Em um artigo anterior, examinamos o mecanismo de atenção, um método extremamente comum em modelos modernos de aprendizado profundo que podem melhorar os indicadores de desempenho de aplicativos de tradução de máquina neural. Neste artigo, veremos o Transformer, um modelo que usa o mecanismo de atenção para aumentar a velocidade de aprendizado. Além disso, para várias tarefas, os Transformers superam o modelo de tradução automática neural do Google. No entanto, a maior vantagem dos transformadores é sua alta eficiência em condições de paralelização. Até o Google Cloud recomenda usar o Transformer como modelo ao trabalhar no Cloud TPU . Vamos tentar descobrir em que consiste o modelo e quais funções ele executa.
O modelo Transformer foi proposto pela primeira vez no artigo Atenção é tudo que você precisa . Uma implementação no TensorFlow está disponível como parte do pacote Tensor2Tensor . Além disso, um grupo de pesquisadores da PNL de Harvard criou uma anotação de guia do artigo com uma implementação no PyTorch . Neste mesmo guia, tentaremos declarar de maneira mais simples e consistente as principais idéias e conceitos que, esperamos, ajudem as pessoas que não têm um conhecimento profundo da área a entender esse modelo.
Revisão de Alto Nível
Vejamos o modelo como uma espécie de caixa preta. Em aplicativos de tradução automática, ele aceita uma frase em um idioma como entrada e exibe uma frase em outro.

, , , .
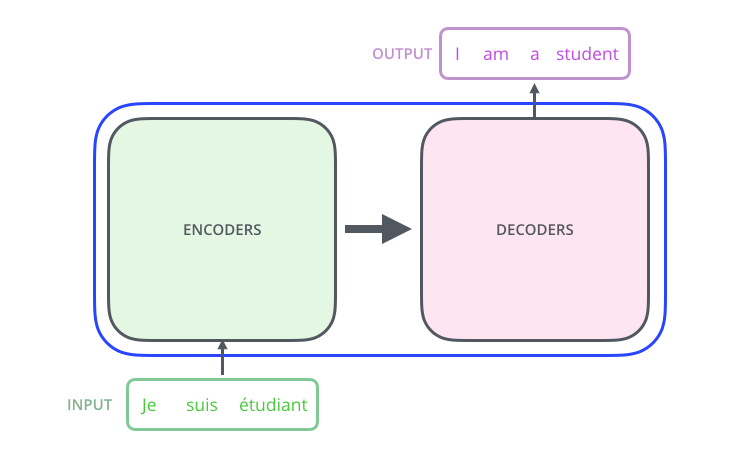
– ; 6 , ( 6 , ). – , .
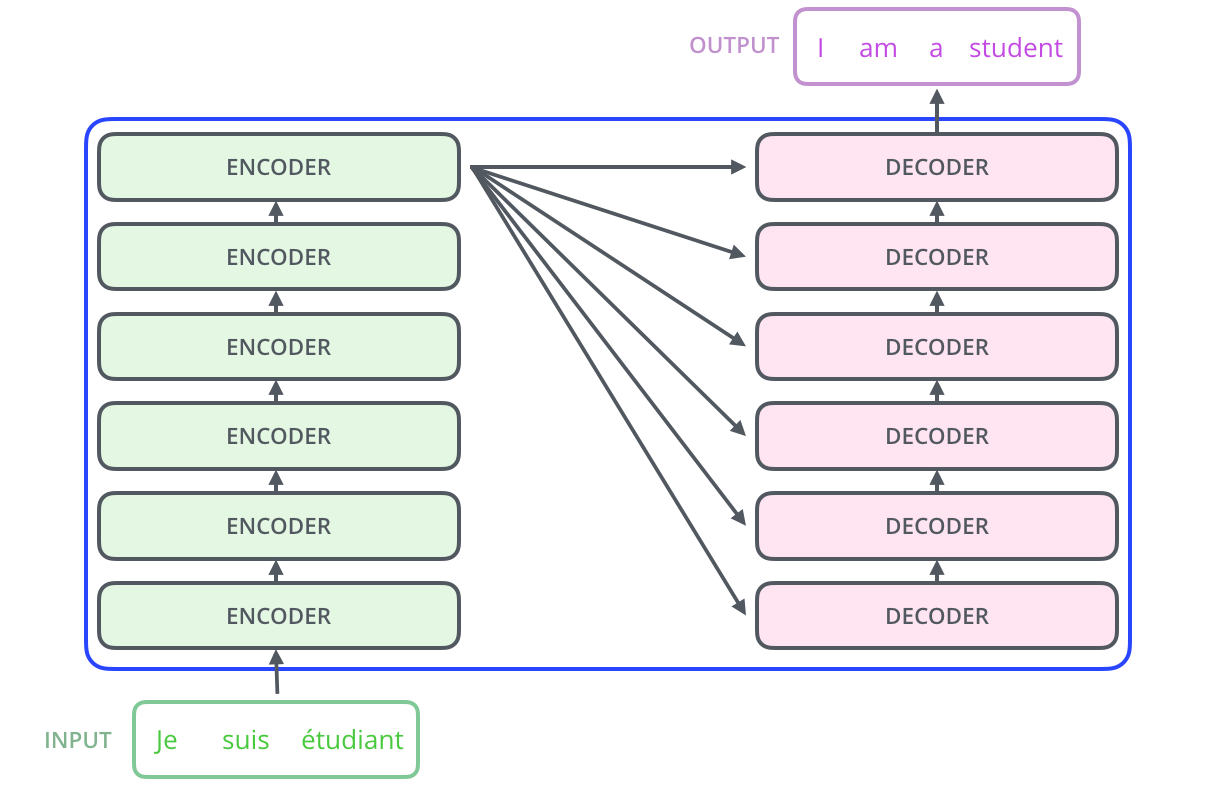
, . :
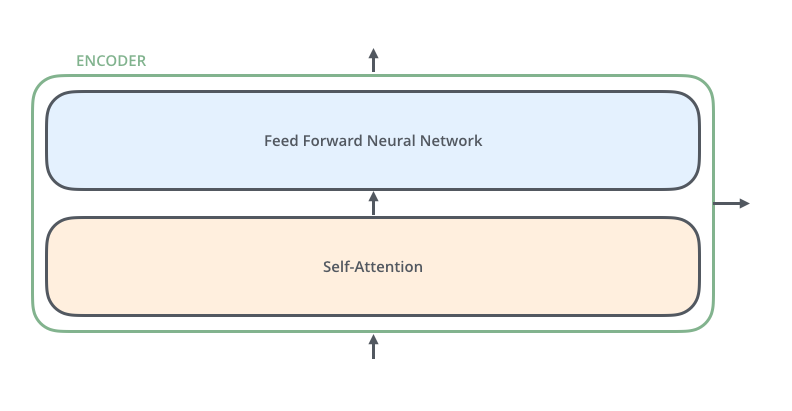
, , (self-attention), . .
(feed-forward neural network). .
, , ( , seq2seq).
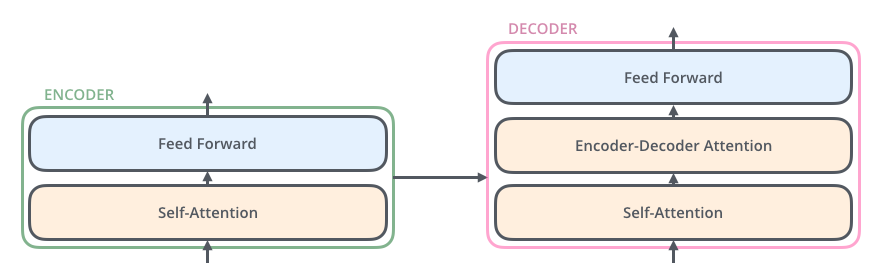
, , /, , .
NLP-, , , (word embeddings).

512. .
. , , : 512 ( , – ). , , , , .
, .
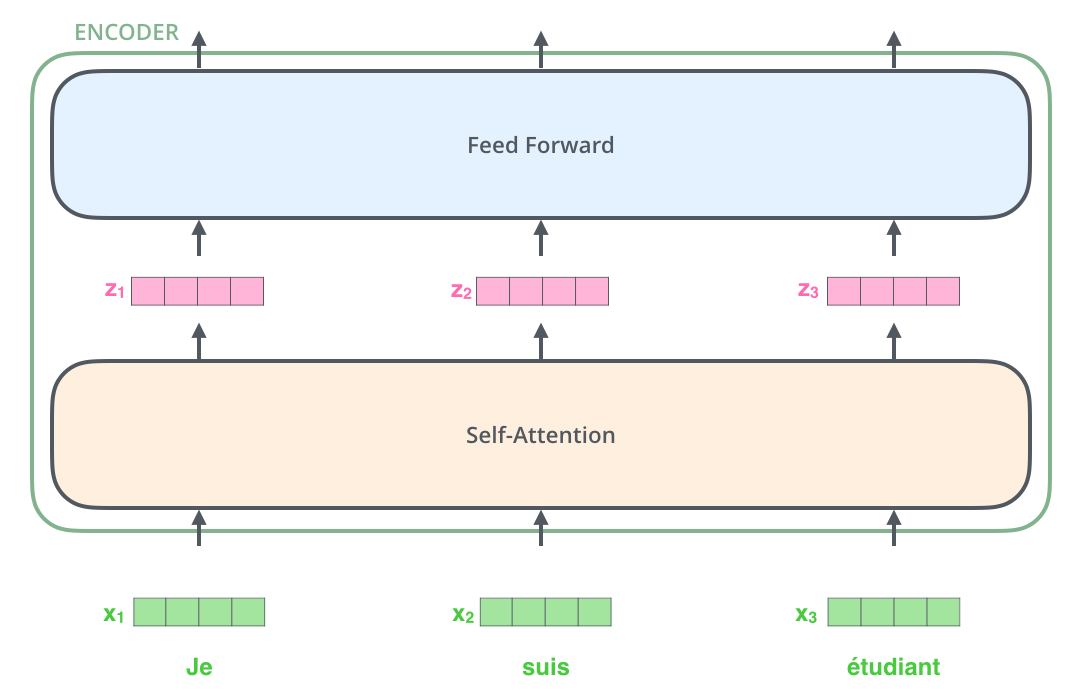
: . , , , .
, .
!
, , – , , , .
