Algumas semanas atrás, em uma conversa durante o jantar, um colega reclamou de algum tipo de processo lento. Ele calculou o número de bytes gerados, o número de ciclos de processamento e, finalmente, a quantidade de RAM. Um colega disse que uma GPU moderna com uma largura de banda de memória superior a 500 GB / s iria cumprir sua tarefa e não sufocar.Pareceu-me que esta é uma abordagem interessante. Pessoalmente, não avaliei anteriormente os objetivos de desempenho dessa perspectiva. Sim, eu sei sobre a diferença no desempenho do processador e da memória. Eu sei escrever código que faz uso pesado do cache. Conheço os números aproximados de atraso. Mas isso não é suficiente para avaliar imediatamente a largura de banda da memória.Aqui está um experimento mental. Imagine na memória uma matriz contínua de bilhões de números inteiros de 32 bits. São 4 gigabytes. Quanto tempo levará para percorrer essa matriz e adicionar os valores? Quantos bytes por segundo a CPU pode ler da RAM? Dados contínuos? Acesso aleatório? Quão bem esse processo pode ser paralelo?Você dirá que estas são perguntas inúteis. Programas reais são complexos demais para tornar um marco tão ingênuo. E aqui está! A resposta real é "dependendo da situação".No entanto, acho que vale a pena explorar essa questão. Não estou tentando encontrar a resposta . Mas acho que podemos definir alguns limites superiores e inferiores, alguns pontos interessantes no meio e aprender alguma coisa no processo.
Eu sei escrever código que faz uso pesado do cache. Conheço os números aproximados de atraso. Mas isso não é suficiente para avaliar imediatamente a largura de banda da memória.Aqui está um experimento mental. Imagine na memória uma matriz contínua de bilhões de números inteiros de 32 bits. São 4 gigabytes. Quanto tempo levará para percorrer essa matriz e adicionar os valores? Quantos bytes por segundo a CPU pode ler da RAM? Dados contínuos? Acesso aleatório? Quão bem esse processo pode ser paralelo?Você dirá que estas são perguntas inúteis. Programas reais são complexos demais para tornar um marco tão ingênuo. E aqui está! A resposta real é "dependendo da situação".No entanto, acho que vale a pena explorar essa questão. Não estou tentando encontrar a resposta . Mas acho que podemos definir alguns limites superiores e inferiores, alguns pontos interessantes no meio e aprender alguma coisa no processo.Os números que todo programador deve saber
Se você lê blogs de programação, provavelmente encontrou "números que todo programador deveria conhecer". Eles se parecem com isso:Link para o cache L1 0,5 ns
Previsão incorreta de 5 ns
Link para cache L2 7 ns 14x para cache L1
Captura / liberação Mutex 25 ns
Link para a memória principal 100 ns 20x para cache L2, 200x para cache L1
Comprima 1000 bytes com Zippy 3000 ns 3 μs
Envio de 1000 bytes em uma rede de 1 Gbps 10.000 ns 10 μs
Leitura aleatória 4000 com SSD 150.000 ns 150 μs ~ 1GB / s SSD
Leia 1 MB sequencialmente de 250.000 ns 250 μs
Pacote de ida e volta dentro do data center 500.000 ns 500 μs
Leitura sequencial de 1 MB no SSD 1.000.000 ns 1.000 μs 1 ms ~ 1 GB / s SSD, memória 4x
Pesquisa em disco 10.000.000 ns 10.000 μs 10 ms 20x para o data center
Leia 1 MB sequencialmente do disco 20.000.000 ns 20.000 μs 20 ms 80x para a memória, 20x para SSD
Envio de pacote CA-> Holanda-> CA 150.000.000 ns 150.000 μs 150 ms
Fonte: Jonas BonerÓtima lista. Ele aparece no HackerNews pelo menos uma vez por ano. Todo programador deve conhecer esses números.Mas esses números são sobre outra coisa. Latência e largura de banda não são a mesma coisa.Atraso em 2020
Essa lista foi compilada em 2012 e, neste artigo de 2020, os tempos mudaram. Aqui estão os números para o Intel i7 com o StackOverflow .Acerto no cache L1, ~ 4 ciclos (2,1 - 1,2 ns)
Acerto no cache L2, ~ 10 ciclos (5,3 - 3,0 ns)
Acerto no cache L3, para um único núcleo ~ 40 ciclos (21,4 - 12,0 ns)
Acerto no cache L3, juntos por outro kernel ~ 65 ciclos (34,8 - 19,5 ns)
Bata no cache L3, com uma alteração para outro kernel ~ 75 ciclos (40,2 - 22,5 ns)
RAM local ~ 60 ns
Interessante! O que mudou?- L1 tornou-se mais lento;
0,5 → 1,5
- L2 mais rápido;
7 → 4,2
- A proporção de L1 e L2 é muito reduzida;
2,5x 14(Uau!)
