 5 19 54 9 1 0 1 29 0]
SCHED 3758ms: ... runqueue=0 [67 1 5 0 0 1 0 0 87 4 0 0]
SCHED 3859ms: ... runqueue=6 [0 0 3 6 0 0 0 0 3 2 2 19]
SCHED 3960ms: ... runqueue=0 [0 0 1 0 1 0 0 1 0 1 0 0]
SCHED 4060ms: ... runqueue=5 [4 0 5 0 1 0 0 0 0 0 0 0]
SCHED 4161ms: ... runqueue=0 [0 0 0 0 0 0 0 1 0 0 0 0]
SCHED 4262ms: ... runqueue=4 [0 128 21 172 1 19 8 2 43 5 139 37]
SCHED 4362ms: ... runqueue=0 [0 0 0 0 0 0 0 0 0 0 0 0]
SCHED 4463ms: ... runqueue=6 [0 28 23 39 4 11 4 11 25 0 25 0]
SCHED 4564ms: ... runqueue=354 [51 45 33 32 15 20 8 7 5 42 6 0]
runqueue é o comprimento da fila global de goroutines a serem executadas. Os números entre parênteses são o comprimento da fila do processo.A situação ideal é quando todos os processos estão ocupados executando goroutines e o comprimento moderado da fila de execução é distribuído igualmente entre todos os processos:SCHED 2449ms: gomaxprocs=12 idleprocs=0 threads=40 spinningthreads=1 idlethreads=1 runqueue=20 [20 20 20 20 20 20 20 20 20 20 20]
Observando a saída do schedtrace , podemos ver períodos em que quase todos os processos estão ociosos. Isso significa que não estamos usando o processador na capacidade total.Rastreio de coletor de lixo
Para habilitar o rastreamento de coleta de lixo (GC), execute o programa com uma variável de ambiente GODEBUG=gctrace=1:GODEBUG=gctrace=1 ./redins -c config1.json
.
.
.
gc 30 @3.727s 1%: 0.066+21+0.093 ms clock, 0.79+128/59/0+1.1 ms cpu, 67->71->45 MB, 76 MB goal, 12 P
gc 31 @3.784s 2%: 0.030+27+0.053 ms clock, 0.36+177/81/7.8+0.63 ms cpu, 79->84->55 MB, 90 MB goal, 12 P
gc 32 @3.858s 3%: 0.026+34+0.024 ms clock, 0.32+234/104/0+0.29 ms cpu, 96->100->65 MB, 110 MB goal, 12 P
gc 33 @3.954s 3%: 0.026+44+0.13 ms clock, 0.32+191/131/57+1.6 ms cpu, 117->123->79 MB, 131 MB goal, 12 P
gc 34 @4.077s 4%: 0.010+53+0.024 ms clock, 0.12+241/159/69+0.29 ms cpu, 142->147->91 MB, 158 MB goal, 12 P
gc 35 @4.228s 5%: 0.017+61+0.12 ms clock, 0.20+296/179/94+1.5 ms cpu, 166->174->105 MB, 182 MB goal, 12 P
gc 36 @4.391s 6%: 0.017+73+0.086 ms clock, 0.21+492/216/4.0+1.0 ms cpu, 191->198->122 MB, 210 MB goal, 12 P
gc 37 @4.590s 7%: 0.049+85+0.095 ms clock, 0.59+618/253/0+1.1 ms cpu, 222->230->140 MB, 244 MB goal, 12 P
.
.
.
Como vemos aqui, a quantidade de memória usada aumenta e o tempo que o GC leva para concluir seu trabalho também aumenta. Isso significa que consumimos mais memória do que ela pode suportar.Você GODEBUGpode aprender mais sobre e algumas outras variáveis de ambiente golang aqui .Ativando o Profiler
go tool pprof- Uma ferramenta para análise e criação de perfil de dados. Existem duas maneiras de configurar pprof: chamar diretamente funções runtime/pprofno seu código, por exemplo pprof.StartCPUProfile(), ou instalar um net/http/pproflistner http e obter dados a partir daí, o que fizemos. Ele tem um pprofconsumo de recursos muito pequeno, portanto pode ser usado com segurança no desenvolvimento, mas o terminal do perfil não deve estar disponível ao público, pois dados confidenciais podem ser divulgados.Tudo o que precisamos fazer para a segunda opção é importar o pacote "net / http / pprof" :import (
_ "net/http/pprof"
)
adicione um listner http:go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
O Pprof possui vários perfis padrão:- alocações : busca todas as alocações de memória anteriores
- block : rastreamento de pilha que levou ao bloqueio de primitivas de sincronização
- goroutine : rastreia todas as goroutines atuais da pilha
- heap : busca alocações de memória de objetos ativos.
- mutex : rastreamento de pilha de titulares mutex conflitantes
- profile : perfil do processador.