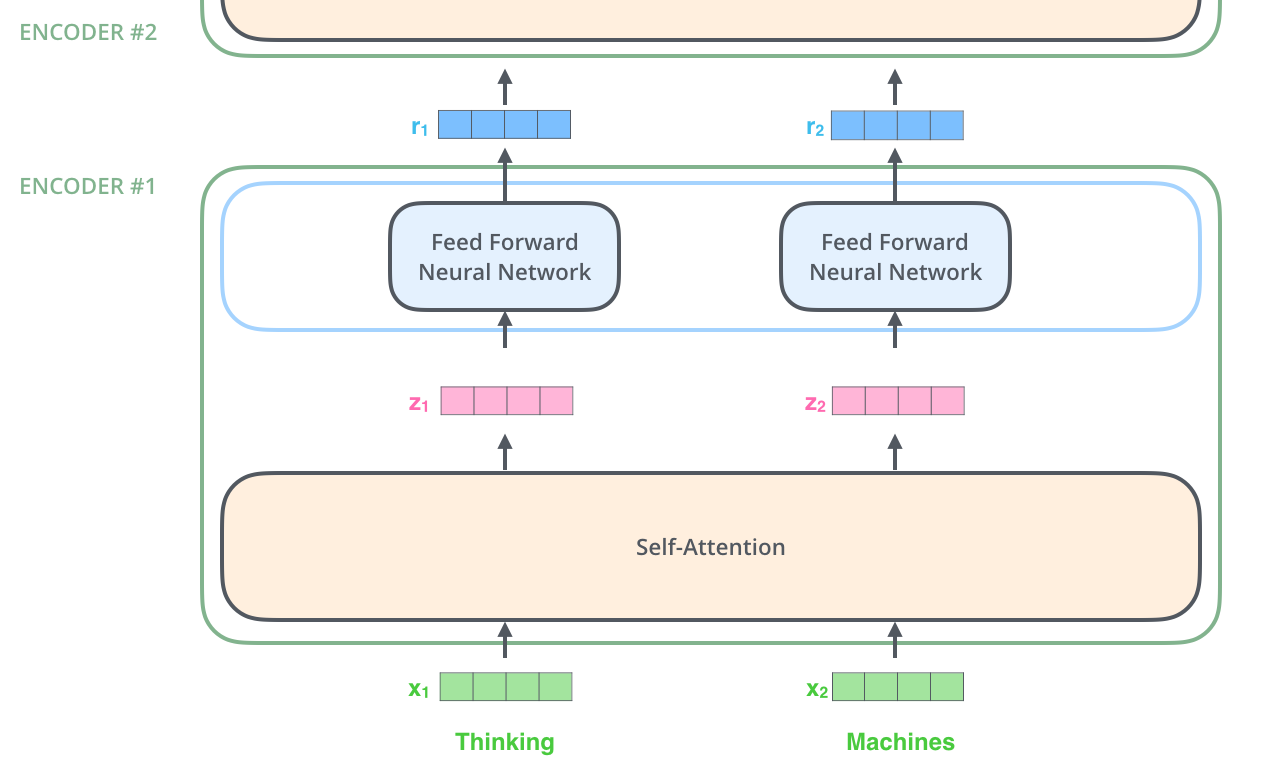
. , .
, « » -, . , «Attention is All You Need». , .
– , :
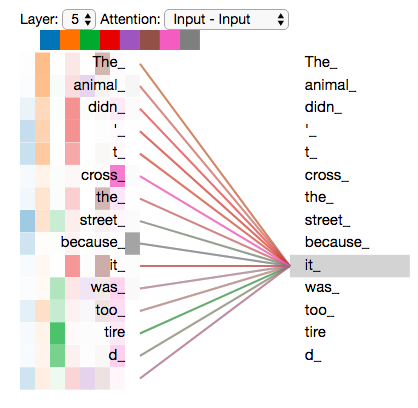
”The animal didn't cross the street because it was too tired”
«it» ? (street) (animal)? .
«it», , «it» «animal».
( ), , .
(RNN), , RNN /, , . – , , «» .

«it» #5 ( ), «The animal» «it».
Tensor2Tensor, , .
, , , .
– ( – ): (Query vector), (Key vector) (Value vector). , .
, , . 64, / 512. , (multi-head attention) .
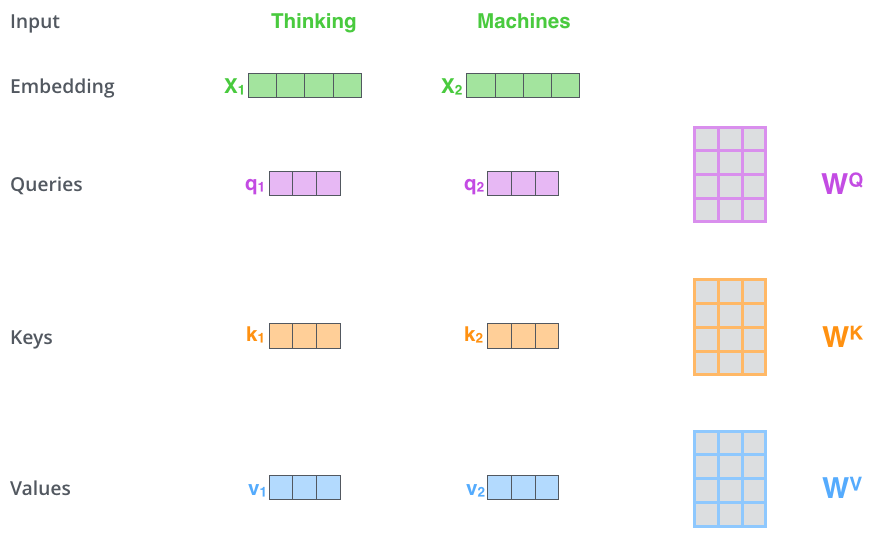
x1 WQ q1, «», . «», «» «» .
«», «» «»?
, . , , , .
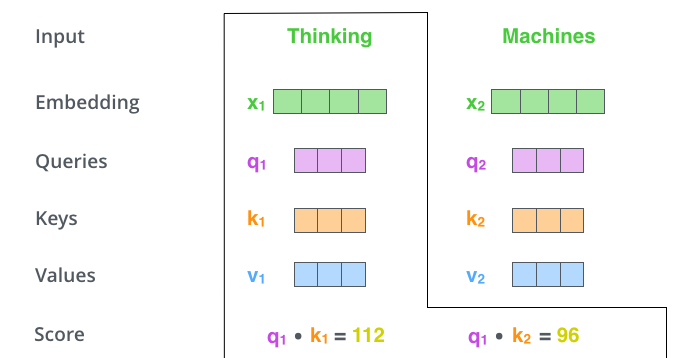
– (score). , – «Thinking». . , .
. , #1, q1 k1, — q1 k2.
– 8 ( , – 64; , ), (softmax). , 1.
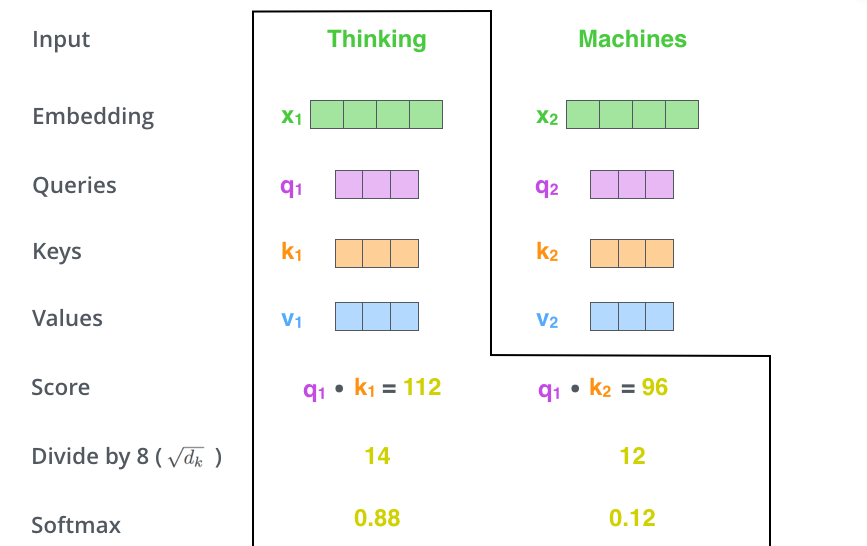
- (softmax score) , . , -, , .
– - ( ). : , , ( , , 0.001).
– . ( ).
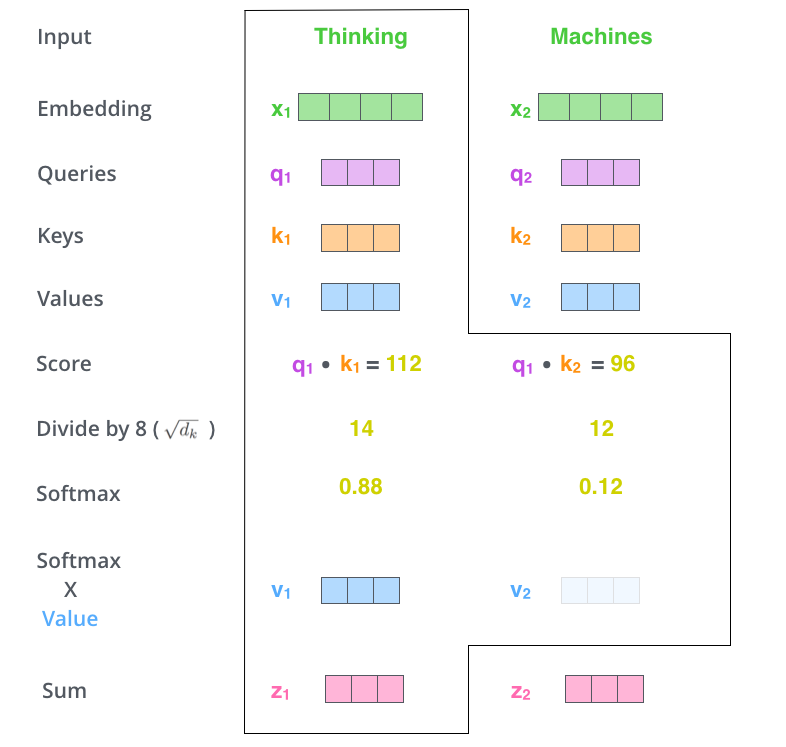
. , . , , . , , .
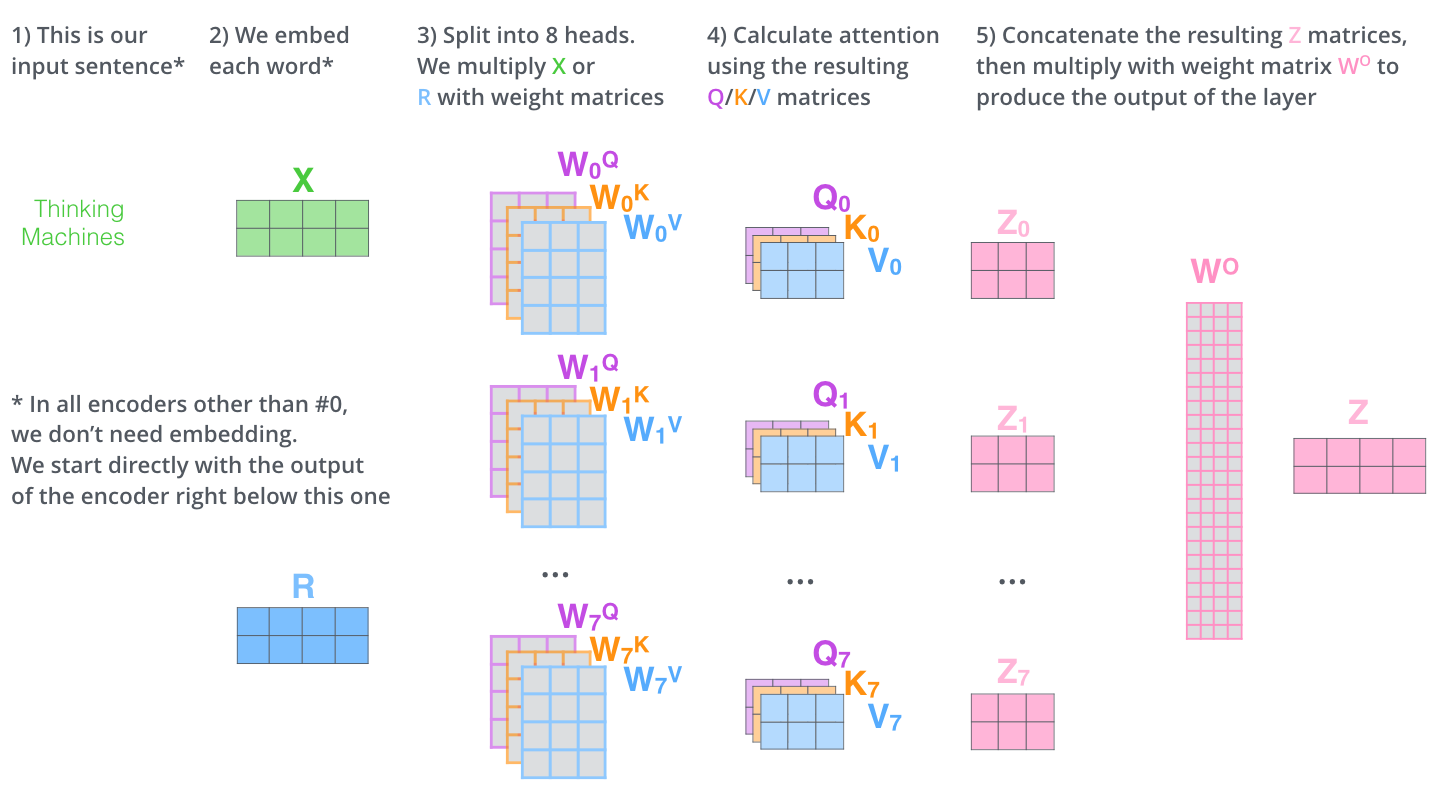
– , . X , (WQ, WK, WV).

