Otimização massiva de consultas no PostgreSQL. Kirill Borovikov (tensor)
O relatório apresenta algumas abordagens que permitem monitorar o desempenho das consultas SQL quando existem milhões por dia e centenas de servidores PostgreSQL controlados.Quais soluções técnicas nos permitem processar com eficiência esse volume de informações e como facilita a vida de um desenvolvedor comum.Quem está interessado em analisar problemas específicos e várias técnicas para otimizar consultas SQL e resolver problemas típicos de DBA no PostgreSQL ? Você também pode ler uma série de artigos sobre este tópico. Meu nome é Kirill Borovikov, represento a empresa "Tensor" . Especificamente, sou especialista em trabalhar com bancos de dados em nossa empresa.Hoje vou lhe dizer como estamos envolvidos na otimização de consultas, quando você não precisa "captar" o desempenho de uma única solicitação, mas sim resolver o problema em massa. Quando existem milhões de solicitações, e você precisa encontrar algumas abordagens para resolver esse grande problema.Em geral, o “tensor” para nossos milhões de clientes é o VLSI - nosso aplicativo : uma rede social corporativa, soluções de comunicação por vídeo, para gerenciamento interno e externo de documentos, sistemas de contabilidade para contabilidade e armazenamento ... Ou seja, uma “mega combinação” para gerenciamento de negócios integrado, que são mais de 100 projetos internos diferentes.Para garantir que todos funcionem e se desenvolvam normalmente, temos 10 centros de desenvolvimento em todo o país, eles têm mais de 1000 desenvolvedores .Trabalhamos com o PostgreSQL desde 2008 e acumulamos uma grande quantidade do que processamos - dados de clientes, estatísticos, analíticos, dados de sistemas externos de informação - mais de 400 TB . Somente "em produção" existem cerca de 250 servidores e, no total, os servidores de banco de dados que monitoramos são cerca de 1000.
Meu nome é Kirill Borovikov, represento a empresa "Tensor" . Especificamente, sou especialista em trabalhar com bancos de dados em nossa empresa.Hoje vou lhe dizer como estamos envolvidos na otimização de consultas, quando você não precisa "captar" o desempenho de uma única solicitação, mas sim resolver o problema em massa. Quando existem milhões de solicitações, e você precisa encontrar algumas abordagens para resolver esse grande problema.Em geral, o “tensor” para nossos milhões de clientes é o VLSI - nosso aplicativo : uma rede social corporativa, soluções de comunicação por vídeo, para gerenciamento interno e externo de documentos, sistemas de contabilidade para contabilidade e armazenamento ... Ou seja, uma “mega combinação” para gerenciamento de negócios integrado, que são mais de 100 projetos internos diferentes.Para garantir que todos funcionem e se desenvolvam normalmente, temos 10 centros de desenvolvimento em todo o país, eles têm mais de 1000 desenvolvedores .Trabalhamos com o PostgreSQL desde 2008 e acumulamos uma grande quantidade do que processamos - dados de clientes, estatísticos, analíticos, dados de sistemas externos de informação - mais de 400 TB . Somente "em produção" existem cerca de 250 servidores e, no total, os servidores de banco de dados que monitoramos são cerca de 1000. SQL é uma linguagem declarativa. Você descreve não "como" algo deve funcionar, mas "o que" você deseja receber. O DBMS sabe como criar o JOIN - como conectar seus tablets, quais condições impor, o que será indexado, o que não ...Alguns DBMSs aceitam dicas: "Não, conecte esses dois tablets em tal e qual fila", mas o PostgreSQL não. Esta é a posição consciente dos principais desenvolvedores: "Melhor terminarmos o otimizador de consultas do que permitir que os desenvolvedores usem algum tipo de dica".Mas, apesar do PostgreSQL não permitir que "fora" se controle, ele perfeitamente permite que você veja o que acontece "dentro" quando você executa sua consulta e onde ela apresenta problemas.
SQL é uma linguagem declarativa. Você descreve não "como" algo deve funcionar, mas "o que" você deseja receber. O DBMS sabe como criar o JOIN - como conectar seus tablets, quais condições impor, o que será indexado, o que não ...Alguns DBMSs aceitam dicas: "Não, conecte esses dois tablets em tal e qual fila", mas o PostgreSQL não. Esta é a posição consciente dos principais desenvolvedores: "Melhor terminarmos o otimizador de consultas do que permitir que os desenvolvedores usem algum tipo de dica".Mas, apesar do PostgreSQL não permitir que "fora" se controle, ele perfeitamente permite que você veja o que acontece "dentro" quando você executa sua consulta e onde ela apresenta problemas. Em geral, com quais problemas clássicos o desenvolvedor [chega ao DBA] normalmente? "Aqui nós cumprimos a solicitação, e tudo é lento , tudo trava, algo acontece ... Algum tipo de problema!"Os motivos são quase sempre os mesmos:
Em geral, com quais problemas clássicos o desenvolvedor [chega ao DBA] normalmente? "Aqui nós cumprimos a solicitação, e tudo é lento , tudo trava, algo acontece ... Algum tipo de problema!"Os motivos são quase sempre os mesmos:
: « SQL 10 JOIN...» — , «», . , (10 FROM) - . []
PostgreSQL, «» , — «» . 10 , 10 , PostgreSQL , . []- «»
, , , . … - , .
, (INSERT, UPDATE, DELETE) — .
... E para todo o resto, precisamos de um plano ! Precisamos ver o que está acontecendo dentro do servidor. O plano de execução de consultas para o PostgreSQL é uma árvore do algoritmo de execução de consultas em uma representação textual. É o algoritmo que, como resultado da análise do planejador, foi reconhecido como o mais eficaz.Cada nó da árvore é uma operação: extração de dados de uma tabela ou índice, construção de um bitmap, união de duas tabelas, união, interseção ou eliminação de amostras. O cumprimento da solicitação é uma passagem pelos nós desta árvore.Para obter um plano de consulta, a maneira mais fácil é executar a instrução
O plano de execução de consultas para o PostgreSQL é uma árvore do algoritmo de execução de consultas em uma representação textual. É o algoritmo que, como resultado da análise do planejador, foi reconhecido como o mais eficaz.Cada nó da árvore é uma operação: extração de dados de uma tabela ou índice, construção de um bitmap, união de duas tabelas, união, interseção ou eliminação de amostras. O cumprimento da solicitação é uma passagem pelos nós desta árvore.Para obter um plano de consulta, a maneira mais fácil é executar a instrução EXPLAIN. Para obter todos os atributos reais, ou seja, execute uma consulta baseada em - EXPLAIN (ANALYZE, BUFFERS) SELECT ....O ponto negativo: quando você o executa, acontece "aqui e agora", portanto é adequado apenas para depuração local. Se você pegar um servidor com muita carga, que está sob um forte fluxo de alterações de dados, e você vê: “Sim! Aqui, somos mais lentos com o pedido de Xia . " Meia hora, uma hora atrás - enquanto você estava executando e recebendo essa solicitação dos logs, transportando-a novamente para o servidor, todos os dados e estatísticas foram alterados. Você o executa para depurar - e corre rapidamente! E você não pode entender o porquê, porque foi lento. Para entender o que era exatamente no momento em que a solicitação é executada no servidor, as pessoas inteligentes escreveram o módulo auto_explain. Está presente em quase todas as distribuições mais comuns do PostgreSQL, e você pode simplesmente ativá-lo no arquivo de configuração.Se ele entender que uma solicitação está sendo executada por mais tempo do que a borda que você lhe disse, ele tira um instantâneo do plano dessa solicitação e os grava juntos em um log .
Para entender o que era exatamente no momento em que a solicitação é executada no servidor, as pessoas inteligentes escreveram o módulo auto_explain. Está presente em quase todas as distribuições mais comuns do PostgreSQL, e você pode simplesmente ativá-lo no arquivo de configuração.Se ele entender que uma solicitação está sendo executada por mais tempo do que a borda que você lhe disse, ele tira um instantâneo do plano dessa solicitação e os grava juntos em um log . Tudo parece estar bem agora, vamos ao log e vemos lá ... [passo de texto]. Mas não podemos dizer nada sobre ele, exceto pelo fato de esse ser um excelente plano, porque foram necessários 11ms para ser concluído.Tudo parece estar bem - mas nada está claro sobre o que realmente aconteceu. Além do tempo total, não vemos muito. Porque olhar para um texto simples como esse "latuha" é geralmente amado.Mas mesmo que seja amado, embora desconfortável, mas há mais problemas importantes:
Tudo parece estar bem agora, vamos ao log e vemos lá ... [passo de texto]. Mas não podemos dizer nada sobre ele, exceto pelo fato de esse ser um excelente plano, porque foram necessários 11ms para ser concluído.Tudo parece estar bem - mas nada está claro sobre o que realmente aconteceu. Além do tempo total, não vemos muito. Porque olhar para um texto simples como esse "latuha" é geralmente amado.Mas mesmo que seja amado, embora desconfortável, mas há mais problemas importantes:- . , Index Scan — , - . , «» , CTE — « ».
- : , , — . , , , , loops — . . , , , — - « ».