- O cache L3 agora se tornou o padrão;
12 40
- RAM tornou-se mais rápida;
100 → 60
Não tiraremos conclusões de longo alcance. Não está claro como os números originais foram calculados. Não vamos comparar maçãs com laranjas.Aqui estão alguns dados da wikichip sobre a largura de banda e o tamanho do cache do meu processador.Largura de banda da memória: 39,74 Gigabytes por segundo
Cache L1: 192 kilobytes (32 KB por núcleo)
Cache L2: 1,5 megabytes (256 KB por núcleo)
Cache L3: 12 megabytes (compartilhado; 2 MB por núcleo)
O que eu quero saber:- Limite superior do desempenho da RAM
- limite inferior
- Limites de cache L1 / L2 / L3
Benchmarking ingênuo
Vamos fazer alguns testes. Para medir a largura de banda, escrevi um programa C ++ simples. Muito aproximadamente, ela se parece com isso.
std::vector<int> nums;
for (size_t i = 0; i < 1024*1024*1024; ++i)
nums.push_back(rng() % 1024);
for (int thread_count = 1; thread_count <= MAX_THREADS; ++thread_count) {
auto slice_len = nums.size() / thread_count;
for (size_t thread = 0; thread < thread_count; ++thread) {
auto begin = nums.begin() + thread * slice_len;
auto end = (thread == thread_count - 1)
? nums.end() : begin + slice_len;
futures.push_back(std::async([begin, end] {
int64_t sum = 0;
for (auto ptr = begin; ptr < end; ++ptr)
sum += *ptr;
return sum;
}));
}
int64_t sum = 0;
for (auto& future : futures)
sum += future.get();
}
Alguns detalhes são omitidos. Mas você entendeu a ideia. Crie uma matriz grande e contínua de elementos. Divida a matriz em fragmentos separados. Processe cada fragmento em um thread separado. Acumule resultados.Você também precisa medir o acesso aleatório. É muito difícil. Eu tentei de várias maneiras, finalmente decidi misturar índices pré-computados. Cada índice existe exatamente uma vez. Em seguida, o loop interno itera sobre os índices e calcula sum += nums[index].std::vector<int> nums = ;
