Olá a todos!Quero falar sobre um projeto muito chato, onde robótica, Machine Learning (e juntos é Robot Learning), realidade virtual e um pouco de tecnologia em nuvem se cruzam. E tudo isso realmente faz sentido. Afinal, é realmente conveniente mudar para um robô, mostrar o que fazer e treinar pesos no servidor ML usando os dados armazenados.Abaixo do corte, contaremos como ele funciona agora e alguns detalhes sobre cada um dos aspectos que precisavam ser desenvolvidos.
Pelo que
Para começar, vale a pena revelar um pouco.Parece que robôs armados com o Deep Learning estão prestes a expulsar pessoas de seus empregos em todos os lugares. De fato, nem tudo é tão bom. Onde as ações são estritamente repetidas, os processos já estão muito bem automatizados. Se estamos falando de "robôs inteligentes", isto é, aplicativos onde a visão e os algoritmos de computador já são suficientes. Mas também existem muitas histórias extremamente complicadas. Os robôs dificilmente conseguem lidar com a variedade de objetos com os quais precisam lidar e a diversidade do ambiente.Pontos chave
Existem três aspectos principais em termos de implementação que ainda não foram encontrados em todos os lugares:- (data-driven learning). .. , , , . , .
- ()
- - (Human-machine collaboration)
O segundo também é importante, porque agora observaremos uma mudança nas abordagens de aprendizado, algoritmos, por trás deles e ferramentas de computação. Os algoritmos de percepção e controle se tornarão mais flexíveis. Uma atualização de robô custa dinheiro. E a calculadora pode ser usada com mais eficiência se atender a vários robôs ao mesmo tempo. Esse conceito é chamado de "robótica em nuvem".Com o último, tudo é simples - a IA não está suficientemente desenvolvida no momento para fornecer 100% de confiabilidade e precisão em todas as situações exigidas pelos negócios. Portanto, o operador supervisor, que às vezes pode ajudar os robôs de proteção, não fará mal.Esquema
Para começar, sobre uma plataforma de software / rede que fornece todas as funcionalidades descritas: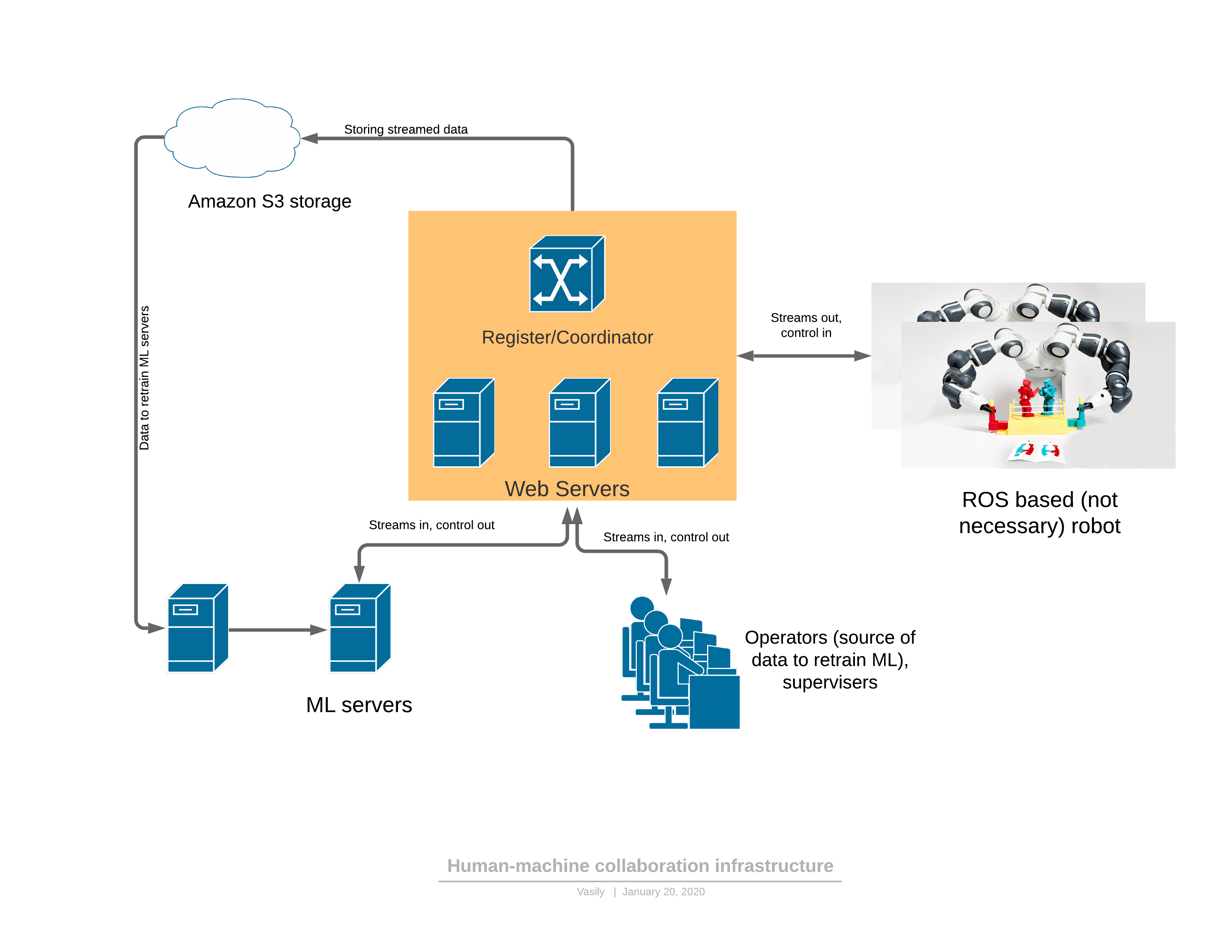 Componentes:
Componentes:- O robô envia um fluxo de vídeo 3D para o servidor e recebe controle em resposta.
- : - , (, , , )
- ML ( ), , , . — 3D , .
- - , 3D , UI . — .
Existem 2 modos de funcionamento do robô: automático e manual.No modo manual, o robô funciona se o serviço ML ainda não estiver treinado. Em seguida, o robô passa de automático para manual ou a pedido do operador (vi comportamentos estranhos enquanto assistia o robô) ou quando os próprios serviços de ML detectam uma anomalia. Sobre a detecção de anomalias será mais tarde - esta é uma parte muito importante, sem a qual é impossível aplicar a abordagem proposta.A evolução do controle é a seguinte:- A tarefa do robô é formada em termos legíveis por humanos e os indicadores de desempenho são descritos.
