Halo lagi. Hari ini kami melanjutkan serangkaian terjemahan untuk mengantisipasi dimulainya kursus dasar "Matematika untuk Ilmu Data" .
Dalam sebuah artikel baru-baru ini, kami berbicara tentang cara membuat detektor anomali di Power BI dengan mengintegrasikan PyCaret ke dalamnya, dan membantu analis dan analis data menambahkan pembelajaran mesin pada laporan dan dasbor tanpa terlalu banyak usaha.Pada artikel ini, kita akan melihat bagaimana melakukan analisis kluster menggunakan PyCaret dan Power BI. Jika Anda belum pernah mendengar tentang PyCaret sebelumnya, Anda dapat mulai berkenalan dengannya di sini .Apa yang akan kita bahas dalam panduan hari ini:- Apa itu clustering? Jenis pengelompokan.
- Belajar tanpa guru dan menerapkan model clustering di Power BI.
- Analisis hasil dan visualisasi informasi di dashboard.
- Bagaimana cara menerapkan model pengelompokan pada produksi di Power BI?
Sebelum kita mulai ...
Jika Anda sudah pernah menggunakan Python sebelumnya, kemungkinan besar Anda sudah memiliki Anaconda di komputer Anda. Jika tidak, Anda dapat mengunduh distribusi Anaconda dari Python 3.7 atau lebih tinggi dari sini .Pengaturan lingkungan
Sebelum Anda mulai menggunakan fitur pembelajaran mesin PyCaret di Power BI, Anda perlu membuat lingkungan virtual dan memasangnya di dalamnya pycaret. Untuk melakukan ini, kita perlu melakukan tiga langkah:Langkah 1 - Membuat lingkungan virtualBuka command prompt Anaconda dan masukkan yang berikut ini:conda create --name myenv python=3.7
Langkah 2 - Instal PyCaretJalankan perintah berikut di prompt perintah Anaconda:pip install pycaret
Instalasi mungkin memakan waktu 15-20 menit. Jika Anda menemukan masalah apa pun selama instalasi, Anda dapat membiasakan diri dengan solusi mereka di halaman kami di GitHub .Langkah 3 - Tunjukkan di Power BI di mana Python diinstal.Lingkungan virtual yang dibuat harus dikaitkan dengan Power BI. Anda dapat melakukan ini menggunakan Pengaturan Global di Power BI Desktop (File -> Options -> Global -> Python scripting). Lingkungan Anaconda dimasukkan ke dalam direktori secara default:C:\Users\username\AppData\Local\Continuum\anaconda3\envs\myenv
Apa itu clustering?
Clustering adalah metode pemisahan data ke dalam kelompok sesuai dengan karakteristik yang sama. Kelompok semacam itu dapat berguna untuk mempelajari data, mengidentifikasi pola, dan menganalisis himpunan bagian data. Clustering data membantu mengidentifikasi struktur data yang mendasarinya, yang berguna di banyak industri. Berikut adalah beberapa kegunaan umum untuk pengelompokan dalam bisnis:- Segmentasi pelanggan pemasaran.
- Analisis perilaku konsumen untuk promosi dan diskon.
- Identifikasi geoclusters selama wabah, seperti, misalnya, COVID-19.
Jenis Clustering
Mengingat sifat subyektif dari tugas pengelompokan, ada berbagai algoritma yang lebih cocok untuk menyelesaikan jenis tugas tertentu. Setiap algoritma memiliki karakteristik dan pembenaran matematis sendiri, yang mendasari distribusi cluster.Dalam tutorial hari ini, kita berbicara tentang analisis klaster di Power BI menggunakan pustaka Python yang disebut PyCaret dan kita tidak akan membahas matematika. Hari ini kita akan menggunakan metode k-means - salah satu metode pengajaran paling sederhana dan paling populer tanpa guru. Anda dapat menemukan informasi lebih lanjut tentang metode k-means di sini .