std::vector<uint32_t> indices = ;
int64_t sum = 0;
for (auto ptr = indices.begin(); ptr < indices.end(); ++ptr) {
auto idx = *ptr;
sum += nums[idx];
}
return sum;
Ao calcular a taxa de transferência, não considero a memória da matriz de índices. Somente bytes que contribuem para o total são contados sum. Não comparo meu hardware, mas avalio a capacidade de trabalhar com conjuntos de dados de tamanhos diferentes e com esquemas de acesso diferentes.Realizaremos testes com três tipos de dados:int- o principal inteiro de 32 bitsmatri4x4- contém int[16]; se encaixa em uma linha de cache de 64 bytesmatrix4x4_simd- usa ferramentas internas__m256iGrande bloco
Meu primeiro teste funciona com um grande bloco de memória. Um bloco de Nitens de 1 GB é destacado e preenchido com pequenos valores aleatórios. Um loop simples itera sobre uma matriz N vezes, para acessar a memória com um volume N para calcular a soma int64_t. Vários segmentos dividem a matriz e cada um obtém acesso ao mesmo número de elementos.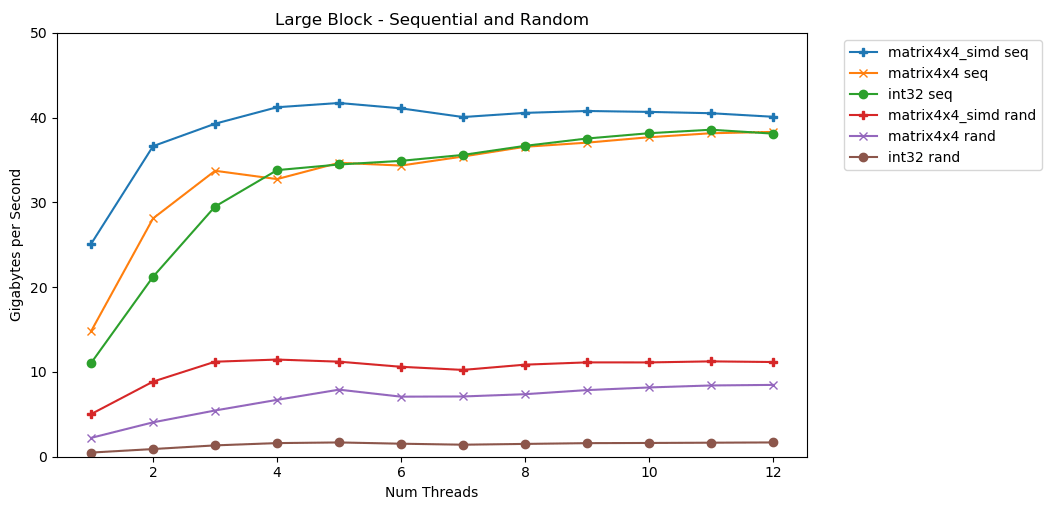 Surpresa! Neste gráfico, pegamos o tempo médio de execução da operação de soma e convertemos de
Surpresa! Neste gráfico, pegamos o tempo médio de execução da operação de soma e convertemos de runtime_in_nanosecondspara gigabytes_per_second.Resultado muito bom. int32pode ler sequencialmente 11 GB / s em um único fluxo. Escala linearmente até atingir 38 GB / s. Testes matrix4x4e matrix4x4_simdmais rápido, mas descanse no mesmo teto.Existe um limite claro e óbvio para a quantidade de dados que podemos ler da RAM por segundo. No meu sistema, isso é aproximadamente 40 GB / s. Isso está em conformidade com as especificações atuais listadas acima.A julgar pelos três gráficos inferiores, o acesso aleatório é lento. Muito, muito devagar. O desempenho de thread único int32é desprezível 0,46 GB / s. Isso