Entendendo o modelo de aprendizado de máquina que quebra o CAPTCHA
Olá a todos! Este mês, a OTUS está recrutando um novo grupo no curso Machine Learning . De acordo com a tradição estabelecida, na véspera do início do curso, estamos compartilhando com você a tradução de material interessante sobre o tema. A visão computacional é um dos tópicos mais relevantes e pesquisados da IA [1], no entanto, os métodos atuais para resolver problemas usando redes neurais convolucionais são seriamente criticados porque essas redes são fáceis de enganar. Para não ser infundado, vou falar sobre várias razões: redes desse tipo fornecem um resultado incorreto com alta confiança para imagens que ocorrem naturalmente que não contêm sinais estatísticos [2], nas quais as redes neurais convolucionais se baseiam, para imagens que foram classificadas corretamente corretamente, mas em que um pixel [3] ou imagens com objetos físicos foram adicionados à cena, mas não precisaram alterar o resultado da classificação [4] alterado. O fato é que, se queremos criar máquinas verdadeiramente inteligentes,deveria nos parecer razoável investir no estudo de novas idéias.Uma dessas novas idéias é a aplicação da Vicarious da Rede Cortical Recursiva (RCN), que se inspira na neurociência. Este modelo alegou ser extremamente eficaz em quebrar o captcha de texto, causando muita conversa em torno de si . Por isso, decidi escrever vários artigos, cada um dos quais explica um certo aspecto deste modelo. Neste artigo, falaremos sobre sua estrutura e como é gerada a geração de imagens apresentadas nos materiais do artigo principal da RCN [5].Este artigo pressupõe que você já esteja familiarizado com redes neurais convolucionais, por isso vou fazer muitas analogias com elas.Para se preparar para a conscientização da RCN, é necessário entender que as RCNs se baseiam na idéia de separar a forma (esboço do objeto) da aparência (sua textura) e que é um modelo generativo, não discriminante, para que possamos gerar imagens usando-o, como em um generativo redes adversárias. Além disso, é usada uma estrutura hierárquica paralela, semelhante à arquitetura das redes neurais convolucionais, que começa com o estágio de determinação da forma do objeto alvo nas camadas inferiores e, em seguida, sua aparência é adicionada à camada superior. Ao contrário das redes neurais convolucionais, o modelo que estamos considerando se baseia em uma rica base teórica de modelos gráficos, em vez de somas ponderadas e descida de gradiente. Agora vamos nos aprofundar nos recursos da estrutura RCN.
A visão computacional é um dos tópicos mais relevantes e pesquisados da IA [1], no entanto, os métodos atuais para resolver problemas usando redes neurais convolucionais são seriamente criticados porque essas redes são fáceis de enganar. Para não ser infundado, vou falar sobre várias razões: redes desse tipo fornecem um resultado incorreto com alta confiança para imagens que ocorrem naturalmente que não contêm sinais estatísticos [2], nas quais as redes neurais convolucionais se baseiam, para imagens que foram classificadas corretamente corretamente, mas em que um pixel [3] ou imagens com objetos físicos foram adicionados à cena, mas não precisaram alterar o resultado da classificação [4] alterado. O fato é que, se queremos criar máquinas verdadeiramente inteligentes,deveria nos parecer razoável investir no estudo de novas idéias.Uma dessas novas idéias é a aplicação da Vicarious da Rede Cortical Recursiva (RCN), que se inspira na neurociência. Este modelo alegou ser extremamente eficaz em quebrar o captcha de texto, causando muita conversa em torno de si . Por isso, decidi escrever vários artigos, cada um dos quais explica um certo aspecto deste modelo. Neste artigo, falaremos sobre sua estrutura e como é gerada a geração de imagens apresentadas nos materiais do artigo principal da RCN [5].Este artigo pressupõe que você já esteja familiarizado com redes neurais convolucionais, por isso vou fazer muitas analogias com elas.Para se preparar para a conscientização da RCN, é necessário entender que as RCNs se baseiam na idéia de separar a forma (esboço do objeto) da aparência (sua textura) e que é um modelo generativo, não discriminante, para que possamos gerar imagens usando-o, como em um generativo redes adversárias. Além disso, é usada uma estrutura hierárquica paralela, semelhante à arquitetura das redes neurais convolucionais, que começa com o estágio de determinação da forma do objeto alvo nas camadas inferiores e, em seguida, sua aparência é adicionada à camada superior. Ao contrário das redes neurais convolucionais, o modelo que estamos considerando se baseia em uma rica base teórica de modelos gráficos, em vez de somas ponderadas e descida de gradiente. Agora vamos nos aprofundar nos recursos da estrutura RCN.Camadas de recursos
O primeiro tipo de camada no RCN é chamado de camada de recurso. Vamos considerar o modelo gradualmente, então vamos supor, por enquanto, que toda a hierarquia do modelo consiste apenas em camadas desse tipo empilhadas umas sobre as outras. Passaremos de conceitos abstratos de alto nível para recursos mais específicos das camadas inferiores, como mostra a Figura 1 . Uma camada desse tipo consiste em vários nós localizados no espaço bidimensional, de maneira semelhante a mapas de recursos em redes neurais convolucionais. Figura 1 : Várias camadas de recursos localizadas uma acima da outra com nós no espaço bidimensional. A transição da quarta para a primeira camada significa a transição do geral para o particular.Cada nó consiste em vários canais, cada um dos quais representa um recurso separado. Canais são variáveis binárias que assumem o valor Verdadeiro ou Falso, indicando se existe um objeto correspondente a este canal na imagem final gerada na coordenada (x, y) do nó. Em qualquer nível, os nós têm o mesmo tipo de canal.Como exemplo, vamos pegar uma camada intermediária e falar sobre seus canais e as camadas acima para simplificar a explicação. A lista de canais nesta camada será uma hipérbole, um círculo e uma parábola. Em uma determinada execução ao gerar a imagem, os cálculos das camadas sobrepostas exigiram um círculo na coordenada (1,1). Assim, o nó (1, 1) terá um canal correspondente ao objeto “circle” no valor True. Isso afetará diretamente alguns nós na camada abaixo, ou seja, os recursos de nível inferior associados ao círculo na vizinhança (1,1) serão definidos como True. Esses objetos de nível inferior podem ser, por exemplo, quatro arcos com orientações diferentes. Quando os recursos da camada inferior são ativados, eles ativam os canais nas camadas mais baixas até a última camada ser atingida,geração de imagem. A visualização de ativação é mostrada emFigura 2 .Você pode perguntar, como ficará claro que a representação de um círculo é de 4 arcos? E como a RCN sabe que precisa de um canal para representar o círculo? Os canais e suas ligações a outras camadas serão formados no estágio de treinamento da RCN.