Nessas circunstâncias, entenda "Quem é o elo mais fraco?" quase irrealista. Portanto, até os próprios desenvolvedores no "manual" escrevem que "Entender o plano é uma arte que precisa ser aprendida, experimentada ..." .Mas temos 1000 desenvolvedores e cada um deles não passará essa experiência à cabeça. Eu, você, ele - eles sabem, e alguém ali - não está mais lá. Talvez ele aprenda, ou talvez não, mas ele precisa trabalhar agora - e onde ele conseguiria essa experiência.Planejar visualização
Portanto, percebemos que, para lidar com esses problemas, precisamos de uma boa visualização do plano . [artigo]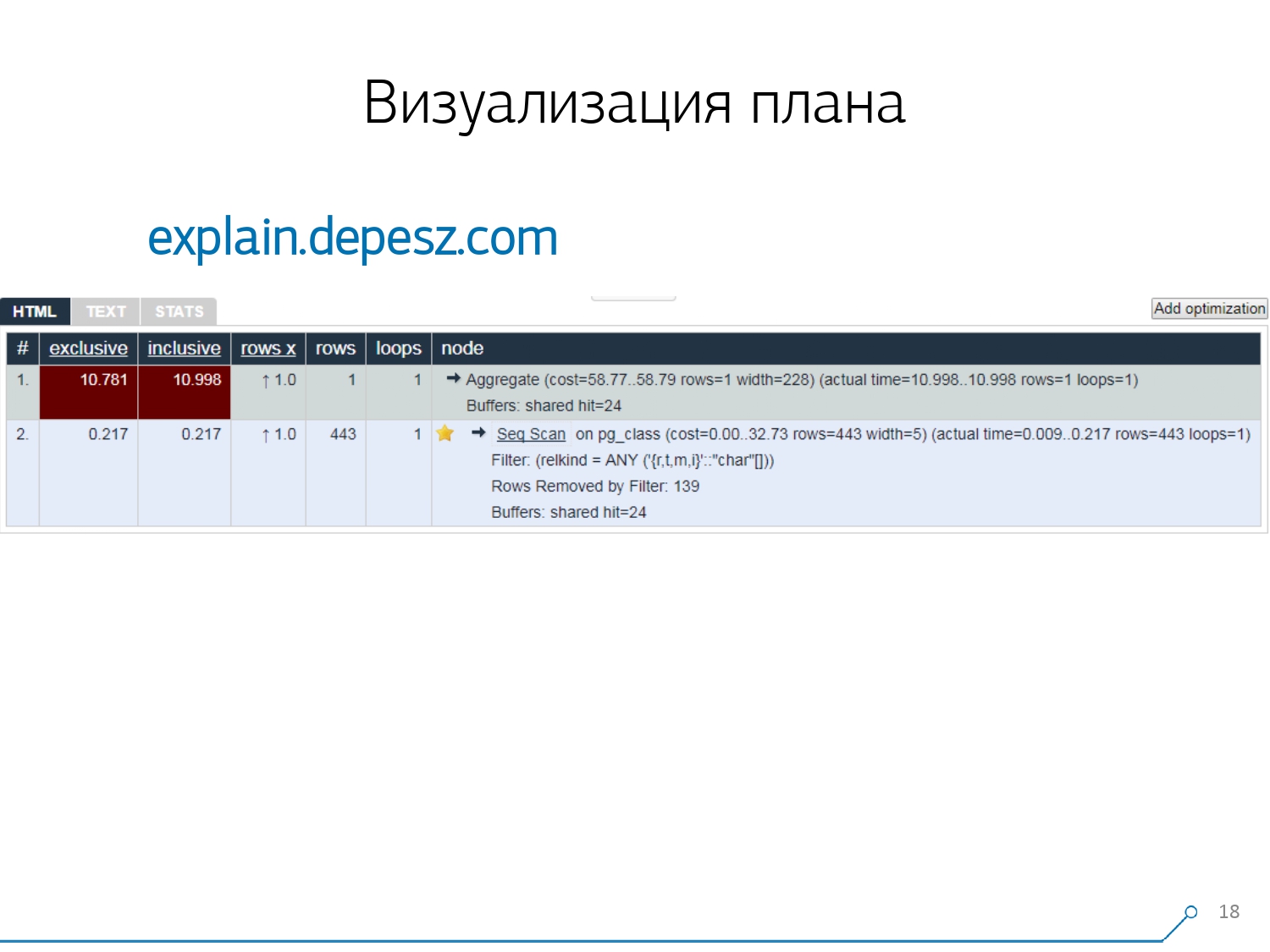 Fomos os primeiros a “dar uma volta no mercado” - vamos procurar na Internet o que existe em geral.Porém, descobriu-se que soluções relativamente "vivas" que são mais ou menos desenvolvidas, existem muito poucas - literalmente, uma coisa: explica.depesz.com de Hubert Lubaczewski. Na entrada do campo "feed", uma representação textual do plano mostra uma placa com os dados analisados:
Fomos os primeiros a “dar uma volta no mercado” - vamos procurar na Internet o que existe em geral.Porém, descobriu-se que soluções relativamente "vivas" que são mais ou menos desenvolvidas, existem muito poucas - literalmente, uma coisa: explica.depesz.com de Hubert Lubaczewski. Na entrada do campo "feed", uma representação textual do plano mostra uma placa com os dados analisados:- tempo de trabalho do nó adequado
- tempo total em toda a subárvore
- o número de registros recuperados e que era estatisticamente esperado
- o próprio corpo do nó
Este serviço também tem a capacidade de compartilhar o arquivo de links. Você jogou seu plano lá e disse: "Ei, Vasya, aqui está um link para você, algo está errado aí". Mas existem alguns problemas menores.Em primeiro lugar, uma enorme quantidade de copiar e colar. Você pega um pedaço do log, coloca-o lá e de novo e de novo.Em segundo lugar, não há análise da quantidade de dados lidos - os próprios buffers que são exibidos
Mas existem alguns problemas menores.Em primeiro lugar, uma enorme quantidade de copiar e colar. Você pega um pedaço do log, coloca-o lá e de novo e de novo.Em segundo lugar, não há análise da quantidade de dados lidos - os próprios buffers que são exibidos EXPLAIN (ANALYZE, BUFFERS), aqui não vemos. Ele simplesmente não sabe como desmontar, entender e trabalhar com eles. Quando você lê muitos dados e entende que pode "decompor" incorretamente em um disco e armazenar em cache na memória, essas informações são muito importantes.O terceiro ponto negativo é o desenvolvimento muito fraco deste projeto. Os commits são muito pequenos, é bom a cada seis meses e o código em Perl.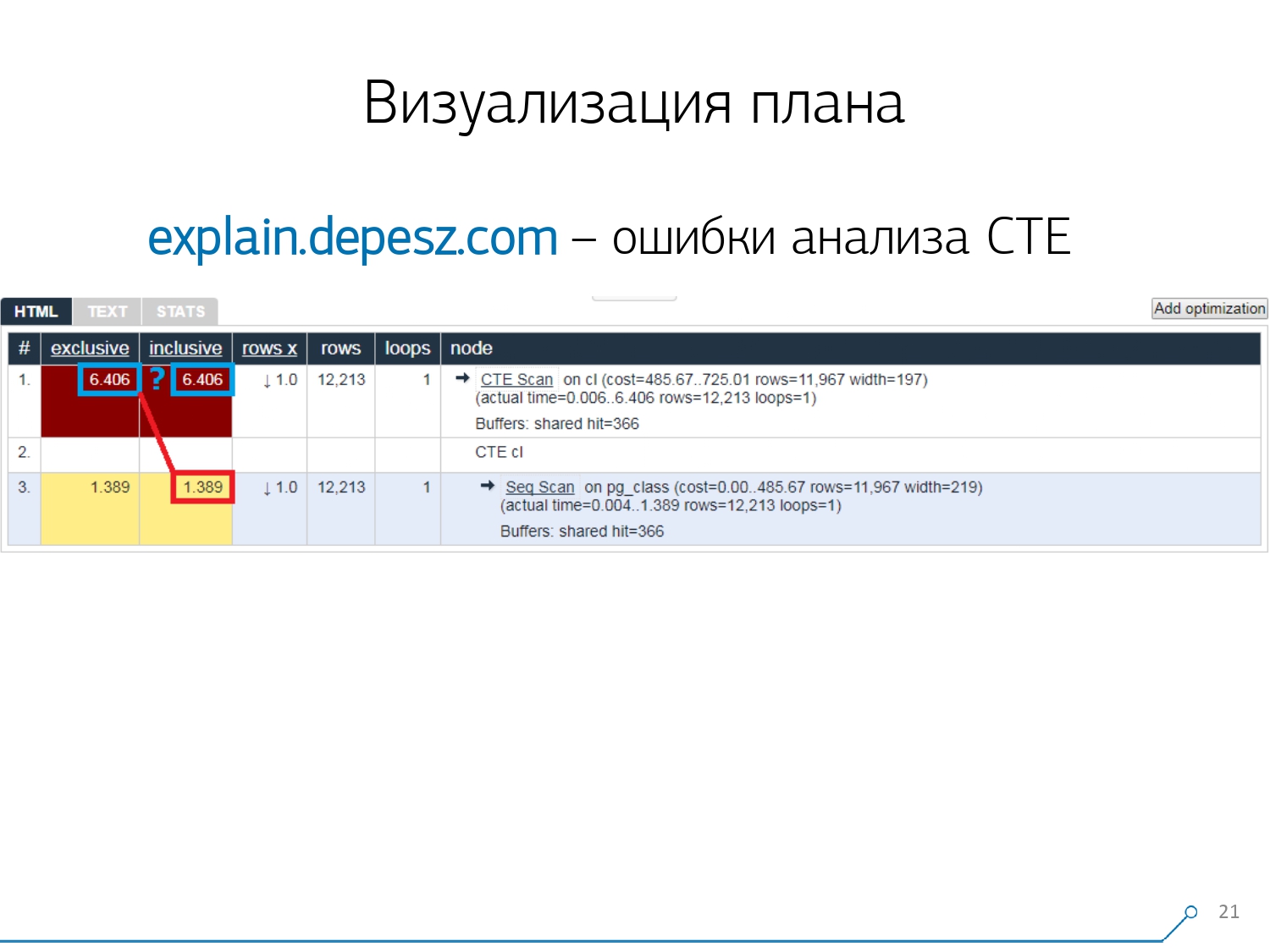 Mas isso é tudo "letra", alguém poderia de alguma forma viver com ela, mas há uma coisa que nos afastou desse serviço. Estes são erros de análise Common Table Expression (CTE) e vários nós dinâmicos como InitPlan / SubPlan.Se você acredita nessa imagem, temos o tempo total de execução de cada nó individual maior que o tempo total de execução de toda a solicitação. É simples - o tempo de geração deste CTE não foi subtraído do nó CTE Scan . Portanto, não sabemos mais a resposta correta, quanto a própria digitalização CTE levou.
