NiFiはますます人気を得ており、新しいリリースごとにデータを操作するためのツールが増えています。それでも、特定の問題を解決するには独自のツールが必要になる場合があります。
Apache Nifiのベースパッケージには300を超えるプロセッサが搭載されています。Nifiプロセッサー これは、NiFiエコシステムでデータフローを作成するための主要なビルディングブロックです。プロセッサーは、NiFiがフローファイル、その属性、およびコンテンツへのアクセスを提供するインターフェースを提供します。独自のカスタムプロセッサを使用すると、多くの単純なプロセッサエレメントの代わりに1つだけがインターフェイスに表示され、1つだけが実行されるので、電力、時間、およびユーザーの注意を節約できます(まあ、または書き込む量)。標準プロセッサと同様に、カスタムプロセッサを使用すると、さまざまな操作を実行し、フローファイルの内容を処理できます。今日は、機能を拡張するための標準ツールについてお話します。
これは、NiFiエコシステムでデータフローを作成するための主要なビルディングブロックです。プロセッサーは、NiFiがフローファイル、その属性、およびコンテンツへのアクセスを提供するインターフェースを提供します。独自のカスタムプロセッサを使用すると、多くの単純なプロセッサエレメントの代わりに1つだけがインターフェイスに表示され、1つだけが実行されるので、電力、時間、およびユーザーの注意を節約できます(まあ、または書き込む量)。標準プロセッサと同様に、カスタムプロセッサを使用すると、さまざまな操作を実行し、フローファイルの内容を処理できます。今日は、機能を拡張するための標準ツールについてお話します。ExecuteScript
ExecuteScriptは、プログラミング言語(Groovy、Jython、Javascript、JRuby)でビジネスロジックを実装するように設計されたユニバーサルプロセッサです。このアプローチにより、目的の機能をすばやく取得できます。スクリプト内のNiFiコンポーネントへのアクセスを提供するには、以下の変数を使用することが可能である:セッション:タイプorg.apache.nifi.processor.ProcessSessionの変数。この変数を使用すると、create()、putAttribute()、Transfer()、read()、write()などの操作をフローファイルで実行できます。