HighLoad ++, Mikhail Makurov, Maxim Chernetsov (Intersvyaz): Zabbix, 100kNVPS em um servidor
A próxima conferência HighLoad ++ será realizada nos dias 6 e 7 de abril de 2020 em São Petersburgo. Detalhes e ingressos aqui . HighLoad ++ Moscow 2018. Salão de Moscou. 9 de novembro, 15h Resumos e apresentação . * Monitoramento - online e analítico.* As principais limitações da plataforma ZABBIX.* Solução para dimensionar o armazenamento analítico.Otimização do servidor ZABBIX.* Otimização da interface do usuário.* Experiência em operar o sistema com cargas de mais de 40k NVPS.* Conclusões breves.Mikhail Makurov (a seguir - MM): - Olá pessoal!Maxim Chernetsov (daqui em diante - MCH): - Boa tarde!MM: - Deixe-me apresentar Maxim. Max é um engenheiro talentoso, o melhor networker que eu conheço. A Maxim lida com redes e serviços, seu desenvolvimento e operação.
* Monitoramento - online e analítico.* As principais limitações da plataforma ZABBIX.* Solução para dimensionar o armazenamento analítico.Otimização do servidor ZABBIX.* Otimização da interface do usuário.* Experiência em operar o sistema com cargas de mais de 40k NVPS.* Conclusões breves.Mikhail Makurov (a seguir - MM): - Olá pessoal!Maxim Chernetsov (daqui em diante - MCH): - Boa tarde!MM: - Deixe-me apresentar Maxim. Max é um engenheiro talentoso, o melhor networker que eu conheço. A Maxim lida com redes e serviços, seu desenvolvimento e operação. MCH: - E eu gostaria de falar sobre o Michael. Michael é desenvolvedor de C. Ele escreveu algumas soluções de processamento de tráfego altamente carregadas para nossa empresa. Vivemos e trabalhamos nos Urais, na cidade de severos camponeses de Chelyabinsk, na empresa Intersvyaz. Nossa empresa é fornecedora de serviços de Internet e televisão a cabo para um milhão de pessoas em 16 cidades.MILÍMETROS:- E vale dizer que a Intersvyaz é muito mais do que apenas um provedor, é uma empresa de TI. A maioria das nossas decisões é tomada pelo nosso departamento de TI.R: dos servidores que processam o tráfego, ao call center e ao aplicativo móvel. Existem cerca de 80 pessoas no departamento de TI com competências muito, muito diversas.
MCH: - E eu gostaria de falar sobre o Michael. Michael é desenvolvedor de C. Ele escreveu algumas soluções de processamento de tráfego altamente carregadas para nossa empresa. Vivemos e trabalhamos nos Urais, na cidade de severos camponeses de Chelyabinsk, na empresa Intersvyaz. Nossa empresa é fornecedora de serviços de Internet e televisão a cabo para um milhão de pessoas em 16 cidades.MILÍMETROS:- E vale dizer que a Intersvyaz é muito mais do que apenas um provedor, é uma empresa de TI. A maioria das nossas decisões é tomada pelo nosso departamento de TI.R: dos servidores que processam o tráfego, ao call center e ao aplicativo móvel. Existem cerca de 80 pessoas no departamento de TI com competências muito, muito diversas.Sobre o Zabbix e sua arquitetura
MCH: - E agora vou tentar estabelecer um recorde pessoal e dizer em um minuto o que é o Zabbix (daqui em diante - "Zabbiks").O Zabbix se posiciona como um sistema de monitoramento "pronto para uso" no nível corporativo. Possui muitos recursos que simplificam a vida: regras avançadas de escalação, APIs para integração, agrupamento e detecção automática de hosts e métricas. No Zabbix, existem as chamadas ferramentas de dimensionamento - proxies. O Zabbix é um sistema de código aberto.Brevemente sobre arquitetura. Podemos dizer que consiste em três componentes: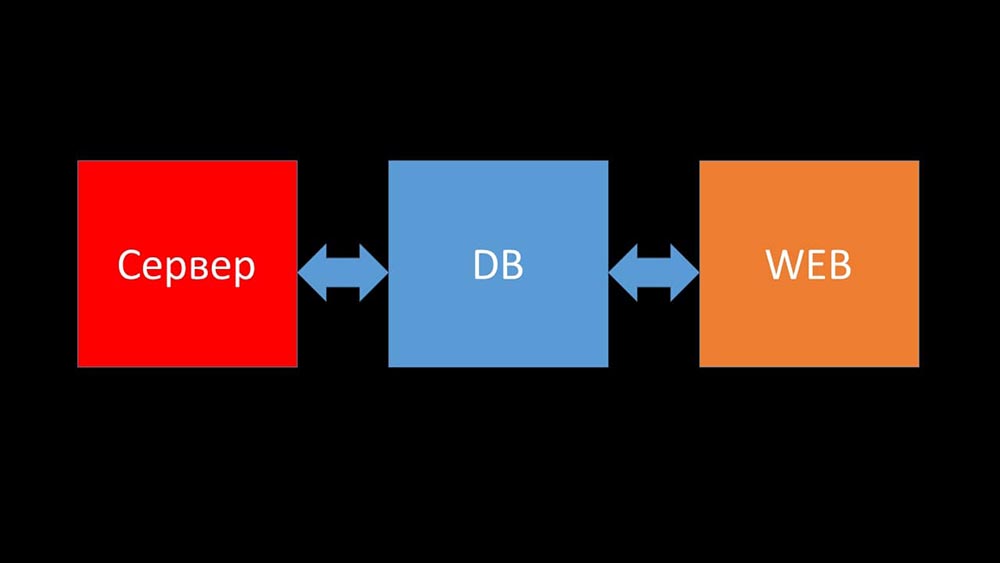
- Servidor. Está escrito em C. Com processamento e transmissão de informações bastante complicados entre fluxos. Todo o processamento ocorre nele: do recebimento até o salvamento no banco de dados.
- Todos os dados são armazenados no banco de dados. O Zabbix suporta MySQL, PostreSQL e Oracle.
- A interface da web é escrita em PHP. Na maioria dos sistemas, ele vem com um servidor Apache, mas funciona com mais eficiência no pacote nginx + php.
Hoje gostaríamos de contar da vida de nossa empresa uma história relacionada ao Zabbix ...História de vida da empresa Intersvyaz. O que temos e o que é necessário?
 5 ou 6 meses atrás. Depois do trabalho ...MCH: - Misha, olá! Que bom que eu consegui pegar você - há uma conversa. Novamente tivemos problemas com o monitoramento. Durante um acidente grave, tudo ficou mais lento e não havia informações sobre o status da rede. Infelizmente, esta não é a primeira vez que se repete. Preciso da tua ajuda. Vamos fazer nosso monitoramento funcionar sob quaisquer circunstâncias!MM: - Mas vamos sincronizar primeiro. Eu não olho lá há alguns anos. Tanto quanto me lembro, recusamos o Nagios e mudamos para o Zabbix há 8 anos. E agora parece que temos 6 servidores poderosos e cerca de uma dúzia de proxies. Estou confundindo alguma coisa?MCH:- Por pouco. 15 servidores, alguns dos quais são máquinas virtuais. Mais importante, isso não nos salva no momento em que mais precisamos. Como um acidente - os servidores estão diminuindo a velocidade e nada é visível. Tentamos otimizar a configuração, mas isso não fornece o ganho de desempenho ideal.MM: - Entendo. Você olhou alguma coisa, você cavou algo do diagnóstico?MCH:- A primeira coisa com a qual você precisa lidar é apenas o banco de dados. O MySQL é carregado constantemente, preservando novas métricas e, quando o Zabbix começa a gerar vários eventos, o banco de dados fica literalmente por várias horas. Eu já falei sobre a otimização da configuração, mas literalmente este ano atualizamos o hardware: há mais de cem gigabytes de memória nos servidores e matrizes de disco nos SSD RAID-ahs - não faz sentido expandi-lo linearmente. O que nós fazemos?MM: - Entendo. Em geral, o MySQL é um banco de dados LTP. Aparentemente, não é mais adequado para armazenar um arquivo de métricas do nosso tamanho. Vamos descobrir.MCH: - Vamos lá!
5 ou 6 meses atrás. Depois do trabalho ...MCH: - Misha, olá! Que bom que eu consegui pegar você - há uma conversa. Novamente tivemos problemas com o monitoramento. Durante um acidente grave, tudo ficou mais lento e não havia informações sobre o status da rede. Infelizmente, esta não é a primeira vez que se repete. Preciso da tua ajuda. Vamos fazer nosso monitoramento funcionar sob quaisquer circunstâncias!MM: - Mas vamos sincronizar primeiro. Eu não olho lá há alguns anos. Tanto quanto me lembro, recusamos o Nagios e mudamos para o Zabbix há 8 anos. E agora parece que temos 6 servidores poderosos e cerca de uma dúzia de proxies. Estou confundindo alguma coisa?MCH:- Por pouco. 15 servidores, alguns dos quais são máquinas virtuais. Mais importante, isso não nos salva no momento em que mais precisamos. Como um acidente - os servidores estão diminuindo a velocidade e nada é visível. Tentamos otimizar a configuração, mas isso não fornece o ganho de desempenho ideal.MM: - Entendo. Você olhou alguma coisa, você cavou algo do diagnóstico?MCH:- A primeira coisa com a qual você precisa lidar é apenas o banco de dados. O MySQL é carregado constantemente, preservando novas métricas e, quando o Zabbix começa a gerar vários eventos, o banco de dados fica literalmente por várias horas. Eu já falei sobre a otimização da configuração, mas literalmente este ano atualizamos o hardware: há mais de cem gigabytes de memória nos servidores e matrizes de disco nos SSD RAID-ahs - não faz sentido expandi-lo linearmente. O que nós fazemos?MM: - Entendo. Em geral, o MySQL é um banco de dados LTP. Aparentemente, não é mais adequado para armazenar um arquivo de métricas do nosso tamanho. Vamos descobrir.MCH: - Vamos lá!Integração do Zabbix e Clickhouse como resultado do hackathon
Depois de algum tempo, recebemos dados interessantes: a maior parte do espaço em nosso banco de dados foi ocupada pelo arquivo de métricas e menos de 1% foi usado para configuração, modelos e configurações. Naquela época, há mais de um ano estávamos operando a solução de Big Data com base no Clickhouse. A direção do movimento era óbvia para nós. No Hackathon da primavera, ele escreveu a integração do Zabbix ao Clickhouse para o servidor e o front-end. Naquela época, o Zabbix já tinha suporte para o ElasticSearch, e decidimos compará-los.
maior parte do espaço em nosso banco de dados foi ocupada pelo arquivo de métricas e menos de 1% foi usado para configuração, modelos e configurações. Naquela época, há mais de um ano estávamos operando a solução de Big Data com base no Clickhouse. A direção do movimento era óbvia para nós. No Hackathon da primavera, ele escreveu a integração do Zabbix ao Clickhouse para o servidor e o front-end. Naquela época, o Zabbix já tinha suporte para o ElasticSearch, e decidimos compará-los.
