HighLoad ++, Mikhail Tyulenev (MongoDB): Consistência causal: da teoria à prática
A próxima conferência HighLoad ++ será realizada nos dias 6 e 7 de abril de 2020 em São Petersburgo.Detalhes e ingressos aqui . HighLoad ++ Sibéria 2019. Salão "Krasnoyarsk". 25 de junho, 12:00. Resumos e apresentação . Ocorre que os requisitos práticos entram em conflito com uma teoria em que aspectos importantes para um produto comercial não são levados em consideração. Este relatório apresenta o processo de seleção e combinação de várias abordagens para criar componentes de consistência causal com base em pesquisa acadêmica com base nos requisitos de um produto comercial. Os alunos aprenderão sobre as abordagens teóricas existentes para relógios lógicos, rastreamento de dependências, segurança do sistema, sincronização de clock e por que o MongoDB parou nessas ou nessas soluções.Mikhail Tyulenev (doravante - MT): - Vou falar sobre consistência causal - esse é um recurso que trabalhamos no MongoDB. Eu trabalho em um grupo de sistemas distribuídos, fizemos isso cerca de dois anos atrás.
Ocorre que os requisitos práticos entram em conflito com uma teoria em que aspectos importantes para um produto comercial não são levados em consideração. Este relatório apresenta o processo de seleção e combinação de várias abordagens para criar componentes de consistência causal com base em pesquisa acadêmica com base nos requisitos de um produto comercial. Os alunos aprenderão sobre as abordagens teóricas existentes para relógios lógicos, rastreamento de dependências, segurança do sistema, sincronização de clock e por que o MongoDB parou nessas ou nessas soluções.Mikhail Tyulenev (doravante - MT): - Vou falar sobre consistência causal - esse é um recurso que trabalhamos no MongoDB. Eu trabalho em um grupo de sistemas distribuídos, fizemos isso cerca de dois anos atrás. No processo, tive que me familiarizar com muita pesquisa acadêmica, porque esse recurso é bem estudado. Verificou-se que nem um único artigo se encaixa no que é necessário na produção, o banco de dados em vista dos requisitos muito específicos que são, provavelmente, em qualquer aplicativo de produção.Vou falar sobre como nós, como consumidores de Pesquisa acadêmica, preparamos algo que podemos apresentar aos nossos usuários como um prato pronto que é conveniente e seguro de usar.
No processo, tive que me familiarizar com muita pesquisa acadêmica, porque esse recurso é bem estudado. Verificou-se que nem um único artigo se encaixa no que é necessário na produção, o banco de dados em vista dos requisitos muito específicos que são, provavelmente, em qualquer aplicativo de produção.Vou falar sobre como nós, como consumidores de Pesquisa acadêmica, preparamos algo que podemos apresentar aos nossos usuários como um prato pronto que é conveniente e seguro de usar.Consistência causal. Vamos definir conceitos
Para começar, quero descrever em termos gerais o que é consistência causal. Existem dois personagens - Leonard e Penny (a série "The Big Bang Theory"):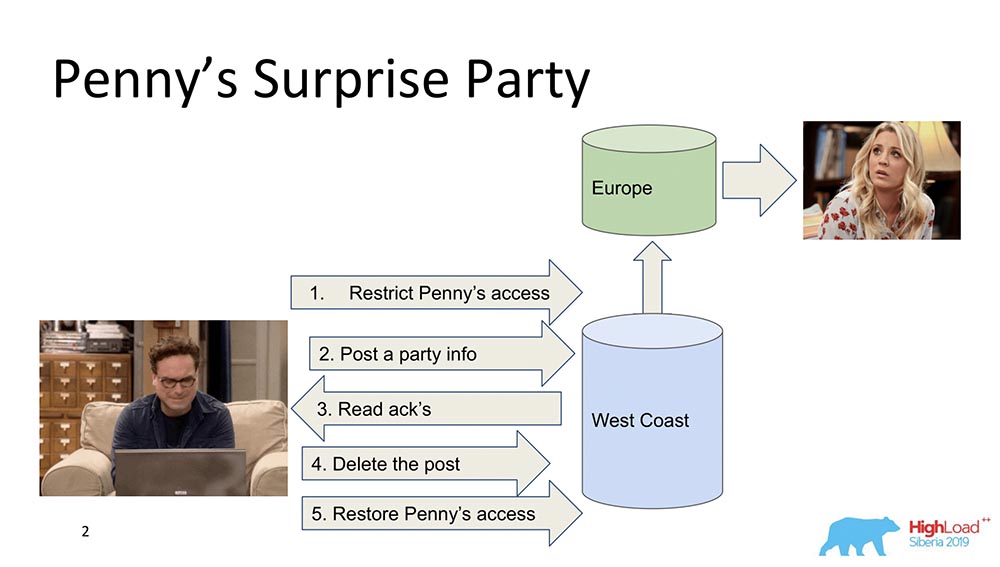 Suponha que Penny esteja na Europa e Leonard queira fazer algum tipo de surpresa para ela, uma festa. E ele não tem nada melhor do que jogá-la para fora da lista de amigos, enviando atualizações para alimentar todos os amigos: "Vamos fazer Penny feliz!" (ela na Europa, enquanto dorme, não vê tudo isso e não pode ver, porque ela não está lá). No final, ele exclui este post, apaga-o do "Feed" e restaura o acesso para que ele não perceba nada e não haja escândalo.Tudo bem, mas vamos supor que o sistema esteja distribuído e que os eventos deram um certo erro. Talvez, por exemplo, aconteça que a restrição de acesso a Penny ocorreu após a publicação desta postagem, se os eventos não estiverem conectados por um relacionamento causal. Na verdade, este é um exemplo de quando a consistência causal é necessária para cumprir uma função comercial (neste caso).De fato, essas são propriedades não triviais do banco de dados - poucas pessoas as apóiam. Vamos para os modelos.
Suponha que Penny esteja na Europa e Leonard queira fazer algum tipo de surpresa para ela, uma festa. E ele não tem nada melhor do que jogá-la para fora da lista de amigos, enviando atualizações para alimentar todos os amigos: "Vamos fazer Penny feliz!" (ela na Europa, enquanto dorme, não vê tudo isso e não pode ver, porque ela não está lá). No final, ele exclui este post, apaga-o do "Feed" e restaura o acesso para que ele não perceba nada e não haja escândalo.Tudo bem, mas vamos supor que o sistema esteja distribuído e que os eventos deram um certo erro. Talvez, por exemplo, aconteça que a restrição de acesso a Penny ocorreu após a publicação desta postagem, se os eventos não estiverem conectados por um relacionamento causal. Na verdade, este é um exemplo de quando a consistência causal é necessária para cumprir uma função comercial (neste caso).De fato, essas são propriedades não triviais do banco de dados - poucas pessoas as apóiam. Vamos para os modelos.Modelos de consistência
O que é um modelo de consistência em bancos de dados em geral? Essas são algumas das garantias que um sistema distribuído oferece em relação a quais dados e em que sequência o cliente pode receber.Em princípio, todos os modelos de consistência se resumem a como o sistema é distribuído como um sistema que funciona, por exemplo, no mesmo aceno de um laptop. E é assim que o sistema, que funciona em milhares de nós geodistribuídos, é semelhante a um laptop, no qual todas essas propriedades são executadas automaticamente em princípio.Portanto, os modelos de consistência se aplicam apenas a sistemas distribuídos. Todos os sistemas que existiam anteriormente e trabalhavam na mesma escala vertical não tiveram esses problemas. Havia um cache de buffer, e tudo era sempre lido nele.Modelo forte
Na verdade, o primeiro modelo é Forte (ou a capacidade de aumentar a linha, como costuma ser chamada). Este é um modelo de consistência que garante que todas as alterações, assim que a confirmação de que ocorreu, sejam visíveis a todos os usuários do sistema.Isso cria uma ordem global de todos os eventos no banco de dados. Esta é uma propriedade de consistência muito forte e geralmente é muito cara. No entanto, é muito bem conservado. É simplesmente muito caro e lento - eles são raramente usados. Isso é chamado de capacidade de aumento.Há outra propriedade mais poderosa suportada na "Chave inglesa" - chamada Consistência externa. Falaremos sobre ele um pouco mais tarde.Causal
O seguinte é causal, exatamente do que eu estava falando. Existem vários subníveis entre Strong e Causal dos quais não falarei, mas todos eles se resumem a Causal. Este é um modelo importante porque é o mais forte de todos os modelos, a consistência mais forte na presença de uma rede ou partições.Causais é realmente uma situação na qual os eventos são conectados por um relacionamento causal. Muitas vezes, eles são percebidos como direitos de leitura, do ponto de vista do cliente. Se o cliente observou alguns valores, ele não pode ver os valores que estavam no passado. Ele já está começando a ver leituras de prefixo. Tudo se resume à mesma coisa.Causais como modelo de consistência é uma ordem parcial de eventos no servidor, na qual os eventos de todos os clientes são observados na mesma sequência. Nesse caso, Leonard e Penny.Eventual
O terceiro modelo é a consistência eventual. É isso que suporta absolutamente todos os sistemas distribuídos, um modelo mínimo que geralmente faz sentido. Significa o seguinte: quando temos algumas alterações nos dados, elas se tornam consistentes em algum momento.Nesse momento, ela não diz nada, caso contrário ela se tornaria Consistência Externa - haveria uma história completamente diferente. No entanto, este é um modelo muito popular, o mais comum. Por padrão, todos os usuários de sistemas distribuídos usam Consistência Eventual.Quero dar alguns exemplos comparativos: o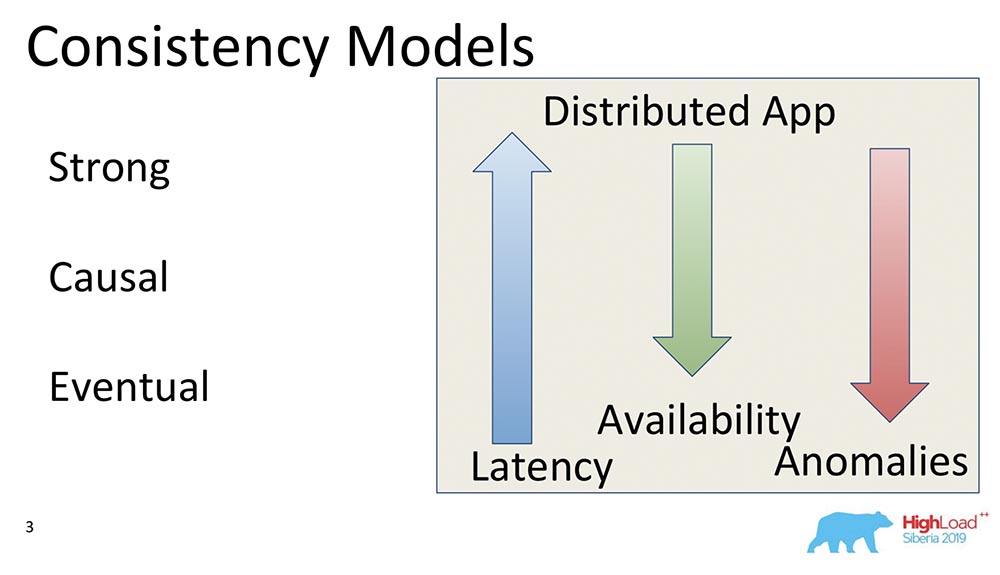 que essas setas significam?