- threadcreate : um rastreamento de pilha que levou à criação de novos threads no sistema operacional
- trace : rastreia a execução do programa atual.
Nota: o ponto de extremidade de rastreio, diferente de todos os outros pontos de extremidade, é um perfil de rastreio , não o pprof ; é possível visualizá-lo usando o rastreio da ferramenta go go tool pprof.
Agora que tudo está pronto, podemos olhar para as ferramentas disponíveis.Perfil do processador
$ go tool pprof http:
O criador de perfil do processador, por padrão, trabalha por 30 segundos (podemos mudar isso configurando o parâmetro seconds) e coleta amostras a cada 100 milissegundos, após o que entra no modo interativo. Os comandos mais comuns estão disponíveis top, list, web.Use top npara visualizar as entradas mais quentes no formato de texto, também existem duas opções para classificar a saída, -cumpor ordem cumulativa e -flat.(pprof) top 10 -cum
Showing nodes accounting for 1.50s, 6.19% of 24.23s total
Dropped 347 nodes (cum <= 0.12s)
Showing top 10 nodes out of 186
flat flat% sum% cum cum%
0.03s 0.12% 0.12% 16.7s 69.13% (*Server).serveUDPPacket
0.05s 0.21% 0.33% 15.6s 64.51% (*Server).serveDNS
0 0% 0.33% 14.3s 59.10% (*ServeMux).ServeDNS
0 0% 0.33% 14.2s 58.73% HandlerFunc.ServeDNS
0.01s 0.04% 0.37% 14.2s 58.73% main.handleRequest
0.07s 0.29% 0.66% 13.5s 56.00% (*DnsRequestHandler).HandleRequest
0.99s 4.09% 4.75% 7.56s 31.20% runtime.gentraceback
0.02s 0.08% 4.83% 7.02s 28.97% runtime.systemstack
0.31s 1.28% 6.11% 6.62s 27.32% runtime.mallocgc
0.02s 0.08% 6.19% 6.35s 26.21% (*DnsRequestHandler).FindANAME
(pprof)
use listpara explorar a função.(pprof) list handleRequest
Total: 24.23s
ROUTINE ======================== main.handleRequest in /home/arash/go/src/arvancloud/redins/redins.go
10ms 14.23s (flat, cum) 58.73% of Total
. . 35: l *handler.RateLimiter
. . 36: configFile string
. . 37:)
. . 38:
. . 39:func handleRequest(w dns.ResponseWriter, r *dns.Msg) {
10ms 610ms 40: context := handler.NewRequestContext(w, r)
. 50ms 41: logger.Default.Debugf("handle request: [%d] %s %s", r.Id, context.RawName(), context.Type())
. . 42:
. . 43: if l.CanHandle(context.IP()) {
. 13.57s 44: h.HandleRequest(context)
. . 45: } else {
. . 46: context.Response(dns.RcodeRefused)
. . 47: }
. . 48:}
. . 49:
(pprof)
A equipe webgera um gráfico SVG de áreas críticas e o abre no navegador.(pprof)web handleReques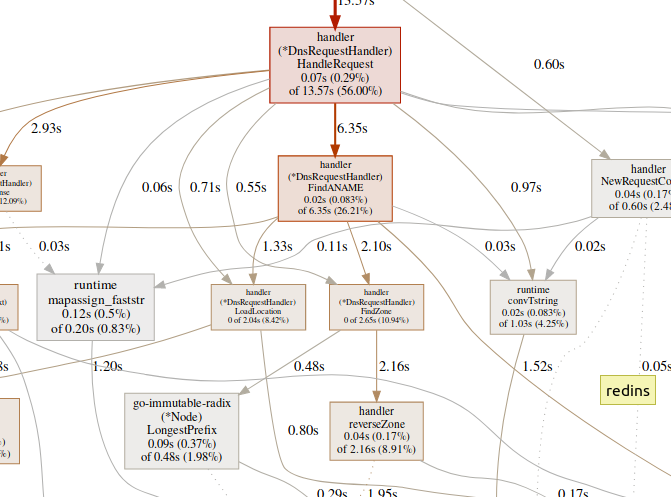 Uma grande quantidade de tempo gasto em funções do GC, como
Uma grande quantidade de tempo gasto em funções do GC, como runtime.mallocgc, geralmente resulta em alocação significativa de memória, o que pode adicionar carga ao coletor de lixo e aumentar a latência.Uma grande quantidade de tempo gasto em mecanismos de sincronização, como runtime.chansendou runtime.lock, pode ser um sinal de conflito.Uma grande quantidade de tempo gasto syscall.Read/Writesignifica uso excessivo de operações de E / S.Perfilador de memória
$ go tool pprof http:
Por padrão, mostra o tempo de vida da memória alocada. Podemos ver o número de objetos selecionados usando -alloc_objectsoutras opções úteis: -iuse_objectse -inuse_spacepara verificar a memória ao vivo .Geralmente, se você deseja reduzir o consumo de memória, é necessário observar -inuse_space, mas se deseja reduzir a latência, verifique -alloc_objectsapós um tempo de execução / carregamento suficiente.Identificação de um gargalo
É importante primeiro determinar o tipo de gargalo (processador, E / S, memória) com o qual estamos lidando. Além dos criadores de perfil, há outro tipo de ferramenta.go tool tracepode mostrar o que as goroutines fazem em detalhes. Para coletar um exemplo de rastreamento, precisamos enviar uma solicitação http para o terminal de rastreamento:$ curl http:
O arquivo gerado pode ser visualizado usando a ferramenta de rastreamento:$ go tool trace trace.out
2019/12/25 15:30:50 Parsing trace...
2019/12/25 15:30:59 Splitting trace...
2019/12/25 15:31:10 Opening browser. Trace viewer is listening on http:
O rastreamento da ferramenta Go é um aplicativo da web que usa o protocolo Chrome DevTools e é compatível apenas com os navegadores Chrome. A página principal é mais ou menos assim:Exibir rastreamento (0s-409.575266ms)Exibir rastreamento (411.075559ms-747.252311ms)Exibir rastreamento (747.252311ms-1.234968945s)Exibir rastreamento (1.234968945s-1.774245108s)Exibir rastreamento (1.774245484s-2.111339514s)Ver trace (2.111339514s-2.674030898s)Ver trace (2.674031362s-3.044145798s)Ver trace (3.044145798s-3.458795252s)Ver trace (3.43953778s-4.075080634s)Ver trace (4.075081098s-4.439271287s)View35 4.439 -4,814869651s)Exibir rastreamento (4.814869651s-5.253597835s)Análise da goroutinaPerfil de bloqueio de rede ()Sincronização bloqueando perfil ()SYSCALL perfil de bloqueio ()Scheduler latência perfil ()tarefas definidas pelo usuárioregiões definidas pelo usuáriomínima de utilização modificadorTrace divide o tempo traço para que o seu navegador pode lidar com isso.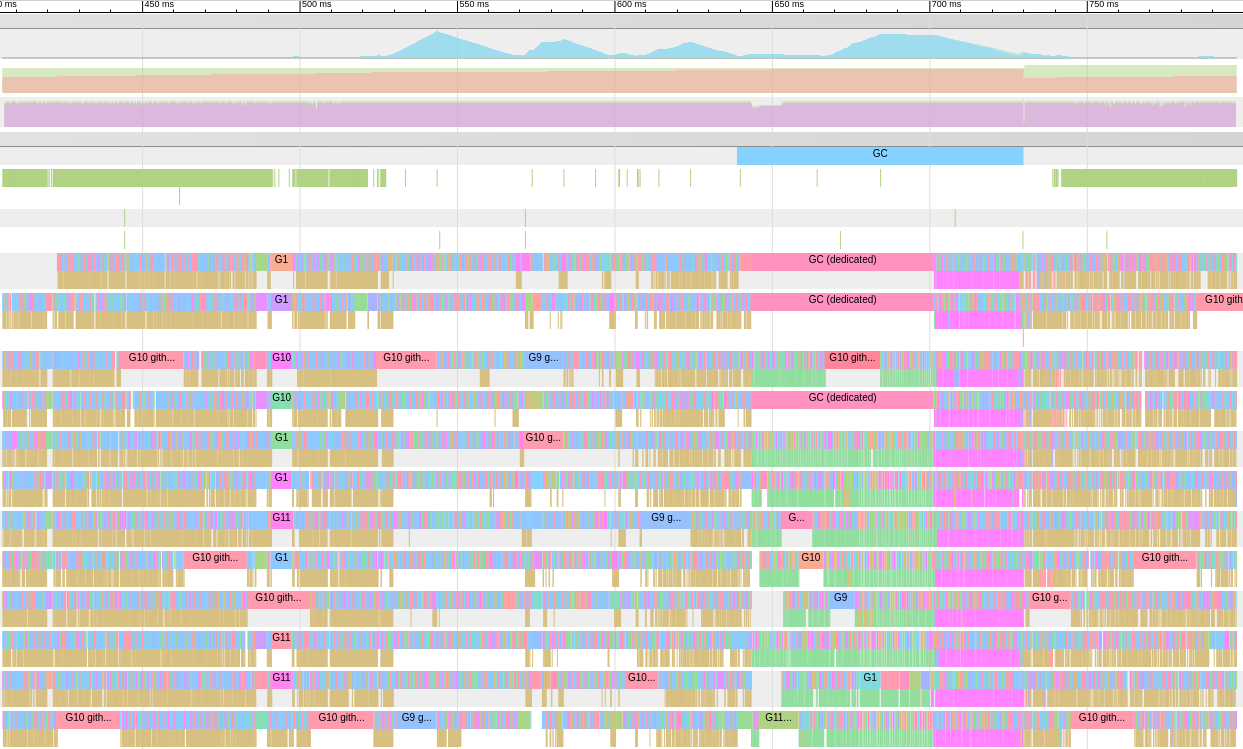 Há uma enorme quantidade de dados aqui, o que os torna quase ilegível se não sabemos o que estamos procurando. Vamos deixar por enquanto.O link a seguir na página principal é "análise de goroutines" , que mostra os diferentes tipos de goroutines em funcionamento no programa durante o período de rastreamento:
Há uma enorme quantidade de dados aqui, o que os torna quase ilegível se não sabemos o que estamos procurando. Vamos deixar por enquanto.O link a seguir na página principal é "análise de goroutines" , que mostra os diferentes tipos de goroutines em funcionamento no programa durante o período de rastreamento:Goroutines:
github.com/miekg/dns.(*Server).serveUDPPacket N=441703
runtime.gcBgMarkWorker N=12
github.com/karlseguin/ccache.(*Cache).worker N=2
main.Start.func1 N=1
runtime.bgsweep N=1
arvancloud/redins/handler.NewHandler.func2 N=1
runtime/trace.Start.func1 N=1
net/http.(*conn).serve N=1
runtime.timerproc N=3
net/http.(*connReader).backgroundRead N=1
N=40
Clique no primeiro elemento com N = 441703 , é o que obtemos: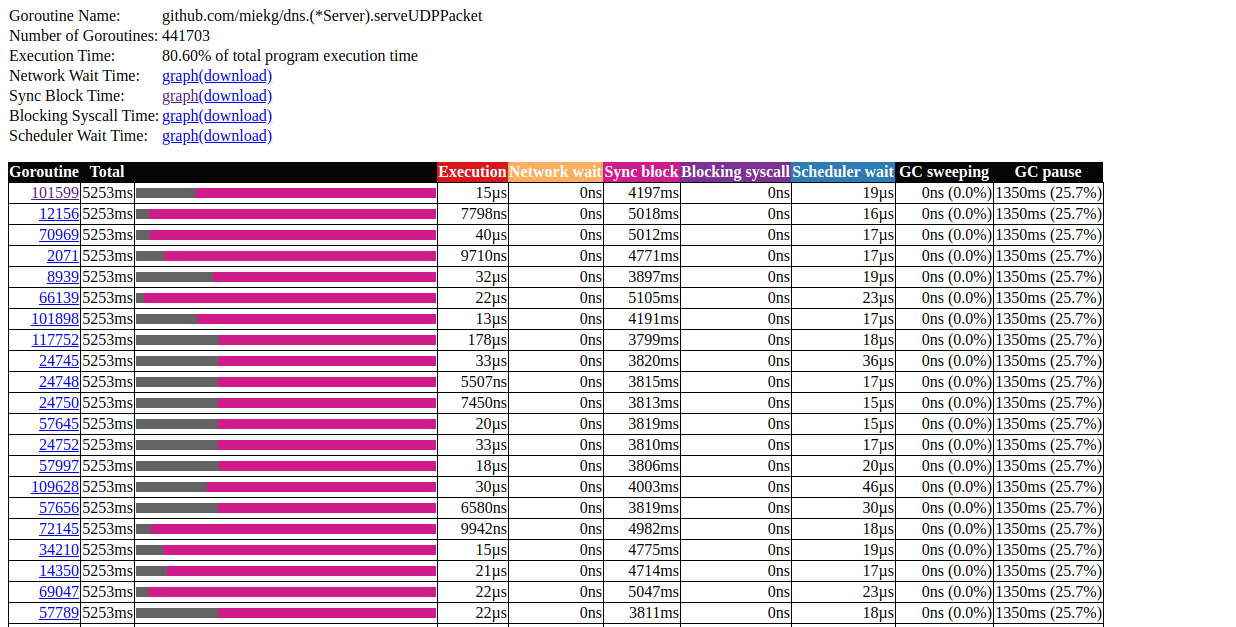 análise de goroutinIsso é muito interessante. A maioria das operações leva quase pouco tempo para ser concluída e a maior parte do tempo é gasta no bloco Sync. Vamos dar uma olhada em um deles:
análise de goroutinIsso é muito interessante. A maioria das operações leva quase pouco tempo para ser concluída e a maior parte do tempo é gasta no bloco Sync. Vamos dar uma olhada em um deles: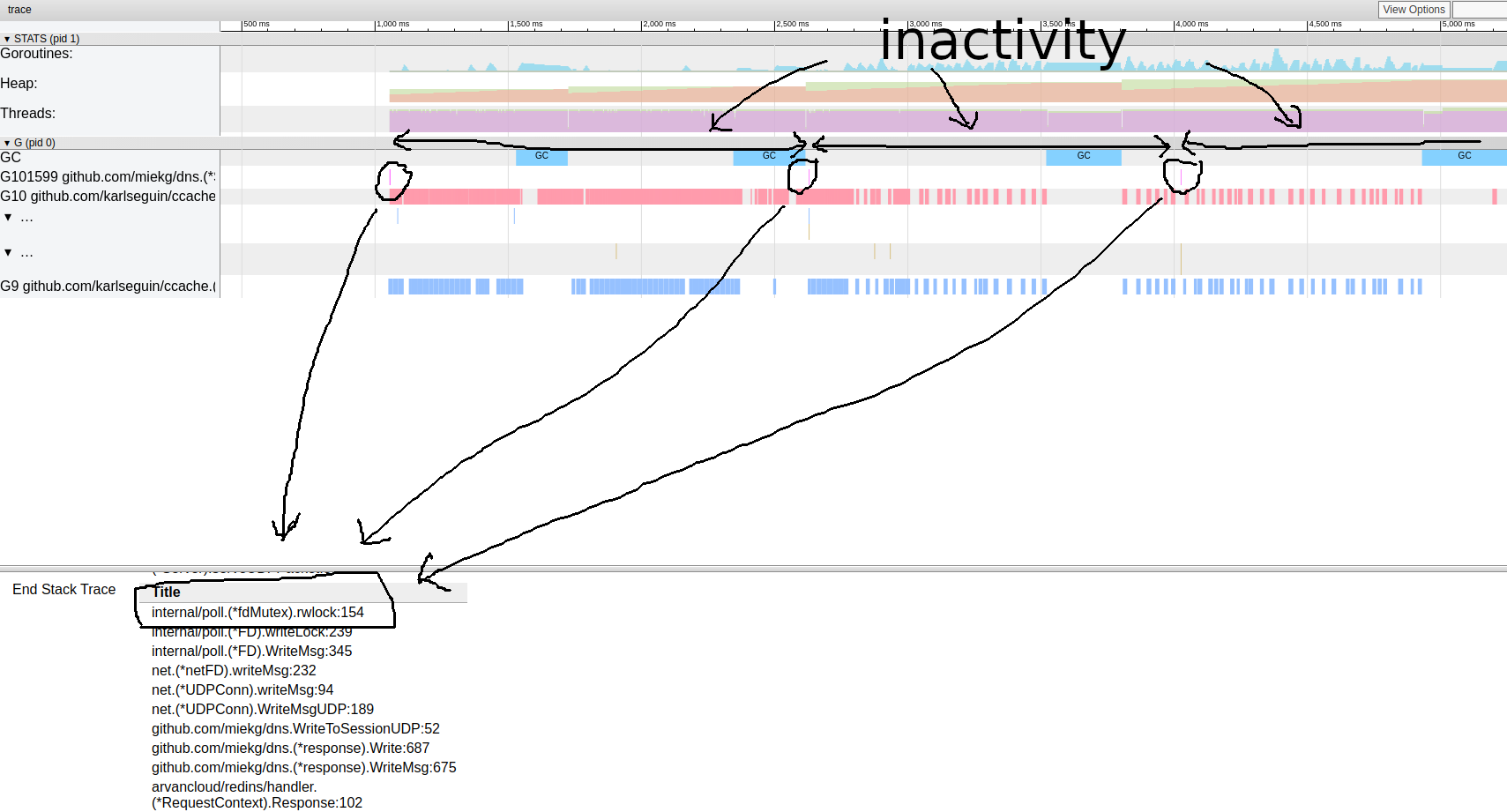 padrão de rastreamento de goroutineParece que nosso programa é quase sempre inativo. A partir daqui, podemos ir diretamente para a ferramenta de bloqueio; Como o perfil de bloqueio está desativado por padrão, precisamos ativá-lo em nosso código primeiro:
padrão de rastreamento de goroutineParece que nosso programa é quase sempre inativo. A partir daqui, podemos ir diretamente para a ferramenta de bloqueio; Como o perfil de bloqueio está desativado por padrão, precisamos ativá-lo em nosso código primeiro:runtime.SetBlockProfileRate(1)
Agora podemos obter uma seleção de bloqueios:$ go tool pprof http:
(pprof) top
Showing nodes accounting for 16.03wks, 99.75% of 16.07wks total
Dropped 87 nodes (cum <= 0.08wks)
Showing top 10 nodes out of 27
flat flat% sum% cum cum%
10.78wks 67.08% 67.08% 10.78wks 67.08% internal/poll.(*fdMutex).rwlock