Mas isso é tudo "letra", alguém poderia de alguma forma viver com ela, mas há uma coisa que nos afastou desse serviço. Estes são erros de análise Common Table Expression (CTE) e vários nós dinâmicos como InitPlan / SubPlan.Se você acredita nessa imagem, temos o tempo total de execução de cada nó individual maior que o tempo total de execução de toda a solicitação. É simples - o tempo de geração deste CTE não foi subtraído do nó CTE Scan . Portanto, não sabemos mais a resposta correta, quanto a própria digitalização CTE levou. Então percebemos que era hora de escrever a nossa - viva! Cada desenvolvedor diz: "Agora vamos escrever nossos próprios, será apenas super!"Eles usaram uma pilha típica de serviços da Web: o núcleo do Node.js + Express, puxaram o Bootstrap e para belos diagramas - D3.js. E nossas expectativas foram justificadas - recebemos o primeiro protótipo em duas semanas:
Então percebemos que era hora de escrever a nossa - viva! Cada desenvolvedor diz: "Agora vamos escrever nossos próprios, será apenas super!"Eles usaram uma pilha típica de serviços da Web: o núcleo do Node.js + Express, puxaram o Bootstrap e para belos diagramas - D3.js. E nossas expectativas foram justificadas - recebemos o primeiro protótipo em duas semanas:- analisador de plano próprio
Ou seja, agora geralmente podemos analisar qualquer plano daqueles gerados pelo PostgreSQL. - análise correta de nós dinâmicos - CTE Scan, InitPlan, SubPlan
- análise da distribuição de buffers - onde são lidas páginas de dados da memória, onde do cache local, onde do disco
- visibilidade recebida
Para que não esteja "no registro" que está "cavando", mas que você veja o "link mais fraco" imediatamente na imagem.
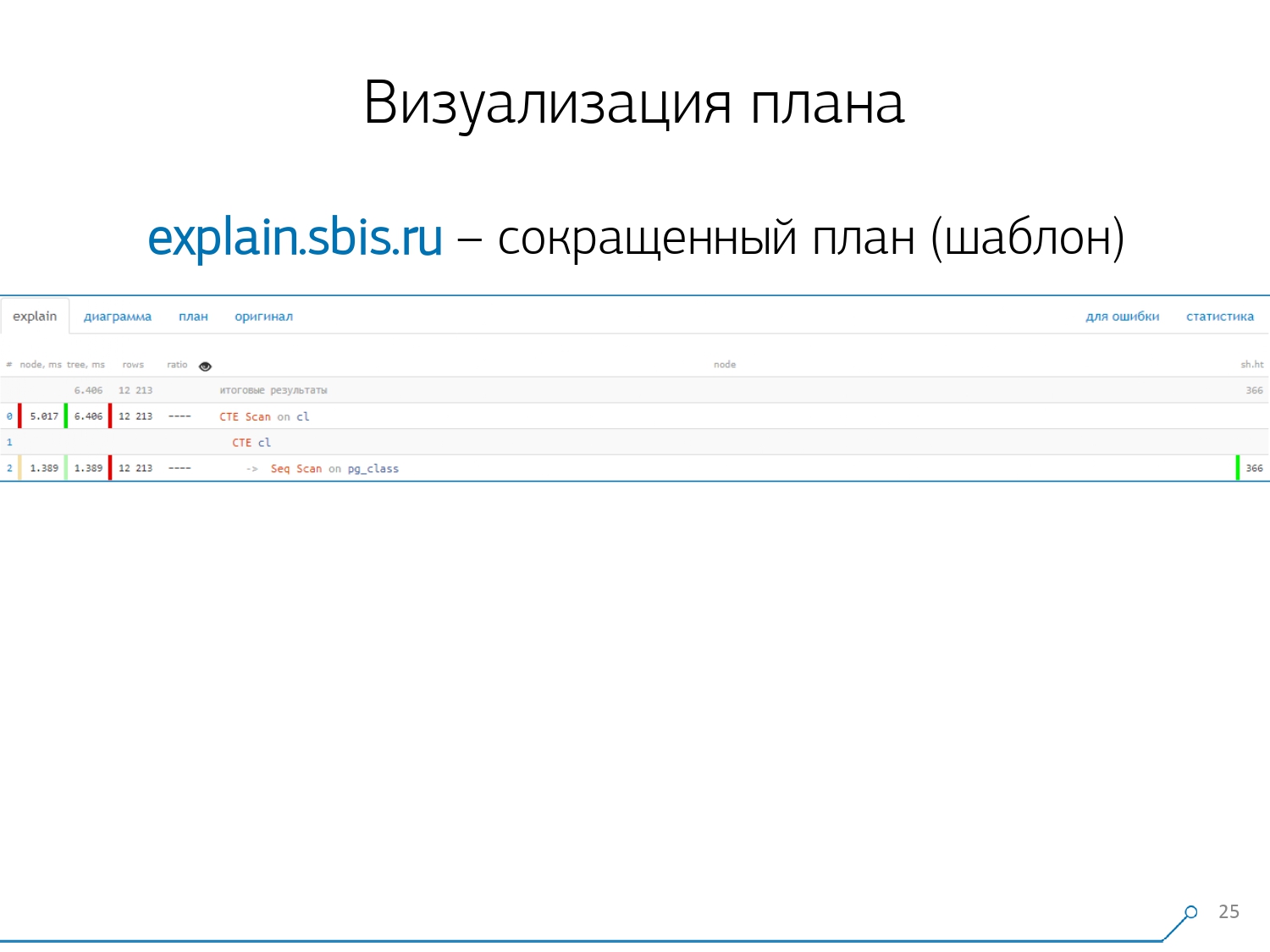 Temos algo parecido com isto - imediatamente com destaque de sintaxe. Mas geralmente nossos desenvolvedores não estão mais trabalhando com uma apresentação completa do plano, mas com uma apresentação mais curta. Afinal, já analisamos todos os dígitos e os jogamos para a esquerda e para a direita e deixamos apenas a primeira linha no meio, que tipo de nó é: geração CTE Scan, CTE ou Seq Scan por algum tipo de etiqueta.Essa visão abreviada é o que chamamos de modelo de plano .