que essas setas significam?- Latency. : , , , . Eventual Consistency , , , memory .
- Availability. , partitions, - – , , - . Eventual Consistency – , .
- Anomalies. , , . Strong Consistency , Eventual Consistency . : Eventual Consistency, ? , Eventual Consistency- , , , ; - ; . , .
CAP
Quando você vê as palavras consistência, disponibilidade - o que vem à sua mente? Direito - teorema da CAP! Agora quero dissipar o mito ... Não sou eu - há Martin Kleppman, que escreveu um artigo maravilhoso, um livro maravilhoso. O teorema da PAC é um princípio formulado nos anos 2000 que Consistência, Disponibilidade, Partições: pegue dois, e você não pode escolher três. Era um certo princípio. Foi provado como um teorema alguns anos depois, por Gilbert e Lynch. Em seguida, tornou-se usado como um mantra - os sistemas começaram a ser divididos em CA, CP, AP e assim por diante.Esse teorema foi realmente provado pelos seguintes motivos ... Primeiro, a disponibilidade não foi considerada como um valor contínuo de zero a centenas (0 - o sistema está "morto", 100 - responde rapidamente; estamos acostumados a considerá-lo), mas como uma propriedade do algoritmo , que garante que, com todas as suas execuções, retorne dados.Não há uma palavra sobre o tempo de resposta! Existe um algoritmo que retorna dados após 100 anos - um algoritmo perfeitamente disponível, que faz parte do teorema da CAP.Segundo: foi provado um teorema para mudanças nos valores da mesma chave, apesar de essas mudanças serem uma linha redimensionável. Isso significa que, na verdade, eles praticamente não são usados, porque os modelos são diferentes de Consistência Eventual, Consistência Forte (talvez).Por que isso é tudo? Além disso, o teorema da PAC, na forma em que é provado, praticamente não é aplicável, é raramente usado. Em uma forma teórica, de alguma forma limita tudo. Acontece que um certo princípio é intuitivamente verdadeiro, mas de modo algum é provado em geral.
O teorema da PAC é um princípio formulado nos anos 2000 que Consistência, Disponibilidade, Partições: pegue dois, e você não pode escolher três. Era um certo princípio. Foi provado como um teorema alguns anos depois, por Gilbert e Lynch. Em seguida, tornou-se usado como um mantra - os sistemas começaram a ser divididos em CA, CP, AP e assim por diante.Esse teorema foi realmente provado pelos seguintes motivos ... Primeiro, a disponibilidade não foi considerada como um valor contínuo de zero a centenas (0 - o sistema está "morto", 100 - responde rapidamente; estamos acostumados a considerá-lo), mas como uma propriedade do algoritmo , que garante que, com todas as suas execuções, retorne dados.Não há uma palavra sobre o tempo de resposta! Existe um algoritmo que retorna dados após 100 anos - um algoritmo perfeitamente disponível, que faz parte do teorema da CAP.Segundo: foi provado um teorema para mudanças nos valores da mesma chave, apesar de essas mudanças serem uma linha redimensionável. Isso significa que, na verdade, eles praticamente não são usados, porque os modelos são diferentes de Consistência Eventual, Consistência Forte (talvez).Por que isso é tudo? Além disso, o teorema da PAC, na forma em que é provado, praticamente não é aplicável, é raramente usado. Em uma forma teórica, de alguma forma limita tudo. Acontece que um certo princípio é intuitivamente verdadeiro, mas de modo algum é provado em geral.Consistência causal - o modelo mais forte
O que está acontecendo agora - você pode obter todas as três coisas: Consistência e disponibilidade podem ser obtidas usando Partições. Em particular, a consistência causal é o modelo de consistência mais forte que, na presença de Partições (quebras de rede), ainda funciona. Portanto, é de tão grande interesse e, portanto, estamos envolvidos nela. Primeiro, simplifica o trabalho dos desenvolvedores de aplicativos. Em particular, há muito suporte do servidor: quando todos os registros que ocorrem dentro de um cliente são garantidos para chegar nessa ordem no outro cliente. Em segundo lugar, suporta partições.
Primeiro, simplifica o trabalho dos desenvolvedores de aplicativos. Em particular, há muito suporte do servidor: quando todos os registros que ocorrem dentro de um cliente são garantidos para chegar nessa ordem no outro cliente. Em segundo lugar, suporta partições.Cozinha interior MongoDB
Lembrando do almoço, vamos para a cozinha. Vou falar sobre o modelo do sistema, ou seja, o que é o MongoDB para quem primeiro ouviu sobre esse banco de dados.
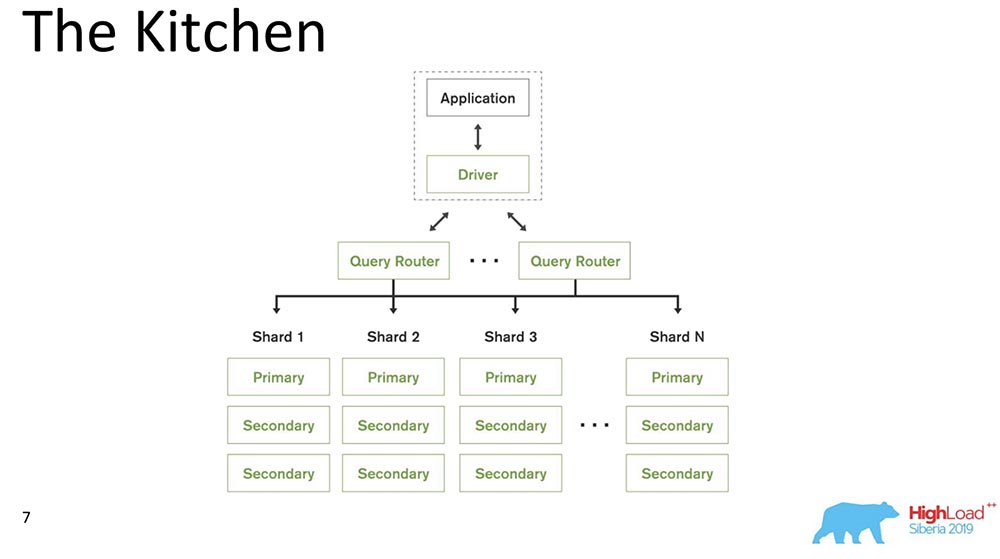 O MongoDB (doravante denominado "MongoBD") é um sistema distribuído que suporta escala horizontal, ou seja, sharding; e dentro de cada fragmento, ele também suporta redundância de dados, ou seja, replicação.O sharding no “MongoBD” (banco de dados não relacional) executa o balanceamento automático, ou seja, cada coleção de documentos (ou “tabela” em termos de dados relacionais) em pedaços, e o servidor já os move automaticamente entre os shards.O Query Router que distribui consultas para o cliente é um cliente através do qual ele trabalha. Ele já sabe onde e quais dados estão localizados, envia todas as solicitações para o shard correto.Outro ponto importante: o MongoDB é um único mestre. Há uma Primária - ela pode receber registros que suportam as chaves que ela contém. Você não pode fazer gravação multimestre.Fizemos o lançamento 4.2 - novas coisas interessantes apareceram lá. Em particular, eles inseriram o Lucene - a pesquisa - era executável java diretamente no "Mongo", e foi possível pesquisar no Lucene, o mesmo que no "Elastic".E eles criaram um novo produto - Gráficos, também está disponível no Atlas (a própria nuvem do Mongo). Eles têm nível gratuito - você pode brincar com isso. Gostei muito dos gráficos - a visualização de dados é muito intuitiva.