5.25wks 32.67% 99.75% 5.25wks 32.67% sync.(*Mutex).Lock
0 0% 99.75% 5.25wks 32.67% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 99.75% 5.25wks 32.68% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0 0% 99.75% 16.04wks 99.81% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0 0% 99.75% 10.78wks 67.08% arvancloud/redins/handler.(*DnsRequestHandler).Response
0 0% 99.75% 10.78wks 67.08% arvancloud/redins/handler.(*RequestContext).Response
0 0% 99.75% 5.25wks 32.67% arvancloud/redins/handler.ChooseIp
0 0% 99.75% 16.04wks 99.81% github.com/miekg/dns.(*ServeMux).ServeDNS
0 0% 99.75% 16.04wks 99.81% github.com/miekg/dns.(*Server).serveDNS
(pprof)
Aqui temos dois bloqueios diferentes ( poll.fdMutex e sync.Mutex ), responsáveis por quase 100% dos bloqueios. Isso confirma nossa suposição sobre um conflito de bloqueio, agora só precisamos descobrir onde isso acontece:(pprof) svg lock
Este comando cria um gráfico vetorial de todos os nós que levam em conta os conflitos, com ênfase nas funções de bloqueio: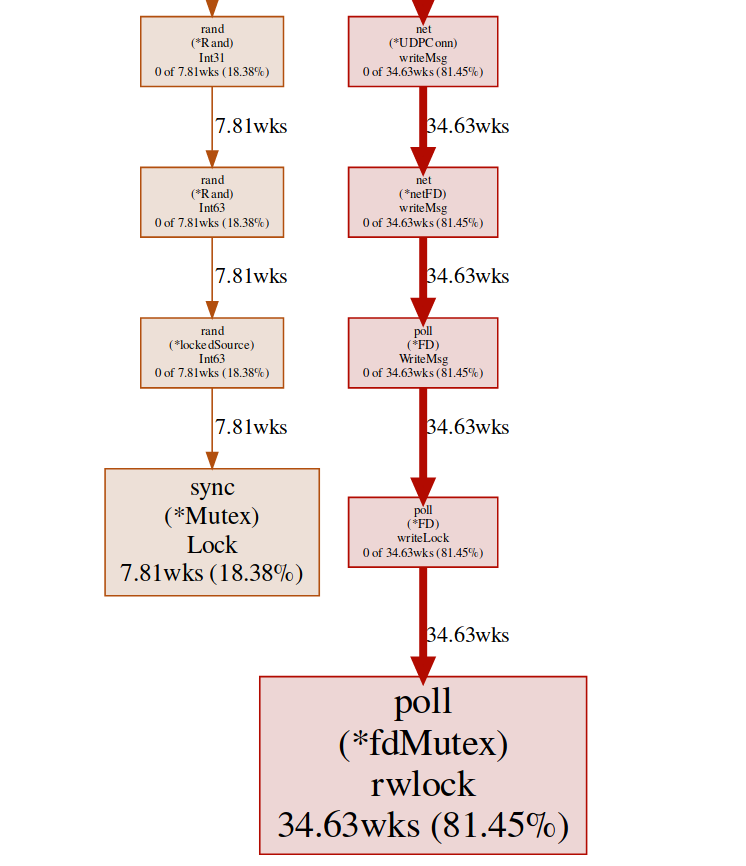 svg-graph do ponto final de bloqueio, podemos obter o mesmo resultado do ponto final da goroutine:
svg-graph do ponto final de bloqueio, podemos obter o mesmo resultado do ponto final da goroutine:$ go tool pprof http:
e depois:(pprof) top
Showing nodes accounting for 294412, 100% of 294424 total
Dropped 84 nodes (cum <= 1472)
Showing top 10 nodes out of 32
flat flat% sum% cum cum%
294404 100% 100% 294404 100% runtime.gopark
8 0.0027% 100% 294405 100% github.com/miekg/dns.(*Server).serveUDPPacket
0 0% 100% 58257 19.79% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 100% 58259 19.79% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0 0% 100% 293852 99.81% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0 0% 100% 235406 79.95% arvancloud/redins/handler.(*DnsRequestHandler).Response
0 0% 100% 235406 79.95% arvancloud/redins/handler.(*RequestContext).Response
0 0% 100% 58140 19.75% arvancloud/redins/handler.ChooseIp
0 0% 100% 293852 99.81% github.com/miekg/dns.(*ServeMux).ServeDNS
0 0% 100% 293900 99.82% github.com/miekg/dns.(*Server).serveDNS
(pprof)
quase todos os nossos programas estão localizados em runtime.gopark, é um agendador que dorme goroutines; uma razão muito comum para isso é um conflito de bloqueio(pprof) svg gopark
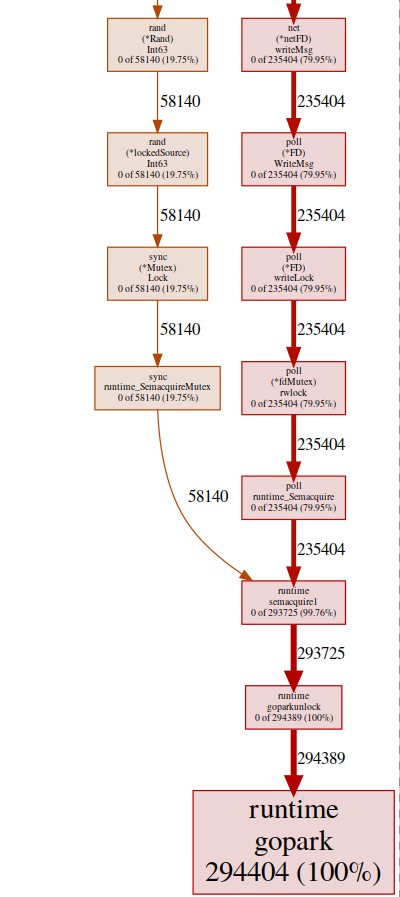 svg-graph do ponto final goroutinAqui vemos duas fontes de conflito:
svg-graph do ponto final goroutinAqui vemos duas fontes de conflito:UDPConn.WriteMsg ()
Parece que todas as respostas acabam escrevendo para o mesmo FD (daí o bloqueio), isso faz sentido, pois todas elas têm o mesmo endereço de origem.Realizamos um pequeno experimento com várias soluções e, no final, decidimos usar vários ouvintes para equilibrar a carga. Assim, permitimos que o sistema operacional equilibre solicitações recebidas entre diferentes conexões e reduza conflitos.Rand ()
Parece que há um bloqueio nas funções regulares de matemática / rand (mais sobre isso aqui ). Isso pode ser facilmente corrigido com a ajuda de Rand.New()um gerador de números aleatórios que cria um invólucro sem bloqueio.rg := rand.New(rand.NewSource(int64(time.Now().Nanosecond())))
Está um pouco melhor, mas criar uma nova fonte é sempre caro. É possível fazer ainda melhor? No nosso caso, realmente não precisamos de um número aleatório. Só precisamos de uma distribuição uniforme para equilibrar a carga, e acontece que isso Time.Nanoseconds()pode nos servir.Agora que removemos todos os bloqueios desnecessários, vejamos os resultados: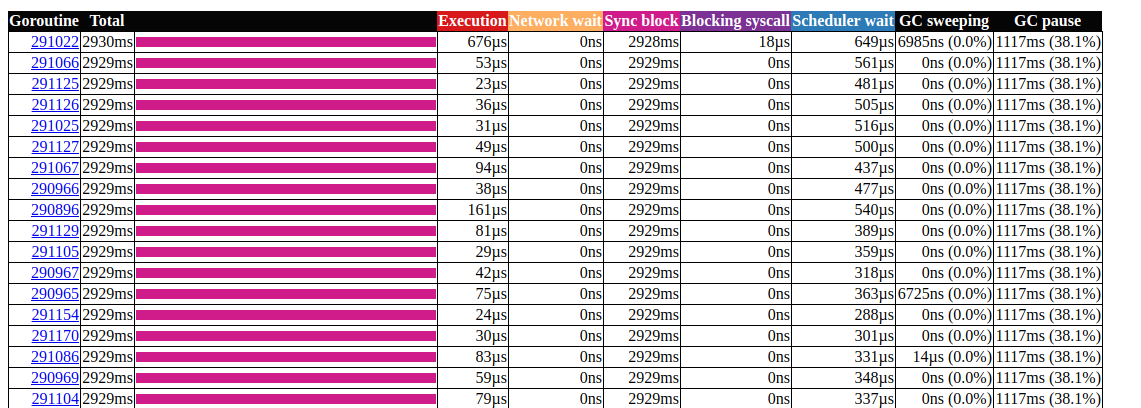 análise de goroutinParece melhor, mas ainda assim, na maioria das vezes leva para bloquear a sincronização. Vamos dar uma olhada no perfil de bloqueio de sincronização na página principal da interface do usuário de rastreamento:
análise de goroutinParece melhor, mas ainda assim, na maioria das vezes leva para bloquear a sincronização. Vamos dar uma olhada no perfil de bloqueio de sincronização na página principal da interface do usuário de rastreamento: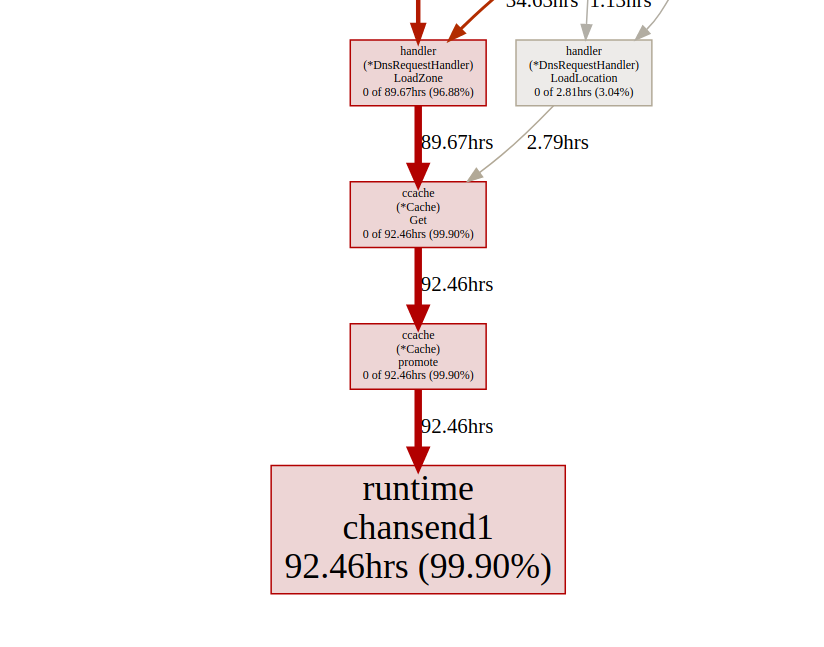 linhado tempo do bloqueio de sincronização Vamos dar uma olhada na função de reforço
linhado tempo do bloqueio de sincronização Vamos dar uma olhada na função de reforço ccacheno ponto final de bloqueio pprof:(pprof) list promote
ROUTINE ======================== github.com/karlseguin/ccache.(*Cache).promote in ...
0 9.66days (flat, cum) 99.70% of Total
. . 155: h.Write([]byte(key))
. . 156: return c.buckets[h.Sum32()&c.bucketMask]
. . 157:}
. . 158:
. . 159:func (c *Cache) promote(item *Item) {
. 9.66days 160: c.promotables <- item
. . 161:}
. . 162:
. . 163:func (c *Cache) worker() {
. . 164: defer close(c.donec)
. . 165:
Todas as chamadas ccache.Get()terminam em um canal c.promotables. O cache é uma parte importante do nosso serviço; devemos considerar outras opções; No Dgraph há um excelente artigo sobre o estado do cache! Go , eles também têm um excelente módulo de cache chamado ristretto . Infelizmente, o ristretto ainda não oferece suporte à versão baseada em Ttl. Podemos solucionar esse problema usando um problema muito grande MaxCoste mantendo o valor de tempo limite em nossa estrutura de cache (queremos manter os dados desatualizados no cache). Vamos ver o resultado ao usar o ristretto: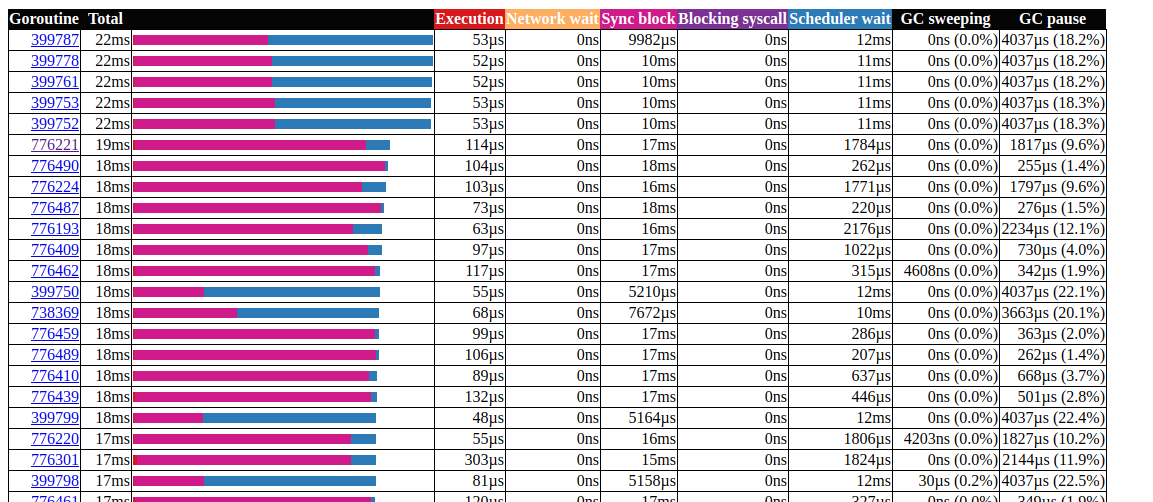 análise de goroutinÓtimo!Conseguimos reduzir o tempo de execução máximo da gorutina de 5000 ms para 22 ms. No entanto, a maior parte do tempo de execução é dividida entre "bloqueio de sincronização" e "aguardando o agendador". Vamos ver se podemos fazer algo sobre isso: a
análise de goroutinÓtimo!Conseguimos reduzir o tempo de execução máximo da gorutina de 5000 ms para 22 ms. No entanto, a maior parte do tempo de execução é dividida entre "bloqueio de sincronização" e "aguardando o agendador". Vamos ver se podemos fazer algo sobre isso: a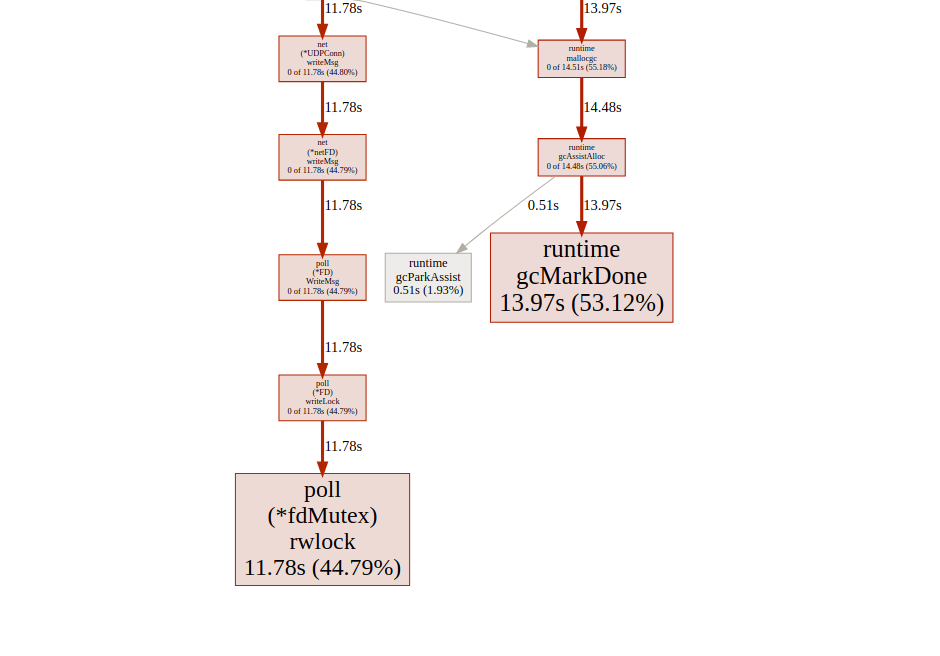 linha do tempo do bloqueio de sincronizaçãoPodemos fazer pouco com isso
linha do tempo do bloqueio de sincronizaçãoPodemos fazer pouco com isso fdMutex.rwlock, agora vamos nos concentrar em outro: gcMarkDone, que representa 53% do tempo de bloqueio. Esse recurso faz parte do processo de coleta de lixo. A presença deles na seção crítica é frequentemente um sinal de que estamos sobrecarregando o GC.otimização de alocação
Nesse ponto, pode ser útil ver como a coleta de lixo funciona; Go usa um seletor de marcação e varredura. Ele monitora tudo o que está selecionado e, assim que atinge o dobro do tamanho (ou qualquer outro valor em que o GOGC está definido) do tamanho do tamanho anterior, a limpeza do GC é iniciada. A avaliação ocorre em três etapas:- Configuração do marcador (STW)
- Marcação (paralela)
- Fim da rotulagem (STW)
As fases Stop The World (STW) interrompem todo o processo, embora sejam geralmente muito curtas, ciclos contínuos podem aumentar a duração. Isso ocorre no momento (vá v1.13) que as goroutines são suplantadas apenas nos pontos da chamada de função, portanto, para um ciclo contínuo, é possível um tempo de pausa arbitrariamente longo, pois o GC espera que todas as goroutines parem.Durante a marcação, o gc usa cerca de 25% GOMAXPROCS, mas funções auxiliares adicionais podem ser adicionadas à força para marcar a assistência , isso acontece quando a goroutine em movimento rápido ultrapassa o marcador de segundo plano para reduzir o atraso causado pelo gc, precisamos minimizar o uso de heap.Duas coisas a serem observadas:- o número de alocações é mais importante que o tamanho (por exemplo, 1000 alocações de memória de uma estrutura de 20 bytes criam muito mais carga no heap do que uma única alocação de 20.000 bytes);