Figura 1 : Várias camadas de recursos localizadas uma acima da outra com nós no espaço bidimensional. A transição da quarta para a primeira camada significa a transição do geral para o particular.Cada nó consiste em vários canais, cada um dos quais representa um recurso separado. Canais são variáveis binárias que assumem o valor Verdadeiro ou Falso, indicando se existe um objeto correspondente a este canal na imagem final gerada na coordenada (x, y) do nó. Em qualquer nível, os nós têm o mesmo tipo de canal.Como exemplo, vamos pegar uma camada intermediária e falar sobre seus canais e as camadas acima para simplificar a explicação. A lista de canais nesta camada será uma hipérbole, um círculo e uma parábola. Em uma determinada execução ao gerar a imagem, os cálculos das camadas sobrepostas exigiram um círculo na coordenada (1,1). Assim, o nó (1, 1) terá um canal correspondente ao objeto “circle” no valor True. Isso afetará diretamente alguns nós na camada abaixo, ou seja, os recursos de nível inferior associados ao círculo na vizinhança (1,1) serão definidos como True. Esses objetos de nível inferior podem ser, por exemplo, quatro arcos com orientações diferentes. Quando os recursos da camada inferior são ativados, eles ativam os canais nas camadas mais baixas até a última camada ser atingida,geração de imagem. A visualização de ativação é mostrada emFigura 2 .Você pode perguntar, como ficará claro que a representação de um círculo é de 4 arcos? E como a RCN sabe que precisa de um canal para representar o círculo? Os canais e suas ligações a outras camadas serão formados no estágio de treinamento da RCN.