Olá, Habr.Meu nome é Misha Butrimov, gostaria de falar um pouco sobre Cassandra. Minha história será útil para quem nunca encontrou bancos de dados NoSQL - ela possui muitos recursos e armadilhas de implementação que você precisa conhecer. E se, além da Oracle ou de qualquer outra base relacional, você não tiver visto nada, essas coisas salvarão sua vida.O que há de bom em Cassandra? Este é um banco de dados NoSQL projetado sem um único ponto de falha, que escala bem. Se você precisar adicionar alguns terabytes para qualquer base, basta adicionar nós ao anel. Estendê-lo para outro data center? Adicione nós ao cluster. Aumentar RPS processado? Adicione nós ao cluster. A outra maneira também funciona. No que mais ela é boa? É para lidar com muitos pedidos. Mas quanto é quanto? 10, 20, 30, 40 mil solicitações por segundo - isso não é muito. 100 mil solicitações por segundo para gravação também. Há empresas que disseram ter 2 milhões de solicitações por segundo. Aqui eles provavelmente têm que acreditar.E, em princípio, Cassandra tem uma grande diferença em relação aos dados relacionais - eles não se parecem com eles. E isso é muito importante para lembrar.
No que mais ela é boa? É para lidar com muitos pedidos. Mas quanto é quanto? 10, 20, 30, 40 mil solicitações por segundo - isso não é muito. 100 mil solicitações por segundo para gravação também. Há empresas que disseram ter 2 milhões de solicitações por segundo. Aqui eles provavelmente têm que acreditar.E, em princípio, Cassandra tem uma grande diferença em relação aos dados relacionais - eles não se parecem com eles. E isso é muito importante para lembrar.Nem tudo o que parece igual funciona da mesma maneira
Certa vez, um colega me procurou e perguntou: “Aqui está a linguagem de consulta do CQL Cassandra, e ela tem uma instrução select, ela tem onde, tem e. Eu escrevo cartas e não funciona. Por quê?". Se você tratar Cassandra como um banco de dados relacional, essa é a maneira ideal de terminar sua vida com um suicídio brutal. E eu não advogo, é proibido na Rússia. Você está apenas projetando algo errado.Por exemplo, um cliente chega até nós e diz: “Vamos criar um banco de dados para programas de TV ou um banco de dados para um diretório de receitas. Teremos pratos de comida lá ou uma lista de séries e atores. Dizemos alegremente: "Vamos lá!". Estes são dois bytes para enviar, algumas placas e tudo está pronto, tudo funcionará muito rapidamente, de forma confiável. E está tudo bem até os clientes chegarem e dizerem que as donas de casa também estão resolvendo o problema inverso: elas têm uma lista de produtos e querem saber qual prato querem cozinhar. Você está morto.Isso ocorre porque o Cassandra é um banco de dados híbrido: é um valor-chave e armazena dados em colunas amplas. Falando em Java ou Kotlin, poderia ser descrito assim:Map<RowKey, SortedMap<ColumnKey, ColumnValue>>Ou seja, um mapa, dentro do qual também há um mapa classificado. A primeira chave desse mapa é a chave de linha ou a chave de partição - a chave de partição. A segunda chave, que é a chave do mapa já classificado, é a chave de cluster.Para ilustrar a distribuição do banco de dados, desenhamos três nós. Agora você precisa entender como decompor dados em nós. Porque se colocarmos tudo em um (a propósito, pode haver mil, dois mil, cinco - quantos você quiser), isso não é realmente sobre distribuição. Portanto, precisamos de uma função matemática que retorne um número. Apenas um número, um int longo que cairá em algum intervalo. E nós temos um nó que será responsável por um intervalo, o segundo - pelo segundo, n-ésimo - pelo n-ésimo. Esse número é obtido usando uma função hash que se aplica exatamente ao que chamamos de chave Partition. Essa é a coluna especificada na diretiva Chave Primária e esta é a coluna que será a primeira e a mais básica chave do mapa. Determina qual nó obtém quais dados. Uma tabela é criada no Cassandra com quase a mesma sintaxe que no SQL:
Esse número é obtido usando uma função hash que se aplica exatamente ao que chamamos de chave Partition. Essa é a coluna especificada na diretiva Chave Primária e esta é a coluna que será a primeira e a mais básica chave do mapa. Determina qual nó obtém quais dados. Uma tabela é criada no Cassandra com quase a mesma sintaxe que no SQL:CREATE TABLE users (
user_id uu id,
name text,
year int,
salary float,
PRIMARY KEY(user_id)
)
A chave primária nesse caso consiste em uma coluna e também é uma chave de partição.Como os usuários cairão conosco? Parte cairá em uma nota, parte em outra e parte em uma terceira. Acontece uma tabela de hash comum, também é um mapa, também é um dicionário em Python, é também uma estrutura simples de valor de chave, na qual podemos ler todos os valores, ler e escrever por chave.