é 24 vezes mais lento que o empilhamento seqüencial a 11,03 GB / s! O teste matrix4x4mostra o melhor resultado, porque é executado em linhas de cache completas. Mas ainda é quatro a sete vezes mais lento que o acesso seqüencial e atinge um pico de apenas 8 GB / s.Bloco pequeno: leitura sequencial
No meu sistema, o tamanho do cache L1 / L2 / L3 para cada fluxo é de 32 KB, 256 KB e 2 MB. O que acontece se você pegar um bloco de 32 kilobytes de elementos e iterá-lo 125.000 vezes? São 4 GB de memória, mas sempre iremos para o cache.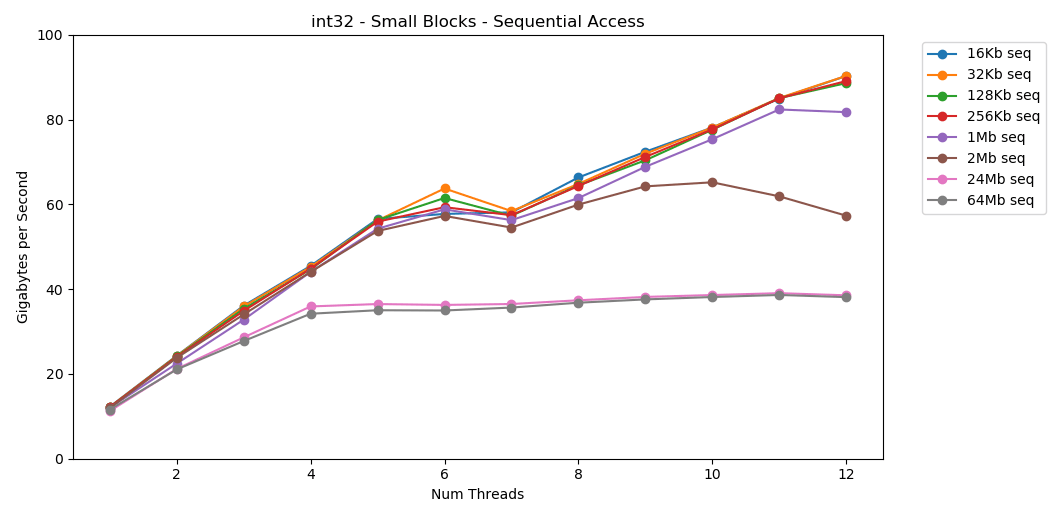 Impressionante! O desempenho de thread único é semelhante à leitura de um bloco grande, cerca de 12 GB / s. Só que desta vez, o multithreading ultrapassa o limite de 40 GB / s. Faz sentido. Os dados permanecem no cache, portanto, o gargalo da RAM não aparece. Para dados que não couberam no cache L3, o mesmo teto de cerca de 38 GB / s se aplica.O teste
Impressionante! O desempenho de thread único é semelhante à leitura de um bloco grande, cerca de 12 GB / s. Só que desta vez, o multithreading ultrapassa o limite de 40 GB / s. Faz sentido. Os dados permanecem no cache, portanto, o gargalo da RAM não aparece. Para dados que não couberam no cache L3, o mesmo teto de cerca de 38 GB / s se aplica.O teste matrix4x4mostra resultados semelhantes ao circuito, mas ainda mais rápido; 31 GB / s no modo single-thread, 171 GB / s no multi-thread.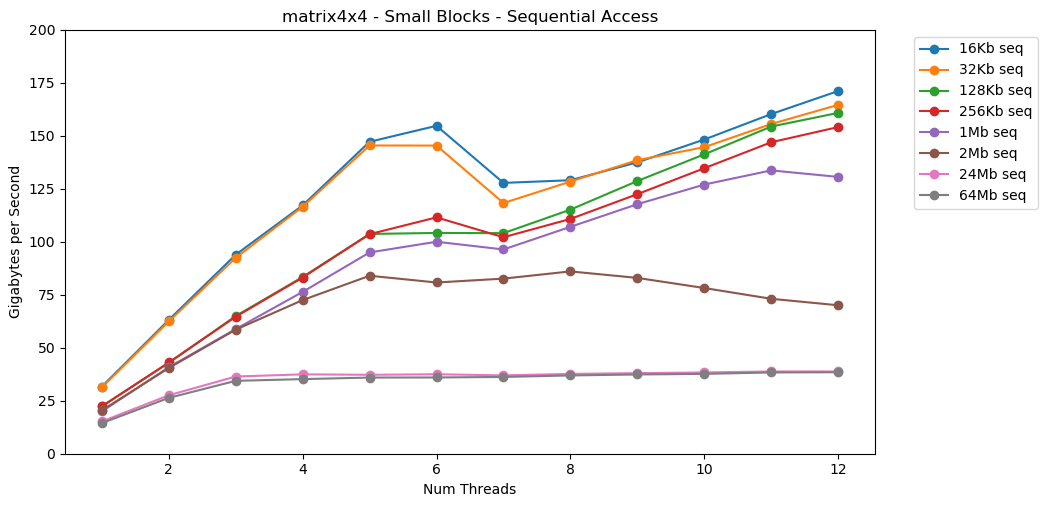 Agora vamos olhar
Agora vamos olhar matrix4x4_simd. Preste atenção ao eixo y.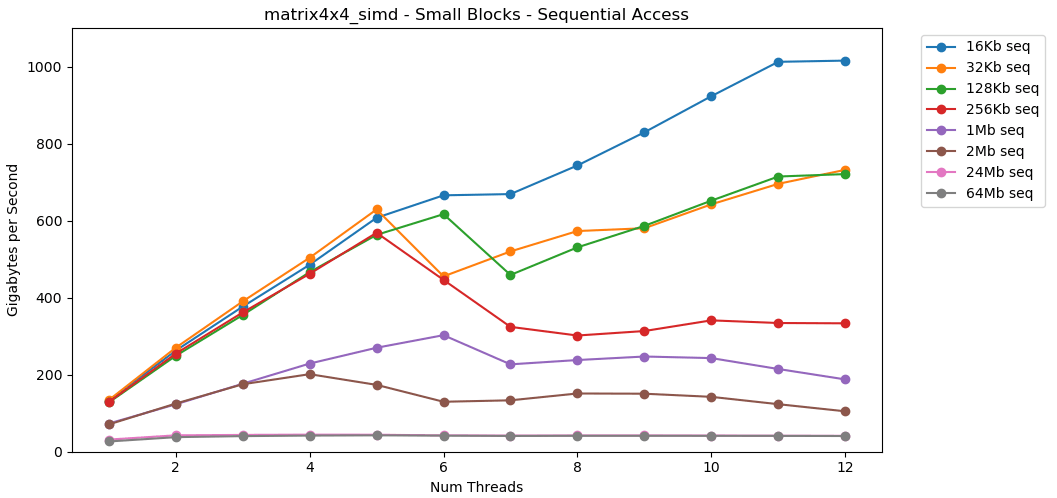
matrix4x4_simdexcepcionalmente rápido. É 10 vezes mais rápido que int32. Em um bloco de 16 KB, ele ainda ultrapassa 1000 GB / s!Obviamente, este é um teste sintético de superfície. A maioria dos aplicativos não executa a mesma operação com os mesmos dados um milhão de vezes seguidas. O teste