Nuvem catastrófica: como funciona
Olá Habr!Após o feriado de ano novo, reiniciámos uma nuvem resistente a desastres com base em dois sites. Hoje, mostraremos como funciona e mostraremos o que acontece com as máquinas virtuais clientes quando elementos de cluster individuais falham e todo o site cai (spoiler - tudo está bem com eles). Armazenamento em nuvem à prova de desastres no site OST.
Armazenamento em nuvem à prova de desastres no site OST.O que esta dentro
Sob o capô do cluster estão os servidores Cisco UCS com hypervisor VMware ESXi, dois sistemas de armazenamento INFINIDAT InfiniBox F2240, equipamentos de rede Cisco Nexus e comutadores Brocade SAN. O cluster é espaçado em dois sites - OST e NORD, ou seja, em cada data center, um conjunto idêntico de equipamentos. Na verdade, isso o torna catastrófico.Dentro de uma plataforma, os principais elementos também são duplicados (hosts, comutadores SAN, placa de rede).Dois sites são conectados por caminhos de fibra óptica dedicados, também reservados.Algumas palavras sobre armazenamento. A primeira nuvem resistente a desastres que construímos na NetApp. O INFINIDAT foi escolhido aqui e aqui está o porquê:- Opção de replicação ativo-ativo. Ele permite que a máquina virtual permaneça operacional, mesmo que um dos sistemas de armazenamento falhe completamente. Mais adiante, falarei sobre replicação.
- Três controladores de disco para maior resiliência do sistema. Geralmente existem dois.
- Solução pronta. Um rack já montado chegou até nós, que só precisa ser conectado à rede e configurado.
- Suporte técnico atencioso. Os engenheiros do INFINIDAT analisam constantemente logs e eventos de sistemas de armazenamento, instalam novas versões no firmware e ajudam na configuração.
Aqui estão algumas fotos da descompactação:

Como funciona
A nuvem já é resiliente em si mesma. Ele protege o cliente contra falhas únicas de hardware e software. O catastrófico ajudará a proteger contra falhas em massa no mesmo site: por exemplo, falha no sistema de armazenamento (ou cluster SDS, o que ocorre com frequência :)), erros em massa na rede de armazenamento e muito mais. Bem e o mais importante: uma nuvem como essa salva quando um site inteiro fica inacessível devido a incêndio, blecaute, captura de invasores, aterrissagens alienígenas.Em todos esses casos, as máquinas virtuais clientes continuam em execução, e aqui está o porquê.O esquema de cluster foi projetado para que qualquer host ESXi com máquinas virtuais clientes possa acessar um dos dois sistemas de armazenamento. Se o armazenamento no site OST falhar, as máquinas virtuais continuarão funcionando: os hosts nos quais trabalham acessarão o armazenamento na NORD para dados. É assim que o diagrama de conexão no cluster é exibido.Isso é possível devido ao fato de um Link Inter-Switch estar configurado entre as fábricas da SAN dos dois sites: o comutador SAN Fabric A A está conectado ao comutador SAN Fabric A NORD, da mesma forma que os comutadores SAN Fabric B.Bem, para que todos esses meandros das fábricas de SAN façam sentido, a replicação Active-Active é configurada entre os dois sistemas de armazenamento: as informações são gravadas quase simultaneamente nos sistemas de armazenamento local e remoto, RPO = 0. Acontece que em um SHD os dados originais são armazenados, por outro - sua réplica. Os dados são replicados no nível do volume de armazenamento e os dados da VM (seus discos, arquivo de configuração, arquivo de troca etc.) já estão armazenados neles.O host ESXi vê o volume primário e sua réplica como um único dispositivo de armazenamento. Existem 24 caminhos do host ESXi para cada dispositivo de disco:12 caminhos o associam ao armazenamento local (caminhos ideais) e os 12 restantes - ao remoto (caminhos não ideais). Em uma situação normal, o ESXi acessa dados no armazenamento local usando caminhos "ideais". Se esse sistema de armazenamento falhar, o ESXi perderá os caminhos ideais e alternará para os caminhos "não ideais". Veja como fica no diagrama.