O MongoDB (doravante denominado "MongoBD") é um sistema distribuído que suporta escala horizontal, ou seja, sharding; e dentro de cada fragmento, ele também suporta redundância de dados, ou seja, replicação.O sharding no “MongoBD” (banco de dados não relacional) executa o balanceamento automático, ou seja, cada coleção de documentos (ou “tabela” em termos de dados relacionais) em pedaços, e o servidor já os move automaticamente entre os shards.O Query Router que distribui consultas para o cliente é um cliente através do qual ele trabalha. Ele já sabe onde e quais dados estão localizados, envia todas as solicitações para o shard correto.Outro ponto importante: o MongoDB é um único mestre. Há uma Primária - ela pode receber registros que suportam as chaves que ela contém. Você não pode fazer gravação multimestre.Fizemos o lançamento 4.2 - novas coisas interessantes apareceram lá. Em particular, eles inseriram o Lucene - a pesquisa - era executável java diretamente no "Mongo", e foi possível pesquisar no Lucene, o mesmo que no "Elastic".E eles criaram um novo produto - Gráficos, também está disponível no Atlas (a própria nuvem do Mongo). Eles têm nível gratuito - você pode brincar com isso. Gostei muito dos gráficos - a visualização de dados é muito intuitiva.Ingredientes causais de consistência
Contei cerca de 230 artigos que foram publicados sobre esse assunto - de Leslie Lampert. Agora, da minha memória, trarei para você algumas partes desses materiais. Tudo começou com um artigo de Leslie Lampert, que foi escrito na década de 1970. Como você pode ver, algumas pesquisas sobre esse tópico ainda estão em andamento. Agora, a consistência causal está experimentando interesse em conexão com o desenvolvimento de sistemas distribuídos.
Tudo começou com um artigo de Leslie Lampert, que foi escrito na década de 1970. Como você pode ver, algumas pesquisas sobre esse tópico ainda estão em andamento. Agora, a consistência causal está experimentando interesse em conexão com o desenvolvimento de sistemas distribuídos.Limitações
Quais são as limitações? Este é realmente um dos pontos principais, porque as restrições impostas pelos sistemas de produção são muito diferentes das restrições existentes nos artigos acadêmicos. Muitas vezes, são bastante artificiais.
- Em primeiro lugar, o "MongoDB" é um único mestre, como eu já disse (isso simplifica bastante).
- , 10 . - , .
- , , , binary, , .
- , Research : . «» – . , , – . , .
- , – : , performance degradation .
- Outro ponto é geralmente anti-acadêmico: compatibilidade de versões anteriores e futuras. Drivers antigos devem suportar novas atualizações e o banco de dados deve suportar drivers antigos.
Em geral, tudo isso impõe limitações.Componentes de consistência causal
Agora vou falar sobre alguns dos componentes. Se considerarmos a consistência Causal geral, podemos distinguir blocos. Optamos pelas obras que pertencem a um determinado bloco: Rastreamento de Dependências, escolha de horas, como esses relógios podem ser sincronizados entre si e como garantimos a segurança - este é um plano aproximado do que falarei:
Rastreamento de Dependência Total
Por que é necessário? Para que, quando os dados forem replicados - cada registro, cada alteração de dados contenha informações sobre quais alterações elas dependem. A primeira e ingênua alteração ocorre quando cada mensagem que contém um registro contém informações sobre mensagens anteriores: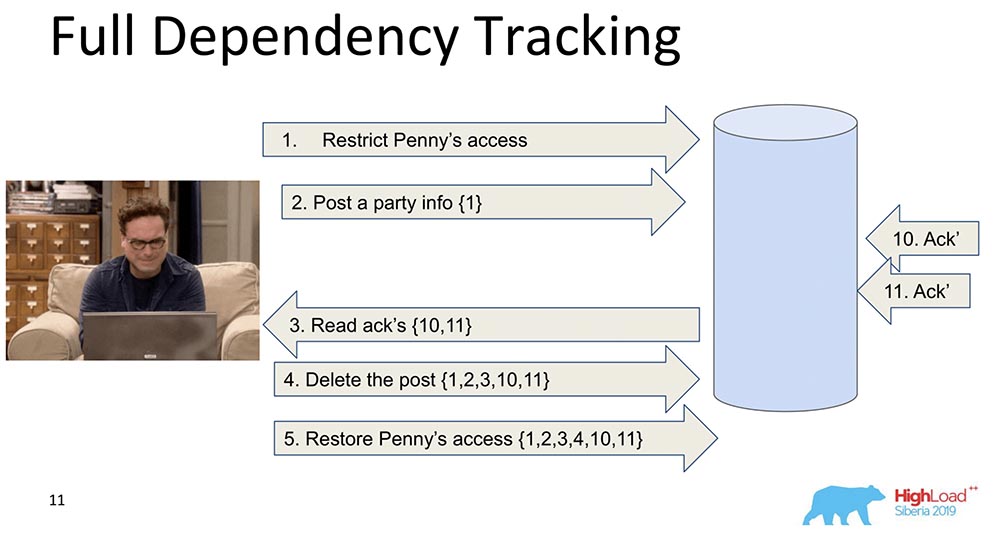 Neste exemplo, o número entre chaves é o número de registros. Às vezes, esses registros com valores são transferidos na íntegra, às vezes, algumas versões são transferidas. A conclusão é que cada mudança contém informações sobre a anterior (obviamente, ela carrega tudo por si mesma).Por que decidimos não usar essa abordagem (rastreamento completo)? Obviamente, porque essa abordagem é impraticável: qualquer alteração na rede social depende de todas as alterações anteriores nessa rede social, transmitindo, digamos, o Facebook ou o Vkontakte em cada atualização. No entanto, existem muitas pesquisas, a saber, o Full Dependency Tracking - essas são redes sociais, para algumas situações realmente funcionam.
Neste exemplo, o número entre chaves é o número de registros. Às vezes, esses registros com valores são transferidos na íntegra, às vezes, algumas versões são transferidas. A conclusão é que cada mudança contém informações sobre a anterior (obviamente, ela carrega tudo por si mesma).Por que decidimos não usar essa abordagem (rastreamento completo)? Obviamente, porque essa abordagem é impraticável: qualquer alteração na rede social depende de todas as alterações anteriores nessa rede social, transmitindo, digamos, o Facebook ou o Vkontakte em cada atualização. No entanto, existem muitas pesquisas, a saber, o Full Dependency Tracking - essas são redes sociais, para algumas situações realmente funcionam.Rastreamento de dependência explícito
O próximo é mais limitado. Também aqui é considerada a transmissão de informações, mas apenas as que claramente dependem. O que depende do que, como regra, já é determinado pelo Aplicativo. Quando os dados são replicados, apenas as respostas são retornadas quando uma solicitação é feita, quando as dependências anteriores foram atendidas, ou seja, mostradas. Essa é a essência de como a consistência causal funciona.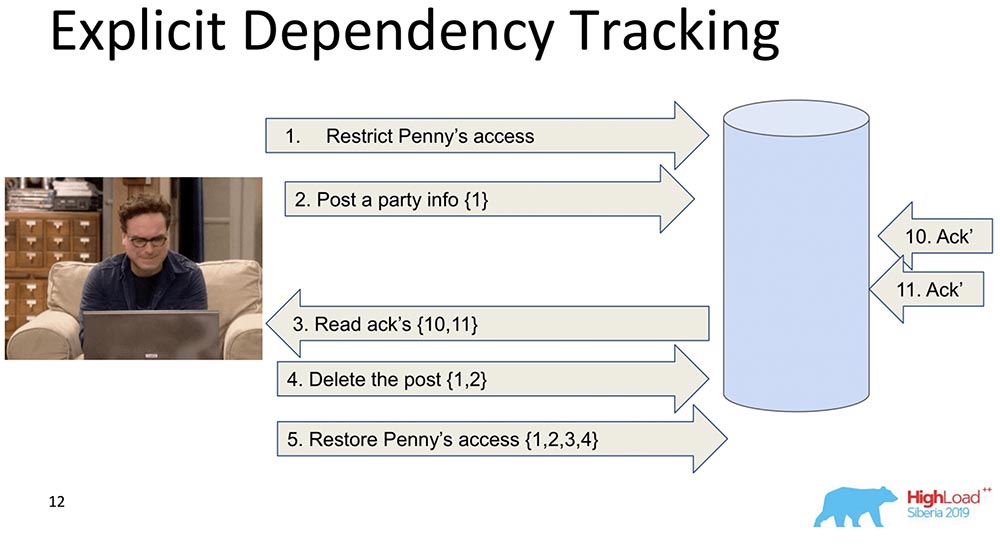 Ela vê que o registro 5 depende dos registros 1, 2, 3, 4 - respectivamente, espera antes que o cliente obtenha acesso às alterações feitas pelo decreto de acesso de Penny quando todas as alterações anteriores já tiverem passado para o banco de dados.Isso também não nos convém, porque de qualquer maneira há muita informação, e isso desacelerará. Existe uma abordagem diferente ...