não mostra desempenho no mundo real.Mas a lição é clara. Dentro do cache, os dados são processados rapidamente . Com um teto muito alto ao usar o SIMD: mais de 100 GB / s no modo de rosca única, mais de 1000 GB / s em multithread. A gravação de dados no cache é lenta e com um limite rígido de cerca de 40 GB / s.Bloco pequeno: leitura aleatória
Vamos fazer o mesmo, mas agora com acesso aleatório. Esta é a minha parte favorita do artigo.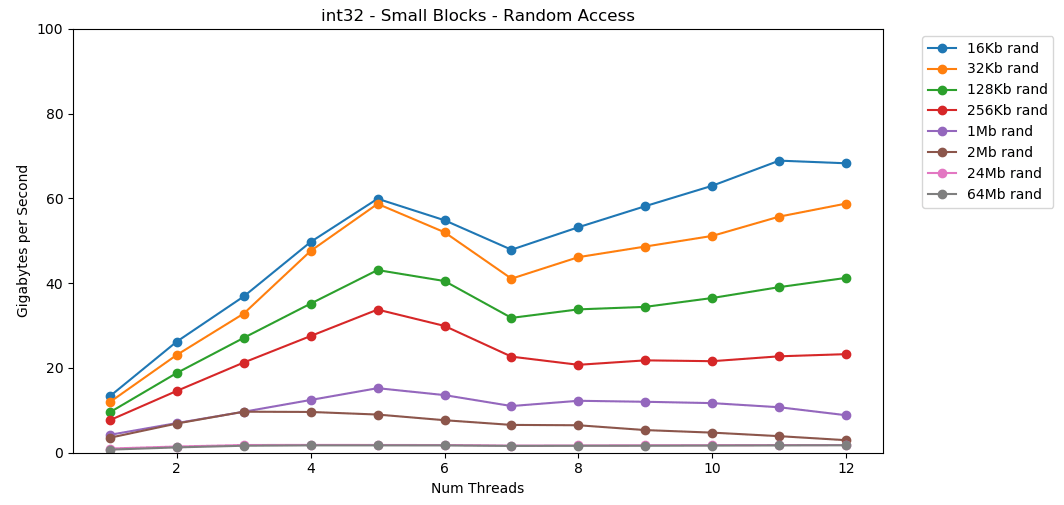 A leitura de valores aleatórios da RAM é lenta, apenas 0,46 GB / s. A leitura de valores aleatórios do cache L1 é muito rápida: 13 GB / s. Isso é mais rápido do que ler dados seriais
A leitura de valores aleatórios da RAM é lenta, apenas 0,46 GB / s. A leitura de valores aleatórios do cache L1 é muito rápida: 13 GB / s. Isso é mais rápido do que ler dados seriais int32da RAM (11 GB / s).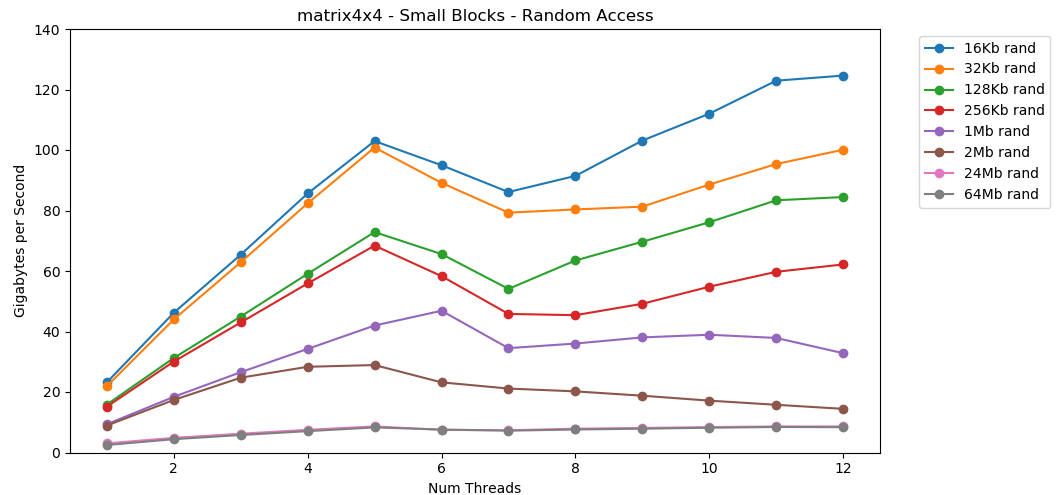 O teste
O teste matrix4x4mostra um resultado semelhante para o mesmo modelo, mas duas vezes mais rápido que int.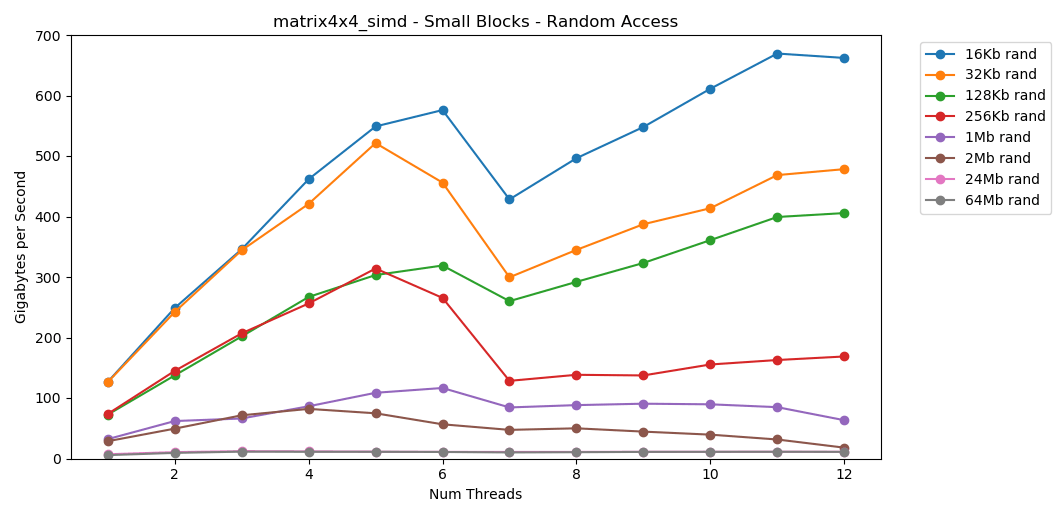 O acesso aleatório é
O acesso aleatório é matrix4x4_simdincrivelmente rápido.Achados de acesso aleatório
A leitura livre da memória é lenta. Catastroficamente lento. Menos de 1 GB / s para os dois casos de teste int32. Ao mesmo tempo, as leituras aleatórias do cache são surpreendentemente rápidas. É comparável à leitura seqüencial da RAM.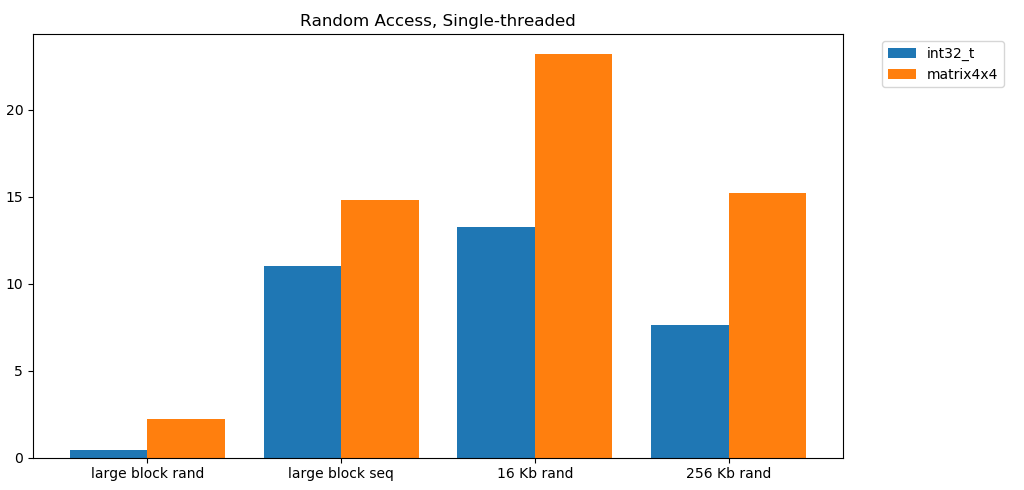 Ele precisa ser digerido. O acesso aleatório ao cache é comparável em velocidade ao acesso seqüencial à RAM. A queda de L1 16 KB para L2 256 KB é apenas metade ou menos.Eu acho que isso terá consequências profundas.
Ele precisa ser digerido. O acesso aleatório ao cache é comparável em velocidade ao acesso seqüencial à RAM. A queda de L1 16 KB para L2 256 KB é apenas metade ou menos.Eu acho que isso terá consequências profundas.Listas vinculadas são consideradas prejudiciais