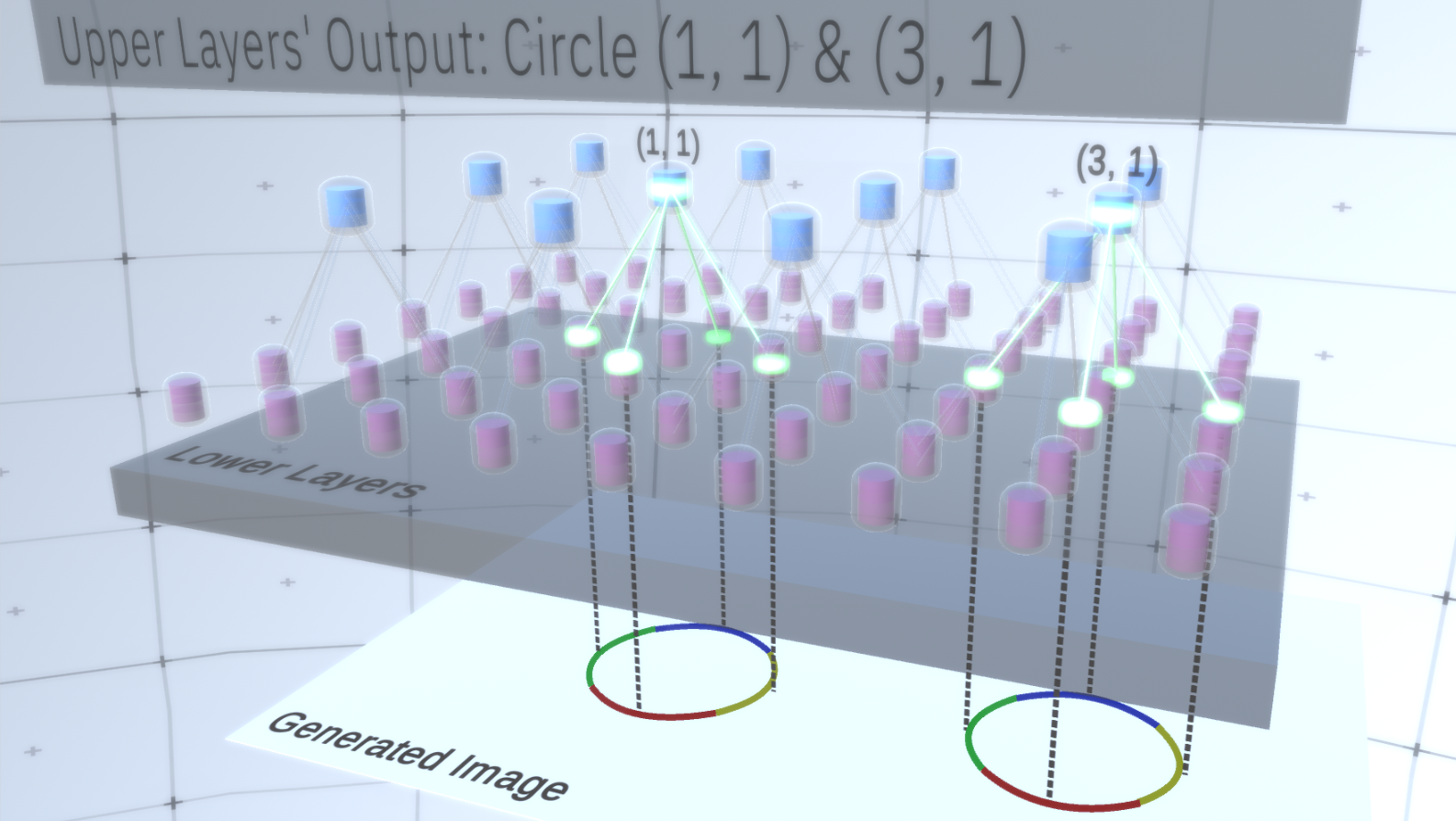 Figura 2: Fluxo de informações nas camadas de recursos. Nós de sinais são cápsulas contendo discos representando canais. Algumas das camadas superior e inferior foram apresentadas na forma de um paralelepípedo para simplificar, no entanto, na realidade, elas também consistem em nós de características como camadas intermediárias. Observe que a camada intermediária superior consiste em 3 canais e a segunda camada consiste em 4 canais.Você pode indicar um método muito rígido e determinístico para gerar o modelo adotado, mas para as pessoas, pequenas perturbações da curvatura do círculo ainda são consideradas um círculo, como você pode ver na Figura 3 .
Figura 2: Fluxo de informações nas camadas de recursos. Nós de sinais são cápsulas contendo discos representando canais. Algumas das camadas superior e inferior foram apresentadas na forma de um paralelepípedo para simplificar, no entanto, na realidade, elas também consistem em nós de características como camadas intermediárias. Observe que a camada intermediária superior consiste em 3 canais e a segunda camada consiste em 4 canais.Você pode indicar um método muito rígido e determinístico para gerar o modelo adotado, mas para as pessoas, pequenas perturbações da curvatura do círculo ainda são consideradas um círculo, como você pode ver na Figura 3 .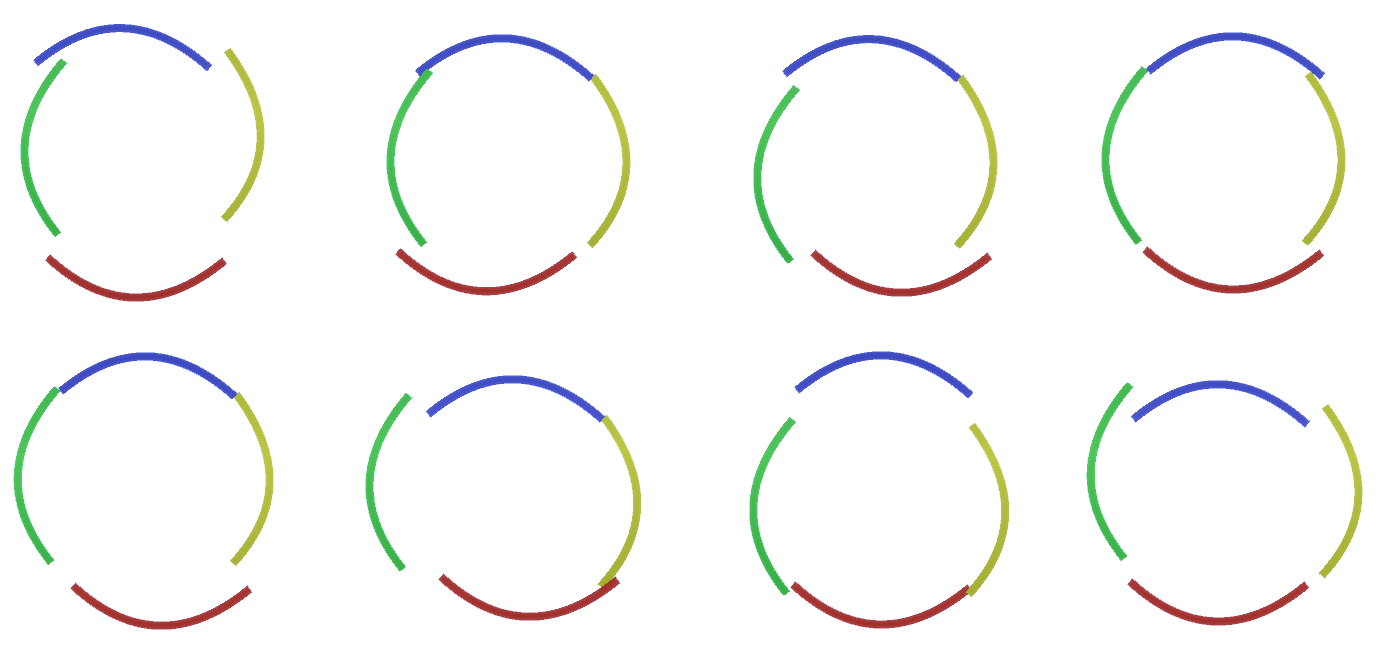 Figura 3: Muitas variações da construção de um círculo de quatro arcos curvos da Figura 2.Seria difícil considerar cada uma dessas variações como um novo canal separado na camada. Da mesma forma, o agrupamento de variações na mesma entidade facilitará muito a generalização em novas variações quando adaptarmos a RCN à classificação, em vez da geração, um pouco mais tarde. Mas como mudamos a RCN para obter essa oportunidade?