- O operador se conecta ao robô em VR e executa a tarefa no fluxo de trabalho existente por algum tempo
- A parte ML é treinada nos dados recebidos
- , ML
3D
Muitas vezes, os robôs usam o ambiente ROS (sistema operacional do robô), que na verdade é uma estrutura para gerenciar "nós" (nós), cada um dos quais fornece parte da funcionalidade do robô. Em geral, essa é uma maneira relativamente conveniente de programar robôs, que de certa forma se assemelha à arquitetura de microsserviço de aplicativos da Web em sua essência. A principal vantagem do ROS é o padrão do setor e já existe um grande número de módulos necessários para criar um robô. Até os braços robóticos industriais podem ter um módulo de interface ROS.O mais simples é criar um modelo de ponte entre a parte do servidor e o ROS. Por exemplo, tais. Agora, nosso projeto usa uma versão mais desenvolvida do “nó” do ROS, que efetua login e pesquisa o microsserviço do registro ao qual servidor de retransmissão um robô específico pode se conectar. O código fonte é fornecido apenas como um exemplo de instruções para a instalação do módulo ROS. No início, quando você domina essa estrutura (ROS), tudo parece bastante hostil, mas a documentação é muito boa e, após algumas semanas, os desenvolvedores começam a usar sua funcionalidade com bastante confiança.De interessante - o problema de compressão do fluxo de dados 3D, que deve ser produzido diretamente no robô.Não é tão fácil compactar o mapa de profundidade. Mesmo com um pequeno grau de compactação do fluxo RGB, é permitida uma distorção local muito séria do brilho em pixels nas bordas ou quando objetos em movimento são permitidos. O olho quase não percebe isso, mas assim que as mesmas distorções são permitidas no mapa de profundidade, ao renderizar em 3D tudo fica muito ruim: (do artigo )Esses defeitos nas bordas estragam bastante a cena 3D, porque há muito lixo no ar.Começamos a usar a compactação quadro a quadro - JPEG para RGB e PNG para um mapa de profundidade com pequenos hacks. Esse método compacta o fluxo de 30FPS para uma resolução de scanner 3D de 640x480 a 25 Mbps. Uma melhor compactação também pode ser fornecida se o tráfego for crítico para o aplicativo. Existem codecs de fluxo 3D comerciais que também podem ser usados para compactar esse fluxo.
