 Quando os problemas de análise vão além das ferramentas pré-criadas, provavelmente é hora de você escolher um banco de dados para análise. Você não deve gravar scripts de consultas no banco de dados em funcionamento, pois pode alterar a ordem dos dados e, muito provavelmente, desacelerar o aplicativo.Você também pode excluir acidentalmente informações importantes se analistas ou engenheiros trabalharem lá.Para análise, você precisa de um tipo separado de banco de dados. Mas qual é a verdade?Neste post, consideraremos ofertas e práticas recomendadas para uma empresa comum que está apenas começando a funcionar. Qualquer que seja a configuração escolhida, você poderá encontrar um compromisso no futuro para melhorar o desempenho sobre o que estamos discutindo aqui.Trabalhando com um grande número de clientes, descobrimos que os critérios mais importantes que devem ser considerados são:
Quando os problemas de análise vão além das ferramentas pré-criadas, provavelmente é hora de você escolher um banco de dados para análise. Você não deve gravar scripts de consultas no banco de dados em funcionamento, pois pode alterar a ordem dos dados e, muito provavelmente, desacelerar o aplicativo.Você também pode excluir acidentalmente informações importantes se analistas ou engenheiros trabalharem lá.Para análise, você precisa de um tipo separado de banco de dados. Mas qual é a verdade?Neste post, consideraremos ofertas e práticas recomendadas para uma empresa comum que está apenas começando a funcionar. Qualquer que seja a configuração escolhida, você poderá encontrar um compromisso no futuro para melhorar o desempenho sobre o que estamos discutindo aqui.Trabalhando com um grande número de clientes, descobrimos que os critérios mais importantes que devem ser considerados são:- Tipo de dados analisados
- Quantos dados você tem?
- O foco da sua equipe de engenharia
- Quão rápido você precisa de informações
Quais tipos de dados você analisa?
Pense nos dados que você deseja analisar. Eles se encaixam bem em linhas e colunas como uma enorme planilha do Excel? Ou faria mais sentido se você os colocasse em um documento do Word?Se você respondeu ao Excel, um banco de dados relacional como Postgres, MySQL, Amazon Redshift ou BigQuery atenderá às suas necessidades. Esses bancos de dados relacionais estruturados são ótimos quando você sabe exatamente quais dados você receberá e como eles se relacionam - basicamente, como as linhas e colunas estão relacionadas. Para a maioria dos tipos de análise de usuários, os bancos de dados relacionais funcionam bem. Atributos do usuário, como nomes, emails e planos de cobrança, se encaixam perfeitamente na tabela, como eventos do usuário e suas propriedades .Por outro lado, se seus dados couberem melhor em um pedaço de papel, você deve consultar um banco de dados não relacional (NoSQL), como Hadoop ou Mongo.Os bancos de dados não relacionais são caracterizados por um número extremamente grande de valores privados (milhões) de dados semiestruturados. Exemplos clássicos de dados semiestruturados são textos como email, livros e redes sociais, dados audiovisuais e geográficos. Se você estiver realizando muita mineração de texto, processamento de idiomas ou processamento de imagens, provavelmente precisará usar armazenamentos de dados não relacionais.
Com quantos dados você está lidando?
A próxima pergunta a ser feita é com quantos dados você está lidando. Quanto mais dados você tiver, mais útil será o banco de dados não relacional, porque ele não impõe restrições aos dados recebidos, o que permitirá que você grave no banco de dados mais rapidamente. Essas não são restrições estritas, e cada uma pode processar mais ou menos dados, dependendo de vários fatores, mas descobrimos que cada um dos bancos de dados funciona perfeitamente dentro desses limites.Se você tiver menos de 1 TB de dados, com o Postgres você obterá um bom desempenho. Mas diminui para cerca de 6 TB. Se você gosta do MySQL, mas precisa de uma escala um pouco maior, o Aurora (versão da Amazon) pode atingir 64 TB. Para um tamanho de petabyte, o Amazon Redshift geralmente é uma boa escolha, pois é otimizado para análises de até 2PB. Para processamento paralelo ou até dados MOAR, provavelmente é hora de dar uma olhada no Hadoop.No entanto, a AWS nos disse que eles estão executando o Amazon.com no Redshift; portanto, se você tiver uma equipe de DBA de primeira classe, poderá escalar além do "limite" de 2PB.