Figura 3: Muitas variações da construção de um círculo de quatro arcos curvos da Figura 2.Seria difícil considerar cada uma dessas variações como um novo canal separado na camada. Da mesma forma, o agrupamento de variações na mesma entidade facilitará muito a generalização em novas variações quando adaptarmos a RCN à classificação, em vez da geração, um pouco mais tarde. Mas como mudamos a RCN para obter essa oportunidade?Camadas de subamostragem
Para fazer isso, você precisa de um novo tipo de camada - a camada de pool. Está localizado entre duas camadas de sinais e atua como intermediário entre elas. Também consiste em canais, porém eles têm valores inteiros, não binários.Para ilustrar como essas camadas funcionam, vamos voltar ao exemplo do círculo. Em vez de exigir 4 arcos com coordenadas fixas da camada de feição acima dela como característica de um círculo, a pesquisa será realizada na camada de subamostra. Em seguida, cada canal ativado na camada de subamostra selecionará um nó na camada subjacente nas proximidades para permitir uma leve distorção do recurso. Assim, se estabelecermos comunicação com 9 nós diretamente abaixo do nó da subamostra, o canal da subamostra, sempre que for ativado, selecionará uniformemente um desses 9 nós e o ativará, e o índice do nó selecionado será o estado do canal da subamostra - um número inteiro. Na figura 4você pode ver várias execuções, nas quais cada execução usa um conjunto diferente de nós de nível inferior, respectivamente, permitindo criar um círculo de várias maneiras. Figura 4: Operação das camadas de subamostragem. Cada quadro nesta imagem GIF é um lançamento separado. Nós de subamostragem são em cubos. Nesta imagem, os nós da subamostra têm 4 canais equivalentes a 4 canais da camada de feição abaixo dela. As camadas superior e inferior foram completamente removidas da imagem.Apesar do fato de precisarmos da variabilidade do nosso modelo, seria melhor se ele permanecesse mais restrito e focado. Nas duas figuras anteriores, alguns círculos parecem estranhos demais para realmente interpretá-los como círculos devido ao fato de os arcos não estarem interconectados, como pode ser visto na Figura 5. Gostaríamos de evitar gerá-los. Assim, se pudéssemos adicionar um mecanismo para canais de subamostragem para coordenar a seleção de nós de recursos e focar em formulários contínuos, nosso modelo seria mais preciso.
Figura 4: Operação das camadas de subamostragem. Cada quadro nesta imagem GIF é um lançamento separado. Nós de subamostragem são em cubos. Nesta imagem, os nós da subamostra têm 4 canais equivalentes a 4 canais da camada de feição abaixo dela. As camadas superior e inferior foram completamente removidas da imagem.Apesar do fato de precisarmos da variabilidade do nosso modelo, seria melhor se ele permanecesse mais restrito e focado. Nas duas figuras anteriores, alguns círculos parecem estranhos demais para realmente interpretá-los como círculos devido ao fato de os arcos não estarem interconectados, como pode ser visto na Figura 5. Gostaríamos de evitar gerá-los. Assim, se pudéssemos adicionar um mecanismo para canais de subamostragem para coordenar a seleção de nós de recursos e focar em formulários contínuos, nosso modelo seria mais preciso. Figura 5: Muitas opções para construir um círculo. Essas opções que queremos soltar estão marcadas com cruzes vermelhas.Os autores da RCN usaram a conexão lateral em camadas de subamostragem para esse fim. Essencialmente, os canais de subamostragem terão links com outros canais de subamostragem do ambiente imediato, e esses links não permitirão que alguns pares de estados coexistam em dois canais simultaneamente. De fato, a área de amostra desses dois canais será simplesmente limitada. Em várias versões do círculo, essas conexões, por exemplo, não permitem que dois arcos adjacentes se afastem um do outro. Este mecanismo é mostrado na Figura 6.. Novamente, essas relações são estabelecidas na fase de treinamento. Deve-se notar que as redes neurais artificiais de baunilha modernas não têm conexões laterais em suas camadas, embora existam em redes neurais biológicas e supõe-se que elas tenham um papel na integração de contornos no córtex visual (mas, francamente, o córtex visual tem dispositivo mais complexo do que parece na declaração anterior).