. (512, 4 ) q/k/v (64, 3 ).
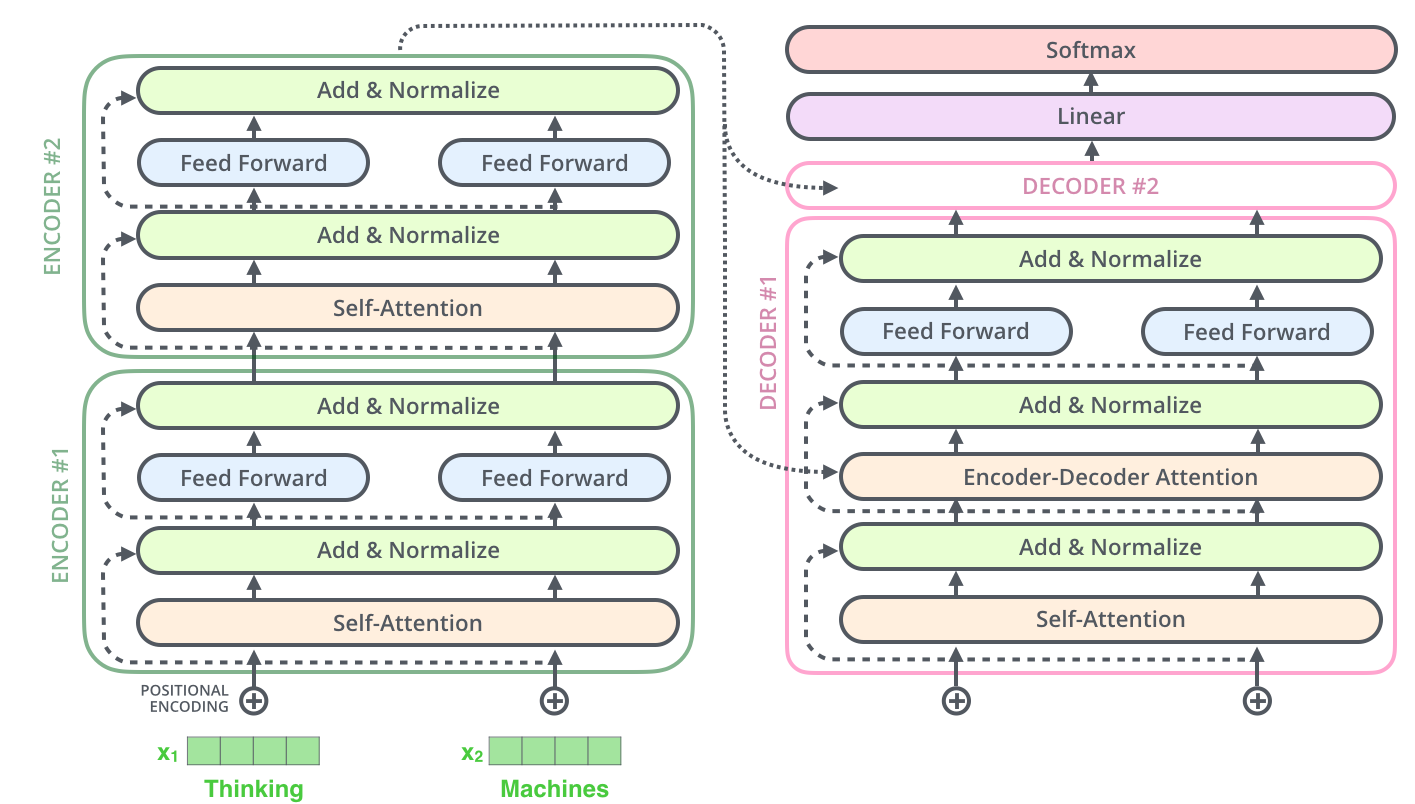
, , 2-6 .
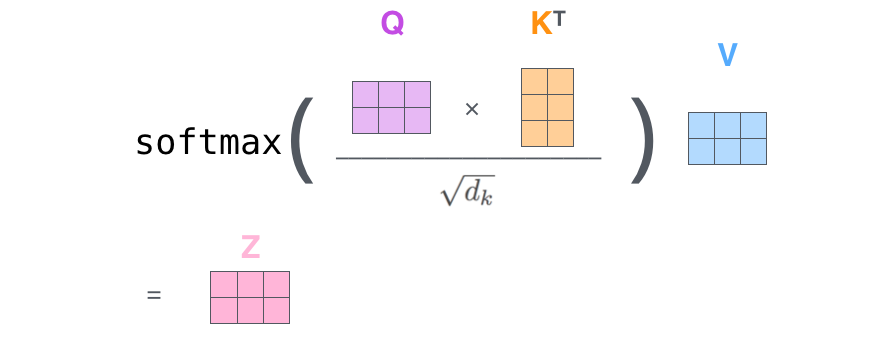
.
, (multi-head attention). :
- . , , z1 , . «The animal didn’t cross the street because it was too tired», , «it».
- « » (representation subspaces). , , // ( 8 «» , 8 /). . ( /) .
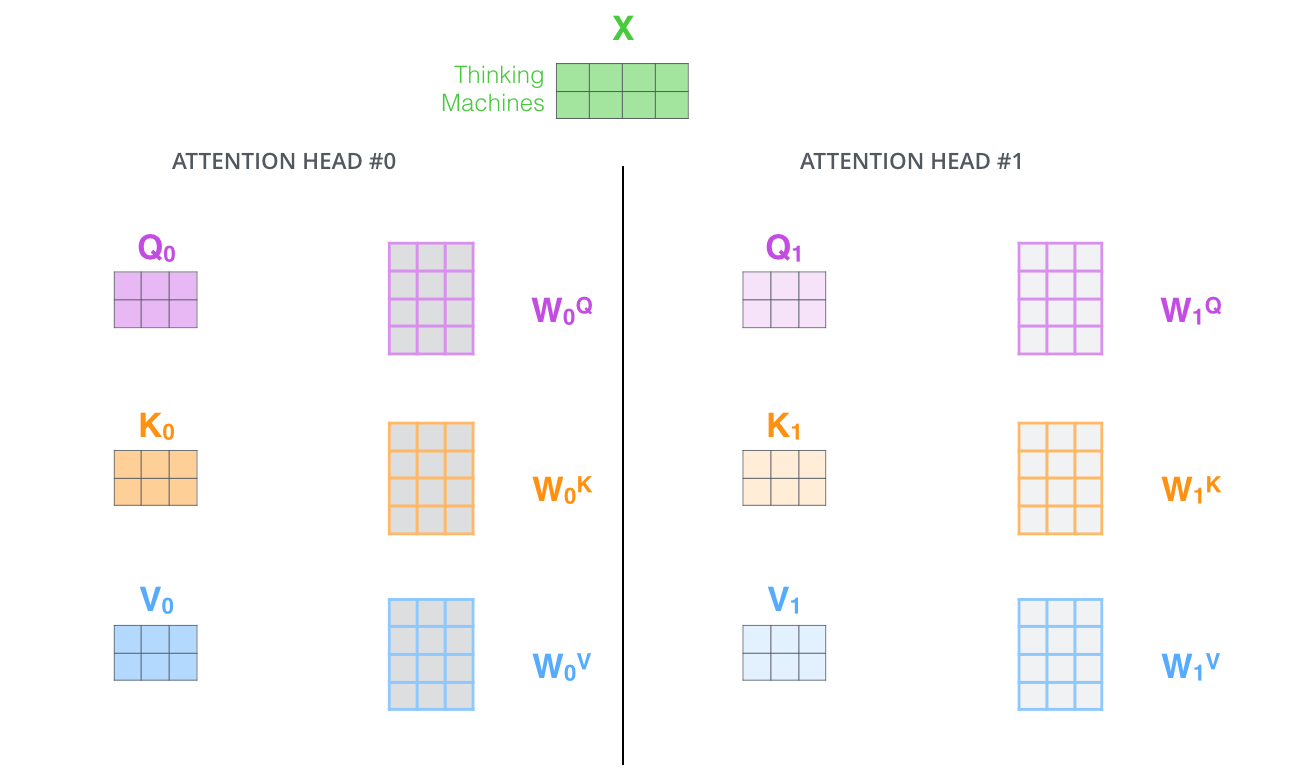
, WQ/WK/WV «», Q/K/V . , WQ/WK/WV Q/K/V .
, , 8 , 8 Z .
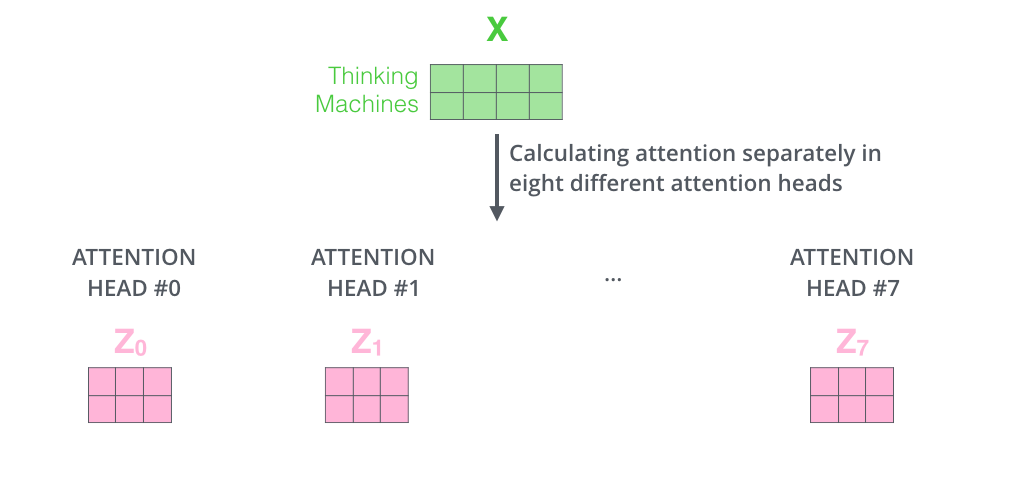
. , 8 – ( ), Z .
? WO.
