HighLoad ++, Anastasia Tsymbalyuk, Stanislav Tselovalnikov (Sberbank): como nos tornamos MDA
A próxima conferência HighLoad ++ será realizada nos dias 6 e 7 de abril de 2020 em São Petersburgo.Detalhes e ingressos aqui . HighLoad ++ Sibéria 2019. Salão "Krasnoyarsk". 25 de junho de 14h Resumos e apresentação .Desenvolver um sistema industrial de gerenciamento e disseminação de dados do zero não é tarefa fácil. Especialmente quando há um atraso completo, o tempo para o trabalho é de um quarto e os requisitos do produto são uma turbulência perpétua. Vamos mostrar o exemplo da construção de um sistema de gerenciamento de metadados, como construir um sistema escalável industrial em um curto período de tempo, o que inclui o armazenamento e a disseminação de dados.Nossa abordagem aproveita ao máximo os metadados, o código SQL dinâmico e a geração de código com base no codegen e no guidão da Swagger. Essa solução reduz o tempo de desenvolvimento e reconfiguração do sistema e a adição de novos objetos de gerenciamento não requer uma única linha de novo código.Contaremos como funciona em nossa equipe: quais regras seguimos, quais ferramentas usamos, quais dificuldades encontramos e como superá-las heroicamente.Anastasia Tsymbalyuk (a seguir - CA): - Meu nome é Nastya, e este é Stas!Stas Tselovalnikov (a seguir - SC): - Olá pessoal!AC: - Hoje falaremos sobre o MDA e como, usando essa abordagem, reduzimos o tempo de desenvolvimento e apresentamos ao mundo um sistema industrial de gerenciamento de metadados escalável. Viva!SC: - Nastya, o que é MDA?AC: - Stas, acho que vamos passar sem problemas agora. Mais precisamente, falarei um pouco sobre isso no final da apresentação. Vamos falar sobre nós primeiro:
Vamos mostrar o exemplo da construção de um sistema de gerenciamento de metadados, como construir um sistema escalável industrial em um curto período de tempo, o que inclui o armazenamento e a disseminação de dados.Nossa abordagem aproveita ao máximo os metadados, o código SQL dinâmico e a geração de código com base no codegen e no guidão da Swagger. Essa solução reduz o tempo de desenvolvimento e reconfiguração do sistema e a adição de novos objetos de gerenciamento não requer uma única linha de novo código.Contaremos como funciona em nossa equipe: quais regras seguimos, quais ferramentas usamos, quais dificuldades encontramos e como superá-las heroicamente.Anastasia Tsymbalyuk (a seguir - CA): - Meu nome é Nastya, e este é Stas!Stas Tselovalnikov (a seguir - SC): - Olá pessoal!AC: - Hoje falaremos sobre o MDA e como, usando essa abordagem, reduzimos o tempo de desenvolvimento e apresentamos ao mundo um sistema industrial de gerenciamento de metadados escalável. Viva!SC: - Nastya, o que é MDA?AC: - Stas, acho que vamos passar sem problemas agora. Mais precisamente, falarei um pouco sobre isso no final da apresentação. Vamos falar sobre nós primeiro: posso me descrever como um candidato a sinergia em soluções de TI industriais.SC: - e eu?
posso me descrever como um candidato a sinergia em soluções de TI industriais.SC: - e eu?O que a equipe SberData faz?
AC: - E você é apenas um mastodonte industrial, porque você trouxe mais de uma solução para o baile!SC: - De fato, trabalhamos juntos no Sberbank na mesma equipe e gerenciamos os metadados do SberData: AC: - SberData, se de uma maneira simples - é uma plataforma analítica onde todas as faixas digitais de cada cliente fluem. Se você é cliente do Sberbank, todas as informações sobre você fluem exatamente para lá. Muitos conjuntos de dados são armazenados lá, mas entendemos que a quantidade de dados não significa sua qualidade. E os dados sem contexto às vezes são completamente inúteis, porque não podemos aplicá-los, interpretar, proteger, enriquecê-los.Apenas essas tarefas são resolvidas por metadados. Eles nos mostram o contexto comercial e o componente técnico dos dados, ou seja, onde eles apareceram, como foram transformados, em que ponto a descrição mínima, a marcação é agora. Isso já é suficiente para começar a usar os dados e confiar neles. Essa é precisamente a solução dos metadados da tarefa.SC: - Em outras palavras, a missão da nossa equipe é aumentar a eficiência da plataforma analítica de informações do Sberbank devido ao fato de que as informações sobre as quais você acabou de falar devem ser entregues às pessoas certas, na hora certa, no lugar certo. E lembre-se, você também disse que, se os dados são petróleo moderno, os metadados são um mapa dos depósitos desse petróleo.AC:- De fato, esta é uma das minhas declarações brilhantes, da qual tenho muito orgulho. Tecnicamente, essa tarefa foi reduzida ao fato de termos que criar uma ferramenta de gerenciamento de metadados dentro de nossa plataforma e garantir seu ciclo de vida completo.Mas, para nos aprofundarmos nos problemas de nossa área de atuação e entendermos em que ponto estamos, sugiro voltar 9 meses atrás.Então, imagine: do lado de fora da janela é o mês de novembro, todos os pássaros voaram para o sul, estamos tristes ... E naquela época tivemos um piloto de sucesso com a equipe, havia clientes - todos ficamos na zona de conforto até o ponto de retorno.
AC: - SberData, se de uma maneira simples - é uma plataforma analítica onde todas as faixas digitais de cada cliente fluem. Se você é cliente do Sberbank, todas as informações sobre você fluem exatamente para lá. Muitos conjuntos de dados são armazenados lá, mas entendemos que a quantidade de dados não significa sua qualidade. E os dados sem contexto às vezes são completamente inúteis, porque não podemos aplicá-los, interpretar, proteger, enriquecê-los.Apenas essas tarefas são resolvidas por metadados. Eles nos mostram o contexto comercial e o componente técnico dos dados, ou seja, onde eles apareceram, como foram transformados, em que ponto a descrição mínima, a marcação é agora. Isso já é suficiente para começar a usar os dados e confiar neles. Essa é precisamente a solução dos metadados da tarefa.SC: - Em outras palavras, a missão da nossa equipe é aumentar a eficiência da plataforma analítica de informações do Sberbank devido ao fato de que as informações sobre as quais você acabou de falar devem ser entregues às pessoas certas, na hora certa, no lugar certo. E lembre-se, você também disse que, se os dados são petróleo moderno, os metadados são um mapa dos depósitos desse petróleo.AC:- De fato, esta é uma das minhas declarações brilhantes, da qual tenho muito orgulho. Tecnicamente, essa tarefa foi reduzida ao fato de termos que criar uma ferramenta de gerenciamento de metadados dentro de nossa plataforma e garantir seu ciclo de vida completo.Mas, para nos aprofundarmos nos problemas de nossa área de atuação e entendermos em que ponto estamos, sugiro voltar 9 meses atrás.Então, imagine: do lado de fora da janela é o mês de novembro, todos os pássaros voaram para o sul, estamos tristes ... E naquela época tivemos um piloto de sucesso com a equipe, havia clientes - todos ficamos na zona de conforto até o ponto de retorno.Sistema de gerenciamento de metadados do modelo
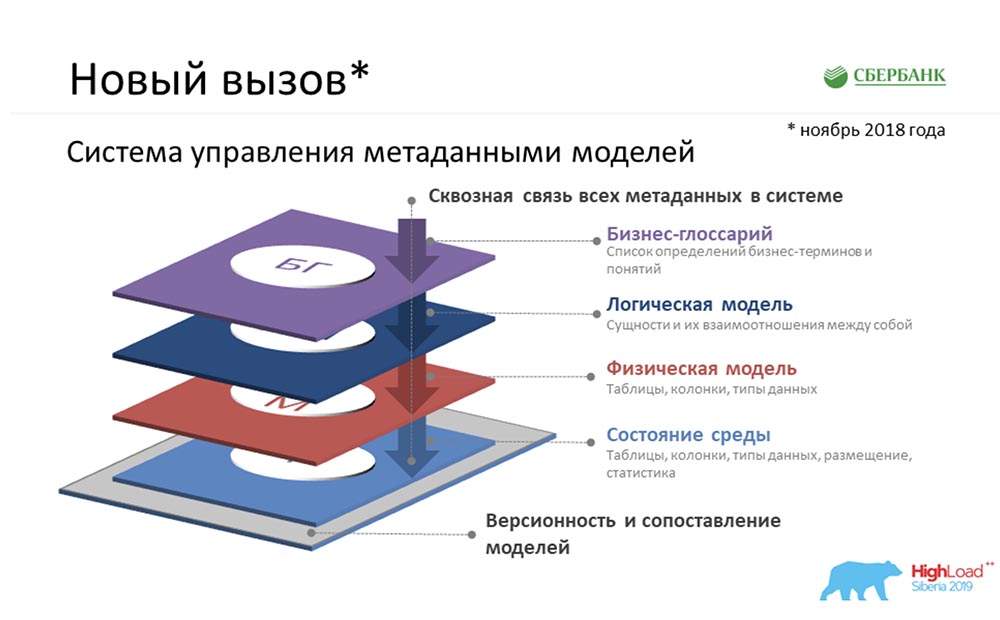 SC: - Havia algo mais que você tinha em estar em uma zona de conforto ... De fato, tivemos a tarefa de criar o Metadata Broker, que deveria dar a oportunidade de se comunicar com nossos clientes, programas, sistemas. Nossos clientes deveriam ter tido a oportunidade, no nível de back-end, de enviar ou receber algum tipo de pacote de metadados. E nós, fornecendo essa função, em nosso nível, tivemos que acumular as informações mais consistentes e relevantes sobre os metadados em quatro níveis lógicos:
SC: - Havia algo mais que você tinha em estar em uma zona de conforto ... De fato, tivemos a tarefa de criar o Metadata Broker, que deveria dar a oportunidade de se comunicar com nossos clientes, programas, sistemas. Nossos clientes deveriam ter tido a oportunidade, no nível de back-end, de enviar ou receber algum tipo de pacote de metadados. E nós, fornecendo essa função, em nosso nível, tivemos que acumular as informações mais consistentes e relevantes sobre os metadados em quatro níveis lógicos:- Nível de glossário de negócios.
- O nível do modelo lógico.
- O nível do modelo físico.
- O estado do ambiente que recebemos devido ao reverso dos ambientes industriais.
E tudo isso deve ser consistente.AC: - Sim, sério. Mas aqui eu também explicaria de alguma maneira de uma maneira simples, porque não excluo que a área de assunto não é clara e incompreensível ... Umglossário de negócios é sobre o que as pessoas inteligentes de terno criam por horas ... como nomear um termo, como elaborar uma fórmula Cálculo. Eles pensam há muito tempo e, no final, têm apenas um glossário comercial.O modelo lógico é sobre como o analista se vê no mundo, capaz de se comunicar com essas pessoas inteligentes de terno e gravata, mas ao mesmo tempo entende como seria possível aterrissar. Longe dos detalhes da realização física.O modelo físico é sobre quando é a vez de duros programadores, arquitetos que realmente entendem como pousar esses objetos - em qual tabela colocar, quais campos criar, quais índices pendurar ... Oestado do ambiente é uma espécie de elenco. Isto é como um testemunho de um carro. Às vezes, um programador quer dizer uma coisa à máquina, mas ela entende mal. Apenas o estado do ambiente nos mostra o estado real das coisas, e constantemente comparamos tudo; e entendemos que há uma diferença entre o que o programador disse e o estado real do ambiente.Caso para descrever metadados
SC: - Vamos explicar com um exemplo concreto. Por exemplo, temos quatro desses níveis designados. Suponha que tenhamos pessoas sérias que trabalhem no nível de um glossário comercial - elas não entendem como e o que é organizado dentro dela. Mas eles entendem que precisam criar uma forma de relatório obrigatório, precisam obter, digamos, o saldo médio em contas pessoais: para esse nível, uma pessoa já deve ter seu próprio glossário comercial (termos de relatório obrigatório) ou tê-lo (saldo médio em uma conta pessoal). A seguir, o analista que o entende perfeitamente, pode falar a mesma língua com ele, mas também pode falar a mesma língua com os programadores.Ele diz: "Escute, aqui você tem toda a história dividida em contas separadas como entidades, e elas têm um atributo - o saldo médio".Em seguida, vem o arquiteto e diz: “Faremos essa vitrine de empréstimos para pessoas jurídicas. Dessa forma, faremos uma tabela física de contas pessoais, faremos uma tabela física de saldos diários em contas pessoais (porque eles são recebidos todos os dias no fechamento do dia de negociação). E uma vez por mês no prazo, calcularemos a média (tabela de saldos mensais), conforme solicitado. ”Não antes de dizer que acabou. E então nosso analisador chegou, que foi ao circuito industrial e disse: “Sim, entendo - existem tabelas necessárias ...” O que mais enriqueceu essa tabela? Aqui (como exemplo) - partições e índices, embora, estritamente falando, ambas partições e índices possam estar no nível de design do modelo físico, mas pode haver algo mais (por exemplo, volume de dados).
