etcd 3.4.3: confiabilidade de armazenamento e pesquisa de segurança
Nota perev. : O conteúdo deste artigo não é totalmente típico do nosso blog. No entanto, como muitas pessoas sabem, o etcd está localizado no coração de Kubernetes, motivo pelo qual este estudo, conduzido por um consultor independente no campo da confiabilidade, mostrou-se interessante entre os engenheiros que operam este sistema. Além disso, é interessante no contexto de como os projetos de código aberto que já se comprovaram na produção estão sendo aprimorados, mesmo em um nível tão "baixo". O cofre de valor-chave (KV) etc é um banco de dados distribuído baseado no algoritmo de consenso Raft. Em uma análise realizada em 2014 , descobrimos que o etcd 0.4.1 foi afetado pelas chamadas leituras obsoletas por padrão(leia operações que retornam um valor antigo e irrelevante devido a um atraso na sincronização - aprox. transl.) . Decidimos retornar ao etcd (desta vez - para a versão 3.4.3) para avaliar novamente em detalhes seu potencial no campo da confiabilidade e segurança.Descobrimos que a operação com pares de "valor-chave" é estritamente serializável e que os processos do observador (relógios) entregam todas as alterações na chave de ordem. No entanto, os bloqueios no etcd são fundamentalmente inseguros e os riscos associados a eles são exacerbados por um bug, como resultado da qual a relevância da concessão não é verificada após a espera do bloqueio. Você pode ler o comentário dos desenvolvedores etcd em nosso relatório no blog do projeto .O estudo foi patrocinado pela Cloud Native Computing Foundation (CNCF), parte da Linux Foundation. Foi realizado em total conformidade com as políticas éticas da Jepsen .
O cofre de valor-chave (KV) etc é um banco de dados distribuído baseado no algoritmo de consenso Raft. Em uma análise realizada em 2014 , descobrimos que o etcd 0.4.1 foi afetado pelas chamadas leituras obsoletas por padrão(leia operações que retornam um valor antigo e irrelevante devido a um atraso na sincronização - aprox. transl.) . Decidimos retornar ao etcd (desta vez - para a versão 3.4.3) para avaliar novamente em detalhes seu potencial no campo da confiabilidade e segurança.Descobrimos que a operação com pares de "valor-chave" é estritamente serializável e que os processos do observador (relógios) entregam todas as alterações na chave de ordem. No entanto, os bloqueios no etcd são fundamentalmente inseguros e os riscos associados a eles são exacerbados por um bug, como resultado da qual a relevância da concessão não é verificada após a espera do bloqueio. Você pode ler o comentário dos desenvolvedores etcd em nosso relatório no blog do projeto .O estudo foi patrocinado pela Cloud Native Computing Foundation (CNCF), parte da Linux Foundation. Foi realizado em total conformidade com as políticas éticas da Jepsen .1. Fundo
O repositório Etc KV é um sistema distribuído projetado para ser usado como base de coordenação. Como o Zookeeper e o Consul , o etcd armazena pequenas quantidades de estados raramente atualizados ( por padrão, até 8 GB ) na forma de um mapa de valores-chave e fornece leitura, gravação e microtransações estritamente serializáveis em todo o data warehouse, além de primitivas de coordenação como bloqueios , rastreamento (relógios) e seleção de líder. Muitos sistemas distribuídos, como Kubernetes e OpenStack , usam o etcd para armazenar metadados de cluster, coordenar visualizações coordenadas de dados, escolher um líder etc.Em 2014, já realizamos uma avaliação do etcd 0.4.1 . Em seguida, descobrimos que, por padrão, é propenso a leituras obsoletas devido à otimização. Enquanto o trabalho sobre os princípios do Raft discute a necessidade de dividir as operações de leitura em threads e passá-las por um sistema de consenso para garantir a viabilidade, o etcd lê qualquer líder localmente, sem verificar se há um estado mais atual no líder mais novo. A equipe de desenvolvimento do etcd implementou o sinalizador de quorum opcional e, na API da versão 3.0 do etcd , a linearização de todas as operações, exceto as operações de rastreamento, apareceu por padrão . A API etcd 3.0 concentra-se em um mapa plano KV, onde as chaves e os valores são opacosmatrizes