Ela vê que o registro 5 depende dos registros 1, 2, 3, 4 - respectivamente, espera antes que o cliente obtenha acesso às alterações feitas pelo decreto de acesso de Penny quando todas as alterações anteriores já tiverem passado para o banco de dados.Isso também não nos convém, porque de qualquer maneira há muita informação, e isso desacelerará. Existe uma abordagem diferente ...Lamport Clock
Eles são muito antigos. O Lamport Clock implica que essas dependências sejam recolhidas em uma função escalar chamada Lamport Clock.Uma função escalar é algum número abstrato. Muitas vezes chamado de tempo lógico. Em cada evento, esse contador aumenta. O contador, atualmente conhecido pelo processo, envia cada mensagem. É claro que os processos podem estar fora de sincronia, eles podem ter tempos completamente diferentes. No entanto, o sistema de alguma forma equilibra o relógio com essas mensagens. O que acontece nesse caso?Dividi esse grande fragmento em dois para que fique claro: os amigos podem viver em um nó que contém uma parte da coleção e o Feed pode viver em outro nó que contém uma parte dessa coleção. Está claro como eles podem sair da curva? Primeiro, o Feed diz "Replicado" e depois Amigos. Se o sistema não fornecer garantias de que o Feed não será mostrado até que as dependências de Friends na coleção Friends também sejam entregues, teremos apenas uma situação que mencionei.Você vê como o tempo do contador logicamente aumenta no Feed: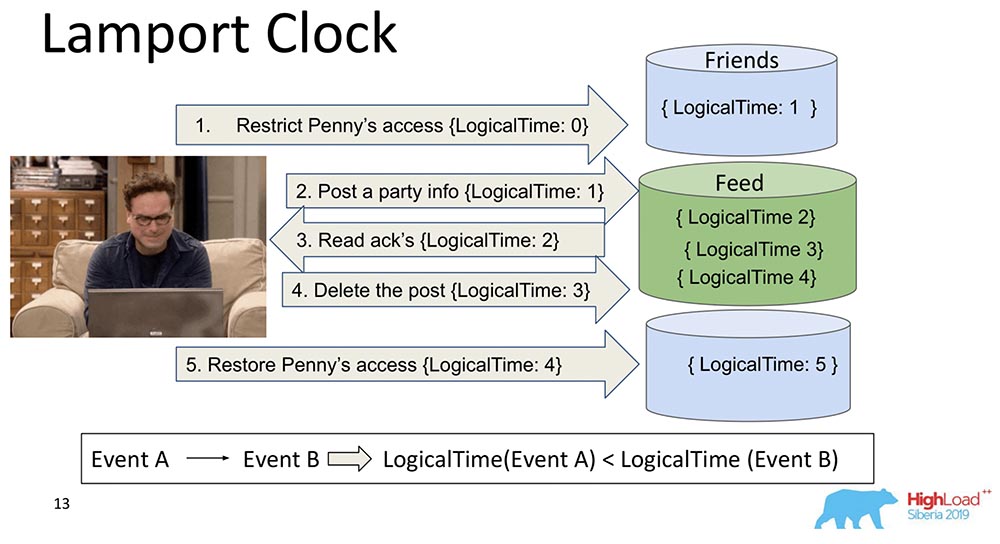 Assim, a propriedade principal dessa consistência causal e de relógio de Lamport (explicada através do relógio de Lamport) é a seguinte: se tivermos os eventos A e B e o evento B depender do evento A *, então o LogicalTime do evento A será menor do que o LogicalTime do Evento B.* Às vezes eles até dizem que A aconteceu antes de B, ou seja, A aconteceu antes de B - esse é um tipo de relacionamento que ordena parcialmente todo o conjunto de eventos que geralmente acontecem.O contrário está errado. Esta é realmente uma das principais desvantagens do Lamport Clock - pedido parcial. Existe um conceito de eventos simultâneos, ou seja, eventos nos quais nem (A aconteceu antes de B) nem (A aconteceu antes de B). Um exemplo é a adição paralela de Leonard a amigos de outra pessoa (nem mesmo Leonard, mas Sheldon, por exemplo).Essa é a propriedade frequentemente usada ao trabalhar com relógios Lamport: eles examinam a função exatamente e tiram uma conclusão disso - talvez esses eventos sejam dependentes. Porque em uma direção isso é verdade: se LogicalTime A for menor que LogicalTime B, B não poderá ocorrer antes de A; e se mais, então talvez.
Assim, a propriedade principal dessa consistência causal e de relógio de Lamport (explicada através do relógio de Lamport) é a seguinte: se tivermos os eventos A e B e o evento B depender do evento A *, então o LogicalTime do evento A será menor do que o LogicalTime do Evento B.* Às vezes eles até dizem que A aconteceu antes de B, ou seja, A aconteceu antes de B - esse é um tipo de relacionamento que ordena parcialmente todo o conjunto de eventos que geralmente acontecem.O contrário está errado. Esta é realmente uma das principais desvantagens do Lamport Clock - pedido parcial. Existe um conceito de eventos simultâneos, ou seja, eventos nos quais nem (A aconteceu antes de B) nem (A aconteceu antes de B). Um exemplo é a adição paralela de Leonard a amigos de outra pessoa (nem mesmo Leonard, mas Sheldon, por exemplo).Essa é a propriedade frequentemente usada ao trabalhar com relógios Lamport: eles examinam a função exatamente e tiram uma conclusão disso - talvez esses eventos sejam dependentes. Porque em uma direção isso é verdade: se LogicalTime A for menor que LogicalTime B, B não poderá ocorrer antes de A; e se mais, então talvez.Relógio de vetor
O desenvolvimento lógico dos relógios Lamport é o Vector Clock. Eles diferem em que cada nó aqui contém seu próprio relógio separado e são transmitidos como um vetor.Nesse caso, você vê que o índice zero do vetor é responsável pelo Feed e o primeiro índice do vetor é para Friends (cada um desses nós). E agora eles aumentarão: o índice zero do "Feed" aumenta ao gravar - 1, 2, 3: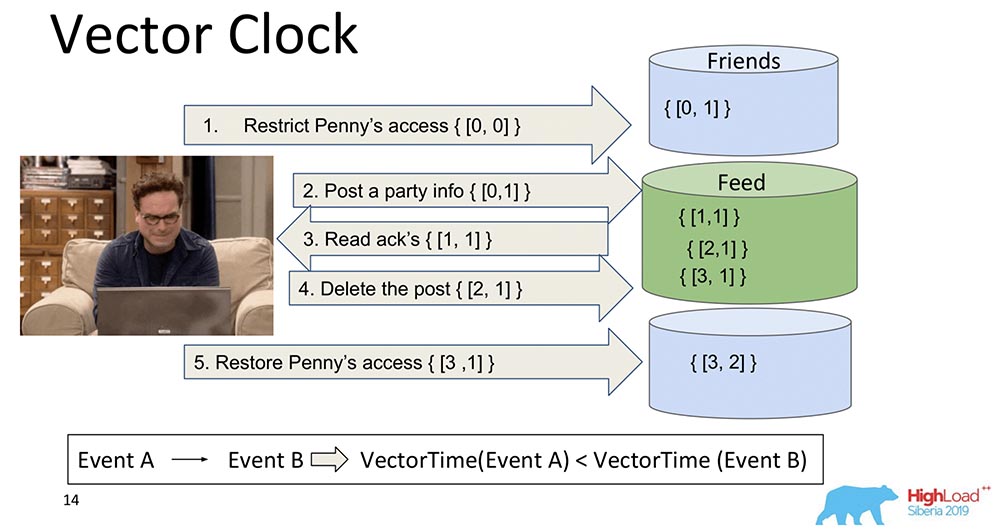 Como é o relógio vetorial melhor? O fato de que eles podem descobrir quais eventos são simultâneos e quando ocorrem em diferentes nós. Isso é muito importante para um sistema de sharding como o MongoBD. No entanto, não escolhemos isso, embora seja uma coisa maravilhosa, e funcione muito bem, e provavelmente nos sirva ...Se temos 10 mil fragmentos, não podemos transferir 10 mil componentes, mesmo se compactar, pensamos em outra coisa - mesmo assim, a carga útil será várias vezes menor que o volume de todo esse vetor. Portanto, moendo nossos corações e dentes, abandonamos essa abordagem e passamos para outra.