Figura 5: Muitas opções para construir um círculo. Essas opções que queremos soltar estão marcadas com cruzes vermelhas.Os autores da RCN usaram a conexão lateral em camadas de subamostragem para esse fim. Essencialmente, os canais de subamostragem terão links com outros canais de subamostragem do ambiente imediato, e esses links não permitirão que alguns pares de estados coexistam em dois canais simultaneamente. De fato, a área de amostra desses dois canais será simplesmente limitada. Em várias versões do círculo, essas conexões, por exemplo, não permitem que dois arcos adjacentes se afastem um do outro. Este mecanismo é mostrado na Figura 6.. Novamente, essas relações são estabelecidas na fase de treinamento. Deve-se notar que as redes neurais artificiais de baunilha modernas não têm conexões laterais em suas camadas, embora existam em redes neurais biológicas e supõe-se que elas tenham um papel na integração de contornos no córtex visual (mas, francamente, o córtex visual tem dispositivo mais complexo do que parece na declaração anterior).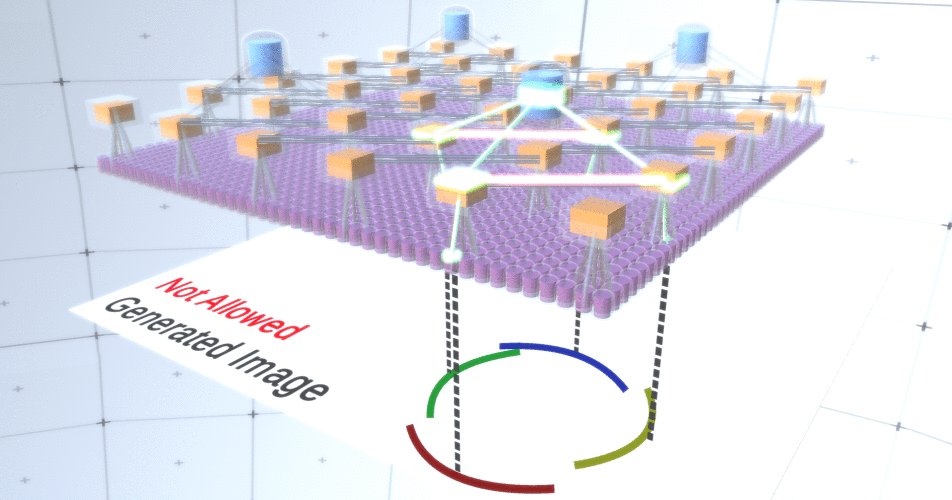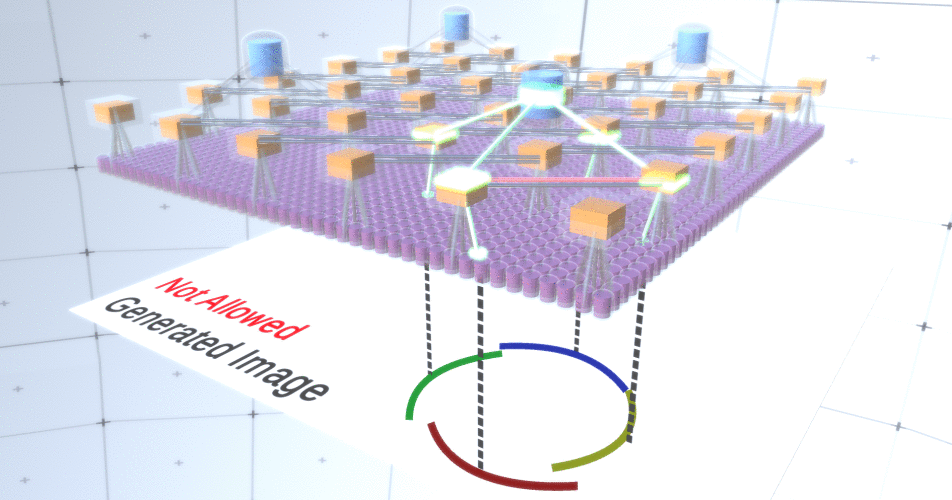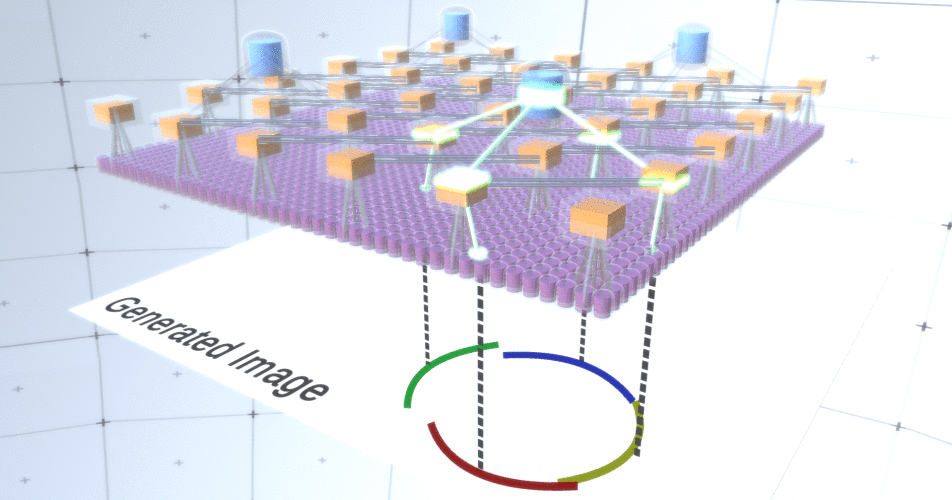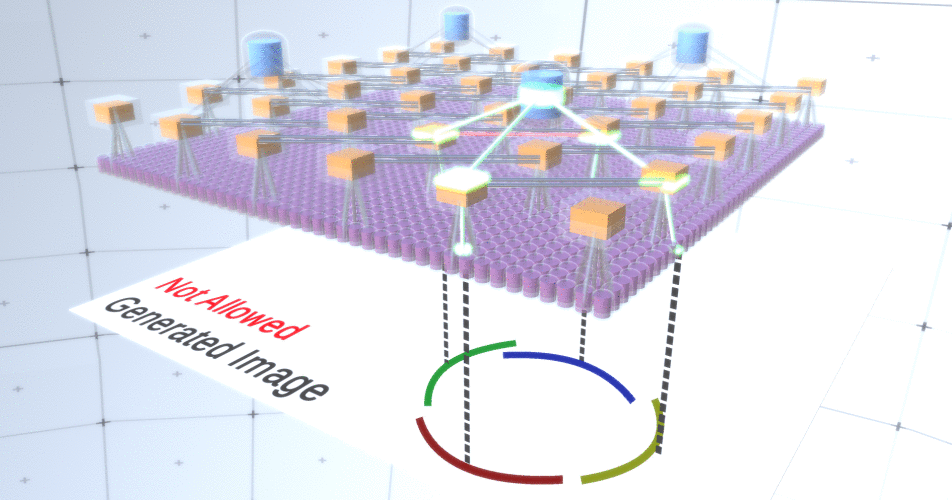 Figura 6: GIF- RCN . , . , RCN , , . .Até agora, falamos sobre as camadas intermediárias da RCN, temos apenas a camada superior e a camada inferior que interage com os pixels da imagem gerada. A camada superior é uma camada de recurso regular, onde os canais de cada nó são classes de nosso conjunto de dados rotulado. Ao gerar, simplesmente selecionamos o local e a classe que queremos criar, vamos para o nó com o