(do artigo )Esses defeitos nas bordas estragam bastante a cena 3D, porque há muito lixo no ar.Começamos a usar a compactação quadro a quadro - JPEG para RGB e PNG para um mapa de profundidade com pequenos hacks. Esse método compacta o fluxo de 30FPS para uma resolução de scanner 3D de 640x480 a 25 Mbps. Uma melhor compactação também pode ser fornecida se o tráfego for crítico para o aplicativo. Existem codecs de fluxo 3D comerciais que também podem ser usados para compactar esse fluxo.Controle de realidade virtual
Depois de calibrarmos o quadro de referência da câmera e do robô (e já escrevemos um artigo sobre calibração ), o braço do robô pode ser controlado em realidade virtual. O controlador define a posição no 3D XYZ e a orientação. Para alguns roboruk, apenas 3 coordenadas serão suficientes, mas com um grande número de graus de liberdade, a orientação da ferramenta especificada pelo controlador também deve ser transmitida. Além disso, há controles suficientes nos controladores para executar comandos do robô, como ligar / desligar a bomba, controlar a garra e outros.Inicialmente, foi decidido usar a estrutura JavaScript para o quadro A de realidade virtual, com base no mecanismo WebVR. E os primeiros resultados (demonstração em vídeo no final do artigo para o braço de 4 coordenadas) foram obtidos no quadro A.De fato, descobriu-se que o WebVR (ou quadro A) era uma solução malsucedida por vários motivos:- compatibilidade principalmente com o FireFox , enquanto era no FireFox que a estrutura A-frame não liberava recursos de textura (o resto dos navegadores lidavam) até que o consumo de memória chegasse a 16 GB
- interação limitada com controladores e capacete VR. Portanto, por exemplo, não foi possível adicionar marcas adicionais com as quais você pode definir a posição, por exemplo, dos cotovelos do operador.
- O aplicativo exigia multithreading ou vários processos. Em um thread / processo, foi necessário descompactar os quadros de vídeo, em outro - empate. Como resultado, tudo foi organizado pelos trabalhadores, mas o tempo de desempacotamento chegou a 30 ms e a renderização em VR deve ser feita a uma frequência de 90FPS.