para esse nível, uma pessoa já deve ter seu próprio glossário comercial (termos de relatório obrigatório) ou tê-lo (saldo médio em uma conta pessoal). A seguir, o analista que o entende perfeitamente, pode falar a mesma língua com ele, mas também pode falar a mesma língua com os programadores.Ele diz: "Escute, aqui você tem toda a história dividida em contas separadas como entidades, e elas têm um atributo - o saldo médio".Em seguida, vem o arquiteto e diz: “Faremos essa vitrine de empréstimos para pessoas jurídicas. Dessa forma, faremos uma tabela física de contas pessoais, faremos uma tabela física de saldos diários em contas pessoais (porque eles são recebidos todos os dias no fechamento do dia de negociação). E uma vez por mês no prazo, calcularemos a média (tabela de saldos mensais), conforme solicitado. ”Não antes de dizer que acabou. E então nosso analisador chegou, que foi ao circuito industrial e disse: “Sim, entendo - existem tabelas necessárias ...” O que mais enriqueceu essa tabela? Aqui (como exemplo) - partições e índices, embora, estritamente falando, ambas partições e índices possam estar no nível de design do modelo físico, mas pode haver algo mais (por exemplo, volume de dados).Registro e armazenamento no nível de metadados
AC: - Como tudo é armazenado conosco? Esta é uma forma super simplificada do exemplo que Stas pintou anteriormente! Como tudo isso estará conosco?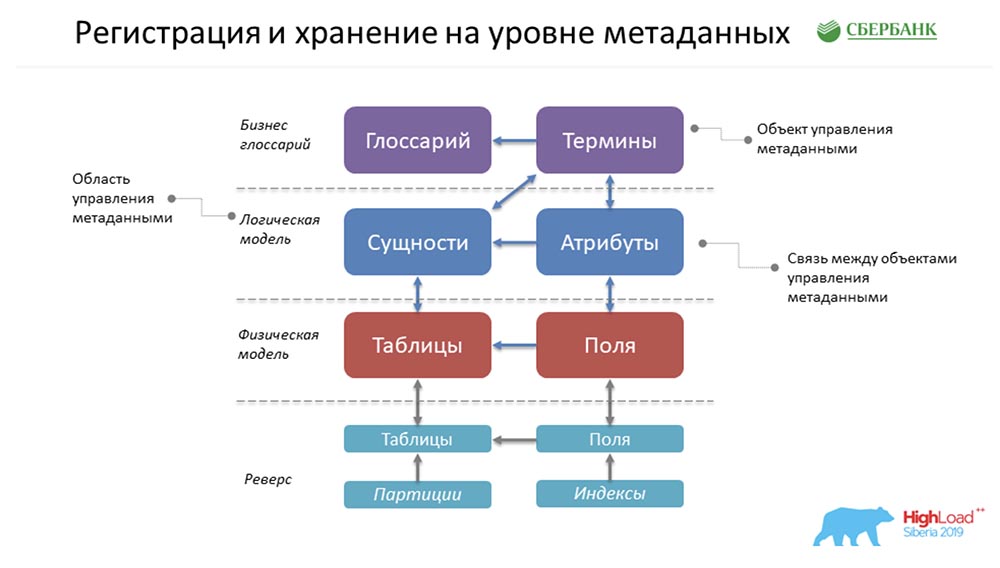 De fato, haverá uma linha no objeto Glossário, uma no objeto Termos, uma nas Entidades, uma nos Atributos e assim por diante. Na figura acima, cada retângulo é um objeto em nosso sistema de controle, que representa essa ou aquela informação armazenada lá.Para apresentar lentamente a terminologia, peço que observe o seguinte ... O que é um objeto de gerenciamento de metadados? Fisicamente, isso é apresentado na forma de uma tabela, mas, de fato, certas informações são armazenadas lá em termos, glossários, entidades, atributos, etc. Este termo, "objeto", continuaremos a usar em nossa apresentação.SC: - Aqui deve-se dizer que cada cubo é apenas uma tabela em nosso sistema onde armazenamos metadados e chamamos isso de objeto de controle.
De fato, haverá uma linha no objeto Glossário, uma no objeto Termos, uma nas Entidades, uma nos Atributos e assim por diante. Na figura acima, cada retângulo é um objeto em nosso sistema de controle, que representa essa ou aquela informação armazenada lá.Para apresentar lentamente a terminologia, peço que observe o seguinte ... O que é um objeto de gerenciamento de metadados? Fisicamente, isso é apresentado na forma de uma tabela, mas, de fato, certas informações são armazenadas lá em termos, glossários, entidades, atributos, etc. Este termo, "objeto", continuaremos a usar em nossa apresentação.SC: - Aqui deve-se dizer que cada cubo é apenas uma tabela em nosso sistema onde armazenamos metadados e chamamos isso de objeto de controle.Requisitos de metadados
O que tínhamos na entrada? Na entrada, recebemos requisitos bastante interessantes. Havia muitos deles, mas aqui queremos mostrar três principais: O primeiro requisito é bastante clássico. Dizem-nos: "Gente, tudo o que chegou a você uma vez tem que vir para sempre". O histórico está completo e qualquer alteração no seu sistema de metadados que chega até você (não importa se um pacote de 100 campos chegou (100 alterações) ou se um campo foi alterado em uma tabela) exige um novo registro dos metadados. Eles também exigem retornar a resposta:
O primeiro requisito é bastante clássico. Dizem-nos: "Gente, tudo o que chegou a você uma vez tem que vir para sempre". O histórico está completo e qualquer alteração no seu sistema de metadados que chega até você (não importa se um pacote de 100 campos chegou (100 alterações) ou se um campo foi alterado em uma tabela) exige um novo registro dos metadados. Eles também exigem retornar a resposta:- por padrão - estado atual;
- por data;
- pelo número da revisão.
O segundo requisito foi mais interessante: nos disseram que eles podem trabalhar conosco em objetos, mas eles precisam programar muito em Java, mas não querem. Eles sugeriram que misturássemos 100 objetos (ou 10) de uma só vez, e deveríamos lidar com esse negócio (porque podemos). O que significa a mistura? Por exemplo, 10 colunas vieram. Eles têm um link para o identificador da tabela, mas não temos a tabela em si - ela veio no final do JSON. "Você pensa e processa - é necessário que você possa"!Em ordem crescente de interesse - a terceira: “Queremos poder não apenas usar a API que você nos fará, mas também entender a nós mesmos ...” E, em uma ordem arbitrária, diga: “Dê-nos a união deste objeto para aquele através do terceiro objeto. E deixe seu próprio sistema entender como fazer tudo, solicitar ao banco de dados e retornar o resultado em JSON. ”Tínhamos uma história assim na entrada.Estimativas estimadas
 AC: - De acordo com nossos cálculos aproximados, para implementar todo esse conceito, cada objeto de controle precisava participar de sete interfaces: simples (simples), para gravação / leitura e exclusão em todo o objeto ... Maistrês - para gravação / leitura / exclusão universal, t Ou seja, podemos jogar tudo em qualquer ordem e como transferir o conjunto de sopas para o sistema, e ela descobrirá em que ordem excluir, colocar, ler.Mais uma coisa - construir uma hierarquia para que possamos indicar ao sistema - “Devolva-nos de objeto a objeto”; e retorna uma árvore de objetos aninhados.
AC: - De acordo com nossos cálculos aproximados, para implementar todo esse conceito, cada objeto de controle precisava participar de sete interfaces: simples (simples), para gravação / leitura e exclusão em todo o objeto ... Maistrês - para gravação / leitura / exclusão universal, t Ou seja, podemos jogar tudo em qualquer ordem e como transferir o conjunto de sopas para o sistema, e ela descobrirá em que ordem excluir, colocar, ler.Mais uma coisa - construir uma hierarquia para que possamos indicar ao sistema - “Devolva-nos de objeto a objeto”; e retorna uma árvore de objetos aninhados.Complexidade de implementação
SC: - Além dos requisitos técnicos que nos chegaram no momento do início desta história, tivemos dificuldades adicionais. Em primeiro lugar, isso é uma incerteza de requisitos. Nem toda equipe nem sempre conseguiu articular claramente o que precisa do serviço, e muitas vezes o momento da verdade nasceu no momento da criação de protótipos de uma história no circuito de def. E enquanto chegava ao baile, poderia haver vários ciclos.AC: - Essa é a própria turbulência que foi anunciada no início.SC: - Próximo ...Havia um prazo proibitivo, porque mesmo no momento do lançamento, mais de cinco equipes dependiam de nós. Clássicos do gênero: o resultado foi necessário ontem. A opção de trabalho está no modo cavalo escaldado, que foi o que fizemos.O terceiro é uma grande quantidade de desenvolvimento. Nastya, em seu slide, mostrou que, quando analisamos os requisitos do que e como fazer, percebemos: 1 objeto requer sete APIs (para isso ou participação em sete APIs). Isso significa que se tivermos um patch (6 objetos, modelo, 42 API) ocorre em uma semana ...
Em primeiro lugar, isso é uma incerteza de requisitos. Nem toda equipe nem sempre conseguiu articular claramente o que precisa do serviço, e muitas vezes o momento da verdade nasceu no momento da criação de protótipos de uma história no circuito de def. E enquanto chegava ao baile, poderia haver vários ciclos.AC: - Essa é a própria turbulência que foi anunciada no início.SC: - Próximo ...Havia um prazo proibitivo, porque mesmo no momento do lançamento, mais de cinco equipes dependiam de nós. Clássicos do gênero: o resultado foi necessário ontem. A opção de trabalho está no modo cavalo escaldado, que foi o que fizemos.O terceiro é uma grande quantidade de desenvolvimento. Nastya, em seu slide, mostrou que, quando analisamos os requisitos do que e como fazer, percebemos: 1 objeto requer sete APIs (para isso ou participação em sete APIs). Isso significa que se tivermos um patch (6 objetos, modelo, 42 API) ocorre em uma semana ...Abordagem padrão
AC: - Sim, na verdade 42 APIs por semana é apenas a ponta do iceberg. Estamos cientes de que, para garantir que essas 42 APIs funcionem, precisamos:- primeiro, crie uma estrutura de armazenamento para o objeto;
- segundo, garantir a lógica de seu processamento;
- em terceiro lugar, escreva a própria API da qual o objeto participa (ou é configurado especificamente para ele);
- quarto, seria bom cobrir tudo isso idealmente com os contornos dos testes, testar e dizer que está tudo bem;
- quinto (a mesma cereja no bolo), para documentar toda essa história.
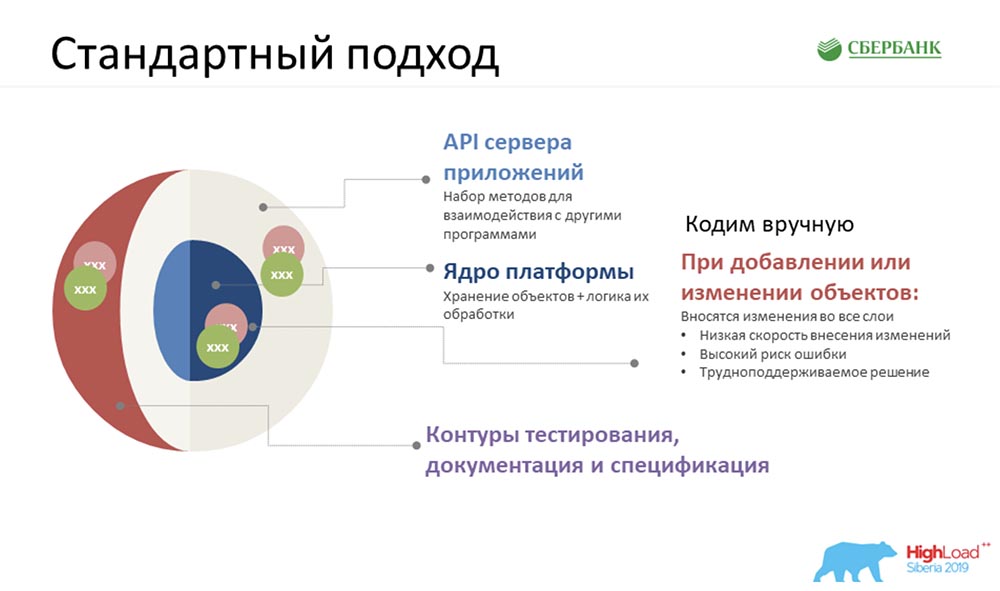 Naturalmente, a primeira coisa que nos ocorreu (no início, mostramos um diagrama aproximado) - tínhamos cerca de 35 objetos. Algo tinha que ser feito com eles, tudo isso tinha que ser deduzido, e havia muito pouco tempo. E a primeira ideia que nos ocorreu foi sentar, arregaçar as mangas e começar a codificar.Mesmo depois de trabalhar nesse modo por alguns dias (tínhamos três equipes), atingimos uma temperatura tão brilhante ... Todo mundo estava nervoso ... E percebemos que precisávamos procurar uma abordagem diferente.
Naturalmente, a primeira coisa que nos ocorreu (no início, mostramos um diagrama aproximado) - tínhamos cerca de 35 objetos. Algo tinha que ser feito com eles, tudo isso tinha que ser deduzido, e havia muito pouco tempo. E a primeira ideia que nos ocorreu foi sentar, arregaçar as mangas e começar a codificar.Mesmo depois de trabalhar nesse modo por alguns dias (tínhamos três equipes), atingimos uma temperatura tão brilhante ... Todo mundo estava nervoso ... E percebemos que precisávamos procurar uma abordagem diferente.Abordagem personalizada
Começamos a prestar atenção ao que estamos fazendo. A idéia dessa abordagem sempre esteve diante de nossos olhos, porque estamos envolvidos em metadados há muito tempo. De alguma forma, imediatamente, isso não ocorreu a nós ...Como você pode imaginar, a essência dessa idéia é usar metadados. Consiste no fato de coletarmos a estrutura de nosso repositório (são certos metadados), uma vez que criamos um modelo para algum código (por exemplo, várias APIs ou procedimentos para processar lógica, scripts para criar estruturas). Depois de criarmos esse modelo, e executarmos todos os metadados. Por tags, as propriedades são substituídas no código (nomes de objetos, campos, características importantes) e o código resultante está pronto. Ou seja, basta ficar confuso uma vez - crie um modelo e use todas essas informações para objetos existentes e novos. Aqui apresentamos outro conceito - #META_META. Vou explicar o porquê, para não confundir você.Nosso sistema está envolvido no gerenciamento de metadados, e a abordagem que usamos descreve um sistema de gerenciamento de metadados, ou seja, duas metas. “MetaMeta” - chamamos em casa, dentro da equipe. Para não confundir ainda mais os outros, usaremos esse mesmo termo.