Compare Clickhouse e Elasticsearch
MM: - Para comparação, geramos a mesma carga que o servidor Zabbix fornece e analisamos como os sistemas se comportariam. Escrevemos dados em lotes de 1000 linhas, usados CURL. Sugerimos anteriormente que o Clickhouse seria mais eficaz para o perfil de carga que o Zabbix. Os resultados até superaram nossas expectativas: nas mesmas condições de teste, o Clickhouse gravou três vezes mais dados. Ao mesmo tempo, ambos os sistemas consumiram muito eficientemente (uma pequena quantidade de recursos) durante a leitura dos dados. Mas o "Elastix" exigiu uma grande quantidade de processador ao gravar:No total, a Clickhouse excedeu significativamente o Elastix no consumo e velocidade do processador. Ao mesmo tempo, devido à compactação de dados, o “Clickhouse” usa 11 vezes menos no disco rígido e faz cerca de 30 vezes menos operações no disco:
nas mesmas condições de teste, o Clickhouse gravou três vezes mais dados. Ao mesmo tempo, ambos os sistemas consumiram muito eficientemente (uma pequena quantidade de recursos) durante a leitura dos dados. Mas o "Elastix" exigiu uma grande quantidade de processador ao gravar:No total, a Clickhouse excedeu significativamente o Elastix no consumo e velocidade do processador. Ao mesmo tempo, devido à compactação de dados, o “Clickhouse” usa 11 vezes menos no disco rígido e faz cerca de 30 vezes menos operações no disco: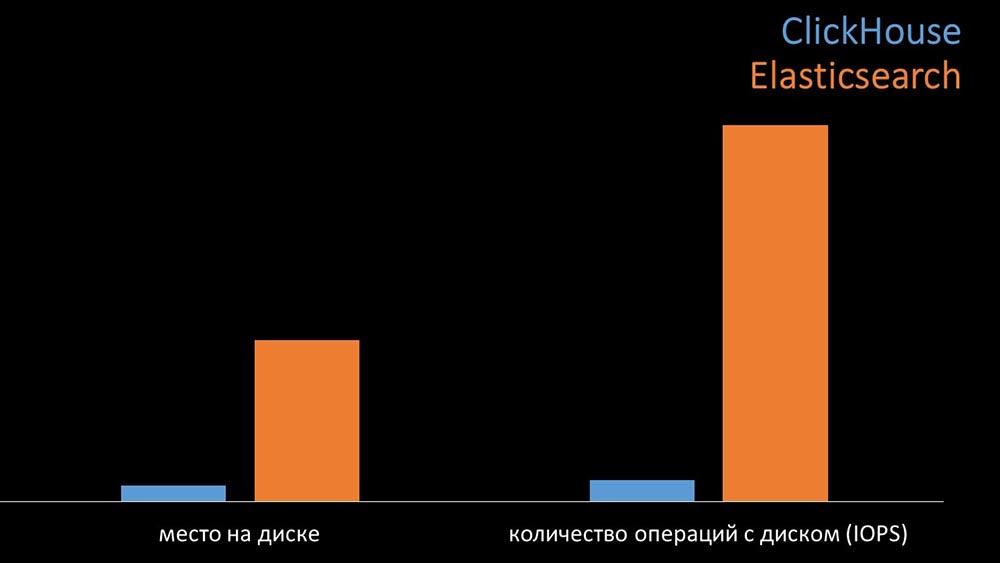 MCH: - Sim, trabalhar com o subsistema de disco no “Clickhouse” é muito eficaz. Sob as bases, você pode usar enormes discos SATA e obter uma velocidade de gravação de centenas de milhares de linhas por segundo. O sistema "pronto para uso" suporta sharding, replicação, é muito fácil de configurar. Estamos mais do que felizes com sua operação por um ano.Para otimizar os recursos, você pode instalar o "Clickhouse" ao lado da base principal existente e, assim, economizar muito tempo do processador e operações do disco. Tiramos o arquivo de métricas para os clusters "Clickhouse" existentes:
MCH: - Sim, trabalhar com o subsistema de disco no “Clickhouse” é muito eficaz. Sob as bases, você pode usar enormes discos SATA e obter uma velocidade de gravação de centenas de milhares de linhas por segundo. O sistema "pronto para uso" suporta sharding, replicação, é muito fácil de configurar. Estamos mais do que felizes com sua operação por um ano.Para otimizar os recursos, você pode instalar o "Clickhouse" ao lado da base principal existente e, assim, economizar muito tempo do processador e operações do disco. Tiramos o arquivo de métricas para os clusters "Clickhouse" existentes: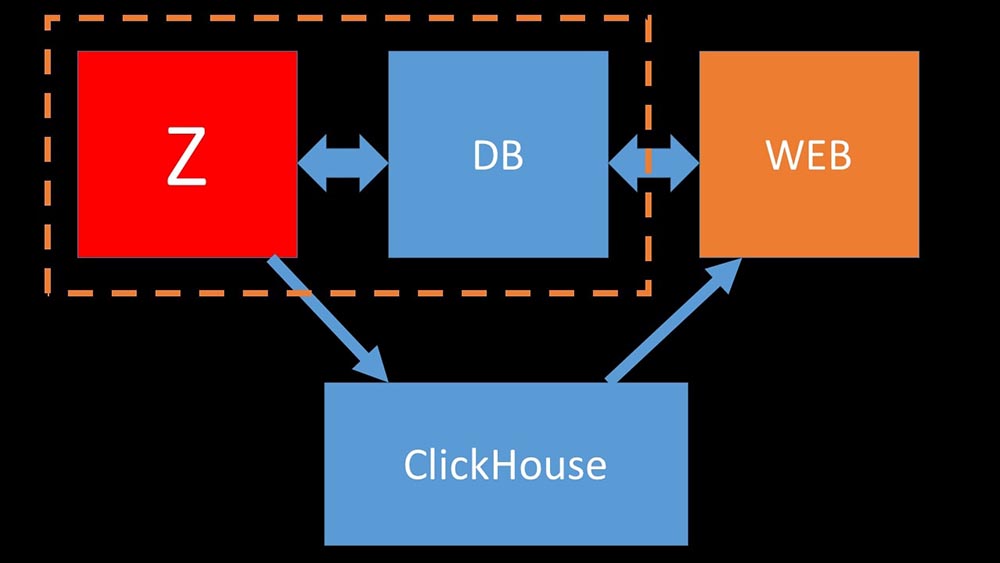 Descarregamos tanto o banco de dados principal do MySQL que podemos combiná-lo na mesma máquina com o servidor Zabbix e abandonar o servidor dedicado para o MySQL.
Descarregamos tanto o banco de dados principal do MySQL que podemos combiná-lo na mesma máquina com o servidor Zabbix e abandonar o servidor dedicado para o MySQL.Como funciona a pesquisa no Zabbix?
4 meses atrásMM: - Bem, você pode esquecer os problemas com a base?MCH: - Isso é certo! Outro problema que precisamos resolver é a lenta coleta de dados. Agora, todos os nossos 15 proxies estão sobrecarregados com SNMP e processos de pesquisa. E não há outro senão configurar novos e novos servidores.MM: - Ótimo. Mas primeiro me diga como a pesquisa funciona no Zabbix.MCH: - Em resumo, existem 20 tipos de métricas e uma dúzia de maneiras de obtê-las. O Zabbix pode coletar dados no modo "solicitação-resposta" ou esperar novos dados através da "Interface Trapper". Vale ressaltar que no Zabbix original esse método (Trapper) é o mais rápido.Existem proxies para balanceamento de carga:
Vale ressaltar que no Zabbix original esse método (Trapper) é o mais rápido.Existem proxies para balanceamento de carga: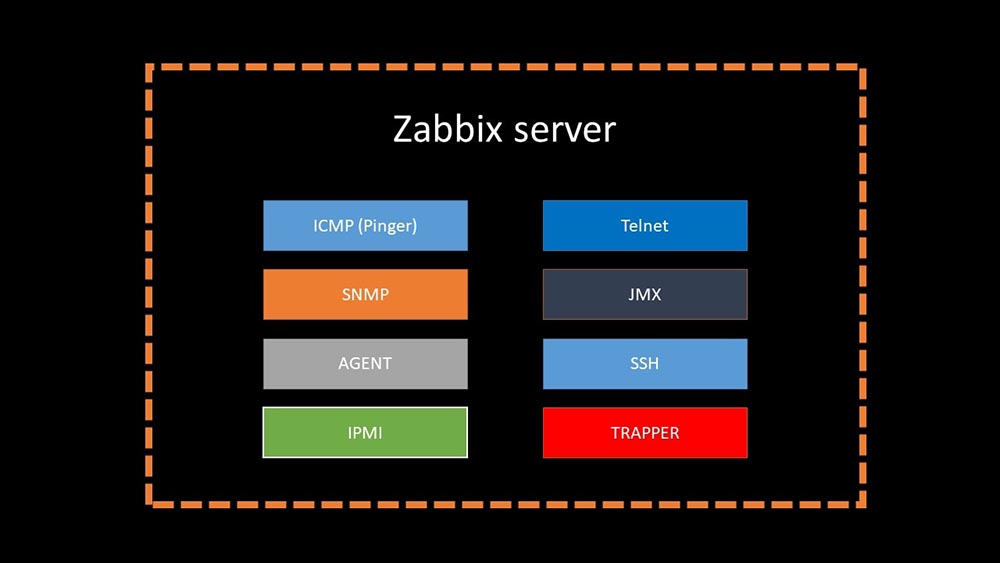 Os proxies podem executar as mesmas funções de coleta que o servidor Zabbix, recebendo tarefas dele e enviando métricas coletadas pela interface do Trapper. Este é o método de balanceamento de carga oficialmente recomendado. Além disso, os proxies são úteis para monitorar uma infraestrutura remota que funciona por meio de NAT ou de um canal lento:
Os proxies podem executar as mesmas funções de coleta que o servidor Zabbix, recebendo tarefas dele e enviando métricas coletadas pela interface do Trapper. Este é o método de balanceamento de carga oficialmente recomendado. Além disso, os proxies são úteis para monitorar uma infraestrutura remota que funciona por meio de NAT ou de um canal lento: MM: - Tudo fica claro na arquitetura. Devemos olhar para a fonte ...Alguns dias depois
MM: - Tudo fica claro na arquitetura. Devemos olhar para a fonte ...Alguns dias depoisHistória de como o nmap fping venceu
MM: - Parece que eu cavei alguma coisa.MCH: - Diga-me!MM: - Descobri que, durante as verificações de disponibilidade, o Zabbix faz uma verificação de até 128 hosts por vez. Tentei aumentar esse número para 500 e removi o intervalo entre pacotes no ping (ping) - isso aumentou o desempenho em um fator de dois. Mas eu gostaria de grandes números.MCH: - Na minha prática, às vezes tenho que verificar a disponibilidade de milhares de hosts e não vi nada mais rápido que o nmap. Estou certo de que este é o caminho mais rápido. Vamos tentar! Você precisa aumentar significativamente o número de hosts em uma iteração.MM: - Verifica mais de quinhentos? 600?MCH: - Pelo menos alguns milhares.MILÍMETROS:- OK. A coisa mais importante que eu queria dizer: descobri que a maioria das pesquisas no Zabbix era feita de forma síncrona. Devemos refazê-lo de forma assíncrona. Em seguida, podemos aumentar drasticamente o número de métricas coletadas pelos pesquisadores, especialmente se aumentarmos o número de métricas em uma iteração.MCH: - Ótimo! E quando?MM: - Como sempre, ontem.MCH: - Comparamos as duas versões do fping e do nmap: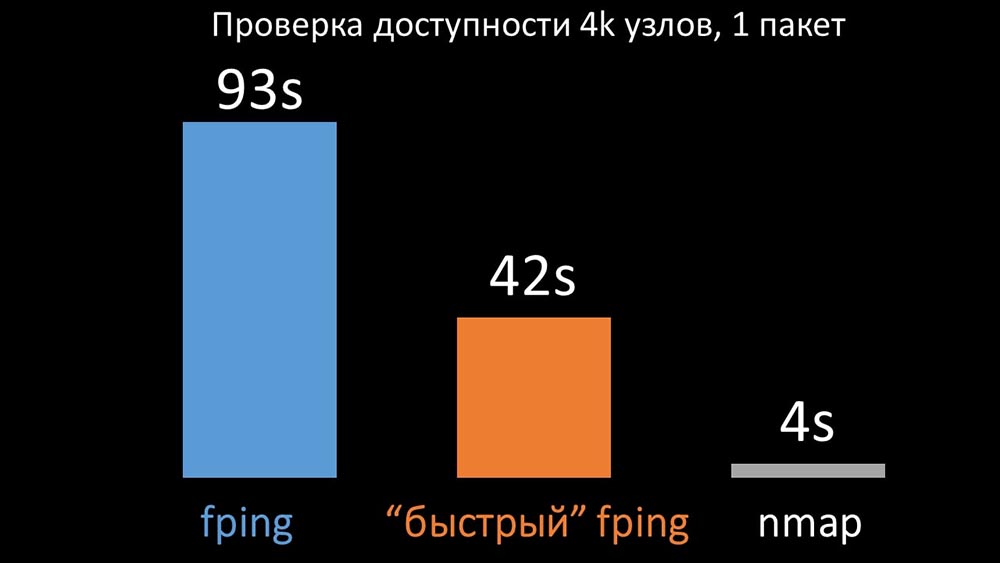 Em um grande número de hosts, o nmap era esperado até cinco vezes mais eficiente. Como o nmap verifica apenas o fato de disponibilidade e tempo de resposta, transferimos o cálculo de perda para acionadores e reduzimos significativamente os intervalos de verificação de disponibilidade. Encontramos o número ideal de hosts para o nmap na região de 4 mil por iteração. O Nmap nos permitiu reduzir em três vezes os custos de CPU para verificações de disponibilidade e reduzir o intervalo de 120 segundos para 10.
