Tradução do Guia da Rede Neural Recursiva de Tensorflow.org. O material discute os recursos internos do Keras / Tensorflow 2.0 para malhas rápidas, bem como a possibilidade de personalizar camadas e células. Casos e limitações do uso do núcleo CuDNN também são considerados, o que permite acelerar o processo de aprendizado da rede neural.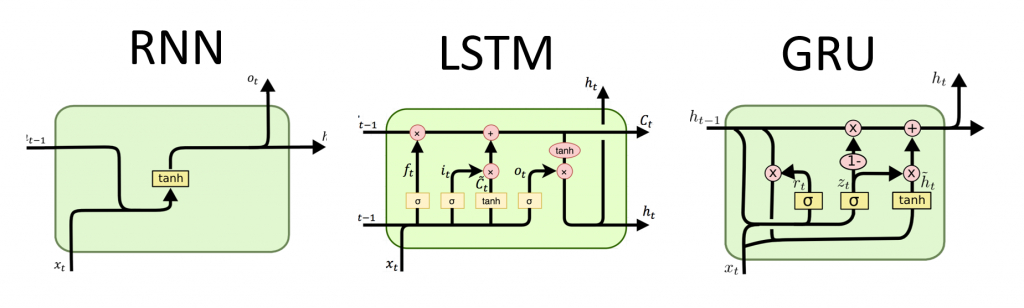 As redes neurais recursivas (RNNs) são uma classe de redes neurais que são boas para modelar dados seriais, como séries temporais ou linguagem natural.Se esquematicamente, a camada RNN usa um loop
As redes neurais recursivas (RNNs) são uma classe de redes neurais que são boas para modelar dados seriais, como séries temporais ou linguagem natural.Se esquematicamente, a camada RNN usa um loop forpara iterar em uma sequência ordenada pelo tempo, enquanto armazena em um estado interno, informações codificadas sobre as etapas que ele já viu.Keras RNN API é projetado com foco em:Facilidade de uso : built-in camadas tf.keras.layers.RNN, tf.keras.layers.LSTM, tf.keras.layers.GRUpermitem construir rapidamente um modelo recursivo sem ter que fazer configurações complexas.Fácil personalização : você também pode definir sua própria camada de células RNN (parte interna do loopfor) com comportamento personalizado e use-o com uma camada comum de `tf.keras.layers.RNN` (o próprio loop` for`). Isso permitirá que você protótipo rapidamente de várias idéias de pesquisa de maneira flexível, com um mínimo de código.Instalação
from __future__ import absolute_import, division, print_function, unicode_literals
import collections
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras import layers
Construindo um modelo simples
Keras possui três camadas RNN integradas:tf.keras.layers.SimpleRNN, uma RNN totalmente conectada na qual a saída da etapa anterior deve ser passada para a próxima etapa.tf.keras.layers.GRU, proposto pela primeira vez no artigo Estudo de frases usando o codec RNN para tradução automática estatísticatf.keras.layers.LSTM, proposto pela primeira vez no artigo Memória de curto prazo a longo prazo
No início de 2015, Keras apresentou as primeiras implementações reutilizáveis de código aberto Python e LSTM e GRU.A seguir, é apresentado um exemplo de Sequentialmodelo que processa seqüências de números inteiros, aninhando cada número inteiro em um vetor de 64 dimensões e processando sequências de vetores usando uma camada LSTM.model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.LSTM(128))
model.add(layers.Dense(10))
model.summary()
Saídas e status
Por padrão, a saída da camada RNN contém um vetor por elemento. Esse vetor é a saída da última célula RNN que contém informações sobre toda a sequência de entrada. A dimensão desta saída (batch_size, units), em que unitscorresponde ao argumento unitspassado ao construtor da camada.A camada RNN também pode retornar a sequência de saída inteira para cada elemento (um vetor para cada etapa), se você especificar return_sequences=True. A dimensão desta saída é (batch_size, timesteps, units).model = tf.keras.Sequential()
model.add(layers.Embedding(input_dim=1000, output_dim=64))
model.add(layers.GRU(256, return_sequences=True))
model.add(layers.SimpleRNN(128))
model.add(layers.Dense(10))
model.summary()
Além disso, a camada RNN pode retornar seus estados internos finais.Os estados retornados podem ser usados posteriormente para retomar a execução do RNN ou para inicializar outro RNN . Essa configuração geralmente é usada no modelo codificador-decodificador, sequência a sequência, em que o estado final do codificador é usado para o estado inicial do decodificador.Para que a camada RNN retorne seu estado interno, defina o parâmetro return_statecomo valor Trueao criar a camada. Observe que existem LSTM2 tensores de estado e GRUapenas um.Para ajustar o estado inicial de uma camada, basta chamar a camada com um argumento adicional initial_state.Observe que a dimensão deve corresponder à dimensão do elemento da camada, como no exemplo a seguir.encoder_vocab = 1000