Perseguir um ponteiro (pular em ponteiros) é ruim. Muito muito mal. Quanto está diminuindo o desempenho? Veja por si mesmo. Eu fiz um teste extra que envolve matrix4x4em std::unique_ptr. Cada acesso passa por um ponteiro. Aqui está um resultado terrível, apenas catastrófico. 1 fio | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Bloco grande - Seq | 14,8 GB / s | 0,8 GB / s | 19x
16 KB - Seq | 31,6 GB / s | 2,2 GB / s | 14x |
256 KB - Seq | 22,2 GB / s | 1,9 GB / s | 12x |
Bloco grande - Rand | 2,2 GB / s | 0,1 GB / s | 22x |
16 KB - Rand | 23,2 GB / s | 1,7 GB / s | 14x |
256 KB - Rand | 15,2 GB / s | 0,8 GB / s | 19x
6 tópicos | matrix4x4 | unique_ptr | diff |
-------------------- | --------------- | ------------ | -------- |
Bloco grande - Seq | 34,4 GB / s | 2,5 GB / s | 14x |
16 KB - Seq | 154,8 GB / s | 8,0 GB / s | 19x
256 KB - Seq | 111,6 GB / s | 5,7 GB / s | 20x |
Bloco grande - Rand | 7,1 GB / s | 0,4 GB / s | 18x |
16 KB - Rand | 95,0 GB / s | 7,8 GB / s | 12x |
256 KB - Rand | 58,3 GB / s | 1,6 GB / s | 36x |A soma sequencial dos valores atrás do ponteiro é realizada a uma velocidade inferior a 1 GB / s. A velocidade de acesso aleatório ignorado do cache é de apenas 0,1 GB / s.Perseguir um ponteiro diminui a execução do código de 10 a 20 vezes. Não deixe seus amigos usarem listas vinculadas. Por favor, pense sobre o cache.Estimativa de orçamento para quadros
É comum que os desenvolvedores de jogos definam um limite (orçamento) para a carga na CPU e a quantidade de memória. Mas nunca vi um orçamento de largura de banda.Nos jogos modernos, o FPS continua a crescer. Agora é de 60 FPS. VR opera a uma frequência de 90 Hz. Eu tenho um monitor de jogos de 144 Hz. É incrível, então os 60 FPS parecem uma merda. Eu nunca voltarei ao monitor antigo. Esportes e serpentinas Twitch