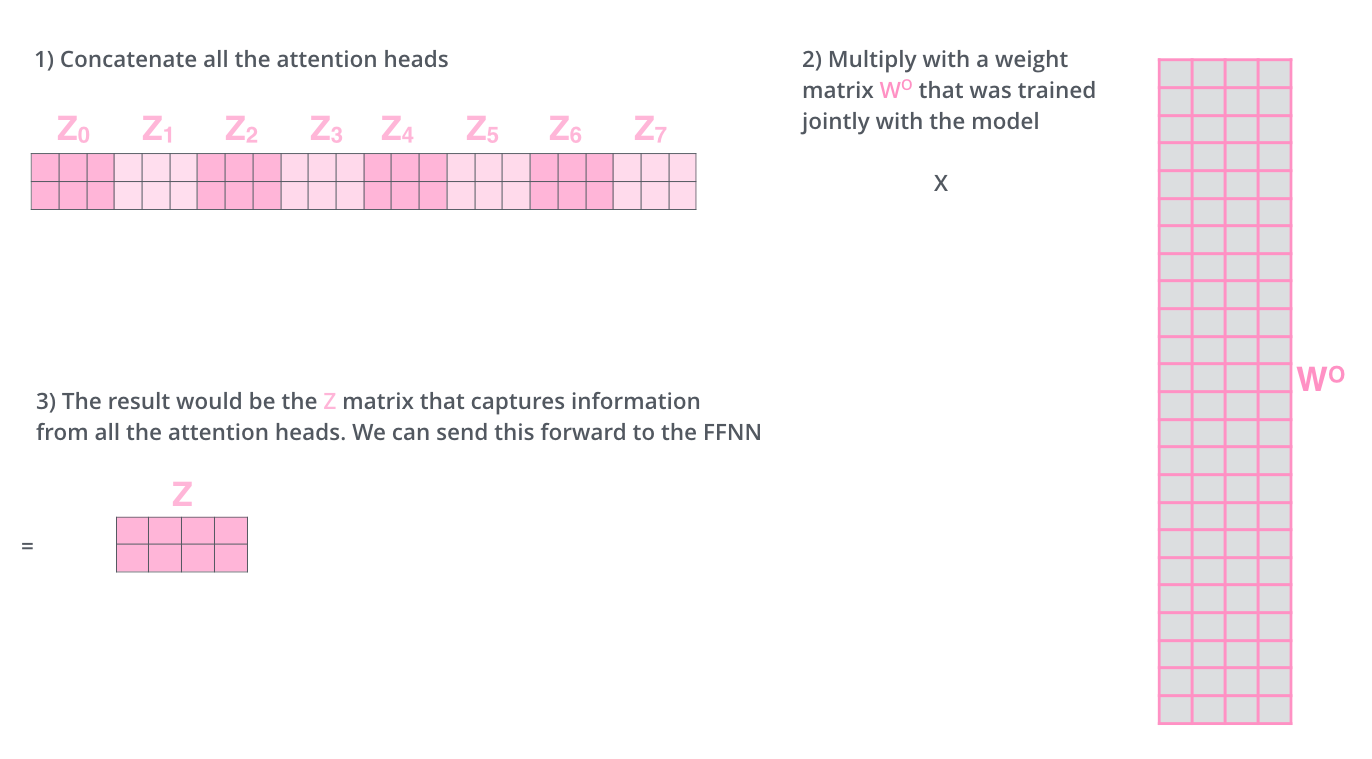
, , . , . , .
, «» , , , «» «it» :

«it», «» «the animal», — «tired». , «it» «animal» «tired».
«» , , .
— .
. , . , Q/K/V .
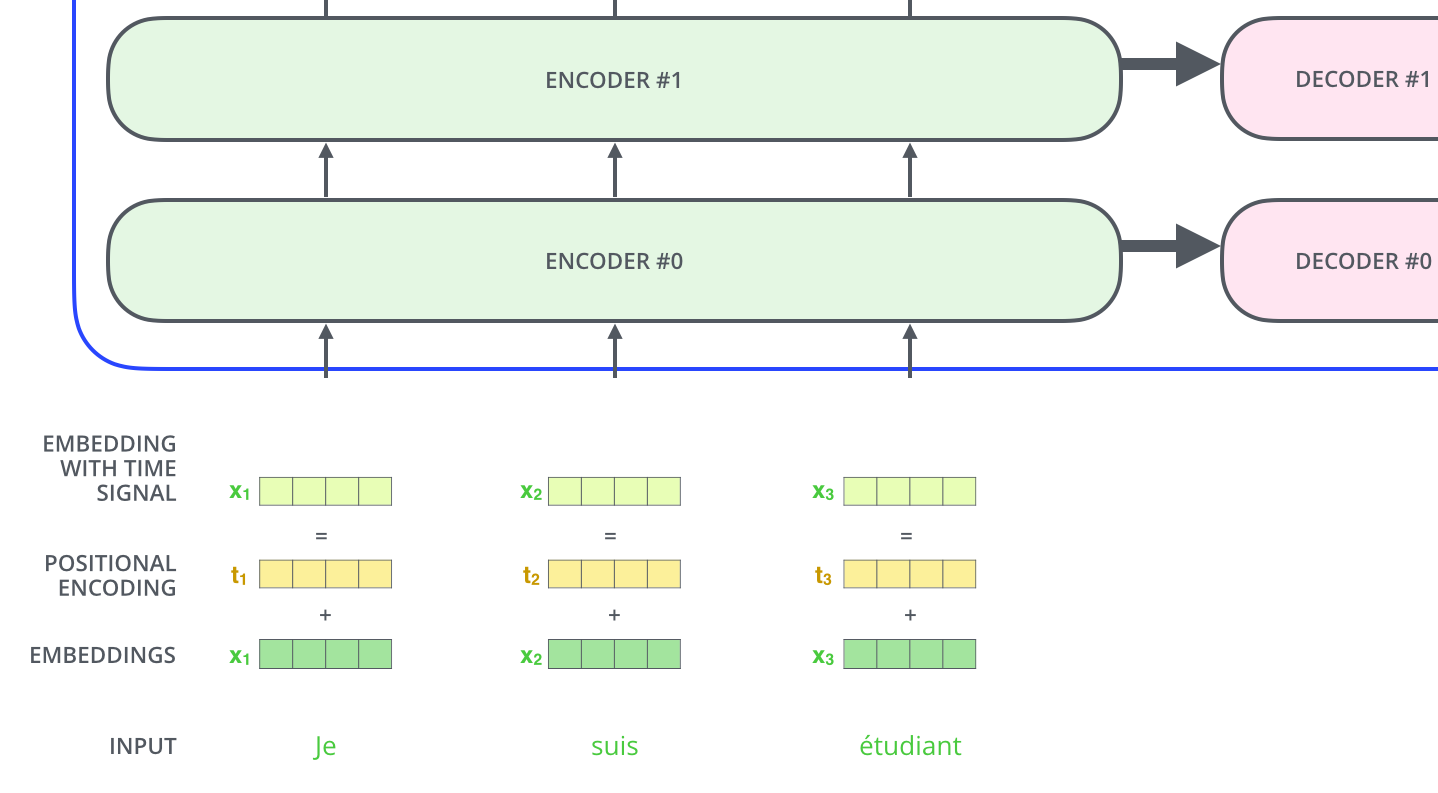
, , , .
, 4, :
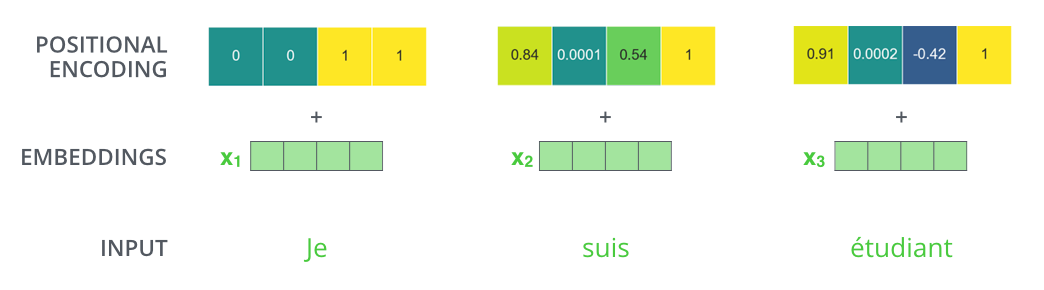
?
: , , , — .. 512 -1 1. , .
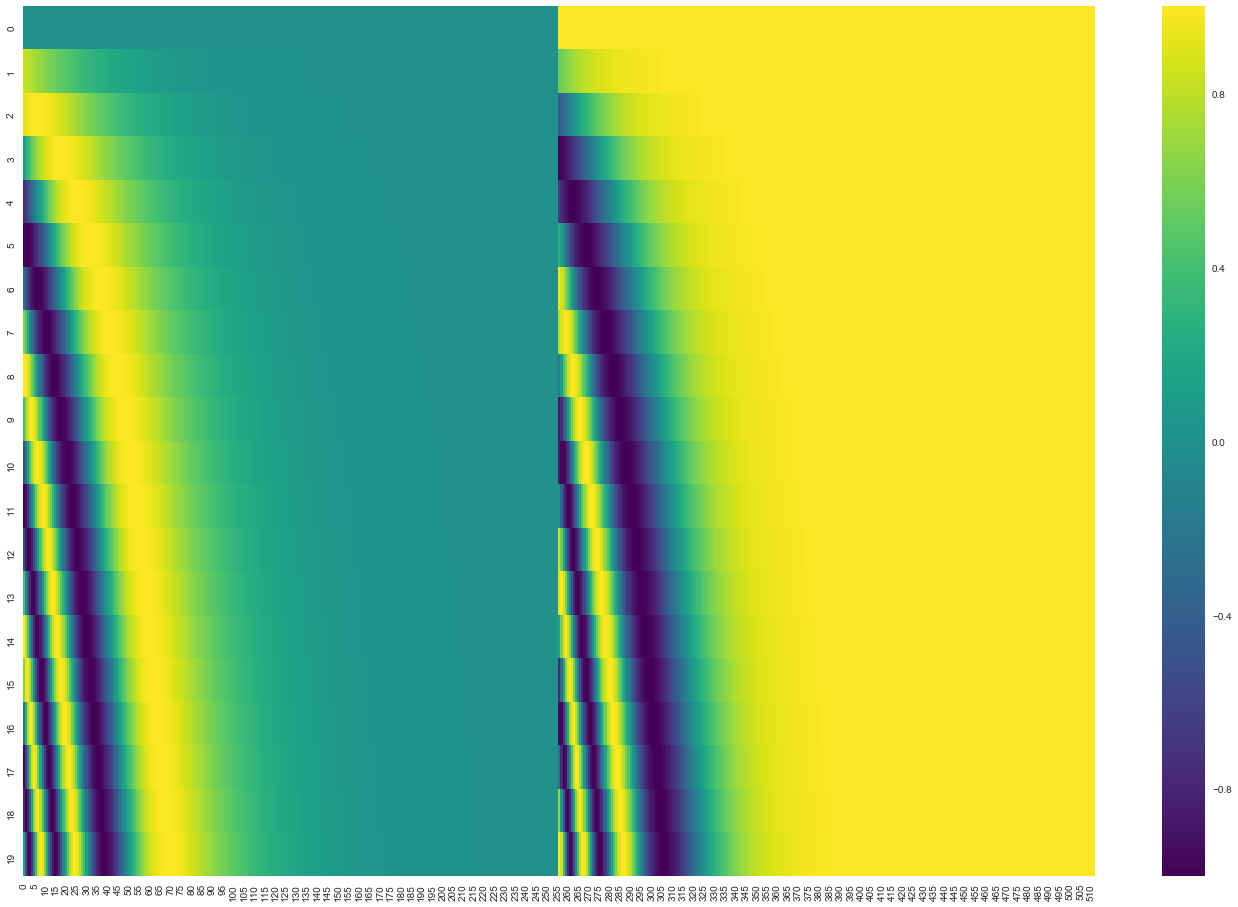
20 () 512 (). , : ( ), – ( ). .
