Como as tecnologias da ABLYY NLP aprendem a monitorar notícias e gerenciar riscos
 A variedade de tarefas que podem ser resolvidas usando as tecnologias da ABBYY foi reabastecida com outra oportunidade interessante. Treinamos nosso mecanismo no trabalho de um subscritor de banco - uma pessoa que captura eventos em contrapartes a partir de um gigantesco fluxo de notícias e avalia riscos.Agora, esses sistemas baseados nas tecnologias da ABBYY já são usados por vários grandes bancos russos. Queremos falar sobre as nuances da implementação dessa solução - desafios não triviais e inesperados que nossos ontologistas enfrentaram.
A variedade de tarefas que podem ser resolvidas usando as tecnologias da ABBYY foi reabastecida com outra oportunidade interessante. Treinamos nosso mecanismo no trabalho de um subscritor de banco - uma pessoa que captura eventos em contrapartes a partir de um gigantesco fluxo de notícias e avalia riscos.Agora, esses sistemas baseados nas tecnologias da ABBYY já são usados por vários grandes bancos russos. Queremos falar sobre as nuances da implementação dessa solução - desafios não triviais e inesperados que nossos ontologistas enfrentaram.Limite o fluxo de notícias
Para ter sucesso, um banco precisa saber exatamente com quem está lidando e responder rapidamente a mudanças importantes na vida de suas contrapartes. Especialmente quando se trata de outros bancos ou grandes clientes corporativos - empresas de TI, empresas agrícolas e outros. Para isso, a maioria dos bancos russos tem especialistas especiais - subscritores. Eles analisam informações de várias fontes, incluindo notícias, quanto a fatores de risco para o banco. É necessário não apenas ler as notícias, mas também avaliar como isso afetará o banco e seus clientes.Os fatores de risco podem variar:- falência,
- conflito de acionistas
- Mudanças na propriedade ou na estrutura de gerenciamento,
- fatos de fraude, ameaça de perda de negócios por um cliente,
- informações sobre reclamações e inspeções não programadas por agências reguladoras,
- a presença de reivindicações
- ,
- .
Se o subscritor identificar um fator de risco, a cooperação a longo prazo com essa contraparte poderá trazer problemas ao banco, até o julgamento. E a probabilidade de um resultado negativo é importante para descobrir o mais rápido possível. Por que não é tão simples? Nas notícias, não apenas a menção de contrapartes é importante, mas também o contexto. Você precisa entender qual é o relacionamento de uma pessoa ou empresa com os fatores que o banco relaciona com as fontes de risco.Enquanto isso, o fluxo de notícias, especialmente considerando não apenas a mídia federal, mas também a mídia regional, é enorme e continua a crescer. Somente a Medialogy, um serviço de monitoramento de notícias, agrega conteúdo de 52 mil fontes. Segundo Roskomnadzor, em setembro de 2019, estava registrado no registro de mídia russomais de 67 mil mídias ativas. Uma pessoa é fisicamente incapaz de ler rapidamente todas as notícias, mesmo que seja apenas um tópico de seu interesse. Portanto, os bancos precisam constantemente reabastecer a equipe de subscritores ou procurar uma solução alternativa no campo da tecnologia da informação.Opções de solução
A maneira mais óbvia é restringir o fluxo de mensagens através de assinaturas pagas para feeds de notícias fechados sobre vários tópicos. Essas fitas são oferecidas pela Interfax, Prime, Thomson Reuters, Bloomberg e outras agências de notícias. As notícias nelas já estão parcialmente estruturadas: existem tags com nomes de empresas, pessoas-chave envolvidas nas notícias. Mas isso não resolve o problema completamente: o trabalho com o contexto ainda recai sobre os subscritores.Muitos sistemas de monitoramento de mídia existentes nas empresas trabalham pesquisando palavras-chave no texto. Essa abordagem gera muito "ruído" informativo e não funciona sem truques adicionais na forma de filtros. A integridade e precisão no cenário com palavras-chave deixam muito a desejar, porque:- A palavra-chave e suas variações cognatas podem ser mencionadas no texto, mas não são relevantes. Por exemplo, uma empresa pode estar listada em uma referência histórica que não está diretamente relacionada à mensagem.