Temos algo parecido com isto - imediatamente com destaque de sintaxe. Mas geralmente nossos desenvolvedores não estão mais trabalhando com uma apresentação completa do plano, mas com uma apresentação mais curta. Afinal, já analisamos todos os dígitos e os jogamos para a esquerda e para a direita e deixamos apenas a primeira linha no meio, que tipo de nó é: geração CTE Scan, CTE ou Seq Scan por algum tipo de etiqueta.Essa visão abreviada é o que chamamos de modelo de plano .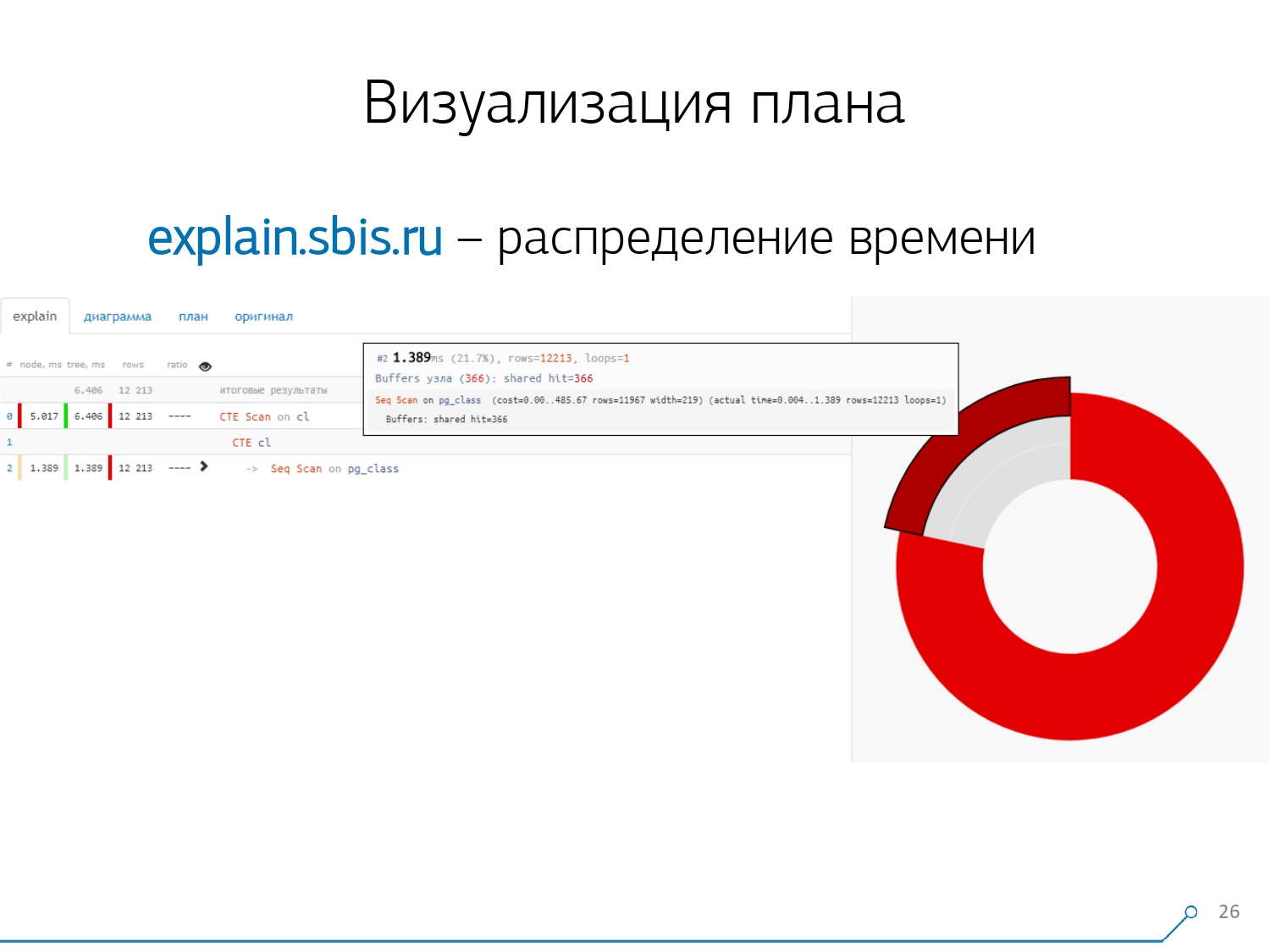 O que mais seria conveniente? Seria conveniente ver qual a proporção de qual nó do tempo total é alocado para nós - e apenas "travar" o gráfico de pizza ao lado .Apontamos para o nó e vemos - conosco, verifica-se que o Seq Scan levou menos de um quarto do tempo todo e os restantes 3/4 fizeram o CTE Scan. Horror! Esta é uma pequena observação sobre a "taxa de incêndio" do CTE Scan, se você os usar ativamente em suas consultas. Eles não são muito rápidos - eles perdem mesmo para a varredura de tabela usual. [artigo] [artigo]Mas, geralmente, esses diagramas são mais interessantes, mais complicados quando apontamos imediatamente para um segmento e vemos, por exemplo, que mais da metade do tempo todo, algumas Seq Scan “comiam”. Além disso, havia algum tipo de filtro dentro, vários registros foram lançados nele ... Você pode enviar essa foto diretamente para o desenvolvedor e dizer: “Vasya, tudo está ruim com você aqui! Entenda, olhe - algo está errado!
O que mais seria conveniente? Seria conveniente ver qual a proporção de qual nó do tempo total é alocado para nós - e apenas "travar" o gráfico de pizza ao lado .Apontamos para o nó e vemos - conosco, verifica-se que o Seq Scan levou menos de um quarto do tempo todo e os restantes 3/4 fizeram o CTE Scan. Horror! Esta é uma pequena observação sobre a "taxa de incêndio" do CTE Scan, se você os usar ativamente em suas consultas. Eles não são muito rápidos - eles perdem mesmo para a varredura de tabela usual. [artigo] [artigo]Mas, geralmente, esses diagramas são mais interessantes, mais complicados quando apontamos imediatamente para um segmento e vemos, por exemplo, que mais da metade do tempo todo, algumas Seq Scan “comiam”. Além disso, havia algum tipo de filtro dentro, vários registros foram lançados nele ... Você pode enviar essa foto diretamente para o desenvolvedor e dizer: “Vasya, tudo está ruim com você aqui! Entenda, olhe - algo está errado! Naturalmente, houve um "ancinho".A primeira coisa em que "pisaram" é o problema do arredondamento. O tempo do nó de cada indivíduo no plano é indicado com uma precisão de 1 μs. E quando o número de ciclos de nós excede, por exemplo, 1000 - após a execução, o PostgreSQL o dividiu "até", então, no cálculo reverso, obtemos o tempo total "em algum lugar entre 0,95 ms e 1,05 ms". Quando a conta é gasta em microssegundos - nada ainda, mas já há [mili] segundos - é necessário levar essas informações em consideração ao "desatar" recursos nos nós do plano "quem consumiu quem consumiu quem".
Naturalmente, houve um "ancinho".A primeira coisa em que "pisaram" é o problema do arredondamento. O tempo do nó de cada indivíduo no plano é indicado com uma precisão de 1 μs. E quando o número de ciclos de nós excede, por exemplo, 1000 - após a execução, o PostgreSQL o dividiu "até", então, no cálculo reverso, obtemos o tempo total "em algum lugar entre 0,95 ms e 1,05 ms". Quando a conta é gasta em microssegundos - nada ainda, mas já há [mili] segundos - é necessário levar essas informações em consideração ao "desatar" recursos nos nós do plano "quem consumiu quem consumiu quem". O segundo ponto, mais complexo, é a distribuição de recursos (esses mesmos buffers) entre nós dinâmicos. Isso nos custou as primeiras 2 semanas no protótipo mais o plus da semana 4.Conseguir esse problema é bastante simples - criamos um CTE e supostamente estamos lendo algo nele. De fato, o PostgreSQL é inteligente e não lê nada aqui. Então pegamos o primeiro registro dele, e os primeiros cem do mesmo CTE.
O segundo ponto, mais complexo, é a distribuição de recursos (esses mesmos buffers) entre nós dinâmicos. Isso nos custou as primeiras 2 semanas no protótipo mais o plus da semana 4.Conseguir esse problema é bastante simples - criamos um CTE e supostamente estamos lendo algo nele. De fato, o PostgreSQL é inteligente e não lê nada aqui. Então pegamos o primeiro registro dele, e os primeiros cem do mesmo CTE.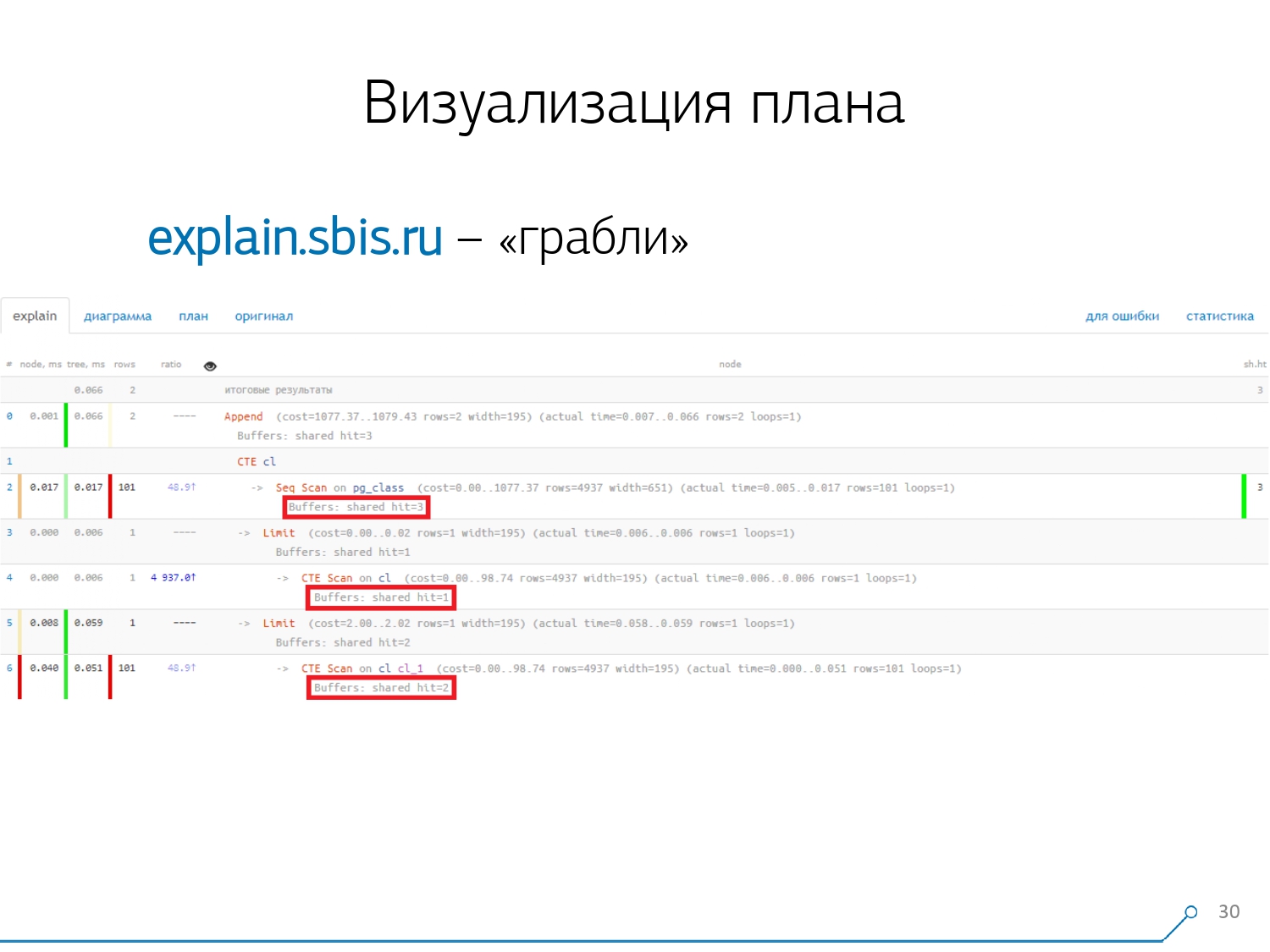 Nós olhamos para o plano e entendemos - estranho, temos 3 buffers (páginas de dados) "consumidos" no Seq Scan, outro 1 no CTE Scan e mais 2 no segundo CTE Scan. Ou seja, se tudo é simplesmente resumido, obtemos 6, mas da placa lemos apenas 3! O CTE Scan não lê nada de qualquer lugar, mas trabalha diretamente com a memória do processo. Ou seja, há claramente algo errado aqui!De fato, verifica-se que aqui todas as 3 páginas de dados solicitadas à Seq Scan, primeiro 1 solicitou a 1ª CTE Scan e, em seguida, a 2ª, e elas leram outras 2. Ou seja, 3 páginas foram lidas no total dados, não 6.