( 3.5). get_timing_signal_1d(). , , (, , , ).
, , , , ( , ) , (layer-normalization step).
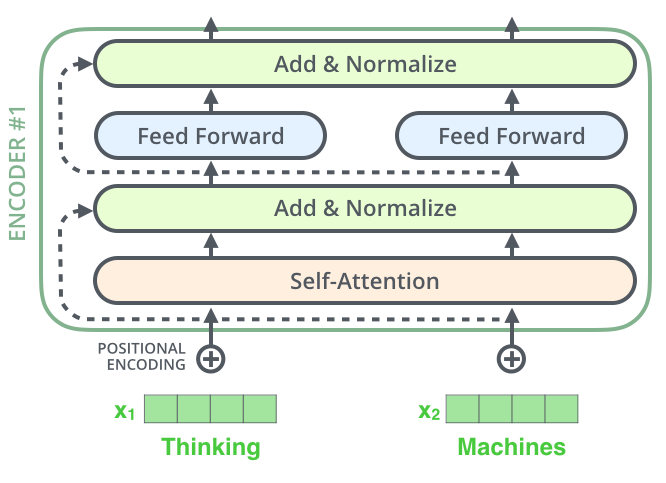
, , :
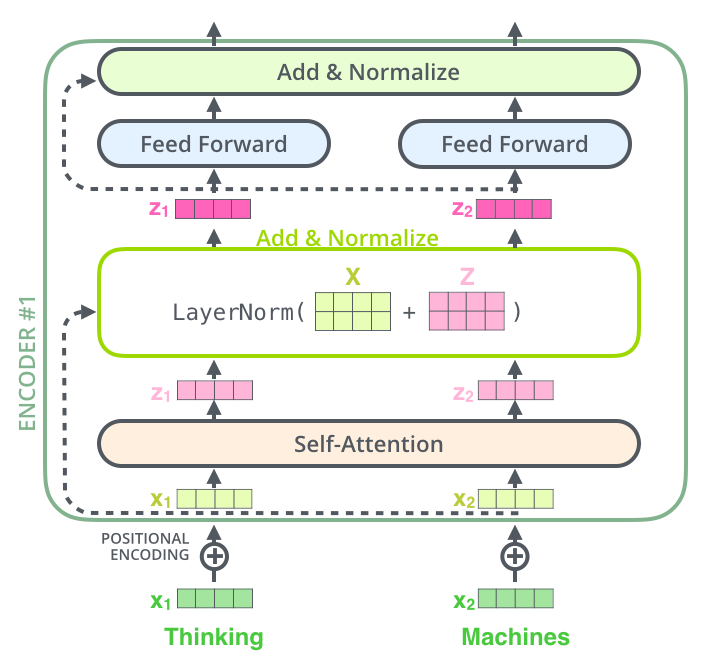
. , :
, , , . , .
. K V. «-» , :
. ( – ).
, , . , , . , , , .
.
. ( –inf) .
«-» , , , , .
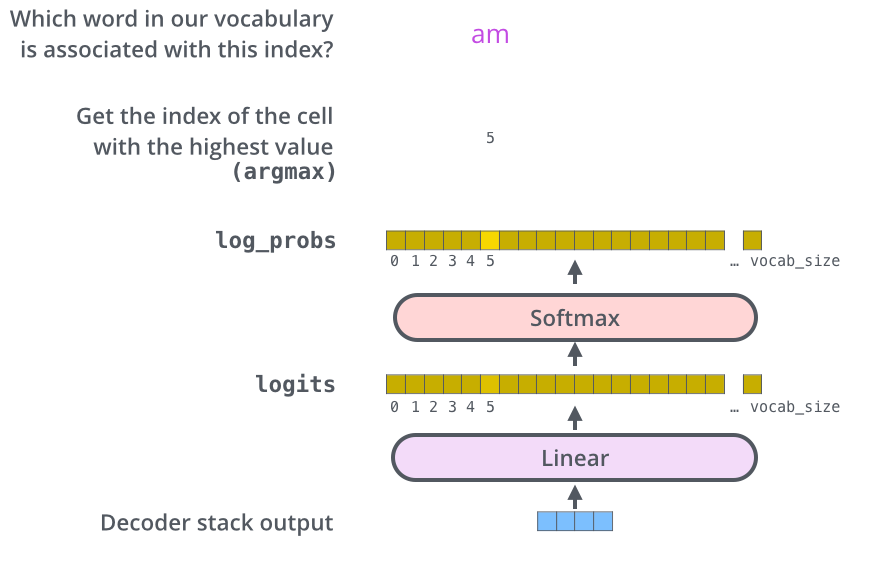
. ? .
– , , , , (logits vector).
10 (« » ), . , 10 000 – . .
( , 1). .
, , .
, , , , .
, . .. , .
, 6 («a», «am», «i», «thanks», «student» «<eos>» (« »).
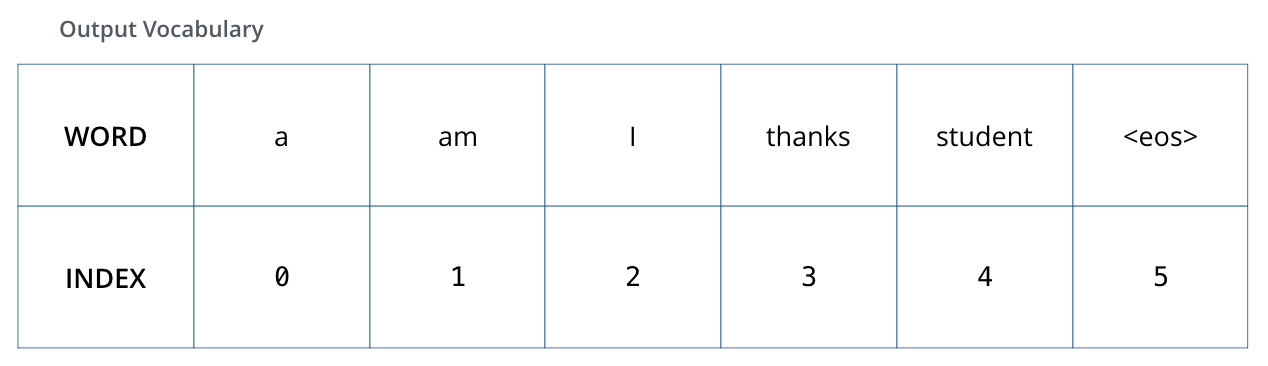
.
, (, one-hot-). , «am», :
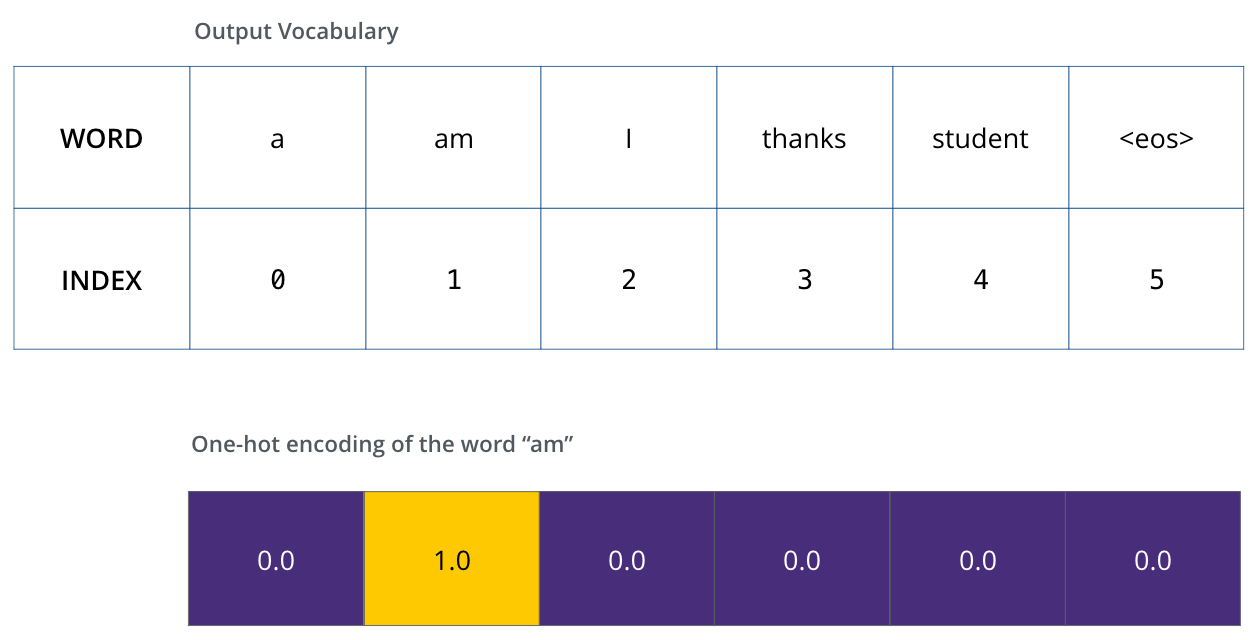
: one-hot- .
(loss function) – , , , .
, . – «merci» «thanks».
, , , «thanks». .. , .
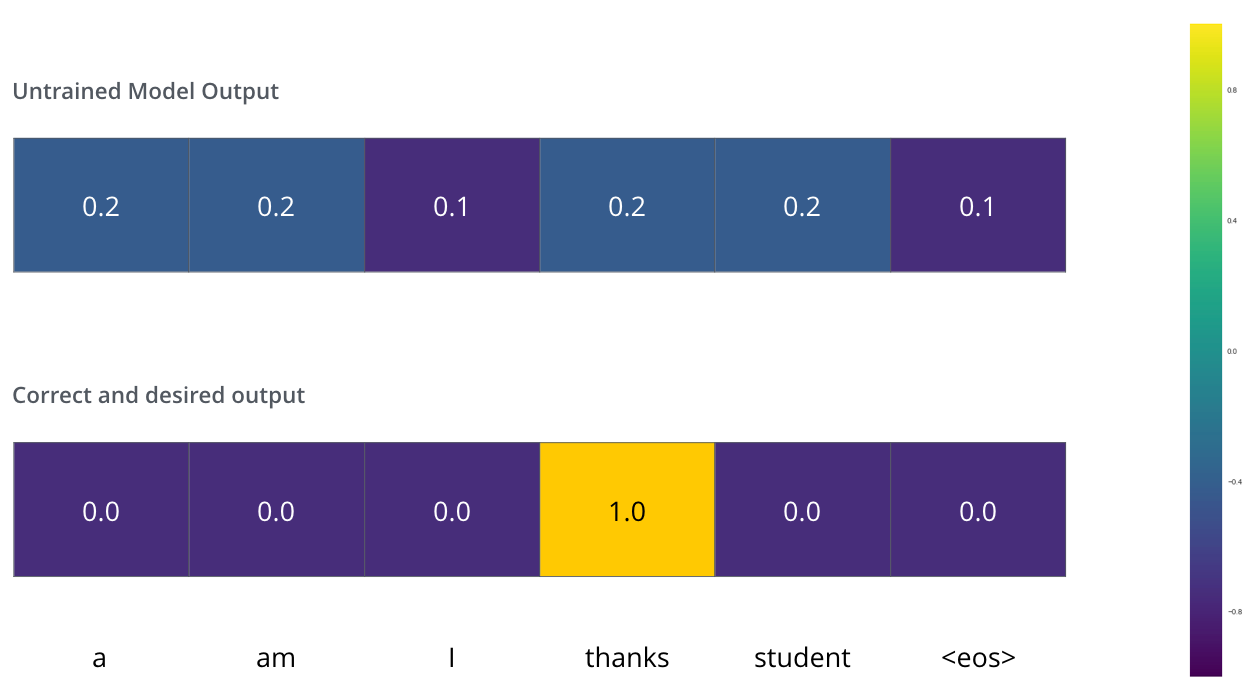
() , /. , , , .