É assim que o diagrama de conexão no cluster é exibido.Isso é possível devido ao fato de um Link Inter-Switch estar configurado entre as fábricas da SAN dos dois sites: o comutador SAN Fabric A A está conectado ao comutador SAN Fabric A NORD, da mesma forma que os comutadores SAN Fabric B.Bem, para que todos esses meandros das fábricas de SAN façam sentido, a replicação Active-Active é configurada entre os dois sistemas de armazenamento: as informações são gravadas quase simultaneamente nos sistemas de armazenamento local e remoto, RPO = 0. Acontece que em um SHD os dados originais são armazenados, por outro - sua réplica. Os dados são replicados no nível do volume de armazenamento e os dados da VM (seus discos, arquivo de configuração, arquivo de troca etc.) já estão armazenados neles.O host ESXi vê o volume primário e sua réplica como um único dispositivo de armazenamento. Existem 24 caminhos do host ESXi para cada dispositivo de disco:12 caminhos o associam ao armazenamento local (caminhos ideais) e os 12 restantes - ao remoto (caminhos não ideais). Em uma situação normal, o ESXi acessa dados no armazenamento local usando caminhos "ideais". Se esse sistema de armazenamento falhar, o ESXi perderá os caminhos ideais e alternará para os caminhos "não ideais". Veja como fica no diagrama. O esquema de um cluster resistente a desastres.Todas as redes de clientes são estabelecidas nos dois sites por meio de uma fábrica de rede comum. O Provider Edge (PE) é executado em cada site, no qual as redes do cliente são encerradas. Os PEs são combinados em um único cluster. Se o PE falhar em um site, todo o tráfego será redirecionado para o segundo site. Graças a isso, as máquinas virtuais do site sem PE permanecem disponíveis na rede para o cliente.Vamos agora ver o que acontecerá com as máquinas virtuais clientes em caso de várias falhas. Vamos começar com as opções mais leves e terminar com as mais graves - a falha de todo o site. Nos exemplos, o site principal será OST e o backup, com réplicas de dados, será NORD.
O esquema de um cluster resistente a desastres.Todas as redes de clientes são estabelecidas nos dois sites por meio de uma fábrica de rede comum. O Provider Edge (PE) é executado em cada site, no qual as redes do cliente são encerradas. Os PEs são combinados em um único cluster. Se o PE falhar em um site, todo o tráfego será redirecionado para o segundo site. Graças a isso, as máquinas virtuais do site sem PE permanecem disponíveis na rede para o cliente.Vamos agora ver o que acontecerá com as máquinas virtuais clientes em caso de várias falhas. Vamos começar com as opções mais leves e terminar com as mais graves - a falha de todo o site. Nos exemplos, o site principal será OST e o backup, com réplicas de dados, será NORD.O que acontece com uma máquina virtual cliente se ...
Falha no link de replicação. A replicação entre os sistemas de armazenamento dos dois sites é interrompida.O ESXi funcionará apenas com dispositivos de disco local (nos caminhos ideais).Máquinas virtuais continuam funcionando. Existe uma lacuna ISL (Inter-Switch Link). O caso é improvável. A menos que uma escavadeira louca desenterre várias rotas ópticas ao mesmo tempo, que passam por rotas independentes e são levadas aos locais por diferentes entradas. Mas mesmo assim. Nesse caso, os hosts ESXi perdem metade de seus caminhos e podem acessar apenas o armazenamento local. As réplicas são coletadas, mas os hosts não poderão acessá-las.Máquinas virtuais funcionam normalmente.
Existe uma lacuna ISL (Inter-Switch Link). O caso é improvável. A menos que uma escavadeira louca desenterre várias rotas ópticas ao mesmo tempo, que passam por rotas independentes e são levadas aos locais por diferentes entradas. Mas mesmo assim. Nesse caso, os hosts ESXi perdem metade de seus caminhos e podem acessar apenas o armazenamento local. As réplicas são coletadas, mas os hosts não poderão acessá-las.Máquinas virtuais funcionam normalmente. Recusa um switch SAN em um dos sites.Os hosts ESXi perdem alguns de seus caminhos de armazenamento. Nesse caso, os hosts no site em que o comutador falhou funcionarão apenas através de seu próprio HBA.Ao mesmo tempo, as máquinas virtuais continuam funcionando normalmente.