コンテキスト:org.apache.nifi.processor.ProcessContext。プロセッサのプロパティ、関係、コントローラサービス、およびStateManagerを取得するために使用できます。REL_SUCCESS:関係「成功」。REL_FAILURE:失敗の関係動的プロパティ:ExecuteScriptで定義された動的プロパティは、変数としてスクリプトエンジンに渡され、PropertyValueとして設定されます。これにより、プロパティの値を取得し、その値を適切なデータ型(論理など)に変換できます。使用するには、スクリプトまたはスクリプト自体でScript Engineファイルの場所を選択して指定します。
いくつかの例を見てみましょう:
キューから1つのストリームファイルを取得します。Script File Script Body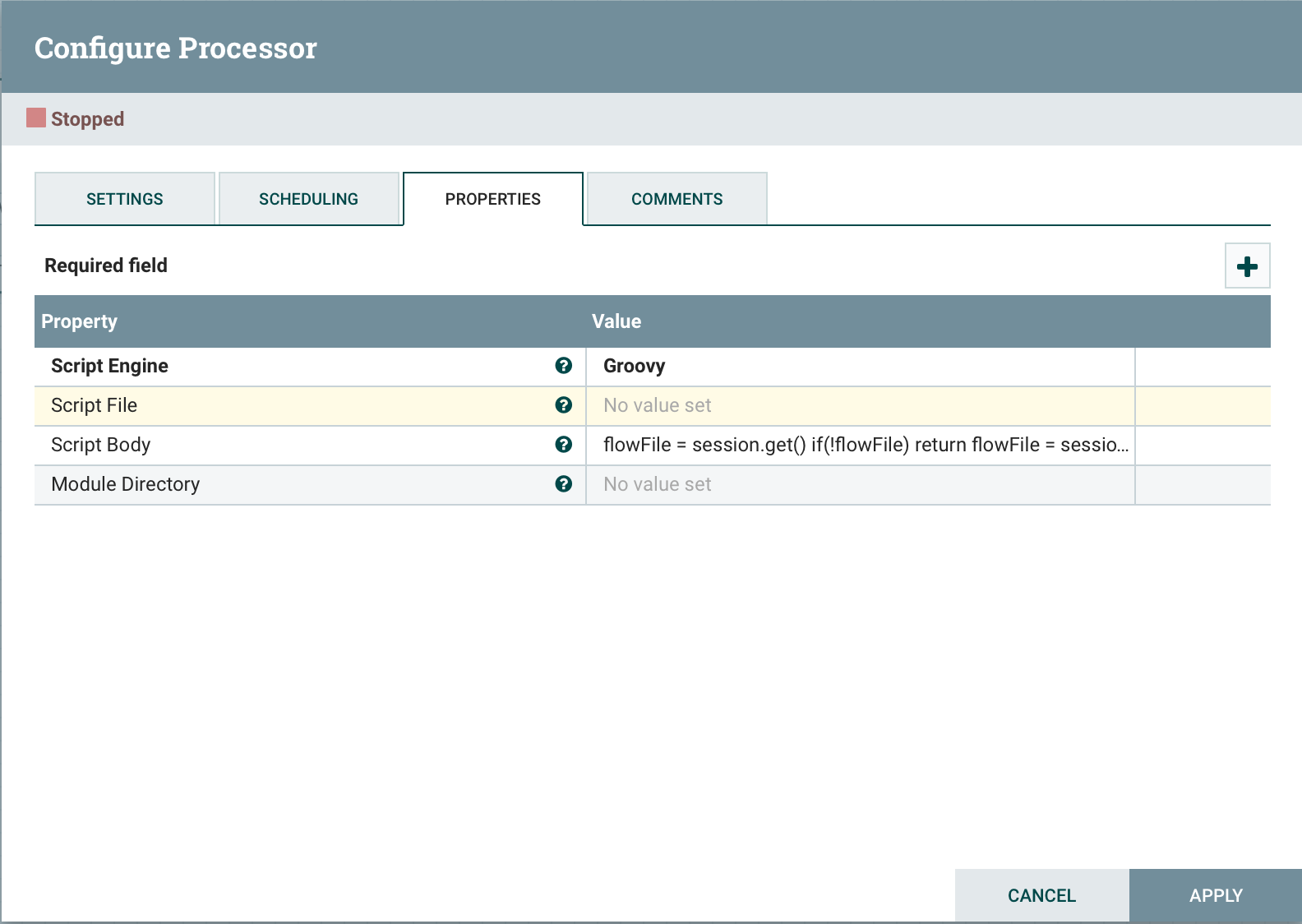
flowFile = session.get()
if(!flowFile) return
新しいFlowFileを生成するflowFile = session.create()
// Additional processing here
FlowFileに属性を追加flowFile = session.get()
if(!flowFile) return
flowFile = session.putAttribute(flowFile, 'myAttr', 'myValue')
すべての属性を抽出して処理します。flowFile = session.get() if(!flowFile) return
flowFile.getAttributes().each { key,value ->
// Do something with the key/value pair
}
ロガーlog.info('Found these things: {} {} {}', ['Hello',1,true] as Object[])
ExecuteScriptの高度な機能を使用できます。詳細については、記事ExecuteScript Cookbookを参照してください。ExecuteGroovyScript