? . , . -.
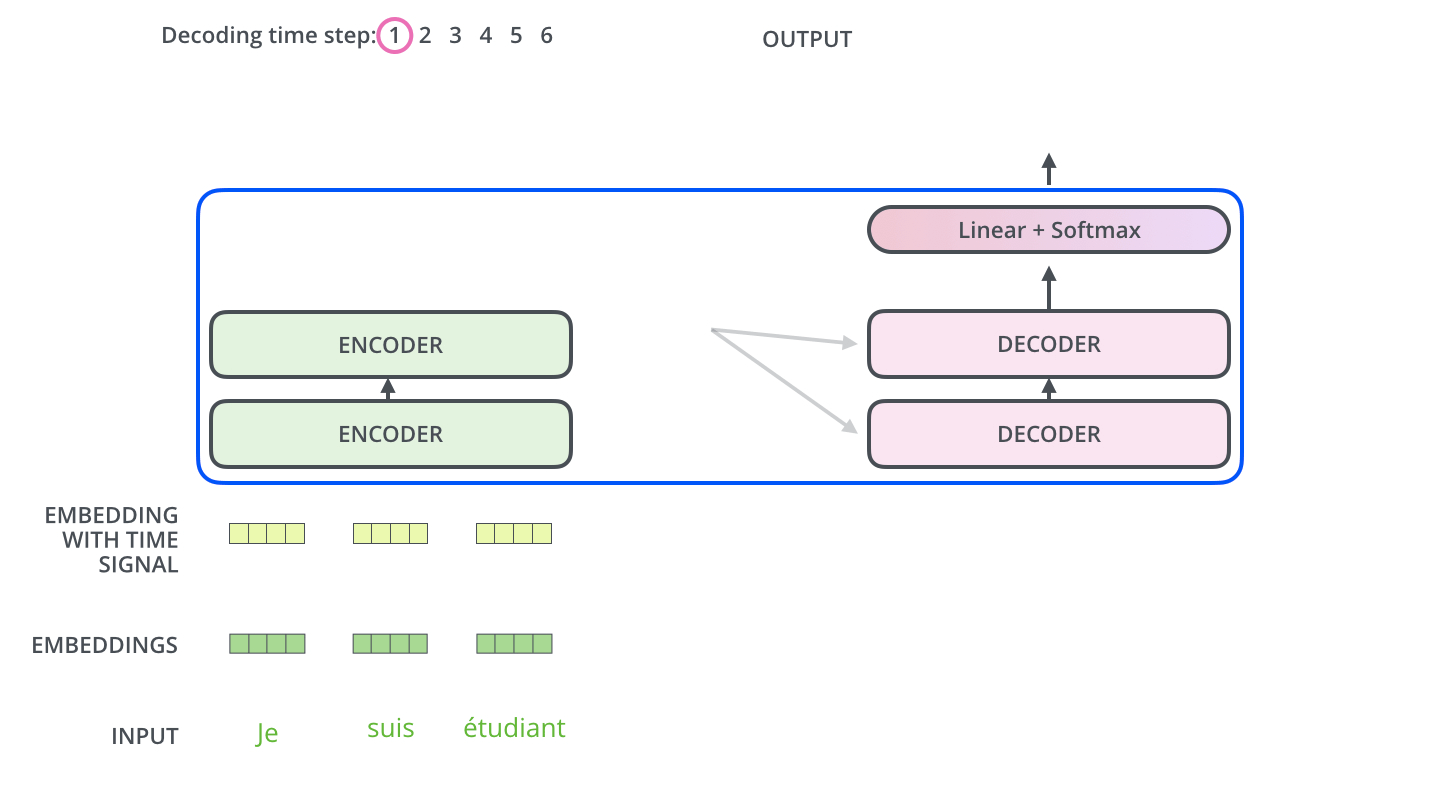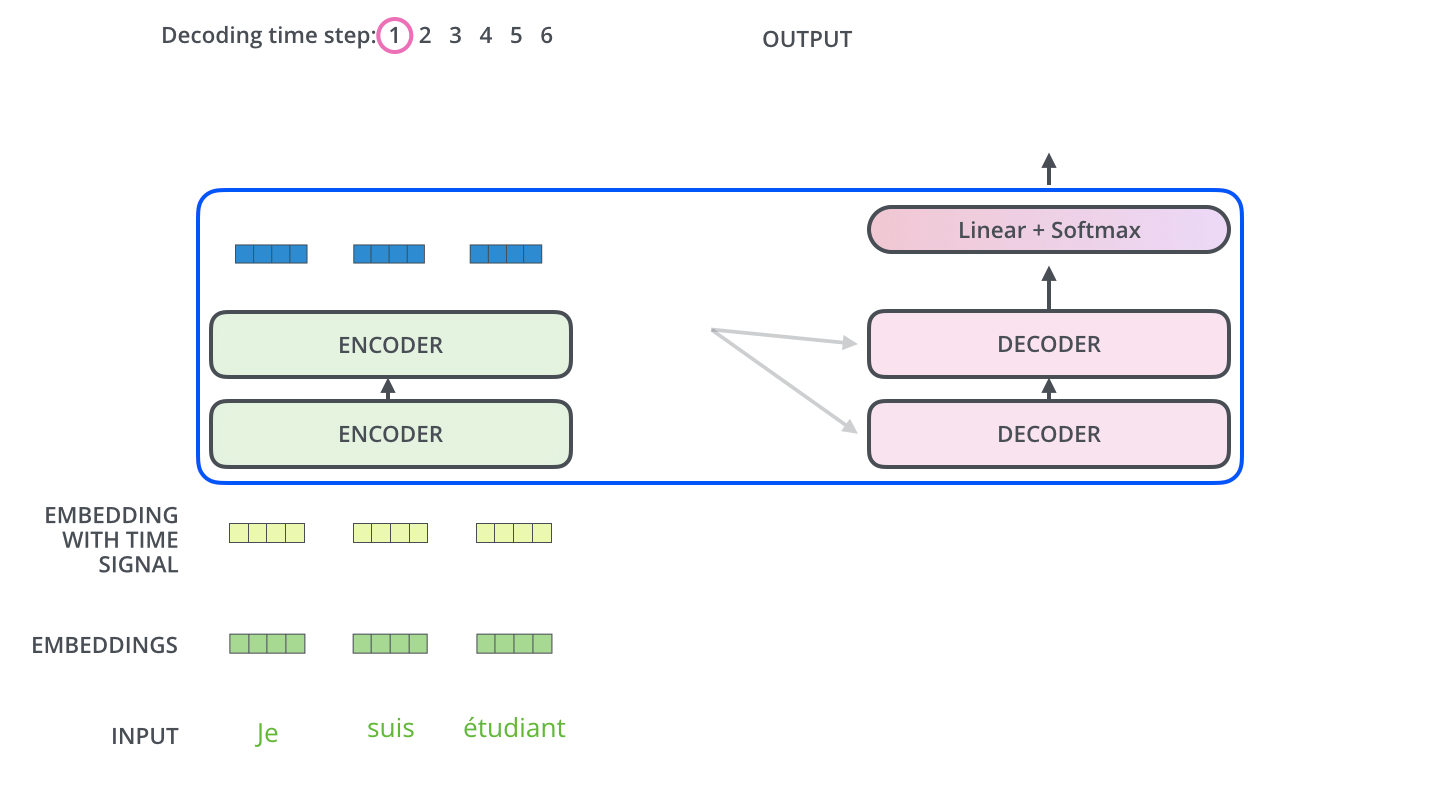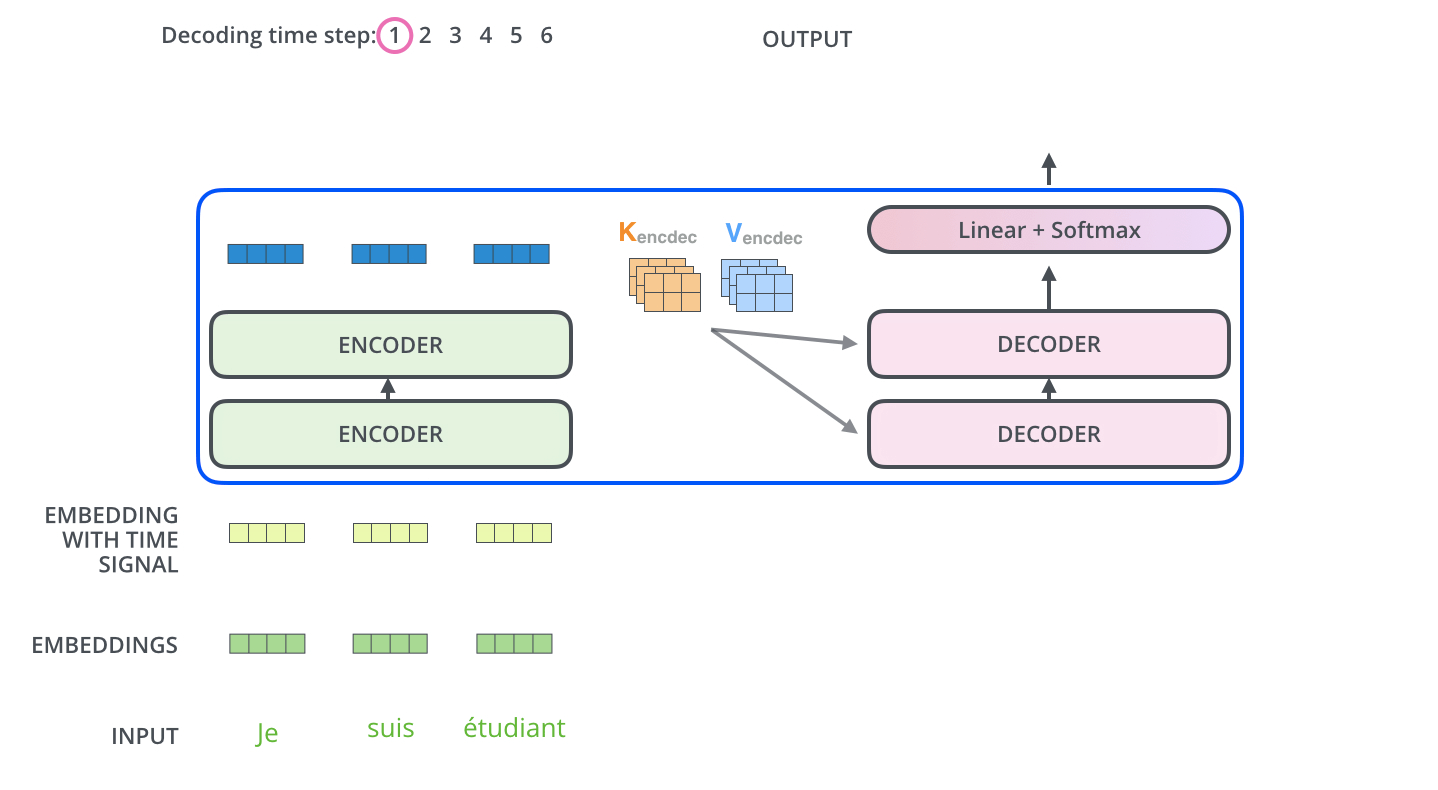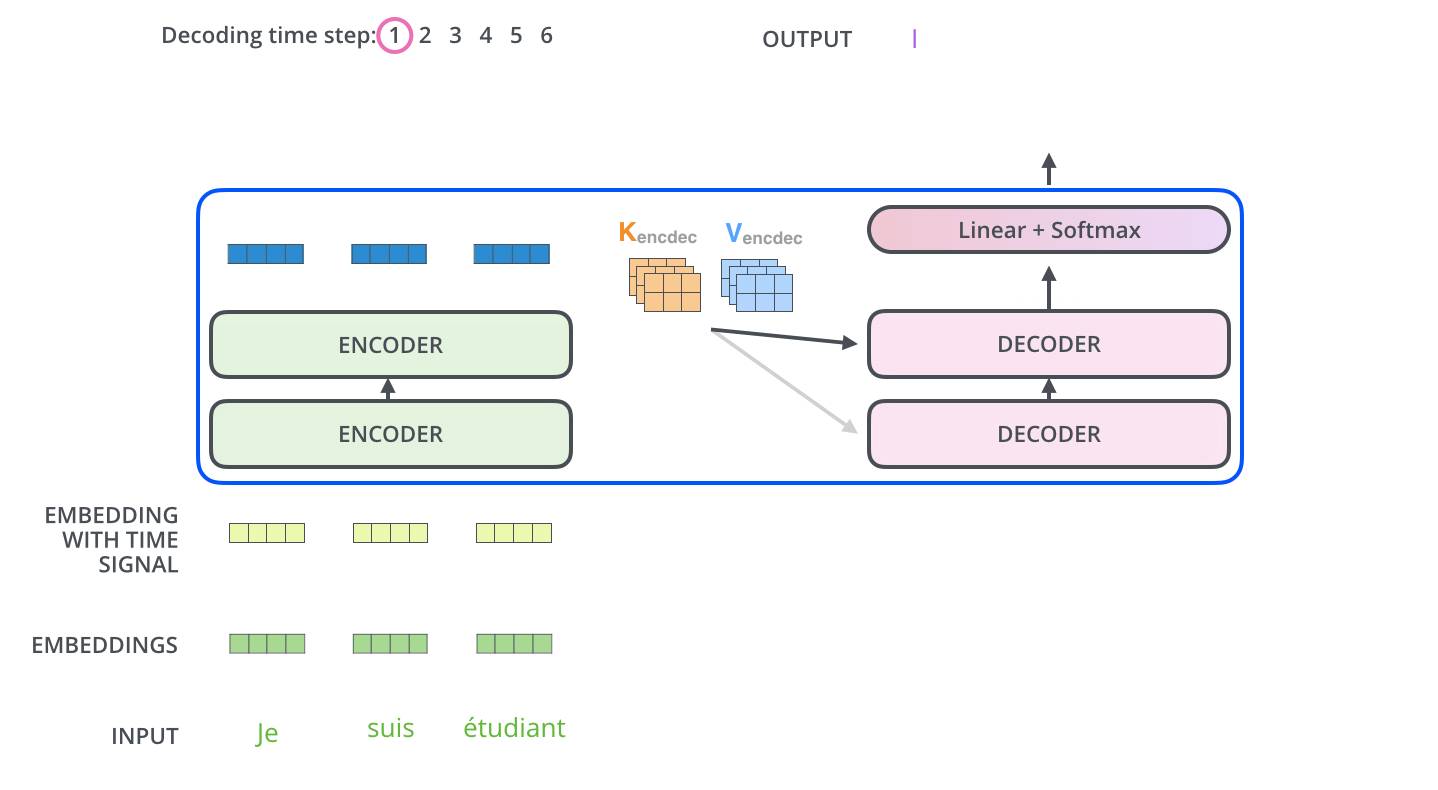
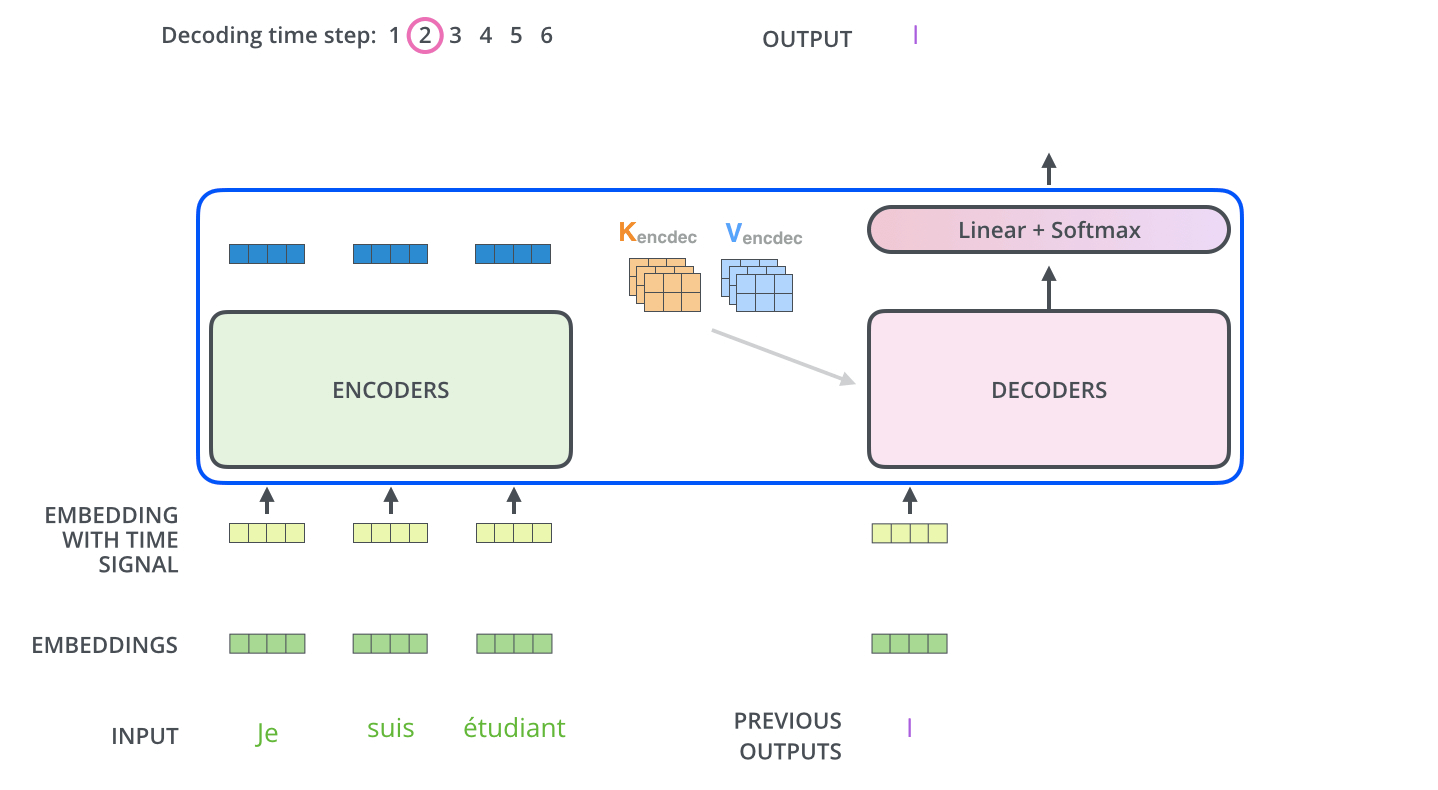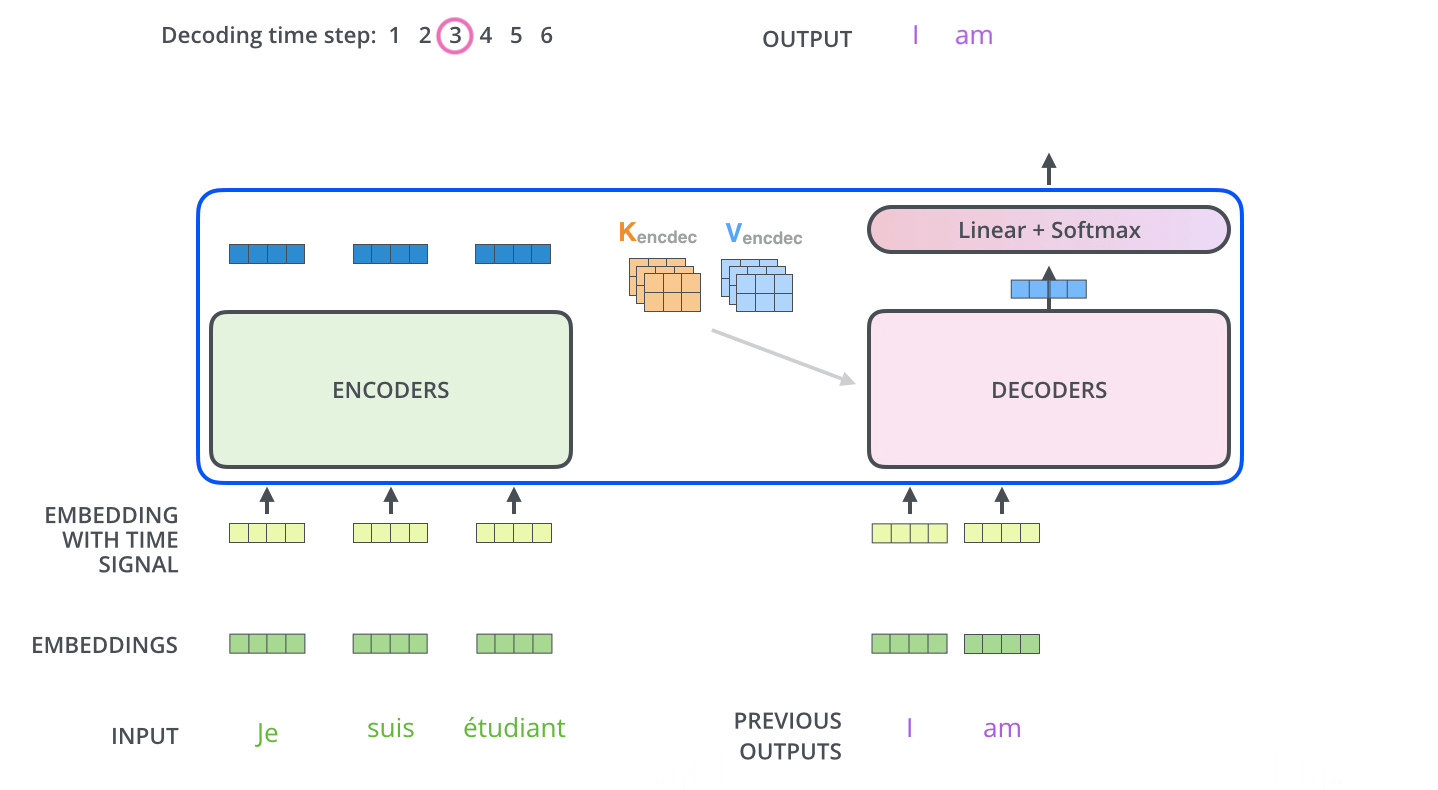