Ou seja, basta ficar confuso uma vez - crie um modelo e use todas essas informações para objetos existentes e novos. Aqui apresentamos outro conceito - #META_META. Vou explicar o porquê, para não confundir você.Nosso sistema está envolvido no gerenciamento de metadados, e a abordagem que usamos descreve um sistema de gerenciamento de metadados, ou seja, duas metas. “MetaMeta” - chamamos em casa, dentro da equipe. Para não confundir ainda mais os outros, usaremos esse mesmo termo.Mecanismo para garantir a historização e revisão
SC: - Você resumiu o resto do nosso discurso. Vamos contar com mais detalhes.Devo dizer que quando estávamos nos preparando para o discurso, fomos solicitados a fornecer informações técnicas que poderiam interessar aos colegas. Nós faremos. Além disso, os slides serão mais técnicos - talvez alguém veja algo interessante por si.Primeiro, como resolvemos a questão da historização e revisão. Talvez isso seja semelhante a quantos. Considere isso usando metadados como exemplo, que descrevem um único campo na tabela de lançamentos (como exemplo):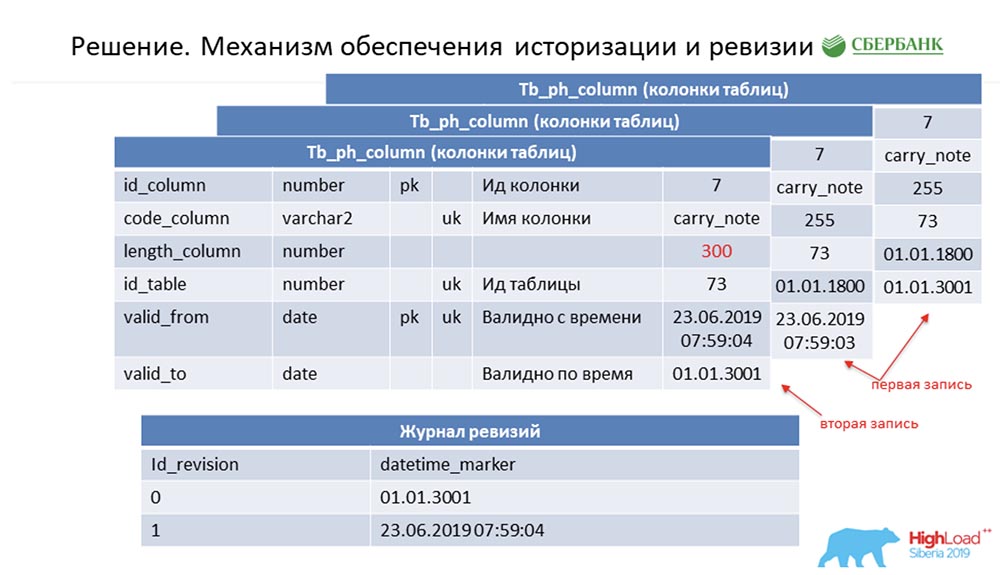 Ele possui um id - "7", um nome - carry_note, um link id_table 73 e um campo - 255. Entramos na chave primária e alternativa um campo (do tipo data) a partir do momento em que essa entrada se torna válida - valid_from. E mais um campo - em que data esse registro é válido (valid_to). Nesse caso, eles são preenchidos por padrão - é claro que essa entrada é sempre válida em princípio. E isso acontece até que desejemos alterar, digamos, o comprimento do campo.Assim que queremos fazer isso, fechamos o registro valid_to (fixamos o carimbo de data e hora em que o evento ocorreu). Ao mesmo tempo, fazemos um novo registro ("300"). É fácil perceber que, nessa situação, se você observar o banco de dados a partir de algum ponto da “batalha” (entre) entre valid_from e valid_to, obteremos um único registro, mas relevante naquele momento. E, ao mesmo tempo, mantivemos simultaneamente algum log de revisão:
Ele possui um id - "7", um nome - carry_note, um link id_table 73 e um campo - 255. Entramos na chave primária e alternativa um campo (do tipo data) a partir do momento em que essa entrada se torna válida - valid_from. E mais um campo - em que data esse registro é válido (valid_to). Nesse caso, eles são preenchidos por padrão - é claro que essa entrada é sempre válida em princípio. E isso acontece até que desejemos alterar, digamos, o comprimento do campo.Assim que queremos fazer isso, fechamos o registro valid_to (fixamos o carimbo de data e hora em que o evento ocorreu). Ao mesmo tempo, fazemos um novo registro ("300"). É fácil perceber que, nessa situação, se você observar o banco de dados a partir de algum ponto da “batalha” (entre) entre valid_from e valid_to, obteremos um único registro, mas relevante naquele momento. E, ao mesmo tempo, mantivemos simultaneamente algum log de revisão: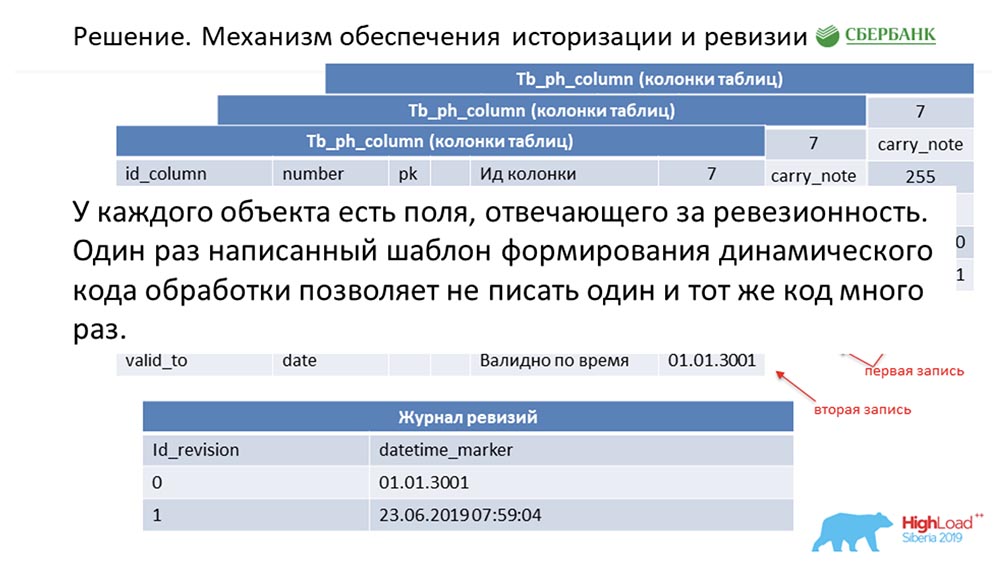 nele, registramos as revisões que estão aumentando no ID de sequência (sequência) e o ponto no tempo que corresponde a esse ID de revisão. Então, conseguimos fechar a primeira demanda.AC:- Eu acho que sim! Aqui a abordagem é a mesma. Entendemos que cada objeto no sistema possui esses dois campos obrigatórios e, quando nos confundimos - codificamos a lógica de processamento desse modelo e, em seguida (ao gerar o código dinâmico), simplesmente substituímos os nomes dos objetos correspondentes. Portanto, todo objeto em nosso sistema se torna revisão e tudo isso pode ser processado - geralmente não escrevemos uma única linha de código.
nele, registramos as revisões que estão aumentando no ID de sequência (sequência) e o ponto no tempo que corresponde a esse ID de revisão. Então, conseguimos fechar a primeira demanda.AC:- Eu acho que sim! Aqui a abordagem é a mesma. Entendemos que cada objeto no sistema possui esses dois campos obrigatórios e, quando nos confundimos - codificamos a lógica de processamento desse modelo e, em seguida (ao gerar o código dinâmico), simplesmente substituímos os nomes dos objetos correspondentes. Portanto, todo objeto em nosso sistema se torna revisão e tudo isso pode ser processado - geralmente não escrevemos uma única linha de código.Atualização em lote
SC: - O segundo requisito para mim foi um pouco mais interessante. Honestamente, quando se tratava da entrada, eu entrei em um estupor. Mas a decisão chegou!Lembro que este é o mesmo caso quando, digamos, o JSON com um pacote chegou até o enésimo número de objetos que precisam ser inseridos no sistema. Ao mesmo tempo, no início, temos 10 colunas referentes a uma tabela inexistente, e a tabela foi na cauda do JSON. O que fazer? Descobrimos uma maneira de usar o mecanismo de consultas hierárquicas recursivas - isso é com certeza a conexão bem conhecida por construção anterior. Fizemos o seguinte: aqui está um fragmento do nosso código de produção:
Descobrimos uma maneira de usar o mecanismo de consultas hierárquicas recursivas - isso é com certeza a conexão bem conhecida por construção anterior. Fizemos o seguinte: aqui está um fragmento do nosso código de produção: Neste ponto (uma seção de código circulada em um oval vermelho) é o ponto principal que dá uma idéia. E aqui o objeto está vinculado a outro objeto vinculado por uma chave estrangeira, que está no sistema.Para entender: se alguém escreve código no Oracle, existem All_columns, All_all_ tables, All_constraint tables - este é o dicionário que é processado pelos scripts (como os mostrados no slide acima).Na saída, obtemos campos que nos dão a prioridade de processar objetos e, adicionalmente, fornecem um descritor - é essencialmente um identificador de string exclusivo para qualquer registro de metadados. O código pelo qual o descritor é recebido também é indicado no slide acima.Por exemplo, um campo - como poderia ser? Este é o código da plataforma: oracle KP., Production. KP, meu_sistema, KP, minha_tabela. KP, etc., onde KP é o código do campo. Portanto, haverá um descritor.AC: - Quais são os problemas aqui? Temos objetos no sistema e a ordem de inserção deles é muito importante para nós. Por exemplo, não podemos inserir colunas na frente das tabelas, porque uma coluna deve se referir a uma tabela específica. Como fazemos como padrão: primeiro, inserimos as tabelas; em resposta, obtemos uma matriz de id; por esses IDs, lançamos as colunas e fazemos a segunda operação de inserção.Na realidade, como Stas mostrou, o comprimento dessa cadeia atinge 8-9 objetos. O usuário, usando a abordagem padrão, precisa executar todas essas operações sucessivamente (todas essas 9 operações) e entender claramente sua ordem para que nenhum erro ocorra.Tanto quanto interpreto corretamente o Stas, podemos transferir todos esses objetos para o sistema em qualquer ordem e não nos preocupamos com como precisamos inserir isso - apenas jogamos um conjunto de sopa no sistema e tudo determinou em qual ordem inserir.A única coisa que tenho é a pergunta: e se inserirmos o objeto pela primeira vez? Nós inserimos a tabela antes, não sabemos o seu ID. Como indicamos (um exemplo puramente hipotético) que precisamos inserir duas tabelas, cada uma das quais com uma coluna? Como indicamos que nesta coluna JSON se refere à tabela1, não à tabela2?SC: - Um descritor! A alça que indicamos nesse slide (anterior).E neste slide, a própria solução é fornecida:
Neste ponto (uma seção de código circulada em um oval vermelho) é o ponto principal que dá uma idéia. E aqui o objeto está vinculado a outro objeto vinculado por uma chave estrangeira, que está no sistema.Para entender: se alguém escreve código no Oracle, existem All_columns, All_all_ tables, All_constraint tables - este é o dicionário que é processado pelos scripts (como os mostrados no slide acima).Na saída, obtemos campos que nos dão a prioridade de processar objetos e, adicionalmente, fornecem um descritor - é essencialmente um identificador de string exclusivo para qualquer registro de metadados. O código pelo qual o descritor é recebido também é indicado no slide acima.Por exemplo, um campo - como poderia ser? Este é o código da plataforma: oracle KP., Production. KP, meu_sistema, KP, minha_tabela. KP, etc., onde KP é o código do campo. Portanto, haverá um descritor.AC: - Quais são os problemas aqui? Temos objetos no sistema e a ordem de inserção deles é muito importante para nós. Por exemplo, não podemos inserir colunas na frente das tabelas, porque uma coluna deve se referir a uma tabela específica. Como fazemos como padrão: primeiro, inserimos as tabelas; em resposta, obtemos uma matriz de id; por esses IDs, lançamos as colunas e fazemos a segunda operação de inserção.Na realidade, como Stas mostrou, o comprimento dessa cadeia atinge 8-9 objetos. O usuário, usando a abordagem padrão, precisa executar todas essas operações sucessivamente (todas essas 9 operações) e entender claramente sua ordem para que nenhum erro ocorra.Tanto quanto interpreto corretamente o Stas, podemos transferir todos esses objetos para o sistema em qualquer ordem e não nos preocupamos com como precisamos inserir isso - apenas jogamos um conjunto de sopa no sistema e tudo determinou em qual ordem inserir.A única coisa que tenho é a pergunta: e se inserirmos o objeto pela primeira vez? Nós inserimos a tabela antes, não sabemos o seu ID. Como indicamos (um exemplo puramente hipotético) que precisamos inserir duas tabelas, cada uma das quais com uma coluna? Como indicamos que nesta coluna JSON se refere à tabela1, não à tabela2?SC: - Um descritor! A alça que indicamos nesse slide (anterior).E neste slide, a própria solução é fornecida: Os descritores são usados no sistema como um tipo de campo mnemônico que não existe, mas substitui o id. Nesse momento, quando, a princípio, o sistema entender que é necessário inserir a tabela - insert, ele receberá o id; e já no estágio de geração da consulta SQL para a inserção e a coluna, ela operará no id. O usuário não pode tomar um banho de vapor: “Dê o cabo e execute!”. O sistema funcionará.