Essas não são restrições estritas, e cada uma pode processar mais ou menos dados, dependendo de vários fatores, mas descobrimos que cada um dos bancos de dados funciona perfeitamente dentro desses limites.Se você tiver menos de 1 TB de dados, com o Postgres você obterá um bom desempenho. Mas diminui para cerca de 6 TB. Se você gosta do MySQL, mas precisa de uma escala um pouco maior, o Aurora (versão da Amazon) pode atingir 64 TB. Para um tamanho de petabyte, o Amazon Redshift geralmente é uma boa escolha, pois é otimizado para análises de até 2PB. Para processamento paralelo ou até dados MOAR, provavelmente é hora de dar uma olhada no Hadoop.No entanto, a AWS nos disse que eles estão executando o Amazon.com no Redshift; portanto, se você tiver uma equipe de DBA de primeira classe, poderá escalar além do "limite" de 2PB.Em que sua equipe de engenharia está focada?
Essa é outra pergunta importante a ser feita ao discutir o banco de dados. Quanto menor sua equipe geral, maior a probabilidade de seus engenheiros se concentrarem principalmente na criação de produtos, em vez de processamento e gerenciamento de dados. O número de pessoas que você pode dedicar a esses projetos afetará bastante suas opções.Com alguns recursos de engenharia, você tem mais opções - pode acessar um banco de dados relacional ou não relacional. Os bancos de dados relacionais levam menos tempo que o NoSQL.Se você tem vários engenheiros que estão trabalhando na instalação, mas não podem trazer ninguém para o serviço, escolha algo como Postgres , Google SQL (hospedagem MySQL opcional) ou Segment Warehouses(Hospedagem Redshift) é provavelmente uma opção melhor que Redshift, Aurora ou BigQuery, pois eles exigem correção periódica do processamento de dados. Se você tiver mais tempo para atender, escolher Redshift ou BigQuery fornecerá consultas mais rápidas e em maior escala.Os bancos de dados relacionais têm outra vantagem: você pode usar o SQL para consultá-los. O SQL é bem conhecido por analistas e engenheiros e é mais fácil de aprender do que a maioria das linguagens de programação.Por outro lado, a análise de dados semiestruturados geralmente exige, no mínimo, experiência em programação orientada a objetos ou, melhor, experiência na escrita de código para trabalhar com big data. Mesmo com o advento de ferramentas de análise como Hunkpara Hadoop ou Slamdata para MongoDB, será necessário um analista experiente ou um especialista em dados para analisar esses tipos de bancos de dados.Quão rápido você precisa desses dados?
Embora a “análise em tempo real” seja muito popular em casos como detecção de fraude e monitoramento do sistema, a maioria das análises não requer dados em tempo real ou análise imediata.Quando você responde perguntas, por exemplo, o que causa a saída de usuários ou como as pessoas mudam do seu aplicativo para o site, o acesso aos seus dados com um pequeno atraso (intervalos de hora em hora ou diariamente) é bastante aceitável. Seus dados não mudam minuto a minuto.Portanto, se você estiver trabalhando principalmente na análise real, consulte um banco de dados otimizado para análises, como Redshift ou BigQuery. Esses bancos de dados são projetados para acomodar uma grande quantidade de dados e ler e combinar dados rapidamente, agilizando as consultas. Eles também podem baixar dados com rapidez suficiente (a cada hora) enquanto alguém está fazendo o processo de limpeza, redimensionando e monitorando o cluster.Se você precisar absolutamente de dados em tempo real, deve procurar um banco de dados não estruturado, como o Hadoop. Você pode projetar seu banco de dados Hadoop para que os dados sejam carregados muito rapidamente, embora a consulta possa demorar mais, dependendo do uso da RAM, do espaço em disco disponível e da estrutura dos dados.Postgres vs. Amazon Redshift vs. Bigquery do Google
Você provavelmente já percebeu que um banco de dados relacional seria a melhor opção para analisar a maioria dos tipos de comportamento do usuário. Informações sobre como seus usuários interagem com seu site e aplicativos podem facilmente caber em um formato estruturado.analytics.track('Completed Order') — select * from ios.completed_order
 Então a pergunta é qual banco de dados SQL usar? Quatro critérios devem ser considerados.