Todas essas deficiências resultaram no fato de que a renderização do quadro não teve tempo nos 10ms atribuídos e houve contrações muito desagradáveis na VR. Provavelmente, tudo poderia ser superado, mas a identidade de cada navegador era um pouco irritante.Agora decidimos partir para as portas C #, OpenTK e C # da biblioteca OpenVR. Ainda existe uma alternativa - Unidade. Eles escrevem que a Unity é para iniciantes ... mas difícil.A coisa mais importante que precisava ser encontrada e conhecida para obter liberdade:VRTextureBounds_t bounds = new VRTextureBounds_t() { uMin = 0, vMin = 0, uMax = 1f, vMax = 1f };
OpenVR.Compositor.Submit(EVREye.Eye_Left, ref leftTexture, ref bounds, EVRSubmitFlags.Submit_Default);
OpenVR.Compositor.Submit(EVREye.Eye_Right, ref rightTexture, ref bounds, EVRSubmitFlags.Submit_Default);
(este é o código para enviar duas texturas para os olhos esquerdo e direito do capacete),ou seja, desenhe o OpenGL na textura que olhos diferentes vêem e envie para os óculos. Joy não tinha limites quando se tratava de encher o olho esquerdo de vermelho e o direito de azul. Apenas alguns dias e agora a profundidade e o mapa RGB vindo via webSocket foram transferidos para o modelo poligonal em 10ms em vez de 30 em JS. E, em seguida, basta interrogar as coordenadas e os botões dos controladores, inserir o sistema de eventos para os botões, processar cliques do usuário, inserir a Máquina de estado para a interface do usuário e agora você pode pegar um copo do café expresso:Agora a qualidade do Realsense D435 é um pouco deprimente, mas passará assim que instalarmos pelo menos um scanner 3D tão interessante da Microsoft , cuja nuvem de pontos é muito mais precisa.Lado do servidor
Servidor de retransmissãoO principal elemento funcional é a retransmissão do servidor (servidor no meio), que recebe um fluxo de vídeo do robô com imagens 3D e leituras de sensores e o estado do robô e o distribui entre os consumidores. Insira quadros compactados com dados e leituras de sensores provenientes de TCP / IP. A distribuição aos consumidores é realizada por soquetes da Web (um mecanismo muito conveniente para transmitir para vários consumidores, incluindo um navegador).Além disso, o servidor de armazenamento