de bytes ( opacos ) . Usando consultas de intervalo, você pode simular chaves hierárquicas. Os usuários podem ler, escrever e excluir chaves, bem como monitorar o fluxo de atualizações para uma única chave ou intervalo de chaves. O kit de ferramentas etcd é complementado por concessões (objetos variáveis com vida útil limitada, que são mantidas no estado ativo por solicitações de pulsação do cliente), bloqueios (objetos nomeados dedicados vinculados a concessões) e a escolha de líderes.Na versão 3.0, o etcd oferece uma API transacional limitadapara operações atômicas com muitas chaves. Nesse modelo, uma transação é uma expressão condicional com um predicado, uma ramificação verdadeira e uma ramificação falsa. Um predicado pode ser uma conjunção de várias comparações de chaves: igualdade ou várias desigualdades, de acordo com versões de uma chave, revisão global etcd ou o valor atual da chave. Ramos verdadeiros e falsos podem incluir várias operações de leitura e gravação; todos eles são aplicados atomicamente, dependendo do resultado da estimativa do predicado.1.1 Garantias de consistência na documentação
Em outubro de 2019, a documentação etcd da API afirma que "todas as chamadas da API demonstram consistência consistente - a forma mais forte de garantia de consistência disponível em sistemas distribuídos". Não é assim: consistência consistente é estritamente mais fraca que linearidade, e a linearizabilidade é definitivamente possível em sistemas distribuídos. Além disso, a documentação afirma que "durante a operação de leitura, etcd não garante a transferência do valor [mais recente (medido pelo relógio externo após a conclusão da consulta)] disponível em qualquer membro do cluster". Essa também é uma declaração muito conservadora: se o etcd fornecer linearizabilidade, as operações de leitura sempre serão associadas ao estado confirmado mais recente na ordem de linearização.A documentação também afirma que o etcd garante isolamento serializável: todas as operações (mesmo aquelas que afetam várias teclas) são executadas em alguma ordem geral. Os autores descrevem o isolamento serializável como "o nível de isolamento mais forte disponível em sistemas distribuídos". Isso (dependendo do que você quer dizer com "nível de isolamento") também não é verdadeiro; a serialização estrita é mais forte que a serialização simples, enquanto a primeira também é possível em sistemas distribuídos.A documentação diz que todas as operações (exceto rastreamento) no etcd são linearizáveis por padrão. Nesse caso, linearizabilidade é definida como consistência com relógios globais fracamente sincronizados. Note-se que essa definição não é apenas incompatível com a definição de linearizabilidadeHerlihy & Wing, mas também implica uma violação da causalidade: os nós com horário de expediente tentarão ler os resultados das operações que nem sequer começaram. Assumimos que o etcd ainda não é uma máquina do tempo e, como é baseado no algoritmo Raft, a definição geralmente aceita de linearizabilidade deve ser aplicada.Como as operações KV no etcd são serializáveis e linearizáveis, acreditamos que o etcd fornece serialização estrita por padrão . Isso faz sentido, uma vez que todas as chaves etcd estão em uma única máquina de estado, e o Raft fornece a ordem completa de todas as operações nessa máquina de estado. De fato, todo o conjunto de dados etcd é um único objeto linearizável.O sinalizador opcional serializable diminuiO nível de operações de leitura da consistência serializável estrita para regular, permitindo a leitura de um estado confirmado desatualizado. Observe que a bandeira serializablenão afeta a serialização da história; As operações KV etcd são serializáveis em todos os casos.2. Desenvolvimento de Teste