Em um grande número de hosts, o nmap era esperado até cinco vezes mais eficiente. Como o nmap verifica apenas o fato de disponibilidade e tempo de resposta, transferimos o cálculo de perda para acionadores e reduzimos significativamente os intervalos de verificação de disponibilidade. Encontramos o número ideal de hosts para o nmap na região de 4 mil por iteração. O Nmap nos permitiu reduzir em três vezes os custos de CPU para verificações de disponibilidade e reduzir o intervalo de 120 segundos para 10.Otimização de polling
MM: - Então fomos para pesquisas. Estávamos interessados principalmente na remoção e agentes de SNMP. No Zabbix, a pesquisa foi realizada de forma síncrona e foram tomadas medidas especiais para aumentar a eficiência do sistema. No modo síncrono, a indisponibilidade do host causa uma degradação significativa da pesquisa. Existe todo um sistema de estados, há processos especiais - os chamados pesquisadores inacessíveis, que funcionam apenas com hosts inacessíveis: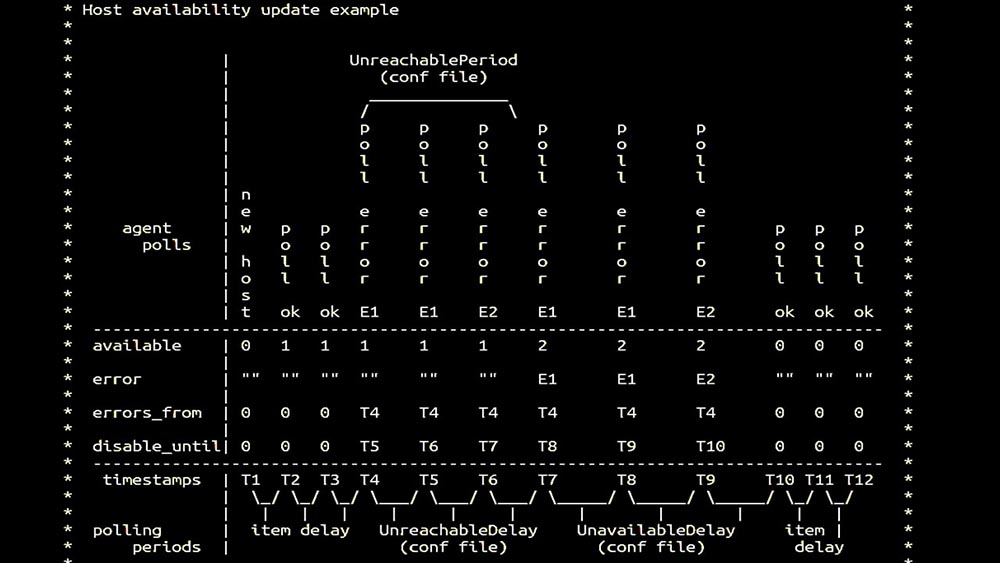 este é um comentário que demonstra a matriz de estados, a complexidade do sistema de transição necessária para que o sistema permaneça eficaz. Além disso, a pesquisa síncrona é bastante lenta:
este é um comentário que demonstra a matriz de estados, a complexidade do sistema de transição necessária para que o sistema permaneça eficaz. Além disso, a pesquisa síncrona é bastante lenta: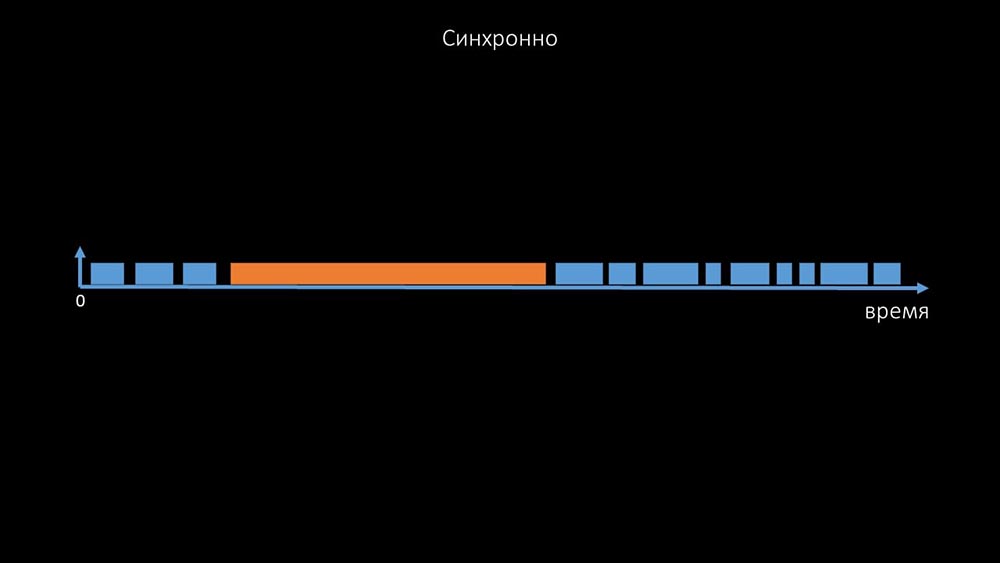 É por isso que milhares de threads de pesquisas em uma dúzia de proxies não puderam coletar a quantidade necessária de dados para nós. A implementação assíncrona resolveu não apenas os problemas com o número de threads, mas também simplificou significativamente o sistema de estado de hosts inacessíveis, porque para qualquer número verificado em uma iteração de polling, o tempo de espera máximo era de 1 tempo limite:
É por isso que milhares de threads de pesquisas em uma dúzia de proxies não puderam coletar a quantidade necessária de dados para nós. A implementação assíncrona resolveu não apenas os problemas com o número de threads, mas também simplificou significativamente o sistema de estado de hosts inacessíveis, porque para qualquer número verificado em uma iteração de polling, o tempo de espera máximo era de 1 tempo limite: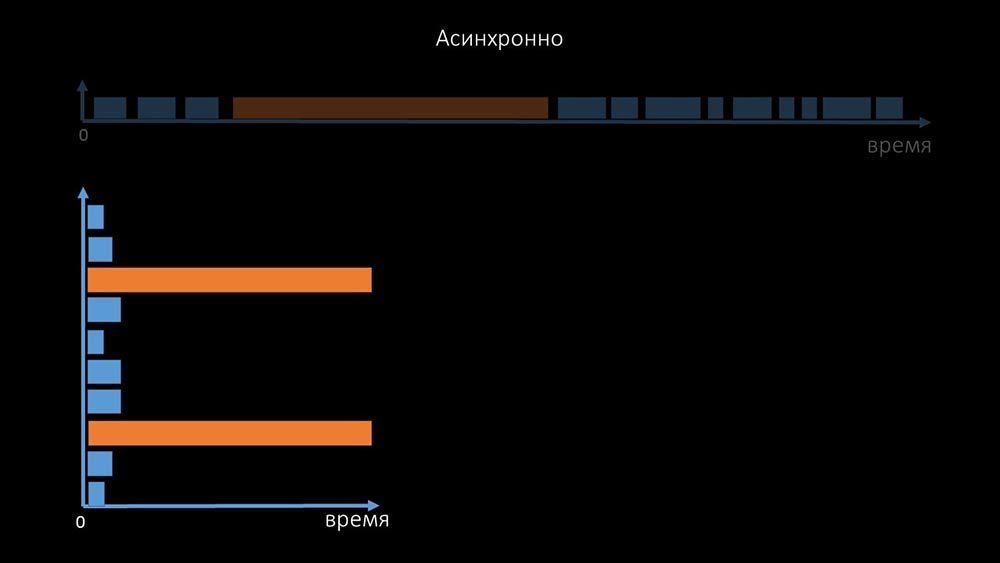 além disso, modificamos e melhoramos o sistema de polling para SNMP- consultas. O fato é que a maioria não pode responder a várias solicitações SNMP ao mesmo tempo. Portanto, criamos um modo híbrido quando a pesquisa SNMP do mesmo host faz assincronamente:
além disso, modificamos e melhoramos o sistema de polling para SNMP- consultas. O fato é que a maioria não pode responder a várias solicitações SNMP ao mesmo tempo. Portanto, criamos um modo híbrido quando a pesquisa SNMP do mesmo host faz assincronamente: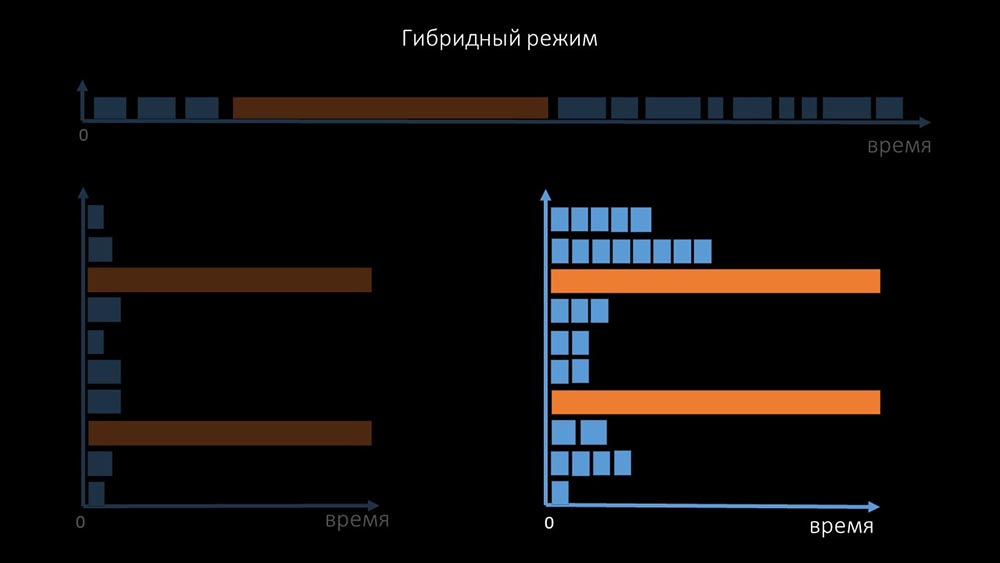 Isso é feito para todo o pacote configurável do host. No final, esse modo não é mais lento do que completamente assíncrono, pois a pesquisa de uma centena e meia de valores SNMP ainda é muito mais rápida que um tempo limite.Nossas experiências mostraram que o número ideal de solicitações em uma iteração é de cerca de 8 mil com a pesquisa SNMP. No total, a transição para o modo assíncrono permitiu acelerar o desempenho da pesquisa em 200 vezes, várias centenas de vezes.MCH: - As otimizações de pesquisa obtidas mostraram que não apenas podemos nos livrar de todos os proxies, mas também reduzir os intervalos para muitas verificações, e os proxies não serão necessários como forma de compartilhar a carga.Cerca de três meses atrás