- Ao contrário de idiomas como C / C ++, nem todas as alocações de memória acabam no heap. O compilador go decide se a variável será movida para o heap ou se poderá ser colocada dentro do quadro da pilha. Diferente das variáveis alocadas no heap, as variáveis alocadas na pilha não carregam gc.
Para obter mais informações sobre o modelo de memória Go e a arquitetura do GC, consulte esta apresentação .Para otimizar a alocação de memória, usamos o kit de ferramentas go:- perfil de processador para encontrar distribuições quentes;
- perfilador de memória para rastrear alocações;
- rastreador de padrões; Gc
- análise de escape para descobrir por que a alocação ocorre.
Vamos começar com o perfil do processador:$ go tool pprof http:
(pprof) top 20 -cum
Showing nodes accounting for 7.27s, 29.10% of 24.98s total
Dropped 315 nodes (cum <= 0.12s)
Showing top 20 nodes out of 201
flat flat% sum% cum cum%
0 0% 0% 16.42s 65.73% github.com/miekg/dns.(*Server).serveUDPPacket
0.02s 0.08% 0.08% 16.02s 64.13% github.com/miekg/dns.(*Server).serveDNS
0.02s 0.08% 0.16% 13.69s 54.80% github.com/miekg/dns.(*ServeMux).ServeDNS
0.01s 0.04% 0.2% 13.48s 53.96% github.com/miekg/dns.HandlerFunc.ServeDNS
0.02s 0.08% 0.28% 13.47s 53.92% main.handleRequest
0.24s 0.96% 1.24% 12.50s 50.04% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
0.81s 3.24% 4.48% 6.91s 27.66% runtime.gentraceback
3.82s 15.29% 19.78% 5.48s 21.94% syscall.Syscall
0.02s 0.08% 19.86% 5.44s 21.78% arvancloud/redins/handler.(*DnsRequestHandler).Response
0.06s 0.24% 20.10% 5.25s 21.02% arvancloud/redins/handler.(*RequestContext).Response
0.03s 0.12% 20.22% 4.97s 19.90% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
0.56s 2.24% 22.46% 4.92s 19.70% runtime.mallocgc
0.07s 0.28% 22.74% 4.90s 19.62% github.com/miekg/dns.(*response).WriteMsg
0.04s 0.16% 22.90% 4.40s 17.61% github.com/miekg/dns.(*response).Write
0.01s 0.04% 22.94% 4.36s 17.45% github.com/miekg/dns.WriteToSessionUDP
1.43s 5.72% 28.66% 4.30s 17.21% runtime.pcvalue
0.01s 0.04% 28.70% 4.15s 16.61% runtime.newstack
0.06s 0.24% 28.94% 4.09s 16.37% runtime.copystack
0.01s 0.04% 28.98% 4.05s 16.21% net.(*UDPConn).WriteMsgUDP
0.03s 0.12% 29.10% 4.04s 16.17% net.(*UDPConn).writeMsg
Estamos particularmente interessados em funções relacionadas. mallocgcÉ aqui que ajuda com tags(pprof) svg mallocgc
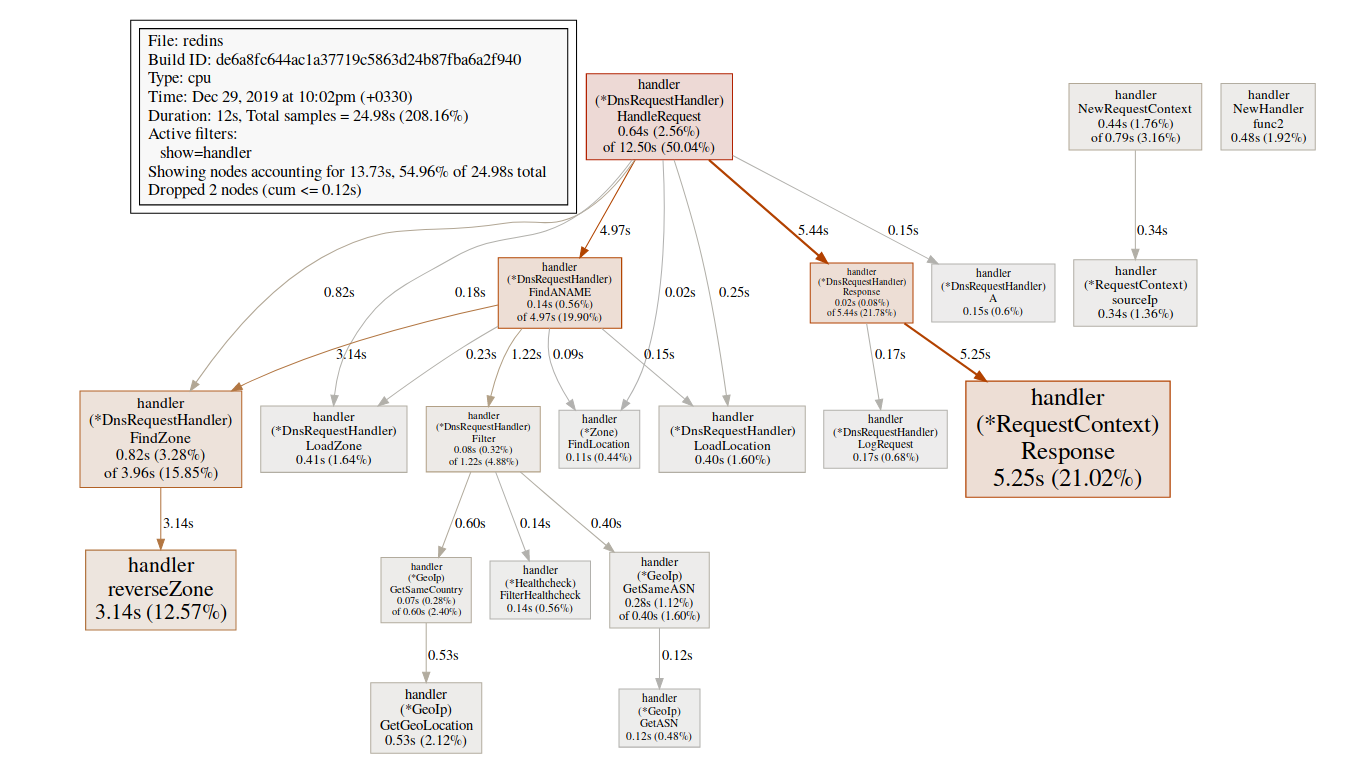 Podemos rastrear a distribuição usando o terminal
Podemos rastrear a distribuição usando o terminal alloc, a opção alloc_objectsignifica o número total de alocações, existem outras opções para usar memória e espaço de alocação.$ go tool pprof -alloc_objects http:
(pprof) top -cum
Active filters:
show=handler
Showing nodes accounting for 58464353, 59.78% of 97803168 total
Dropped 1 node (cum <= 489015)
Showing top 10 nodes out of 19
flat flat% sum% cum cum%
15401215 15.75% 15.75% 70279955 71.86% arvancloud/redins/handler.(*DnsRequestHandler).HandleRequest
2392100 2.45% 18.19% 27198697 27.81% arvancloud/redins/handler.(*DnsRequestHandler).FindANAME
711174 0.73% 18.92% 14936976 15.27% arvancloud/redins/handler.(*DnsRequestHandler).Filter
0 0% 18.92% 14161410 14.48% arvancloud/redins/handler.(*DnsRequestHandler).Response
14161410 14.48% 33.40% 14161410 14.48% arvancloud/redins/handler.(*RequestContext).Response