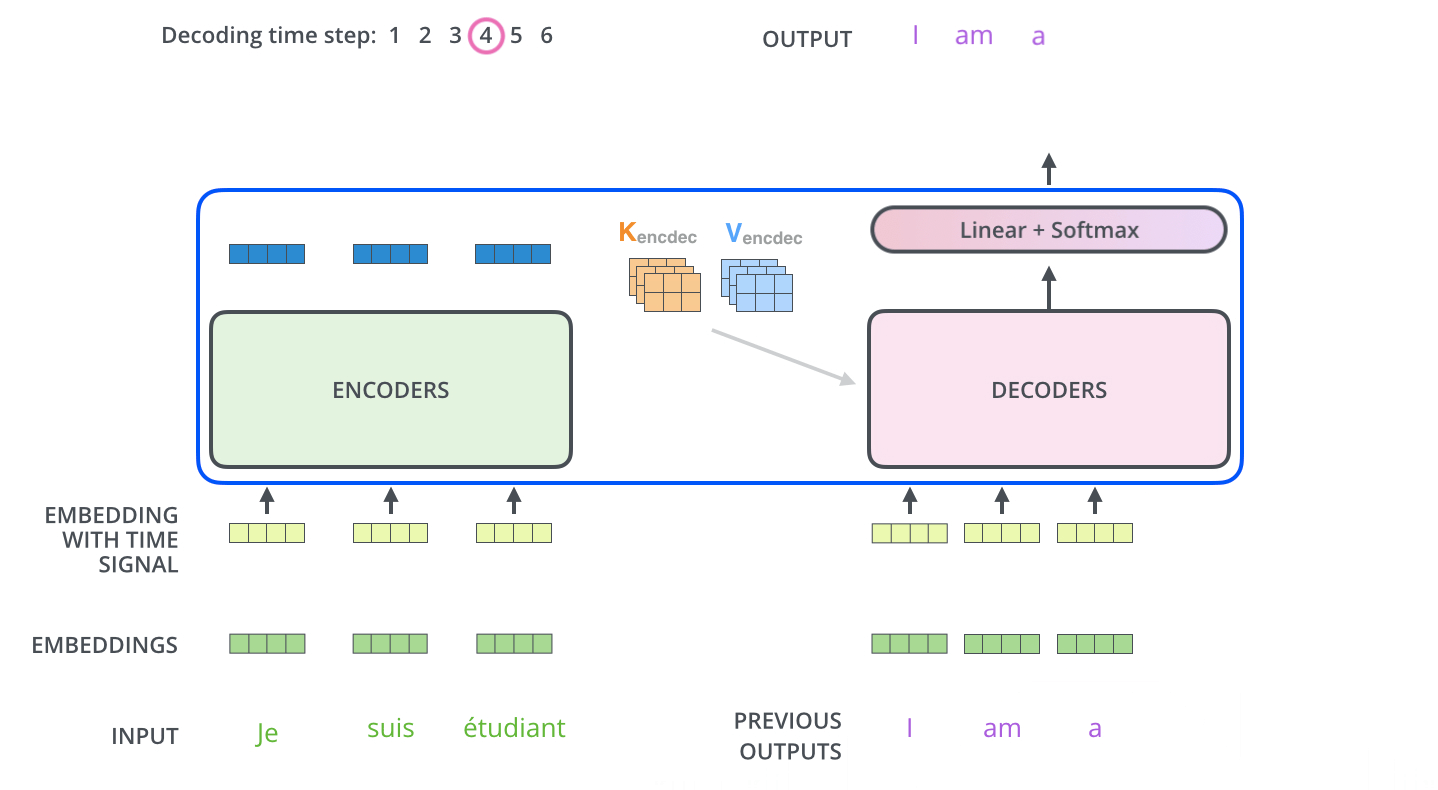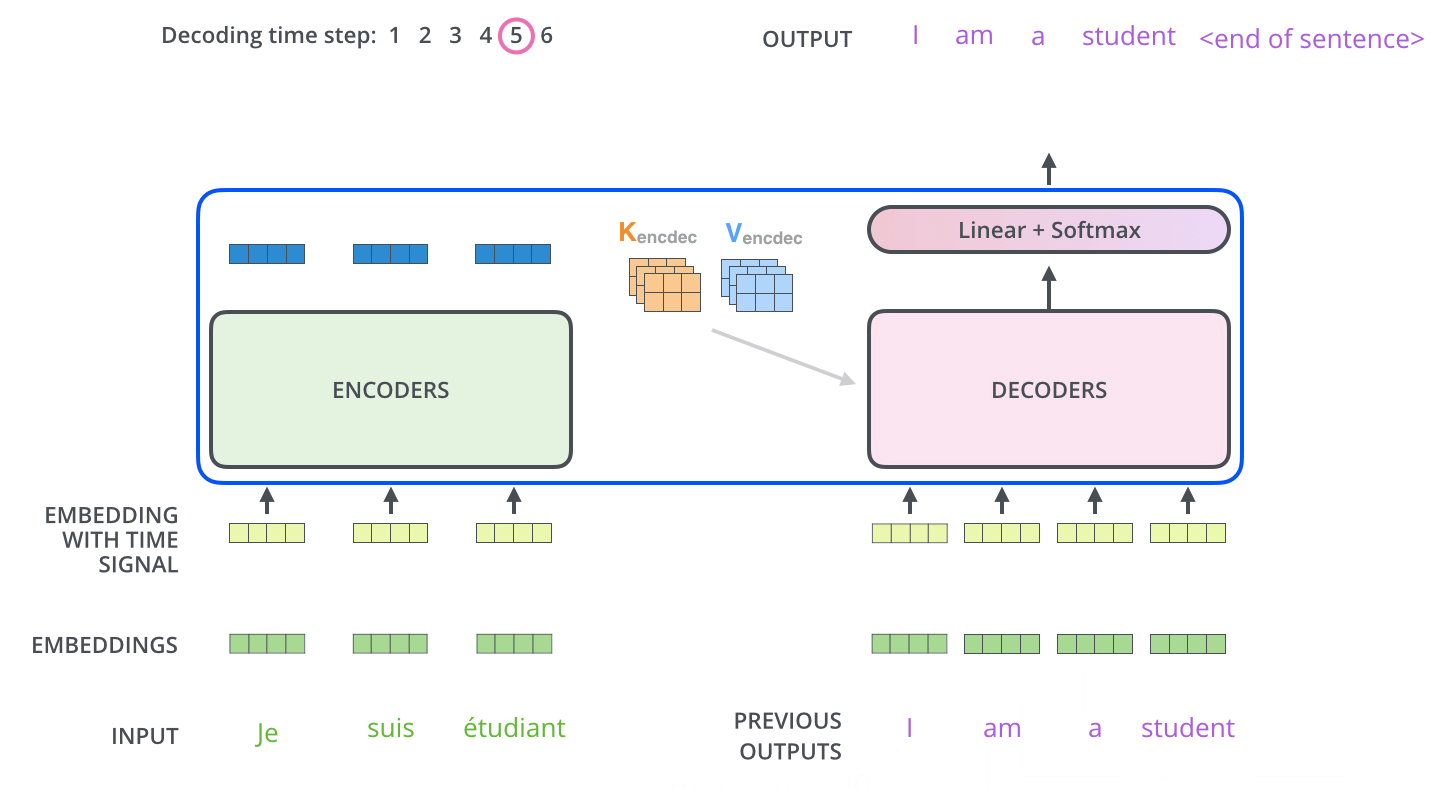
, . . , «je suis étudiant» – «I am a student». , , , :
- (6 , – 3000 10000);
- , «i»;
- , «am»;
- .. , .
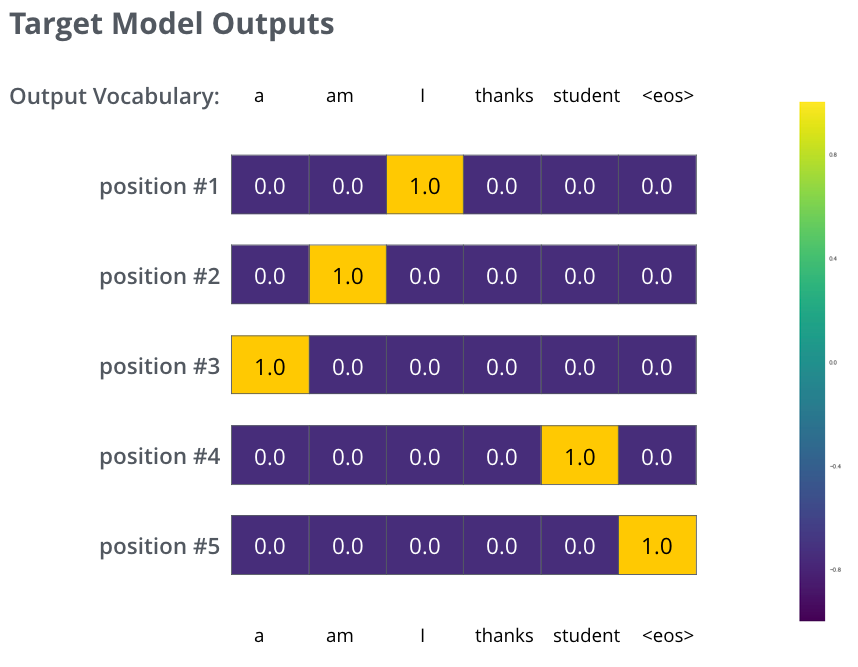