Recusa um switch SAN em um dos sites.Os hosts ESXi perdem alguns de seus caminhos de armazenamento. Nesse caso, os hosts no site em que o comutador falhou funcionarão apenas através de seu próprio HBA.Ao mesmo tempo, as máquinas virtuais continuam funcionando normalmente. Todos os comutadores SAN em um dos sites falham. Digamos que esse desastre aconteceu no site da OST. Nesse caso, os hosts ESXi neste site perderão todos os caminhos para seus dispositivos de disco. O mecanismo padrão do VMware vSphere HA entra em ação: ele reiniciará todas as máquinas virtuais da plataforma OST na NORD após um máximo de 140 segundos.Máquinas virtuais em execução nos hosts do site NORD funcionam normalmente.
Todos os comutadores SAN em um dos sites falham. Digamos que esse desastre aconteceu no site da OST. Nesse caso, os hosts ESXi neste site perderão todos os caminhos para seus dispositivos de disco. O mecanismo padrão do VMware vSphere HA entra em ação: ele reiniciará todas as máquinas virtuais da plataforma OST na NORD após um máximo de 140 segundos.Máquinas virtuais em execução nos hosts do site NORD funcionam normalmente.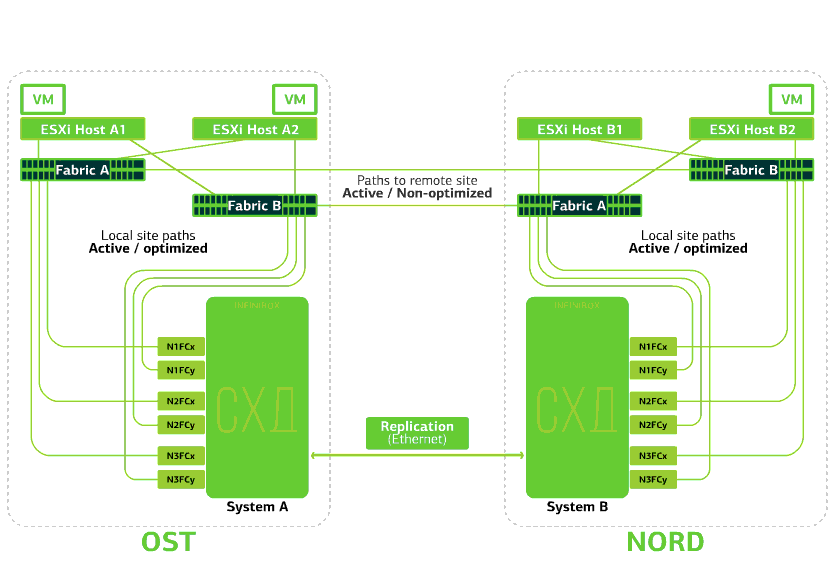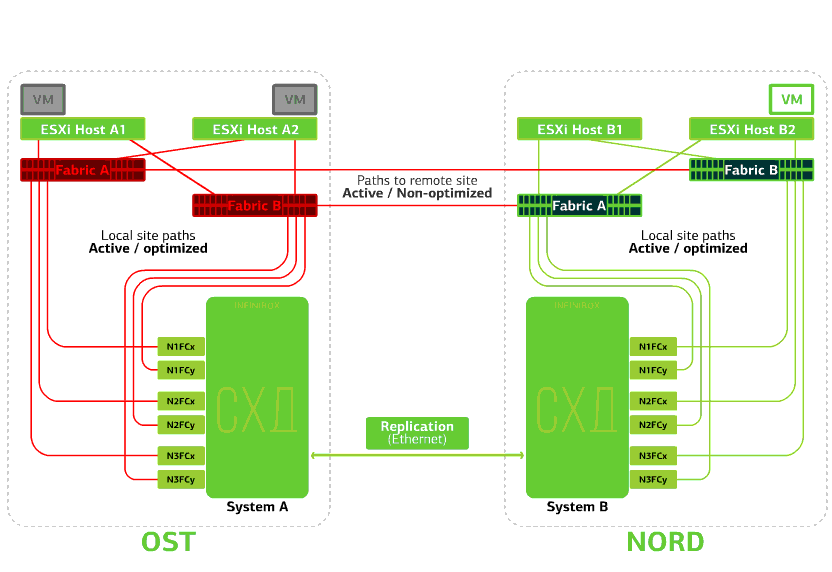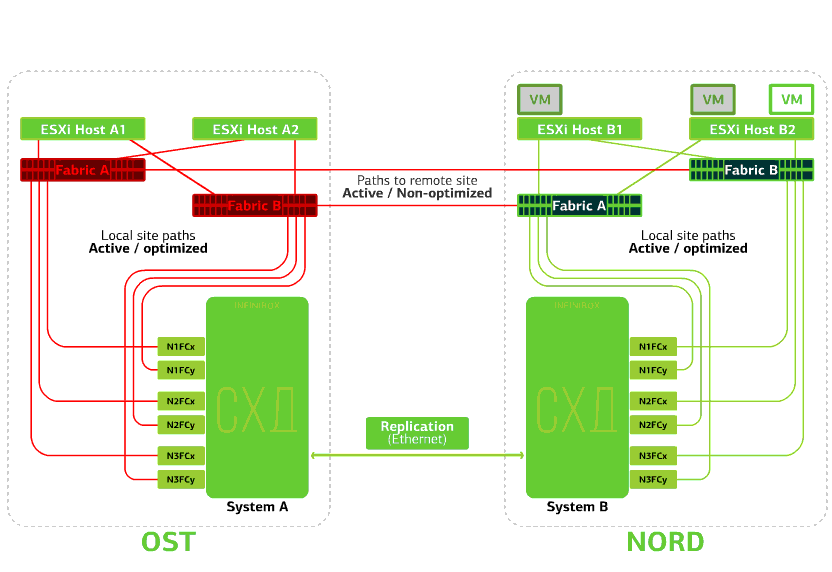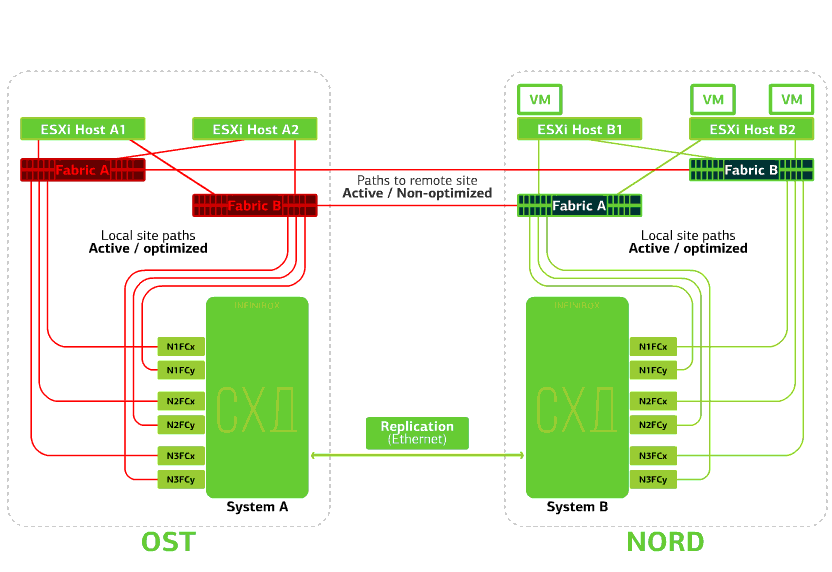 Recusa o host ESXi em um site.Aqui, o mecanismo do vSphere HA funciona novamente: máquinas virtuais de um host com falha são reiniciadas em outros hosts - no mesmo site ou em local remoto. O tempo de reinicialização da máquina virtual é de até 1 minuto.Se todos os hosts ESXi da plataforma OST falharem, não há opções: as VMs são reiniciadas em outra. O tempo de reinicialização é o mesmo.