Nós olhamos para o plano e entendemos - estranho, temos 3 buffers (páginas de dados) "consumidos" no Seq Scan, outro 1 no CTE Scan e mais 2 no segundo CTE Scan. Ou seja, se tudo é simplesmente resumido, obtemos 6, mas da placa lemos apenas 3! O CTE Scan não lê nada de qualquer lugar, mas trabalha diretamente com a memória do processo. Ou seja, há claramente algo errado aqui!De fato, verifica-se que aqui todas as 3 páginas de dados solicitadas à Seq Scan, primeiro 1 solicitou a 1ª CTE Scan e, em seguida, a 2ª, e elas leram outras 2. Ou seja, 3 páginas foram lidas no total dados, não 6.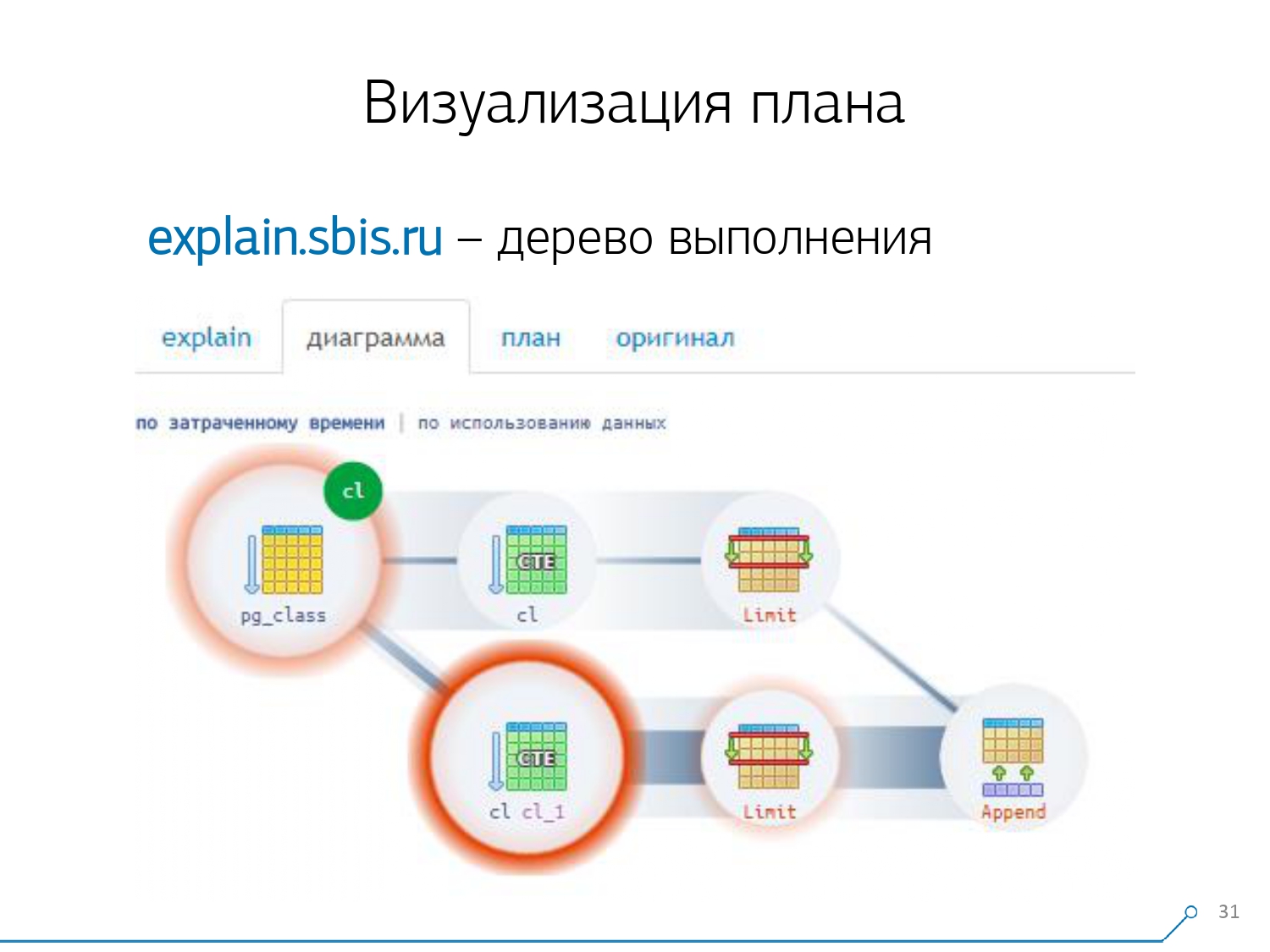 E essa imagem nos levou a entender que a implementação do plano não é mais uma árvore, mas apenas algum tipo de gráfico acíclico. E nós temos um gráfico como este para entendermos "de onde ele veio". Ou seja, aqui criamos um CTE a partir de pg_class e o solicitamos duas vezes, e quase o tempo todo nos levou ao ramo quando solicitamos pela segunda vez. É claro que ler o 101º registro é muito mais caro do que apenas o 1º do tablet.
E essa imagem nos levou a entender que a implementação do plano não é mais uma árvore, mas apenas algum tipo de gráfico acíclico. E nós temos um gráfico como este para entendermos "de onde ele veio". Ou seja, aqui criamos um CTE a partir de pg_class e o solicitamos duas vezes, e quase o tempo todo nos levou ao ramo quando solicitamos pela segunda vez. É claro que ler o 101º registro é muito mais caro do que apenas o 1º do tablet. Nós expiramos por um tempo. Eles disseram: “Agora, Neo, você sabe kung fu! Agora nossa experiência está na sua tela. Agora você pode usá-lo. [artigo]
Nós expiramos por um tempo. Eles disseram: “Agora, Neo, você sabe kung fu! Agora nossa experiência está na sua tela. Agora você pode usá-lo. [artigo]Consolidação de log
Nossos 1000 desenvolvedores deram um suspiro de alívio. Mas entendemos que só temos centenas de servidores de "batalha" e toda essa "copiar e colar" pelos desenvolvedores não é de todo conveniente. Percebemos que precisávamos coletá-lo nós mesmos. Em geral, existe um módulo regular que pode coletar estatísticas; no entanto, ele também precisa ser ativado na configuração - este é o módulo pg_stat_statements . Mas ele não nos convinha.Em primeiro lugar, ele atribui QueryId diferente às mesmas consultas em diferentes esquemas no mesmo banco de dados . Ou seja, se você fizer primeiro
Em geral, existe um módulo regular que pode coletar estatísticas; no entanto, ele também precisa ser ativado na configuração - este é o módulo pg_stat_statements . Mas ele não nos convinha.Em primeiro lugar, ele atribui QueryId diferente às mesmas consultas em diferentes esquemas no mesmo banco de dados . Ou seja, se você fizer primeiro SET search_path = '01'; SELECT * FROM user LIMIT 1;e depois SET search_path = '02';a mesma solicitação, as estatísticas deste módulo terão entradas diferentes e não poderei coletar estatísticas gerais precisamente no contexto desse perfil de solicitação, sem levar em consideração os esquemas.O segundo ponto que nos impediu de usá-lo é a falta de planos . Ou seja, não há plano, apenas a solicitação em si. Vemos o que estava desacelerando, mas não entendemos o porquê. E aqui voltamos ao problema de um conjunto de dados que muda rapidamente.E o último ponto é a falta de "fatos" . Ou seja, é impossível resolver uma instância específica de execução de consulta - ela não existe, existem apenas estatísticas agregadas. Embora seja possível trabalhar com isso, é simplesmente muito difícil.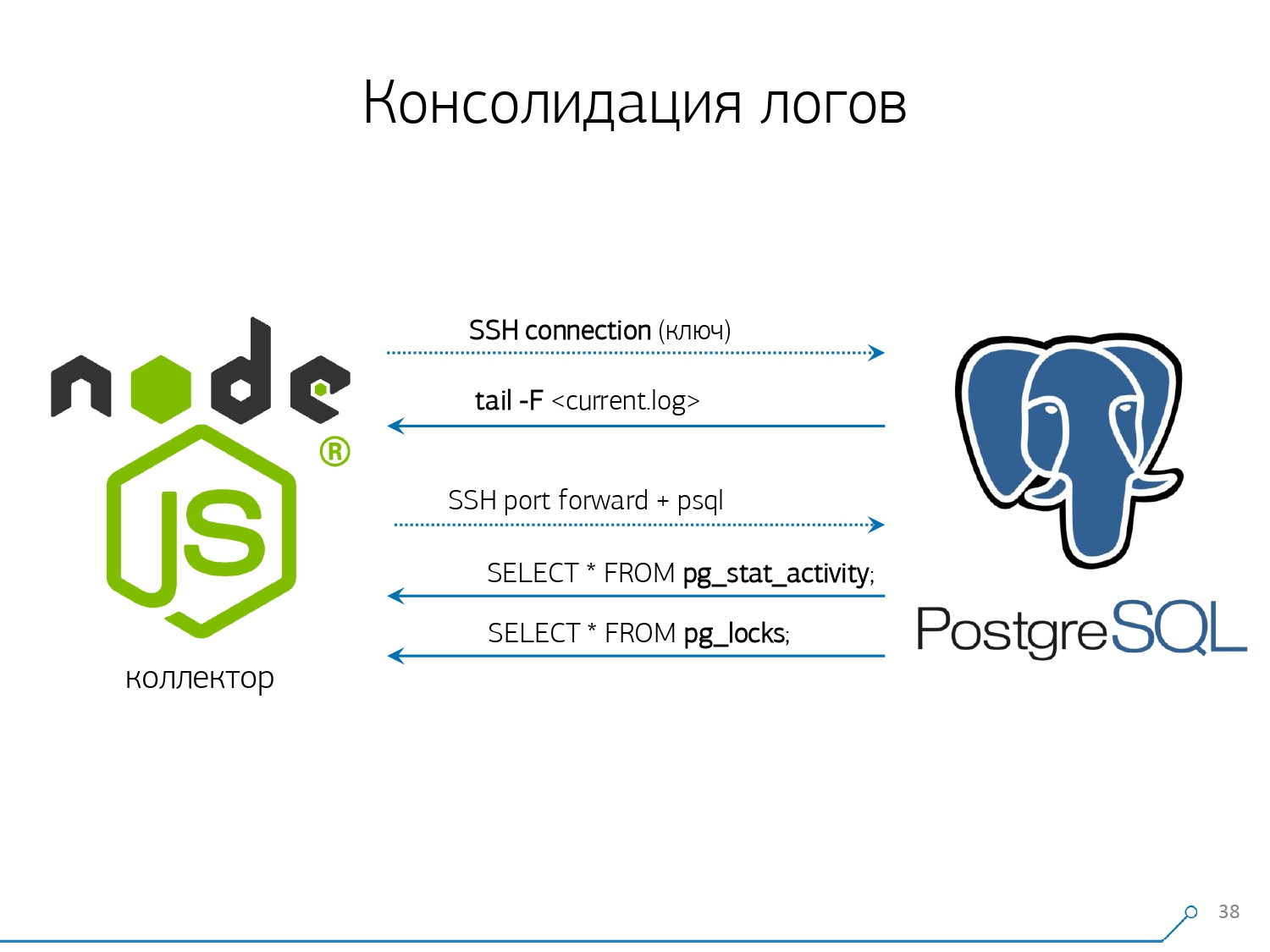 Por isso, decidimos combater o “copiar e colar” e começamos a escrever um colecionador .O coletor é conectado via SSH, "puxa" uma conexão segura para o servidor com o banco de dados usando o certificado e
Por isso, decidimos combater o “copiar e colar” e começamos a escrever um colecionador .O coletor é conectado via SSH, "puxa" uma conexão segura para o servidor com o banco de dados usando o certificado e tail -F"se apega" ao arquivo de log. Então nesta sessãoobtemos um "espelho" completo de todo o arquivo de log que o servidor gera. A carga no próprio servidor é mínima, porque não analisamos nada lá, simplesmente espelhamos o tráfego.Como já começamos a escrever a interface no Node.js, continuamos a escrever o coletor. E essa tecnologia valeu a pena, porque é muito conveniente usar JavaScript para trabalhar com dados de texto mal formatados, que é o log. E a própria infraestrutura do Node.js. como plataforma de back-end permite que você trabalhe fácil e convenientemente com conexões de rede e, de fato, com algum tipo de fluxo de dados.Dessa forma, "puxamos" duas conexões: a primeira é "ouvir" o próprio log e levá-lo para nós mesmos, e a segunda é perguntar periodicamente ao banco de dados. "Mas no log chegou que a placa com oid 123 estava bloqueada", mas não diz nada ao desenvolvedor, e seria bom perguntar ao banco de dados "afinal, o que é OID = 123?" Por isso, solicitamos periodicamente à base algo que ainda não sabemos em casa. "Você simplesmente não levou em consideração, existe uma espécie de abelha parecida com um elefante!" Começamos a desenvolver esse sistema quando queríamos monitorar 10 servidores. O mais crítico em nosso entendimento, sobre o qual houve alguns problemas difíceis de lidar. Porém, durante o primeiro trimestre, conseguimos cem para monitorar - porque o sistema "entrou", todo mundo queria, todo mundo estava confortável.Tudo isso deve ser adicionado, o fluxo de dados é grande, ativo. Na verdade, monitoramos com o que somos capazes de lidar - depois usamos. Também usamos o PostgreSQL como um data warehouse. Mas nada é mais rápido para "derramar" dados nele do que