Então a pergunta é qual banco de dados SQL usar? Quatro critérios devem ser considerados.Tamanho vs. Rapidez
Quando você precisa de velocidade, vale a pena considerar o Postgres: para um banco de dados com menos de 1 TB, o Postgres é bastante rápido para carregar dados e consultas. Além disso, está disponível. À medida que você se aproxima de 6 TB (herdado do Amazon RDS), suas consultas ficam mais lentas.Portanto, quando você precisa de um tamanho maior, geralmente recomendamos Redshift. Nossa experiência mostra que o Redshift tem a melhor relação custo / benefício.Destaque SQL
O Redshift é construído sobre uma variação do Postgres e ambos suportam o bom e velho SQL. O Redshift não suporta todos os tipos de dados e funções que o postgres suporta, mas é muito mais próximo do padrão do setor do que o BigQuery, que possui seu próprio SQL.Diferentemente de muitos outros sistemas baseados em SQL, o BigQuery usa sintaxe separada por vírgula para indicar junções de tabelas, e não de acordo com a documentação do SQL . Isso significa que, sem cautela, as consultas SQL podem levar a erros ou resultados inesperados. Portanto, muitas das equipes que conhecemos não podem convencer seus analistas a aprender o BigQuery SQL.Ecossistema de terceiros
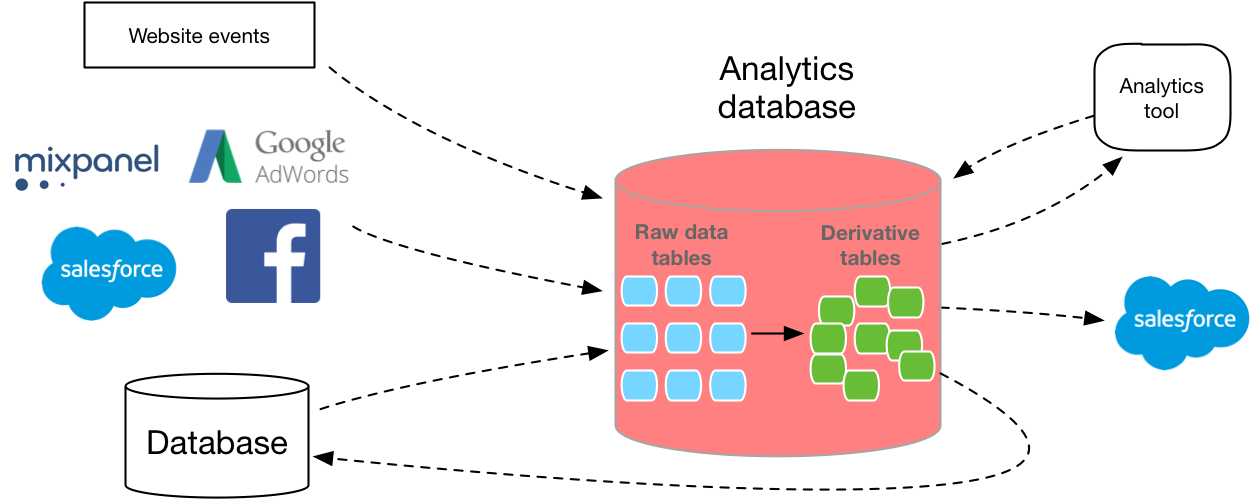
Raramente o seu data warehouse vive por conta própria. Você precisa colocar os dados em um banco de dados e, além disso, precisa usar algum tipo de software para analisá-los. (A menos que você execute a consulta SQL na linha de comando).Portanto, muitas vezes as pessoas gostam desse Redshift tem um ecossistema muito grande de ferramentas de terceiros. A AWS possui recursos como o Segment Data Warehouse para carregar dados no Redshift a partir da API de análise e também trabalha com quase todas as ferramentas de visualização de dados do mercado. Menos serviços de terceiros se conectam ao Google, portanto, a transferência dos mesmos dados para o BigQuery pode levar mais tempo para se desenvolver, e você não terá tantas opções para o software de BI.Você pode ver parceiros da Amazonaqui e google aqui .No entanto, se você já usa o Google Cloud Storage em vez do Amazon S3, pode ser benéfico permanecer no ecossistema do Google. Ambos os serviços facilitam o download de dados, se eles já existem no repositório de armazenamento em nuvem correspondente, para que, embora não viole os termos de uso, será muito mais fácil se você parar de usar um desses provedores.Treinamento
Agora que você tem uma idéia mais clara de qual banco de dados usar, a próxima etapa é descobrir como você coletará os dados no banco de dados.Muitos novos desenvolvedores de banco de dados subestimam o quão difícil é criar um pipeline de dados escalável. Você deve escrever sua própria camada de extração, API de coleta de dados, camada de consulta e conversão. E todo mundo tem que escalar. Além disso, você precisa determinar o layout correto com base no tamanho e tipo de cada coluna. O MVP replica seu banco de dados de produção para uma nova instância, mas isso geralmente significa usar um banco de dados que não é otimizado para análise.Felizmente, existem várias opções no mercado que podem ajudá-lo a contornar alguns desses obstáculos e fazer automaticamente um ETL para você.Mas, seja seu próprio desenvolvimento ou compra, vale a pena obter dados no SQL.Com base nos dados iniciais do usuário, somente com a ajuda de um formato SQL flexível você poderá responder perguntas detalhadas sobre o que seus clientes estão fazendo, avaliar com precisão a distribuição, entender o comportamento de plataforma cruzada, criar painéis para uma empresa em particular e muito mais.