decoder_vocab = 2000
encoder_input = layers.Input(shape=(None, ))
encoder_embedded = layers.Embedding(input_dim=encoder_vocab, output_dim=64)(encoder_input)
output, state_h, state_c = layers.LSTM(
64, return_state=True, name='encoder')(encoder_embedded)
encoder_state = [state_h, state_c]
decoder_input = layers.Input(shape=(None, ))
decoder_embedded = layers.Embedding(input_dim=decoder_vocab, output_dim=64)(decoder_input)
decoder_output = layers.LSTM(
64, name='decoder')(decoder_embedded, initial_state=encoder_state)
output = layers.Dense(10)(decoder_output)
model = tf.keras.Model([encoder_input, decoder_input], output)
model.summary()
Camadas RNN e células RNN
A API RNN, além das camadas RNN internas, também fornece APIs no nível da célula. Diferentemente das camadas RNN, que processam pacotes inteiros de seqüências de entrada, uma célula RNN processa apenas uma etapa.A célula está dentro do ciclo da forcamada RNN. A quebra de uma célula com uma camada tf.keras.layers.RNNfornece uma camada capaz de processar pacotes de sequência, por exemplo RNN(LSTMCell(10)).Matematicamente, RNN(LSTMCell(10))fornece o mesmo resultado que LSTM(10). De fato, a implementação dessa camada no TF v1.x foi apenas para criar a célula RNN correspondente e envolvê-la na camada RNN. No entanto, o uso de camadas incorporadas GRUe LSTMpermite o uso de CuDNN que pode oferecer melhor desempenho.Existem três células RNN internas, cada uma das quais corresponde à sua própria camada RNN.tf.keras.layers.SimpleRNNCellcorresponde à camada SimpleRNN.tf.keras.layers.GRUCellcorresponde à camada GRU.tf.keras.layers.LSTMCellcorresponde à camada LSTM.
A abstração de uma célula junto com uma classe comum tf.keras.layers.RNNfacilita muito a implementação de arquiteturas RNN personalizadas para sua pesquisa.Estado de salvamento em lotes cruzados
Ao processar sequências longas (possivelmente intermináveis), convém usar o padrão de estado de lote cruzado .Geralmente, o estado interno da camada RNN é redefinido a cada novo pacote de dados (ou seja, cada exemplo que vê a camada é considerado independente do passado). A camada manterá o estado apenas pela duração do processamento desse elemento.No entanto, se você tiver sequências muito longas, é útil dividi-las em sequências mais curtas e transferi-las para a camada RNN, por sua vez, sem redefinir o estado da camada. Assim, uma camada pode armazenar informações sobre toda a sequência, embora apenas veja uma subsequência por vez.Você pode fazer isso definindo `stateful = True` no construtor.Se você tiver a sequência `s = [t0, t1, ... t1546, t1547]`, poderá dividi-la, por exemplo, em:s1 = [t0, t1, ... t100]
s2 = [t101, ... t201]
...
s16 = [t1501, ... t1547]
Então você pode processá-lo com:lstm_layer = layers.LSTM(64, stateful=True)
for s in sub_sequences:
output = lstm_layer(s)
Quando você quiser limpar a condição, use layer.reset_states().Nota: Nesse caso, supõe-se que o exemplo ineste pacote seja uma continuação do exemplo do ipacote anterior. Isso significa que todos os pacotes contêm o mesmo número de elementos (tamanho do pacote). Por exemplo, se o pacote contiver [sequence_A_from_t0_to_t100, sequence_B_from_t0_to_t100], o próximo pacote deverá conter [sequence_A_from_t101_to_t200, sequence_B_from_t101_to_t200].