Para criar um conjunto de testes, usamos a biblioteca Jepsen apropriada. A versão etcd 3.4.3 (a mais recente em outubro de 19) foi analisada, trabalhando em clusters Debian Stretch que consistem em 5 nós. Implementamos várias falhas nesses clusters, incluindo partições de rede, isolando nós individuais, particionando o cluster em maioria e minoria, além de partições não transitivas com maioria sobreposta. Eles “derrubaram” e suspenderam subconjuntos aleatórios de nós, e também deliberadamente desabilitaram líderes. Foram introduzidas distorções temporais de várias centenas de segundos, tanto em intervalos de multissegundos quanto em milissegundos ("flicker" rápido). Como o etcd suporta a alteração dinâmica do número de componentes, adicionamos e removemos aleatoriamente nós durante o teste.As cargas de teste incluíam registros, conjuntos e testes transacionais para operações de verificação em KV, bem como cargas especializadas para bloqueios e relógios.2.1 Registros
Para avaliar a confiabilidade do etcd durante as operações de KV, foi desenvolvido um teste de registro durante o qual as operações aleatórias de leitura, gravação, comparação e configuração foram realizadas nas teclas da unidade. Os resultados foram avaliados usando a ferramenta de linearização Knossos , usando o modelo de registro de comparação / instalação e informações sobre a versão.2.2 Conjuntos
Para quantificar leituras obsoletas, foi desenvolvido um teste que usou uma transação de comparar e definir para ler um conjunto de números inteiros de uma única chave e, em seguida, adicionar um valor a esse conjunto. Durante o teste, também fizemos uma leitura paralela de todo o conjunto. Após a conclusão do teste, os resultados foram analisados para a ocorrência de casos em que o elemento, que se sabia estar presente no conjunto, estava ausente nos resultados da leitura. Esses casos foram usados para quantificar leituras obsoletas e atualizações perdidas.2.3 Anexar teste
Para verificar a serialização estrita, um teste de acréscimo foi desenvolvido durante o qual as transações eram lidas em paralelo e adicionavam valores a listas que consistiam em conjuntos únicos de números inteiros. Cada lista foi armazenada em uma chave etcd, e foram feitas adições em cada transação, lendo cada chave que precisava ser alterada em uma transação e, em seguida, essas chaves foram gravadas e as leituras foram executadas na segunda transação, protegidapara garantir que nenhuma chave gravada tenha sido alterada desde a primeira leitura. No final do teste, plotamos o relacionamento entre transações com base na prioridade em tempo real e o relacionamento das operações de leitura e adição. A verificação deste gráfico em busca de loops tornou possível determinar se as operações eram estritamente serializáveis.Enquanto o etcd impede que as transações gravem a mesma chave várias vezes, você pode criar transações com até um registro por chave. Também garantimos que as operações de leitura dentro da mesma transação refletissem operações de gravação anteriores da mesma transação.2.4 Fechaduras
Como um serviço de coordenação, o etcd promete suporte interno para bloqueio distribuído . Investigamos esses bloqueios de duas maneiras. Inicialmente, foram geradas solicitações aleatórias de bloqueio e desbloqueio , recebendo uma concessão para cada bloqueio e deixando-o aberto usando o cliente etc embutido no cliente Java keepaliveaté o lançamento . Testamos os resultados com o Knossos para verificar se eles formam uma implementação linearizada do serviço de bloqueio.Para um teste mais prático (e para quantificar a frequência de falhas de bloqueio), usamos bloqueios e etcd para organizar a exclusão mútua ao fazer atualizações para o conjunto na memóriae procurou por atualizações perdidas neste conjunto. Este teste nos permitiu confirmar diretamente se os sistemas que usam o etcd como mutex podem atualizar com segurança o estado interno.A terceira versão do teste de bloqueio envolvia proteções na chave de concessão para modificar o conjunto armazenado no etcd.2.5 Rastreamento
Para verificar se os relógios fornecem informações sobre cada atualização de chave, uma chave foi criada como parte do teste e valores inteiros exclusivos atribuídos às cegas . Enquanto isso, os clientes compartilhavam essa chave por vários segundos por vez. Cada vez após o início do relógio, o cliente começou com a revisão em que havia parado da última vez.No final deste processo, garantimos que cada cliente observasse a mesma sequência de alterações importantes.3. Resultados
3.1 Rastreamento a partir da 0ª revisão