local especificado e dizemos que ele ativa o canal da classe que selecionamos. Isso ativa alguns dos canais na camada de subamostra abaixo dele, depois a camada de recurso abaixo e assim por diante, até chegarmos à última camada de recurso. Com base no seu conhecimento de redes neurais convolucionais, você deve pensar que a camada superior terá um único nó, mas não é assim, e essa é uma das vantagens da RCN,mas uma discussão sobre este tópico está além do escopo deste artigo.A última camada de recurso será exclusiva. Lembre-se, eu falei sobre como as RCNs separam a forma da aparência? É essa camada que será responsável por obter a forma do objeto gerado. Portanto, essa camada deve funcionar com recursos de nível muito baixo, os blocos de construção mais básicos de qualquer forma, o que nos ajudará a gerar a forma desejada. Pequenas bordas rotativas em ângulos diferentes são bastante adequadas, e é exatamente elas que os autores da tecnologia usam.Os autores selecionaram os atributos do último nível para representar uma janela 3x3 que possui uma borda com um determinado ângulo de rotação, que eles chamam de descritor de patch. O número de ângulos de rotação que eles escolheram é 16. Além disso, para poder adicionar uma aparência mais tarde, você precisa de duas orientações para cada rotação, a fim de saber se o plano de fundo está na borda esquerda ou direita, se essas são bordas externas e orientação adicional no caso de limites internos (ou seja, dentro do objeto). Na Figura 7 mostra as características do último conjunto de camadas, e a Figura 8 mostra como os descritores de amostras podem gerar certa forma.
