Durante anos, especialistas em C ++ discutem a semântica de valores, imutabilidade e compartilhamento de recursos por meio da comunicação. Sobre um novo mundo sem mutexes e raças, sem padrões de Comando e Observador. De fato, nem tudo é tão simples. O principal problema ainda está em nossas estruturas de dados. Estruturas de dados imutáveis não alteram seus valores. Para fazer algo com eles, você precisa criar novos valores. Os valores antigos permanecem no mesmo local, para que possam ser lidos de diferentes fluxos sem problemas e bloqueios. Como resultado, os recursos podem ser compartilhados de maneira mais racional e ordenada, porque valores antigos e novos podem usar dados comuns. Graças a isso, eles são muito mais rápidos para comparar e armazenar de forma compacta o histórico das operações com a possibilidade de cancelamento. Tudo isso se encaixa perfeitamente em sistemas interativos e multiencadeados: essas estruturas de dados simplificam a arquitetura dos aplicativos de desktop e permitem que os serviços sejam melhor dimensionados. Estruturas imutáveis são o segredo do sucesso de Clojure e Scala, e até a comunidade JavaScript agora se beneficia delas, porque elas têm a biblioteca Immutable.js,escrito nas entranhas da empresa Facebook.Sob o corte - vídeo e tradução do relatório Juan Puente da conferência C ++ Russia 2019 Moscow. Juan fala sobre o Immer , uma biblioteca de estruturas imutáveis para C ++. No post:
Estruturas de dados imutáveis não alteram seus valores. Para fazer algo com eles, você precisa criar novos valores. Os valores antigos permanecem no mesmo local, para que possam ser lidos de diferentes fluxos sem problemas e bloqueios. Como resultado, os recursos podem ser compartilhados de maneira mais racional e ordenada, porque valores antigos e novos podem usar dados comuns. Graças a isso, eles são muito mais rápidos para comparar e armazenar de forma compacta o histórico das operações com a possibilidade de cancelamento. Tudo isso se encaixa perfeitamente em sistemas interativos e multiencadeados: essas estruturas de dados simplificam a arquitetura dos aplicativos de desktop e permitem que os serviços sejam melhor dimensionados. Estruturas imutáveis são o segredo do sucesso de Clojure e Scala, e até a comunidade JavaScript agora se beneficia delas, porque elas têm a biblioteca Immutable.js,escrito nas entranhas da empresa Facebook.Sob o corte - vídeo e tradução do relatório Juan Puente da conferência C ++ Russia 2019 Moscow. Juan fala sobre o Immer , uma biblioteca de estruturas imutáveis para C ++. No post:- vantagens arquitetônicas da imunidade;
- criação de um tipo de vetor persistente eficaz baseado em árvores RRB;
- análise da arquitetura no exemplo de um editor de texto simples.
A tragédia da arquitetura baseada em valor
Para entender a importância de estruturas de dados imutáveis, discutimos a semântica de valores. Esse é um recurso muito importante do C ++; considero uma das principais vantagens dessa linguagem. Por tudo isso, é muito difícil usar a semântica de valores como gostaríamos. Acredito que essa é a tragédia da arquitetura baseada em valor, e o caminho para essa tragédia é pavimentado com boas intenções. Suponha que precisamos escrever software interativo com base em um modelo de dados com uma representação de um documento editável pelo usuário. Quando a arquitectura com base nos valores que estão no centro deste modelo usa tipos simples e conveniente de valores que já existem na língua: vector, map, tuple,struct. A lógica do aplicativo é criada a partir de funções que recebem documentos por valor e retornam uma nova versão de um documento por valor. Este documento pode mudar dentro da função (como acontece abaixo), mas a semântica dos valores em C ++, aplicada ao argumento por valor e o tipo de retorno por valor, garante que não haja efeitos colaterais.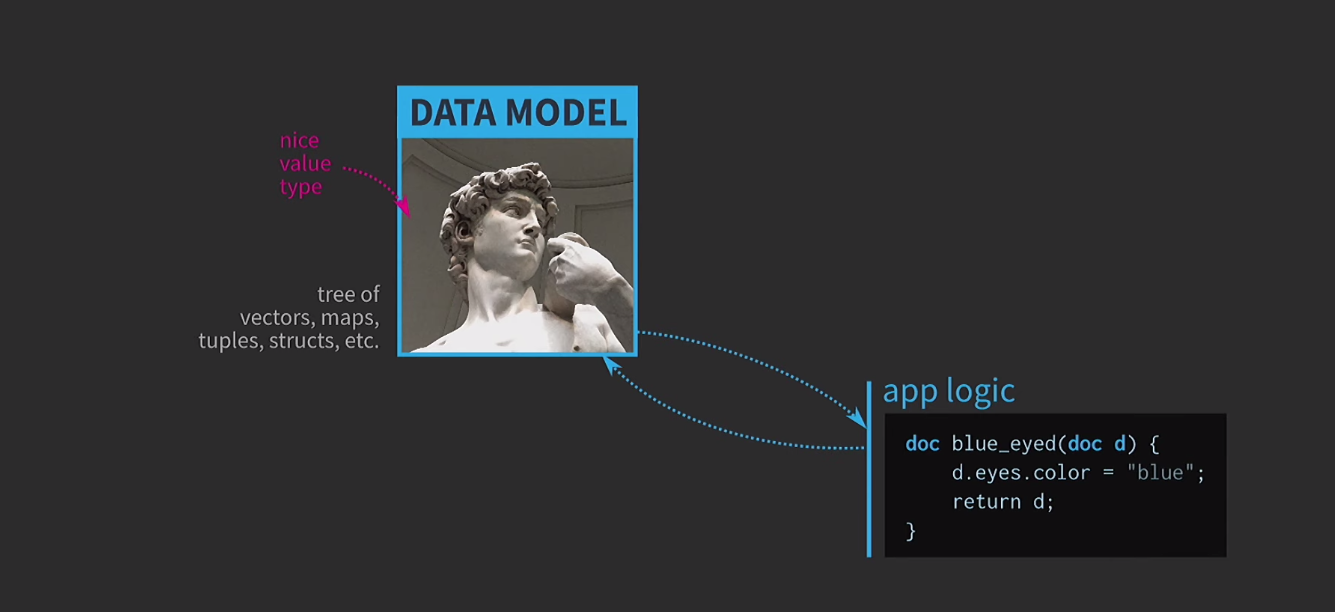 Esse recurso é muito fácil de analisar e testar.
Esse recurso é muito fácil de analisar e testar. Como estamos trabalhando com valores, tentaremos implementar o desfazer da ação. Isso pode ser difícil, mas com a nossa abordagem é uma tarefa trivial: temos
Como estamos trabalhando com valores, tentaremos implementar o desfazer da ação. Isso pode ser difícil, mas com a nossa abordagem é uma tarefa trivial: temos std::vectorcom diferentes estados várias cópias do documento.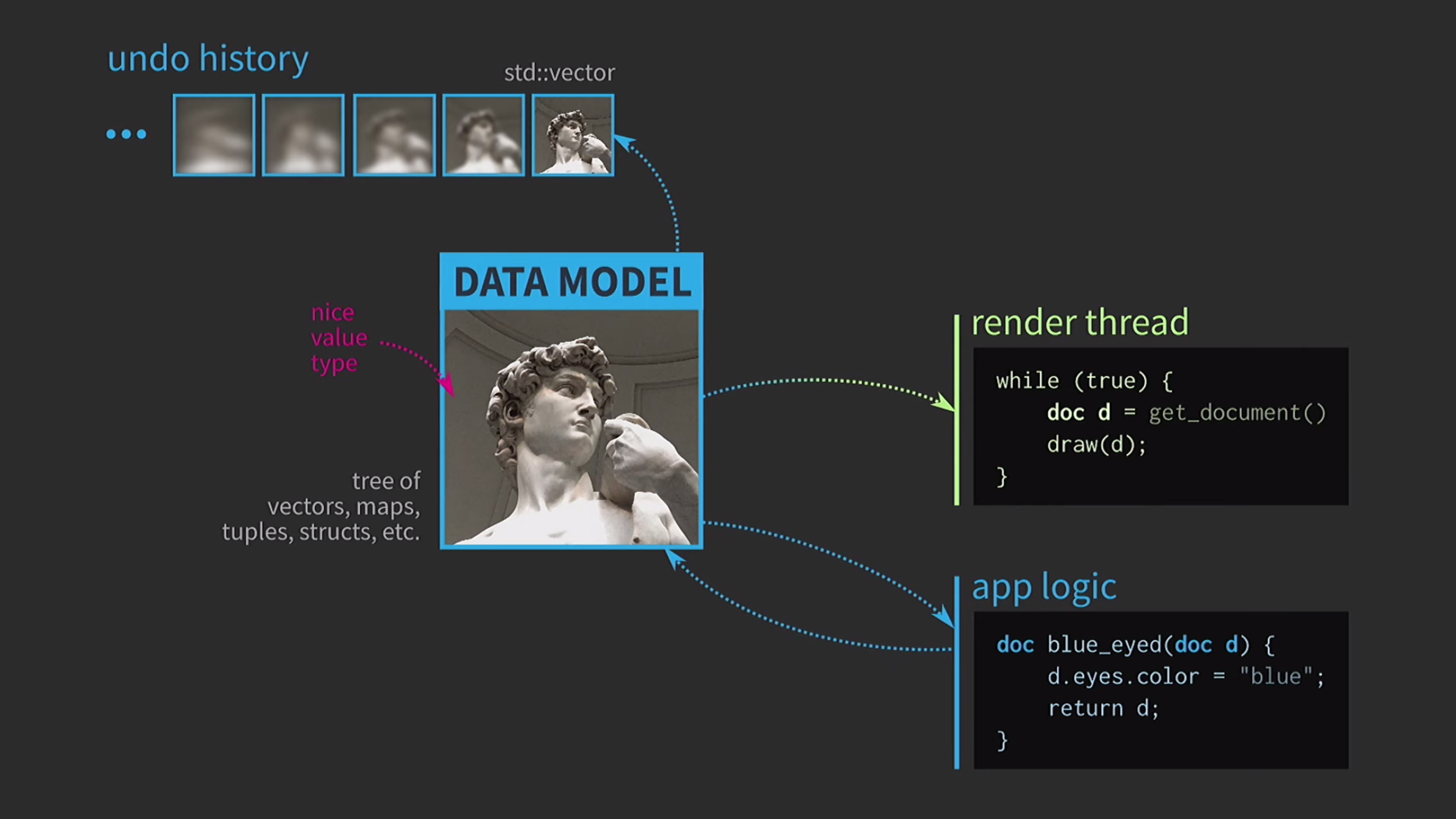 Suponha que também tenhamos uma interface do usuário e, para garantir sua capacidade de resposta, o mapeamento da interface do usuário precise ser feito em um encadeamento separado. O documento é enviado para outro fluxo por mensagem e a interação também ocorre com base nas mensagens, e não através do compartilhamento do estado usando
Suponha que também tenhamos uma interface do usuário e, para garantir sua capacidade de resposta, o mapeamento da interface do usuário precise ser feito em um encadeamento separado. O documento é enviado para outro fluxo por mensagem e a interação também ocorre com base nas mensagens, e não através do compartilhamento do estado usando mutexes. Quando a cópia é recebida pelo segundo fluxo, você pode executar todas as operações necessárias. Salvar um documento em disco geralmente é muito lento, especialmente se o documento for grande. Portanto, o uso
Salvar um documento em disco geralmente é muito lento, especialmente se o documento for grande. Portanto, o uso std::asyncdesta operação é realizado de forma assíncrona. Usamos um lambda, colocamos um sinal de igual dentro dele para ter uma cópia e agora você pode salvar sem outros tipos primitivos de sincronização.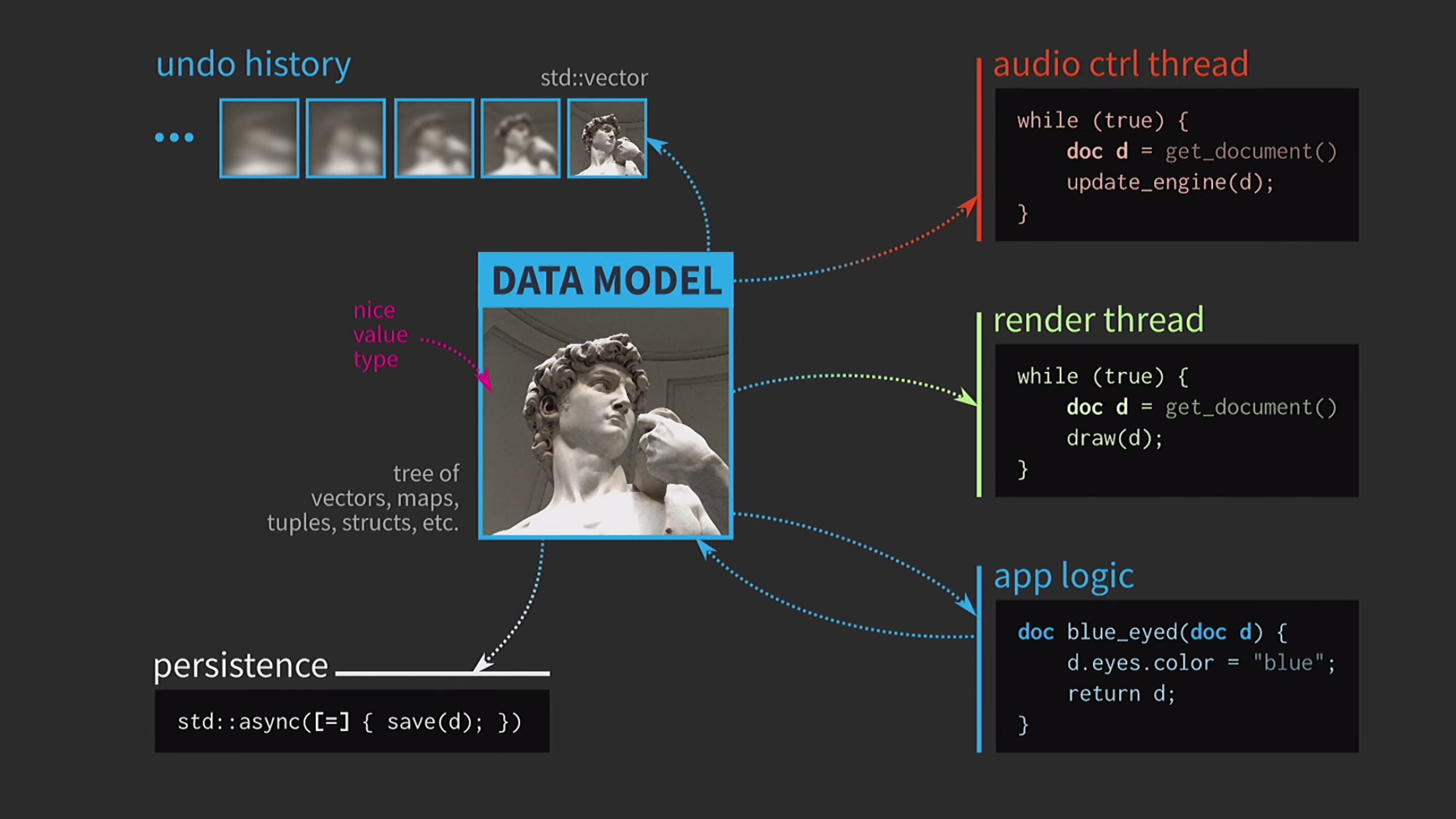 Além disso, suponha que também tenhamos um fluxo de controle de som. Como eu disse, trabalhei muito com software de música e o som é outra representação do nosso documento, ele deve estar em um fluxo separado. Portanto, também é necessária uma cópia do documento para esse fluxo.Como resultado, obtivemos um esquema muito bonito, mas não muito realista.