Hari ini kita akan menggunakan metode k-means - salah satu metode pengajaran paling sederhana dan paling populer tanpa guru. Anda dapat menemukan informasi lebih lanjut tentang metode k-means di sini .Konteks bisnis
Dalam panduan ini, kami akan menggunakan dataset yang sudah jadi dari database Pengeluaran Kesehatan Global Organisasi Kesehatan Dunia. Ini berisi pengeluaran kesehatan sebagai persentase dari PDB nasional untuk lebih dari 200 negara dari tahun 2000 hingga 2017.Tugas kami adalah menemukan pola dan grup dalam data ini menggunakan metode k-means.Data dapat ditemukan di sini .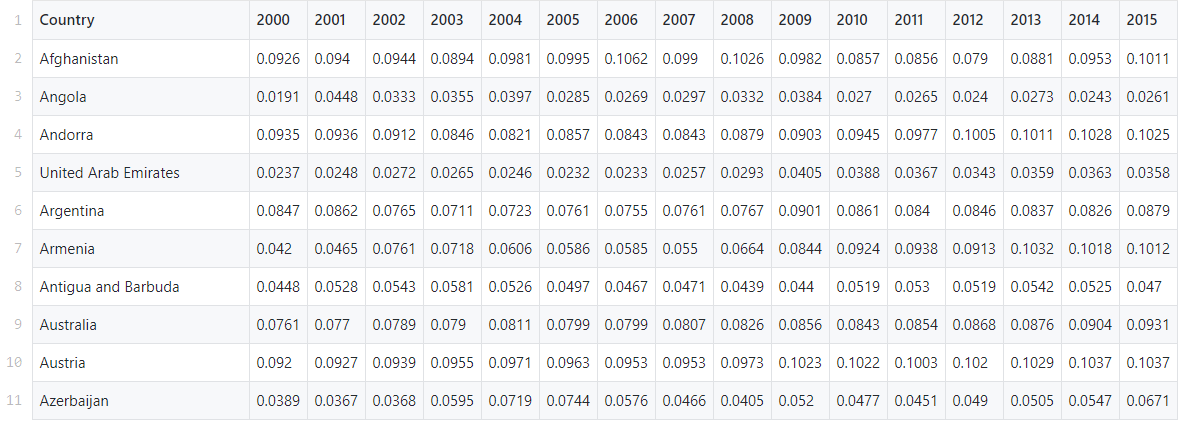
Jadi, mari kita mulai
Sekarang setelah Anda mengatur lingkungan Anaconda, memasang PyCaret, Anda memahami dasar-dasar analisis kluster dan konteks bisnis, saatnya untuk turun ke bisnis.1. Akuisisi data
Langkah pertama adalah mengimpor dataset ke Power BI Desktop. Anda dapat mengunduh data menggunakan konektor web. (Power BI Desktop → Dapatkan Data → Dari Web ). Tautan ke file csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .
Tautan ke file csv: https://github.com/pycaret/powerbi-clustering/blob/master/clustering.csv .2. Pelatihan model
Untuk mempelajari model pengelompokan dalam Power BI, kita perlu menjalankan skrip Python di Power Query Editor ( Power Query Editor → Transform → Run skrip python ). Gunakan kode berikut sebagai skrip:from pycaret.clustering import *
dataset = get_clusters(dataset, num_clusters=5, ignore_features=['Country'])
 Kami mengabaikan kolom "Negara" dari set menggunakan parameter