Recusa o host ESXi em um site.Aqui, o mecanismo do vSphere HA funciona novamente: máquinas virtuais de um host com falha são reiniciadas em outros hosts - no mesmo site ou em local remoto. O tempo de reinicialização da máquina virtual é de até 1 minuto.Se todos os hosts ESXi da plataforma OST falharem, não há opções: as VMs são reiniciadas em outra. O tempo de reinicialização é o mesmo.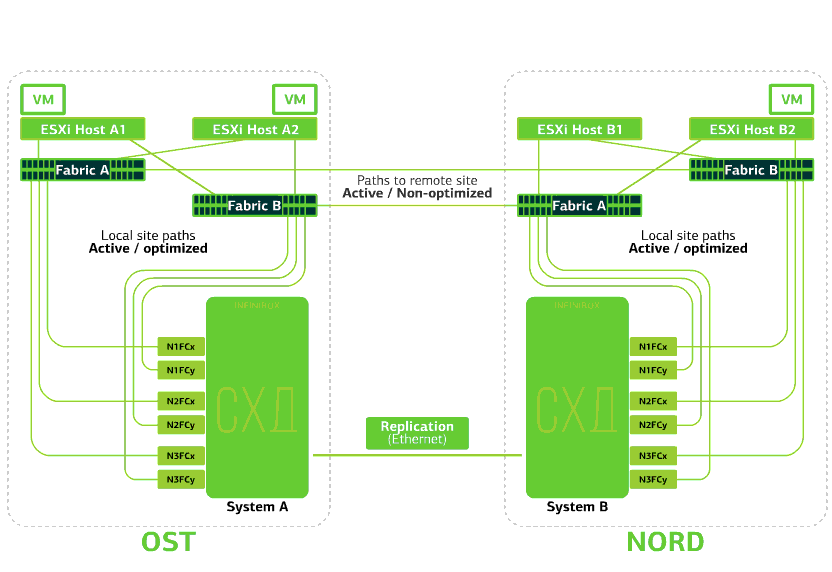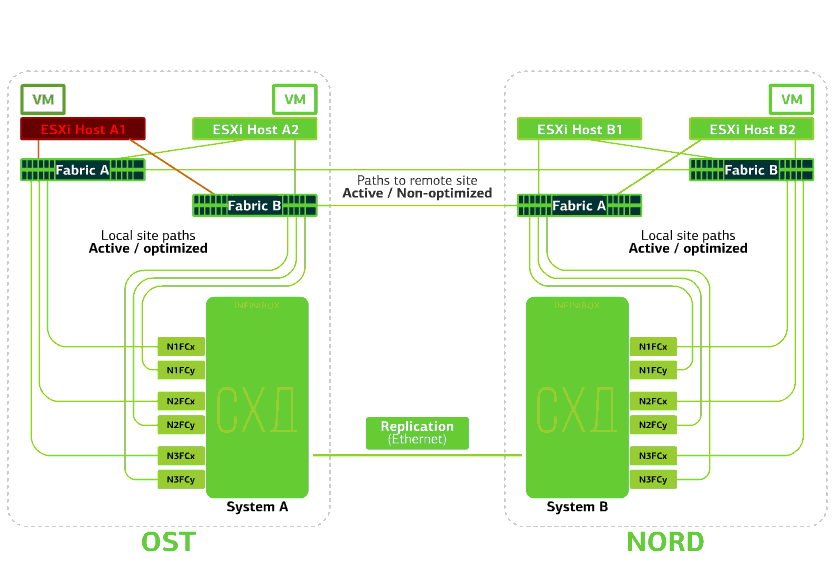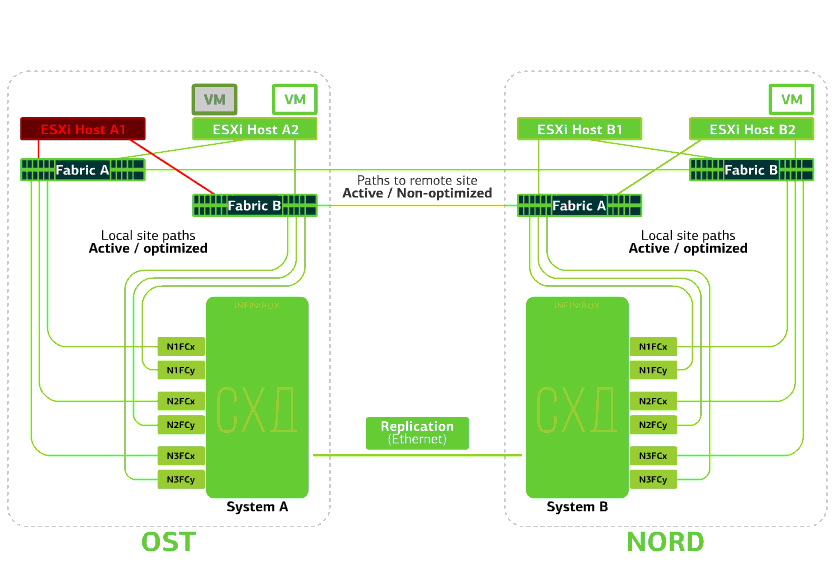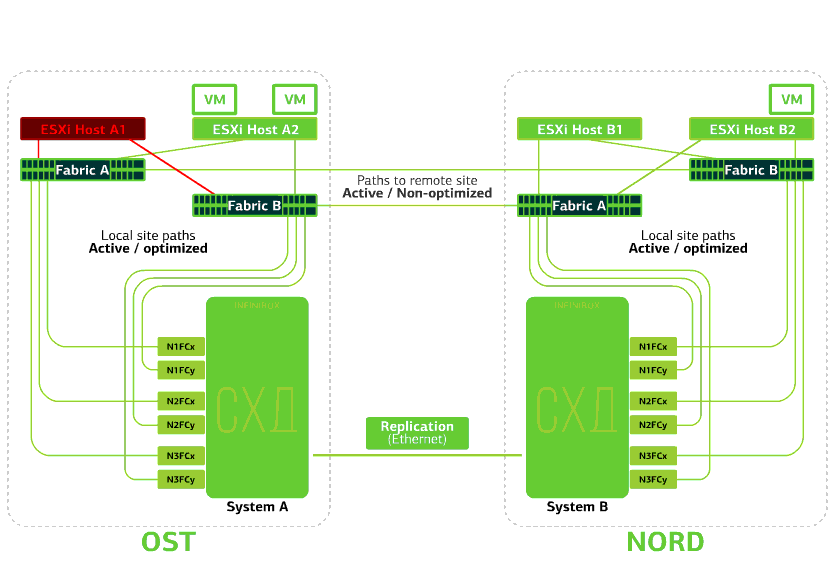 Recusa o armazenamento no mesmo site. Digamos que o sistema de armazenamento tenha sido recusado no site OST. Em seguida, os hosts OST ESXi alternam para trabalhar com réplicas de armazenamento no NORD. Depois que o sistema de armazenamento com falha retornar ao sistema, a replicação forçada ocorrerá, os hosts do OST ESXi voltarão a entrar em contato com o sistema de armazenamento local.Máquinas virtuais estão trabalhando esse tempo todo.
Recusa o armazenamento no mesmo site. Digamos que o sistema de armazenamento tenha sido recusado no site OST. Em seguida, os hosts OST ESXi alternam para trabalhar com réplicas de armazenamento no NORD. Depois que o sistema de armazenamento com falha retornar ao sistema, a replicação forçada ocorrerá, os hosts do OST ESXi voltarão a entrar em contato com o sistema de armazenamento local.Máquinas virtuais estão trabalhando esse tempo todo. Falha em um dos sites.Nesse caso, todas as máquinas virtuais serão reiniciadas no site de backup através do mecanismo vSphere HA. Tempo de reinicialização da VM - 140 segundos. Nesse caso, todas as configurações de rede da máquina virtual serão salvas e permanecerão disponíveis para o cliente pela rede.Para reiniciar as máquinas no site de backup sem problemas, cada site está apenas meio cheio. A segunda metade é a reserva, caso todas as máquinas virtuais sejam movidas do segundo local danificado.