Além disso, suponha que também tenhamos um fluxo de controle de som. Como eu disse, trabalhei muito com software de música e o som é outra representação do nosso documento, ele deve estar em um fluxo separado. Portanto, também é necessária uma cópia do documento para esse fluxo.Como resultado, obtivemos um esquema muito bonito, mas não muito realista.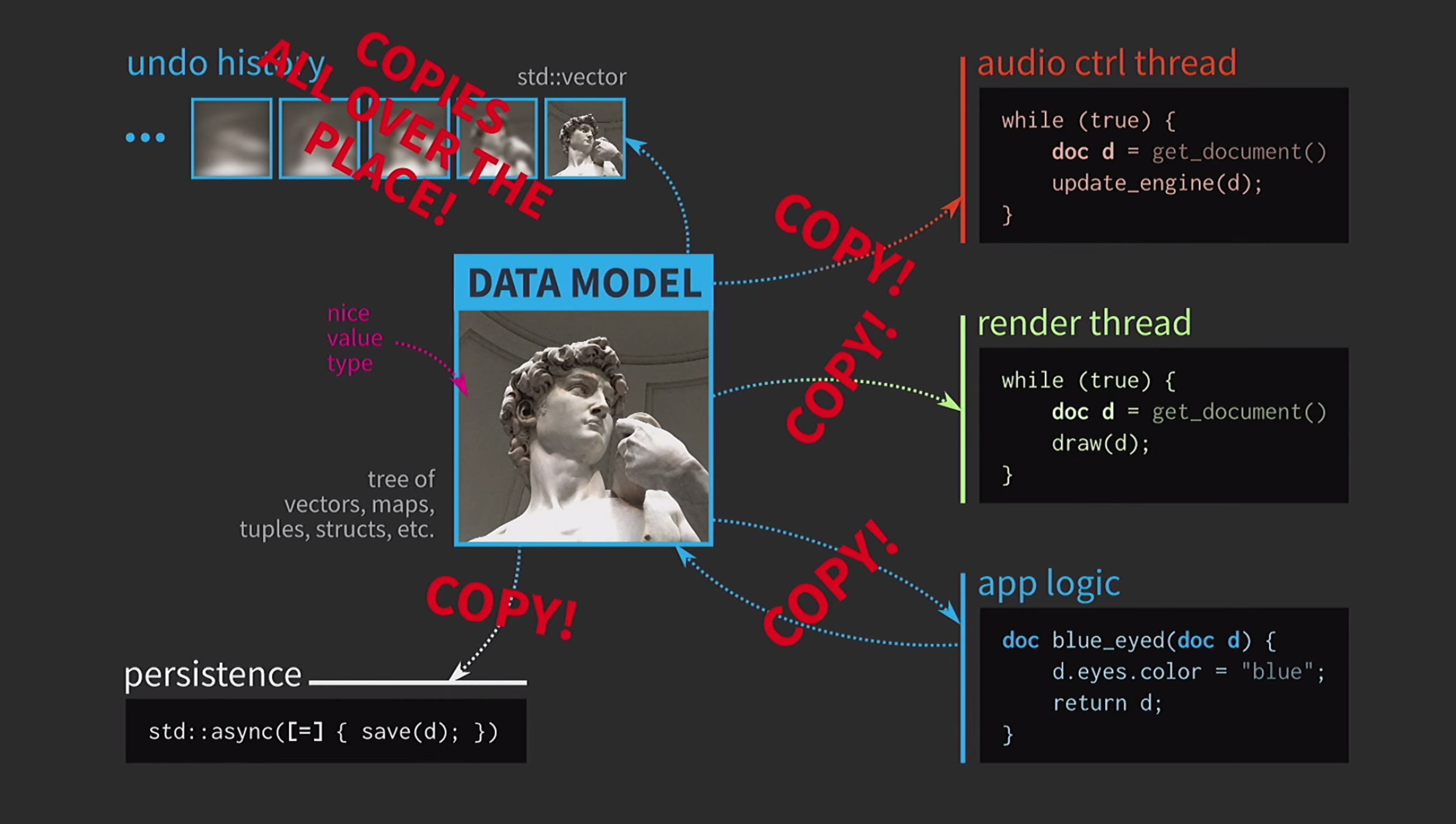 Ele constantemente precisa copiar documentos, o histórico de ações para cancelamento leva gigabytes e, para cada renderização da interface do usuário, é necessário fazer uma cópia profunda do documento. Em geral, todas as interações são muito caras.
Ele constantemente precisa copiar documentos, o histórico de ações para cancelamento leva gigabytes e, para cada renderização da interface do usuário, é necessário fazer uma cópia profunda do documento. Em geral, todas as interações são muito caras.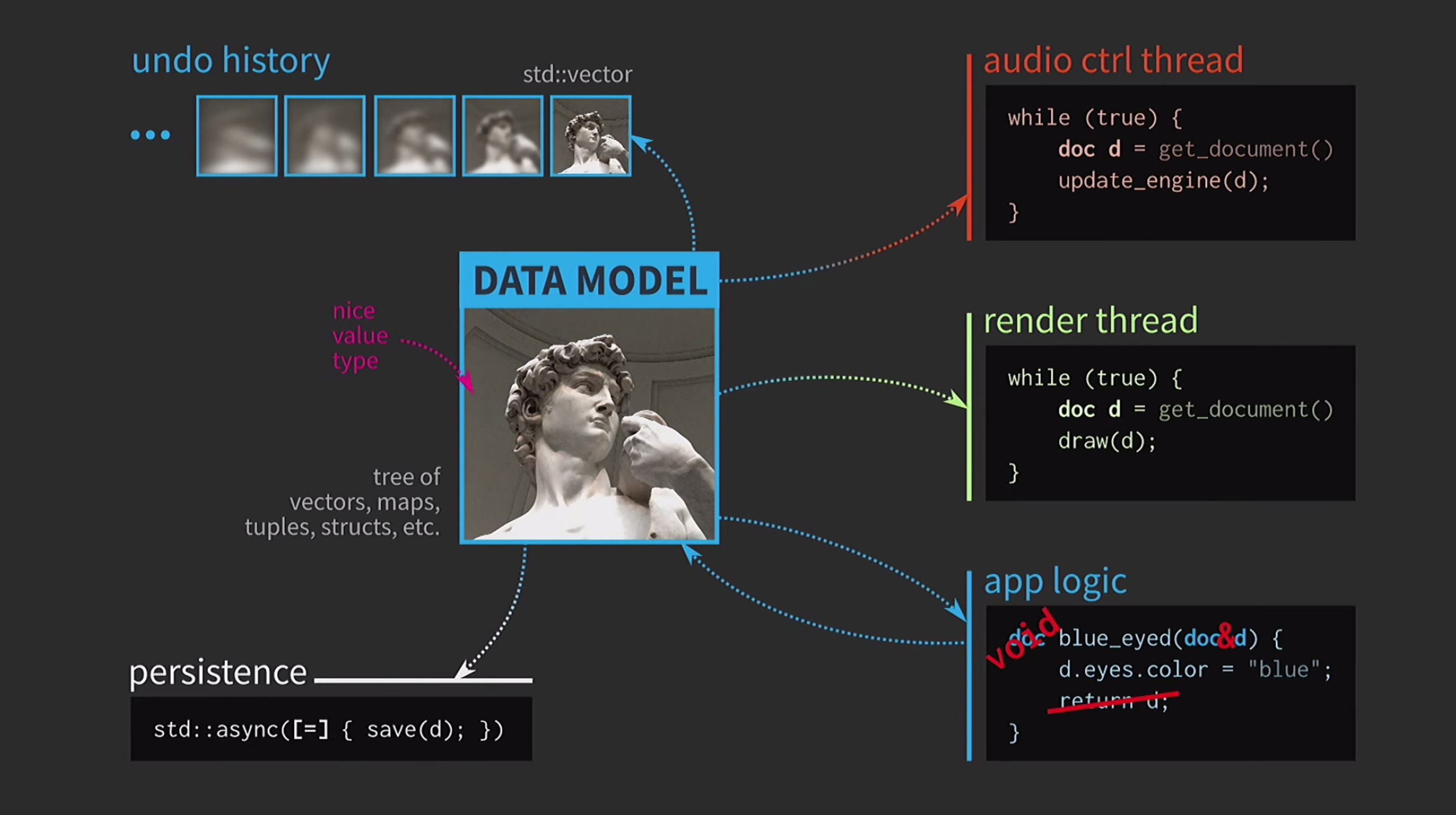 O que o desenvolvedor do C ++ está fazendo nessa situação? Em vez de aceitar um documento por valor, a lógica do aplicativo agora aceita um link para o documento e o atualiza, se necessário. Nesse caso, você não precisa retornar nada. Mas agora não estamos lidando com valores, mas com objetos e locais. Isso cria novos problemas: se houver um link para o estado com acesso compartilhado, você precisará dele
O que o desenvolvedor do C ++ está fazendo nessa situação? Em vez de aceitar um documento por valor, a lógica do aplicativo agora aceita um link para o documento e o atualiza, se necessário. Nesse caso, você não precisa retornar nada. Mas agora não estamos lidando com valores, mas com objetos e locais. Isso cria novos problemas: se houver um link para o estado com acesso compartilhado, você precisará dele mutex. Isso é extremamente caro, portanto haverá alguma representação da nossa interface do usuário na forma de uma árvore extremamente complexa de vários Widgets.Todos esses elementos devem receber atualizações quando um documento é alterado, portanto, é necessário algum mecanismo de enfileiramento para sinais de alteração. Além disso, o histórico do documento não é mais um conjunto de estados; será uma implementação do padrão de equipe. A operação deve ser implementada duas vezes, em uma direção e na outra, e verifique se tudo é simétrico. Salvar em um encadeamento separado já é muito difícil, portanto, isso terá que ser abandonado.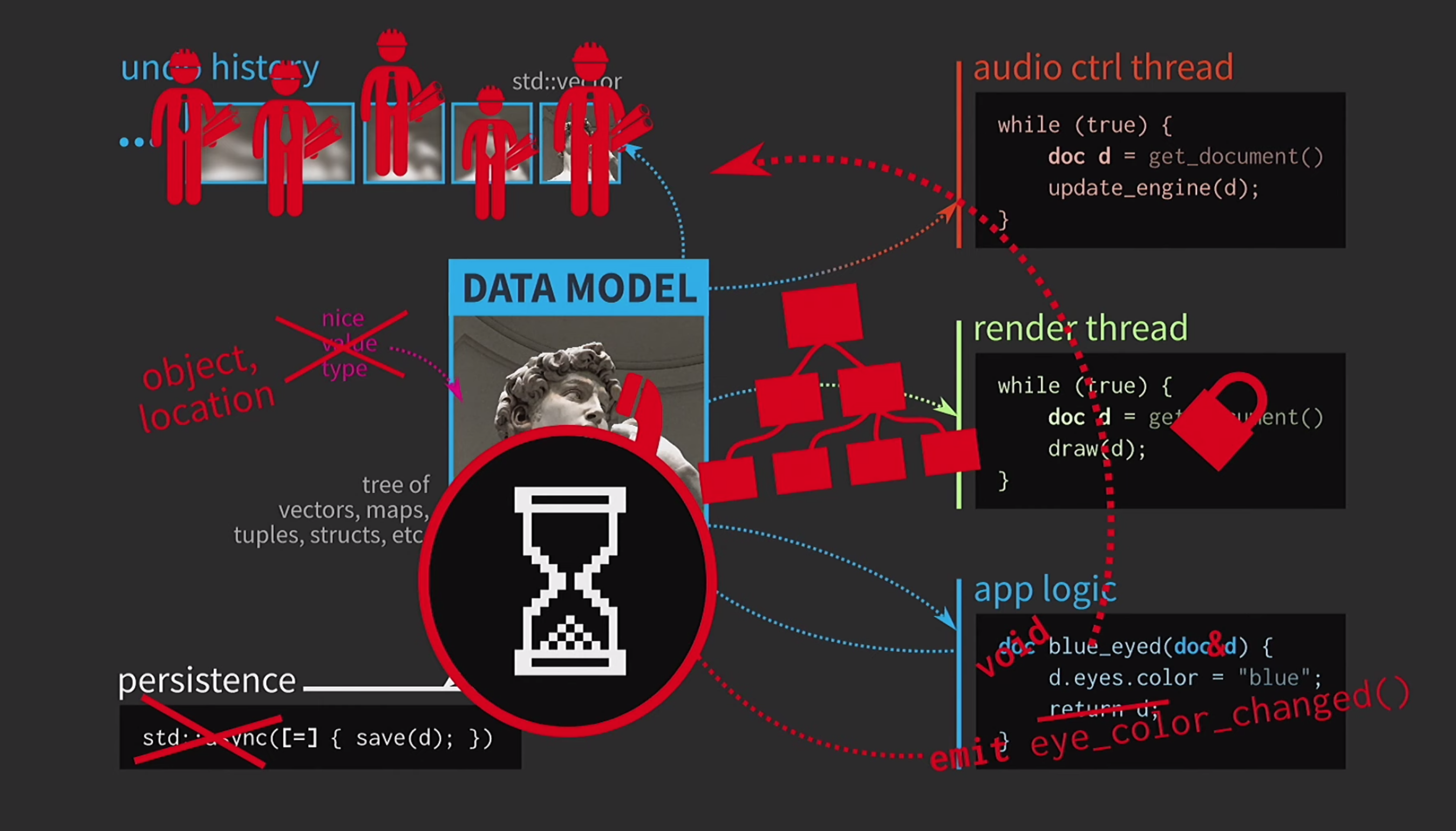 Os usuários já estão acostumados com a imagem da ampulheta, então tudo bem se eles esperarem um pouco. Outra coisa é assustadora - o monstro das massas agora governa nosso código.Em que ponto tudo correu ladeira abaixo? Nós projetamos nosso código muito bem e tivemos que comprometer devido à cópia. Mas em C ++, a cópia é necessária para passar por valor apenas para dados mutáveis. Se o objeto for imutável, o operador de atribuição poderá ser implementado para que ele copie apenas o ponteiro para a representação interna e nada mais.
Os usuários já estão acostumados com a imagem da ampulheta, então tudo bem se eles esperarem um pouco. Outra coisa é assustadora - o monstro das massas agora governa nosso código.Em que ponto tudo correu ladeira abaixo? Nós projetamos nosso código muito bem e tivemos que comprometer devido à cópia. Mas em C ++, a cópia é necessária para passar por valor apenas para dados mutáveis. Se o objeto for imutável, o operador de atribuição poderá ser implementado para que ele copie apenas o ponteiro para a representação interna e nada mais.const auto v0 = vector<int>{};
Considere uma estrutura de dados que poderia nos ajudar. No vetor abaixo, todos os métodos estão marcados como const, portanto, é imutável. Na execução .push_back, o vetor não é atualizado; em vez disso, um novo vetor é retornado, ao qual os dados transferidos são adicionados. Infelizmente, não podemos usar colchetes com essa abordagem devido à forma como eles são definidos. Em vez disso, você pode usar a função.setque retorna uma nova versão com um item atualizado. Nossa estrutura de dados agora possui uma propriedade chamada persistência na programação funcional. Isso não significa que salvamos essa estrutura de dados no disco rígido, mas o fato de que, quando atualizado, o conteúdo antigo não é excluído - em vez disso, é criada uma nova bifurcação do nosso mundo, ou seja, a estrutura. Graças a isso, podemos comparar valores passados com presentes - isso é feito com a ajuda de dois assert.const auto v0 = vector<int>{};
const auto v1 = v0.push_back(15);
const auto v2 = v1.push_back(16);
const auto v3 = v2.set(0, 42);
assert(v2.size() == v0.size() + 2);
assert(v3[0] - v1[0] == 27);
As alterações agora podem ser verificadas diretamente, elas não são mais propriedades ocultas da estrutura de dados. Esse recurso é especialmente valioso em sistemas interativos, onde precisamos constantemente alterar dados.Outra propriedade importante é o compartilhamento estrutural. Agora não estamos copiando todos os dados para cada nova versão da estrutura de dados. Mesmo com .push_backe.setnem todos os dados são copiados, mas apenas uma pequena parte deles. Todos os nossos garfos têm acesso comum a uma visualização compacta, proporcional ao número de alterações, não ao número de cópias. Da mesma forma, a comparação é muito rápida: se tudo estiver armazenado em um bloco de memória, em um ponteiro, você poderá simplesmente comparar os ponteiros e não examinar os elementos que estão dentro deles, se forem iguais.Como esse vetor, parece-me, é extremamente útil, eu o implementei em uma biblioteca separada: isto é immer - uma biblioteca de estruturas imutáveis, um projeto de código aberto.Ao escrevê-lo, eu queria que seu uso fosse familiar aos desenvolvedores de C ++. Existem muitas bibliotecas que implementam os conceitos de programação funcional em C ++, mas dão a impressão de que os desenvolvedores escrevem para Haskell e não para C ++. Isso cria inconveniência. Além disso, consegui um bom desempenho. As pessoas usam C ++ quando os recursos disponíveis são limitados. Finalmente, queria que a biblioteca fosse personalizável. Este requisito está relacionado ao requisito de desempenho.Em busca de um vetor mágico