Isso é feito para todo o pacote configurável do host. No final, esse modo não é mais lento do que completamente assíncrono, pois a pesquisa de uma centena e meia de valores SNMP ainda é muito mais rápida que um tempo limite.Nossas experiências mostraram que o número ideal de solicitações em uma iteração é de cerca de 8 mil com a pesquisa SNMP. No total, a transição para o modo assíncrono permitiu acelerar o desempenho da pesquisa em 200 vezes, várias centenas de vezes.MCH: - As otimizações de pesquisa obtidas mostraram que não apenas podemos nos livrar de todos os proxies, mas também reduzir os intervalos para muitas verificações, e os proxies não serão necessários como forma de compartilhar a carga.Cerca de três meses atrásMude a arquitetura - aumente a carga!
MM: - Bem, Max, é hora de ser produtivo? Eu preciso de um servidor poderoso e de um bom engenheiro.MCH: - Bem, planejamos. É hora de decolar a 5.000 métricas por segundo.Manhã após a atualização doMCH: - Misha, atualizamos, mas revertemos de manhã ... Adivinhe que velocidade você alcançou?MM: - Mil no máximo 20.MCH: - Sim, 25! Infelizmente, estamos onde começamos.MM: - E então? Você recebeu algum diagnóstico?MCH: - Sim, claro! Aqui, por exemplo, um top interessante: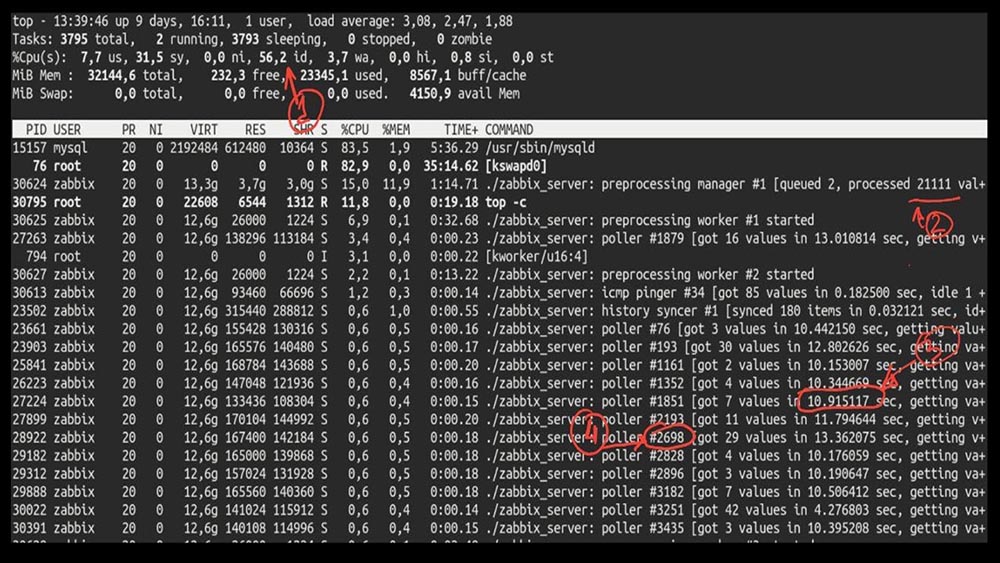 MM: - Vamos ver. Vejo que tentamos um grande número de threads de pesquisa:
MM: - Vamos ver. Vejo que tentamos um grande número de threads de pesquisa: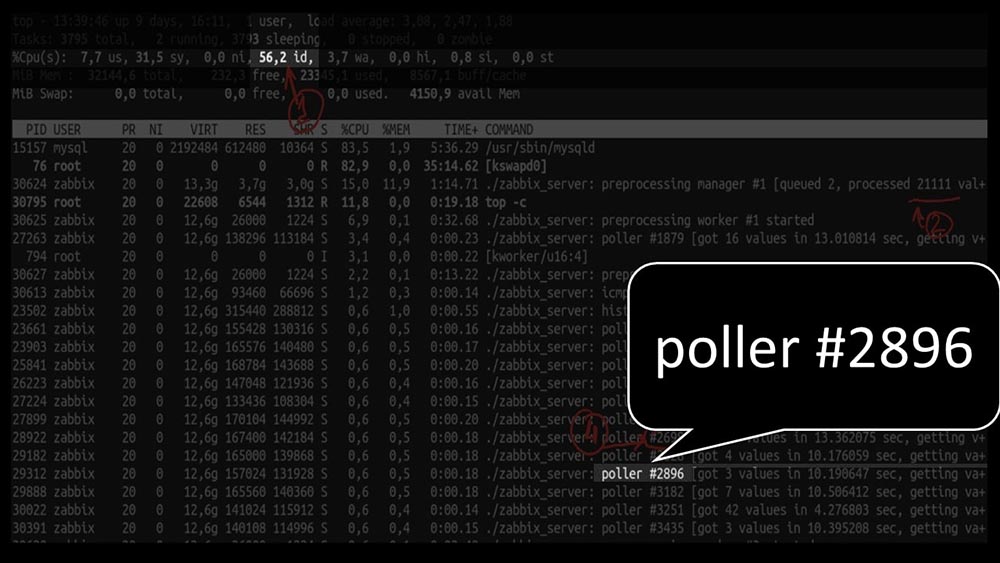 mas, ao mesmo tempo, não conseguimos utilizar o sistema nem pela metade:
mas, ao mesmo tempo, não conseguimos utilizar o sistema nem pela metade: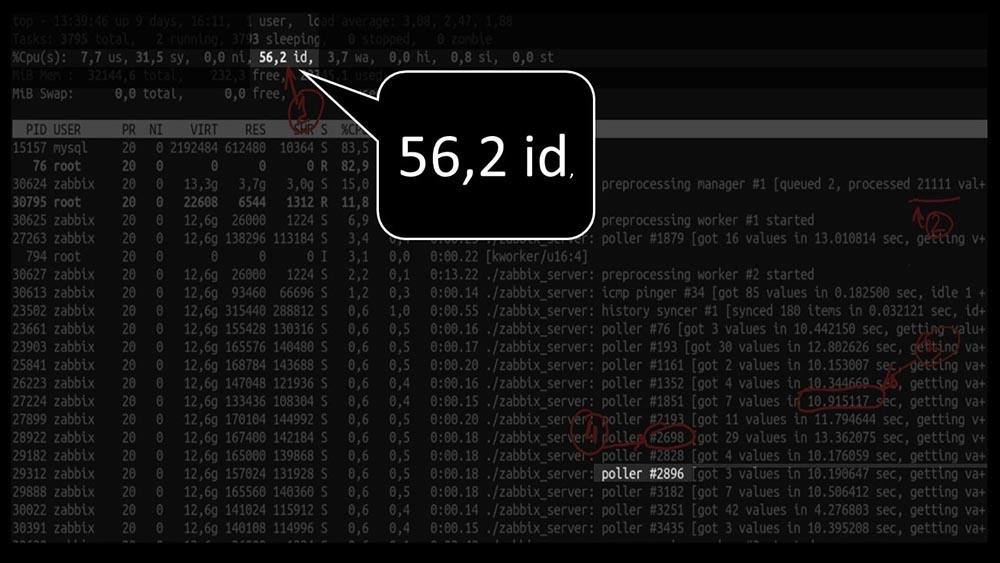 E o desempenho geral é bem pequeno, cerca de 4 mil métricas por segundo:
E o desempenho geral é bem pequeno, cerca de 4 mil métricas por segundo: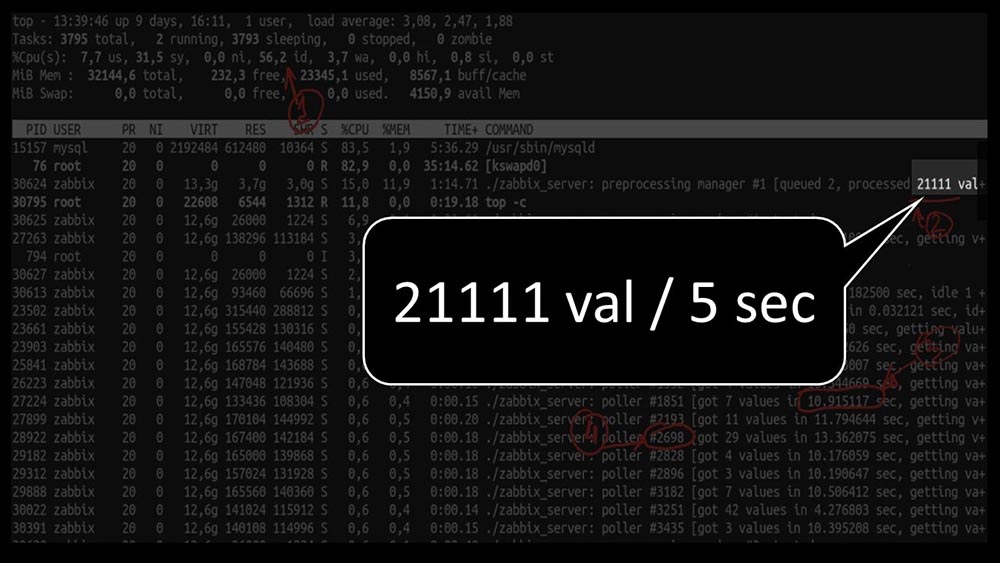 há mais alguma coisa?MCH: - Sim, vestígios de um dos pesquisadores:
há mais alguma coisa?MCH: - Sim, vestígios de um dos pesquisadores: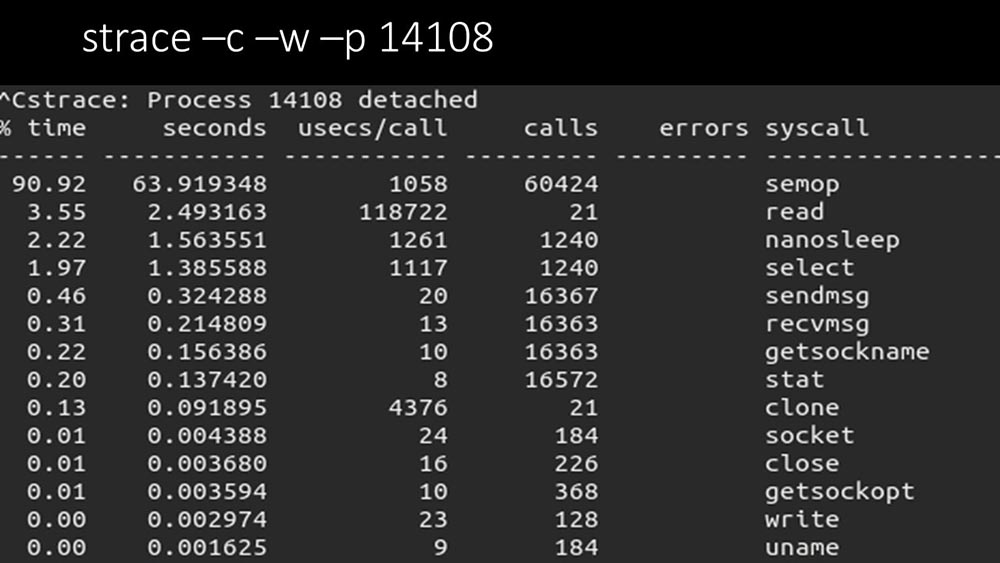 MM: - É claramente visto aqui que o processo de votação está aguardando "semáforos". Estes são bloqueios:
MM: - É claramente visto aqui que o processo de votação está aguardando "semáforos". Estes são bloqueios: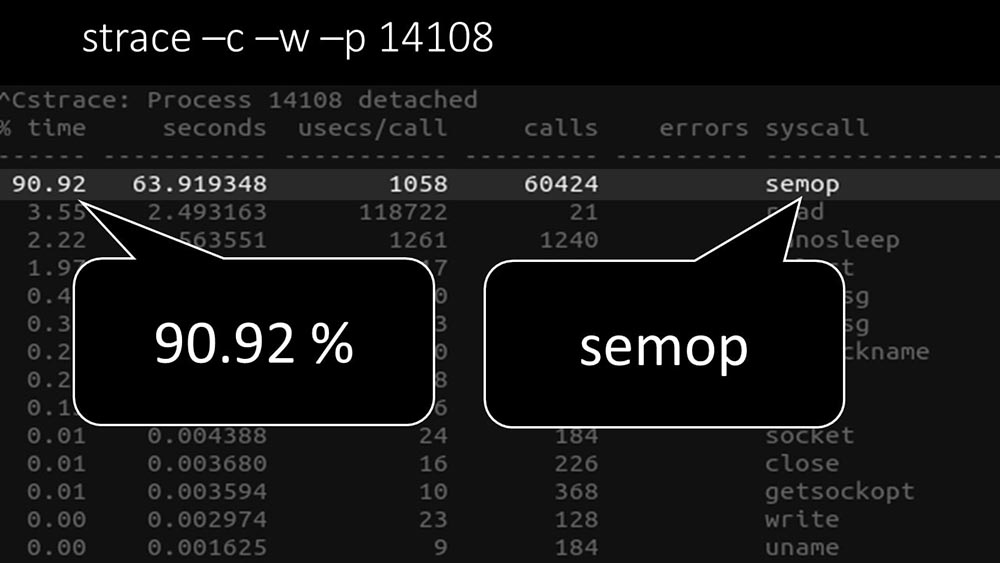 MCH: - Não está claro.MM: - Veja, é como uma situação em que vários threads estão tentando trabalhar com recursos com os quais apenas um pode trabalhar por vez. Então, tudo o que eles podem fazer é compartilhar esse recurso por tempo:
MCH: - Não está claro.MM: - Veja, é como uma situação em que vários threads estão tentando trabalhar com recursos com os quais apenas um pode trabalhar por vez. Então, tudo o que eles podem fazer é compartilhar esse recurso por tempo: e a produtividade total do trabalho com esse recurso é limitada pela velocidade de um núcleo:
e a produtividade total do trabalho com esse recurso é limitada pela velocidade de um núcleo: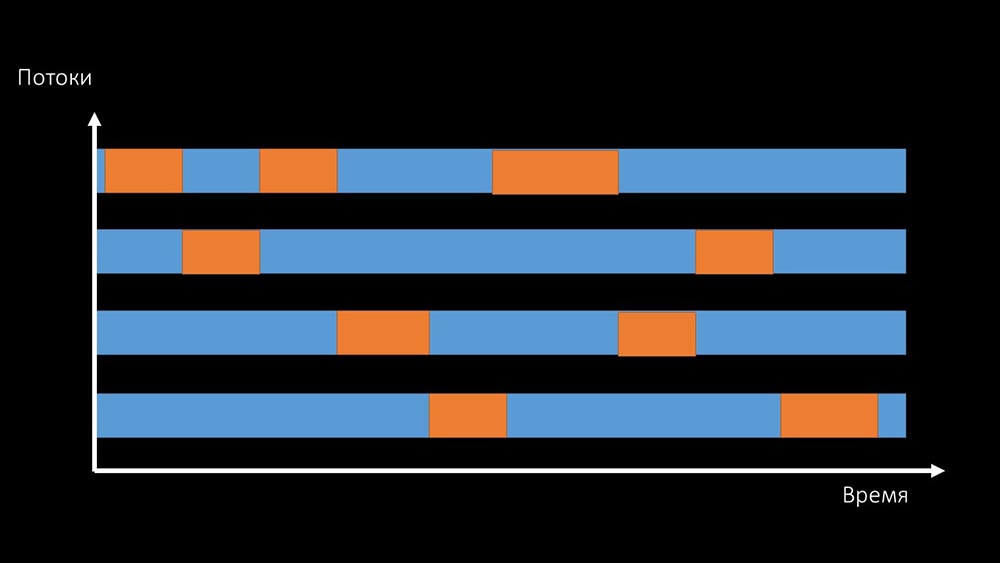 existem duas maneiras de resolver esse problema.Atualize o ferro da máquina, mude para kernels mais rápidos:
existem duas maneiras de resolver esse problema.Atualize o ferro da máquina, mude para kernels mais rápidos: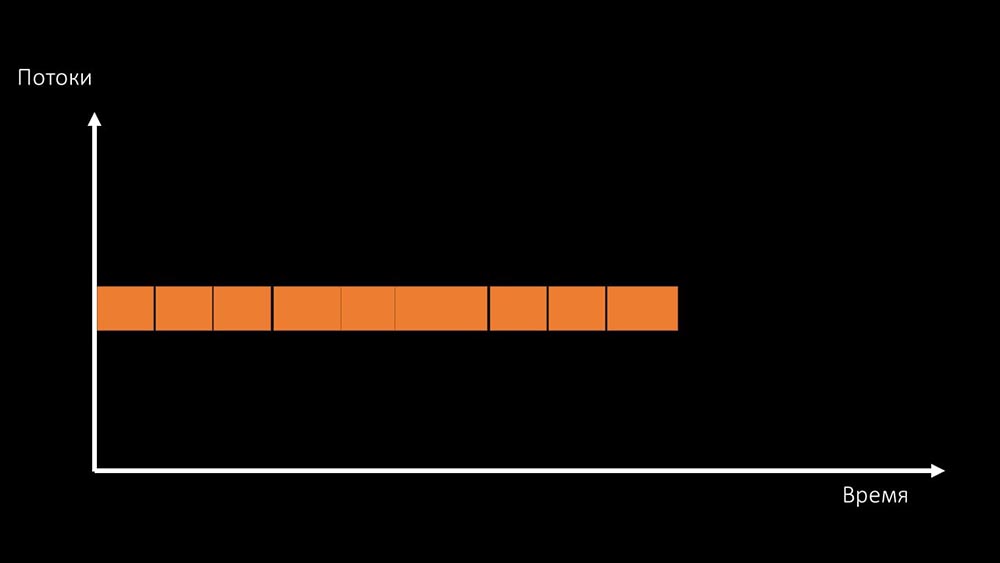 Ou mude a arquitetura e , ao mesmo tempo , a carga:
Ou mude a arquitetura e , ao mesmo tempo , a carga: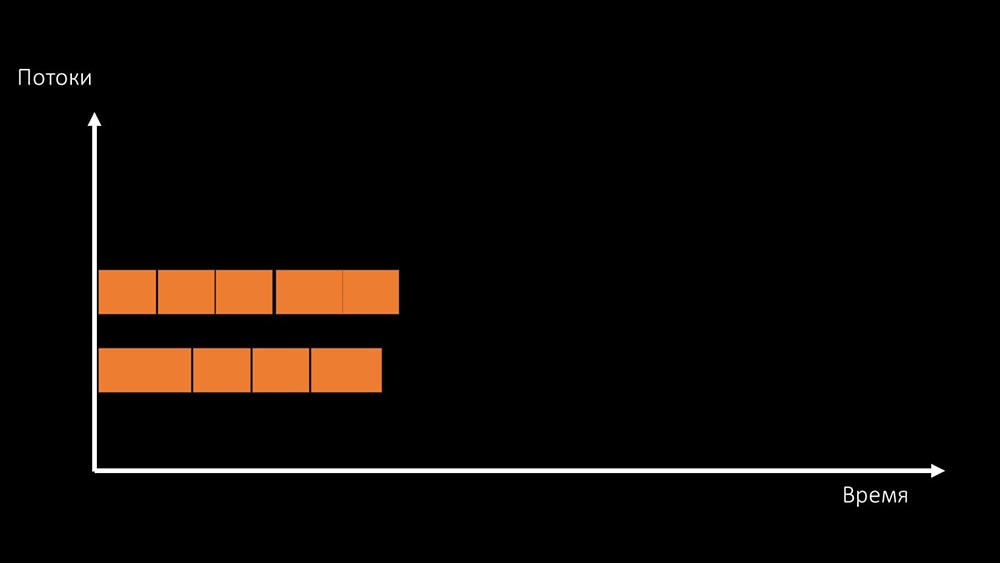 MCH: - A propósito, vamos colocar menos núcleos em uma máquina de teste do que em uma de combate, mas eles são 1,5 vezes mais rápidos em frequência por núcleo!MM: - Está claro? É necessário olhar para o código do servidor.