Os descritores são usados no sistema como um tipo de campo mnemônico que não existe, mas substitui o id. Nesse momento, quando, a princípio, o sistema entender que é necessário inserir a tabela - insert, ele receberá o id; e já no estágio de geração da consulta SQL para a inserção e a coluna, ela operará no id. O usuário não pode tomar um banho de vapor: “Dê o cabo e execute!”. O sistema funcionará.Consulta universal em um grupo de objetos relacionados
Talvez o meu caso favorito. Esse é o requisito técnico favorito que tínhamos. Eles vieram até nós e disseram: “Gente, faça isso para que o sistema possa fazer tudo! De objeto para objeto, por favor. Adivinhe como tudo se junta entre si. Devolva-nos, JSON, por favor. Não queremos programar muito usando o seu serviço "...Pergunta:" Como?! "Na verdade, seguimos o mesmo caminho. Exatamente a mesma construção: foi usada para resolver esse problema. A única diferença é que havia um filtro válido, que desenrolou essa árvore hierárquica apenas para as histórias em que um descritor era necessário. Relativamente falando, era único para cada objeto. Aqui, todas as conexões possíveis no sistema não são torcidas (temos cerca de 50 objetos).Todas as conexões possíveis entre objetos são preparadas com antecedência. Se tivermos um objeto envolvido em três relacionamentos, respectivamente, três linhas serão preparadas para que o algoritmo possa entender. E assim que a solicitação do JSON chega até nós, vamos ao local onde essa história foi preparada com antecedência no MeteMet, e estamos procurando o caminho que precisamos. Se não encontrarmos, esta é uma história; se a encontrarmos, formamos uma consulta no banco de dados. Em execução - retornando JSON (conforme solicitado).AC: - Como resultado, podemos transferir para o sistema o objeto que queremos receber. E se você puder delinear uma conexão clara entre dois objetos, o próprio sistema descobrirá qual nível de aninhamento do objeto retornará para você na árvore:É muito flexível! Mais uma vez, nossos usuários estão em um estado de "turbulência": hoje eles precisam de uma coisa, amanhã precisam de outra. E essa solução nos permite adaptar a estrutura de maneira muito flexível. Esses foram três casos principais que foram usados em nosso núcleo.SC: - Vamos resumir alguns. É claro que agora não contaremos todas as fichas por causa do tempo limitado. Três casos, em nossa opinião, realizamos e contamos. Fomos bem-sucedidos, conseguimos colocar toda a lógica mais complexa e a que deveria funcionar de maneira uniforme para cada objeto de gerenciamento de metadados no código do kernel.Não foi possível tornar esse código 100% dinâmico, o que significa que, com quaisquer objetos criados (não importa se eles já foram criados ou que serão criados posteriormente; o principal é ser criado de acordo com as regras), o sistema pode funcionar - nada precisa ser adicionado, reescrito. Apenas testar é suficiente. Estacionamos toda essa história em três métodos universais. Na minha opinião, existem o suficiente para resolver praticamente qualquer problema de negócios:
foi usada para resolver esse problema. A única diferença é que havia um filtro válido, que desenrolou essa árvore hierárquica apenas para as histórias em que um descritor era necessário. Relativamente falando, era único para cada objeto. Aqui, todas as conexões possíveis no sistema não são torcidas (temos cerca de 50 objetos).Todas as conexões possíveis entre objetos são preparadas com antecedência. Se tivermos um objeto envolvido em três relacionamentos, respectivamente, três linhas serão preparadas para que o algoritmo possa entender. E assim que a solicitação do JSON chega até nós, vamos ao local onde essa história foi preparada com antecedência no MeteMet, e estamos procurando o caminho que precisamos. Se não encontrarmos, esta é uma história; se a encontrarmos, formamos uma consulta no banco de dados. Em execução - retornando JSON (conforme solicitado).AC: - Como resultado, podemos transferir para o sistema o objeto que queremos receber. E se você puder delinear uma conexão clara entre dois objetos, o próprio sistema descobrirá qual nível de aninhamento do objeto retornará para você na árvore:É muito flexível! Mais uma vez, nossos usuários estão em um estado de "turbulência": hoje eles precisam de uma coisa, amanhã precisam de outra. E essa solução nos permite adaptar a estrutura de maneira muito flexível. Esses foram três casos principais que foram usados em nosso núcleo.SC: - Vamos resumir alguns. É claro que agora não contaremos todas as fichas por causa do tempo limitado. Três casos, em nossa opinião, realizamos e contamos. Fomos bem-sucedidos, conseguimos colocar toda a lógica mais complexa e a que deveria funcionar de maneira uniforme para cada objeto de gerenciamento de metadados no código do kernel.Não foi possível tornar esse código 100% dinâmico, o que significa que, com quaisquer objetos criados (não importa se eles já foram criados ou que serão criados posteriormente; o principal é ser criado de acordo com as regras), o sistema pode funcionar - nada precisa ser adicionado, reescrito. Apenas testar é suficiente. Estacionamos toda essa história em três métodos universais. Na minha opinião, existem o suficiente para resolver praticamente qualquer problema de negócios:- primeiro, esse mesmo “atualizador” universal é um método que pode atualizar / inserir / excluir (excluir está fechando um registro) em um ou em um grupo de objetos transferidos em ordem aleatória.
- o segundo é um método que pode retornar informações universais em apenas um objeto;
- o terceiro é o mesmo método que pode retornar informações de associação conectadas por grupos de objetos.
Foi assim que aconteceu, e criamos o núcleo. E então passaremos para a sua parte favorita.Ponto de entrada do aplicativo
AC: - Sim, esta é a minha parte favorita, porque esta é minha área de responsabilidade - Application Server. Para entender em que situação eu estava, tentarei mergulhá-lo em um problema novamente.Stas fez um bom trabalho e me passou esses três métodos padrão que manipularam esses objetos. Esta é uma descrição puramente superficial - na realidade, existem muitas mais: Vamos voltar ao começo para imergir você ... Como os metadados no sistema serão apresentados aqui?
Vamos voltar ao começo para imergir você ... Como os metadados no sistema serão apresentados aqui?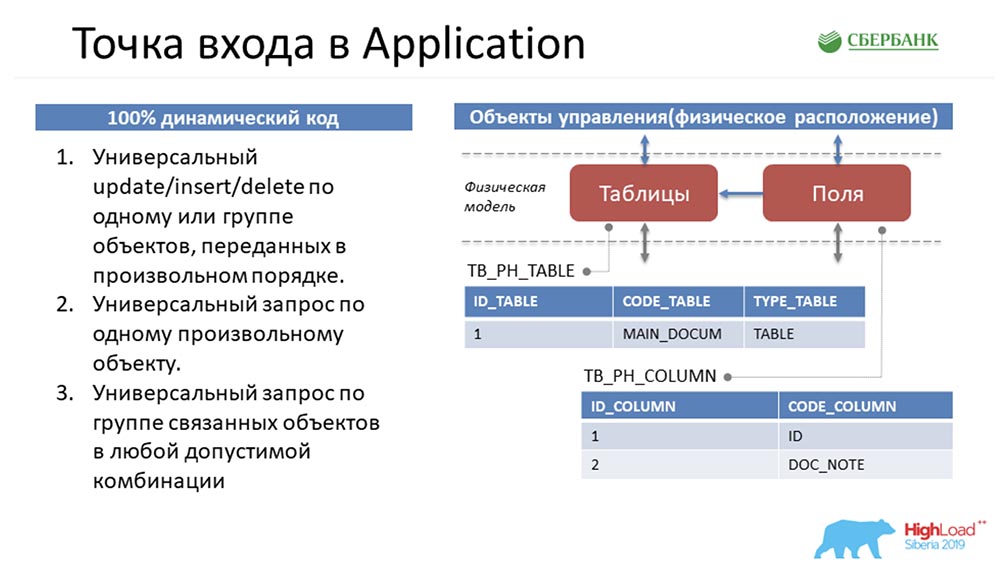 Se percebermos que há uma tabela no ambiente, ela cairá em nosso sistema como um registro no objeto de tabela e alguns registros no objeto de campo. Essencialmente, reunimos uma estrutura.Podemos notar que a quantidade desses objetos é diferente. Então, para manipular esses objetos, trazer tudo a uma estrutura universal, para que todos os três métodos entendam o que está sendo discutido, Stas faz um movimento com o cavalo. Ele pega e vira todos os objetos, ou seja, representa qualquer objeto em nosso sistema de gerenciamento de metadados como quatro linhas:
Se percebermos que há uma tabela no ambiente, ela cairá em nosso sistema como um registro no objeto de tabela e alguns registros no objeto de campo. Essencialmente, reunimos uma estrutura.Podemos notar que a quantidade desses objetos é diferente. Então, para manipular esses objetos, trazer tudo a uma estrutura universal, para que todos os três métodos entendam o que está sendo discutido, Stas faz um movimento com o cavalo. Ele pega e vira todos os objetos, ou seja, representa qualquer objeto em nosso sistema de gerenciamento de metadados como quatro linhas: Como qualquer objeto em nosso sistema de gerenciamento de metadados é fisicamente uma tabela, qualquer objeto pode ser decomposto de acordo com esses quatro sinais: número da linha , tabela, campo e valor do campo. Foi Stas quem apresentou tudo isso, e eu precisava implementá-lo de alguma forma e entregá-lo aos usuários.SC:- Desculpe, mas como posso transmitir a você em uma coluna de respostas simples, por exemplo, que ainda não foram criadas, será criada em algum momento e Deus sabe o que elas podem ser? .. Portanto, a única opção nas condições do código dinâmico é configurar a interação entre núcleo e aplicativo, para transmitir essas informações a você - apenas como as vemos. Acredito que, do meu ponto de vista, essa decisão foi engenhosa, porque veio apenas de você.AC: - Agora não discutiremos sobre isso. Duas semanas antes do final do prazo, fiquei com o fato de ter esses três métodos em mãos (à esquerda no slide anterior) que manipularam a estrutura universal (à direita no mesmo slide).Meu primeiro pensamento foi simplesmente encerrar tudo no nível da API e ir até o usuário com isso, dizendo: “Olha, que coisa brilhante! Você pode fazer qualquer coisa! Transfira quaisquer objetos, ou mesmo objetos inexistentes. Legal, sim "?!
Como qualquer objeto em nosso sistema de gerenciamento de metadados é fisicamente uma tabela, qualquer objeto pode ser decomposto de acordo com esses quatro sinais: número da linha , tabela, campo e valor do campo. Foi Stas quem apresentou tudo isso, e eu precisava implementá-lo de alguma forma e entregá-lo aos usuários.SC:- Desculpe, mas como posso transmitir a você em uma coluna de respostas simples, por exemplo, que ainda não foram criadas, será criada em algum momento e Deus sabe o que elas podem ser? .. Portanto, a única opção nas condições do código dinâmico é configurar a interação entre núcleo e aplicativo, para transmitir essas informações a você - apenas como as vemos. Acredito que, do meu ponto de vista, essa decisão foi engenhosa, porque veio apenas de você.AC: - Agora não discutiremos sobre isso. Duas semanas antes do final do prazo, fiquei com o fato de ter esses três métodos em mãos (à esquerda no slide anterior) que manipularam a estrutura universal (à direita no mesmo slide).Meu primeiro pensamento foi simplesmente encerrar tudo no nível da API e ir até o usuário com isso, dizendo: “Olha, que coisa brilhante! Você pode fazer qualquer coisa! Transfira quaisquer objetos, ou mesmo objetos inexistentes. Legal, sim "?! E eles dizem: “Mas você entende que seu serviço não é de todo especializado? Como usuário, não entendo quais objetos posso transferir para o sistema, como posso manipulá-los ... Para mim, é uma caixa preta, geralmente tenho medo de enviar dados; Eu posso estar enganado - estou com medo. Faça com que eu possa seguir claramente as instruções e ver quais objetos estão no sistema e quais métodos de manipulação posso usar. ”
E eles dizem: “Mas você entende que seu serviço não é de todo especializado? Como usuário, não entendo quais objetos posso transferir para o sistema, como posso manipulá-los ... Para mim, é uma caixa preta, geralmente tenho medo de enviar dados; Eu posso estar enganado - estou com medo. Faça com que eu possa seguir claramente as instruções e ver quais objetos estão no sistema e quais métodos de manipulação posso usar. ”Speck. Uma abordagem
Então ficou claro para nós que era legal fazer uma especificação para o nosso serviço. Em resumo, fazer uma lista de objetos do nosso sistema, uma lista de pontos, manipulações e quais objetos eles manipulam. Aconteceu que em nossa empresa usamos o Swagger para esses fins como algum tipo de solução arquitetural. Tendo examinado a estrutura do Swagger, percebi que precisava levar para algum lugar a estrutura dos objetos que estão no sistema. Do kernel, recebi apenas três métodos padrão e um trocador de tabelas. Nada mais. Para mim, parecia uma tarefa impossível obter toda a estrutura que está no repositório desses quatro campos padrão. Sinceramente, não entendi onde me conseguir todas as descrições de objetos, todos os valores permitidos, toda a lógica ...SC:- O que significa onde? Você e eu temos o MetaMeta, que fornece o kernel no modo em tempo real. O kernel na execução em tempo real gera uma consulta SQL que se comunica com o banco de dados. Tudo está lá, não apenas o que você precisa. Também há links entre objetos.AC: - Seguindo o conselho da Stas, fui ao MetaMetu e fiquei surpreso, porque todo o kit de cavalheiros necessário para gerar especificações padrão estava presente lá. Então surgiu a ideia de que você precisa criar um modelo e pintar tudo de acordo com sete cenários possíveis - 7 APIs padrão para cada objeto.
Tendo examinado a estrutura do Swagger, percebi que precisava levar para algum lugar a estrutura dos objetos que estão no sistema. Do kernel, recebi apenas três métodos padrão e um trocador de tabelas. Nada mais. Para mim, parecia uma tarefa impossível obter toda a estrutura que está no repositório desses quatro campos padrão. Sinceramente, não entendi onde me conseguir todas as descrições de objetos, todos os valores permitidos, toda a lógica ...SC:- O que significa onde? Você e eu temos o MetaMeta, que fornece o kernel no modo em tempo real. O kernel na execução em tempo real gera uma consulta SQL que se comunica com o banco de dados. Tudo está lá, não apenas o que você precisa. Também há links entre objetos.AC: - Seguindo o conselho da Stas, fui ao MetaMetu e fiquei surpreso, porque todo o kit de cavalheiros necessário para gerar especificações padrão estava presente lá. Então surgiu a ideia de que você precisa criar um modelo e pintar tudo de acordo com sete cenários possíveis - 7 APIs padrão para cada objeto.Speck. OEA + Guidão
Portanto, é fácil perceber em que consiste a especificação: você pode acessar o site da OEA e do guidão (na parte inferior do slide) e ver o que deve consistir - há um conjunto de pontos finais, um conjunto de métodos e, no final, existem modelos. O código é repetido de tempos em tempos. Para cada objeto, devemos escrever get, put. excluir; para um grupo de objetos, devemos escrever isso e assim por diante.O truque era escrever a história toda uma vez e não tomar banho. O slide mostra um exemplo de código real. Objetos azuis são tags no guidão, este é um mecanismo de modelo; bastante flexível, eu aconselho a todos - você pode personalizá-lo, escrever manipuladores de tags personalizados ...No lugar dessas tags azuis, quando esse modelo é executado sobre todos os metadados, todas as propriedades significativas são substituídas - o nome do objeto, sua descrição, algum tipo de lógica (por exemplo, que precisamos adicionar um parâmetro adicional, dependendo da propriedade) e assim por diante. No final, há um link para o modelo que ele está interpretando.
você pode acessar o site da OEA e do guidão (na parte inferior do slide) e ver o que deve consistir - há um conjunto de pontos finais, um conjunto de métodos e, no final, existem modelos. O código é repetido de tempos em tempos. Para cada objeto, devemos escrever get, put. excluir; para um grupo de objetos, devemos escrever isso e assim por diante.O truque era escrever a história toda uma vez e não tomar banho. O slide mostra um exemplo de código real. Objetos azuis são tags no guidão, este é um mecanismo de modelo; bastante flexível, eu aconselho a todos - você pode personalizá-lo, escrever manipuladores de tags personalizados ...No lugar dessas tags azuis, quando esse modelo é executado sobre todos os metadados, todas as propriedades significativas são substituídas - o nome do objeto, sua descrição, algum tipo de lógica (por exemplo, que precisamos adicionar um parâmetro adicional, dependendo da propriedade) e assim por diante. No final, há um link para o modelo que ele está interpretando.Código do aplicativo. Swagger Codegen + Guiador
Tudo isso que codificamos, gravamos e criamos uma especificação. Tudo foi muito legal e bom. Temos todos os 7 cenários possíveis para cada objeto.Deu ao usuário. Ele disse: “Uau! Legal! Agora nós queremos usá-lo! Qual é o problema mesmo?Temos uma especificação que descreve cada método em detalhes, o que fazer com ele, quais objetos manipular. E há três métodos padrão do kernel que usam a tabela invertida descrita acima como entrada.Então você só tinha que cruzar um com o outro (agora parece fácil para mim). Ou seja, quando um usuário chama um método na interface, tivemos que encaminhar corretamente e corretamente para o kernel, transformando o modelo (onde temos belas especificações) nesses quatro campos padrão. Isso era tudo o que precisava ser feito. Para colocar tudo isso em prática, precisávamos de transformações "nominativas" ...