Como é o relógio vetorial melhor? O fato de que eles podem descobrir quais eventos são simultâneos e quando ocorrem em diferentes nós. Isso é muito importante para um sistema de sharding como o MongoBD. No entanto, não escolhemos isso, embora seja uma coisa maravilhosa, e funcione muito bem, e provavelmente nos sirva ...Se temos 10 mil fragmentos, não podemos transferir 10 mil componentes, mesmo se compactar, pensamos em outra coisa - mesmo assim, a carga útil será várias vezes menor que o volume de todo esse vetor. Portanto, moendo nossos corações e dentes, abandonamos essa abordagem e passamos para outra.Chave inglesa TrueTime. Relógio atômico
Eu disse que haverá uma história sobre a Spanner. Isso é legal, no século XXI: relógios atômicos, sincronização GPS.Que ideia? O Spanner é um sistema do Google que recentemente se tornou disponível para as pessoas (elas anexaram o SQL a ele). Cada transação tem um carimbo de data / hora. Como a hora é sincronizada *, cada evento pode ser atribuído a uma hora específica - o relógio atômico possui um tempo de espera, após o qual é garantido que outra hora ocorrerá. Assim, apenas gravando no banco de dados e aguardando um certo período de tempo, a serialização do evento é garantida automaticamente. Eles têm o modelo de consistência mais forte, que em princípio pode ser imaginado - é Consistência Externa.* Esse é o principal problema dos relógios Lampart - eles nunca são síncronos em sistemas distribuídos. Eles podem divergir, mesmo com o NTP, eles ainda não funcionam muito bem. "Spanner" possui um relógio atômico e a sincronização parece ser microssegundos.Por que não escolhemos? Não assumimos que nossos usuários tenham um relógio atômico embutido. Quando eles aparecerem, sendo incorporados a todos os laptops, haverá algum tipo de sincronização GPS super bacana - então sim ... Enquanto isso, o melhor possível é a Amazon, estações base para fanáticos ... Portanto, usamos outros relógios.
Assim, apenas gravando no banco de dados e aguardando um certo período de tempo, a serialização do evento é garantida automaticamente. Eles têm o modelo de consistência mais forte, que em princípio pode ser imaginado - é Consistência Externa.* Esse é o principal problema dos relógios Lampart - eles nunca são síncronos em sistemas distribuídos. Eles podem divergir, mesmo com o NTP, eles ainda não funcionam muito bem. "Spanner" possui um relógio atômico e a sincronização parece ser microssegundos.Por que não escolhemos? Não assumimos que nossos usuários tenham um relógio atômico embutido. Quando eles aparecerem, sendo incorporados a todos os laptops, haverá algum tipo de sincronização GPS super bacana - então sim ... Enquanto isso, o melhor possível é a Amazon, estações base para fanáticos ... Portanto, usamos outros relógios.Relógio híbrido
É isso que realmente marca o “MongoBD”, garantindo a consistência causal. O que eles são híbridos? Um híbrido é um valor escalar, mas consiste em dois componentes:
- A primeira é a era unix (quantos segundos se passaram desde o "começo do mundo dos computadores").
- O segundo é um incremento, também um int não assinado de 32 bits.
Isso é tudo, na verdade. Existe uma abordagem desse tipo: a parte responsável pela hora é sincronizada com o relógio o tempo todo; toda vez que ocorre uma atualização, essa parte é sincronizada com o relógio e a hora é sempre mais ou menos correta, e o incremento permite distinguir entre os eventos que ocorreram ao mesmo tempo.Por que isso é importante para o MongoBD? Como ele permite que você faça algum tipo de restauração de backup em um determinado momento, ou seja, o evento é indexado por tempo. Isso é importante quando alguns eventos são necessários; para um banco de dados, eventos são alterações no banco de dados que ocorrem em determinados momentos no tempo.Vou apenas dizer o motivo mais importante (por favor, não conte a ninguém)! Fizemos isso porque os dados ordenados e indexados no MongoDB OpLog são assim. O OpLog é uma estrutura de dados que contém absolutamente todas as alterações no banco de dados: elas primeiro acessam o OpLog e depois são aplicadas ao próprio armazenamento, no caso de uma data ou fragmento replicado.Essa foi a principal razão. Ainda, existem também requisitos práticos para o desenvolvimento do banco de dados, o que significa que ele deve ser simples - há pouco código, o mínimo possível de coisas quebradas que precisam ser reescritas e testadas. O fato de nossos oplogs terem sido indexados por um relógio híbrido ajudou muito e nos permitiu fazer a escolha certa. Realmente valeu a pena e de alguma forma funcionou magicamente, no primeiro protótipo. Foi muito legal!Sincronização do relógio
Existem vários métodos de sincronização descritos na literatura científica. Estou falando de sincronização quando temos dois shards diferentes. Se houver um conjunto de réplicas, não há necessidade de sincronização: é um "mestre único"; temos um OpLog no qual todas as alterações entram - nesse caso, tudo já está ordenado sequencialmente no próprio "Oplog". Mas se tivermos dois shards diferentes, a sincronização de tempo é importante aqui. Aqui os relógios vetoriais ajudaram mais! Mas nós não os temos. O segundo são os batimentos cardíacos. Você pode trocar alguns sinais que ocorrem a cada unidade de tempo. Mas o Hartbits é muito lento, não podemos fornecer latência para o nosso cliente.O verdadeiro tempo é, obviamente, uma coisa maravilhosa. Mas, novamente, este é provavelmente o futuro ... Embora o Atlas já possa ser feito, já existem sincronizadores de tempo "amazônicos" rápidos. Mas não estará disponível para todos.Fofocar é quando todas as mensagens incluem tempo. Isto é aproximadamente o que usamos. Cada mensagem entre nós, um driver, um roteador de nós de dados, absolutamente tudo para o MongoDB são alguns elementos, componentes de banco de dados que contêm horas que fluem. Onde quer que eles tenham o significado de tempo híbrido, ele é transmitido. 64 bits? Permite, é possível.
O segundo são os batimentos cardíacos. Você pode trocar alguns sinais que ocorrem a cada unidade de tempo. Mas o Hartbits é muito lento, não podemos fornecer latência para o nosso cliente.O verdadeiro tempo é, obviamente, uma coisa maravilhosa. Mas, novamente, este é provavelmente o futuro ... Embora o Atlas já possa ser feito, já existem sincronizadores de tempo "amazônicos" rápidos. Mas não estará disponível para todos.Fofocar é quando todas as mensagens incluem tempo. Isto é aproximadamente o que usamos. Cada mensagem entre nós, um driver, um roteador de nós de dados, absolutamente tudo para o MongoDB são alguns elementos, componentes de banco de dados que contêm horas que fluem. Onde quer que eles tenham o significado de tempo híbrido, ele é transmitido. 64 bits? Permite, é possível.Como tudo isso funciona juntos?