Na segunda parte do relatório, consideraremos como esse vetor imutável é estruturado. A maneira mais fácil de entender os princípios dessa estrutura de dados é começando com uma lista regular. Se você estiver um pouco familiarizado com a programação funcional (usando Lisp ou Haskell como exemplo), você sabe que as listas são as estruturas de dados imutáveis mais comuns.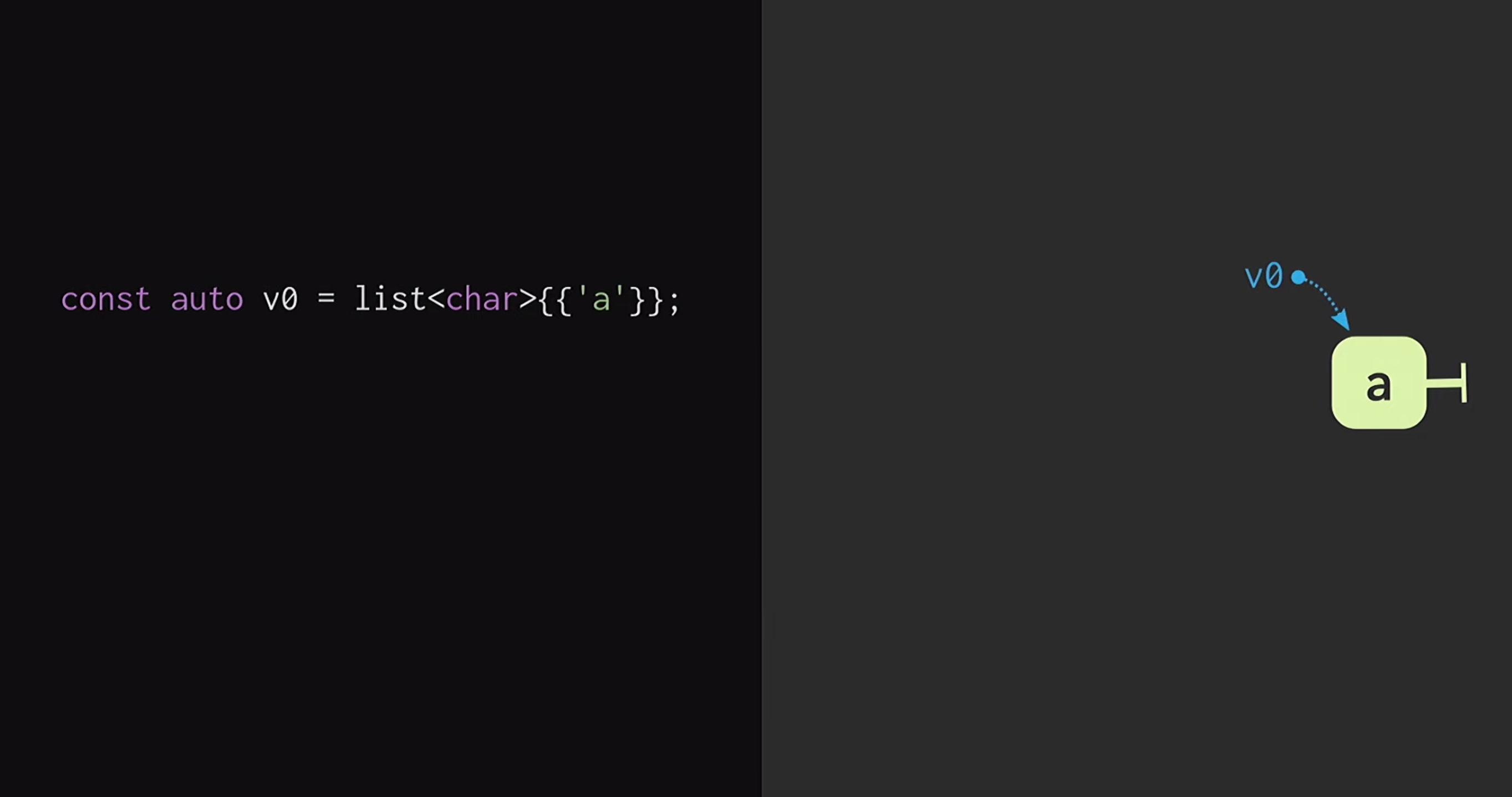 Para começar, vamos assumir que temos uma lista com um único nó
Para começar, vamos assumir que temos uma lista com um único nó v1eles v0indicam elementos diferentes.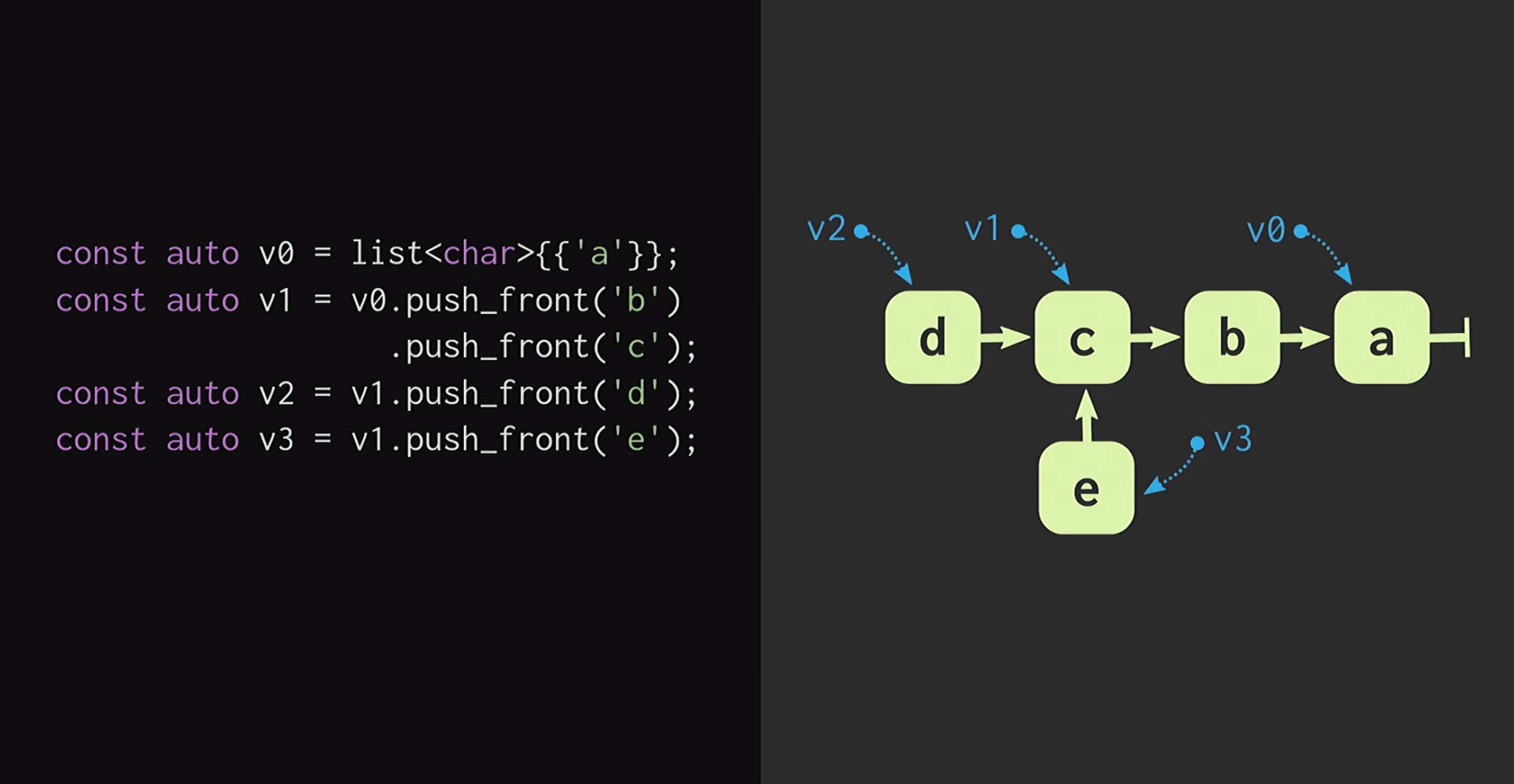 Também podemos criar uma bifurcação da realidade, ou seja, criar uma nova lista que tenha o mesmo final, mas um começo diferente.Tais estruturas de dados são estudadas há muito tempo: Chris Okasaki escreveu o trabalho fundamental de Estruturas de dados puramente funcionais . Além disso, a estrutura de dados da Finger Tree proposta por Ralf Hinze e Ross Paterson é muito interessante . Mas para C ++, essas estruturas de dados não funcionam bem. Eles usam nós pequenos e sabemos que em C ++ pequenos nós significam falta de eficiência do armazenamento em cache.Além disso, eles geralmente contam com propriedades que o C ++ não possui, como preguiça. Portanto, o trabalho de Phil Bagwell sobre estruturas de dados imutáveis é muito mais útil para nós - um link escrito no início dos anos 2000, bem como o trabalho de Rich Hickey - link, autor de Clojure. Rich Hickey criou uma lista, que na verdade não é uma lista, mas baseada em estruturas de dados modernas: vetores e mapas de hash. Essas estruturas de dados têm eficiência de armazenamento em cache e interagem bem com processadores modernos, para os quais é indesejável trabalhar com pequenos nós. Tais estruturas podem ser usadas em C ++.Como construir um vetor imune? No coração de qualquer estrutura, mesmo remotamente semelhante a um vetor, deve haver uma matriz. Mas a matriz não possui compartilhamento estrutural. Para alterar qualquer elemento da matriz, sem perder a propriedade persistence, você deve copiar a matriz inteira. Para não fazer isso, a matriz pode ser dividida em partes separadas.Agora, ao atualizar um elemento vetorial, precisamos copiar apenas uma parte, e não o vetor inteiro. Mas essas partes em si não são uma estrutura de dados; elas devem ser combinadas de uma maneira ou de outra. Coloque-os em outra matriz. Mais uma vez, surge o problema de que a matriz pode ser muito grande e, em seguida, copiá-la novamente levará muito tempo.Dividimos esse array em pedaços, os colocamos novamente em um array separado e repetimos esse procedimento até que exista apenas um array raiz. A estrutura resultante é chamada de árvore residual. Essa árvore é descrita pela constante M = 2B, ou seja, o fator de ramificação. Esse indicador de ramificação deve ter uma potência de dois, e logo descobriremos o porquê. No exemplo do slide, são usados blocos de quatro caracteres, mas, na prática, são usados blocos de 32 caracteres. Existem experimentos com os quais você pode encontrar o tamanho ideal de bloco para uma arquitetura específica. Isso permite alcançar a melhor proporção de acesso compartilhado estrutural ao tempo de acesso: quanto menor a árvore, menor o tempo de acesso.Lendo isso, os desenvolvedores que escrevem em C ++ provavelmente pensam: mas qualquer estrutura baseada em árvore é muito lenta! As árvores crescem com um aumento no número de elementos nelas e, por isso, o tempo de acesso é reduzido. É por isso que os programadores preferem
Também podemos criar uma bifurcação da realidade, ou seja, criar uma nova lista que tenha o mesmo final, mas um começo diferente.Tais estruturas de dados são estudadas há muito tempo: Chris Okasaki escreveu o trabalho fundamental de Estruturas de dados puramente funcionais . Além disso, a estrutura de dados da Finger Tree proposta por Ralf Hinze e Ross Paterson é muito interessante . Mas para C ++, essas estruturas de dados não funcionam bem. Eles usam nós pequenos e sabemos que em C ++ pequenos nós significam falta de eficiência do armazenamento em cache.Além disso, eles geralmente contam com propriedades que o C ++ não possui, como preguiça. Portanto, o trabalho de Phil Bagwell sobre estruturas de dados imutáveis é muito mais útil para nós - um link escrito no início dos anos 2000, bem como o trabalho de Rich Hickey - link, autor de Clojure. Rich Hickey criou uma lista, que na verdade não é uma lista, mas baseada em estruturas de dados modernas: vetores e mapas de hash. Essas estruturas de dados têm eficiência de armazenamento em cache e interagem bem com processadores modernos, para os quais é indesejável trabalhar com pequenos nós. Tais estruturas podem ser usadas em C ++.Como construir um vetor imune? No coração de qualquer estrutura, mesmo remotamente semelhante a um vetor, deve haver uma matriz. Mas a matriz não possui compartilhamento estrutural. Para alterar qualquer elemento da matriz, sem perder a