Aqui está um exemplo completo:paragraph1 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph2 = np.random.random((20, 10, 50)).astype(np.float32)
paragraph3 = np.random.random((20, 10, 50)).astype(np.float32)
lstm_layer = layers.LSTM(64, stateful=True)
output = lstm_layer(paragraph1)
output = lstm_layer(paragraph2)
output = lstm_layer(paragraph3)
lstm_layer.reset_states()
RNN bidirecional
Para sequências que não sejam séries temporais (por exemplo, textos), muitas vezes acontece que o modelo RNN funciona melhor se processar a sequência não apenas do início ao fim, mas vice-versa. Por exemplo, para prever a próxima palavra em uma frase, geralmente é útil conhecer o contexto em torno da palavra, e não apenas as palavras à sua frente.Keras fornece uma API simples para criar esses RNNs bidirecionais: um wrapper tf.keras.layers.Bidirectional.model = tf.keras.Sequential()
model.add(layers.Bidirectional(layers.LSTM(64, return_sequences=True),
input_shape=(5, 10)))
model.add(layers.Bidirectional(layers.LSTM(32)))
model.add(layers.Dense(10))
model.summary()
Sob o capô, a Bidirectionalcamada RNN transferida go_backwardsserá copiada e o campo da nova camada copiada será revertido e, assim, os dados de entrada serão processados na ordem inversa.A saída de ` BidirectionalRNN por padrão será a soma da saída da camada direta e a saída da camada reversa. Se você precisar de outro comportamento de mesclagem, por exemplo, concatenação, altere o parâmetro `merge_mode` no construtor do wrapper` Bidirecional`.Otimização de desempenho e núcleo CuDNN no TensorFlow 2.0
No TensorFlow 2.0, as camadas LSTM e GRU incorporadas são utilizáveis por núcleos CuDNN padrão, se um processador gráfico estiver disponível. Com essa alteração, as camadas anteriores keras.layers.CuDNNLSTM/CuDNNGRUestão desatualizadas e você pode construir seu modelo sem se preocupar com o equipamento no qual ele trabalhará.Como o kernel CuDNN é construído com algumas suposições, isso significa que a camada não poderá usar a camada CuDNN se você alterar as configurações padrão das camadas LSTM ou GRU internas . Por exemplo.- Alterando uma função
activationde tanhpara outra coisa. - Alterando uma função
recurrent_activationde sigmoidpara outra coisa. - Uso
recurrent_dropout> 0. - Configurando-o
unrollcomo True, o que faz com que o LSTM / GRU decomponha o interno tf.while_loopem um loop implementado for. - Defina
use_biascomo Falso. - Usando máscaras quando os dados de entrada não estão corretamente justificados (se a máscara corresponder aos dados estritamente alinhados, o CuDNN ainda poderá ser usado. Esse é o caso mais comum).
Quando possível, use kernels CuDNN
batch_size = 64
input_dim = 28
units = 64
output_size = 10
def build_model(allow_cudnn_kernel=True):
if allow_cudnn_kernel:
lstm_layer = tf.keras.layers.LSTM(units, input_shape=(None, input_dim))
else:
lstm_layer = tf.keras.layers.RNN(
tf.keras.layers.LSTMCell(units),
input_shape=(None, input_dim))
model = tf.keras.models.Sequential([
lstm_layer,
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Dense(output_size)]
)
return model
Carregando o conjunto de dados MNIST
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
sample, sample_label = x_train[0], y_train[0]
Crie uma instância do modelo e compile-a
Nós escolhemos sparse_categorical_crossentropyem função das perdas. A saída do modelo tem uma dimensão [batch_size, 10]. A resposta do modelo é um vetor inteiro, cada um dos números está no intervalo de 0 a 9.model = build_model(allow_cudnn_kernel=True)
model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=5)
Crie um novo modelo sem o núcleo CuDNN
slow_model = build_model(allow_cudnn_kernel=False)
slow_model.set_weights(model.get_weights())
slow_model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer='sgd',
metrics=['accuracy'])
slow_model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=batch_size,
epochs=1)
Como você pode ver, o modelo criado com o CuDNN é muito mais rápido para o treinamento do que o modelo usando o núcleo habitual do TensorFlow.O mesmo modelo com suporte CuDNN pode ser usado para saída em um ambiente de processador único. A anotação tf.deviceindica simplesmente o dispositivo usado. O modelo será executado por padrão na CPU se a GPU não estiver disponível.Você simplesmente não precisa se preocupar com o hardware em que está trabalhando. Isso não é legal?with tf.device('CPU:0'):