Falha em um dos sites.Nesse caso, todas as máquinas virtuais serão reiniciadas no site de backup através do mecanismo vSphere HA. Tempo de reinicialização da VM - 140 segundos. Nesse caso, todas as configurações de rede da máquina virtual serão salvas e permanecerão disponíveis para o cliente pela rede.Para reiniciar as máquinas no site de backup sem problemas, cada site está apenas meio cheio. A segunda metade é a reserva, caso todas as máquinas virtuais sejam movidas do segundo local danificado.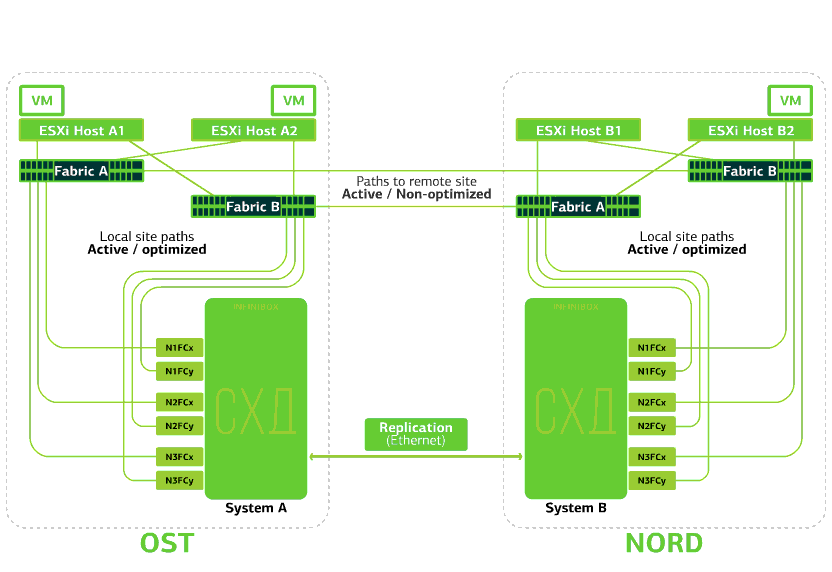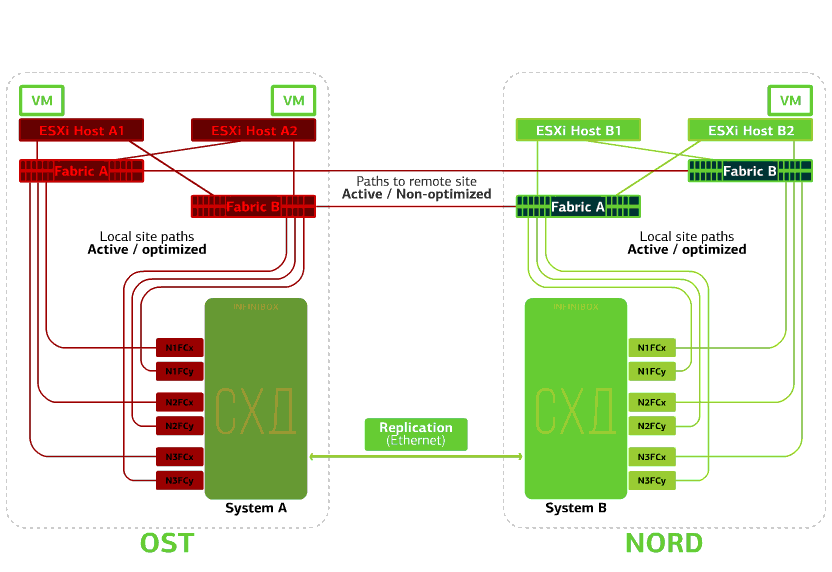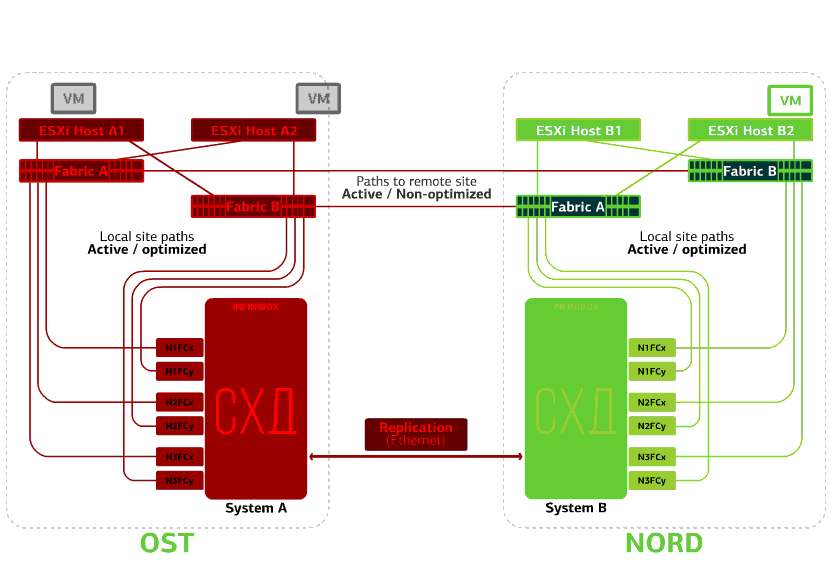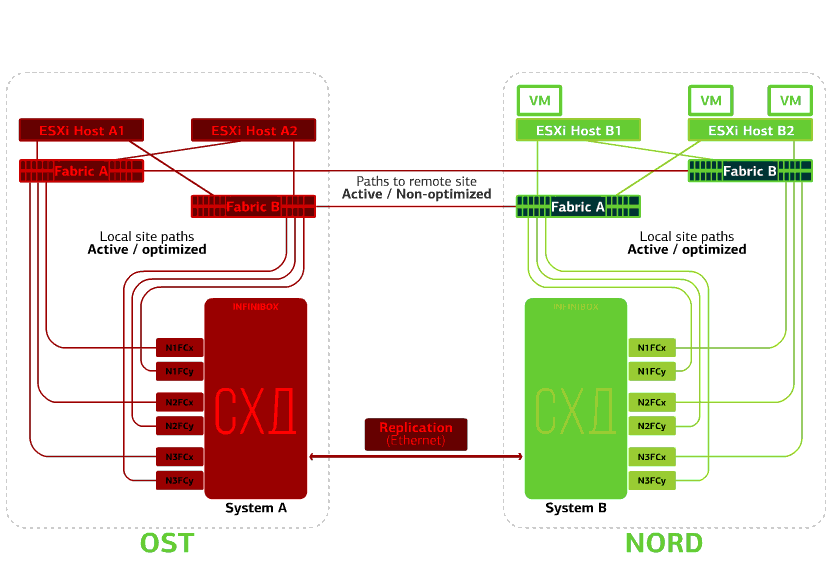 Uma nuvem à prova de desastres baseada em dois data centers protege contra essas falhas.Esse prazer não é barato, porque, além dos principais recursos, você precisa de uma reserva no segundo site. Portanto, eles colocam serviços essenciais aos negócios nessa nuvem, cujo longo tempo de inatividade acarreta grandes perdas financeiras e de reputação, ou se requisitos de tolerância a desastres forem impostos ao sistema de informações pelos reguladores ou pelos regulamentos internos da empresa.Fontes:
Uma nuvem à prova de desastres baseada em dois data centers protege contra essas falhas.Esse prazer não é barato, porque, além dos principais recursos, você precisa de uma reserva no segundo site. Portanto, eles colocam serviços essenciais aos negócios nessa nuvem, cujo longo tempo de inatividade acarreta grandes perdas financeiras e de reputação, ou se requisitos de tolerância a desastres forem impostos ao sistema de informações pelos reguladores ou pelos regulamentos internos da empresa.Fontes:- www.infinidat.com/sites/default/files/resource-pdfs/DS-INFBOX-190331-US_0.pdf
- support.infinidat.com/hc/pt-br/articles/207057109-InfiniBox-best-practices-guides
Source: https://habr.com/ru/post/undefined/
All Articles