Para colocar tudo isso em prática, precisávamos de transformações "nominativas" ...Conversões
O Swagger inicialmente possui essa ferramenta - Swagger Codegen. Se você alguma vez entrou em especificações fabricadas, existe o botão "Gerar parte do servidor". Clique em, escolha um idioma - um projeto final é gerado para você.É gerado notavelmente: há todas as descrições de classe, todas as descrições de terminais ... - funciona. Você pode executá-lo localmente - funcionará. O problema é um: retorna stubs - cada método não é incrementado.A idéia era adicionar lógica com base nesses sete cenários no gerador de código - “estrague” um dos modelos padrão, configure você mesmo. Aqui está apenas um exemplo de código real que usamos no mecanismo de modelo e uma lista das ações que precisávamos executar para configurar este gerador de código para nós mesmos: O mais importante que eles fizeram foi conectar as bibliotecas necessárias, escrever classes para se comunicar com o kernel e interpretar (dependendo do cenário) a chamada de um ou mais métodos no lado do kernel. O modelo também foi invertido: do bonito indicado na especificação para quatro campos e depois transformado de volta.Provavelmente, o caso mais difícil aqui foi fornecer uma árvore ao usuário, porque o kernel também retorna quatro linhas para nós - vá e veja em que nível a hierarquia está. Usamos o mecanismo de relações externas, que está no IDE, ou seja, fomos ao MetaMetu, examinamos todos os caminhos de um para o outro e geramos dinamicamente uma árvore através deles. O usuário pode solicitar a qualquer objeto o que ele quiser - uma bela árvore será devolvida na saída, na qual tudo já está estruturado.SC: - Vou parar você por um segundo, porque já estou começando a me perder. Vou perguntar no estilo "Entendo isso corretamente" ...Você quer dizer que calculamos todo o código mais complicado e complexo que precisaria ser escrito para algum novo objeto. E, para economizar tempo, e não fazê-lo, conseguimos inserir tudo no kernel e tornar essa história dinâmica ... Mas essa API (como brincavam, "teimosa") é tão "qualquer coisa" que é assustador divulgá-la: com ele, você pode corromper os metadados. Isso está por um lado.Por outro lado, percebemos que não podemos nos comunicar com nossos clientes, a menos que lhes forneça uma API, que será uma projeção exclusiva dos objetos de gerenciamento de metadados incorporados ao sistema (de fato, execute um determinado contrato para o nosso serviço). Parece que tudo - nós batemos: se não houver objeto - não está lá, e quando aparece - a extensão do contrato aparece, um novo código.Parece que entramos na codificação manual evitável, mas aqui você propõe fazer esse código por botão. Novamente, conseguimos fugir da história quando precisamos escrever algo com as mãos. Isso é verdade?AC: - Sim, é mesmo. Em geral, minha idéia era começar a programar de uma vez por todas, pelo menos com a ajuda de mecanismos de modelo. Escreva o código uma vez e depois relaxe. E mesmo que um novo objeto apareça no sistema - pelo botão que iniciamos a atualização, tudo fica mais rígido, temos uma nova estrutura, novos métodos são gerados, tudo fica bem.
O mais importante que eles fizeram foi conectar as bibliotecas necessárias, escrever classes para se comunicar com o kernel e interpretar (dependendo do cenário) a chamada de um ou mais métodos no lado do kernel. O modelo também foi invertido: do bonito indicado na especificação para quatro campos e depois transformado de volta.Provavelmente, o caso mais difícil aqui foi fornecer uma árvore ao usuário, porque o kernel também retorna quatro linhas para nós - vá e veja em que nível a hierarquia está. Usamos o mecanismo de relações externas, que está no IDE, ou seja, fomos ao MetaMetu, examinamos todos os caminhos de um para o outro e geramos dinamicamente uma árvore através deles. O usuário pode solicitar a qualquer objeto o que ele quiser - uma bela árvore será devolvida na saída, na qual tudo já está estruturado.SC: - Vou parar você por um segundo, porque já estou começando a me perder. Vou perguntar no estilo "Entendo isso corretamente" ...Você quer dizer que calculamos todo o código mais complicado e complexo que precisaria ser escrito para algum novo objeto. E, para economizar tempo, e não fazê-lo, conseguimos inserir tudo no kernel e tornar essa história dinâmica ... Mas essa API (como brincavam, "teimosa") é tão "qualquer coisa" que é assustador divulgá-la: com ele, você pode corromper os metadados. Isso está por um lado.Por outro lado, percebemos que não podemos nos comunicar com nossos clientes, a menos que lhes forneça uma API, que será uma projeção exclusiva dos objetos de gerenciamento de metadados incorporados ao sistema (de fato, execute um determinado contrato para o nosso serviço). Parece que tudo - nós batemos: se não houver objeto - não está lá, e quando aparece - a extensão do contrato aparece, um novo código.Parece que entramos na codificação manual evitável, mas aqui você propõe fazer esse código por botão. Novamente, conseguimos fugir da história quando precisamos escrever algo com as mãos. Isso é verdade?AC: - Sim, é mesmo. Em geral, minha idéia era começar a programar de uma vez por todas, pelo menos com a ajuda de mecanismos de modelo. Escreva o código uma vez e depois relaxe. E mesmo que um novo objeto apareça no sistema - pelo botão que iniciamos a atualização, tudo fica mais rígido, temos uma nova estrutura, novos métodos são gerados, tudo fica bem.Ajustando o MetaMeta
Para tornar nosso serviço ainda melhor, enriquecemos o MetaMeta padrão. Na entrada, tínhamos o que restava do núcleo. Também adicionamos uma descrição adicional aos objetos, os objetos são agrupados em áreas. Exibimos tudo isso nas especificações para que o usuário entenda o que ele está manipulando e com qual objeto ele está se comunicando no momento.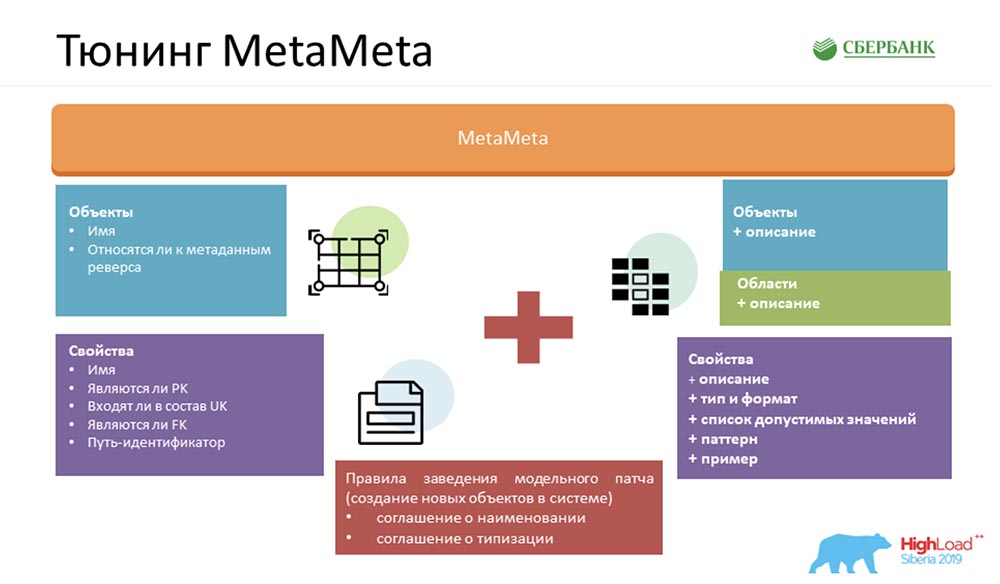 Somente adicionamos algumas coisinhas - tipos, formatos, listas de valores aceitáveis, padrões, exemplos. Isso também agrada aos usuários - eles já entendem claramente o que pode ser inserido, o que não pode. Também fornecemos um artefato de cliente ao usuário, o que nos permite detectar erros ao nos comunicar com nosso serviço (precisamente por formato, já no estágio de compilação).Mas o mais importante, para que toda essa mágica funcionasse, precisávamos concordar de dentro: criar um conjunto de certas regras. Não há muitos - contei três (há dois no slide, então um terá que ser lembrado):
Somente adicionamos algumas coisinhas - tipos, formatos, listas de valores aceitáveis, padrões, exemplos. Isso também agrada aos usuários - eles já entendem claramente o que pode ser inserido, o que não pode. Também fornecemos um artefato de cliente ao usuário, o que nos permite detectar erros ao nos comunicar com nosso serviço (precisamente por formato, já no estágio de compilação).Mas o mais importante, para que toda essa mágica funcionasse, precisávamos concordar de dentro: criar um conjunto de certas regras. Não há muitos - contei três (há dois no slide, então um terá que ser lembrado):- Convenção de nomes. Nomeamos especificamente objetos no sistema para facilitar o reconhecimento de cenários para seu uso posterior.
- Contrato de digitação. Isso é para determinar corretamente os tipos, formatos e que eles lutaram entre o kernel e o servidor de aplicativos, usamos o sistema de verificação, pelo qual entendemos a qual formato uma propriedade específica pertence.
- Chaves estrangeiras válidas. Se o objeto receber um link inválido para outro objeto, toda essa mágica funcionará incorretamente.
Resultado
SC: - É legal, mas com muita teoria. Você pode dar um exemplo prático?AC: - Sim, eu o preparei especialmente. Antes de partir para a conferência, na sexta-feira à noite, literalmente 5 minutos antes do final do dia útil, Stas me disse: “Oh, olha! Lancei um patch de modelo - que legal! Seria bom atualizar nosso serviço ". O patch continha apenas dois objetos, mas entendo que, com a abordagem antiga, eu teria que ficar confuso e escrever ou adicionar 7 APIs.Imediatamente, bastai clicar em um botão para fazer toda essa mágica funcionar. Eu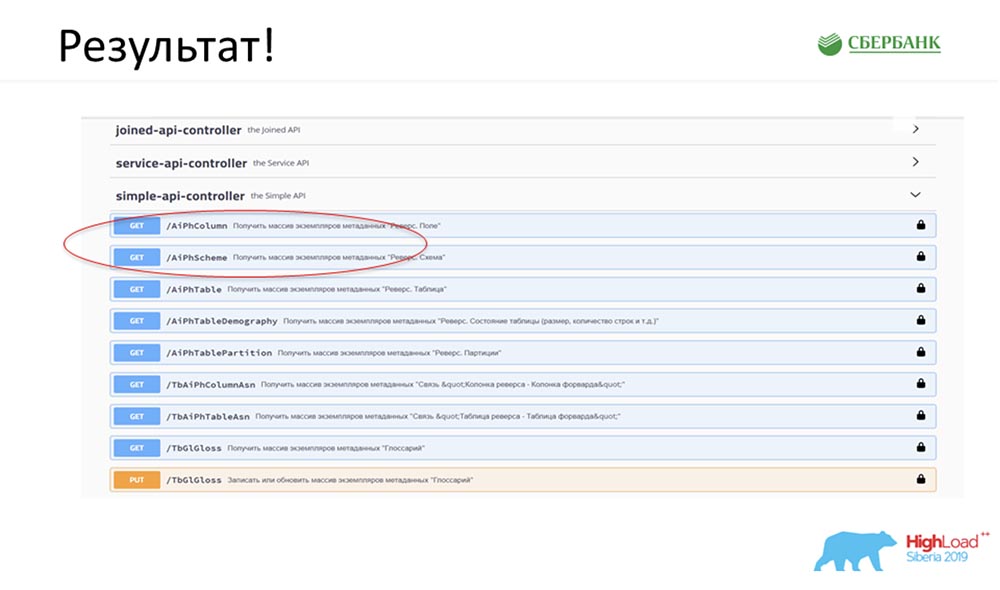 circulei especialmente em vermelho o lugar onde a mágica está prestes a acontecer: clico no botão ... Essas são, obviamente, capturas de tela, mas, na realidade, tudo funciona assim:
circulei especialmente em vermelho o lugar onde a mágica está prestes a acontecer: clico no botão ... Essas são, obviamente, capturas de tela, mas, na realidade, tudo funciona assim: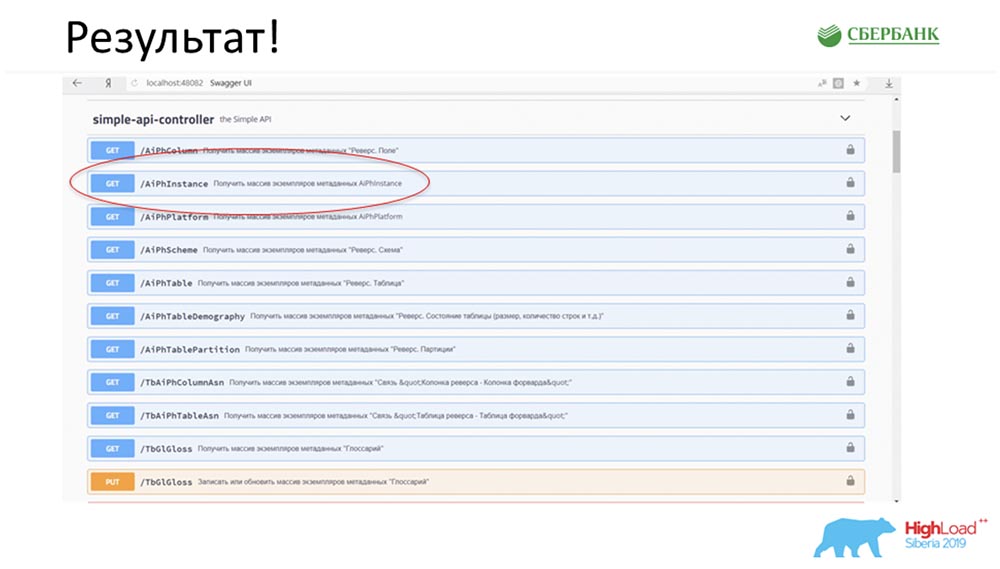 Temos um novo método (entre os dois), que já fornece dados, pelo qual nós na hierarquia podemos consultar toda a estrutura, todos os objetos aninhados:
Temos um novo método (entre os dois), que já fornece dados, pelo qual nós na hierarquia podemos consultar toda a estrutura, todos os objetos aninhados:
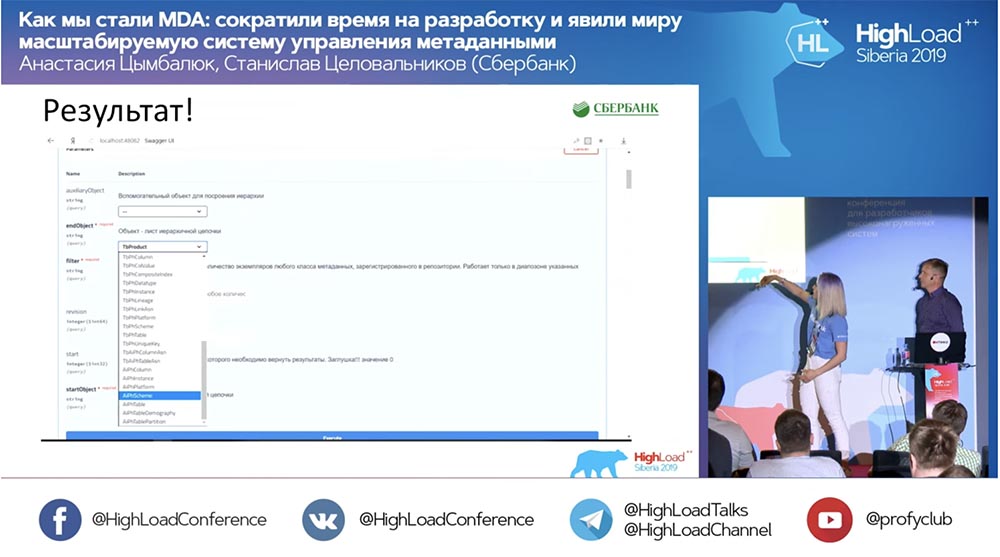
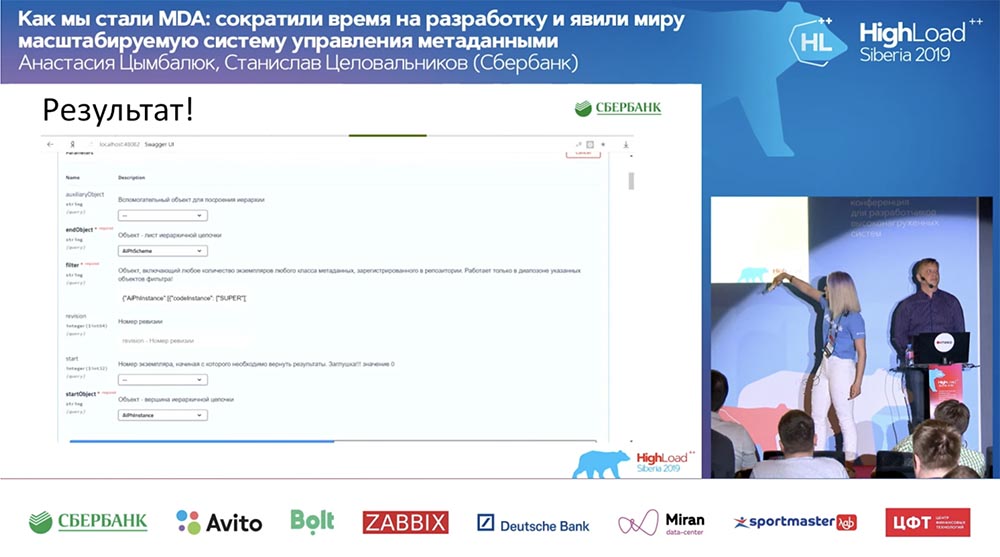 E tudo funciona! Eu não escrevi uma única linha de código.