Figura 6: GIF- RCN . , . , RCN , , . .Até agora, falamos sobre as camadas intermediárias da RCN, temos apenas a camada superior e a camada inferior que interage com os pixels da imagem gerada. A camada superior é uma camada de recurso regular, onde os canais de cada nó são classes de nosso conjunto de dados rotulado. Ao gerar, simplesmente selecionamos o local e a classe que queremos criar, vamos para o nó com o local especificado e dizemos que ele ativa o canal da classe que selecionamos. Isso ativa alguns dos canais na camada de subamostra abaixo dele, depois a camada de recurso abaixo e assim por diante, até chegarmos à última camada de recurso. Com base no seu conhecimento de redes neurais convolucionais, você deve pensar que a camada superior terá um único nó, mas não é assim, e essa é uma das vantagens da RCN,mas uma discussão sobre este tópico está além do escopo deste artigo.A última camada de recurso será exclusiva. Lembre-se, eu falei sobre como as RCNs separam a forma da aparência? É essa camada que será responsável por obter a forma do objeto gerado. Portanto, essa camada deve funcionar com recursos de nível muito baixo, os blocos de construção mais básicos de qualquer forma, o que nos ajudará a gerar a forma desejada. Pequenas bordas rotativas em ângulos diferentes são bastante adequadas, e é exatamente elas que os autores da tecnologia usam.Os autores selecionaram os atributos do último nível para representar uma janela 3x3 que possui uma borda com um determinado ângulo de rotação, que eles chamam de descritor de patch. O número de ângulos de rotação que eles escolheram é 16. Além disso, para poder adicionar uma aparência mais tarde, você precisa de duas orientações para cada rotação, a fim de saber se o plano de fundo está na borda esquerda ou direita, se essas são bordas externas e orientação adicional no caso de limites internos (ou seja, dentro do objeto). Na Figura 7 mostra as características do último conjunto de camadas, e a Figura 8 mostra como os descritores de amostras podem gerar certa forma.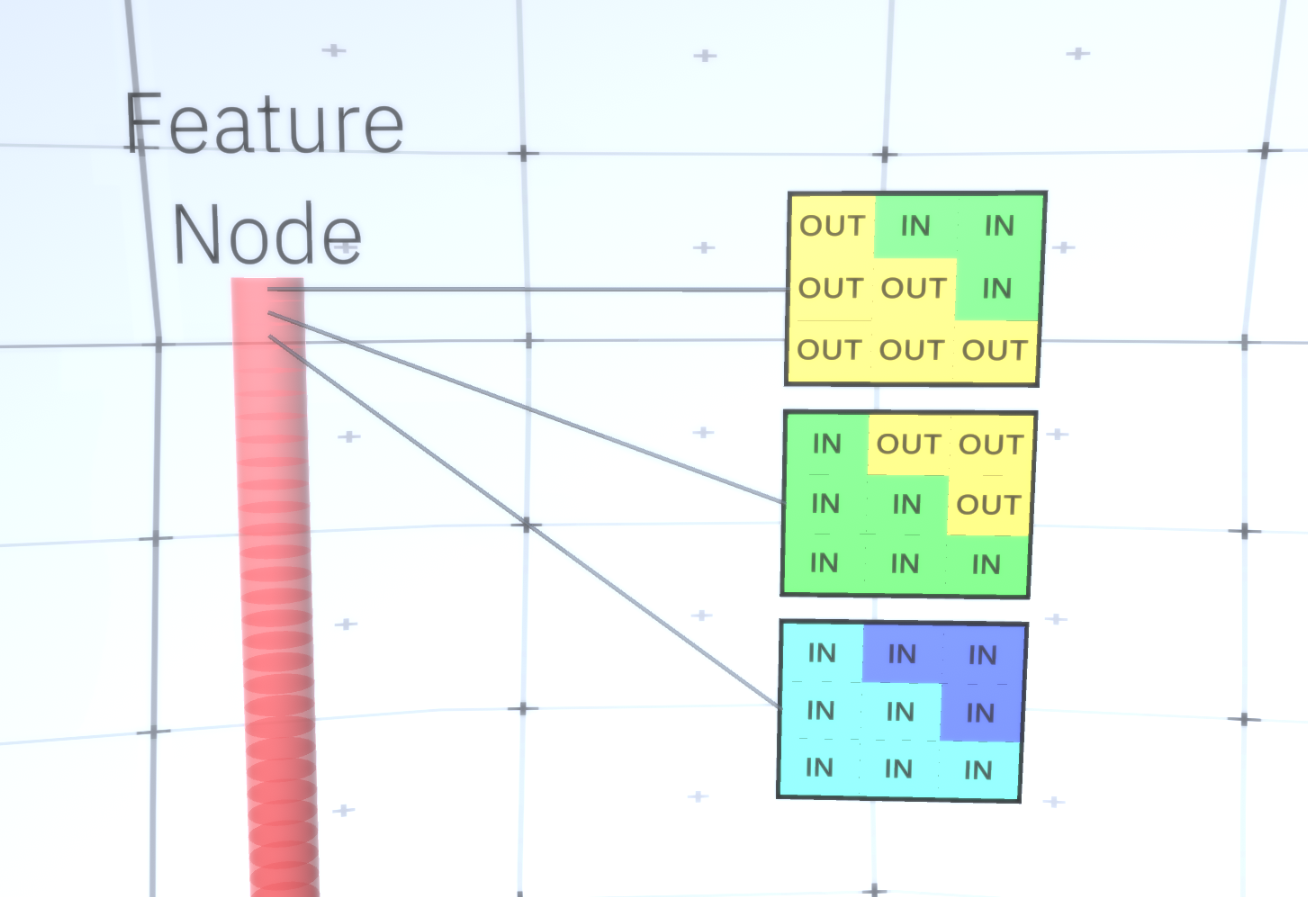 Figura 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — .
Figura 7: . 48 ( ) , 16 3 . – 45 . “IN " , “OUT” — . 8: «i» .Agora que alcançamos a última camada de sinais, temos um diagrama no qual os limites do objeto são determinados e a compreensão de se a área fora da borda é interna ou externa. Resta adicionar uma aparência, designando cada área restante da imagem como IN ou OUT e pintar sobre a área. Um campo aleatório condicional pode ajudar aqui. Sem entrar em detalhes matemáticos, simplesmente atribuímos a cada pixel na imagem final uma distribuição de probabilidade por cor e estado (IN ou OUT). Esta distribuição refletirá as informações obtidas a partir da borda do mapa. Por exemplo, se houver dois pixels adjacentes, um dos quais é IN e o outro é OUT, a probabilidade de que eles tenham uma cor diferente aumenta muito. Se dois pixels adjacentes estiverem em lados opostos da borda interna, a probabilidadeque terão uma cor diferente também aumentará. Se os pixels estiverem dentro da borda e não estiverem separados por nada, a probabilidade de que eles tenham a mesma cor aumentará, mas os pixels externos podem ter um leve desvio um do outro e assim por diante. Para obter a imagem final, basta selecionar a distribuição de probabilidade conjunta que acabamos de instalar. Para tornar a imagem gerada mais interessante, podemos substituir as cores pela textura. Não discutiremos essa camada porque o RCN pode executar a classificação sem basear-se na aparência.Para obter a imagem final, basta fazer uma seleção da distribuição de probabilidade conjunta que acabamos de instalar. Para tornar a imagem gerada mais interessante, podemos substituir as cores pela textura. Não discutiremos essa camada porque o RCN pode executar a classificação sem basear-se na aparência.Para obter a imagem final, basta fazer uma seleção da distribuição de probabilidade conjunta que acabamos de instalar. Para tornar a imagem gerada mais interessante, podemos substituir as cores pela textura. Não discutiremos essa camada porque o RCN pode executar a classificação sem basear-se na aparência.Bem, vamos terminar aqui por hoje. Se você quiser saber mais sobre a RCN, leia este artigo [5] e o apêndice com materiais adicionais ou leia meus outros artigos sobre as conclusões lógicas , o treinamento e os resultados do uso da RCN em vários conjuntos de dados .
8: «i» .Agora que alcançamos a última camada de sinais, temos um diagrama no qual os limites do objeto são determinados e a compreensão de se a área fora da borda é interna ou externa. Resta adicionar uma aparência, designando cada área restante da imagem como IN ou OUT e pintar sobre a área. Um campo aleatório condicional pode ajudar aqui. Sem entrar em detalhes matemáticos, simplesmente atribuímos a cada pixel na imagem final uma distribuição de probabilidade por cor e estado (IN ou OUT). Esta distribuição refletirá as informações obtidas a partir da borda do mapa. Por exemplo, se houver dois pixels adjacentes, um dos quais é IN e o outro é OUT, a probabilidade de que eles tenham uma cor diferente aumenta muito. Se dois pixels adjacentes estiverem em lados opostos da borda interna, a probabilidadeque terão uma cor diferente também aumentará. Se os pixels estiverem dentro da borda e não estiverem separados por nada, a probabilidade de que eles tenham a mesma cor aumentará, mas os pixels externos podem ter um leve desvio um do outro e assim por diante. Para obter a imagem final, basta selecionar a distribuição de probabilidade conjunta que acabamos de instalar. Para tornar a imagem gerada mais interessante, podemos substituir as cores pela textura. Não discutiremos essa camada porque o RCN pode executar a classificação sem basear-se na aparência.Para obter a imagem final, basta fazer uma seleção da distribuição de probabilidade conjunta que acabamos de instalar. Para tornar a imagem gerada mais interessante, podemos substituir as cores pela textura. Não discutiremos essa camada porque o RCN pode executar a classificação sem basear-se na aparência.Para obter a imagem final, basta fazer uma seleção da distribuição de probabilidade conjunta que acabamos de instalar. Para tornar a imagem gerada mais interessante, podemos substituir as cores pela textura. Não discutiremos essa camada porque o RCN pode executar a classificação sem basear-se na aparência.Bem, vamos terminar aqui por hoje. Se você quiser saber mais sobre a RCN, leia este artigo [5] e o apêndice com materiais adicionais ou leia meus outros artigos sobre as conclusões lógicas , o treinamento e os resultados do uso da RCN em vários conjuntos de dados .Fontes:
- [1] R. Perrault, Y. Shoham, E. Brynjolfsson, et al., The AI Index 2019 Annual Report (2019), Human-Centered AI Institute - Stanford University.
- [2] D. Hendrycks, K. Zhao, S. Basart, et al., Natural Adversarial Examples (2019), arXiv: 1907.07174.
- [3] J. Su, D. Vasconcellos Vargas e S. Kouichi, One Pixel Attack for Fooling Deep Neural Networks (2017), arXiv: 1710.08864.
- [4] M. Sharif, S. Bhagavatula, L. Bauer, Uma estrutura geral para exemplos adversos com objetivos (2017), arXiv: 1801.00349.
- [5] D. George, W. Lehrach, K. Kansky, et al., A Generative Vision Model that Trains with High Data Efficiency and Break Text-based CAPTCHAs (2017), Science Mag (Vol 358 — Issue 6368).
- [6] H. Liang, X. Gong, M. Chen, et al., Interactions Between Feedback and Lateral Connections in the Primary Visual Cortex (2017), Proceedings of the National Academy of Sciences of the United States of America.
: « : ». Source: https://habr.com/ru/post/undefined/
All Articles