monitora 240 Hz. Este ano, a Asus lançou um monstro de 360 Hz na CES.Meu processador tem um limite superior de cerca de 40 GB / s. Parece um grande número! No entanto, a uma frequência de 240 Hz, apenas 167 MB por quadro são obtidos. Um aplicativo realista pode gerar tráfego de 5 GB / s a 144 Hz, que é de apenas 69 MB por quadro.Aqui está uma tabela com alguns números. | 1 | 10 30 60 90 144 240 360
-------- | ------- | -------- | -------- | -------- | ------ - | -------- | -------- | -------- |
40 GB / s | 40 GB | 4 GB | 1,3 GB | 667 MB | 444 MB | 278 MB | 167 MB | 111 MB |
10 GB / s | 10 GB | 1 GB | 333 MB | 166 MB | 111 MB | 69 MB | 42 MB | 28 MB |
1 GB / s | 1 GB | 100 MB | 33 MB | 17 MB | 11 MB | 7 MB | 4 MB | 3 MB |
Parece-me que é útil avaliar problemas dessa perspectiva. Isso deixa claro que algumas idéias não são viáveis. Atingir 240 Hz não é fácil. Isso não vai acontecer por si só.Os números que todo programador deve saber (2020)
A lista anterior está desatualizada. Agora, ele precisa ser atualizado e colocado em conformidade até 2020.Aqui estão alguns números para o meu computador doméstico. Esta é uma mistura de AIDA64, Sandra e meus benchmarks. As figuras não dão uma imagem completa e são apenas um ponto de partida.Latência L1: 1 ns
Atraso L2: 2,5 ns
Atraso L3: 10 ns
Latência RAM: 50 ns
(por segmento)
Banda L1: 210 GB / s
Banda L2: 80 GB / s
Banda L3: 60 GB / s
(todo sistema)
Banda RAM: 45 GB / s
Seria bom criar um pequeno e simples benchmark de código aberto. Algum arquivo C que pode ser executado em computadores desktop, servidores, dispositivos móveis, consoles etc. Mas eu não sou o tipo de pessoa que escreve essa ferramenta.Negação de responsabilidade