Aqui, olho para um conjunto de réplicas para torná-lo um pouco mais fácil. Existem Primário e Secundário. O secundário faz replicação e nem sempre é totalmente sincronizado com o primário.Há uma inserção (inserção) nas "Primárias" com um determinado valor de tempo. Esta inserção aumenta o contador interno em 11, se for o máximo. Ou irá verificar os valores do relógio e sincronizar com o relógio, se o relógio for maior. Isso permite que você classifique por tempo.Depois que ele grava, um momento importante ocorre. As horas estão em "MongoDB" e são incrementadas apenas se gravadas no "Oplog". Este é um evento que altera o estado do sistema. Absolutamente em todos os artigos clássicos, um evento é considerado uma mensagem que entra em um nó: uma mensagem chegou - isso significa que o sistema mudou de estado.Isso se deve ao fato de que durante o estudo não é totalmente possível entender como essa mensagem será interpretada. Temos certeza de que, se não estiver refletido no "Oplog", não será interpretado de forma alguma, e somente a entrada no "Oplog" é uma alteração no estado do sistema. Isso simplifica tudo para nós: o modelo simplifica e nos permite organizar na estrutura de um conjunto de réplicas e muitas outras coisas úteis.Ele retorna o valor que já foi registrado no "Oplog" - sabemos que no "Oplog" esse valor já está, e seu tempo é 12. Agora, digamos, a leitura começa em outro nó (Secundário) e já transfere o próprio afterClusterTime mensagem. Ele diz: “Preciso de tudo o que aconteceu depois de pelo menos 12 ou durante doze” (veja a figura acima).Isso é chamado de causal consistente (CAT). Existe tal conceito na teoria que é uma fatia de tempo consistente em si mesma. Nesse caso, podemos dizer que esse é o estado do sistema que foi observado no tempo 12.Agora não há nada aqui, porque parece imitar a situação em que o Secundário precisa replicar dados do Primário. Ele está esperando ... E agora os dados chegaram - retornam esses valores.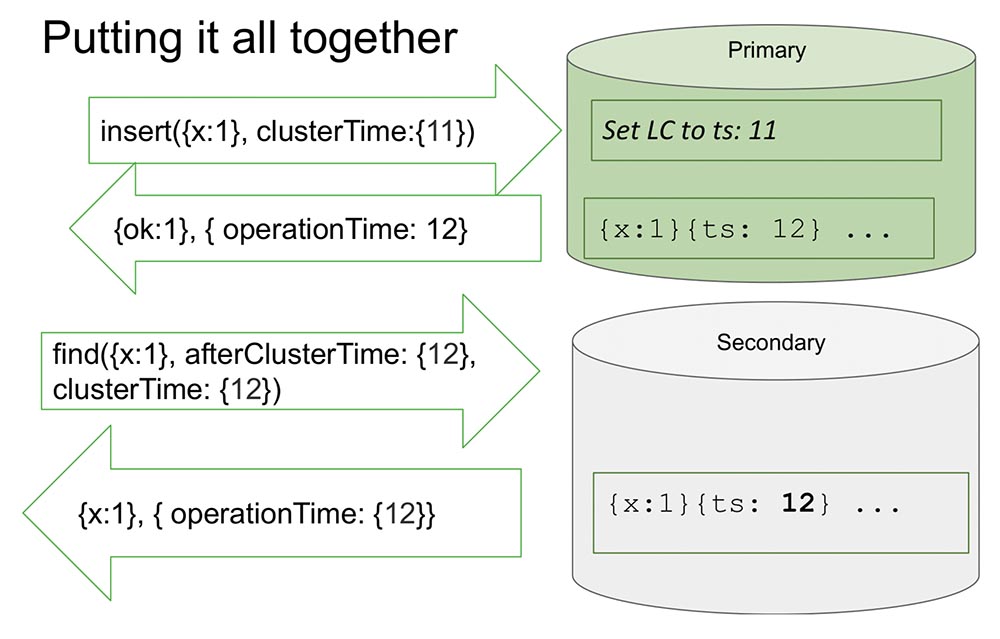 É assim que tudo funciona. Quase.O que significa "quase"? Vamos supor que haja alguém que tenha lido e entendido como tudo isso funciona. Percebi que toda vez que o ClusterTime ocorre, ele atualiza o relógio lógico interno e, em seguida, o próximo registro aumenta em um. Esta função ocupa 20 linhas. Suponha que essa pessoa transmita o maior número possível de 64 bits, menos um.Por que menos um? Como o relógio interno é substituído por esse valor (obviamente, esse é o maior possível e mais que o horário atual), haverá uma entrada no "Olog" e o relógio aumentará em mais um - e já haverá um valor máximo (simplesmente existem todas as unidades, não há para onde ir , entradas não assinadas).É claro que depois disso o sistema se torna completamente inacessível por nada. Só pode ser descarregado, limpo - muito trabalho manual. Disponibilidade total:
É assim que tudo funciona. Quase.O que significa "quase"? Vamos supor que haja alguém que tenha lido e entendido como tudo isso funciona. Percebi que toda vez que o ClusterTime ocorre, ele atualiza o relógio lógico interno e, em seguida, o próximo registro aumenta em um. Esta função ocupa 20 linhas. Suponha que essa pessoa transmita o maior número possível de 64 bits, menos um.Por que menos um? Como o relógio interno é substituído por esse valor (obviamente, esse é o maior possível e mais que o horário atual), haverá uma entrada no "Olog" e o relógio aumentará em mais um - e já haverá um valor máximo (simplesmente existem todas as unidades, não há para onde ir , entradas não assinadas).É claro que depois disso o sistema se torna completamente inacessível por nada. Só pode ser descarregado, limpo - muito trabalho manual. Disponibilidade total: além disso, se isso for replicado em outro lugar, o cluster inteiro simplesmente ficará parado. Uma situação absolutamente inaceitável que qualquer um pode organizar de forma rápida e simples! Portanto, consideramos esse momento como um dos mais importantes. Como evitá-lo?
além disso, se isso for replicado em outro lugar, o cluster inteiro simplesmente ficará parado. Uma situação absolutamente inaceitável que qualquer um pode organizar de forma rápida e simples! Portanto, consideramos esse momento como um dos mais importantes. Como evitá-lo?Nossa maneira é assinar clusterTime
Por isso, é transmitido na mensagem (antes do texto azul). Mas também começamos a gerar uma assinatura (texto azul): A assinatura é gerada por uma chave que é armazenada dentro do banco de dados, dentro do perímetro protegido; é gerado, atualizado (os usuários não veem nada). O hash é gerado e cada mensagem é assinada durante a criação e validada após o recebimento.Provavelmente, surge a pergunta nas pessoas: "Quanto isso desacelera?" Eu disse que deveria funcionar rapidamente, principalmente na ausência desse recurso.O que significa usar a consistência causal neste caso? Isso mostrará o parâmetro afterClusterTime. E sem ele, simplesmente passará valores de qualquer maneira. A fofoca, desde a versão 3.6, sempre funciona.Se deixarmos a geração constante de assinaturas, isso reduzirá a velocidade do sistema, mesmo na ausência de recursos, o que não atende às nossas abordagens e requisitos. E o que fizemos?
assinatura é gerada por uma chave que é armazenada dentro do banco de dados, dentro do perímetro protegido; é gerado, atualizado (os usuários não veem nada). O hash é gerado e cada mensagem é assinada durante a criação e validada após o recebimento.Provavelmente, surge a pergunta nas pessoas: "Quanto isso desacelera?" Eu disse que deveria funcionar rapidamente, principalmente na ausência desse recurso.O que significa usar a consistência causal neste caso? Isso mostrará o parâmetro afterClusterTime. E sem ele, simplesmente passará valores de qualquer maneira. A fofoca, desde a versão 3.6, sempre funciona.Se deixarmos a geração constante de assinaturas, isso reduzirá a velocidade do sistema, mesmo na ausência de recursos, o que não atende às nossas abordagens e requisitos. E o que fizemos?Faça rápido!
Uma coisa bastante simples, mas o truque é interessante - vou compartilhar, talvez alguém esteja interessado.Temos um hash que armazena dados assinados. Todos os dados passam pelo cache. O cache não assina especificamente a hora, mas o intervalo. Quando um determinado valor chega, geramos um intervalo, mascaramos os últimos 16 bits e assinamos esse valor: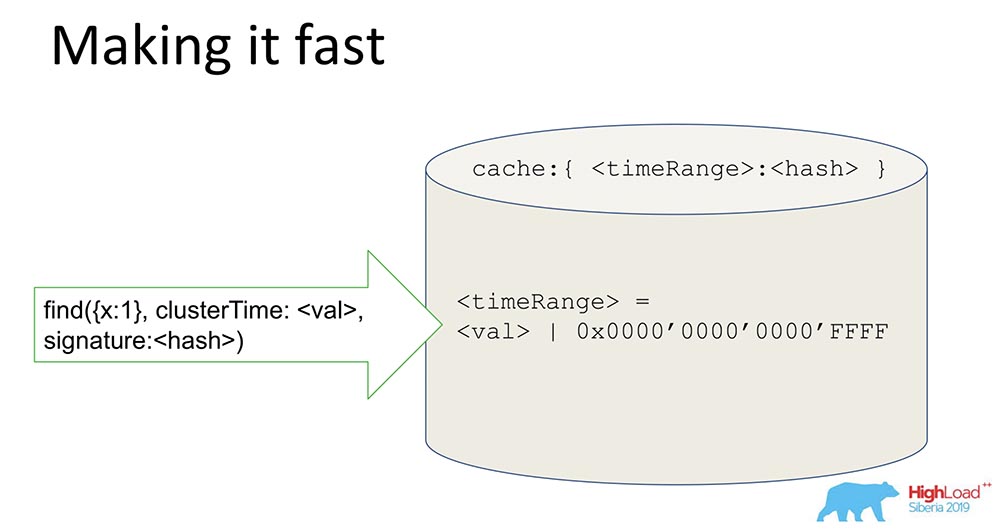 ao receber essa assinatura, agilizamos o sistema (condicionalmente) em 65 mil vezes. Funciona muito bem: quando eles fizeram os experimentos, o tempo em que tivemos uma atualização consistente foi realmente reduzido lá em 10 mil vezes. É claro que, quando estão em desacordo, isso não funciona. Mas, na maioria dos casos práticos, isso funciona. A combinação da assinatura Range com a assinatura resolveu o problema de segurança.
ao receber essa assinatura, agilizamos o sistema (condicionalmente) em 65 mil vezes. Funciona muito bem: quando eles fizeram os experimentos, o tempo em que tivemos uma atualização consistente foi realmente reduzido lá em 10 mil vezes. É claro que, quando estão em desacordo, isso não funciona. Mas, na maioria dos casos práticos, isso funciona. A combinação da assinatura Range com a assinatura resolveu o problema de segurança.O que aprendemos?