temporário armazena o fluxo de dados no armazenamento em nuvem S3, para que possa ser usado posteriormente para treinamento.Cada servidor de retransmissão suporta a API http, que permite descobrir seu estado atual, o que é conveniente para monitorar as conexões atuais.A tarefa de retransmissão é bastante difícil, tanto do ponto de vista da computação quanto do ponto de vista do tráfego. Portanto, seguimos a lógica de que os servidores de retransmissão são implantados em uma variedade de servidores em nuvem. E isso significa que você precisa acompanhar quem está se conectando aonde (especialmente se houver robôs e operadores em regiões diferentes)Registre-seO mais confiável agora será difícil de definir para cada robô em que servidores ele pode se conectar (a redundância não será prejudicial). O serviço de gerenciamento de ML está associado ao robô; ele pesquisa o servidor de retransmissão para determinar a quem o robô está conectado e se conecta ao correspondente, se, é claro, ele possui direitos suficientes para isso. O aplicativo do operador funciona de maneira semelhante.O mais agradável! Devido ao fato de o treinamento de robôs ser um serviço, o serviço é visível apenas para nós dentro. Portanto, seu front-end pode ser o mais conveniente possível para nós! Essa. é um console no navegador (há uma biblioteca terminalJS que é bonita em sua simplicidade , que é muito fácil de modificar, se você deseja funções adicionais, como a conclusão automática do TAB ou o histórico de chamadas em execução) e tem a seguinte aparência: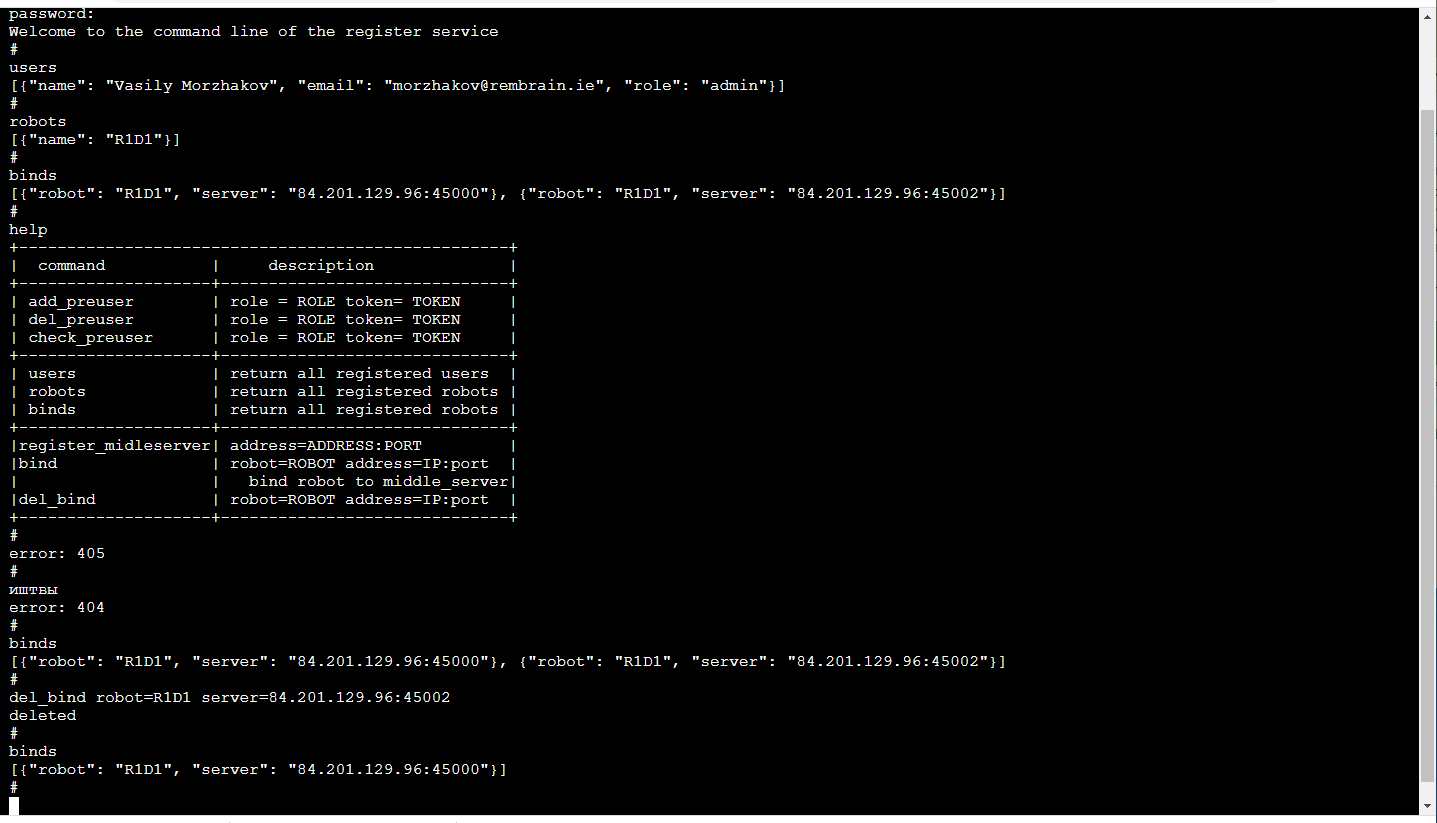 Este, é claro, é um tópico separado para discussão, por que a linha de comando tão confortável. A propósito, é especialmente conveniente fazer testes de unidade desse front-end.Além da API http, este serviço implementa um mecanismo para registrar usuários com tokens temporários, operadores de logon / logout, administradores e robôs, suporte de sessão, chaves de criptografia de sessão para tráfego entre o servidor de retransmissão e o robô.Tudo isso é feito em Python com Flask - uma pilha muito próxima para desenvolvedores de ML (ou seja, nós). Sim, além disso, a infraestrutura existente de CI / CD para microsserviços é amigável com o Flask.