- Nas notícias, é importante não apenas mencionar as contrapartes, mas também o contexto. Você precisa entender qual é o relacionamento de uma pessoa ou empresa com os fatores que o banco relaciona com as fontes de risco. Se você observar exemplos de fatores de risco nos textos das mensagens, poderá ver quantas notícias potencialmente significativas podem ser perdidas ao pesquisar por palavras-chave. Portanto, a frase “conflito de acionistas” nem sempre é mencionada nas notícias. Enquanto isso, se você observar o exemplo abaixo, para o subscritor, o conflito ou seu potencial é óbvio:

Primeiras amostras
Assim, um dos maiores bancos russos decidiu determinar qual das duas tecnologias lidaria melhor com a tarefa de encontrar riscos. Um classificador inteligente de documentos determinou fatores de risco com base no conteúdo das notícias. A solução baseada em análise de texto extraiu os dados necessários das notícias. Como resultado, a melhor opção é uma simbiose de duas soluções: o classificador ajudou a restringir o número de documentos provenientes da fita e removeu informações completamente irrelevantes e, em seguida, as tecnologias de extração de dados foram incluídas no trabalho.Na primeira etapa - Prova de conceito (POC) - foi testada a própria possibilidade de usar essas ferramentas para procurar riscos. O cliente escolheu um fator de risco - uma situação de conflito. A tecnologia deveria identificar mensagens que falavam de um conflito de acionistas - pessoas físicas ou jurídicas, altos executivos de um banco ou um conflito de um banco com agências reguladoras. O ABBYY Onto-Engineers criou um modelo de teste para o desenvolvimento, no qual uma seleção de 1000 notícias foi usada. Ela extraiu o texto do conflito, a data das notícias e uma lista de seus participantes. O modelo comprovou a viabilidade da abordagem proposta: no estágio POC, na amostra de controle fornecida por um dos bancos (notícias que não foram utilizadas para desenvolvimento), foram obtidos os seguintes resultados em 50 documentos: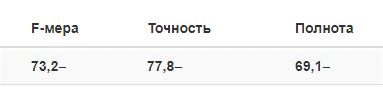
Melhorando o resultado
No processo de desenvolvimento de modelos, os ontologistas são guiados pelos resultados de autotestes regulares, nos quais são registradas todas as discrepâncias entre o alvo e os valores obtidos. Para criar esses relatórios, as notícias foram marcadas de acordo com as instruções fornecidas pelo cliente. Os arquivos marcados no formato xml contendo valores de destino foram comparados com os arquivos xml obtidos como resultado do uso da versão atual do ontomodelo. Os resultados do autoteste fornecem informações de resumo contendo os indicadores de qualidade da análise de toda a coleção de notícias, além de informações particulares para cada objeto e documento extraído separadamente. Assim, você pode avaliar como a precisão do modelo na dinâmica aumenta.Aqui está um exemplo dessa tabela: Os resultados do modelo também podem ser medidos usando o Accuracy Metric, um derivado da integridade e precisão:Métrica de precisão pode ser chamada de base. Ele mede o número de objetos classificados corretamente em relação ao número total de todos os objetos. Precisão O Metric possui algumas desvantagens: não é ideal para classes desequilibradas, onde pode haver muitas instâncias de uma classe e poucas outras.Essa métrica é usada por outro grande banco, também nosso cliente. A métrica de precisão foi de 85%.No futuro, os bancos realizaram independentemente a integração dos produtos ABBYY, dentro dos quais nosso modelo funcionava, e os utilizaram em seus circuitos. Nossos produtos são integrados ao sistema de gerenciamento de risco bancário: eles transferem documentos para análise e coletam os resultados.