Ao rastrear uma chave, os clientes podem especificar uma revisão inicial , que é "uma revisão opcional com a qual o rastreamento inicia (inclusive)". Se o usuário quiser ver cada operação com uma determinada chave, ele poderá especificar a primeira revisão do etcd. O que é essa auditoria? O modelo de dados e o glossário não fornecem uma resposta para esta pergunta; as revisões são descritas como monotonicamente aumentando os contadores de 64 bits, mas não está claro se o etcd inicia de 0 ou 1. É razoável supor que a contagem regressiva é do zero (apenas no caso).Infelizmente, isso está errado. Solicitar a 0ª revisão faz com que o etcd comece a transmitir atualizações, começando com a revisão atual no servidor mais uma, mas não com o primeiro. A solicitação para a 1ª revisão fornece todas as alterações. Esse comportamento não está documentado em nenhum lugar .Acreditamos que, na prática, é improvável que essa sutileza leve a problemas na produção, uma vez que a maioria dos clusters não permanece na primeira revisão. Além disso, o etcd comprime a história de qualquer maneira ao longo do tempo, portanto, em aplicativos do mundo real, provavelmente, em qualquer caso, não é necessário ler todas as versões, começando com a 1ª revisão. Esse comportamento é justificado, mas não prejudicaria a descrição correspondente na documentação.3.2 Fechaduras míticas
A documentação da API para bloqueios afirma que uma chave bloqueada "pode ser usada em conjunto com transações para garantir que as atualizações no etcd ocorram somente quando o bloqueio for de propriedade". Estranho, mas não fornece nenhuma garantia para os bloqueios e seu objetivo não é explicado.No entanto, em outros materiais, os mantenedores etcd ainda compartilham informações sobre o uso de bloqueios. Por exemplo, o comunicado de lançamento do etcd 3.2 descreve um aplicativo etcdctlpara bloquear alterações no compartilhamento de arquivos em um disco. Além disso, em um problema no GitHub com uma pergunta sobre a finalidade específica dos bloqueios, um dos desenvolvedores do etcd respondeu ao seguinte:etcd , ( ) , ( etcd), - :
- etcd;
- - ( , etcd);
- .
Apenas um exemplo é dado em etcdctl: um bloqueio foi usado para proteger a equipe put, mas não vinculou a chave de bloqueio à atualização.Infelizmente, isso não é seguro, pois permite que vários clientes mantenham o mesmo bloqueio simultaneamente. O problema é agravado pela suspensão de processos, falhas de rede ou partições, no entanto, também pode ocorrer em clusters completamente íntegros, sem falhas externas. Por exemplo, nesta execução de teste, o processo número 3 define com êxito o bloqueio e o processo 1 obtém o mesmo bloqueio em paralelo, mesmo antes que o processo 3 tenha a oportunidade de removê-lo: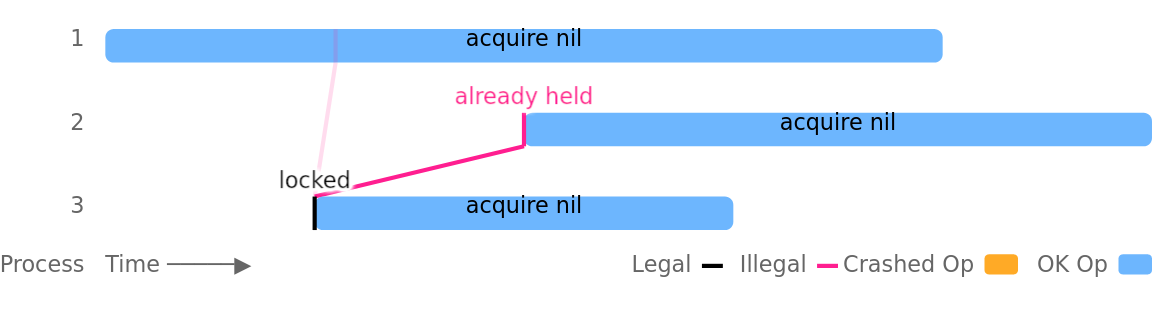 A violação do mutex foi mais perceptível em concessões com TTLs curtos: TTLs de 1, 2 e 3 segundos não foram capazes de fornecer exclusão mútua após apenas alguns minutos de teste (mesmo em clusters saudáveis). Suspensões de processo e partições de rede levaram a problemas ainda mais rapidamente.Em uma de nossas variantes de teste de bloqueio, mutexes etcd foram usados para proteger atualizações conjuntas de um conjunto de números inteiros (como sugere a documentação etcd). Cada atualização lê o valor atual da amostra na memória e, após cerca de um segundo, grava essa coleção novamente com a adição de um elemento exclusivo. Com concessões com TTL de dois segundos, cinco processos paralelos e uma pausa de processo a cada cinco segundos, conseguimos causar uma perda constante de cerca de 18% das atualizações confirmadas.Esse problema foi agravado pelo mecanismo de travamento interno no etcd. Se o cliente aguardou o outro cliente desbloqueá-lo, perdeu a concessão e depois que o bloqueio foi liberado, o servidor não verificou novamente o contrato para garantir que ele ainda é válido antes de informar ao cliente que o bloqueio está por trás dele.A inclusão de uma verificação adicional de concessão, bem como a seleção de TTLs mais longos e a definição cuidadosa dos tempos limite das eleições reduzirão a frequência desse problema. No entanto, as violações de mutex não podem ser completamente eliminadas, pois os bloqueios distribuídos são fundamentalmente inseguros em sistemas assíncronos. O