Selecione: quando permitir que a filtragem se transforme em varredura completa ou como não fazer
Vamos escrever alguma declaração O Select: select * from users where, userid = . Parece que, como no Oracle: escrevemos select, especificamos condições e tudo funciona, os usuários conseguem. Mas se você selecionar, por exemplo, um usuário com um determinado ano de nascimento, Cassandra jura que não pode atender à solicitação. Como ela não sabe nada sobre como distribuímos dados sobre o ano de nascimento - ela tem apenas uma coluna especificada como chave. Então ela diz: “Ok, ainda posso atender a essa solicitação. Adicione permitir filtragem ". Nós adicionamos uma diretiva, tudo funciona. E nesse momento uma coisa terrível acontece.Quando dirigimos dados de teste, tudo está bem. E quando você atende à solicitação de produção, onde, por exemplo, temos 4 milhões de registros, tudo não está muito bem conosco. Como permitir filtragem é uma diretiva que permite ao Cassandra coletar todos os dados desta tabela de todos os nós, todos os datacenters (se houver muitos deles nesse cluster) e somente filtrá-los. Este é um análogo do Full Scan, e quase ninguém se deleita com isso.Se apenas precisássemos de usuários por identificadores, isso nos conviria. Mas, às vezes, precisamos escrever outras consultas e impor outras restrições à seleção. Portanto, lembramos: todos temos um mapa, que possui uma chave de partição, mas dentro dele há um mapa classificado.E ela também tem uma chave, que chamamos de chave de cluster. Essa chave, que, por sua vez, consiste nas colunas que selecionamos, com as quais Cassandra entende como seus dados são classificados fisicamente e estarão em cada nó. Ou seja, para algumas chaves de Partição, a chave de Clustering informará exatamente como inserir os dados nessa árvore, em que lugar eles ocuparão lá.Esta é realmente uma árvore, um comparador é simplesmente chamado ali, para o qual passamos um certo conjunto de colunas na forma de um objeto, e também é definido na forma de uma listagem de colunas.CREATE TABLE users_by_year_salary_id (
user_id uuid,
name text,
year int,
salary float,
PRIMARY KEY((year), salary, user_id)