Os resultados do modelo também podem ser medidos usando o Accuracy Metric, um derivado da integridade e precisão:Métrica de precisão pode ser chamada de base. Ele mede o número de objetos classificados corretamente em relação ao número total de todos os objetos. Precisão O Metric possui algumas desvantagens: não é ideal para classes desequilibradas, onde pode haver muitas instâncias de uma classe e poucas outras.Essa métrica é usada por outro grande banco, também nosso cliente. A métrica de precisão foi de 85%.No futuro, os bancos realizaram independentemente a integração dos produtos ABBYY, dentro dos quais nosso modelo funcionava, e os utilizaram em seus circuitos. Nossos produtos são integrados ao sistema de gerenciamento de risco bancário: eles transferem documentos para análise e coletam os resultados.Como o sistema funciona
Do ponto de vista técnico, o sistema funciona assim: quando o texto é processado na solução ABBYY, é realizada sua análise linguística em vários estágios. No estágio léxico-morfológico, são determinadas as propriedades mais simples das palavras: gênero, número, caso. Em seguida, no estágio de análise, é determinado onde o sujeito, predicado, como as palavras se relacionam. Conhecer a sintaxe permite passar à definição da semântica. Para cada palavra, seu significado é determinado. No topo dessa análise linguística, estão funcionando as regras para extrair informações desenvolvidas por nossos ontologistas. O ontomodel inclui uma descrição da estrutura de dados a ser obtida dos documentos do cliente e regras que permitem que essa estrutura de dados seja recuperada.

Dificuldades inesperadas
Risco é um conceito abstrato. Este é um campo profissional muito específico e é importante levar em consideração as opiniões de especialistas que trabalham com riscos todos os dias. Os usuários de nossos clientes podem votar nas notícias e colocar um "like" condicional: se o sistema determinou corretamente a presença de risco nas notícias ou não.No processo de depuração do sistema, fomos confrontados com o fato de que os subscritores frequentemente interpretam o significado das notícias e a presença de um fator de risco. Um usuário deseja que um certo tipo de notícia apareça em seu feed e outro - considera essas mensagens irrelevantes. Esse problema é resolvido da seguinte forma: o banco coleta dos subscritores uma lista de notícias, que os especialistas deram diferentes interpretações, e toma a decisão final sobre a interpretação de uma notícia específica: existe ou não um fator de risco. Modificações são feitas no ontomodel, dependendo do feedback.E se as notícias estiverem em inglês?
Muitos bancos russos usam fontes como Dow Jones, Bloomberg, Financial Times. Uma das vantagens de nossa abordagem ao desenvolvimento de ontomodelos baseados nas tecnologias da ABLYY NLP acabou sendo uma rápida adaptação de modelos desenvolvidos para analisar notícias em russo e trabalhar com textos em inglês. Isso requer a depuração do modelo nas notícias originais em inglês.Classifique os resultados
Agora, os subscritores podem acompanhar as notícias em tempo real, sem precisar ler todas as 100.500 mensagens. Em princípio, você nem precisa ler todas as notícias em que o sistema encontrou um fator de risco: o fragmento com o mais importante (snippet) é destacado no programa. Em alguns minutos, você pode gerar automaticamente um relatório para um banco, destacar apenas um fator de risco ou vários fatores significativos. Com essa abordagem, é mais difícil perder algo importante. Além disso, o subscritor pode abrir o cartão da contraparte e selecionar as mensagens que ele considera significativas. Com base neles, o rating de crédito da empresa pode ser revisado, a taxa de juros pode ser alterada ou pode haver um motivo para entrar em contato com a administração da empresa. Essas mensagens são transmitidas para o sistema de fluxo de trabalho.Você pode perguntar quantas notícias a tecnologia processa. Tudo depende do fluxo de notícias: em janeiro e maio, por exemplo, tradicionalmente há menos mensagens. Um banco pode verificar até 2,5 milhões de notícias por mês através do nosso sistema. E esse número é limitado apenas pela licença e pelo poder de computação.By the way, tecnologias semelhantespode funcionar não apenas em bancos, mas também em empresas que rastreiam um grande fluxo de mensagens sobre concorrentes, clientes, parceiros e leem opiniões de usuários em redes sociais. Por exemplo, os fundos de risco que usam tecnologias de PNL podem rastrear informações sobre startups promissoras em termos de investimentos potenciais e organizações governamentais - notícias importantes sobre o que está acontecendo em uma região específica, quais são os problemas, quem é responsável etc. Além disso, você pode analisar não apenas mensagens na mídia, mas também blogs e análises nas redes sociais.
E que tarefas você enfrentou ao lidar com projetos de processamento de documentos não estruturados para bancos e empresas de outros setores?Source: https://habr.com/ru/post/undefined/
All Articles