"Você simplesmente não levou em consideração, existe uma espécie de abelha parecida com um elefante!" Começamos a desenvolver esse sistema quando queríamos monitorar 10 servidores. O mais crítico em nosso entendimento, sobre o qual houve alguns problemas difíceis de lidar. Porém, durante o primeiro trimestre, conseguimos cem para monitorar - porque o sistema "entrou", todo mundo queria, todo mundo estava confortável.Tudo isso deve ser adicionado, o fluxo de dados é grande, ativo. Na verdade, monitoramos com o que somos capazes de lidar - depois usamos. Também usamos o PostgreSQL como um data warehouse. Mas nada é mais rápido para "derramar" dados nele do que COPYainda não há operador .Mas apenas "derramar" os dados não é realmente a nossa tecnologia. Como se você tiver cerca de 50 mil solicitações por segundo em uma centena de servidores, isso gerará 100-150 GB de logs por dia para você. Portanto, tivemos que "serrar" cuidadosamente a base.Primeiro, fizemos o particionamento todos os dias , porque, em geral, ninguém está interessado na correlação entre os dias. Qual é a diferença que você teve ontem, se hoje à noite você lançou uma nova versão do aplicativo - e já algumas novas estatísticas.Em segundo lugar, aprendemos (fomos forçados) a escrever muito, muito rapidamente usandoCOPY . Ou seja, não apenas COPYporque é mais rápido que INSERT, mas ainda mais rápido. O terceiro ponto - tive que abandonar os gatilhos, respectivamente, e da Foreign Keys . Ou seja, não temos integridade absolutamente referencial. Porque se você possui uma tabela na qual existe um par de FK e diz na estrutura do banco de dados que “aqui está uma entrada de log refere-se a FK, por exemplo, um grupo de registros”, quando você a insere, o PostgreSQL não tem nada a fazer, exceto como tomar e executar honestamente
O terceiro ponto - tive que abandonar os gatilhos, respectivamente, e da Foreign Keys . Ou seja, não temos integridade absolutamente referencial. Porque se você possui uma tabela na qual existe um par de FK e diz na estrutura do banco de dados que “aqui está uma entrada de log refere-se a FK, por exemplo, um grupo de registros”, quando você a insere, o PostgreSQL não tem nada a fazer, exceto como tomar e executar honestamente SELECT 1 FROM master_fk1_table WHERE ...com o identificador que você está tentando inserir - apenas para verificar se essa entrada existe, se você não está "interrompendo" essa chave estrangeira com sua inserção.Em vez de um registro na tabela de destino e seus índices, obtemos mais uma leitura de todas as tabelas às quais ele se refere. E não precisamos disso: nossa tarefa é escrever o máximo possível e o mais rápido possível, com o mínimo de carga. Então FK - baixo!O próximo ponto é agregação e hash. Inicialmente, eles foram implementados em nosso banco de dados - afinal, é conveniente, imediatamente, quando uma gravação chegar, fazer "mais um" em algum tipo de placa diretamente no gatilho . É bom, conveniente, mas a mesma coisa é ruim - insira um registro, mas você é obrigado a ler e escrever outra coisa de outra tabela. Além disso, não apenas isso, leia e escreva - e também faça isso sempre.Agora imagine que você tem uma placa na qual simplesmente conta o número de solicitações que passaram em um host específico:+1, +1, +1, ..., +1. E você, em princípio, não precisa disso - tudo isso pode ser resumido na memória do coletor e enviado ao banco de dados de cada vez +10.Sim, sua integridade lógica pode "desmoronar" no caso de alguns problemas, mas esse é um caso quase irreal - porque você tem um servidor normal, ele possui uma bateria no controlador, um log de transações, um log no sistema de arquivos ... Em geral, não Vale a pena. Não vale a pena a perda de produtividade que você obtém devido ao trabalho de gatilhos / FK, os custos incorridos ao mesmo tempo.A mesma coisa com hash. Uma certa solicitação voa para você, você calcula um determinado identificador do banco de dados, escreve no banco de dados e depois diz a todos. Tudo está bem, até que, no momento da gravação, uma segunda pessoa chega até você que deseja gravá-la - e você tem uma trava, e isso já é ruim. Portanto, se você pode remover a geração de alguns IDs no cliente (em relação ao banco de dados), é melhor fazer isso.Éramos apenas ideais para usar o MD5 a partir do texto - uma solicitação, plano, modelo, ... Calculamos no lado do coletor e “despejamos” o ID já preparado no banco de dados. O comprimento do MD5 e o particionamento diário nos permitem não se preocupar com possíveis colisões.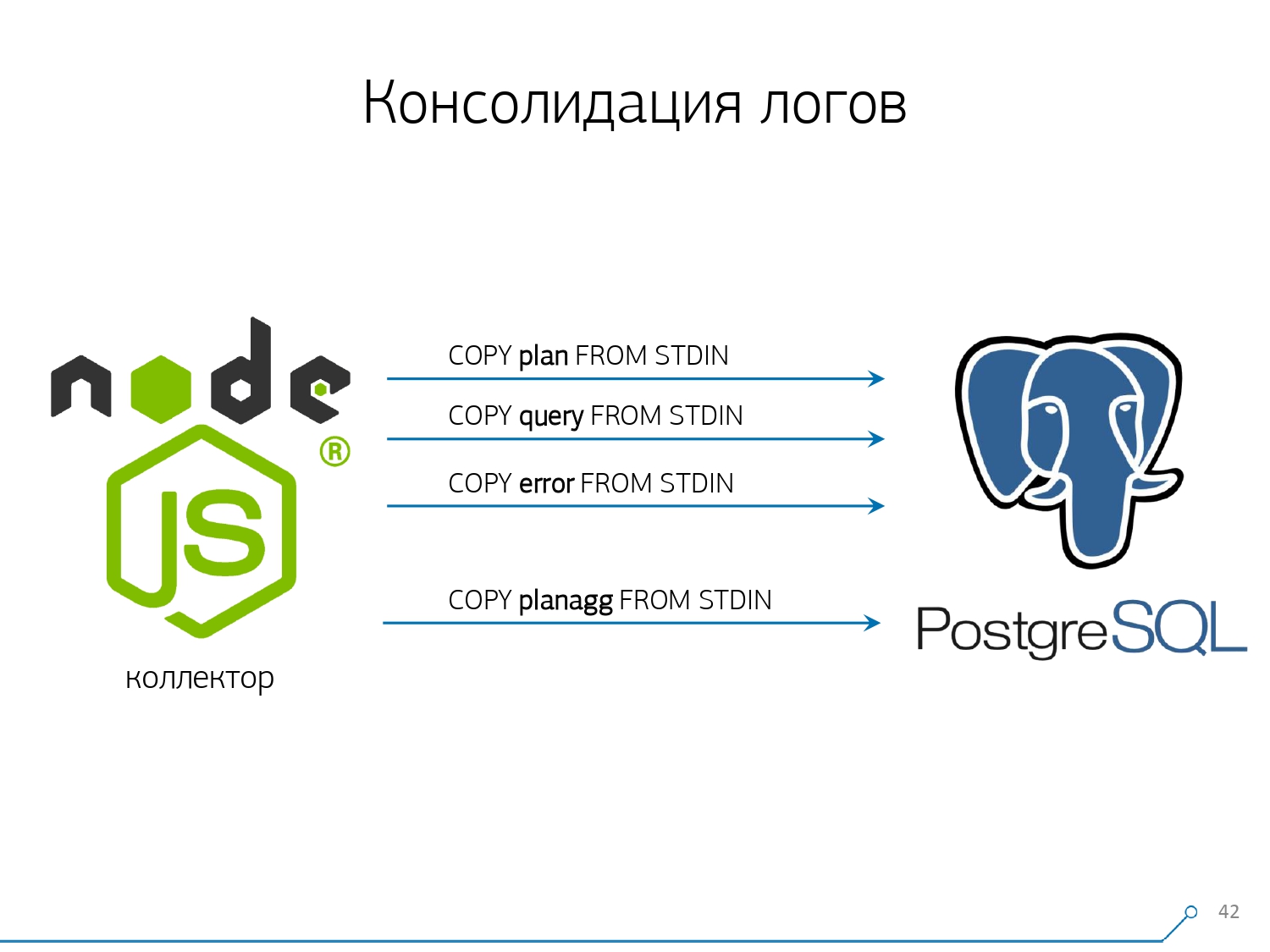 Mas, para gravar tudo isso rapidamente, precisávamos modificar o próprio procedimento de gravação.Como você costuma escrever dados? Temos algum tipo de conjunto de dados, decompomos-o em várias tabelas e depois COPY - primeiro na primeira, depois na segunda, na terceira ... É inconveniente, porque meio que escrevemos um fluxo de dados em três etapas seqüencialmente. Desagradável. É possível fazer mais rápido? Pode!Para fazer isso, basta decompor esses fluxos em paralelo. Acontece que temos erros, solicitações, modelos, bloqueios, voando em fluxos separados ... - e escrevemos tudo em paralelo. Para fazer isso, basta manter o canal COPY permanentemente aberto em cada tabela de destino individual .