MCH: - A propósito, vamos colocar menos núcleos em uma máquina de teste do que em uma de combate, mas eles são 1,5 vezes mais rápidos em frequência por núcleo!MM: - Está claro? É necessário olhar para o código do servidor.Caminho de dados no servidor Zabbix
MCH: - Para entender, começamos a analisar como os dados são transmitidos dentro do servidor Zabbix: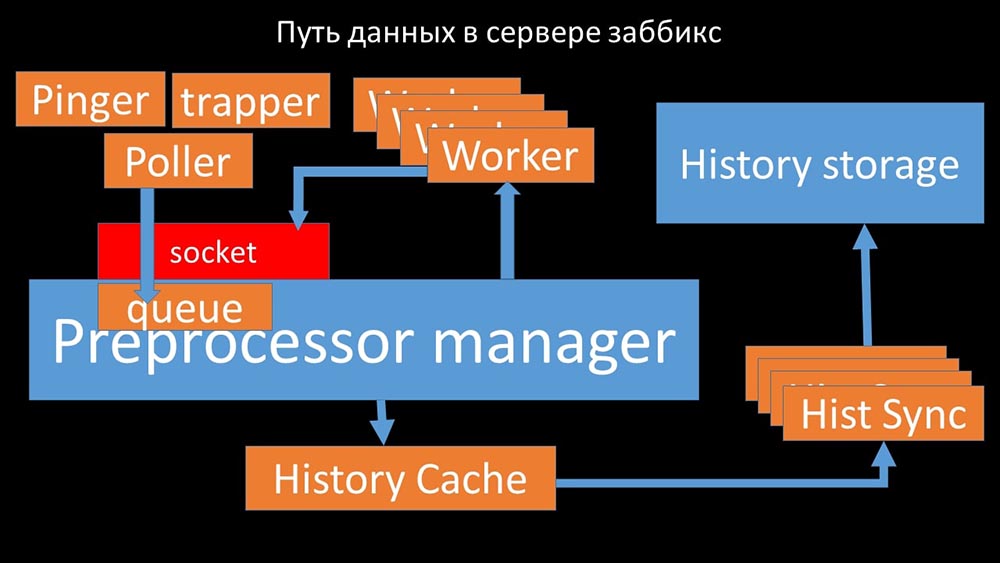 Imagem legal, certo? Vamos passar por isso passo a passo para esclarecer mais ou menos. Existem fluxos e serviços responsáveis pela coleta de dados:
Imagem legal, certo? Vamos passar por isso passo a passo para esclarecer mais ou menos. Existem fluxos e serviços responsáveis pela coleta de dados: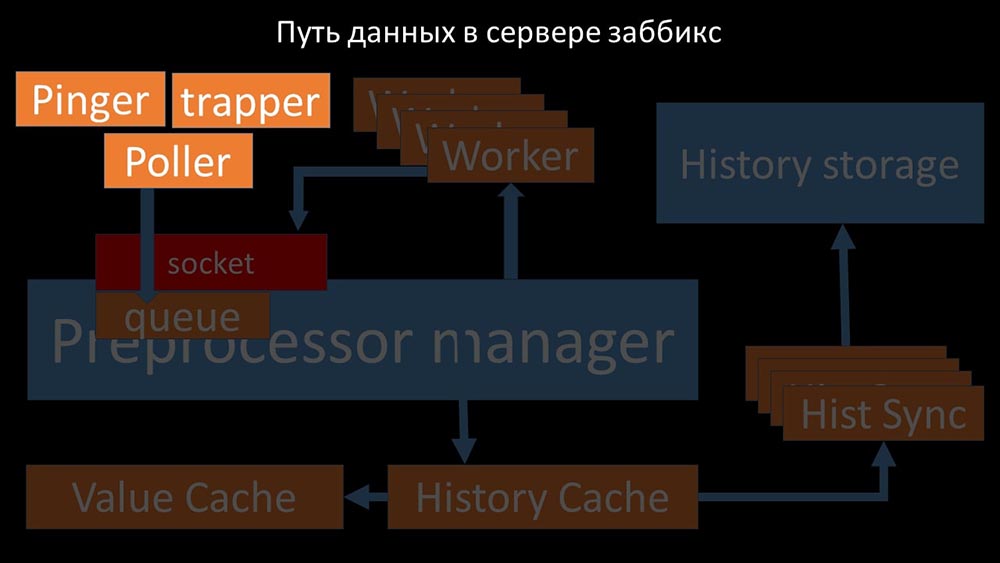 eles transferem as métricas coletadas através do soquete para o gerenciador de pré-processador, onde estão na fila:
eles transferem as métricas coletadas através do soquete para o gerenciador de pré-processador, onde estão na fila: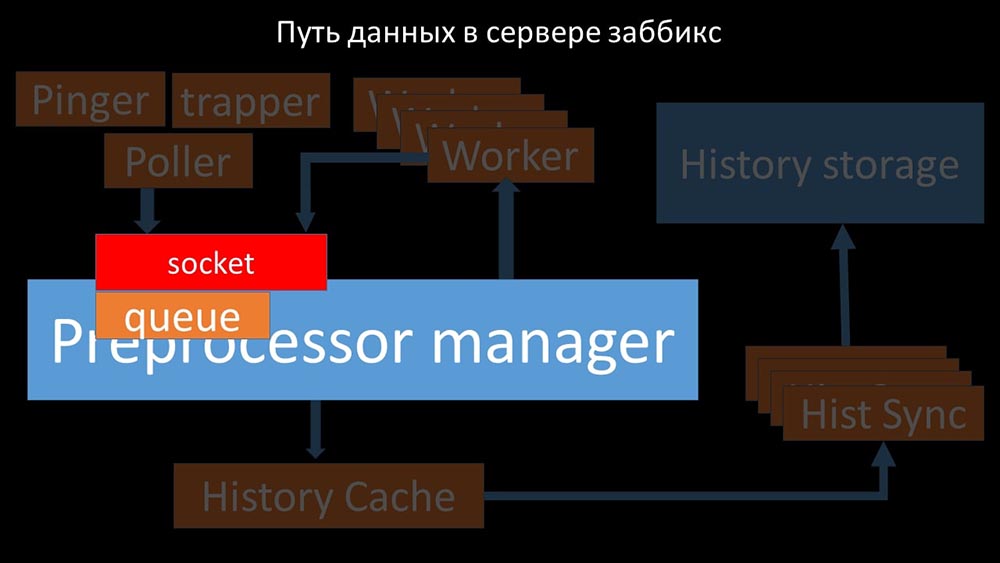 Preprocessor-manager ”transfere dados para seus trabalhadores que executam as instruções de pré-processamento e os devolvem de volta pelo mesmo soquete:
Preprocessor-manager ”transfere dados para seus trabalhadores que executam as instruções de pré-processamento e os devolvem de volta pelo mesmo soquete: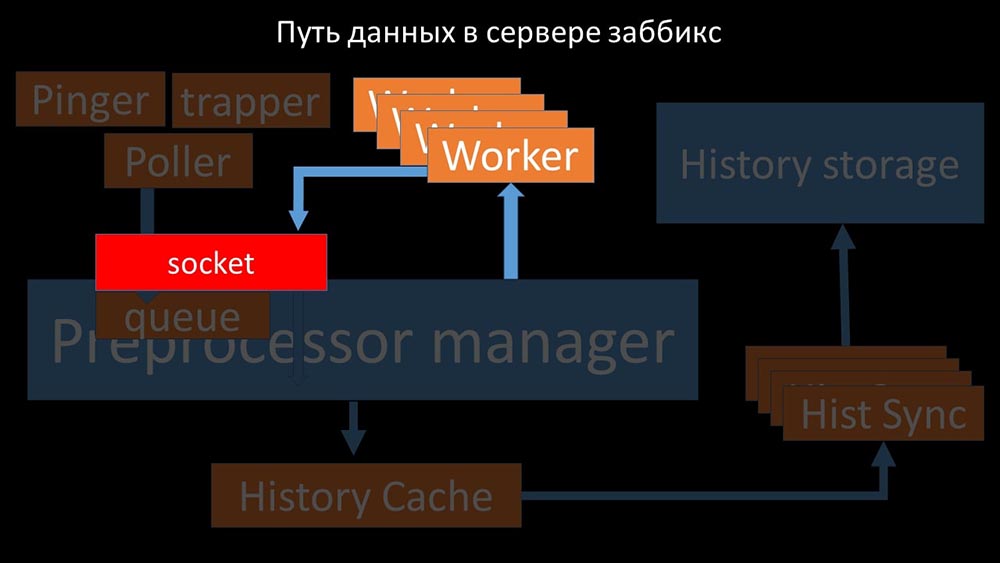 depois disso, o pré-processador O gerenciador os salva no cache do histórico:
depois disso, o pré-processador O gerenciador os salva no cache do histórico: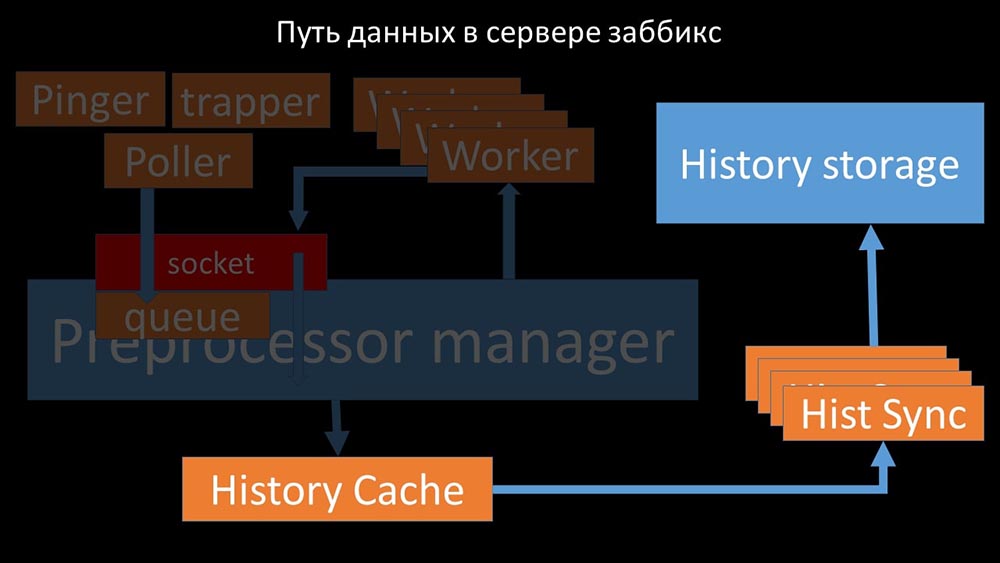 A partir daí, eles são apanhados por afundadores de histórico que desempenham várias funções: por exemplo, calcular gatilhos, preencher o cache de valor e, o mais importante, salvar métricas no repositório de histórico. Em geral, o processo é complexo e muito confuso.