propriedade persistence, você deve copiar a matriz inteira. Para não fazer isso, a matriz pode ser dividida em partes separadas.Agora, ao atualizar um elemento vetorial, precisamos copiar apenas uma parte, e não o vetor inteiro. Mas essas partes em si não são uma estrutura de dados; elas devem ser combinadas de uma maneira ou de outra. Coloque-os em outra matriz. Mais uma vez, surge o problema de que a matriz pode ser muito grande e, em seguida, copiá-la novamente levará muito tempo.Dividimos esse array em pedaços, os colocamos novamente em um array separado e repetimos esse procedimento até que exista apenas um array raiz. A estrutura resultante é chamada de árvore residual. Essa árvore é descrita pela constante M = 2B, ou seja, o fator de ramificação. Esse indicador de ramificação deve ter uma potência de dois, e logo descobriremos o porquê. No exemplo do slide, são usados blocos de quatro caracteres, mas, na prática, são usados blocos de 32 caracteres. Existem experimentos com os quais você pode encontrar o tamanho ideal de bloco para uma arquitetura específica. Isso permite alcançar a melhor proporção de acesso compartilhado estrutural ao tempo de acesso: quanto menor a árvore, menor o tempo de acesso.Lendo isso, os desenvolvedores que escrevem em C ++ provavelmente pensam: mas qualquer estrutura baseada em árvore é muito lenta! As árvores crescem com um aumento no número de elementos nelas e, por isso, o tempo de acesso é reduzido. É por isso que os programadores preferem std::unordered_map, em vez de std::map. Apresso-me a tranquilizá-lo: nossa árvore cresce muito lentamente. Um vetor contendo todos os valores possíveis de um int de 32 bits tem apenas 7 níveis de altura. Pode ser demonstrado experimentalmente que, com esse tamanho de dados, a proporção do cache para o volume de carga afeta significativamente o desempenho que a profundidade da árvore.Vamos ver como é realizado o acesso a um elemento de uma árvore. Suponha que você precise acessar o elemento 17. Nós pegamos uma representação binária do índice e dividimos em grupos do tamanho de um fator de ramificação. Em cada grupo, usamos o valor binário correspondente e, assim, descemos na árvore.Em seguida, suponha que precisamos fazer uma alteração nessa estrutura de dados, ou seja, executar o método
Em cada grupo, usamos o valor binário correspondente e, assim, descemos na árvore.Em seguida, suponha que precisamos fazer uma alteração nessa estrutura de dados, ou seja, executar o método .set.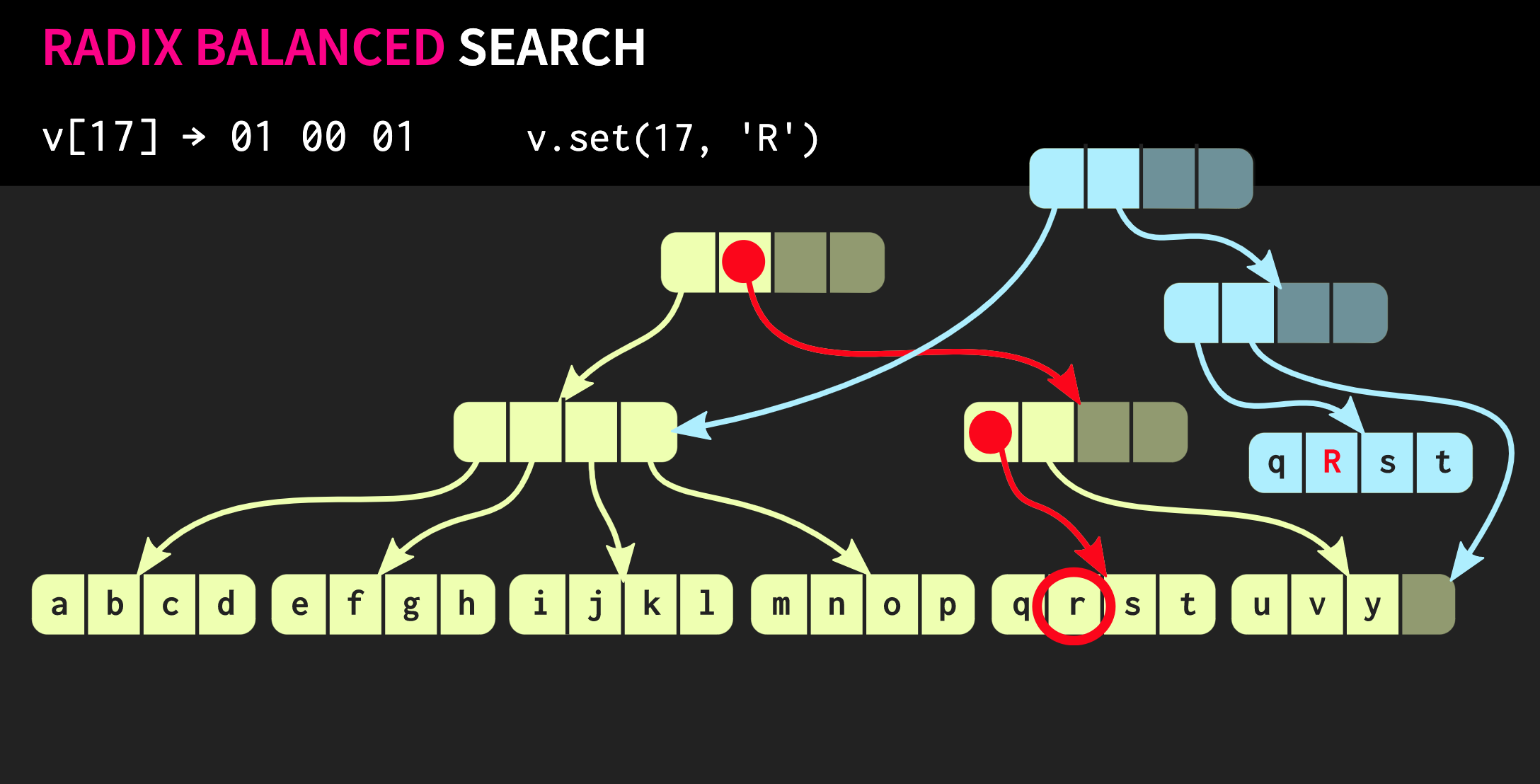 Para fazer isso, primeiro você precisa copiar o bloco em que o elemento está localizado e, em seguida, copiar cada nó interno no caminho para o elemento. Por um lado, muitos dados precisam ser copiados, mas ao mesmo tempo uma parte significativa desses dados é comum, isso compensa o seu volume.A propósito, existe uma estrutura de dados muito mais antiga que é muito semelhante à que eu descrevi. Estas são páginas de memória com uma árvore da tabela de páginas. Seu gerenciamento também é realizado por meio de uma chamada
Para fazer isso, primeiro você precisa copiar o bloco em que o elemento está localizado e, em seguida, copiar cada nó interno no caminho para o elemento. Por um lado, muitos dados precisam ser copiados, mas ao mesmo tempo uma parte significativa desses dados é comum, isso compensa o seu volume.A propósito, existe uma estrutura de dados muito mais antiga que é muito semelhante à que eu descrevi. Estas são páginas de memória com uma árvore da tabela de páginas. Seu gerenciamento também é realizado por meio de uma chamada fork.Vamos tentar melhorar nossa estrutura de dados. Suponha que precisamos conectar dois vetores. A estrutura de dados descrita até o momento tem as mesmas limitações std::vector:que possui células vazias em sua parte mais à direita. Como a estrutura é perfeitamente equilibrada, essas células vazias não podem estar no meio da árvore. Portanto, se houver um segundo vetor que queremos combinar com o primeiro, precisaremos copiar os elementos para células vazias, o que criará células vazias no segundo vetor e, no final, teremos que copiar todo o segundo vetor. Essa operação possui complexidade computacional O (n), onde n é o tamanho do segundo vetor.Vamos tentar alcançar um resultado melhor. Existe uma versão modificada da nossa estrutura de dados denominada árvore balanceada de raiz relaxada. Nessa estrutura, os nós que não estão no caminho mais à esquerda podem ter células vazias. Portanto, nesses nós incompletos (ou relaxados), é necessário calcular o tamanho da subárvore. Agora você pode executar uma operação de junção complexa, mas logarítmica. Esta operação de complexidade de tempo constante é O (log (32)). Como as árvores são rasas, o tempo de acesso é constante, embora relativamente longo. Devido ao fato de termos uma operação de união, uma versão relaxada dessa estrutura de dados é chamada confluente: além de persistente, e você pode bifurcar, duas dessas estruturas podem ser combinadas em uma.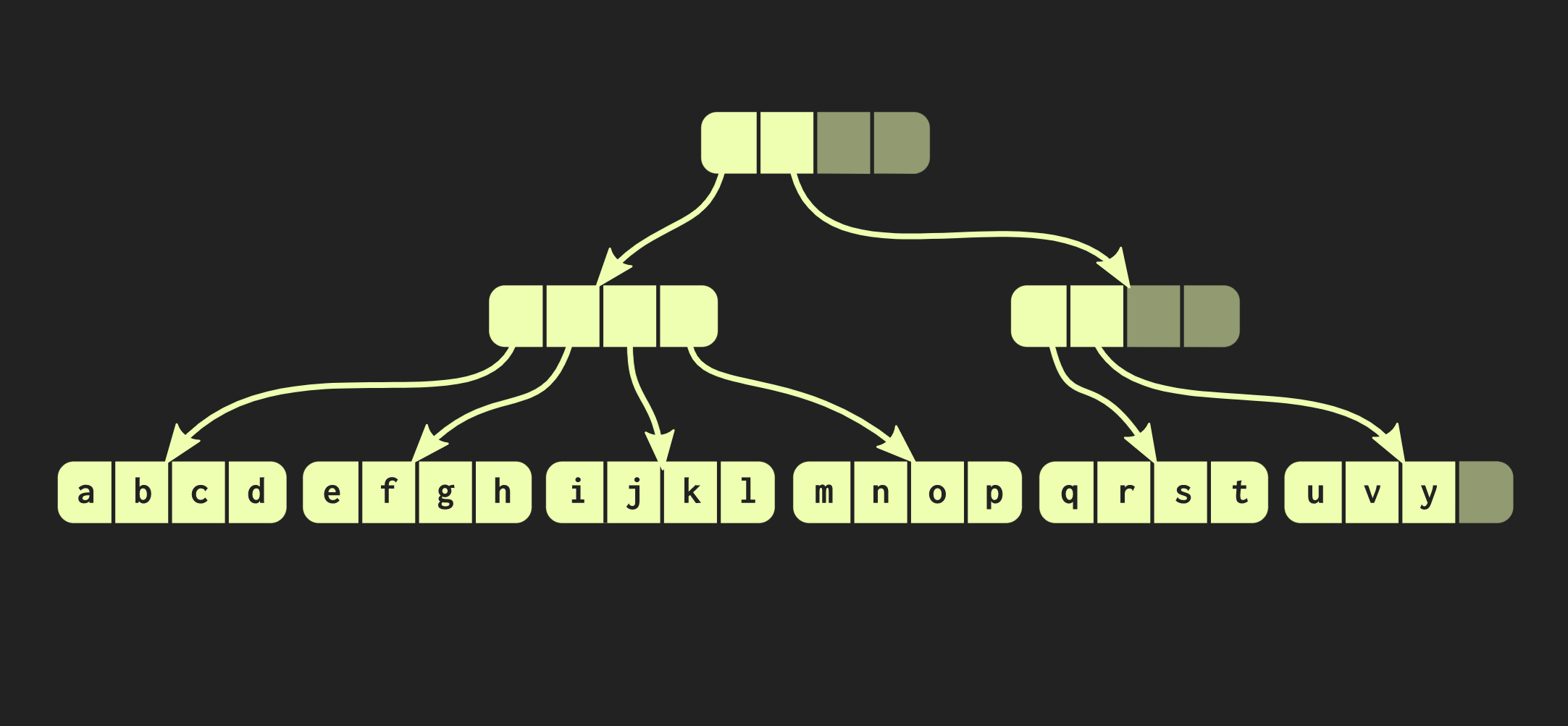 No exemplo com o qual trabalhamos até agora, a estrutura de dados é muito elegante, mas, na prática, as implementações no Clojure e outras linguagens funcionais parecem diferentes. Eles criam contêineres para cada valor, ou seja, cada elemento do vetor está em uma célula separada e os nós folha contêm ponteiros para esses elementos. Mas essa abordagem é extremamente ineficiente, em C ++ geralmente não coloca todo valor em um contêiner. Portanto, seria melhor se esses elementos estivessem localizados diretamente nos nós. Então surge outro problema: elementos diferentes têm tamanhos diferentes. Se o elemento tiver o mesmo tamanho do ponteiro, nossa estrutura será semelhante à mostrada abaixo:
No exemplo com o qual trabalhamos até agora, a estrutura de dados é muito elegante, mas, na prática, as implementações no Clojure e outras linguagens funcionais parecem diferentes. Eles criam contêineres para cada valor, ou seja, cada elemento do vetor está em uma célula separada e os nós folha contêm ponteiros para esses elementos. Mas essa abordagem é extremamente ineficiente, em C ++ geralmente não coloca todo valor em um contêiner. Portanto, seria melhor se esses elementos estivessem localizados diretamente nos nós. Então surge outro problema: elementos diferentes têm tamanhos diferentes. Se o elemento tiver o mesmo tamanho do ponteiro, nossa estrutura será semelhante à mostrada abaixo: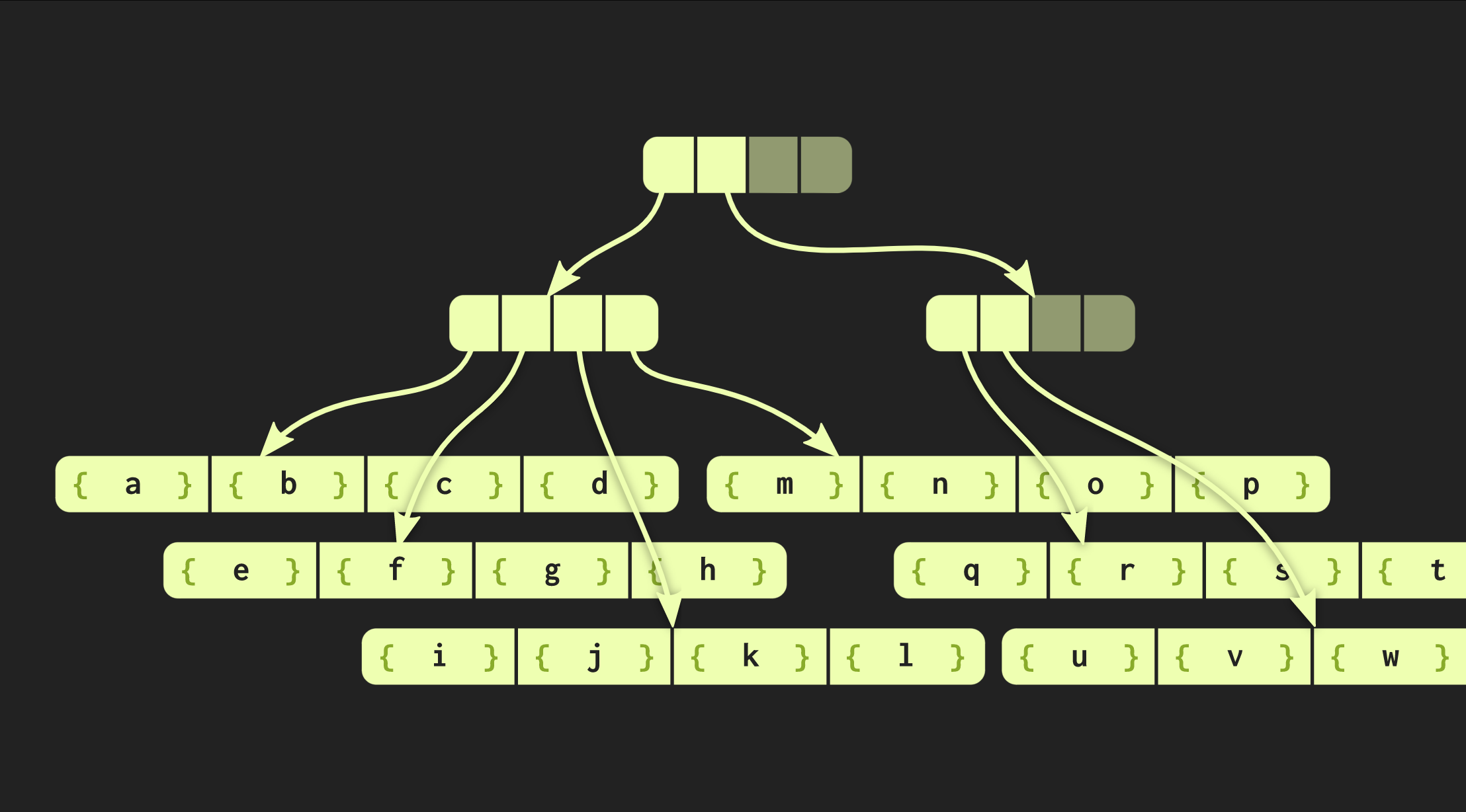 Porém, se os elementos forem grandes, a estrutura de dados perderá as propriedades que medimos (tempo de acesso O (log (32) ())), porque copiar uma das folhas agora leva mais tempo. Portanto, alterei essa estrutura de dados para aumentar o tamanho o número de elementos contidos nela diminuiu o número desses elementos nos nós das folhas. Pelo contrário, se os elementos forem pequenos, eles agora podem se encaixar mais.A nova versão da árvore é chamada de incorporação de árvore balanceada com base em radix.É descrita não por uma constante, mas por duas: uma delas descreve nós internos e o segundo frondoso. A implementação da árvore em C ++ pode calcular o tamanho ideal do elemento folha, dependendo do tamanho dos ponteiros e dos próprios elementos.Nossa árvore já está funcionando muito bem, mas ainda pode ser melhorada. Dê uma olhada em uma função semelhante a uma função
Porém, se os elementos forem grandes, a estrutura de dados perderá as propriedades que medimos (tempo de acesso O (log (32) ())), porque copiar uma das folhas agora leva mais tempo. Portanto, alterei essa estrutura de dados para aumentar o tamanho o número de elementos contidos nela diminuiu o número desses elementos nos nós das folhas. Pelo contrário, se os elementos forem pequenos, eles agora podem se encaixar mais.A nova versão da árvore é chamada de incorporação de árvore balanceada com base em radix.É descrita não por uma constante, mas por duas: uma delas descreve nós internos e o segundo frondoso. A implementação da árvore em C ++ pode calcular o tamanho ideal do elemento folha, dependendo do tamanho dos ponteiros e dos próprios elementos.Nossa árvore já está funcionando muito bem, mas ainda pode ser melhorada. Dê uma olhada em uma função semelhante a uma função iota:vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = v.push_back(i);
return v;
}
Ele pega uma entrada vector, executa push_backno final do vetor para cada número inteiro entre firste laste retorna o que aconteceu. Tudo está em ordem com a correção dessa função, mas funciona ineficientemente. Cada chamada push_backcopia o bloco mais à esquerda desnecessariamente: a próxima chamada pressiona outro elemento e a cópia é repetida novamente, e os dados copiados pelo método anterior são excluídos.Você pode tentar outra implementação dessa função, na qual abandonamos a persistência dentro da função. Pode ser usado transient vectorcom uma API mutável que seja compatível com a API comum vector. Dentro dessa função, cada chamada push_backaltera a estrutura de dados.vector<int> myiota(vector<int> v, int first, int last)
{
auto t = v.transient();
for (auto i = first; i < last; ++i)
t.push_back(i);
return t.persistent();
}
Essa implementação é mais eficiente e permite reutilizar novos elementos no caminho certo. No final da função, .persistent()é feita uma chamada que retorna imutável vector. Os possíveis efeitos colaterais permanecem invisíveis de fora da função. O original vectorera e permanece imutável, apenas os dados criados dentro da função são alterados. Como eu disse, uma vantagem importante dessa abordagem é que você pode usar std::back_inserteralgoritmos padrão que exigem APIs mutáveis.Considere outro exemplo.vector<char> say_hi(vector<char> v)
{
return v.push_back('h')
.push_back('i')
.push_back('!');
}
A função não aceita e retorna vector, mas uma cadeia de chamadas é executada dentro push_back. Aqui, como no exemplo anterior, pode ocorrer cópia desnecessária dentro da chamada push_back. Observe que o primeiro valor executado push_backé o valor nomeado e o restante é o valor r, ou seja, links anônimos. Se você usar a contagem de referência, o método push_backpoderá se referir a contadores de referência para nós para os quais a memória está alocada na árvore. E no caso do valor-r, se o número de links for um, fica claro que nenhuma outra parte do programa acessa esses nós. Aqui, o desempenho é exatamente o mesmo do caso transient.vector<char> say_hi(vector<char> v)
{
return v.push_back('h') ⟵ named value: v
.push_back('i') ⟵ r-value value
.push_back('!'); ⟵ r-value value
}
Além disso, para ajudar o compilador, podemos executá-lo move(v), pois ele vnão é usado em nenhum outro lugar da função. Tivemos uma vantagem importante, que não estava na transientvariante: se passarmos o valor retornado de outro say_hi para a função say_hi, não haverá cópias extras. No caso de c, transientexistem limites nos quais a cópia em excesso pode ocorrer. Em outras palavras, temos uma estrutura de dados persistente e imutável, cujo desempenho depende da quantidade real de acesso compartilhado no tempo de execução. Se não houver compartilhamento, o desempenho será o mesmo de uma estrutura de dados mutáveis. Esta é uma propriedade extremamente importante. O exemplo que eu já mostrei acima pode ser reescrita com um método move(v).vector<int> myiota(vector<int> v, int first, int last)
{
for (auto i = first; i < last; ++i)
v = std::move(v).push_back(i);
return v;
}