Mas, para gravar tudo isso rapidamente, precisávamos modificar o próprio procedimento de gravação.Como você costuma escrever dados? Temos algum tipo de conjunto de dados, decompomos-o em várias tabelas e depois COPY - primeiro na primeira, depois na segunda, na terceira ... É inconveniente, porque meio que escrevemos um fluxo de dados em três etapas seqüencialmente. Desagradável. É possível fazer mais rápido? Pode!Para fazer isso, basta decompor esses fluxos em paralelo. Acontece que temos erros, solicitações, modelos, bloqueios, voando em fluxos separados ... - e escrevemos tudo em paralelo. Para fazer isso, basta manter o canal COPY permanentemente aberto em cada tabela de destino individual . Ou seja, o coletor sempre tem um fluxoem que posso escrever os dados necessários. Mas para que o banco de dados veja esses dados e alguém não fique travado nos bloqueios, aguardando a gravação desses dados, COPY deve ser interrompido em uma determinada frequência . Para nós, um período da ordem de 100ms acabou sendo o mais eficaz - feche e abra-o imediatamente novamente na mesma mesa. E se não temos um fluxo em alguns picos, fazemos o pool para um determinado limite.Além disso, descobrimos que, para esse perfil de carga, qualquer agregação quando os registros são coletados em pacotes é ruim. O mal clássico está
Ou seja, o coletor sempre tem um fluxoem que posso escrever os dados necessários. Mas para que o banco de dados veja esses dados e alguém não fique travado nos bloqueios, aguardando a gravação desses dados, COPY deve ser interrompido em uma determinada frequência . Para nós, um período da ordem de 100ms acabou sendo o mais eficaz - feche e abra-o imediatamente novamente na mesma mesa. E se não temos um fluxo em alguns picos, fazemos o pool para um determinado limite.Além disso, descobrimos que, para esse perfil de carga, qualquer agregação quando os registros são coletados em pacotes é ruim. O mal clássico está INSERT ... VALUESalém de 1000 registros. Porque neste momento você tem um pico de gravação na mídia, e todos os outros que estão tentando gravar algo no disco aguardam.Para se livrar de tais anomalias, simplesmente não agregue nada, não faça buffer . E se ocorrer buffer no disco (felizmente, a API Stream no Node.js permite que você descubra) - adie essa conexão. É quando o evento chega até você, que é gratuito novamente - escreva para ele a partir da fila acumulada. Enquanto isso, está ocupado - pegue o próximo de graça da piscina e escreva para ele.Antes de implementar essa abordagem para a gravação de dados, tínhamos aproximadamente operações de gravação em 4K e, dessa forma, reduzimos a carga em 4 vezes. Agora eles cresceram mais 6 vezes devido a novas bases observáveis - até 100 MB / s. E agora armazenamos logs nos últimos 3 meses no valor de 10 a 15 TB, esperando que em apenas três meses qualquer desenvolvedor possa resolver qualquer problema.Entendemos os problemas
Mas apenas a coleta de todos esses dados é bom, útil, apropriado, mas não suficiente - é preciso entendê-los. Porque são milhões de planos diferentes por dia. Mas milhões são incontroláveis, você deve primeiro fazer "menos". E, antes de tudo, é necessário decidir como você organizará esse "menor".Identificamos para nós três pontos-chave:
Mas milhões são incontroláveis, você deve primeiro fazer "menos". E, antes de tudo, é necessário decidir como você organizará esse "menor".Identificamos para nós três pontos-chave:- quem enviou essa solicitação,
ou seja, de qual aplicativo ele "voou": interface da web, back-end, sistema de pagamento ou algo mais. - onde isso aconteceu
Em qual servidor específico. Como se você tiver vários servidores em um aplicativo e, de repente, um "embotado" (porque o "disco apodreceu", "a memória vazou", outros problemas), será necessário abordar especificamente o servidor. - como o problema se manifestou de uma maneira ou de outra
Para entender “quem” nos enviou a solicitação, usamos uma ferramenta regular - definindo uma variável de sessão: SET application_name = '{bl-host}:{bl-method}';- envie o nome do host da lógica de negócios a partir da qual a solicitação é feita e o nome do método ou aplicativo que a iniciou.Depois de passarmos o "proprietário" da solicitação, ela deve ser exibida no log - para isso, configuramos a variável log_line_prefix = ' %m [%p:%v] [%d] %r %a'. Qualquer pessoa interessada pode ver no manual o que isso tudo significa. Acontece que vemos no log:- Tempo
- identificadores de processo e transação
- nome base
- IP da pessoa que enviou esta solicitação
- e nome do método
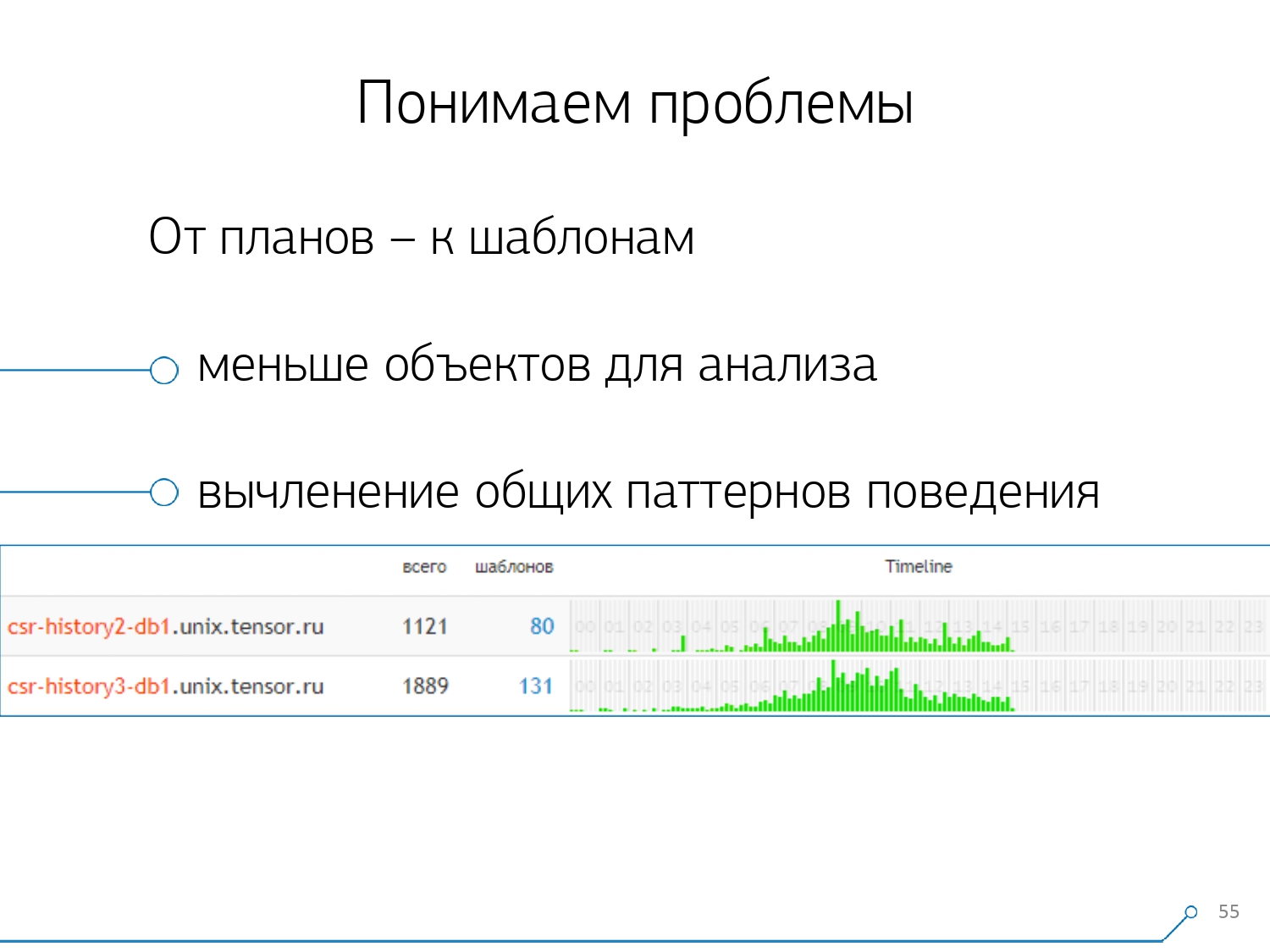 Então percebemos que não é muito interessante observar a correlação de uma solicitação entre servidores diferentes. Isso acontece com pouca frequência quando você tem um aplicativo que craps igualmente aqui e ali. Mas, mesmo que seja o mesmo, observe qualquer um desses servidores.Portanto, a seção “um servidor - um dia” acabou sendo suficiente para qualquer análise.A primeira seção analítica é o próprio "modelo" - uma forma abreviada de apresentação do plano, livre de todos os indicadores numéricos. A segunda seção é o aplicativo ou método, e a terceira é o nó específico do plano que nos causou problemas.Quando passamos de instâncias específicas para modelos, recebemos imediatamente duas vantagens:
Então percebemos que não é muito interessante observar a correlação de uma solicitação entre servidores diferentes. Isso acontece com pouca frequência quando você tem um aplicativo que craps igualmente aqui e ali. Mas, mesmo que seja o mesmo, observe qualquer um desses servidores.Portanto, a seção “um servidor - um dia” acabou sendo suficiente para qualquer análise.A primeira seção analítica é o próprio "modelo" - uma forma abreviada de apresentação do plano, livre de todos os indicadores numéricos. A segunda seção é o aplicativo ou método, e a terceira é o nó específico do plano que nos causou problemas.Quando passamos de instâncias específicas para modelos, recebemos imediatamente duas vantagens:
, .
, «» - , . , - , , , — , , — , , . , , .
 O restante dos métodos se baseia nos indicadores que extraímos do plano: quantas vezes esse padrão ocorreu, o tempo total e médio, quantos dados foram lidos no disco e quanto da memória ...Como você, por exemplo, acessa a página de análise por host, consulte - algo demais no disco para ler o começo. O disco no servidor não lida - e quem lê a partir dele?E você pode classificar por qualquer coluna e decidir com o que irá lidar agora - com a carga no processador ou no disco ou com o número total de solicitações ... Classificadas, com aparência de "superior", reparadas - lançaram uma nova versão do aplicativo.[vídeo aula]E imediatamente você pode ver diferentes aplicativos que vêm com o mesmo modelo de uma solicitação como
O restante dos métodos se baseia nos indicadores que extraímos do plano: quantas vezes esse padrão ocorreu, o tempo total e médio, quantos dados foram lidos no disco e quanto da memória ...Como você, por exemplo, acessa a página de análise por host, consulte - algo demais no disco para ler o começo. O disco no servidor não lida - e quem lê a partir dele?E você pode classificar por qualquer coluna e decidir com o que irá lidar agora - com a carga no processador ou no disco ou com o número total de solicitações ... Classificadas, com aparência de "superior", reparadas - lançaram uma nova versão do aplicativo.[vídeo aula]E imediatamente você pode ver diferentes aplicativos que vêm com o mesmo modelo de uma solicitação comoSELECT * FROM users WHERE login = 'Vasya'. Front-end, back-end, processamento ... E você se pergunta por que o usuário deve ler o processamento se não interagir com ele.O caminho oposto é ver imediatamente a partir do aplicativo o que está fazendo. Por exemplo, um frontend é isso, isso, isso e isso uma vez por hora (apenas a linha do tempo ajuda). E imediatamente surge a pergunta - parece que não é da conta do front-end fazer algo uma vez por hora ... Depois de algum tempo, percebemos que não tínhamos estatísticas agregadas em termos de nós do plano . Isolamos dos planos apenas os nós que fazem algo com os dados das próprias tabelas (os lê / escreve por índice ou não). De fato, em relação à figura anterior, apenas um aspecto é adicionado - quantos registros esse nó trouxe para nós e quantos foram descartados (linhas removidas pelo filtro).Você não tem um índice adequado na placa, faz um pedido, ele passa além do índice, cai na Seq Scan ... você filtrou todos os registros, exceto um. E por que você precisa de 100 milhões de registros filtrados por dia, é melhor rolar o índice?
Depois de algum tempo, percebemos que não tínhamos estatísticas agregadas em termos de nós do plano . Isolamos dos planos apenas os nós que fazem algo com os dados das próprias tabelas (os lê / escreve por índice ou não). De fato, em relação à figura anterior, apenas um aspecto é adicionado - quantos registros esse nó trouxe para nós e quantos foram descartados (linhas removidas pelo filtro).Você não tem um índice adequado na placa, faz um pedido, ele passa além do índice, cai na Seq Scan ... você filtrou todos os registros, exceto um. E por que você precisa de 100 milhões de registros filtrados por dia, é melhor rolar o índice? Depois de examinar todos os planos por nós, percebemos que existem algumas estruturas típicas nos planos que provavelmente parecerão suspeitas. E seria bom dizer ao desenvolvedor: “Amigo, aqui você primeiro lê por índice, depois classifica e depois corta” - como regra, há um registro.Todo mundo que escreveu consultas com esse padrão provavelmente se deparou com: "Dê-me a última ordem para Vasya, a data dele". E se você não tiver um índice por data ou o índice usado não tiver uma data, siga exatamente esse "rake" e prossiga. .Mas sabemos que esse é um "rake" - então por que não dizer imediatamente ao desenvolvedor o que ele deve fazer? Assim, abrindo o plano agora, nosso desenvolvedor imediatamente vê uma bela imagem com avisos, onde é imediatamente informado: "Você tem problemas aqui e aqui, mas eles são resolvidos dessa maneira".Como resultado, a quantidade de experiência necessária para resolver problemas no início e agora caiu significativamente. Aqui nós temos essa ferramenta.
Depois de examinar todos os planos por nós, percebemos que existem algumas estruturas típicas nos planos que provavelmente parecerão suspeitas. E seria bom dizer ao desenvolvedor: “Amigo, aqui você primeiro lê por índice, depois classifica e depois corta” - como regra, há um registro.Todo mundo que escreveu consultas com esse padrão provavelmente se deparou com: "Dê-me a última ordem para Vasya, a data dele". E se você não tiver um índice por data ou o índice usado não tiver uma data, siga exatamente esse "rake" e prossiga. .Mas sabemos que esse é um "rake" - então por que não dizer imediatamente ao desenvolvedor o que ele deve fazer? Assim, abrindo o plano agora, nosso desenvolvedor imediatamente vê uma bela imagem com avisos, onde é imediatamente informado: "Você tem problemas aqui e aqui, mas eles são resolvidos dessa maneira".Como resultado, a quantidade de experiência necessária para resolver problemas no início e agora caiu significativamente. Aqui nós temos essa ferramenta.
Source: https://habr.com/ru/post/undefined/
All Articles