A partir daí, eles são apanhados por afundadores de histórico que desempenham várias funções: por exemplo, calcular gatilhos, preencher o cache de valor e, o mais importante, salvar métricas no repositório de histórico. Em geral, o processo é complexo e muito confuso. MM: - A primeira coisa que vimos é que a maioria dos threads compete pelo chamado "cache de configuração" (uma área de memória onde todas as configurações do servidor são armazenadas). Especialmente muitos bloqueios são feitos pelos fluxos responsáveis pela coleta de dados:
MM: - A primeira coisa que vimos é que a maioria dos threads compete pelo chamado "cache de configuração" (uma área de memória onde todas as configurações do servidor são armazenadas). Especialmente muitos bloqueios são feitos pelos fluxos responsáveis pela coleta de dados: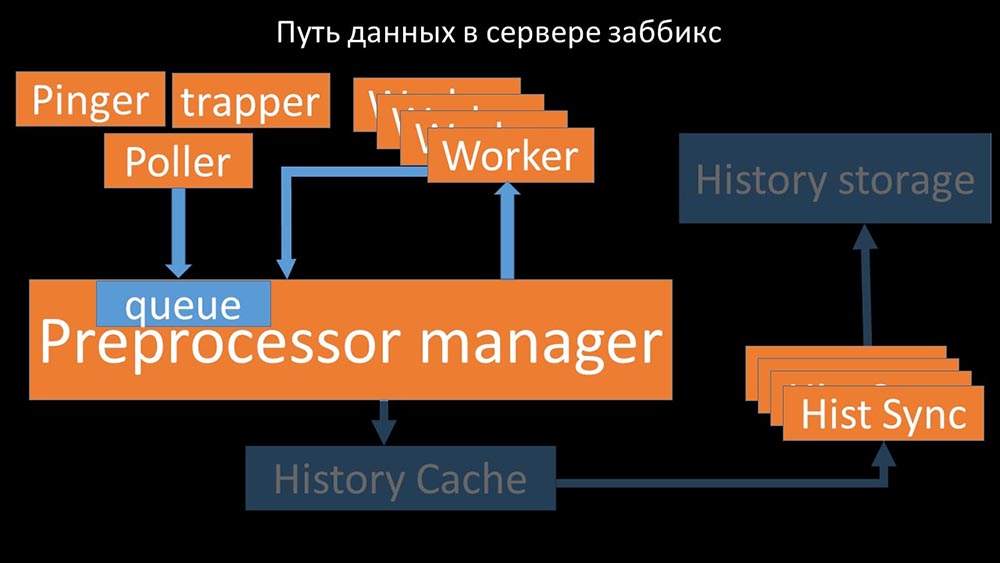 ... uma vez que a configuração armazena não apenas métricas com seus parâmetros, mas também filas, a partir das quais os pesquisadores obtêm informações sobre o que fazer em seguida. Quando há muitos pesquisadores, e um bloqueia a configuração, o restante está aguardando solicitações:
... uma vez que a configuração armazena não apenas métricas com seus parâmetros, mas também filas, a partir das quais os pesquisadores obtêm informações sobre o que fazer em seguida. Quando há muitos pesquisadores, e um bloqueia a configuração, o restante está aguardando solicitações:
Os pesquisadores não devem entrar em conflito
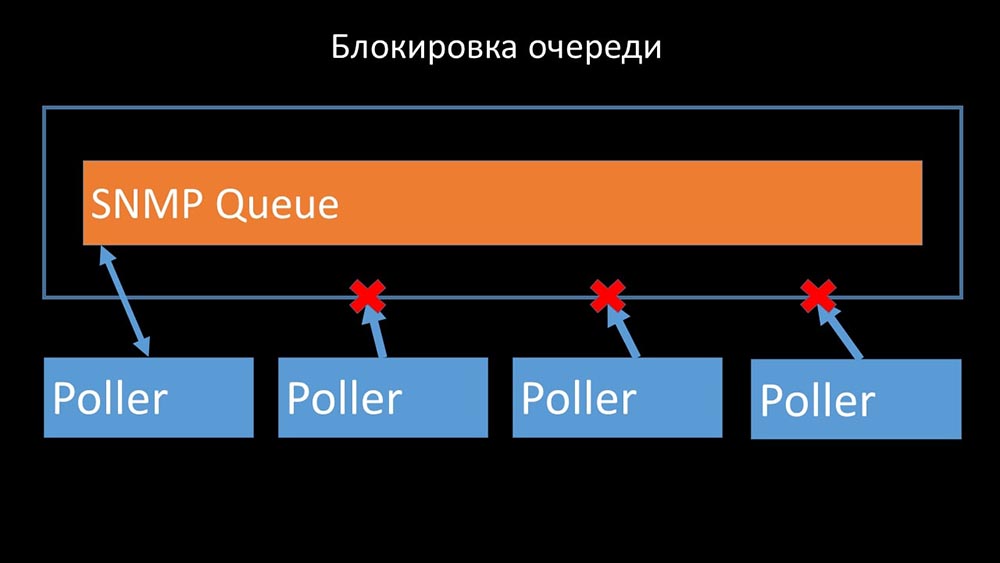 Portanto, a primeira coisa que fizemos foi dividir a fila em 4 partes e permitir que os pesquisadores bloqueassem com segurança essas filas, essas partes ao mesmo tempo:
Portanto, a primeira coisa que fizemos foi dividir a fila em 4 partes e permitir que os pesquisadores bloqueassem com segurança essas filas, essas partes ao mesmo tempo: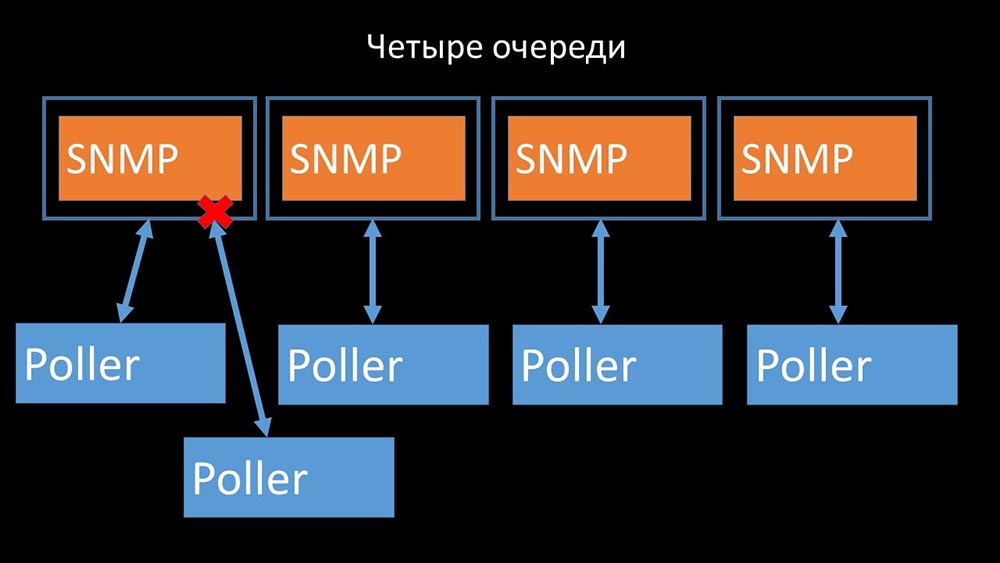 isso eliminou a concorrência pelo cache de configuração e a velocidade dos pesquisadores aumentou significativamente. Mas então fomos confrontados com o fato de que o gerente do pré-processador começou a acumular uma fila de tarefas:
isso eliminou a concorrência pelo cache de configuração e a velocidade dos pesquisadores aumentou significativamente. Mas então fomos confrontados com o fato de que o gerente do pré-processador começou a acumular uma fila de tarefas:
O gerente do pré-processador deve poder priorizar
Isso aconteceu quando ele não tinha produtividade. Então tudo o que podia fazer era solicitações acumular dos processos de coleta de dados e adicionar a sua reserva até que ele come toda a memória e trava: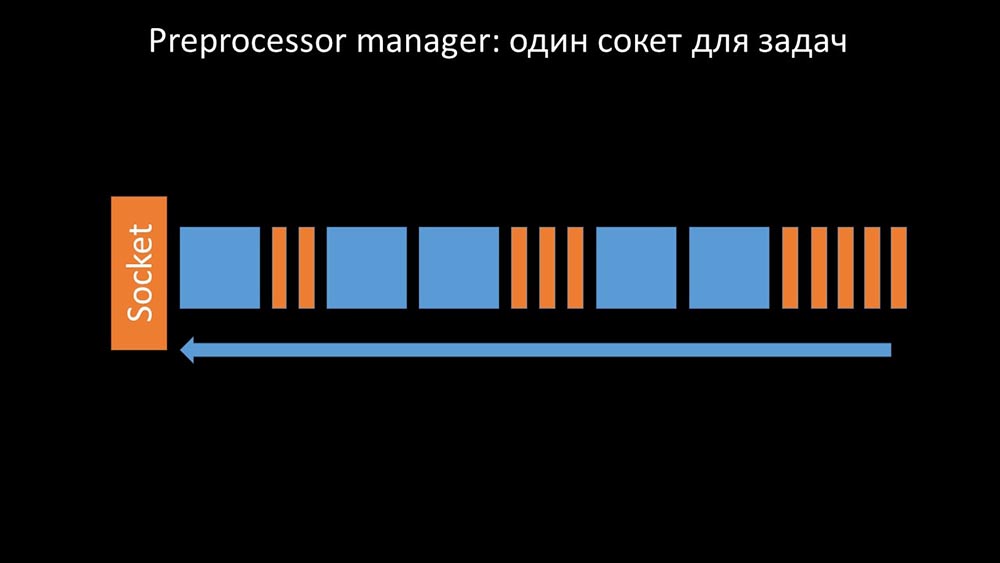 Para resolver este problema, nós adicionamos uma segunda tomada, que foi alocado especificamente para trabalhadores:
Para resolver este problema, nós adicionamos uma segunda tomada, que foi alocado especificamente para trabalhadores: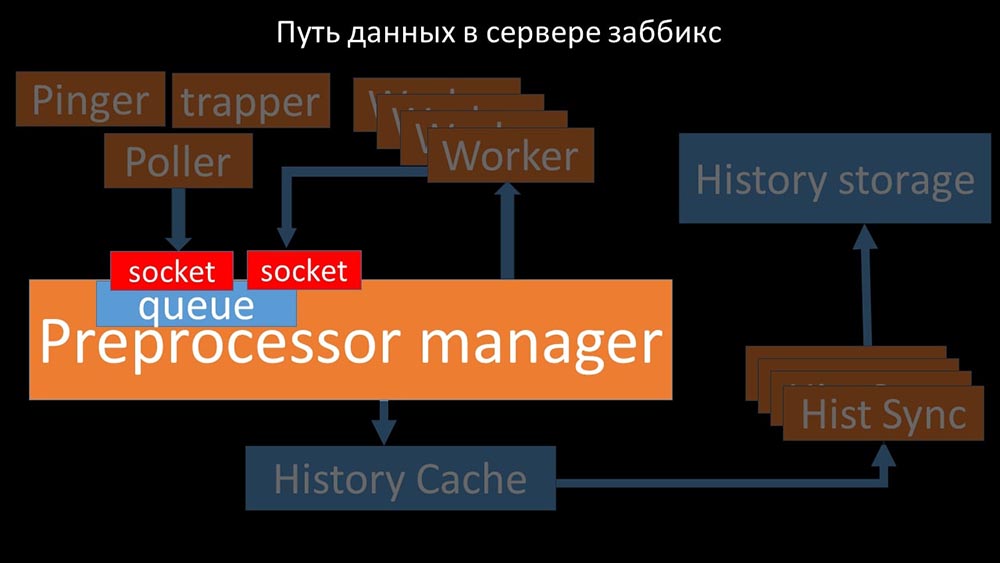 Assim , o gerente do pré-processador teve a oportunidade de priorizar seu trabalho e, caso o buffer cresça, a tarefa é diminuir a velocidade da alimentação, dando aos trabalhadores a oportunidade de buscá-lo:
Assim , o gerente do pré-processador teve a oportunidade de priorizar seu trabalho e, caso o buffer cresça, a tarefa é diminuir a velocidade da alimentação, dando aos trabalhadores a oportunidade de buscá-lo: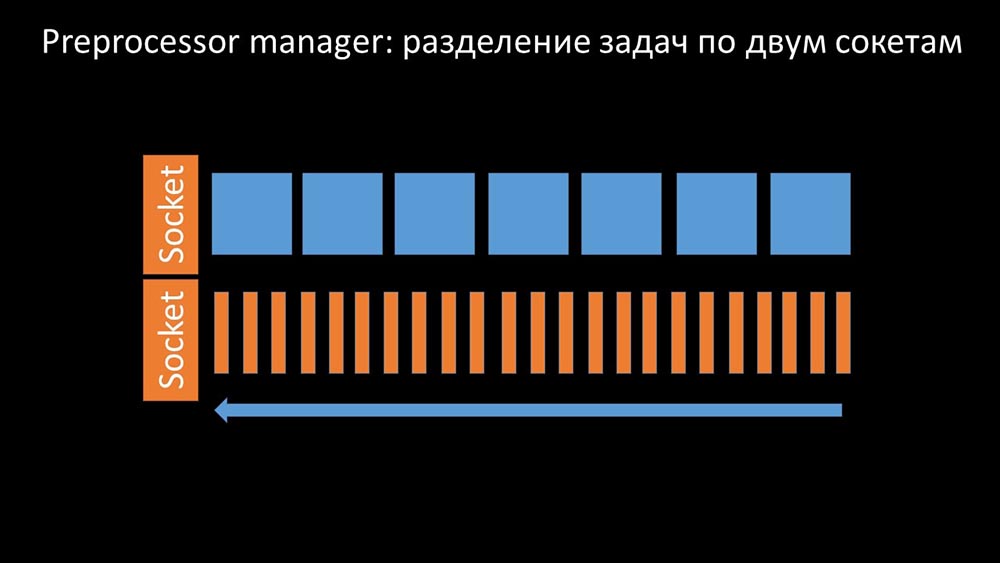 descobrimos que uma das razões para a desaceleração era porque os próprios trabalhadores estavam competindo por recurso vital para o seu trabalho. Registramos esse problema com uma correção de bug e nas novas versões do Zabbix ele já foi resolvido:
descobrimos que uma das razões para a desaceleração era porque os próprios trabalhadores estavam competindo por recurso vital para o seu trabalho. Registramos esse problema com uma correção de bug e nas novas versões do Zabbix ele já foi resolvido: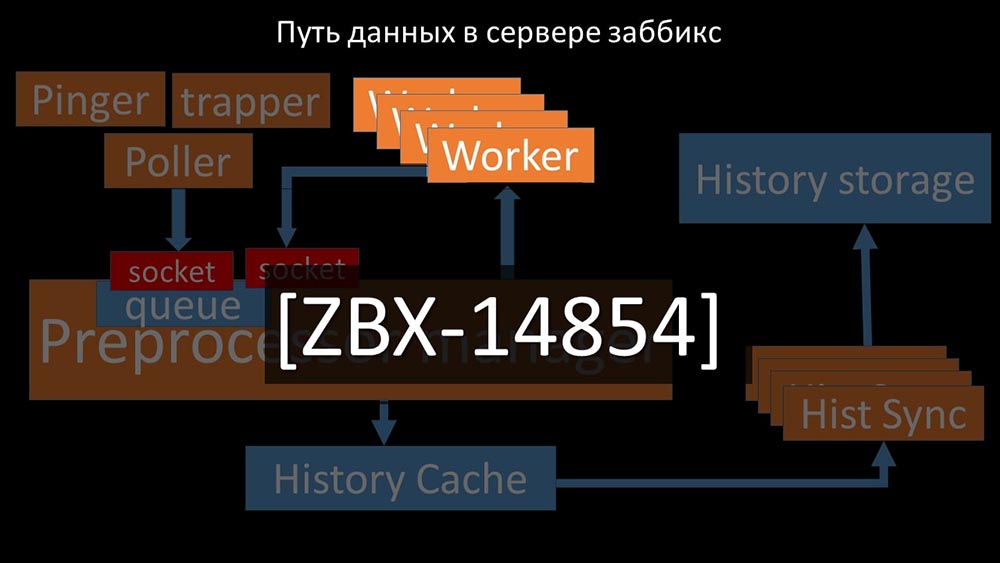
Aumentamos o número de soquetes - obtemos o resultado
Além disso, o próprio gerente de pré-processador se tornou um link estreito, pois é um único encadeamento. Ele repousava na velocidade do núcleo, fornecendo uma velocidade máxima de cerca de 70 mil métricas por segundo: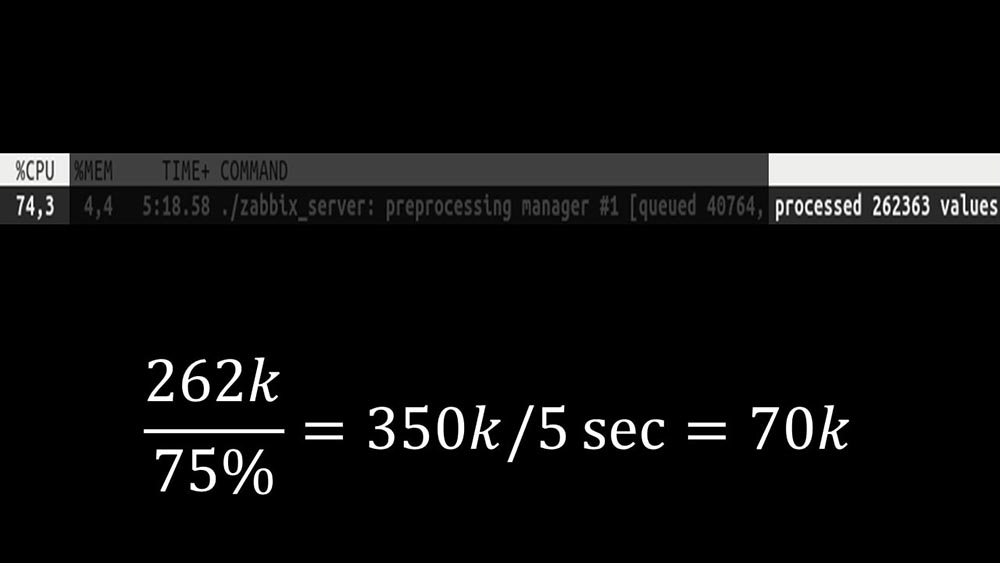 portanto, fizemos quatro, com quatro conjuntos de soquetes, trabalhadores:
portanto, fizemos quatro, com quatro conjuntos de soquetes, trabalhadores: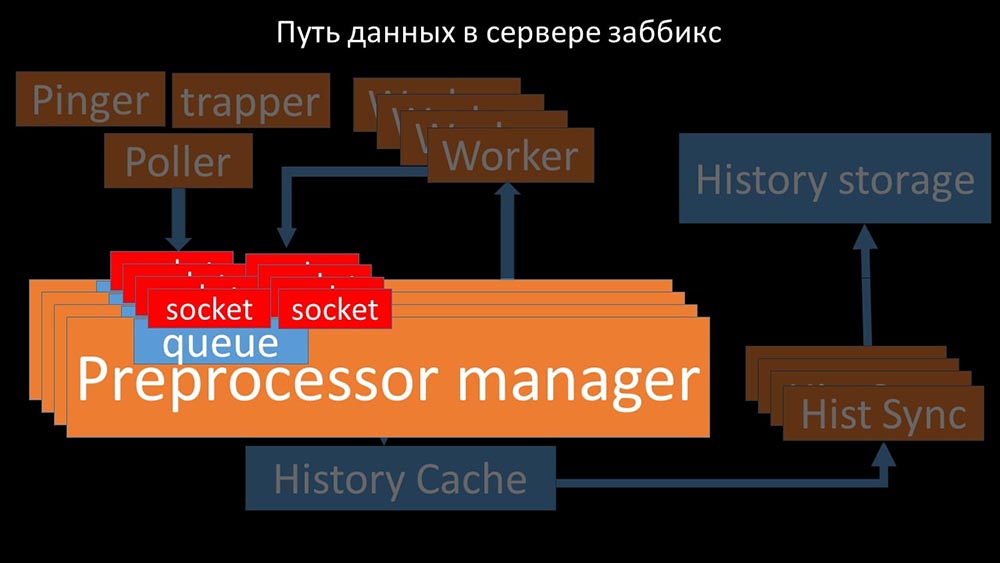 e isso nos permitiu aumentar a velocidade para cerca de 130 mil métricas: A
e isso nos permitiu aumentar a velocidade para cerca de 130 mil métricas: A não linearidade do crescimento é explicada pelo fato de haver competição pelo cache histórias. Para ele, quatro gerentes de pré-processadores e sincronizadores históricos competiram. Nesse ponto, recebemos cerca de 130 mil métricas por segundo em uma máquina de teste, utilizando-a em cerca de 95% no processador:
não linearidade do crescimento é explicada pelo fato de haver competição pelo cache histórias. Para ele, quatro gerentes de pré-processadores e sincronizadores históricos competiram. Nesse ponto, recebemos cerca de 130 mil métricas por segundo em uma máquina de teste, utilizando-a em cerca de 95% no processador: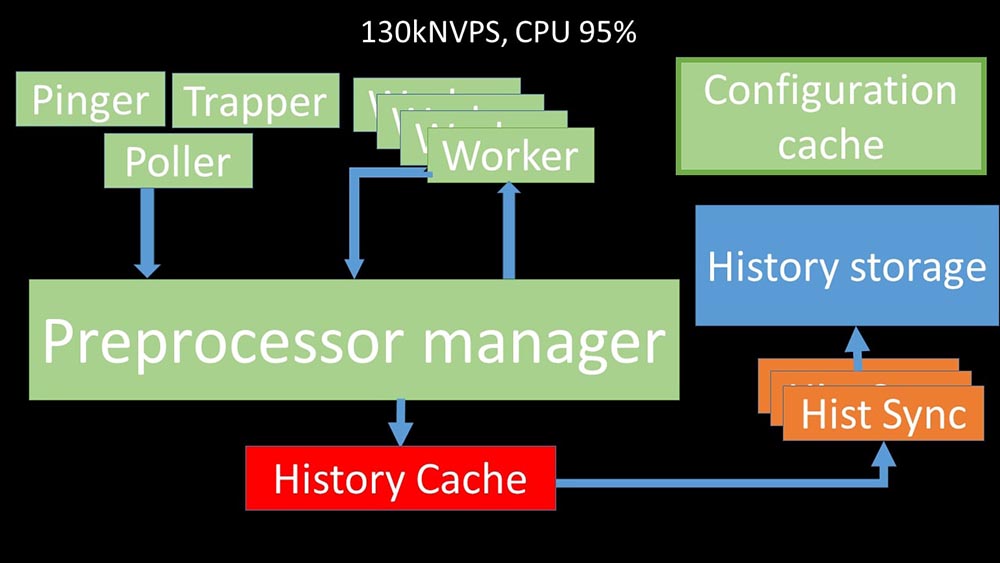 cerca de 2,5 meses atrás
cerca de 2,5 meses atrásA recusa da comunidade snmp aumentou os NVPs em uma vez e meia
MM: - Max, preciso de uma nova máquina de teste! Não nos encaixamos mais no atual.MCH: - E o que é agora?MM: - Agora - 130k NVPs e um processador "de prateleira".MCH: - Uau! Legal! Espere, eu tenho duas perguntas. De acordo com meus cálculos, nossa necessidade é de 15 a 20 mil métricas por segundo. Por que precisamos de mais?MM: - Quero terminar o trabalho até o fim. Eu quero ver o quanto podemos extrair deste sistema.MCH: - Mas ...MM: - Mas é inútil para os negócios.MCH: - Entendo. E a segunda pergunta: o que temos agora, podemos nos apoiar, sem a ajuda de um desenvolvedor?MILÍMETROS:- Eu não acho. Alterar o cache de configuração é um problema. Ele lida com alterações na maioria dos threads e é difícil de manter. Provavelmente, apoiá-la será muito difícil.MCH: - Então você precisa de algum tipo de alternativa.MM: - Existe essa opção. Podemos mudar para núcleos rápidos, enquanto abandonamos o novo sistema de travamento. Ainda temos o desempenho de 60 a 80 mil métricas. Nesse caso, podemos deixar o restante do código. Clickhouse, a pesquisa assíncrona funcionará. E será fácil de manter.MCH: - Ótimo! Proponho me debruçar sobre isso.Depois de otimizar o lado do servidor, finalmente conseguimos executar o novo código no produtivo. Abandonamos parte das mudanças em favor de mudar para uma máquina com kernels rápidos e minimizar o número de alterações no código. Também simplificamos a configuração e, se possível, abandonamos as macros nos elementos de dados, pois são a fonte de bloqueios adicionais. Por exemplo, a rejeição da macro snmp-community, que é freqüentemente encontrada em documentação e exemplos, em nosso caso nos permitiu acelerar adicionalmente os NVPs em cerca de 1,5 vezes.Após dois dias em produção
Por exemplo, a rejeição da macro snmp-community, que é freqüentemente encontrada em documentação e exemplos, em nosso caso nos permitiu acelerar adicionalmente os NVPs em cerca de 1,5 vezes.Após dois dias em produçãoRemover pop-ups do histórico de incidentes
MCH: - Misha, usamos o sistema por dois dias, e tudo funciona. Mas somente quando tudo funciona! Planejamos o trabalho com a transferência de um segmento suficientemente grande da rede e, novamente, com as mãos, verificamos que ele havia subido, ou não.MM: - Não pode ser! Verificamos tudo 10 vezes. O servidor processa até a inacessibilidade completa da rede instantaneamente.MCH: - Sim, eu entendo tudo: servidor, banco de dados, top, austat, logs - tudo é rápido ... Mas olhamos para a interface da web e lá temos o processador "na prateleira" no servidor e este: MM: - Entendo. Vamos assistir a web. Descobrimos que em uma situação em que havia um grande número de incidentes ativos, a maioria dos widgets operacionais começou a funcionar muito lentamente:
MM: - Entendo. Vamos assistir a web. Descobrimos que em uma situação em que havia um grande número de incidentes ativos, a maioria dos widgets operacionais começou a funcionar muito lentamente: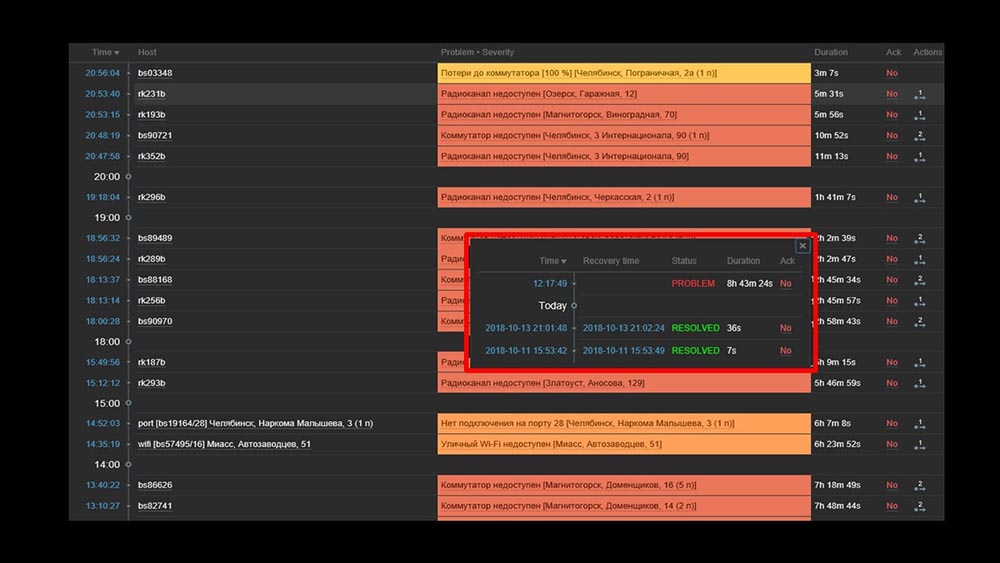 O motivo disso foi a geração de pop-ups com um histórico de incidentes gerados para cada item da lista. Portanto, nos recusamos a gerar essas janelas (comentaram 5 linhas no código), e isso resolveu nossos problemas.O tempo de carregamento do widget, mesmo quando completamente inacessível, foi reduzido de alguns minutos para o aceitável por 10 a 15 segundos, e o histórico ainda pode ser visualizado clicando no horário:
O motivo disso foi a geração de pop-ups com um histórico de incidentes gerados para cada item da lista. Portanto, nos recusamos a gerar essas janelas (comentaram 5 linhas no código), e isso resolveu nossos problemas.O tempo de carregamento do widget, mesmo quando completamente inacessível, foi reduzido de alguns minutos para o aceitável por 10 a 15 segundos, e o histórico ainda pode ser visualizado clicando no horário: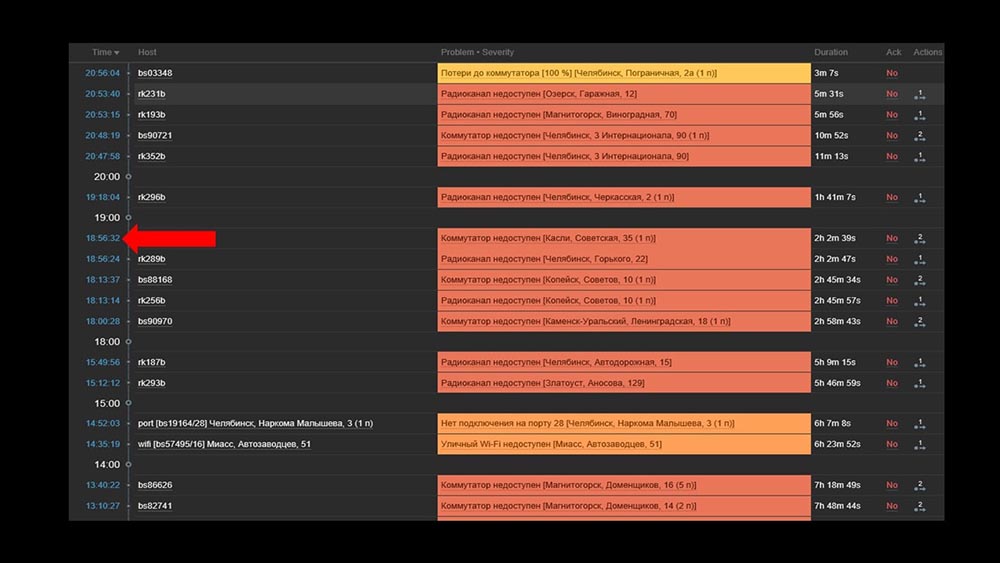 Após o trabalho. 2 meses atrásMCH: - Misha, você está indo embora? Nós temos que conversar.MM: - Não vou. Mais uma vez algo com Zabbix?MCH: - Oh não, relaxe! Eu só queria dizer: tudo funciona, obrigado! Cerveja comigo.