Dr. Martin Kleppmann descreve isso de maneira convincente em seu artigoSobre bloqueios distribuídos. Segundo ele, os serviços de bloqueio devem sacrificar a correção para manter a viabilidade em sistemas assíncronos: se o processo travar ao controlar o bloqueio, o serviço de bloqueio precisará de alguma maneira para forçar o desbloqueio. No entanto, se o processo realmente não cair, mas simplesmente executar lentamente ou estiver temporariamente indisponível, desbloqueá-lo pode causar a retenção em vários locais ao mesmo tempo.Mas mesmo que o serviço de bloqueio distribuído use, digamos, algum tipo de detector de falha mágica e possa realmente garantir exclusão mútua, no caso de algum recurso não local, seu uso ainda será inseguro. Suponha que o processo A envie uma mensagem para o banco de dados D enquanto mantém um cadeado. Depois disso, o processo A trava e o processo B recebe um bloqueio e também envia uma mensagem para a base D. O problema é que uma mensagem do processo A (devido à assincronia) pode vir após uma mensagem do processo B, violando a exceção mútua que o bloqueio deveria fornecer. .Para evitar esse problema, é necessário confiar no fato de que o próprio sistema de armazenamento oferecerá suporte à correção das transações ou, se o serviço de bloqueio fornecer esse mecanismo, useO token " esgrima" que será incluído em todas as operações realizadas pelo detentor da trava. Isso garantirá que nenhuma operação do suporte anterior da trava ocorra repentinamente entre as operações do atual proprietário da trava. Por exemplo, no serviço de bloqueio gordinho do Google , esses tokens são chamados sequenciadores . No etcd, você pode usar a revisão da chave de bloqueio como um token de bloqueio ordenado globalmente.Além disso, as chaves de bloqueio no etcd podem ser usadas para proteger atualizações transacionais no próprio etcd. Verificando a versão da chave de bloqueio como parte da transação, os usuários podem impedir uma transação se o bloqueio não for mais retido (ou seja, a versão da chave de bloqueio for maior que zero). Em nossos testes, essa abordagem nos permitiu isolar com êxito as operações de leitura, modificação e gravação nas quais a gravação era a única transação protegida pelo bloqueio. Essa abordagem fornece isolamento semelhante aos tokens de barragem, mas (como tokens de barragem) não garante atomicidade: um processo pode travar ou perder um mutex durante uma atualização que consiste em muitas operações, deixando o etcd em um estado logicamente inconsistente.Os resultados do trabalho nas questões do projeto:
A violação do mutex foi mais perceptível em concessões com TTLs curtos: TTLs de 1, 2 e 3 segundos não foram capazes de fornecer exclusão mútua após apenas alguns minutos de teste (mesmo em clusters saudáveis). Suspensões de processo e partições de rede levaram a problemas ainda mais rapidamente.Em uma de nossas variantes de teste de bloqueio, mutexes etcd foram usados para proteger atualizações conjuntas de um conjunto de números inteiros (como sugere a documentação etcd). Cada atualização lê o valor atual da amostra na memória e, após cerca de um segundo, grava essa coleção novamente com a adição de um elemento exclusivo. Com concessões com TTL de dois segundos, cinco processos paralelos e uma pausa de processo a cada cinco segundos, conseguimos causar uma perda constante de cerca de 18% das atualizações confirmadas.Esse problema foi agravado pelo mecanismo de travamento interno no etcd. Se o cliente aguardou o outro cliente desbloqueá-lo, perdeu a concessão e depois que o bloqueio foi liberado, o servidor não verificou novamente o contrato para garantir que ele ainda é válido antes de informar ao cliente que o bloqueio está por trás dele.A inclusão de uma verificação adicional de concessão, bem como a seleção de TTLs mais longos e a definição cuidadosa dos tempos limite das eleições reduzirão a frequência desse problema. No entanto, as violações de mutex não podem ser completamente eliminadas, pois os bloqueios distribuídos são fundamentalmente inseguros em sistemas assíncronos. O Dr. Martin Kleppmann descreve isso de maneira convincente em seu artigoSobre bloqueios distribuídos. Segundo ele, os serviços de bloqueio