ExecuteGroovyScriptの機能はExecuteScriptと同じですが、有効な言語の動物園の代わりに、1つしか使用できません-groovy。このプロセッサの主な利点は、サービスサービスをより便利に使用できることです。変数の標準セットに加えて、セッション、コンテキストなどCTLおよびSQL接頭辞を使用して動的プロパティを定義できます。バージョン1.11以降、RecordReaderおよびRecord Writerのサポートが登場しました。すべてのプロパティは「サービス名」をキーとして使用するHashMapであり、値はプロパティに応じて特定のオブジェクトです。RecordWriter HashMap<String,RecordSetWriterFactory>
RecordReader HashMap<String,RecordReaderFactory>
SQL HashMap<String,groovy.sql.Sql>
CTL HashMap<String,ControllerService>
この情報はすでに生活を楽にしている。ソースを調べたり、特定のクラスのドキュメントを見つけることができます。データベースの操作SQL.DBプロパティを定義してDBCPServiceをバインドすると、コードからプロパティにアクセスし、SQL.DB.rows('select * from table')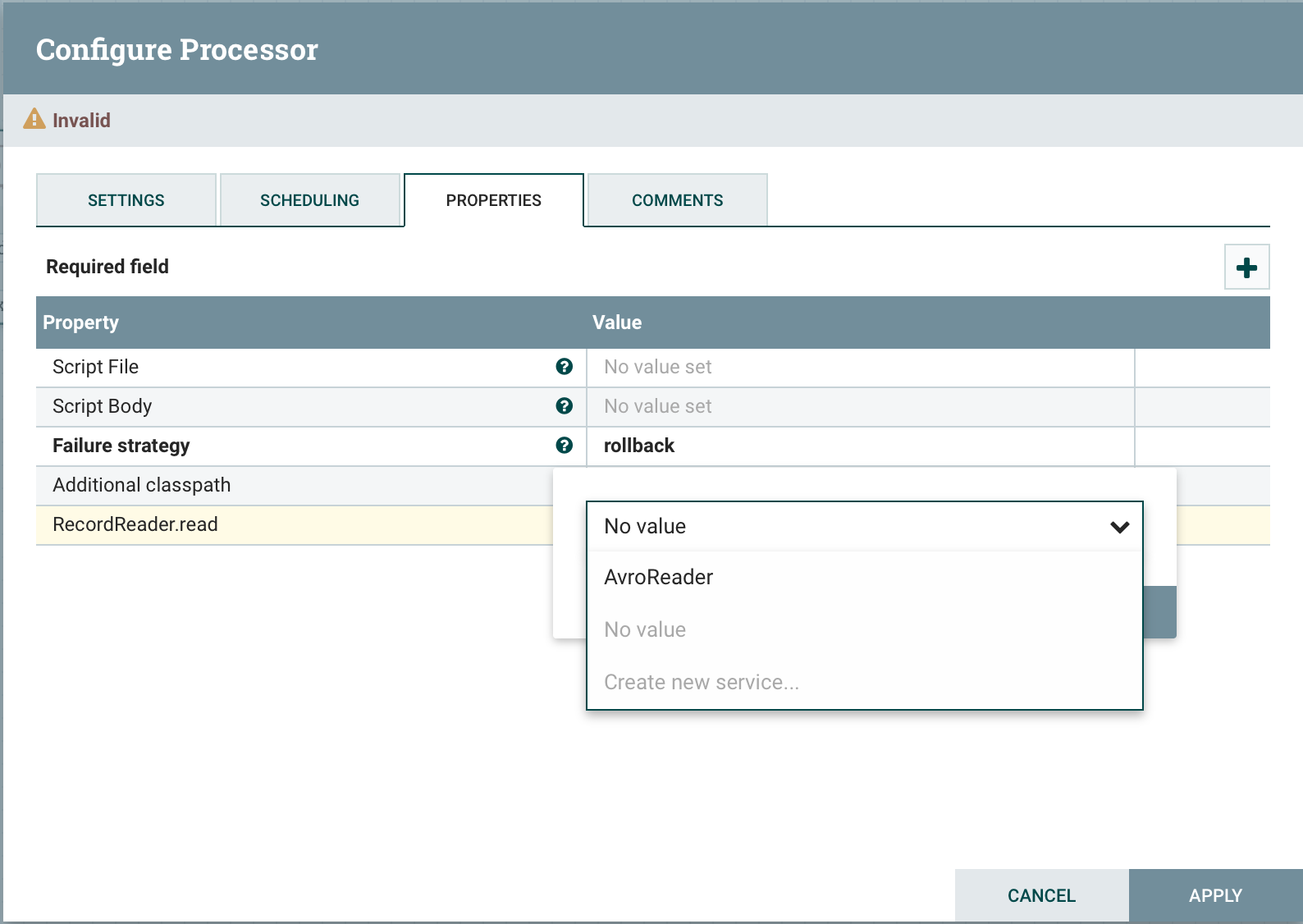 プロセッサは実行前にdbcpサービスからの接続を自動的に受け入れてトランザクションを処理します。エラーが発生すると、データベーストランザクションは自動的にロールバックされ、成功するとコミットされます。ExecuteGroovyScriptでは、適切な静的メソッドを実装することで、開始イベントと停止イベントをインターセプトできます。
プロセッサは実行前にdbcpサービスからの接続を自動的に受け入れてトランザクションを処理します。エラーが発生すると、データベーストランザクションは自動的にロールバックされ、成功するとコミットされます。ExecuteGroovyScriptでは、適切な静的メソッドを実装することで、開始イベントと停止イベントをインターセプトできます。import org.apache.nifi.processor.ProcessContext
...