Após o trabalho. 2 meses atrásMCH: - Misha, você está indo embora? Nós temos que conversar.MM: - Não vou. Mais uma vez algo com Zabbix?MCH: - Oh não, relaxe! Eu só queria dizer: tudo funciona, obrigado! Cerveja comigo.Zabbix é eficaz
O Zabbix é um sistema e função bastante versátil e rico. Pode ser usado para pequenas instalações prontas para uso, mas com o crescimento das necessidades, ele precisa ser otimizado. Para armazenar um grande arquivo de métricas, use o armazenamento apropriado:- Você pode usar as ferramentas integradas na forma de integração com o Elastixerch ou carregar o histórico em arquivos de texto (disponível na quarta versão);
- Você pode tirar proveito da nossa experiência e integração com a Clickhouse.
Para aumentar drasticamente a velocidade da coleta de métricas, colete-as de forma assíncrona e transfira-as pela interface do trapper para o servidor Zabbix; ou você pode usar o patch para pollers assíncronos do próprio Zabbix.O Zabbix é escrito em C e é bastante eficaz. A solução de vários locais estreitos de arquitetura permite aumentar ainda mais sua produtividade e, em nossa experiência, receber mais de 100 mil métricas em uma máquina com processador único.
O mesmo patch do Zabbix
MM: - Quero adicionar alguns pontos. Todo o relatório atual, todos os testes e números são fornecidos para a configuração que é usada conosco. Agora estamos retirando cerca de 20 mil métricas por segundo. Se você está tentando entender se isso funcionará para você - você pode comparar. O que eles falaram hoje está publicado no GitHub como um patch: github.com/miklert/zabbix O patch inclui:
O patch inclui:- total integração com Clickhouse (servidor Zabbix e front-end);
- resolução de problemas com o gerenciador de pré-processador;
- sondagem assíncrona.
O patch é compatível com toda a versão 4, incluindo lts. Provavelmente, com alterações mínimas, ele funcionará na versão 3.4.Obrigado pela atenção.Questões
Pergunta da platéia (doravante - A): - Boa tarde! Por favor, diga-me, você tem planos de interação intensa com a equipe do Zabbix ou eles têm com você para que isso não seja um patch, mas o comportamento normal do Zabbix?MM: - Sim, certamente iremos cometer parte das mudanças. Algo será, algo permanecerá no patch.A: - Muito obrigado pelo excelente relatório! Diga-me, por favor, depois de aplicar o patch, o suporte lateral do Zabbix permanecerá e como continuar a atualização para versões superiores? Será possível atualizar o Zabbix após o patch para 4.2, 5.0?MILÍMETROS:- Eu não posso dizer sobre suporte. Se eu fosse o suporte técnico do Zabbix, provavelmente diria que não, porque esse é o código de outra pessoa. Quanto à base de código 4.2, nossa posição é a seguinte: "Iremos com o tempo e seremos atualizados na próxima versão". Portanto, por algum tempo, carregaremos o patch para versões atualizadas. Eu já disse no relatório: o número de alterações nas versões ainda é muito pequeno. Acho que a transição de 3,4 para 4. levou cerca de 15 minutos, algo mudou por lá, mas não muito importante.R: - Então você planeja manter seu patch e pode colocá-lo em produção com segurança, recebendo no futuro atualizações de alguma forma?MM: - Nós recomendamos fortemente. Isso resolve muitos problemas para nós.MCH:- Mais uma vez, gostaria de enfatizar que as mudanças que não se relacionam à arquitetura e não se relacionam a bloqueios, filas - são modulares, estão em módulos separados. Mesmo por conta própria, com pequenas alterações, eles podem ser mantidos com bastante facilidade.MM: - Se os detalhes forem interessantes, o “Clickhouse” usa a chamada biblioteca de histórico. Está desatado - é uma cópia do suporte do Elastic, ou seja, é configurável. A pesquisa muda apenas os pesquisadores. Acreditamos que isso funcionará por um longo tempo.A: - Muito obrigado. Mas diga-me, existe alguma documentação das alterações feitas? MILÍMETROS:- Documentação é um patch. Obviamente, com a introdução do “Clickhouse”, com a introdução de novos tipos de pollers, surgem novas opções de configuração. O link do último slide possui uma breve descrição de como usá-lo.
MILÍMETROS:- Documentação é um patch. Obviamente, com a introdução do “Clickhouse”, com a introdução de novos tipos de pollers, surgem novas opções de configuração. O link do último slide possui uma breve descrição de como usá-lo.Sobre como substituir o fping pelo nmap
A: - Como você finalmente implementou isso? Você pode dar exemplos específicos: são seus strappers e um script externo? O que eventualmente verifica tantos hosts tão rapidamente? Como você consegue esses hosts? O nmap precisa de alguma forma alimentá-los, obtê-los de algum lugar, colocá-los, iniciar algo? ..MM:- Legal. Pergunta muito correta! O ponto é este. Modificamos a biblioteca (ping ICMP, parte do Zabbix) para verificações de ICMP, que indicam o número de pacotes - unidade (1), e o código tenta usar o nmap. Ou seja, este é o trabalho interno do Zabbix, tornou-se o trabalho interno do pinger. Consequentemente, nenhuma sincronização ou uso de um trapper é necessário. Isso foi feito deliberadamente, a fim de deixar o sistema coerente e não se envolver na sincronização de dois sistemas básicos: o que verificar, preencher através do poller e se o preenchimento foi quebrado em nós? .. Isso é muito mais fácil.A: - Também funciona para um proxy?MM: - Sim, mas não verificamos. O código de pesquisa é o mesmo no Zabbix e no servidor. Deveria trabalhar. Enfatizo novamente: o desempenho do sistema é tal que não precisamos de um proxy.MCH: - A resposta correta para a pergunta é: "Por que você precisa de um proxy com esse sistema?" Só por causa do NAT'a ou para monitorar através de um canal lento alguns ...R: - E você usa o Zabbix como alérgeno, se bem entendi. Ou os gráficos (onde está a camada de arquivamento) que você deixou para outro sistema, como o Grafana? Ou você não está usando esta funcionalidade?MM: - Vou enfatizar mais uma vez: fizemos uma integração completa. Colocamos história no "Clickhouse", mas ao mesmo tempo mudamos o front-end do php. O php-frontend acessa “Clickhouse” e faz todos os gráficos de lá. Ao mesmo tempo, para ser sincero, temos uma parte que é criada a partir do mesmo “Clickhouse”, dos mesmos dados do Zabbix, dados em outros sistemas de exibição gráfica.MCH: - Em "Grafan" também.Como foi tomada a decisão de alocar recursos?
A: - Compartilhe uma pequena cozinha interna. Como foi tomada a decisão de alocar recursos para processamento sério de produtos? Estes são, em geral, certos riscos. E, por favor, diga-me, no contexto em que você apoiará novas versões: como essa decisão se justifica do ponto de vista gerencial?MM: - Aparentemente, não contamos o drama da história muito bem. Nós nos encontramos em uma situação em que algo tinha que ser feito, e seguimos essencialmente dois comandos paralelos:- Um deles estava envolvido no lançamento de um sistema de monitoramento usando novos métodos: monitoramento como serviço, um conjunto padrão de soluções de código aberto que combinamos e, em seguida, tentamos alterar o processo de negócios para trabalhar com o novo sistema de monitoramento.
- Paralelamente, tivemos um programador entusiasmado que estava fazendo isso (sobre si mesmo). Aconteceu que ele ganhou.
A: - E qual é o tamanho da equipe?MCH: - Ela está na sua frente.A: - Isso é, como sempre, necessário um apaixonado?MM: - Não sei o que é um apaixonado.A: - Neste caso, aparentemente, você. Muito obrigado, você é legal.MM: - Obrigado.Sobre patches para o Zabbix
R: - Para um sistema que usa proxies (por exemplo, em alguns sistemas distribuídos), é possível que você decida adaptar e corrigir, digamos, pollers, proxies e parcialmente o pré-processador do próprio Zabbix; e a interação deles? É possível otimizar desenvolvimentos existentes para um sistema com vários proxies?MM: - Eu sei que o servidor Zabbix é montado usando um proxy (ele é compilado e o código é obtido). Não testamos isso no produto. Não tenho certeza disso, mas, na minha opinião, o gerente do pré-processador não é usado no proxy. A tarefa do proxy é pegar um conjunto de métricas do Zabbix, preenchê-las (ele também grava a configuração, banco de dados local) e devolvê-lo ao servidor Zabbix. Em seguida, o próprio servidor fará o pré-processamento quando o receber.O interesse em proxies é compreensível. Vamos verificar isso. Este é um tópico interessante.R: - A idéia era a seguinte: se você pode corrigir os pollers, eles podem ser corrigidos para proxies e interagir com o servidor, e o pré-processador para esses fins pode ser adaptado apenas no servidor.MM: - Eu acho que tudo é ainda mais simples. Você pega o código, aplica o patch e, em seguida, configura-o conforme necessário - colete os servidores proxy (por exemplo, com ODBC) e distribua o código corrigido para os sistemas. Onde necessário - colete proxies, onde necessário - servidor.A: - Além disso, você não precisará corrigir a transmissão do proxy no servidor, provavelmente?MCH: - Não, é padrão.MILÍMETROS:- Na verdade, uma das idéias não soou. Sempre mantivemos um equilíbrio entre uma explosão de idéias e o número de mudanças, a facilidade de suporte.Um pouco de publicidade :)
Obrigado por ficar com a gente. Você gosta dos nossos artigos? Deseja ver materiais mais interessantes? Ajude-nos fazendo um pedido ou recomendando aos seus amigos o VPS na nuvem para desenvolvedores a partir de US $ 4,99 , um analógico exclusivo de servidores de nível básico que foi inventado por nós para você: Toda a verdade sobre o VPS (KVM) E5-2697 v3 (6 núcleos) 10 GB DDR4 480 GB SSD 1 Gbps de US $ 19 ou como dividir o servidor? (as opções estão disponíveis com RAID1 e RAID10, até 24 núcleos e até 40GB DDR4).Dell R730xd 2 vezes mais barato no data center Equinix Tier IV em Amsterdã? Somente nós temos 2 TVs Intel TetraDeca-Core Xeon 2x E5-2697v3 2.6GHz 14C 64GB DDR4 4x960GB SSD 1Gbps 100 TV a partir de US $ 199 na Holanda!Dell R420 - 2x E5-2430 2.2Ghz 6C 128GB DDR3 2x960GB SSD 1Gbps 100TB - a partir de $ 99! Leia sobre Como criar um prédio de infraestrutura. classe c usando servidores Dell R730xd E5-2650 v4 que custam 9.000 euros por um centavo? Source: https://habr.com/ru/post/undefined/
All Articles