Até agora, falamos sobre vetores e, além deles, também existem mapas de hash. Eles são dedicados a um relatório muito útil de Phil Nash: O Santo Graal. Uma matriz de hash mapeada para C ++ . Ele descreve tabelas de hash implementadas com base nos mesmos princípios que acabei de falar.Estou certo de que muitos de vocês têm dúvidas sobre o desempenho de tais estruturas. Eles trabalham rapidamente na prática? Eu fiz muitos testes e, em suma, minha resposta é sim. Se você quiser saber mais sobre os resultados dos testes, eles serão publicados no meu artigo para a Conferência Internacional de Programação Funcional 2017. Agora, acho que é melhor discutir não valores absolutos, mas o efeito que essa estrutura de dados tem no sistema como um todo. Obviamente, a atualização do nosso vetor é mais lenta porque você precisa copiar vários blocos de dados e alocar memória para outros dados. Mas ignorar nosso vetor é realizado quase na mesma velocidade que um vetor normal. Foi muito importante para mim conseguir isso, pois a leitura dos dados é realizada com muito mais frequência do que alterá-los.Além disso, devido à atualização mais lenta, não há necessidade de copiar nada, apenas a estrutura de dados é copiada. Portanto, o tempo gasto na atualização do vetor é, por assim dizer, amortizado para todas as cópias realizadas no sistema. Portanto, se você aplicar essa estrutura de dados em uma arquitetura semelhante à descrita no começo do relatório, o desempenho aumentará significativamente.Ewig
Não serei infundado e demonstrarei minha estrutura de dados usando um exemplo. Eu escrevi um pequeno editor de texto. Essa é uma ferramenta interativa chamada ewig , na qual os documentos são representados por vetores imutáveis. Eu tenho uma cópia de toda a Wikipédia em esperanto no meu disco, ele pesa 1 gigabyte (no começo eu queria baixar a versão em inglês, mas é muito grande). Qualquer que seja o editor de texto que você use, tenho certeza de que ele não gostará deste arquivo. E quando você baixa esse arquivo no ewig , pode editá-lo imediatamente, porque o download é assíncrono. A navegação de arquivos funciona, nada trava, não mutex, nenhuma sincronização. Como você pode ver, o arquivo baixado leva 20 milhões de linhas de código.Antes de considerar as propriedades mais importantes dessa ferramenta, vamos prestar atenção a um detalhe engraçado. No início da linha, destacada em branco na parte inferior da imagem, você vê dois hífens. Essa interface do usuário provavelmente é familiar para os usuários do emacs; hífens indicam que o documento não foi modificado de forma alguma. Se você fizer alterações, os asteriscos serão exibidos em vez de hífens. Porém, diferentemente de outros editores, se você apagar essas alterações no ewig (não desfazê-lo, apenas exclua-o), hífens serão exibidos em vez de asteriscos, porque todas as versões anteriores do texto são salvas no ewig . Graças a isso, não é necessário um sinalizador especial para mostrar se o documento foi alterado: a presença de alterações é determinada por comparação com o documento original.Considere outra propriedade interessante da ferramenta: copie o texto inteiro e cole-o algumas vezes no meio do texto existente. Como você pode ver, isso acontece instantaneamente. A junção de vetores aqui é uma operação logarítmica, e o logaritmo de vários milhões não é uma operação tão longa. Se você tentar salvar esse grande documento no disco rígido, levará muito mais tempo, porque o texto não será mais apresentado como um vetor obtido da versão anterior desse vetor. Ao salvar no disco, a serialização ocorre, perdendo a persistência.
No início da linha, destacada em branco na parte inferior da imagem, você vê dois hífens. Essa interface do usuário provavelmente é familiar para os usuários do emacs; hífens indicam que o documento não foi modificado de forma alguma. Se você fizer alterações, os asteriscos serão exibidos em vez de hífens. Porém, diferentemente de outros editores, se você apagar essas alterações no ewig (não desfazê-lo, apenas exclua-o), hífens serão exibidos em vez de asteriscos, porque todas as versões anteriores do texto são salvas no ewig . Graças a isso, não é necessário um sinalizador especial para mostrar se o documento foi alterado: a presença de alterações é determinada por comparação com o documento original.Considere outra propriedade interessante da ferramenta: copie o texto inteiro e cole-o algumas vezes no meio do texto existente. Como você pode ver, isso acontece instantaneamente. A junção de vetores aqui é uma operação logarítmica, e o logaritmo de vários milhões não é uma operação tão longa. Se você tentar salvar esse grande documento no disco rígido, levará muito mais tempo, porque o texto não será mais apresentado como um vetor obtido da versão anterior desse vetor. Ao salvar no disco, a serialização ocorre, perdendo a persistência.Retornar à arquitetura baseada em valor
 Vamos começar como você não pode retornar a essa arquitetura: usando o habitual controlador, modelo e exibição em estilo Java, que são mais frequentemente usados para aplicativos interativos em C ++. Não há nada errado com eles, mas eles não são adequados para o nosso problema. Por um lado, o padrão Model-View-Controller permite a separação de tarefas, mas, por outro, cada um desses elementos é um objeto, tanto do ponto de vista orientado a objetos quanto do C ++, ou seja, são áreas de memória com mutável doença. O View conhece o Model; o que é muito pior - o Model conhece indiretamente o View, porque quase certamente há um retorno de chamada através do qual o View é notificado quando o Model é alterado. Mesmo com a melhor implementação de princípios orientados a objetos, temos muitas dependências mútuas.