E tudo funciona! Eu não escrevi uma única linha de código.Sumário
SC: - Em primeiro lugar, qual é o fato? Gerenciamos a lógica mais complexa, que levaria mais tempo para nossos programadores, para compilar código de kernel 100% dinâmico que pode funcionar com objetos - aqueles que são e aqueles que serão: em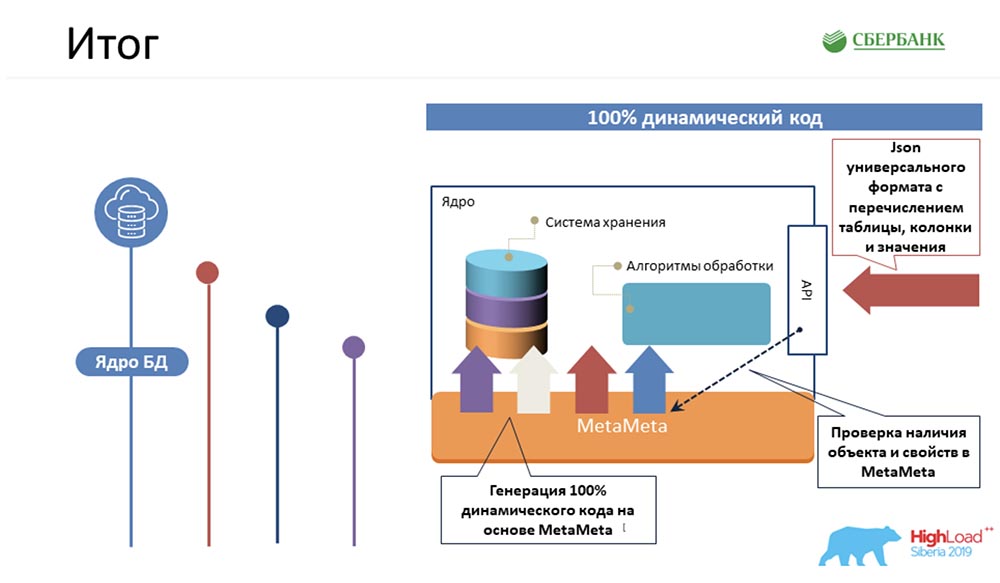 segundo lugar, obtivemos sucesso no nível do servidor de aplicativos (onde não é possível) também evitar a programação devido à geração de código - o mesmo botão que você demonstrou:
segundo lugar, obtivemos sucesso no nível do servidor de aplicativos (onde não é possível) também evitar a programação devido à geração de código - o mesmo botão que você demonstrou: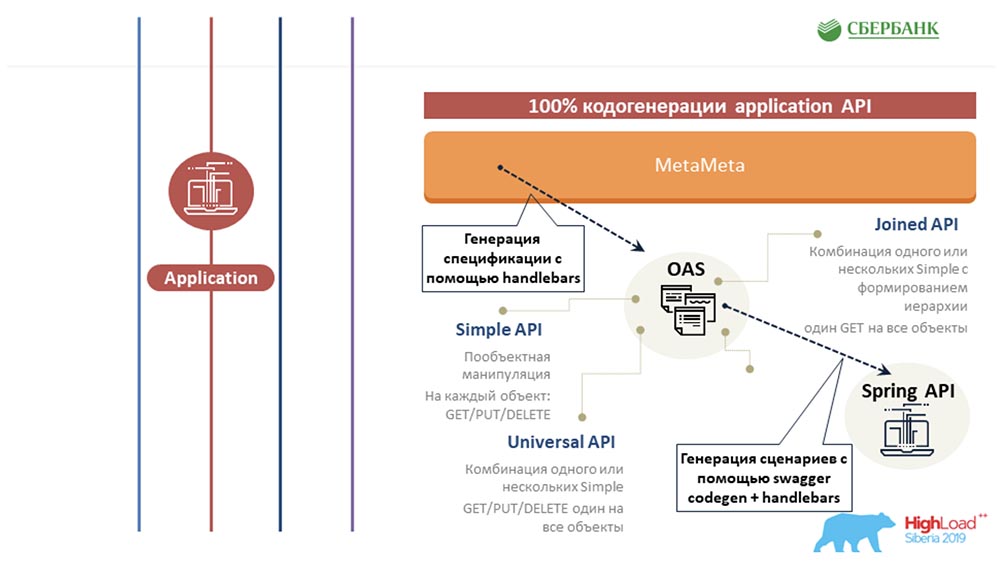 AC: - Tentamos estender a mesma abordagem com base em metadados para outras áreas, para a área de teste. Também escrevemos um modelo uma vez para algum objeto, inserimos tags lá. E quando esse modelo é executado ao longo dos metadados, ele gera uma planilha pronta com todos os cenários de teste, ou seja, de fato, cobrimos todos os objetos com testes.
AC: - Tentamos estender a mesma abordagem com base em metadados para outras áreas, para a área de teste. Também escrevemos um modelo uma vez para algum objeto, inserimos tags lá. E quando esse modelo é executado ao longo dos metadados, ele gera uma planilha pronta com todos os cenários de teste, ou seja, de fato, cobrimos todos os objetos com testes.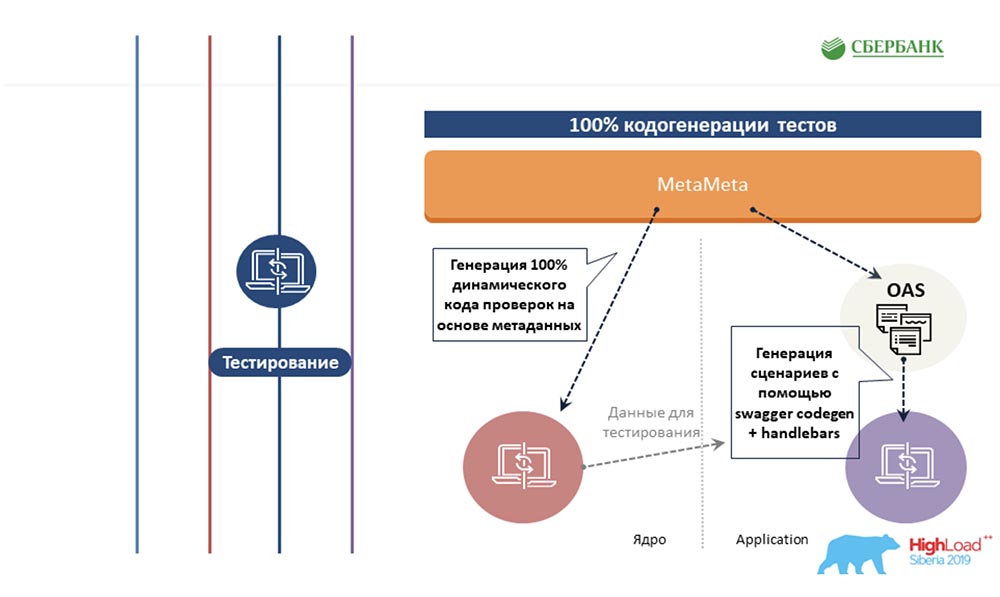 Em seguida é a cereja no bolo. Eu sei que poucas pessoas gostam de documentar o que fazem. Também resolvemos essa dor com base em metadados. Depois que preparamos um modelo com marcação html, o identificamos. E quando examinamos os metadados, todas essas tags são substituídas por suas propriedades correspondentes aos objetos.
Em seguida é a cereja no bolo. Eu sei que poucas pessoas gostam de documentar o que fazem. Também resolvemos essa dor com base em metadados. Depois que preparamos um modelo com marcação html, o identificamos. E quando examinamos os metadados, todas essas tags são substituídas por suas propriedades correspondentes aos objetos. A saída é uma linda página html finalizada. Em seguida, publicamos no Confluence e podemos fornecer aos nossos usuários um formato legível por humanos, para que eles possam ver o que temos no sistema, como trabalhar com ele, alguma descrição mínima, valores aceitáveis, propriedades necessárias, chaves ... Todos eles podem fazer isso ver e pode facilmente descobrir isso.Como resultado, temos quatro pontos principais, e essa abordagem é chamada MDA (Model Driven Architecture). Por alguma razão, isso se traduz em "arquitetura orientada a modelo", embora eu o chamasse de "método de desenvolvimento de software".
A saída é uma linda página html finalizada. Em seguida, publicamos no Confluence e podemos fornecer aos nossos usuários um formato legível por humanos, para que eles possam ver o que temos no sistema, como trabalhar com ele, alguma descrição mínima, valores aceitáveis, propriedades necessárias, chaves ... Todos eles podem fazer isso ver e pode facilmente descobrir isso.Como resultado, temos quatro pontos principais, e essa abordagem é chamada MDA (Model Driven Architecture). Por alguma razão, isso se traduz em "arquitetura orientada a modelo", embora eu o chamasse de "método de desenvolvimento de software". Qual é o ponto? Você cria um modelo, concorda em certas regras. Em seguida, você cria padrões de transformação desse modelo em alguma linguagem de programação disponível para você. Tudo isso funciona para alterar objetos antigos, para adicionar novos. Você escreve o código uma vez e não se incomoda mais.SC: - Eu sinceramente esperei o relatório inteiro quando você responder a essa pergunta. Vamos para os meus slides favoritos.