Este, é claro, é um tópico separado para discussão, por que a linha de comando tão confortável. A propósito, é especialmente conveniente fazer testes de unidade desse front-end.Além da API http, este serviço implementa um mecanismo para registrar usuários com tokens temporários, operadores de logon / logout, administradores e robôs, suporte de sessão, chaves de criptografia de sessão para tráfego entre o servidor de retransmissão e o robô.Tudo isso é feito em Python com Flask - uma pilha muito próxima para desenvolvedores de ML (ou seja, nós). Sim, além disso, a infraestrutura existente de CI / CD para microsserviços é amigável com o Flask.Atraso no problema
Se queremos controlar os manipuladores em tempo real, o atraso mínimo é extremamente útil. Se o atraso se tornar muito grande (mais de 300 ms), será muito difícil controlar os manipuladores com base na imagem no capacete virtual. Em nossa solução, devido à compactação quadro a quadro (ou seja, não há armazenamento em buffer) e ao não uso de ferramentas padrão como o GStreamer, o atraso, mesmo considerando o servidor intermediário, é de cerca de 150-200 ms. O tempo de transmissão pela rede deles é de cerca de 80ms. O restante do atraso é causado pela câmera Realsense D435 e pela frequência de captura limitada.Obviamente, esse é um problema de altura máxima que surge no modo de "rastreamento", quando o manipulador em sua realidade segue constantemente o controlador do operador em realidade virtual. No modo de mudar para um determinado ponto XYZ, o atraso não causa problemas ao operador.Parte ML
Existem 2 tipos de serviços: gerenciamento e treinamento.O serviço de treinamento coleta os dados armazenados no armazenamento S3 e inicia o novo treinamento dos pesos do modelo. No final do treinamento, os pesos são enviados ao serviço de gerenciamento.O serviço de gerenciamento não é diferente em termos de dados de entrada e saída do aplicativo do operador. Da mesma forma, o fluxo de entrada RGBD (RGB + Depth), as leituras do sensor e o status do robô, os comandos de controle de saída. Devido a essa identidade, parece possível treinar na estrutura do conceito de “treinamento orientado a dados”.O estado do robô (e as leituras dos sensores) é uma história fundamental para o ML. Ele define o contexto. Por exemplo, um robô terá uma máquina de estado característica de sua operação, que determina em grande parte que tipo de controle é necessário. Esses 2 valores são transmitidos junto com cada quadro: o modo de operação e o vetor de estado do robô.E um pouco sobre treinamento:na demonstração no final do artigo, havia a tarefa de encontrar um objeto (um cubo infantil) em uma cena 3D. Essa é uma tarefa básica para os aplicativos pick & place.O treinamento foi baseado em um par de quadros "antes e depois" e designação de alvo obtidos com controle manual: devido à presença de dois mapas de profundidade, foi fácil calcular a máscara do objeto movido no quadro:
devido à presença de dois mapas de profundidade, foi fácil calcular a máscara do objeto movido no quadro: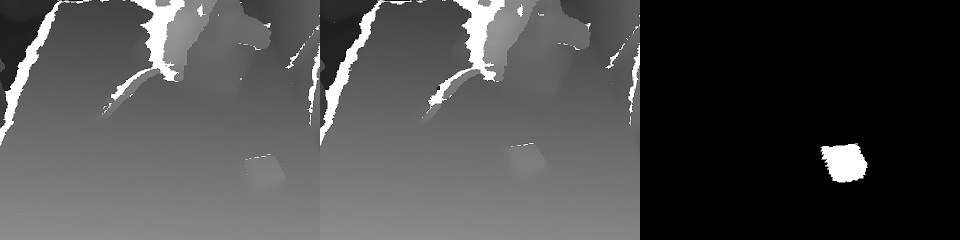 Além disso, xyz são projetados no plano da câmera e você pode selecionar a vizinhança do objeto capturado:
Além disso, xyz são projetados no plano da câmera e você pode selecionar a vizinhança do objeto capturado: Na verdade, com este bairro e vai funcionar.Primeiro, obtemos o XY treinando a Unet em uma rede convolucional para segmentação de cubos.Então, precisamos determinar a profundidade e entender se a imagem está anormal à nossa frente. Isso é feito usando um codificador automático em RGB e um codificador automático condicional em profundidade.Arquitetura de modelo para o treinamento do codificador automático:
Na verdade, com este bairro e vai funcionar.Primeiro, obtemos o XY treinando a Unet em uma rede convolucional para segmentação de cubos.Então, precisamos determinar a profundidade e entender se a imagem está anormal à nossa frente. Isso é feito usando um codificador automático em RGB e um codificador automático condicional em profundidade.Arquitetura de modelo para o treinamento do codificador automático: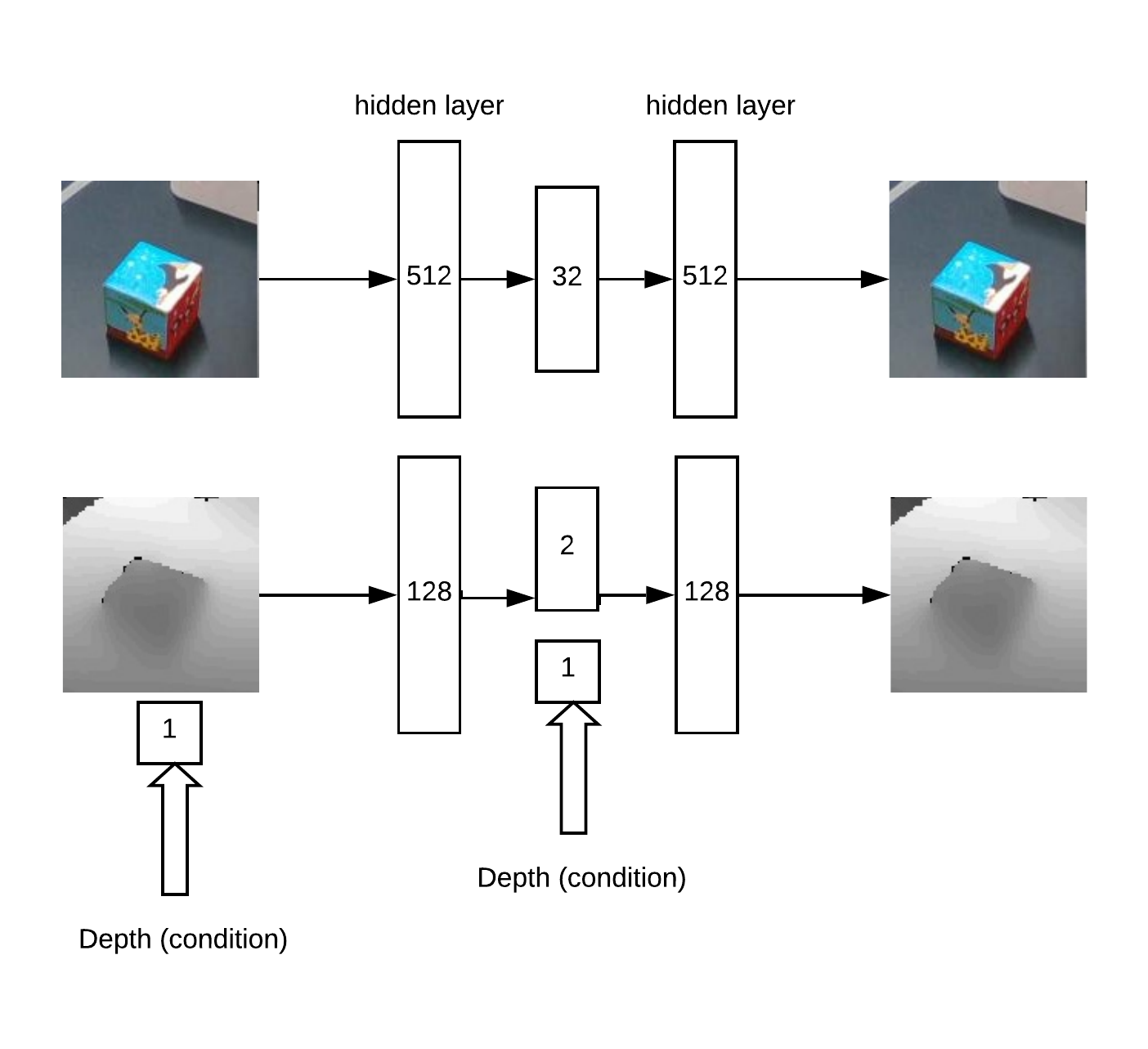 Como resultado, a lógica do trabalho:
Como resultado, a lógica do trabalho:- procure um máximo no "mapa de calor" (determine as coordenadas angulares u = x / zv = y / z do objeto) que excede o limite
- o codificador automático reconstrói a vizinhança do ponto encontrado para todas as hipóteses em profundidade (com um passo dado de min_depth a max_depth) e seleciona a profundidade em que a discrepância entre reconstrução e entrada é mínima
- Tendo as coordenadas angulares u, ve profundidade, é possível obter as coordenadas x, y, z
Um exemplo de reconstrução do codificador automático de um mapa de profundidades de cubo com uma profundidade definida corretamente: Em parte, a idéia de um método de pesquisa de profundidade é baseada em um artigo sobre conjuntos de codificadores automáticos .Essa abordagem funciona bem para objetos de várias formas.Mas, em geral, existem muitas abordagens diferentes para encontrar um objeto XYZ a partir de uma imagem RGBD. Obviamente, é necessário, na prática e com uma grande quantidade de dados, escolher o método mais preciso.Havia também a tarefa de detectar anomalias, para isso precisamos de uma rede convolucional de segmentação para aprender com as máscaras disponíveis. Então, de acordo com esta máscara, você pode avaliar a precisão da reconstrução do codificador automático no mapa de profundidade e RGB. Devido a essa discrepância, pode-se decidir a presença de uma anomalia.Devido a esse método, é possível detectar a aparência de objetos não vistos anteriormente no quadro, que são detectados pelo algoritmo de pesquisa principal.