Preste atenção à diretiva de chave primária, pois o primeiro argumento (no nosso caso, o ano) é sempre a chave de partição. Pode consistir em uma ou várias colunas, não importa. Se houver várias colunas, será necessário removê-lo novamente entre parênteses, para que o pré-processador do idioma entenda que essa é a chave Primária e, por trás dela, todas as outras colunas - a chave de Cluster. Nesse caso, eles serão transmitidos no comparador na ordem em que vão. Ou seja, a primeira coluna é mais significativa, a segunda é menos significativa e assim por diante. À medida que escrevemos para classes de dados, por exemplo, é igual a campos: listamos campos e, para eles, escrevemos quais são maiores e quais são menores. Em Cassandra, esse é, relativamente falando, o campo da classe de dados ao qual os iguais escritos para ele serão aplicados.Definimos o tipo, impomos restrições
Deve-se lembrar que a ordem de classificação (decrescente, crescente, não importa) é definida ao mesmo tempo em que a chave é criada e não é possível alterá-la posteriormente. Ele determina fisicamente como os dados serão classificados e como eles estarão. Se você precisar alterar a chave de cluster ou a ordem de classificação, será necessário criar uma nova tabela e inserir dados nela. Com o existente, isso não funcionará.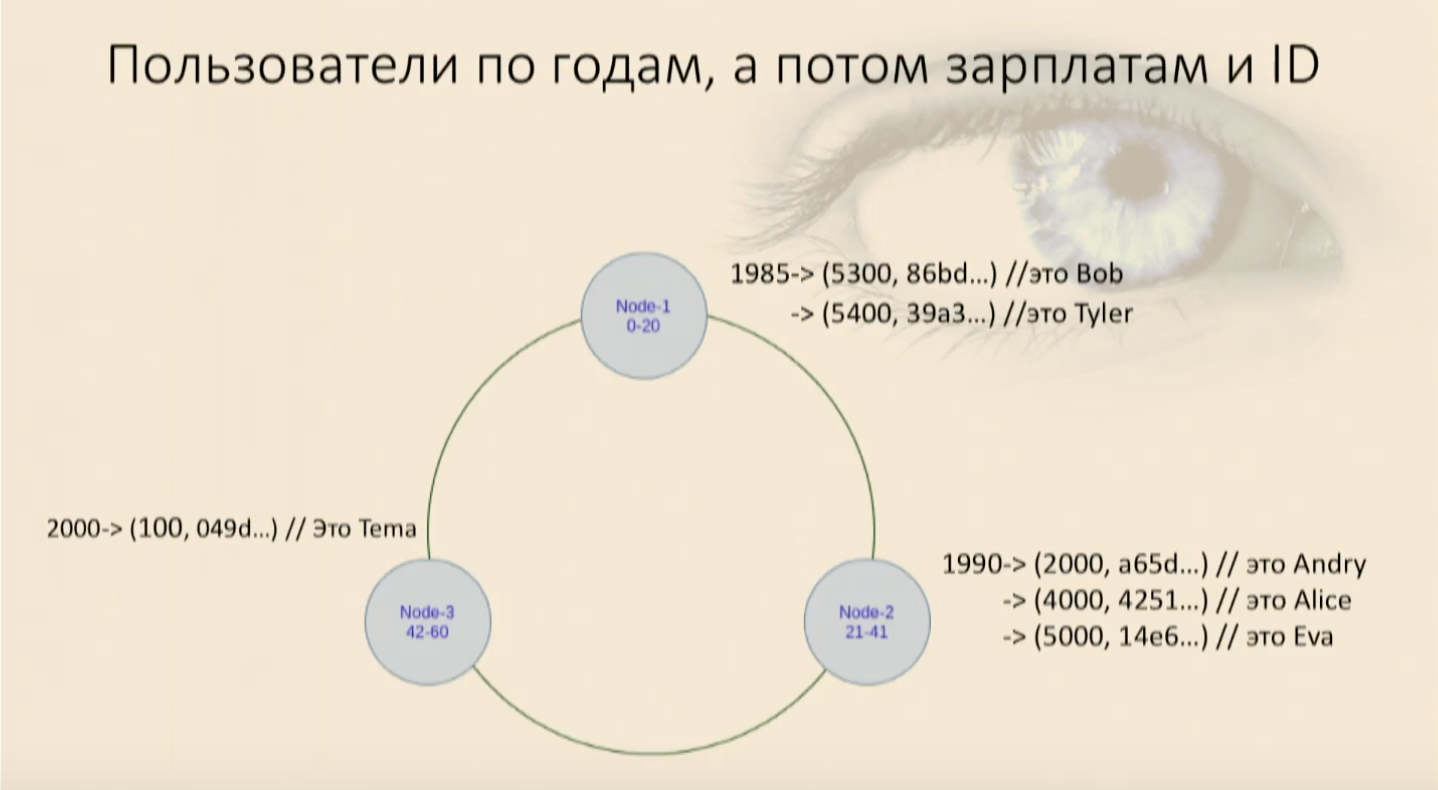 Enchemos nossa mesa com usuários e vimos que eles entraram em contato, primeiro por ano de nascimento e depois em cada nó por salário e por ID do usuário. Agora podemos selecionar, impondo restrições.Nosso trabalho aparece novamente
Enchemos nossa mesa com usuários e vimos que eles entraram em contato, primeiro por ano de nascimento e depois em cada nó por salário e por ID do usuário. Agora podemos selecionar, impondo restrições.Nosso trabalho aparece novamentewhere, and, e os usuários chegam até nós e tudo está bem novamente. Mas se tentarmos usar apenas a parte chave de cluster, a menos significativa, Cassandra jurará imediatamente que não podemos encontrar em nosso mapa onde esse objeto tem esses campos para o comparador nulo, mas este que acabou de ser definido - onde está. Vou ter que pegar todos os dados desse nó novamente e filtrá-lo. E este é um análogo do Full Scan dentro do nó, isso é ruim.Em qualquer situação incompreensível, crie uma nova tabela