Qual é o ponto? Você cria um modelo, concorda em certas regras. Em seguida, você cria padrões de transformação desse modelo em alguma linguagem de programação disponível para você. Tudo isso funciona para alterar objetos antigos, para adicionar novos. Você escreve o código uma vez e não se incomoda mais.SC: - Eu sinceramente esperei o relatório inteiro quando você responder a essa pergunta. Vamos para os meus slides favoritos.Decisão. Processo. Antes
AC: - “O processo. Antes ”- este é o nosso orgulho, porque costumávamos programar muito, não comíamos quase nada - éramos muito maus. Eu tive que executar todas essas 5 etapas para cada objeto: ficou muito triste e levou muito tempo. Agora reduzimos essa cadeia alimentar para três elos, o mais importante dos quais é simplesmente criar o objeto corretamente, e nada mais: o
ficou muito triste e levou muito tempo. Agora reduzimos essa cadeia alimentar para três elos, o mais importante dos quais é simplesmente criar o objeto corretamente, e nada mais: o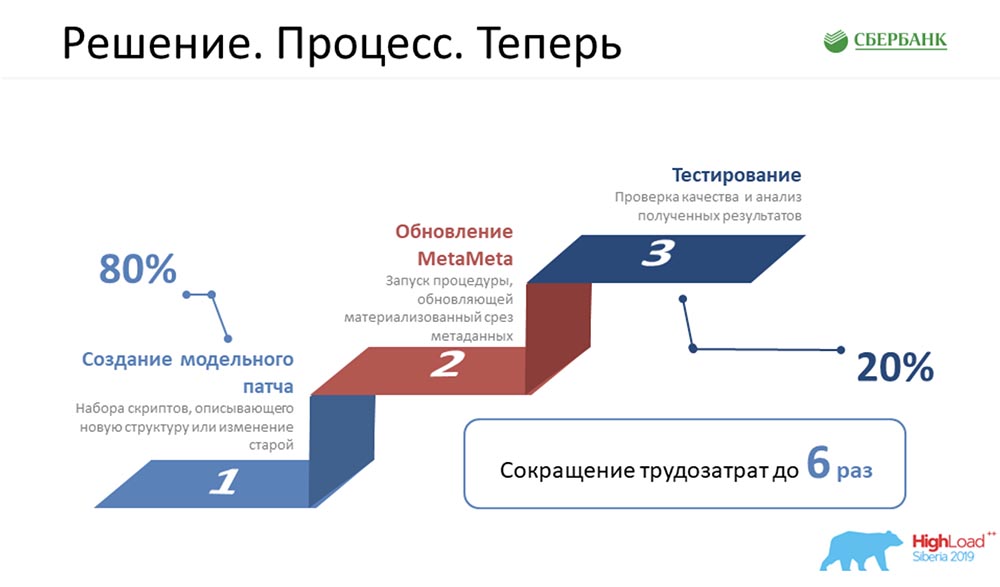 MetaMeta é iniciado por um botão (atualização) e, em seguida, pelo teste. Atualmente, estamos procurando garantir que nada caia de nós, desde que começamos a aplicar essa abordagem recentemente. Estamos tentando controlar todo esse processo.Segundo estimativas, todos os nossos custos de mão-de-obra para o desenvolvimento de todo o nosso software foram reduzidos em 6 vezes.SC:- Quero dizer sinceramente que o número 6 não é exagerado, é até conservador. De fato, a eficiência é ainda maior.
MetaMeta é iniciado por um botão (atualização) e, em seguida, pelo teste. Atualmente, estamos procurando garantir que nada caia de nós, desde que começamos a aplicar essa abordagem recentemente. Estamos tentando controlar todo esse processo.Segundo estimativas, todos os nossos custos de mão-de-obra para o desenvolvimento de todo o nosso software foram reduzidos em 6 vezes.SC:- Quero dizer sinceramente que o número 6 não é exagerado, é até conservador. De fato, a eficiência é ainda maior.Planos futuros
Você pediu no final do relatório para se concentrar em nossos planos. Antes de tudo, parece que devemos alcançar não apenas uma solução completa, mas alienada e em caixa. Essas tecnologias podem ser aplicadas em algum lugar próximo, quando apropriado. Gostaria de obter um produto acabado que será desenvolvido e que poderemos oferecer em nome do Sberbank.Obviamente, se falamos de tarefas imediatas, todas elas são exibidas nos slides com marcadores. Apesar da otimização que recebemos, a carga na equipe ainda é bastante séria. Não posso dizer com certeza de que trimestre podemos avançar para a implementação dessas etapas.Número 6 e o caso que Nastya trouxe - eles são honestos. Realmente foi na sexta-feira, quando precisávamos obter documentos (avião, viagem, etc.). A equipe adjacente estava programada para testar na segunda-feira, e precisávamos lançar esse patch, não para configurar os caras. Funcionou! Este é um caso real.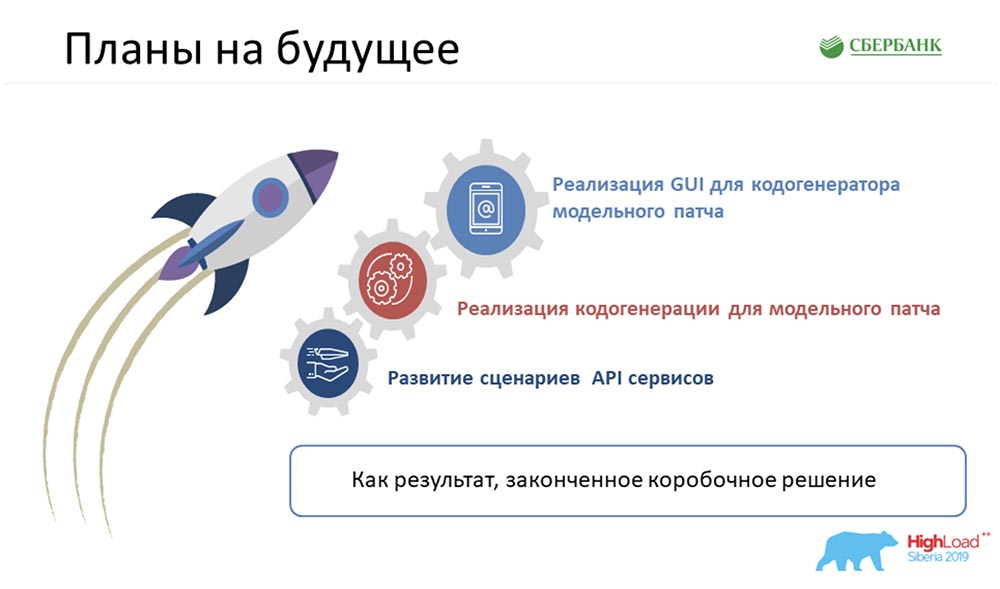 Ficaria feliz se isso pudesse ser útil para qualquer um de vocês. Se tiver mais alguma dúvida estamos à disposição. E após o relatório, também há algum tempo aqui. Peça. Teremos o maior prazer em ajudá-lo!AC:- De fato, acho que essa abordagem pode começar a ser usada por todos. Não necessariamente em nossa forma (estamos envolvidos no gerenciamento de metadados). Pode ser um sistema de controle de qualquer coisa. Tudo que você precisa ter em mãos é uma visão relacional das coisas, pegue metadados a partir daí, entenda alguns mecanismos de modelo e entenda alguma linguagem de programação (como funciona).Todas essas ferramentas são de domínio público - você já pode começar a pesquisar no Google e entender como usá-las. Estou certo de que usá-los tornará sua vida mais fácil, melhor e geralmente liberará tempo para tarefas novas, ambiciosas e interessantes. Obrigado!
Ficaria feliz se isso pudesse ser útil para qualquer um de vocês. Se tiver mais alguma dúvida estamos à disposição. E após o relatório, também há algum tempo aqui. Peça. Teremos o maior prazer em ajudá-lo!AC:- De fato, acho que essa abordagem pode começar a ser usada por todos. Não necessariamente em nossa forma (estamos envolvidos no gerenciamento de metadados). Pode ser um sistema de controle de qualquer coisa. Tudo que você precisa ter em mãos é uma visão relacional das coisas, pegue metadados a partir daí, entenda alguns mecanismos de modelo e entenda alguma linguagem de programação (como funciona).Todas essas ferramentas são de domínio público - você já pode começar a pesquisar no Google e entender como usá-las. Estou certo de que usá-los tornará sua vida mais fácil, melhor e geralmente liberará tempo para tarefas novas, ambiciosas e interessantes. Obrigado!Questões
Pergunta do público (doravante - A): - Entendo corretamente que tudo está empilhado porque você usa um banco de dados relacional? Parece-me que se você olhasse para o banco de dados orientado a documentos, toda essa solução seria muito mais fácil para você do que eu vejo agora.SC: - Na verdade não. O que começamos quando conversamos sobre pessoas que trabalham no nível do glossário e a aranha que vai ao baile de formatura lê essas histórias e verificações - na verdade, a tabela com o campo responsável por esse termo do glossário ocorre no baile de formatura . Eles disseram em nosso serviço: “Pessoal, você deve ter uma API REST. Como você faz isso é seu problema. Aqui está uma lista de tecnologias permitidas - use algo desta lista (é isso que podemos usar no Sberbank). ”Este é o nível da nossa solução, arquitetura aplicada. Para nós, pelo contrário, era mais fácil fazer isso não relacional. Por quê? Vou dar um exemplo, um dos muitos ... Por exemplo, preciso garantir, quando escrevo um campo, que ele não se refira em nenhum lugar a uma tabela que não existe. Eu apenas faço uma chave estrangeira no banco de dados e não estou preocupado. Não estou escrevendo uma linha - ela não me deixa fazer esse registro. E existem muitos exemplos!Aqui devemos preferir falar sobre outra coisa. Uma história mais complicada: lançaremos um patch de modelo com um conjunto de dados de ajuste / certificação e existem 6 objetos lá. E inevitavelmente, para você fornecer esse conjunto de APIs gentilmente, você precisa de três meses para trabalhar (de imediato). Levará uma semana e meia. Sem aplicar essas tecnologias, era simplesmente impossível sobreviver nessas condições. Simplesmente não damos esse nível de serviço!Isso é possível se você construiu a produção de forma a ter um patch de modelo (novo objeto), um botão "Faça tudo bem" e algum software que irá testar no modo de emulação do cliente. Ganhou um novo, o antigo não caiu - isso tinha que ser alcançado, mas como - era a escolha da equipe. A: - Eu tenho uma segunda pergunta. E qual é um exemplo de uso da vida? Entendo que teoricamente parece que você pode pelo menos descrever o mundo inteiro com seu objeto META_META ... Mas na vida, como você o usa? A julgar pela forma como é implementado (tudo deve ser colocado um no outro), deve diminuir a velocidade!SC:- A propósito, não (surpreendentemente)! Outra aplicação dessa história são os geradores de código. É aqui que algumas fachadas de lojas, armazéns são construídos e você é ETL, está tentando estacionar todas as opções possíveis para nove modelos, nove mecanismos de modelo descritos anteriormente. Usando metadados, você descreve essa transformação, usando esses modelos como stubs. Além disso, esta máquina sem programação fornece um código ETL, gera código com base em metadados. Acredito que também existem essas tecnologias, as abordagens serão apropriadas e corretas.A: - Eu estava contando com um exemplo mais específico.R: - Diga-me, por favor, estava escrito nos seus requisitos que você precisa fazer consultas estruturais complexas (Join e similares). Em que idioma ele é implementado ou você o descreve de alguma forma lógica?SC:- Acesso através da API REST, na maioria das vezes é Java, embora possa ser qualquer linguagem. Nosso serviço foi publicado (dhttps, pergunte https - você receberá o JSON de volta). Os trechos de código que mostramos são SQL. Para entender em que ordem ele deve ser processado, fizemos alguns ajustes SQL nos dicionários do DBMS e o estacionamos em um esquema separado na forma de representações materializadas. Assim, quando um patch de modelo é lançado, o botão "Atualizar visualização materializada" é clicado (os campos + aparecem). Mas, na verdade, nosso código é Java e Oracle.AC:- Vale a pena notar aqui que decidimos dividir as áreas de responsabilidade. Nós deliberadamente transferimos toda a magia para o kernel, e o Application simplesmente interpreta corretamente essas respostas. Ou seja, o próprio mecanismo Join ocorre no kernel, e o Java simplesmente dispersa tudo com competência na árvore e fornece ao usuário o resultado final.R: - E o que o Code Gens faz - você já escreve a lógica de consultas complexas lá? Ou é feito no lado do cliente? Precisamos entender de que lado está sendo descrito ... Eles apresentaram, ao que parece, o Code Gen, no qual é necessário descrever com precisão em alguma estrutura: por exemplo, eu quero que minha API aprenda tal e qual Join, vá através da lista; então diga se existe dentro ou não ... - consultas complexas são suficientes. Em que estágio está escrito?SC:- Se entendi sua pergunta corretamente, esta é exatamente a história quando nossos clientes, nossos clientes (esta é uma equipe dentro do kernel, a plataforma) dizem: "Escute, não queremos programar - nos dê isso". "É isso aí", tudo foi feito no âmago. O núcleo - essencialmente o que? 80%, talvez 90 - esta é a geração de código dinâmico, o texto que será chamado sob PL / SQL, mas voltado para o banco de dados. Lá, mesmo com o tempo, essa linha é gerada por mais tempo e, em seguida, o banco de dados é acessado (por exemplo, a solicitação de associação), retorna, envolve-o no JSON e exibe-o de cabeça para baixo. Além disso, Java transforma tudo isso em um contrato, que depende da estrutura.E:- Revelou uma solução de atualização em lote. E como é feita a garantia de entrega - chegou todo o pacote ou parte dele? Eles têm um certo cachend? E como garantir que nem o serviço caia, nem as estruturas de dados tenham algum tipo de coerência, para que não haja erros?SC: - Temos um protocolo - existem dois modos de atualização. Em um deles, você pode definir a bandeira "Aplique tudo o que puder". Há alguns softwares que o Excel converte em JSON - pode haver 10 mil linhas. E você, estritamente falando, duas linhas podem ser inválidas (erro). E você diz: "Aplique tudo o que puder"; ou "Aplique apenas se a história toda não tiver um único erro". Lá, o status integral será reverso, por exemplo. De fato, uma inserção é feita no banco de dados, mas a consolidação não é chamada.Em caso de erro - chama reversão, está no protocolo; você recebe o protocolo de qualquer maneira. Você obtém um status em cada linha e possui um identificador em um campo separado - um número (ID do objeto) ou alguma chave alternativa, ou ambas. O protocolo permite entender o que aconteceu com a minha solicitação.AC: - O próprio usuário indica em qual das opções ele deve se mover. Passamos esse parâmetro para o lado do núcleo, e o núcleo já produz toda a mágica, nos dá a resposta e nós a interpretamos.E:"Por que você não usou nenhum compilador de expressão interno que ajudasse a definir a regra?" Suponha que tenhamos um modelo, estou blogando em alguma linguagem (linguagem de script digitada / não digitada); escreveu: "Eu quero uma lista." Passou esse fragmento para que algum processador de código mastigasse tudo e o colocasse em um banco de dados NoSQL, como sugerido na primeira pergunta ... Ainda não está claro por que um banco de dados relacional e por que e como lidar com a redundância de dados? Um homem envia para você um modelo com um bilhão de lixo ... Como esses acordos são alcançados quando uma pessoa precisa?