Medir a largura de banda da memória é difícil. Muito difícil. Provavelmente há erros no meu código. Muitos fatores não contabilizados. Se você tem alguma crítica por minha técnica, provavelmente está certo.Em última análise, acho que isso é normal. Este artigo não é sobre o desempenho exato da minha área de trabalho. Esta é uma declaração de problema de um certo ponto de vista. E sobre como aprender a fazer alguns cálculos matemáticos.Conclusão
Um colega compartilhou comigo uma opinião interessante sobre a largura de banda da memória da GPU e o desempenho do aplicativo. Isso me levou a estudar o desempenho da memória em computadores modernos.Para cálculos aproximados, aqui estão alguns números para uma área de trabalho moderna:- Desempenho RAM
- Máximo:
45 / - Em média, aproximadamente:
5 / - Mínimo:
1 /
- Desempenho de cache L1 / L2 / L3 (por núcleo)
- Máximo (c simd):
210 // 80 //60 / - Em média, aproximadamente:
25 // 15 //9 / - Mínimo:
13 // 8 //3,5 /
As classificações de amostra estão relacionadas ao desempenho matrix4x4. Código real nunca será tão simples. Mas para cálculos em um guardanapo, este é um ponto de partida razoável. Você precisa ajustar esta figura com base nos padrões de acesso à memória do seu programa, nas características do seu equipamento e no código.No entanto, o mais importante é uma nova maneira de pensar sobre os problemas. Apresentar o problema em bytes por segundo ou bytes por quadro é outra lente a ser examinada. Esta é uma ferramenta útil por precaução.Obrigado pela leitura.Fonte
Gráfico de referência C ++ Pythondata.jsonMais pesquisa
Este artigo tocou apenas ligeiramente no tópico. Eu provavelmente não vou entrar nisso. Mas, se o fizesse, ele poderia cobrir alguns dos seguintes aspectos:Especificações do sistema
Os testes foram realizados no meu PC em casa. Somente configurações de estoque, sem overclock.- SO: Windows 10 v1903 compilação 18362
- CPU: Intel i7-8700k a 3,70 GHz
- Memória RAM: 2x16 GSkill Ripjaw DDR4-3200 (16-18-18-38 @ 1600 MHz)
- Placa-mãe: Asus TUF Z370-Plus Gaming