Se quisermos obter usuários por ID, idade ou salário, o que devemos fazer? Nada. Apenas use duas tabelas. Se você precisar obter usuários de três maneiras diferentes - haverá três tabelas. Longe vão os dias em que economizamos espaço no parafuso. Este é o recurso mais barato. Custa muito menos que o tempo de resposta, o que pode ser fatal para o usuário. O usuário é muito mais agradável para conseguir algo em um segundo do que em 10 minutos.Trocamos espaço excessivo, dados desnormalizados pela capacidade de escalar bem e trabalhar de forma confiável. De fato, na realidade, um cluster que consiste em três datacenters, cada um com cinco nós, com um nível aceitável de armazenamento de dados (quando nada é perdido com certeza), é capaz de sobreviver completamente à morte de um datacenter. E mais dois nós em cada um dos dois restantes. E somente depois disso os problemas começam. Essa é uma redundância bastante boa, pois custa algumas unidades e processadores ssd desnecessários. Portanto, para usar o Cassandra, que nunca é SQL, no qual não há relacionamentos, nem chaves estrangeiras, você precisa conhecer regras simples.Nós projetamos tudo, desde uma solicitação. O principal não são os dados, mas como o aplicativo vai trabalhar com eles. Se ele precisar receber dados diferentes de maneiras diferentes ou os mesmos dados de maneiras diferentes, devemos colocá-los da maneira que for conveniente para a aplicação. Caso contrário, falharemos no Full Scan e o Cassandra não nos dará nenhuma vantagem.Desnormalizar dados é a norma. Esqueça os formulários normais, não temos mais bancos de dados relacionais. Colocamos algo 100 vezes, ele mentirá 100 vezes. É mais barato do que pará-lo de qualquer maneira.Selecionamos as chaves para particionar para que elas sejam distribuídas normalmente. Não precisamos que o hash de nossas chaves caia em um intervalo estreito. Ou seja, o ano de nascimento no exemplo acima é um mau exemplo. Em vez disso, é bom que nossos usuários sejam normalmente distribuídos por ano de nascimento e ruim se estivermos falando de alunos da 5ª série - não será muito bom particionar lá.A classificação é selecionada uma vez durante a criação da chave de cluster. Se você precisar alterá-lo, precisará preencher demais a nossa tabela com uma chave diferente.E o mais importante: se precisarmos coletar os mesmos dados de 100 maneiras diferentes, teremos 100 tabelas diferentes.