devem sacrificar a correção para manter a viabilidade em sistemas assíncronos: se o processo travar ao controlar o bloqueio, o serviço de bloqueio precisará de alguma maneira para forçar o desbloqueio. No entanto, se o processo realmente não cair, mas simplesmente executar lentamente ou estiver temporariamente indisponível, desbloqueá-lo pode causar a retenção em vários locais ao mesmo tempo.Mas mesmo que o serviço de bloqueio distribuído use, digamos, algum tipo de detector de falha mágica e possa realmente garantir exclusão mútua, no caso de algum recurso não local, seu uso ainda será inseguro. Suponha que o processo A envie uma mensagem para o banco de dados D enquanto mantém um cadeado. Depois disso, o processo A trava e o processo B recebe um bloqueio e também envia uma mensagem para a base D. O problema é que uma mensagem do processo A (devido à assincronia) pode vir após uma mensagem do processo B, violando a exceção mútua que o bloqueio deveria fornecer. .Para evitar esse problema, é necessário confiar no fato de que o próprio sistema de armazenamento oferecerá suporte à correção das transações ou, se o serviço de bloqueio fornecer esse mecanismo, useO token " esgrima" que será incluído em todas as operações realizadas pelo detentor da trava. Isso garantirá que nenhuma operação do suporte anterior da trava ocorra repentinamente entre as operações do atual proprietário da trava. Por exemplo, no serviço de bloqueio gordinho do Google , esses tokens são chamados sequenciadores . No etcd, você pode usar a revisão da chave de bloqueio como um token de bloqueio ordenado globalmente.Além disso, as chaves de bloqueio no etcd podem ser usadas para proteger atualizações transacionais no próprio etcd. Verificando a versão da chave de bloqueio como parte da transação, os usuários podem impedir uma transação se o bloqueio não for mais retido (ou seja, a versão da chave de bloqueio for maior que zero). Em nossos testes, essa abordagem nos permitiu isolar com êxito as operações de leitura, modificação e gravação nas quais a gravação era a única transação protegida pelo bloqueio. Essa abordagem fornece isolamento semelhante aos tokens de barragem, mas (como tokens de barragem) não garante atomicidade: um processo pode travar ou perder um mutex durante uma atualização que consiste em muitas operações, deixando o etcd em um estado logicamente inconsistente.Os resultados do trabalho nas questões do projeto:4. Discussão
Em nossos testes, o etcd 3.4.3 atendeu às expectativas em relação às operações KV: observamos consistência estritamente serializável de leitura, gravação e até transações com várias chaves, apesar da suspensão de processos, falhas, manipulação do relógio e da rede, além de uma alteração no número de membros do cluster . O comportamento estritamente serializável foi implementado por padrão nas operações KV; o desempenho das leituras com o serializableconjunto de sinalizadores levou ao aparecimento de leituras obsoletas (conforme descrito na documentação).Monitore (relógios) para funcionar corretamente - pelo menos nas teclas individuais. Até a compactação do histórico destruir os dados antigos, o relógio emitiu com êxito cada atualização de chave.No entanto, os bloqueios no etcd (como todos os bloqueios distribuídos) não fornecem exclusão mútua. Diferentes processos podem manter a trava ao mesmo tempo - mesmo em clusters saudáveis com relógios perfeitamente sincronizados. A documentação com a API de bloqueio não disse nada sobre isso, e os exemplos de bloqueios apresentados não eram seguros. No entanto, alguns dos problemas com os bloqueios tiveram que ocorrer após o lançamento deste patch .Como resultado de nossa colaboração, a equipe etcd fez uma série de alterações na documentação (elas já apareceram no GitHub e serão publicadas em versões futuras do site do projeto). A página da API GitHub Warranties agora declara que, por padrão, o etcd é estritamente serializávele a alegação de que serial e serializável são os níveis mais fortes de consistência disponíveis em sistemas distribuídos foi removida. Com relação às revisões, agora é indicado que o início deve ser da unidade (1) , embora a documentação da API ainda não diga que uma