Em parte, a idéia de um método de pesquisa de profundidade é baseada em um artigo sobre conjuntos de codificadores automáticos .Essa abordagem funciona bem para objetos de várias formas.Mas, em geral, existem muitas abordagens diferentes para encontrar um objeto XYZ a partir de uma imagem RGBD. Obviamente, é necessário, na prática e com uma grande quantidade de dados, escolher o método mais preciso.Havia também a tarefa de detectar anomalias, para isso precisamos de uma rede convolucional de segmentação para aprender com as máscaras disponíveis. Então, de acordo com esta máscara, você pode avaliar a precisão da reconstrução do codificador automático no mapa de profundidade e RGB. Devido a essa discrepância, pode-se decidir a presença de uma anomalia.Devido a esse método, é possível detectar a aparência de objetos não vistos anteriormente no quadro, que são detectados pelo algoritmo de pesquisa principal.Demonstração
A verificação e a depuração de toda a plataforma de software criada foram realizadas no estande:- Câmera 3D Realsense D435
- 4 coordenadas Dobot Magician
- Capacete VR HTC Vive
- Servidores na nuvem Yandex (reduz a latência em comparação com a nuvem da AWS)
No vídeo, ensinamos como encontrar um cubo em uma cena 3D, executando uma tarefa em pick & place VR. Cerca de 50 exemplos foram suficientes para o treinamento em um cubo. Em seguida, o objeto muda e são exibidos mais 30 exemplos. Após a reciclagem, o robô pode encontrar um novo objeto.Todo o processo levou cerca de 15 minutos, dos quais cerca de metade do peso do modelo de treinamento.E neste vídeo, YuMi controla em VR. Para aprender a manipular objetos, você precisa avaliar a orientação e a localização da ferramenta. A matemática se baseia em um princípio semelhante, mas agora está no estágio de teste e desenvolvimento.Conclusão
Big Data e Deep Learning não são tudo.Estamos mudando a abordagem do aprendizado, seguindo em direção a como as pessoas aprendem coisas novas - repetindo o que vêem.O aparato matemático “under the hood”, que desenvolveremos em aplicações reais, visa o problema da interpretação e controle sensíveis ao contexto. O contexto aqui é informações naturais disponíveis a partir de sensores de robô ou informações externas sobre o processo atual.E, quanto mais processos tecnológicos dominamos, mais a estrutura do "cérebro nas nuvens" será desenvolvida e suas partes individuais serão treinadas.Pontos fortes desta abordagem:- a possibilidade de aprender a manipular objetos variáveis
- aprendizagem em um ambiente em mudança (por exemplo, robôs móveis)
- tarefas mal estruturadas
- curto espaço de mercado; Você pode executar o alvo mesmo no modo manual usando os operadores
Limitação:- necessidade de internet confiável e boa
- São necessários métodos adicionais para obter alta precisão, por exemplo, câmeras no próprio manipulador
Atualmente, estamos trabalhando para aplicar nossa abordagem à tarefa padrão de escolher e colocar vários objetos. Mas parece-nos (naturalmente!) Que ele é capaz de mais. Alguma idéia onde mais tentar sua mão?Obrigado pela atenção!