Lições que aprendemos com isso:- , , , . - ( , . .), , . , , , . – .
, , («», ) – . ? . , . – , . - . , «» , , , availability, latency .
- A última é que tivemos que considerar idéias diferentes e combinar vários artigos geralmente diferentes em uma única abordagem. A idéia de assinar, por exemplo, veio de um artigo que examinou o protocolo Paxos, que para Faylor não bizantino dentro do protocolo de autorização, para bizantinos fora do protocolo de autorização ... Em geral, foi exatamente isso que fizemos no final.
Não há absolutamente nada de novo aqui! Mas assim que misturamos tudo ... É como dizer que a receita da salada Olivier não faz sentido, porque ovos, maionese e pepino já surgiram ... É a mesma história.
 Sobre isso eu vou terminar. Obrigado!
Sobre isso eu vou terminar. Obrigado!Questões
Pergunta da audiência (doravante - B): - Obrigado, Michael, pelo relatório! O tema do tempo é interessante. Você está usando fofocas. Eles disseram que todo mundo tem seu próprio tempo, todo mundo sabe o horário local. Pelo que entendi, temos um driver - pode haver muitos clientes com drivers, planejadores de consulta também, muitos fragmentos ... Mas para que serve o sistema se de repente tivermos uma discrepância: alguém decide que ele é por um minuto à frente, alguém - um minuto atrás? Onde nos encontraremos?MT: - Ótima pergunta mesmo! Eu só queria dizer sobre estilhaços. Se eu entendi a pergunta corretamente, temos a seguinte situação: existe o fragmento 1 e o fragmento 2, a leitura ocorre nesses dois fragmentos - eles têm uma discrepância, não interagem entre si, porque o tempo que eles conhecem é diferente, especialmente o tempo em que Eles existem em oplogs.Suponha que o shard 1 tenha feito um milhão de registros, o shard 2 não fez nada e a solicitação ocorreu em dois shards. E o primeiro tem afterClusterTime mais de um milhão. Em tal situação, como expliquei, o fragmento 2 nunca responderá.P: - Eu queria saber como eles são sincronizados e escolhem um horário lógico?MT: - Muito fácil de sincronizar. Shard, quando afterClusterTime chega até ele, e ele não encontra o tempo no "Catch" - inicia não aprovado. Ou seja, ele levanta as mãos para esse valor com as mãos. Isso significa que não há eventos correspondentes a essa consulta. Ele cria esse evento artificialmente e, assim, torna-se o Causal Consistente.P: - E se, depois disso, alguns outros eventos perdidos em algum lugar da rede ainda vierem a ele?MT:- O fragmento está tão arranjado que não virá mais, pois é um único mestre. Se ele já gravou, eles não virão, mas serão depois. Não pode acontecer que em algum lugar algo esteja preso, ele não escreverá e então esses eventos chegaram - e a consistência causal foi violada. Quando ele não escreve, todos têm que vir em seguida (ele esperará por eles). AT:- Eu tenho algumas perguntas sobre as falas. A consistência causal pressupõe que há uma determinada fila de ações que precisam ser executadas. O que acontece se perdermos um pacote? Então o dia 10 passou, o dia 11 ... o dia 12 desapareceu, e todo mundo está esperando que isso seja cumprido. E de repente nosso carro morreu, não podemos fazer nada. Existe um comprimento máximo da fila que se acumula antes de ser executado? Que falha fatal ocorre quando um estado é perdido? Além disso, se escrevermos que existe algum tipo de estado anterior, devemos começar de alguma forma? E eles não se afastaram dele!MT:- Também é uma pergunta maravilhosa! O que estamos fazendo? O MongoDB tem o conceito de registros de quorum, lê o quorum. Quando uma mensagem pode desaparecer? Quando o registro não é quorum ou quando a leitura não é quorum (algum lixo também pode grudar).Com relação à consistência causal, realizamos um grande teste experimental, que resultou no fato de que, quando a gravação e a leitura não são quorum, ocorrem violações da consistência causal. Exatamente o que você diz!Nossa dica: use pelo menos a leitura de quorum ao usar a consistência causal. Nesse caso, nada será perdido, mesmo se o registro de quorum for perdido ... Essa é uma situação ortogonal: se o usuário não quiser que os dados sejam perdidos, você precisará usar o registro de quorum. A consistência causal não garante durabilidade. A garantia de durabilidade é fornecida pela replicação e maquinaria associada à replicação.P: - Quando criamos uma instância que o sharding faz por nós (não mestre, mas escravo, respectivamente), ele se baseia no tempo unix de sua própria máquina ou no tempo do "mestre"; sincronizado pela primeira vez ou periodicamente?MT:- Agora vou deixar claro. Fragmento (ou seja, partição horizontal) - sempre há Primário. E em um fragmento, pode haver um "mestre" e pode haver réplicas. Mas o shard sempre suporta gravação, porque deve suportar um determinado domínio (o Primary está no shard).P: - Ou seja, tudo depende puramente do "mestre"? Sempre use o tempo "mestre"?MT: - Sim. Pode-se dizer figurativamente: o relógio está correndo quando há uma gravação no "master", no "Oplog".P: - Temos um cliente que se conecta e ele não precisa saber nada sobre tempo?MT:- Em geral, você não precisa saber de nada! Se falamos sobre como isso funciona no cliente: no cliente, quando ele deseja usar a consistência causal, ele precisa abrir uma sessão. Agora está tudo lá: ambas as transações na sessão e recuperar direitos ... Uma sessão é uma ordenação de eventos lógicos que ocorrem com um cliente.Se ele abrir esta sessão e disser que deseja consistência causal (se por padrão a sessão suportar consistência causal), tudo funcionará automaticamente. O motorista lembra desse tempo e aumenta quando recebe uma nova mensagem. Ele lembra qual resposta retornou a anterior do servidor que retornou os dados. A solicitação a seguir conterá afterCluster ("o tempo é maior que isso").O cliente não precisa saber absolutamente nada! Isso é absolutamente opaco para ele. Se as pessoas usam esses recursos, o que posso fazer? Primeiro, você pode ler com segurança os secundários: você pode escrever no Primário e ler os secundários geograficamente replicados e garantir que funcione. Ao mesmo tempo, as sessões que foram gravadas na Primária podem ser transferidas até para a Secundária, ou seja, você pode usar não uma sessão, mas várias.P: - O tópico Consistência eventual está fortemente relacionado à nova camada de ciência de computação - tipos de dados CRDT (tipos de dados replicados sem conflitos). Você considerou a integração desses tipos de dados no banco de dados e o que você pode dizer sobre isso?MT: - Boa pergunta! O CRDT faz sentido para conflitos de gravação: no MongoDB - mestre único.AT:- Eu tenho uma pergunta dos devops. No mundo real, existem situações jesuítas quando ocorre a falha bizantina, e as pessoas más dentro do perímetro protegido começam a aderir ao protocolo, enviam pacotes de artesanato de uma maneira especial?