A: - Eu tenho uma segunda pergunta. E qual é um exemplo de uso da vida? Entendo que teoricamente parece que você pode pelo menos descrever o mundo inteiro com seu objeto META_META ... Mas na vida, como você o usa? A julgar pela forma como é implementado (tudo deve ser colocado um no outro), deve diminuir a velocidade!SC:- A propósito, não (surpreendentemente)! Outra aplicação dessa história são os geradores de código. É aqui que algumas fachadas de lojas, armazéns são construídos e você é ETL, está tentando estacionar todas as opções possíveis para nove modelos, nove mecanismos de modelo descritos anteriormente. Usando metadados, você descreve essa transformação, usando esses modelos como stubs. Além disso, esta máquina sem programação fornece um código ETL, gera código com base em metadados. Acredito que também existem essas tecnologias, as abordagens serão apropriadas e corretas.A: - Eu estava contando com um exemplo mais específico.R: - Diga-me, por favor, estava escrito nos seus requisitos que você precisa fazer consultas estruturais complexas (Join e similares). Em que idioma ele é implementado ou você o descreve de alguma forma lógica?SC:- Acesso através da API REST, na maioria das vezes é Java, embora possa ser qualquer linguagem. Nosso serviço foi publicado (dhttps, pergunte https - você receberá o JSON de volta). Os trechos de código que mostramos são SQL. Para entender em que ordem ele deve ser processado, fizemos alguns ajustes SQL nos dicionários do DBMS e o estacionamos em um esquema separado na forma de representações materializadas. Assim, quando um patch de modelo é lançado, o botão "Atualizar visualização materializada" é clicado (os campos + aparecem). Mas, na verdade, nosso código é Java e Oracle.AC:- Vale a pena notar aqui que decidimos dividir as áreas de responsabilidade. Nós deliberadamente transferimos toda a magia para o kernel, e o Application simplesmente interpreta corretamente essas respostas. Ou seja, o próprio mecanismo Join ocorre no kernel, e o Java simplesmente dispersa tudo com competência na árvore e fornece ao usuário o resultado final.R: - E o que o Code Gens faz - você já escreve a lógica de consultas complexas lá? Ou é feito no lado do cliente? Precisamos entender de que lado está sendo descrito ... Eles apresentaram, ao que parece, o Code Gen, no qual é necessário descrever com precisão em alguma estrutura: por exemplo, eu quero que minha API aprenda tal e qual Join, vá através da lista; então diga se existe dentro ou não ... - consultas complexas são suficientes. Em que estágio está escrito?SC:- Se entendi sua pergunta corretamente, esta é exatamente a história quando nossos clientes, nossos clientes (esta é uma equipe dentro do kernel, a plataforma) dizem: "Escute, não queremos programar - nos dê isso". "É isso aí", tudo foi feito no âmago. O núcleo - essencialmente o que? 80%, talvez 90 - esta é a geração de código dinâmico, o texto que será chamado sob PL / SQL, mas voltado para o banco de dados. Lá, mesmo com o tempo, essa linha é gerada por mais tempo e, em seguida, o banco de dados é acessado (por exemplo, a solicitação de associação), retorna, envolve-o no JSON e exibe-o de cabeça para baixo. Além disso, Java transforma tudo isso em um contrato, que depende da estrutura.E:- Revelou uma solução de atualização em lote. E como é feita a garantia de entrega - chegou todo o pacote ou parte dele? Eles têm um certo cachend? E como garantir que nem o serviço caia, nem as estruturas de dados tenham algum tipo de coerência, para que não haja erros?SC: - Temos um protocolo - existem dois modos de atualização. Em um deles, você pode definir a bandeira "Aplique tudo o que puder". Há alguns softwares que o Excel converte em JSON - pode haver 10 mil linhas. E você, estritamente falando, duas linhas podem ser inválidas (erro). E você diz: "Aplique tudo o que puder"; ou "Aplique apenas se a história toda não tiver um único erro". Lá, o status integral será reverso, por exemplo. De fato, uma inserção é feita no banco de dados, mas a consolidação não é chamada.Em caso de erro - chama reversão, está no protocolo; você recebe o protocolo de qualquer maneira. Você obtém um status em cada linha e possui um identificador em um campo separado - um número (ID do objeto) ou alguma chave alternativa, ou ambas. O protocolo permite entender o que aconteceu com a minha solicitação.AC: - O próprio usuário indica em qual das opções ele deve se mover. Passamos esse parâmetro para o lado do núcleo, e o núcleo já produz toda a mágica, nos dá a resposta e nós a interpretamos.E:"Por que você não usou nenhum compilador de expressão interno que ajudasse a definir a regra?" Suponha que tenhamos um modelo, estou blogando em alguma linguagem (linguagem de script digitada / não digitada); escreveu: "Eu quero uma lista." Passou esse fragmento para que algum processador de código mastigasse tudo e o colocasse em um banco de dados NoSQL, como sugerido na primeira pergunta ... Ainda não está claro por que um banco de dados relacional e por que e como lidar com a redundância de dados? Um homem envia para você um modelo com um bilhão de lixo ... Como esses acordos são alcançados quando uma pessoa precisa? SC:"Vou tentar responder à medida que entendi a pergunta." A maior parte do programa se comunica conosco agora. Quando o mecanismo de interação de integração é configurado, poucas pessoas se comunicam conosco como programas. É claro que há casos em que as pessoas enviam la exelniks para o derramamento primário: criamos JSONs a partir deles, carregamos, mas essa é mais uma configuração principal.E temos um modo quando você envia 5.000 linhas, das quais 4.900 retornam com o status "Eu processei, não encontrei nenhuma alteração, não fiz nada". Mas isso se reflete no protocolo e não há erro. Isso é, por um lado, redundância.Temos toda essa história armazenada de forma aproximada à terceira forma normal, que simplesmente não implica redundância, em contraste com algumas estruturas desnormalizadas que são usadas, por exemplo, para vitrines.Por que relacional? Os geradores de código trabalham para nós, e a sensibilidade à qualidade dos metadados no sistema é muito alta. E quando tivermos a oportunidade de configurar a chave estrangeira usando relacional e garantir ... O registro simplesmente não se repete - haverá um erro se algo estiver errado no sistema, se ocorrer uma falha. E queremos, mas não estamos procurando trabalho adicional ...Não somos medidos por causa de quantas linhas de código escrevemos: "Você resolveu a questão do serviço e sua estabilidade ou não?" Você pode nem escrever - o principal é que funciona. Nesse sentido, era simplesmente mais rápido e mais conveniente para nós fazê-lo.Não aceito fornecedores específicos, mas os bancos de dados relacionais estão em desenvolvimento há 20 anos! Não é assim. Pegue, por exemplo, Word ou Excel no Windows - você não programa o código lá, que com a ajuda de "Assembler" acessa e move as cabeças do disco rígido para gravar um arquivo ... O mesmo está aqui! Acabamos de usar os desenvolvimentos que estavam no RDBMS, e isso foi conveniente.AC:- Para garantir todos os nossos requisitos, a integridade dos metadados era importante para nós. E aqui provavelmente também queremos dizer que não precisamos nos apegar - usamos relacional, não relacional ... A essência do relatório é que você também pode começar a usá-lo. Não necessariamente em base relacional, porque com certeza outros também têm algum tipo de metadado que pode ser coletado: pelo menos, quais tabelas, campos e tudo isso está programado.R: - O sistema envolve algum uso. Como você planeja (ou já fez) a entrega de dados ao seu sistema? É claro que algum tipo de atualização da estrutura de dados está acontecendo no mercado. Como isso tudo acontece com você? Automaticamente, ou seu agente está de pé ou você está dobrando todas as equipes de desenvolvimento para receber atualizações?AC:- Temos dois modos de operação. Uma é quando os próprios desenvolvedores ou as próprias equipes são forçados a inserir metadados no sistema através dos serviços REST. O segundo modo de operação é o mesmo “aspirador de pó”: nós mesmos entramos no ambiente e extraímos todos os metadados possíveis. Fazemos isso uma vez por dia e basta verificar o que os desenvolvedores nos enviaram.
SC:"Vou tentar responder à medida que entendi a pergunta." A maior parte do programa se comunica conosco agora. Quando o mecanismo de interação de integração é configurado, poucas pessoas se comunicam conosco como programas. É claro que há casos em que as pessoas enviam la exelniks para o derramamento primário: criamos JSONs a partir deles, carregamos, mas essa é mais uma configuração principal.E temos um modo quando você envia 5.000 linhas, das quais 4.900 retornam com o status "Eu processei, não encontrei nenhuma alteração, não fiz nada". Mas isso se reflete no protocolo e não há erro. Isso é, por um lado, redundância.Temos toda essa história armazenada de forma aproximada à terceira forma normal, que simplesmente não implica redundância, em contraste com algumas estruturas desnormalizadas que são usadas, por exemplo, para vitrines.Por que relacional? Os geradores de código trabalham para nós, e a sensibilidade à qualidade dos metadados no sistema é muito alta. E quando tivermos a oportunidade de configurar a chave estrangeira usando relacional e garantir ... O registro simplesmente não se repete - haverá um erro se algo estiver errado no sistema, se ocorrer uma falha. E queremos, mas não estamos procurando trabalho adicional ...Não somos medidos por causa de quantas linhas de código escrevemos: "Você resolveu a questão do serviço e sua estabilidade ou não?" Você pode nem escrever - o principal é que funciona. Nesse sentido, era simplesmente mais rápido e mais conveniente para nós fazê-lo.Não aceito fornecedores específicos, mas os bancos de dados relacionais estão em desenvolvimento há 20 anos! Não é assim. Pegue, por exemplo, Word ou Excel no Windows - você não programa o código lá, que com a ajuda de "Assembler" acessa e move as cabeças do disco rígido para gravar um arquivo ... O mesmo está aqui! Acabamos de usar os desenvolvimentos que estavam no RDBMS, e isso foi conveniente.AC:- Para garantir todos os nossos requisitos, a integridade dos metadados era importante para nós. E aqui provavelmente também queremos dizer que não precisamos nos apegar - usamos relacional, não relacional ... A essência do relatório é que você também pode começar a usá-lo. Não necessariamente em base relacional, porque com certeza outros também têm algum tipo de metadado que pode ser coletado: pelo menos, quais tabelas, campos e tudo isso está programado.R: - O sistema envolve algum uso. Como você planeja (ou já fez) a entrega de dados ao seu sistema? É claro que algum tipo de atualização da estrutura de dados está acontecendo no mercado. Como isso tudo acontece com você? Automaticamente, ou seu agente está de pé ou você está dobrando todas as equipes de desenvolvimento para receber atualizações?AC:- Temos dois modos de operação. Uma é quando os próprios desenvolvedores ou as próprias equipes são forçados a inserir metadados no sistema através dos serviços REST. O segundo modo de operação é o mesmo “aspirador de pó”: nós mesmos entramos no ambiente e extraímos todos os metadados possíveis. Fazemos isso uma vez por dia e basta verificar o que os desenvolvedores nos enviaram. SC: - Dos quatro níveis que examinamos, os três principais (glossário, modelos lógicos, modelos físicos) são a história que nos chega por padrão no modo Metadata Broker, e somos participantes passivos. Eles nos chamam, nos passam alguma coisa, perguntam; nossa tarefa é estacionar de maneira consistente. Embora existam casos em que criamos algumas histórias com os recursos da equipe, se estamos muito interessados em ter esses metadados.Como Nastya disse, em relação à história ao contrário (no jargão técnico, chamamos de "aspirador"), vamos ao ambiente industrial e lemos alguns dados. Existem casos diferentes - estamos prontos para discutir mais tarde, estamos prontos para contar muitas histórias interessantes.A: - Sou do centro da tecnologia financeira. Eu vi uma palavra familiar lá - DACUM principal. Nossa plataforma possui seus próprios metadados. Como vocês são amigos - diretamente com as tabelas Oracle ou com nossos metadados neste caso? Porque, no nosso caso, ser amigo das tabelas Oracle não é totalmente indicativo.SC:- Existe uma tabela DACUM principal, que contém a fiação. Isso não é segredo: havia e existem produtos que funcionam nessa história. Estas são uma das fontes de informação no repositório. Existe algum tipo de sistema que é um provedor de dados. Naturalmente, está no foco de nossa atenção em termos de metadados, porque uma das histórias que devemos mostrar e que nem tocamos aqui (devido ao tópico do relatório) é a linhagem de dados. Você deve mostrar de onde vem o histórico de dados deste campo. Nesse sentido, se houver uma tabela principal do DACUM, sabemos disso.
SC: - Dos quatro níveis que examinamos, os três principais (glossário, modelos lógicos, modelos físicos) são a história que nos chega por padrão no modo Metadata Broker, e somos participantes passivos. Eles nos chamam, nos passam alguma coisa, perguntam; nossa tarefa é estacionar de maneira consistente. Embora existam casos em que criamos algumas histórias com os recursos da equipe, se estamos muito interessados em ter esses metadados.Como Nastya disse, em relação à história ao contrário (no jargão técnico, chamamos de "aspirador"), vamos ao ambiente industrial e lemos alguns dados. Existem casos diferentes - estamos prontos para discutir mais tarde, estamos prontos para contar muitas histórias interessantes.A: - Sou do centro da tecnologia financeira. Eu vi uma palavra familiar lá - DACUM principal. Nossa plataforma possui seus próprios metadados. Como vocês são amigos - diretamente com as tabelas Oracle ou com nossos metadados neste caso? Porque, no nosso caso, ser amigo das tabelas Oracle não é totalmente indicativo.SC:- Existe uma tabela DACUM principal, que contém a fiação. Isso não é segredo: havia e existem produtos que funcionam nessa história. Estas são uma das fontes de informação no repositório. Existe algum tipo de sistema que é um provedor de dados. Naturalmente, está no foco de nossa atenção em termos de metadados, porque uma das histórias que devemos mostrar e que nem tocamos aqui (devido ao tópico do relatório) é a linhagem de dados. Você deve mostrar de onde vem o histórico de dados deste campo. Nesse sentido, se houver uma tabela principal do DACUM, sabemos disso.Um pouco de publicidade :)
Obrigado por ficar com a gente. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando aos seus amigos o VPS na nuvem para desenvolvedores a partir de US $ 4,99 , um analógico exclusivo de servidores de nível básico que foi inventado por nós para você: Toda a verdade sobre o VPS (KVM) E5-2697 v3 (6 núcleos) 10 GB DDR4 480 GB SSD 1 Gbps de US $ 19 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).Dell R730xd 2 vezes mais barato no data center Equinix Tier IV em Amsterdã? Somente nós temos 2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de US $ 99! Leia sobre Como criar um prédio de infraestrutura. classe c usando servidores Dell R730xd E5-2650 v4 que custam 9.000 euros por um centavo? Source: https://habr.com/ru/post/undefined/
All Articles