Vamos começar como você não pode retornar a essa arquitetura: usando o habitual controlador, modelo e exibição em estilo Java, que são mais frequentemente usados para aplicativos interativos em C ++. Não há nada errado com eles, mas eles não são adequados para o nosso problema. Por um lado, o padrão Model-View-Controller permite a separação de tarefas, mas, por outro, cada um desses elementos é um objeto, tanto do ponto de vista orientado a objetos quanto do C ++, ou seja, são áreas de memória com mutável doença. O View conhece o Model; o que é muito pior - o Model conhece indiretamente o View, porque quase certamente há um retorno de chamada através do qual o View é notificado quando o Model é alterado. Mesmo com a melhor implementação de princípios orientados a objetos, temos muitas dependências mútuas.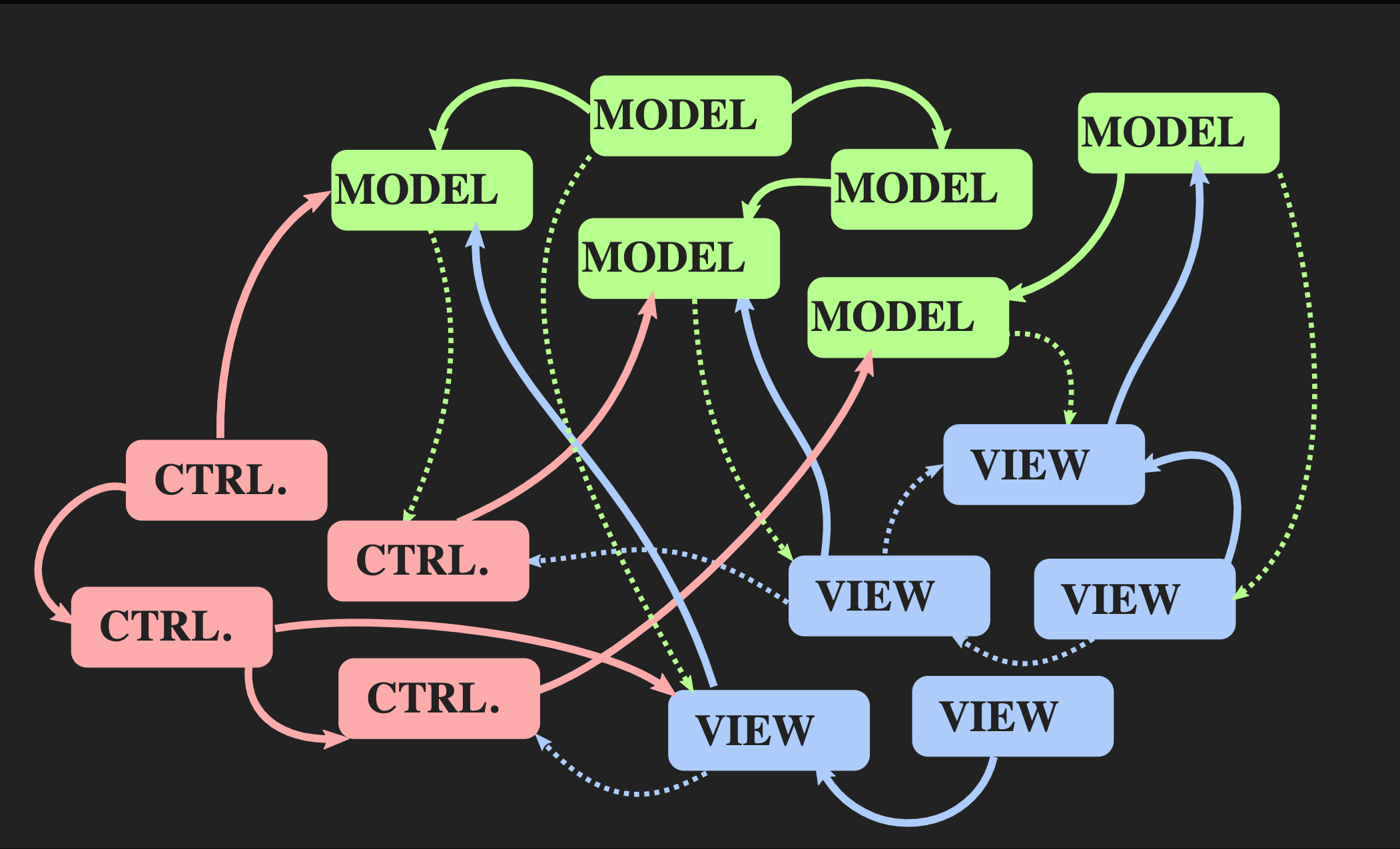 À medida que o aplicativo cresce e novos modelos, controladores e modos de exibição são adicionados, surge uma situação em que, para alterar um segmento do programa, você precisa conhecer todas as partes associadas a ele, sobre todos os modos de exibição que recebem notificações
À medida que o aplicativo cresce e novos modelos, controladores e modos de exibição são adicionados, surge uma situação em que, para alterar um segmento do programa, você precisa conhecer todas as partes associadas a ele, sobre todos os modos de exibição que recebem notificações callback, etc. Como resultado, para todos o familiar monstro da massa começa a examinar essas dependências.Outra arquitetura é possível? Existe uma abordagem alternativa ao padrão Model-View-Controller chamado “Arquitetura de fluxo de dados unidirecional”. Este conceito não foi inventado por mim, é usado com bastante frequência no desenvolvimento web. No Facebook, isso é chamado de arquitetura Flux, mas em C ++, ainda não é aplicado.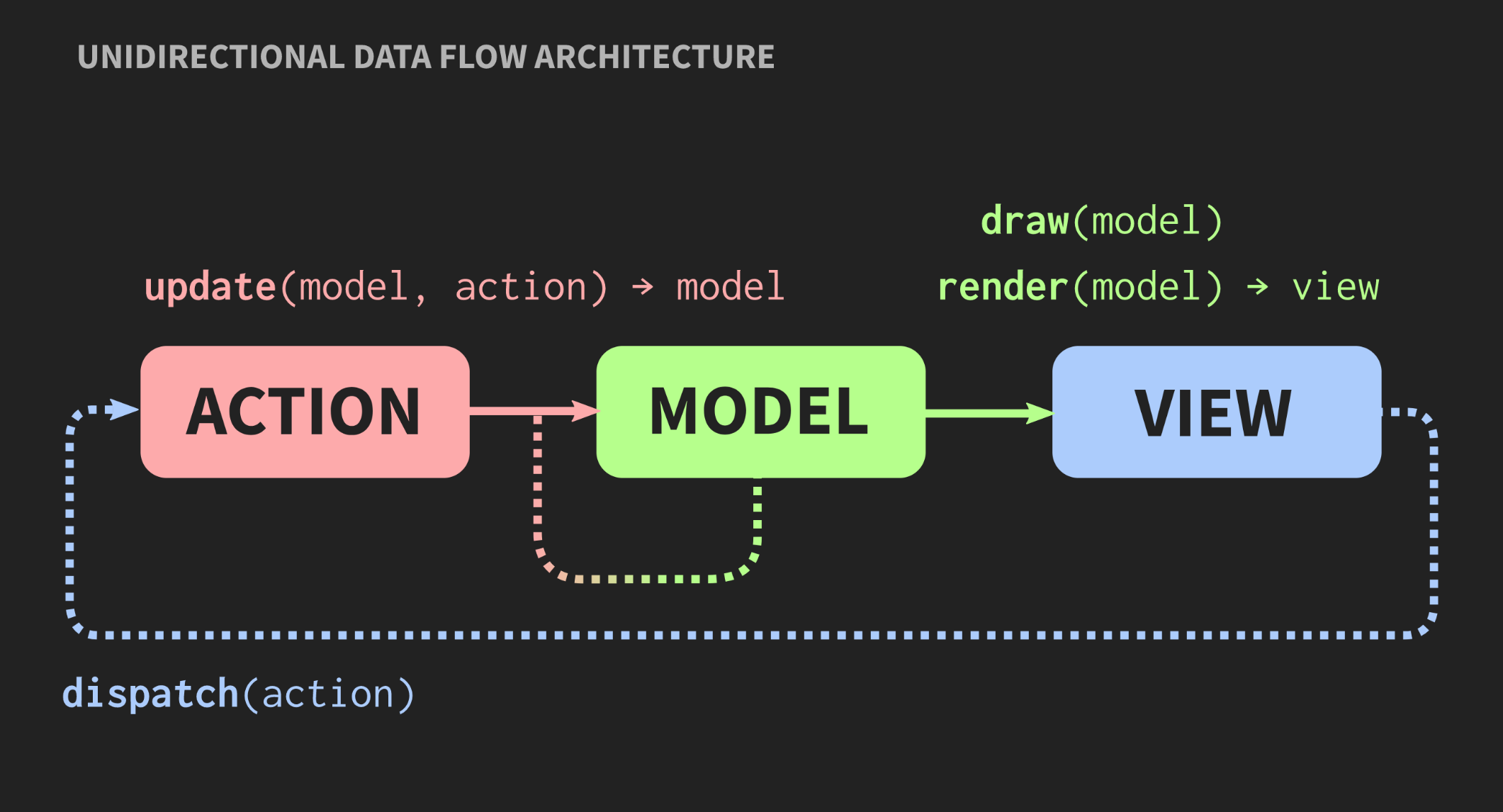 Elementos dessa arquitetura já nos são familiares: Ação, Modelo e Visão, mas o significado de blocos e setas é diferente. Blocos são valores, não objetos e não regiões com estados mutáveis. Isso se aplica até ao modo de exibição. Além disso, as setas não são links, porque sem objetos não pode haver links. Aqui as setas são funções. Entre Ação e Modelo, existe uma função de atualização que aceita o Modelo atual, ou seja, o estado atual do mundo, e Ação, que é uma representação de um evento, por exemplo, um clique do mouse ou um evento de outro nível de abstração, por exemplo, um elemento ou símbolo é inserido em um documento. A função de atualização atualiza o documento e retorna o novo estado do mundo. O modelo se conecta à renderização da função View, que pega o Model e retorna a visualização. Isso requer uma estrutura na qual o View possa ser representado como valores.No desenvolvimento web, o React faz isso, mas em C ++ ainda não há nada parecido, embora quem sabe, se houver pessoas que querem me pagar para escrever algo assim, isso poderá aparecer em breve. Enquanto isso, você pode usar a API do modo imediato, na qual a função de desenho permite criar um valor como efeito colateral.Por fim, a Visualização deve ter um mecanismo que permita ao usuário ou a outras fontes de eventos enviar Ação. Existe uma maneira fácil de implementar isso, é apresentado abaixo:
Elementos dessa arquitetura já nos são familiares: Ação, Modelo e Visão, mas o significado de blocos e setas é diferente. Blocos são valores, não objetos e não regiões com estados mutáveis. Isso se aplica até ao modo de exibição. Além disso, as setas não são links, porque sem objetos não pode haver links. Aqui as setas são funções. Entre Ação e Modelo, existe uma função de atualização que aceita o Modelo atual, ou seja, o estado atual do mundo, e Ação, que é uma representação de um evento, por exemplo, um clique do mouse ou um evento de outro nível de abstração, por exemplo, um elemento ou símbolo é inserido em um documento. A função de atualização atualiza o documento e retorna o novo estado do mundo. O modelo se conecta à renderização da função View, que pega o Model e retorna a visualização. Isso requer uma estrutura na qual o View possa ser representado como valores.No desenvolvimento web, o React faz isso, mas em C ++ ainda não há nada parecido, embora quem sabe, se houver pessoas que querem me pagar para escrever algo assim, isso poderá aparecer em breve. Enquanto isso, você pode usar a API do modo imediato, na qual a função de desenho permite criar um valor como efeito colateral.Por fim, a Visualização deve ter um mecanismo que permita ao usuário ou a outras fontes de eventos enviar Ação. Existe uma maneira fácil de implementar isso, é apresentado abaixo:application update(application state, action ev);
void run(const char* fname)
{
auto term = terminal{};
auto state = application{load_buffer(fname), key_map_emacs};
while (!state.done) {
draw(state);
auto act = term.next();
state = update(state, act);
}
}
Com exceção de salvar e carregar de forma assíncrona, esse é o código usado no editor que acabou de ser apresentado. Há um objeto aqui terminalque permite ler e escrever na linha de comando. Além disso, applicationesse é o valor do Model, ele armazena todo o estado do aplicativo. Como você pode ver na parte superior da tela, existe uma função que retorna uma nova versão application. O ciclo dentro da função é executado até que o aplicativo precise fechar, ou seja, até !state.done. No loop, um novo estado é desenhado e o próximo evento é solicitado. Finalmente, o estado é armazenado em uma variável local statee o loop inicia novamente. Este código tem uma vantagem muito importante: apenas uma variável mutável existe durante a execução do programa, é um objeto state.Os desenvolvedores do Clojure chamam essa arquitetura de átomo único: existe um ponto único em todo o aplicativo através do qual todas as alterações são feitas. A lógica do aplicativo não participa da atualização deste ponto de forma alguma, o que cria um ciclo especialmente projetado para isso. Graças a isso, a lógica da aplicação consiste inteiramente em funções puras, como funções update.Com essa abordagem para escrever aplicativos, a maneira de pensar sobre software está mudando. O trabalho agora começa não com o diagrama UML de interfaces e operações, mas com os próprios dados. Existem algumas semelhanças com o design orientado a dados. É verdade que o design orientado a dados geralmente é usado para obter o máximo desempenho; aqui, além da velocidade, buscamos simplicidade e correção. A ênfase é um pouco diferente, mas há semelhanças importantes na metodologia.using index = int;
struct coord
{
index row = {};
index col = {};
};
using line = immer::flex_vector<char>;
using text = immer::flex_vector<line>;
struct file
{
immer::box<std::string> name;
text content;
};
struct snapshot
{
text content;
coord cursor;
};
struct buffer
{
file from;
text content;
coord cursor;
coord scroll;
std::optional<coord> selection_start;
immer::vector<snapshot> history;
std::optional<std::size_t> history_pos;
};
struct application
{
buffer current;
key_map keys;
key_seq input;
immer::vector<text> clipboard;
immer::vector<message> messages;
};
struct action { key_code key; coord size; };
Acima estão os principais tipos de dados de nosso aplicativo. O corpo principal do aplicativo consiste em lineflex_vector e flex_vector vectorpara o qual você pode executar uma operação de junção. A seguir, texté o vetor em que ele é armazenado line. Como você pode ver, esta é uma representação muito simples do texto. Textarmazenado com a ajuda filede um nome, ou seja, um endereço no sistema de arquivos e, na verdade text. Como fileutilizado outro tipo, um simples, mas muito útil: box. Este é um contêiner de elemento único. Ele permite que você coloque uma pilha e mova um objeto, copiando que pode consumir muitos recursos.Outro tipo importante: snapshot. Com base nesse tipo, uma função de cancelamento está ativa. Ele contém um documento (no formatotext) e posição do cursor (coord). Isso permite que você retorne o cursor para a posição em que estava durante a edição.O próximo tipo é buffer. Este é um termo do vim e do emacs, pois os documentos abertos são chamados lá. Em bufferhá um arquivo a partir do qual o texto foi baixado, bem como o conteúdo do texto - isto permite que você para verificar as alterações no documento. Para destacar parte do texto, há uma variável opcional selection_startindicando o início da seleção. O vetor de snapshoté a história do texto. Observe que não usamos o padrão de equipe; o histórico consiste apenas em estados. Finalmente, se o cancelamento acabou de ser concluído, precisamos de um índice de posição no histórico do estado history_pos.O próximo tipo: application. Ele contém um documento aberto (buffer) key_mapekey_seqpara atalhos de teclado, assim como um vetor da textárea de transferência e outro vetor para mensagens exibidas na parte inferior da tela. Até o momento, na versão de estréia do aplicativo, haverá apenas um encadeamento e um tipo de ação que recebe entrada key_codee coord.Provavelmente, muitos de vocês já estão pensando em como implementar essas operações. Se tomadas por valor e retornadas por valor, na maioria dos casos as operações são bastante simples. O código do meu editor de texto é publicado no github , para que você possa ver como ele realmente se parece. Agora vou me debruçar em detalhes apenas no código que implementa a função de cancelamento.Cancelar