cpu_model = build_model(allow_cudnn_kernel=True)
cpu_model.set_weights(model.get_weights())
result = tf.argmax(cpu_model.predict_on_batch(tf.expand_dims(sample, 0)), axis=1)
print('Predicted result is: %s, target result is: %s' % (result.numpy(), sample_label))
plt.imshow(sample, cmap=plt.get_cmap('gray'))
RNN com entrada de lista / dicionário ou entrada aninhada
Estruturas aninhadas permitem incluir mais informações em uma única etapa. Por exemplo, um quadro de vídeo pode conter entrada de áudio e vídeo simultaneamente. A dimensão dos dados neste caso pode ser:[batch, timestep, {\"video\": [height, width, channel], \"audio\": [frequency]}]
Em outro exemplo, os dados manuscritos podem ter coordenadas xey para a posição atual da caneta, além de informações de pressão. Portanto, os dados podem ser representados da seguinte maneira:[batch, timestep, {\"location\": [x, y], \"pressure\": [force]}]
O código a seguir cria um exemplo de uma célula RNN personalizada que funciona com essa entrada estruturada.Definir uma célula do usuário que suporte entrada / saída aninhada
NestedInput = collections.namedtuple('NestedInput', ['feature1', 'feature2'])
NestedState = collections.namedtuple('NestedState', ['state1', 'state2'])
class NestedCell(tf.keras.layers.Layer):
def __init__(self, unit_1, unit_2, unit_3, **kwargs):
self.unit_1 = unit_1
self.unit_2 = unit_2
self.unit_3 = unit_3
self.state_size = NestedState(state1=unit_1,
state2=tf.TensorShape([unit_2, unit_3]))
self.output_size = (unit_1, tf.TensorShape([unit_2, unit_3]))
super(NestedCell, self).__init__(**kwargs)
def build(self, input_shapes):
input_1 = input_shapes.feature1[1]
input_2, input_3 = input_shapes.feature2[1:]
self.kernel_1 = self.add_weight(
shape=(input_1, self.unit_1), initializer='uniform', name='kernel_1')
self.kernel_2_3 = self.add_weight(
shape=(input_2, input_3, self.unit_2, self.unit_3),
initializer='uniform',
name='kernel_2_3')
def call(self, inputs, states):
input_1, input_2 = tf.nest.flatten(inputs)
s1, s2 = states
output_1 = tf.matmul(input_1, self.kernel_1)
output_2_3 = tf.einsum('bij,ijkl->bkl', input_2, self.kernel_2_3)
state_1 = s1 + output_1
state_2_3 = s2 + output_2_3
output = [output_1, output_2_3]
new_states = NestedState(state1=state_1, state2=state_2_3)
return output, new_states
Construir um modelo RNN com entrada / saída aninhada
Vamos construir um modelo Keras que usa uma camada tf.keras.layers.RNNe uma célula personalizada que acabamos de definir.unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])unit_1 = 10
unit_2 = 20
unit_3 = 30
input_1 = 32
input_2 = 64
input_3 = 32
batch_size = 64
num_batch = 100
timestep = 50
cell = NestedCell(unit_1, unit_2, unit_3)
rnn = tf.keras.layers.RNN(cell)
inp_1 = tf.keras.Input((None, input_1))
inp_2 = tf.keras.Input((None, input_2, input_3))
outputs = rnn(NestedInput(feature1=inp_1, feature2=inp_2))
model = tf.keras.models.Model([inp_1, inp_2], outputs)
model.compile(optimizer='adam', loss='mse', metrics=['accuracy'])
Treine o modelo em dados gerados aleatoriamente
Como não temos um bom conjunto de dados para esse modelo, usamos dados aleatórios gerados pela biblioteca Numpy para demonstração.input_1_data = np.random.random((batch_size * num_batch, timestep, input_1))
input_2_data = np.random.random((batch_size * num_batch, timestep, input_2, input_3))
target_1_data = np.random.random((batch_size * num_batch, unit_1))
target_2_data = np.random.random((batch_size * num_batch, unit_2, unit_3))
input_data = [input_1_data, input_2_data]
target_data = [target_1_data, target_2_data]
model.fit(input_data, target_data, batch_size=batch_size)
Com uma camada, tf.keras.layers.RNNvocê só precisa determinar a lógica matemática de uma única etapa na sequência, e a camada tf.keras.layers.RNNmanipulará a iteração da sequência para você. Essa é uma maneira incrivelmente poderosa de prototipar rapidamente novos tipos de RNNs (por exemplo, a variante LSTM).Após a verificação, a tradução também aparecerá no Tensorflow.org. Se você deseja participar da tradução da documentação do site Tensorflow.org para o russo, entre em contato com um comentário ou pessoal. Quaisquer correções e comentários são apreciados.