static onStart(ProcessContext context){
// your code
}
static onStop(ProcessContext context){
// your code
}
REL_SUCCESS << flowFile
InvokeScriptedProcessor
別の興味深いプロセッサー。これを使用するには、implementsインターフェイスを実装するクラスを宣言し、プロセッサ変数を定義する必要があります。任意のPropertyDescriptorまたはRelationshipを定義し、親ComponentLogにアクセスして、メソッドvoid onScheduled(ProcessContext context)およびvoid onStopped(ProcessContext context)を定義することもできます。これらのメソッドは、NiFiでスケジュールされた開始イベントが発生したとき(onScheduled)、および停止したときに(onScheduled)呼び出されます。class GroovyProcessor implements Processor {
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
ロジックはメソッドに実装する必要があります void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) @Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) throw s ProcessException {
final ProcessSession session = sessionFactory.createSession(); def
flowFile = session.create()
if (!flowFile) return
// your code
try
{ session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
インターフェースで宣言されたすべてのメソッドを記述する必要はないので、次のメソッドを宣言する1つの抽象クラスを回避しましょう。abstract void executeScript(ProcessContext context, ProcessSession session)
呼び出すメソッドvoid onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory)
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.components.ValidationContext import org.apache.nifi.components.ValidationResult import org.apache.nifi.logging.ComponentLog
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.ProcessSessionFactory import org.apache.nifi.processor.Processor
import org.apache.nifi.processor.ProcessorInitializationContext import org.apache.nifi.processor.Relationship
import org.apache.nifi.processor.exception.ProcessException
abstract class BaseGroovyProcessor implements Processor {
public ComponentLog log
public Set<Relationship> relationships;
@Override
void initialize(ProcessorInitializationContext context) { log = context.getLogger()
}
@Override
void onTrigger(ProcessContext context, ProcessSessionFactory sessionFactory) thr final ProcessSession session = sessionFactory.createSession();
try {
executeScript(context, session);
session.commit();
} catch (final Throwable t) {
session.rollback(true);
throw t;
}
}