Escrever corretamente um cancelamento sem a infraestrutura apropriada não é tão simples. No meu editor, eu o implementei de acordo com as linhas do emacs, primeiro algumas palavras sobre seus princípios básicos. O comando return está faltando aqui e, graças a isso, você não pode perder seu emprego. Se for necessário um retorno, qualquer alteração será feita no texto e todas as ações de cancelamento se tornarão novamente parte do histórico de cancelamentos. Este princípio está descrito acima. O losango vermelho aqui mostra uma posição na história: se um cancelamento simplesmente não foi concluído, o losango vermelho está sempre no final. Se você cancelar, o diamante retornará um estado, mas, ao mesmo tempo, outro estado será adicionado ao final da fila - o mesmo que o usuário vê atualmente (S3). Se você cancelar novamente e retornar ao estado S2, o estado S2 será adicionado ao final da fila. Se agora o usuário fizer algum tipo de alteração, ela será adicionada ao final da fila como um novo estado de S5 e um losango será movido para ele. Agora, ao desfazer ações passadas, as ações desfazer anteriores serão roladas primeiro. Para implementar esse sistema de cancelamento, basta o seguinte código:
Este princípio está descrito acima. O losango vermelho aqui mostra uma posição na história: se um cancelamento simplesmente não foi concluído, o losango vermelho está sempre no final. Se você cancelar, o diamante retornará um estado, mas, ao mesmo tempo, outro estado será adicionado ao final da fila - o mesmo que o usuário vê atualmente (S3). Se você cancelar novamente e retornar ao estado S2, o estado S2 será adicionado ao final da fila. Se agora o usuário fizer algum tipo de alteração, ela será adicionada ao final da fila como um novo estado de S5 e um losango será movido para ele. Agora, ao desfazer ações passadas, as ações desfazer anteriores serão roladas primeiro. Para implementar esse sistema de cancelamento, basta o seguinte código:buffer record(buffer before, buffer after)
{
if (before.content != after.content) {
after.history = after.history.push_back({before.content, before.cursor});
if (before.history_pos == after.history_pos)
after.history_pos = std::nullopt;
}
return after;
}
buffer undo(buffer buf)
{
auto idx = buf.history_pos.value_or(buf.history.size());
if (idx > 0) {
auto restore = buf.history[--idx];
buf.content = restore.content;
buf.cursor = restore.cursor;
buf.history_pos = idx;
}
return buf;
}
Existem duas ações recorde undo. Recordrealizada durante qualquer operação. Isso é muito conveniente, pois não precisamos saber se ocorreu alguma edição do documento. A função é transparente para a lógica do aplicativo. Após qualquer ação, a função verifica se o documento foi alterado. Se uma alteração ocorreu, o push_backconteúdo e a posição do cursor são executados history. Se a ação não levou a uma alteração history_pos(ou seja, a entrada recebida buffernão é causada pela ação de cancelamento), history_posum valor é atribuído null. Se necessário undo, verificamos history_pos. Se não tem sentido, consideramos que history_posestá no final da história. Se o histórico de cancelamentos não estiver vazio (ou seja,history_posnão no início da história), o cancelamento é realizado. O conteúdo e o cursor atuais são substituídos e alterados history_pos. A irrevogabilidade da operação de cancelamento é alcançada pela função record, que também é chamada durante a operação de cancelamento.Portanto, temos uma operação undoque ocupa 10 linhas de código e que sem alterações (ou com alterações mínimas) pode ser usada em quase qualquer outro aplicativo.Viagem no tempo
Sobre viagens no tempo. Como veremos agora, este é um tópico relacionado ao cancelamento. Demonstrarei o trabalho de uma estrutura que adicionará funcionalidade útil a qualquer aplicativo com arquitetura semelhante. A estrutura aqui é chamada ewig-debug . Esta versão do ewig inclui alguns recursos de depuração. Agora, no navegador, você pode abrir o depurador, no qual pode examinar o estado do aplicativo. Vimos que a última ação foi redimensionada, porque eu abri uma nova janela e meu gerenciador de janelas redimensionou automaticamente a janela já aberta. Obviamente, para serialização automática em JSON, eu tive que adicionar anotações para struct da biblioteca de reflexão especial. Mas o resto do sistema é bastante universal, pode ser conectado a qualquer aplicativo semelhante. Agora, no navegador, você pode ver todas as ações concluídas. Obviamente, existe um estado inicial que não tem ação. Este é o estado que estava antes do download. Além disso, clicando duas vezes, posso retornar o aplicativo ao seu estado anterior. Essa é uma ferramenta de depuração muito útil que permite rastrear a ocorrência de um mau funcionamento no aplicativo.Se você estiver interessado, pode ouvir meu relatório sobre o CPPCON 19, Os valores mais valiosos, examinarei esse depurador em detalhes.Além disso, a arquitetura baseada em valor é discutida em mais detalhes lá. Nele, também digo como implementar ações e organizá-las hierarquicamente. Isso garante a modularidade do sistema e elimina a necessidade de manter tudo em uma grande função de atualização. Além disso, esse relatório fala sobre assincronia e downloads de arquivos multithread. Há outra versão deste relatório em que meia hora de material adicional são estruturas de dados imutáveis pós-modernas.
Vimos que a última ação foi redimensionada, porque eu abri uma nova janela e meu gerenciador de janelas redimensionou automaticamente a janela já aberta. Obviamente, para serialização automática em JSON, eu tive que adicionar anotações para struct da biblioteca de reflexão especial. Mas o resto do sistema é bastante universal, pode ser conectado a qualquer aplicativo semelhante. Agora, no navegador, você pode ver todas as ações concluídas. Obviamente, existe um estado inicial que não tem ação. Este é o estado que estava antes do download. Além disso, clicando duas vezes, posso retornar o aplicativo ao seu estado anterior. Essa é uma ferramenta de depuração muito útil que permite rastrear a ocorrência de um mau funcionamento no aplicativo.Se você estiver interessado, pode ouvir meu relatório sobre o CPPCON 19, Os valores mais valiosos, examinarei esse depurador em detalhes.Além disso, a arquitetura baseada em valor é discutida em mais detalhes lá. Nele, também digo como implementar ações e organizá-las hierarquicamente. Isso garante a modularidade do sistema e elimina a necessidade de manter tudo em uma grande função de atualização. Além disso, esse relatório fala sobre assincronia e downloads de arquivos multithread. Há outra versão deste relatório em que meia hora de material adicional são estruturas de dados imutáveis pós-modernas.Resumir
Eu acho que é hora de fazer um balanço. Vou citar Andy Wingo - ele é um excelente desenvolvedor, dedicou muito tempo ao V8 e compiladores em geral; finalmente, ele está envolvido no suporte ao Guile, na implementação do Scheme for GNU. Recentemente, ele escreveu em seu Twitter: “Para alcançar uma ligeira aceleração do programa, medimos todas as pequenas alterações e deixamos apenas aquelas que dão um resultado positivo. Mas realmente alcançamos uma aceleração significativa, cegamente, investindo muito esforço, sem ter 100% de confiança e guiados apenas pela intuição. Que dicotomia estranha.Parece-me que os desenvolvedores de C ++ estão tendo sucesso no primeiro gênero. Dê-nos um sistema fechado e nós, armados com nossas ferramentas, espremeremos tudo o que for possível. Mas no segundo gênero não estamos acostumados a trabalhar. Obviamente, a segunda abordagem é mais arriscada e muitas vezes leva a um desperdício de grande esforço. Por outro lado, reescrevendo completamente um programa, ele pode ser facilitado e rápido. Espero ter conseguido convencê-lo a pelo menos tentar esta segunda abordagem.Juan Puente falou na conferência C ++ Russia 2019 Moscow e falou sobre estruturas de dados que permitem fazer coisas interessantes. Parte da magia dessas estruturas está na elisão de cópias - é sobre isso que Anton Polukhin e Roman Rusyaev falarão na próxima conferência . Siga as atualizações do programa no site.