tentativa de iniciar a partir da 0ª revisão resultará em "eventos de saída que ocorreram após a revisão atual mais 1" em vez do esperado "envio de todos os eventos". A documentação dos problemas de segurança de bloqueio está em desenvolvimento .Algumas alterações na documentação, como a descrição do comportamento especial do etcd ao tentar ler, iniciando com uma revisão zero, ainda requerem atenção.Como sempre, enfatizamos que Jepsen prefere uma abordagem experimental à verificação de segurança: podemos confirmar a presença de bugs, mas não a ausência deles. Esforços consideráveis estão sendo feitos para encontrar problemas, mas não podemos provar a correção geral do etcd.4.1 Recomendações
Se você usar bloqueios no etcd, pense se você precisa deles para segurança ou para simplesmente aumentar o desempenho limitando probabilisticamente a simultaneidade. Os bloqueios Etcd podem ser usados para aumentar o desempenho, mas usá-los para fins de segurança pode ser arriscado.Em particular, se você usar o bloqueio etcd para proteger um recurso compartilhado, como um arquivo, banco de dados ou serviço, esse recurso deverá garantir a segurança sem bloquear. Uma maneira de conseguir isso é usar um token de barragem monótono . Pode ser, por exemplo, uma revisão etcd associada à chave de bloqueio atual. O recurso compartilhado deve garantir que, uma vez que o cliente tenha usado o tokenyPara executar alguma operação, qualquer operação com um token x < yserá rejeitada. Essa abordagem não garante a atomicidade, mas garante que as operações dentro da estrutura do bloqueio sejam executadas em ordem e não de forma intermitente.Suspeitamos que é improvável que usuários comuns encontrem esse problema. Mas se você ainda confiar na leitura de todas as mudanças de ETCD, começando com a primeira revisão, lembre-se que você precisa para passar 1, não 0 como parâmetro. Nossos experimentos mostram que uma revisão zero neste meio de caso "revisão atual", não "Mais cedo".Finalmente, bloqueios e etcd (como todos os bloqueios distribuídos) enganam os usuários: eles podem querer usá-los como bloqueios regulares, mas ficarão muito surpresos quando perceberem que esses bloqueios não fornecem exclusão mútua. A documentação da API, as postagens no blog, os problemas no GitHub não dizem nada sobre esse risco. Recomendamos que você inclua informações na documentação etcd de que os bloqueios não fornecem exclusão mútua e fornece exemplos de uso de tokens de barrage para atualizar o status de recursos compartilhados em vez de exemplos que podem levar à perda de atualizações.4.2 Planos adicionais
O projeto etcd é considerado estável há vários anos: o algoritmo Raft baseado nele funcionou bem, a API para operações KV é simples e direta. Embora alguns recursos adicionais tenham recebido recentemente uma nova API, sua semântica é relativamente simples. Acreditamos que já estudamos comandos básicos suficientes como gete put, transações, bloqueio e rastreamento. No entanto, existem outros testes que devem ser realizados.No momento, não realizamos uma avaliação suficientemente detalhada das exclusões.: Pode haver casos de limite associados a versões e revisões, quando objetos são criados e excluídos constantemente. Em testes futuros, pretendemos submeter as operações de remoção a um estudo mais cuidadoso. Também não testamos consultas de intervalo ou operações de rastreamento com várias chaves, embora suspeitemos que suas semânticas sejam semelhantes às operações com chaves únicas.Nos testes, utilizamos a suspensão de processos, falhas, manipulações com o relógio, a rede foi dividida e a composição do cluster alterada; nos bastidores, havia problemas como danos ao disco e outras falhas bizantinas no nível de um nó. Essas oportunidades podem ser exploradas em pesquisas futuras.O trabalho foi apoiado pela Cloud Native Computing Foundation., parte da Linux Foundation e está em conformidade com as políticas éticas da Jepsen . Queremos agradecer à equipe etcd por sua ajuda, e aos seguintes representantes em particular: Chris Aniszczyk, Gyuho Lee, Xiang Li, Hitoshi Mitake, Jingyi Hu e Brandon Philips.PS do tradutor
Leia também no nosso blog: Source: https://habr.com/ru/post/undefined/
All Articles