abstract void executeScript(ProcessContext context, ProcessSession session) thro
@Override
Collection<ValidationResult> validate(ValidationContext context) { return null }
@Override
PropertyDescriptor getPropertyDescriptor(String name) { return null }
@Override
void onPropertyModified(PropertyDescriptor descriptor, String oldValue, String n
@Override
List<PropertyDescriptor> getPropertyDescriptors() { return null }
@Override
String getIdentifier() { return null }
}
次に、後続クラスを宣言して、BaseGroovyProcessorexecuteScriptを記述し、Relationship RELSUCCESSおよびRELFAILUREも追加します。import org.apache.commons.lang3.tuple.Pair
import org.apache.nifi.expression.ExpressionLanguageScope import org.apache.nifi.processor.util.StandardValidators import ru.rt.nifi.common.BaseGroovyProcessor
import org.apache.nifi.components.PropertyDescriptor import org.apache.nifi.dbcp.DBCPService
import org.apache.nifi.processor.ProcessContext import org.apache.nifi.processor.ProcessSession
import org.apache.nifi.processor.exception.ProcessException import org.quartz.CronExpression
import java.sql.Connection
import java.sql.PreparedStatement import java.sql.ResultSet
import java.sql.SQLException import java.sql.Statement
class InvokeScripted extends BaseGroovyProcessor {
public static final REL_SUCCESS = new Relationship.Builder()
.name("success")
.description("If the cache was successfully communicated with it will be rou
.build()
public static final REL_FAILURE = new Relationship.Builder()
.name("failure")
.description("If unable to communicate with the cache or if the cache entry
.build()
@Override
void executeScript(ProcessContext context, ProcessSession session) throws Proces def flowFile = session.create()
if (!flowFile) return
try {
// your code
session.transfer(flowFile, REL_SUCCESS)
} catch(ProcessException | SQLException e) {
session.transfer(flowFile, REL_FAILURE)
log.error("Unable to execute SQL select query {} due to {}. No FlowFile
}
}
}
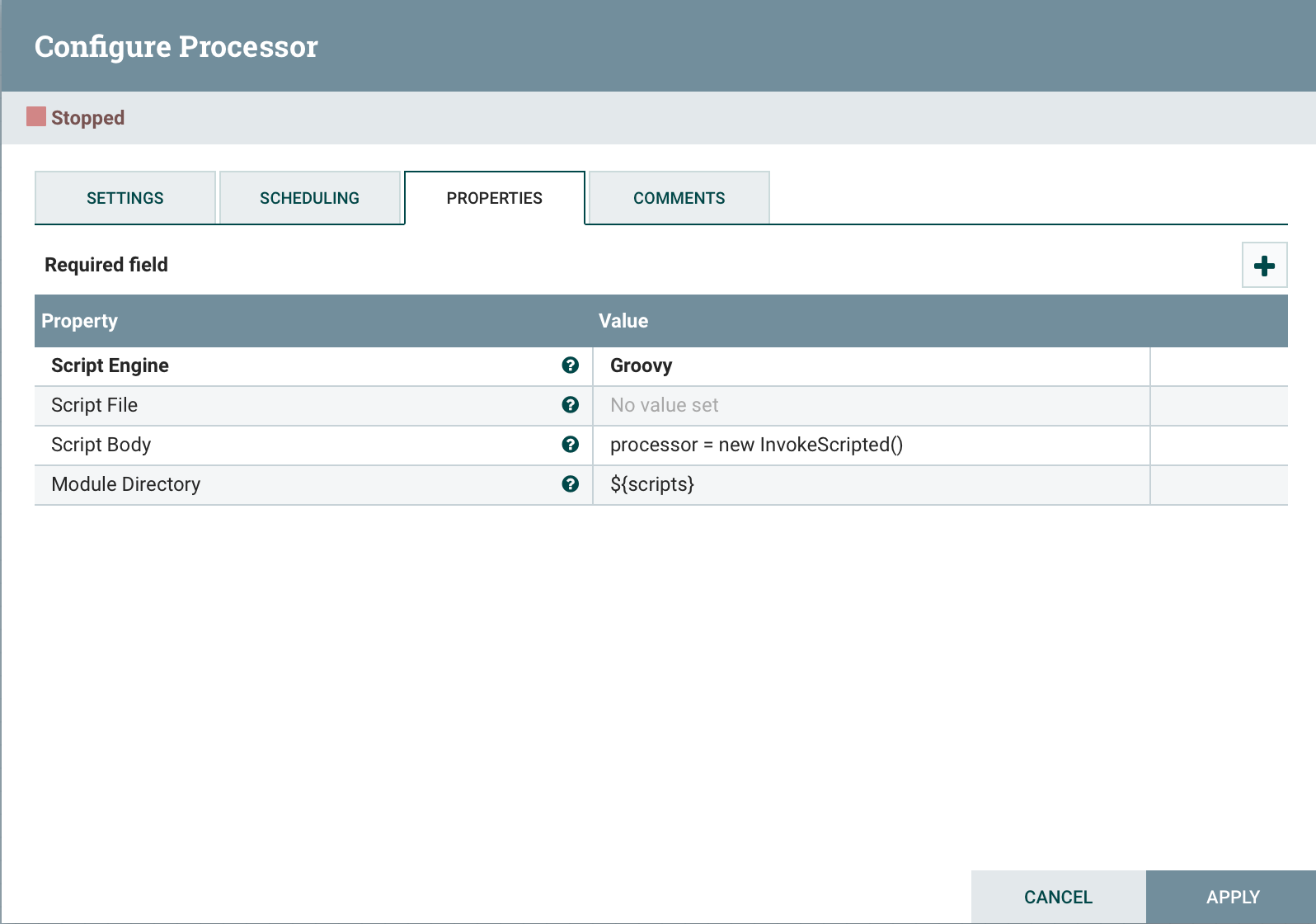 コードの最後に追加します。
コードの最後に追加します。processor = new InvokeScripted()このアプローチは、カスタムプロセッサの作成に似ています。結論
カスタムプロセッサを作成することは、最も簡単なことではありません。初めて、それを理解するために努力する必要がありますが、このアクションの利点は否定できません。Rostelecomデータ管理チームが作成した投稿