7284487 7.45% 40.85% 11118401 11.37% arvancloud/redins/handler.NewRequestContext
10439697 10.67% 51.52% 10439697 10.67% arvancloud/redins/handler.reverseZone
0 0% 51.52% 10371430 10.60% arvancloud/redins/handler.(*DnsRequestHandler).FindZone
2680723 2.74% 54.26% 8022046 8.20% arvancloud/redins/handler.(*GeoIp).GetSameCountry
5393547 5.51% 59.78% 5393547 5.51% arvancloud/redins/handler.(*DnsRequestHandler).LoadLocation
A partir de agora, podemos usar a lista para cada função e ver se podemos reduzir a alocação de memória. Vamos verificar:funções do tipo printf(pprof) list handleRequest
Total: 97803168
ROUTINE ======================== main.handleRequest in /home/arash/go/src/arvancloud/redins/redins.go
2555943 83954299 (flat, cum) 85.84% of Total
. . 35: l *handler.RateLimiter
. . 36: configFile string
. . 37:)
. . 38:
. . 39:func handleRequest(w dns.ResponseWriter, r *dns.Msg) {
. 11118401 40: context := handler.NewRequestContext(w, r)
2555943 2555943 41: logger.Default.Debugf("handle request: [%d] %s %s", r.Id, context.RawName(), context.Type())
. . 42:
. . 43: if l.CanHandle(context.IP()) {
. 70279955 44: h.HandleRequest(context)
. . 45: } else {
. . 46: context.Response(dns.RcodeRefused)
. . 47: }
. . 48:}
. . 49:
A linha 41 é especialmente interessante, mesmo quando a depuração é desativada, a memória ainda é alocada lá, podemos usar a análise de escape para examiná-la com mais detalhes.Go Escape Analysis Tool é na verdade um sinalizador de compilador$ go build -gcflags '-m'
Você pode adicionar outro -m para obter mais informações.$ go build -gcflags '-m '
para uma interface mais conveniente, use o arquivo de anotação de exibição .$ go build -gcflags '-m'
.
.
.
../redins.go:39:20: leaking param: w
./redins.go:39:42: leaking param: r
./redins.go:41:55: r.MsgHdr.Id escapes to heap
./redins.go:41:75: context.RawName() escapes to heap
./redins.go:41:91: context.Request.Type() escapes to heap
./redins.go:41:23: handleRequest []interface {} literal does not escape
./redins.go:219:17: leaking param: path
.
.
.
Aqui todos os parâmetros Debugfvão para a pilha. Isto é devido à maneira de determinar Debugf:func (l *EventLogger) Debugf(format string, args ...interface{})
Todos os parâmetros são argsconvertidos em um tipo interface{}que é sempre despejado no heap. Podemos excluir os logs de depuração ou usar uma biblioteca de logs com uma distribuição zero, por exemplo, zerolog .Para mais informações sobre análise de escape, consulte "Eficiência na alocação em golang" .Trabalhar com strings(pprof) list reverseZone
Total: 100817064
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
6127746 10379086 (flat, cum) 10.29% of Total
. . 396: logger.Default.Warning("log queue is full")
. . 397: }
. . 398:}
. . 399:
. . 400:func reverseZone(zone string) string {
. 4251340 401: x := strings.Split(zone, ".")
. . 402: var y string
. . 403: for i := len(x) - 1; i >= 0; i-- {
6127746 6127746 404: y += x[i] + "."
. . 405: }
. . 406: return y
. . 407:}
. . 408:
. . 409:func (h *DnsRequestHandler) LoadZones() {
(pprof)
Como uma linha no Go é imutável, a criação de uma linha temporária causa alocação de memória. A partir do Go 1.10, você pode usá-lo strings.Builderpara criar uma sequência.(pprof) list reverseZone
Total: 93437002
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
0 7580611 (flat, cum) 8.11% of Total
. . 396: logger.Default.Warning("log queue is full")
. . 397: }
. . 398:}
. . 399:
. . 400:func reverseZone(zone string) string {
. 3681140 401: x := strings.Split(zone, ".")
. . 402: var sb strings.Builder
. 3899471 403: sb.Grow(len(zone)+1)
. . 404: for i := len(x) - 1; i >= 0; i-- {
. . 405: sb.WriteString(x[i])
. . 406: sb.WriteByte('.')