, :
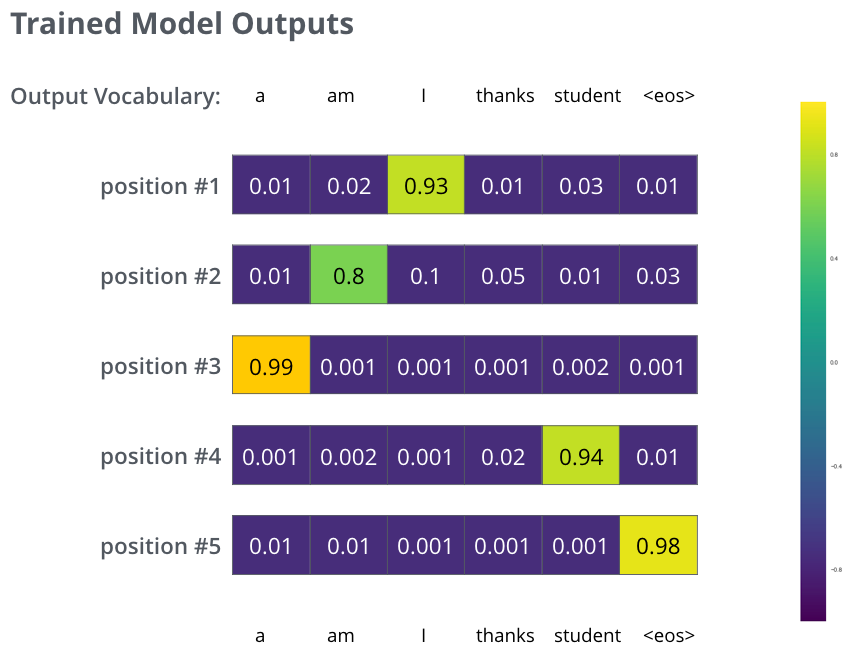
, . , , (.: ). , , , – , .
, , , , . , (greedy decoding). – , , 2 ( , «I» «a») , , : , «I», , , «a». , , . #2 #3 .. « » (beam search). (beam_size) (.. #1 #2), - (top_beams) ( ). .
, . , :
:
Autores