AT:- Eu tenho algumas perguntas sobre as falas. A consistência causal pressupõe que há uma determinada fila de ações que precisam ser executadas. O que acontece se perdermos um pacote? Então o dia 10 passou, o dia 11 ... o dia 12 desapareceu, e todo mundo está esperando que isso seja cumprido. E de repente nosso carro morreu, não podemos fazer nada. Existe um comprimento máximo da fila que se acumula antes de ser executado? Que falha fatal ocorre quando um estado é perdido? Além disso, se escrevermos que existe algum tipo de estado anterior, devemos começar de alguma forma? E eles não se afastaram dele!MT:- Também é uma pergunta maravilhosa! O que estamos fazendo? O MongoDB tem o conceito de registros de quorum, lê o quorum. Quando uma mensagem pode desaparecer? Quando o registro não é quorum ou quando a leitura não é quorum (algum lixo também pode grudar).Com relação à consistência causal, realizamos um grande teste experimental, que resultou no fato de que, quando a gravação e a leitura não são quorum, ocorrem violações da consistência causal. Exatamente o que você diz!Nossa dica: use pelo menos a leitura de quorum ao usar a consistência causal. Nesse caso, nada será perdido, mesmo se o registro de quorum for perdido ... Essa é uma situação ortogonal: se o usuário não quiser que os dados sejam perdidos, você precisará usar o registro de quorum. A consistência causal não garante durabilidade. A garantia de durabilidade é fornecida pela replicação e maquinaria associada à replicação.P: - Quando criamos uma instância que o sharding faz por nós (não mestre, mas escravo, respectivamente), ele se baseia no tempo unix de sua própria máquina ou no tempo do "mestre"; sincronizado pela primeira vez ou periodicamente?MT:- Agora vou deixar claro. Fragmento (ou seja, partição horizontal) - sempre há Primário. E em um fragmento, pode haver um "mestre" e pode haver réplicas. Mas o shard sempre suporta gravação, porque deve suportar um determinado domínio (o Primary está no shard).P: - Ou seja, tudo depende puramente do "mestre"? Sempre use o tempo "mestre"?MT: - Sim. Pode-se dizer figurativamente: o relógio está correndo quando há uma gravação no "master", no "Oplog".P: - Temos um cliente que se conecta e ele não precisa saber nada sobre tempo?MT:- Em geral, você não precisa saber de nada! Se falamos sobre como isso funciona no cliente: no cliente, quando ele deseja usar a consistência causal, ele precisa abrir uma sessão. Agora está tudo lá: ambas as transações na sessão e recuperar direitos ... Uma sessão é uma ordenação de eventos lógicos que ocorrem com um cliente.Se ele abrir esta sessão e disser que deseja consistência causal (se por padrão a sessão suportar consistência causal), tudo funcionará automaticamente. O motorista lembra desse tempo e aumenta quando recebe uma nova mensagem. Ele lembra qual resposta retornou a anterior do servidor que retornou os dados. A solicitação a seguir conterá afterCluster ("o tempo é maior que isso").O cliente não precisa saber absolutamente nada! Isso é absolutamente opaco para ele. Se as pessoas usam esses recursos, o que posso fazer? Primeiro, você pode ler com segurança os secundários: você pode escrever no Primário e ler os secundários geograficamente replicados e garantir que funcione. Ao mesmo tempo, as sessões que foram gravadas na Primária podem ser transferidas até para a Secundária, ou seja, você pode usar não uma sessão, mas várias.P: - O tópico Consistência eventual está fortemente relacionado à nova camada de ciência de computação - tipos de dados CRDT (tipos de dados replicados sem conflitos). Você considerou a integração desses tipos de dados no banco de dados e o que você pode dizer sobre isso?MT: - Boa pergunta! O CRDT faz sentido para conflitos de gravação: no MongoDB - mestre único.AT:- Eu tenho uma pergunta dos devops. No mundo real, existem situações jesuítas quando ocorre a falha bizantina, e as pessoas más dentro do perímetro protegido começam a aderir ao protocolo, enviam pacotes de artesanato de uma maneira especial? MT: - Pessoas más dentro do perímetro são como um cavalo de Tróia! Pessoas más dentro do perímetro podem fazer muitas coisas ruins.P: - É claro que deixar um buraco no servidor, grosso modo, através do qual você pode enfiar o zoológico de elefantes e recolher todo o cluster para sempre ... Levará tempo para a recuperação manual ... Isto é, para dizer o mínimo, errado. Por outro lado, isso é curioso: na vida real, na prática, há situações em que ataques internos naturalmente semelhantes ocorrem?MT:- Como raramente encontro violações de segurança na vida real, não posso dizer - talvez elas aconteçam. Mas se falamos sobre filosofia de desenvolvimento, pensamos assim: temos um perímetro que fornece aos indivíduos que fazem segurança - é um castelo, um muro; e dentro do perímetro você pode fazer o que quiser. É claro que existem usuários com a capacidade de procurar apenas e há usuários com a capacidade de apagar o diretório.Dependendo dos direitos, o dano que os usuários podem causar pode ser um mouse ou um elefante. É claro que um usuário com todos os direitos pode fazer qualquer coisa. Um usuário sem direitos amplos de dano pode causar significativamente menos. Em particular, ele não pode quebrar o sistema.AT:- No perímetro seguro, alguém escalou para formar protocolos inesperados para o servidor, a fim de configurar o servidor com câncer e, se você tiver sorte, todo o cluster ... Isso acontece tão "bem"?MT: - Eu nunca ouvi falar dessas coisas. O fato de que dessa maneira você pode preencher o servidor não é um segredo. Para preencher por dentro, sendo do protocolo, sendo um usuário autorizado que pode escrever algo assim em uma mensagem ... Na verdade, é impossível, porque de qualquer maneira será verificado. É possível desativar essa autenticação para usuários que não desejam - este é o problema deles; grosso modo, eles mesmos destruíram as paredes e você pode amontoar um elefante ali, o que vai atropelar ... Em geral, você pode se vestir como reparador, venha buscá-lo!AT:- Obrigado pelo relatório. Sergey (Yandex). Em "Mong", existe uma constante que limita o número de membros votantes no conjunto de réplicas, e essa constante é 7 (sete). Por que isso é uma constante? Por que isso não é algum tipo de parâmetro?MT: - Conjunto de réplicas também temos 40 nós. Sempre existe uma maioria. Não sei qual versão ...P: - No conjunto de réplicas, você pode executar membros sem direito a voto, mas votando - no máximo 7. Como, nesse caso, ocorrerá o desligamento se o conjunto de réplicas for puxado para três datacenters? Um data center pode desligar-se facilmente e outra máquina cai.MT: - Isso já está um pouco fora do escopo do relatório. Essa é uma pergunta comum. Talvez então eu possa contar a ele.
MT: - Pessoas más dentro do perímetro são como um cavalo de Tróia! Pessoas más dentro do perímetro podem fazer muitas coisas ruins.P: - É claro que deixar um buraco no servidor, grosso modo, através do qual você pode enfiar o zoológico de elefantes e recolher todo o cluster para sempre ... Levará tempo para a recuperação manual ... Isto é, para dizer o mínimo, errado. Por outro lado, isso é curioso: na vida real, na prática, há situações em que ataques internos naturalmente semelhantes ocorrem?MT:- Como raramente encontro violações de segurança na vida real, não posso dizer - talvez elas aconteçam. Mas se falamos sobre filosofia de desenvolvimento, pensamos assim: temos um perímetro que fornece aos indivíduos que fazem segurança - é um castelo, um muro; e dentro do perímetro você pode fazer o que quiser. É claro que existem usuários com a capacidade de procurar apenas e há usuários com a capacidade de apagar o diretório.Dependendo dos direitos, o dano que os usuários podem causar pode ser um mouse ou um elefante. É claro que um usuário com todos os direitos pode fazer qualquer coisa. Um usuário sem direitos amplos de dano pode causar significativamente menos. Em particular, ele não pode quebrar o sistema.AT:- No perímetro seguro, alguém escalou para formar protocolos inesperados para o servidor, a fim de configurar o servidor com câncer e, se você tiver sorte, todo o cluster ... Isso acontece tão "bem"?MT: - Eu nunca ouvi falar dessas coisas. O fato de que dessa maneira você pode preencher o servidor não é um segredo. Para preencher por dentro, sendo do protocolo, sendo um usuário autorizado que pode escrever algo assim em uma mensagem ... Na verdade, é impossível, porque de qualquer maneira será verificado. É possível desativar essa autenticação para usuários que não desejam - este é o problema deles; grosso modo, eles mesmos destruíram as paredes e você pode amontoar um elefante ali, o que vai atropelar ... Em geral, você pode se vestir como reparador, venha buscá-lo!AT:- Obrigado pelo relatório. Sergey (Yandex). Em "Mong", existe uma constante que limita o número de membros votantes no conjunto de réplicas, e essa constante é 7 (sete). Por que isso é uma constante? Por que isso não é algum tipo de parâmetro?MT: - Conjunto de réplicas também temos 40 nós. Sempre existe uma maioria. Não sei qual versão ...P: - No conjunto de réplicas, você pode executar membros sem direito a voto, mas votando - no máximo 7. Como, nesse caso, ocorrerá o desligamento se o conjunto de réplicas for puxado para três datacenters? Um data center pode desligar-se facilmente e outra máquina cai.MT: - Isso já está um pouco fora do escopo do relatório. Essa é uma pergunta comum. Talvez então eu possa contar a ele.
Um pouco de publicidade :)
Obrigado por ficar com a gente. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando aos seus amigos o VPS na nuvem para desenvolvedores a partir de US $ 4,99 , um analógico exclusivo de servidores de nível básico que foi inventado por nós para você: Toda a verdade sobre o VPS (KVM) E5-2697 v3 (6 núcleos) 10 GB DDR4 480 GB SSD 1 Gbps de US $ 19 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).Dell R730xd 2 vezes mais barato no data center Equinix Tier IV em Amsterdã? Somente nós temos 2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre Como criar um prédio de infraestrutura. classe c usando servidores Dell R730xd E5-2650 v4 que custam 9.000 euros por um centavo? Source: https://habr.com/ru/post/undefined/
All Articles