. . 407: }
. . 408: return sb.String()
Como não nos importamos com o valor da linha invertida, podemos eliminá- Split()lo simplesmente invertendo a linha inteira.(pprof) list reverseZone
Total: 89094296
ROUTINE ======================== arvancloud/redins/handler.reverseZone in /home/arash/go/src/arvancloud/redins/handler/handler.go
3801168 3801168 (flat, cum) 4.27% of Total
. . 400:func reverseZone(zone string) []byte {
. . 401: runes := []rune("." + zone)
. . 402: for i, j := 0, len(runes)-1; i < j; i, j = i+1, j-1 {
. . 403: runes[i], runes[j] = runes[j], runes[i]
. . 404: }
3801168 3801168 405: return []byte(string(runes))
. . 406:}
. . 407:
. . 408:func (h *DnsRequestHandler) LoadZones() {
. . 409: h.LastZoneUpdate = time.Now()
. . 410: zones, err := h.Redis.SMembers("redins:zones")
Leia mais sobre como trabalhar com strings aqui .sync.Pool
(pprof) list GetASN
Total: 69005282
ROUTINE ======================== arvancloud/redins/handler.(*GeoIp).GetASN in /home/arash/go/src/arvancloud/redins/handler/geoip.go
1146897 1146897 (flat, cum) 1.66% of Total
. . 231:func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
1146897 1146897 232: var record struct {
. . 233: AutonomousSystemNumber uint `maxminddb:"autonomous_system_number"`
. . 234: }
. . 235: err := g.ASNDB.Lookup(ip, &record)
. . 236: if err != nil {
. . 237: logger.Default.Errorf("lookup failed : %s", err)
(pprof) list GetGeoLocation
Total: 69005282
ROUTINE ======================== arvancloud/redins/handler.(*GeoIp).GetGeoLocation in /home/arash/go/src/arvancloud/redins/handler/geoip.go
1376298 3604572 (flat, cum) 5.22% of Total
. . 207:
. . 208:func (g *GeoIp) GetGeoLocation(ip net.IP) (latitude float64, longitude float64, country string, err error) {
. . 209: if !g.Enable || g.CountryDB == nil {
. . 210: return
. . 211: }
1376298 1376298 212: var record struct {
. . 213: Location struct {
. . 214: Latitude float64 `maxminddb:"latitude"`
. . 215: LongitudeOffset uintptr `maxminddb:"longitude"`
. . 216: } `maxminddb:"location"`
. . 217: Country struct {
. . 218: ISOCode string `maxminddb:"iso_code"`
. . 219: } `maxminddb:"country"`
. . 220: }
. . 221:
. . 222: if err := g.CountryDB.Lookup(ip, &record); err != nil {
. . 223: logger.Default.Errorf("lookup failed : %s", err)
. . 224: return 0, 0, "", err
. . 225: }
. 2228274 226: _ = g.CountryDB.Decode(record.Location.LongitudeOffset, &longitude)
. . 227:
. . 228: return record.Location.Latitude, longitude, record.Country.ISOCode, nil
. . 229:}
. . 230:
. . 231:func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
Usamos as funções maxmiddb para obter dados de geolocalização. Essas funções são tomadas interface{}como parâmetros, que, como vimos anteriormente, podem causar disparos de heap.podemos usar sync.Poolpara armazenar em cache elementos selecionados mas não utilizados para reutilização subsequente.type MMDBGeoLocation struct {
Coordinations struct {
Latitude float64 `maxminddb:"latitude"`
Longitude float64
LongitudeOffset uintptr `maxminddb:"longitude"`
} `maxminddb:"location"`
Country struct {
ISOCode string `maxminddb:"iso_code"`
} `maxminddb:"country"`
}
type MMDBASN struct {
AutonomousSystemNumber uint `maxminddb:"autonomous_system_number"`
}
func (g *GeoIp) GetGeoLocation(ip net.IP) (*MMDBGeoLocation, error) {
if !g.Enable || g.CountryDB == nil {
return nil, EMMDBNotAvailable
}
var record *MMDBGeoLocation = g.LocationPool.Get().(*MMDBGeoLocation)
logger.Default.Debugf("ip : %s", ip)
if err := g.CountryDB.Lookup(ip, &record); err != nil {
logger.Default.Errorf("lookup failed : %s", err)
return nil, err
}
_ = g.CountryDB.Decode(record.Coordinations.LongitudeOffset, &record.Coordinations.Longitude)
logger.Default.Debug("lat = ", record.Coordinations.Latitude, " lang = ", record.Coordinations.Longitude, " country = ", record.Country.ISOCode)
return record, nil
}
func (g *GeoIp) GetASN(ip net.IP) (uint, error) {
var record *MMDBASN = g.AsnPool.Get().(*MMDBASN)
err := g.ASNDB.Lookup(ip, record)
if err != nil {
logger.Default.Errorf("lookup failed : %s", err)
return 0, err
}
logger.Default.Debug("asn = ", record.AutonomousSystemNumber)
return record.AutonomousSystemNumber, nil
}
Mais sobre o sync.Pool aqui .Existem muitas outras otimizações possíveis, mas, no momento, parece que já fizemos o suficiente. Para obter mais informações sobre técnicas de otimização de memória, leia Eficiência de alocação em serviços Go de alto desempenho .resultados
Para visualizar os resultados da otimização de memória, usamos um diagrama go tool tracechamado "Utilização Mínima do Mutator", aqui Mutator significa não gc.Antes da otimização: aqui temos uma janela de cerca de 500 milissegundos sem uso eficiente (o gc consome todos os recursos) e nunca obteremos um uso eficaz de 80% a longo prazo. Queremos que a janela de zero uso efetivo seja a menor possível e o mais rápido possível para atingir 100% de uso, algo como isto:após a otimização:
aqui temos uma janela de cerca de 500 milissegundos sem uso eficiente (o gc consome todos os recursos) e nunca obteremos um uso eficaz de 80% a longo prazo. Queremos que a janela de zero uso efetivo seja a menor possível e o mais rápido possível para atingir 100% de uso, algo como isto:após a otimização: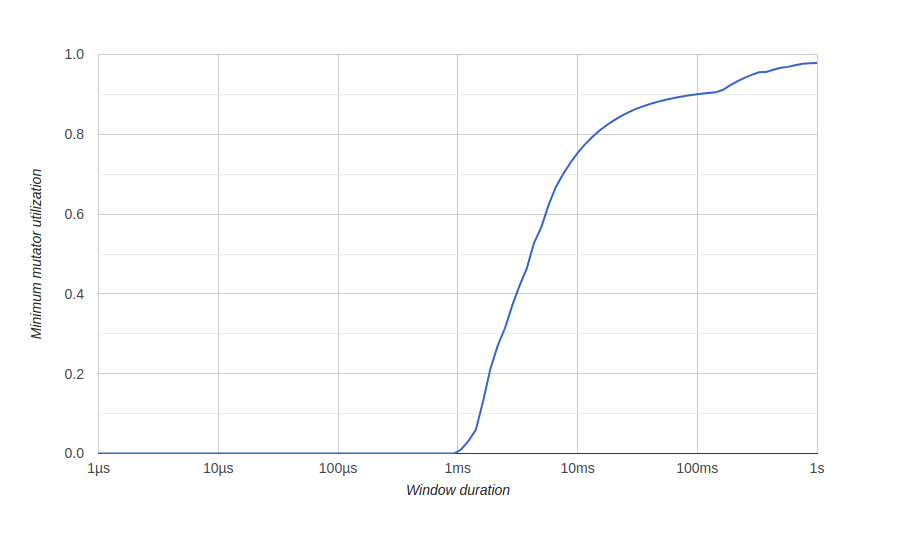
Conclusão
Usando as ferramentas go, conseguimos otimizar nosso serviço para lidar com um grande número de solicitações e melhor uso dos recursos do sistema.Você pode ver nosso código fonte no GitHub . Aqui está uma versão não otimizada e aqui está uma versão otimizada.Também será útil
Isso é tudo. Vejo você no curso !