Kami mengabaikan kolom "Negara" dari set menggunakan parameter ignore_features. Ada banyak alasan mengapa Anda mungkin perlu mengecualikan kolom tertentu untuk lebih melatih model pembelajaran mesin.PyCaret memungkinkan Anda untuk menyembunyikan kolom yang tidak perlu alih-alih menghapusnya, karena Anda mungkin membutuhkannya di masa depan untuk analisis lebih lanjut. Misalnya, saat ini kami tidak ingin menggunakan "Negara" untuk pelatihan dan meneruskan kolom ini ke ignore_features.Ada 8 algoritma pembelajaran mesin yang siap digunakan di PyCaret.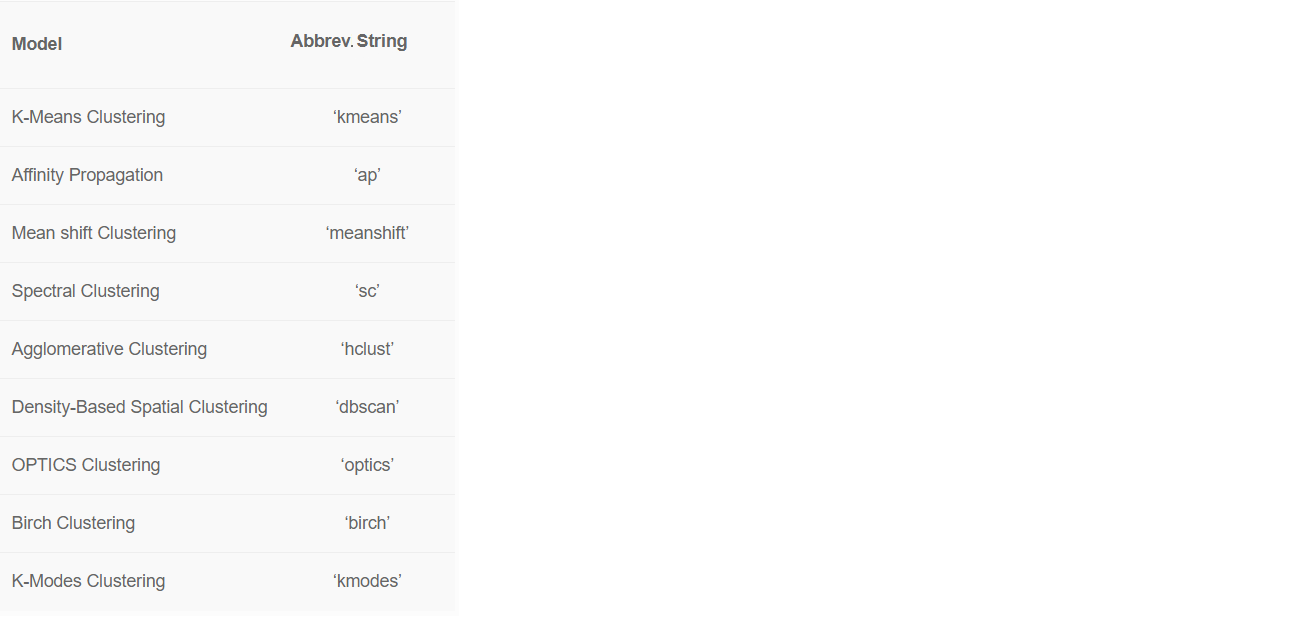 Secara default, PyCaret melatih model klaster k-means pada empat klaster. Tetapi nilai default dapat dengan mudah diubah:
Secara default, PyCaret melatih model klaster k-means pada empat klaster. Tetapi nilai default dapat dengan mudah diubah:- Untuk mengubah jenis model, gunakan parameter model dalam
get_clusters(). - Untuk mengubah jumlah cluster, gunakan opsi
num_clusters.
Sebagai contoh, ini adalah bagaimana Anda dapat melakukan k-means clustering menjadi 6 cluster.from pycaret.clustering import *
dataset = get_clusters(dataset, model='kmodes', num_clusters=6, ignore_features=['Country'])
Kesimpulan:
 Kolom lain dengan label klaster ditambahkan ke dataset asli. Kemudian semua nilai dalam kolom tahun digunakan untuk menormalkan data dan memvisualisasikan lebih lanjut dalam Power BI.Ini adalah bagaimana hasil akhirnya akan terlihat di Power BI.
Kolom lain dengan label klaster ditambahkan ke dataset asli. Kemudian semua nilai dalam kolom tahun digunakan untuk menormalkan data dan memvisualisasikan lebih lanjut dalam Power BI.Ini adalah bagaimana hasil akhirnya akan terlihat di Power BI.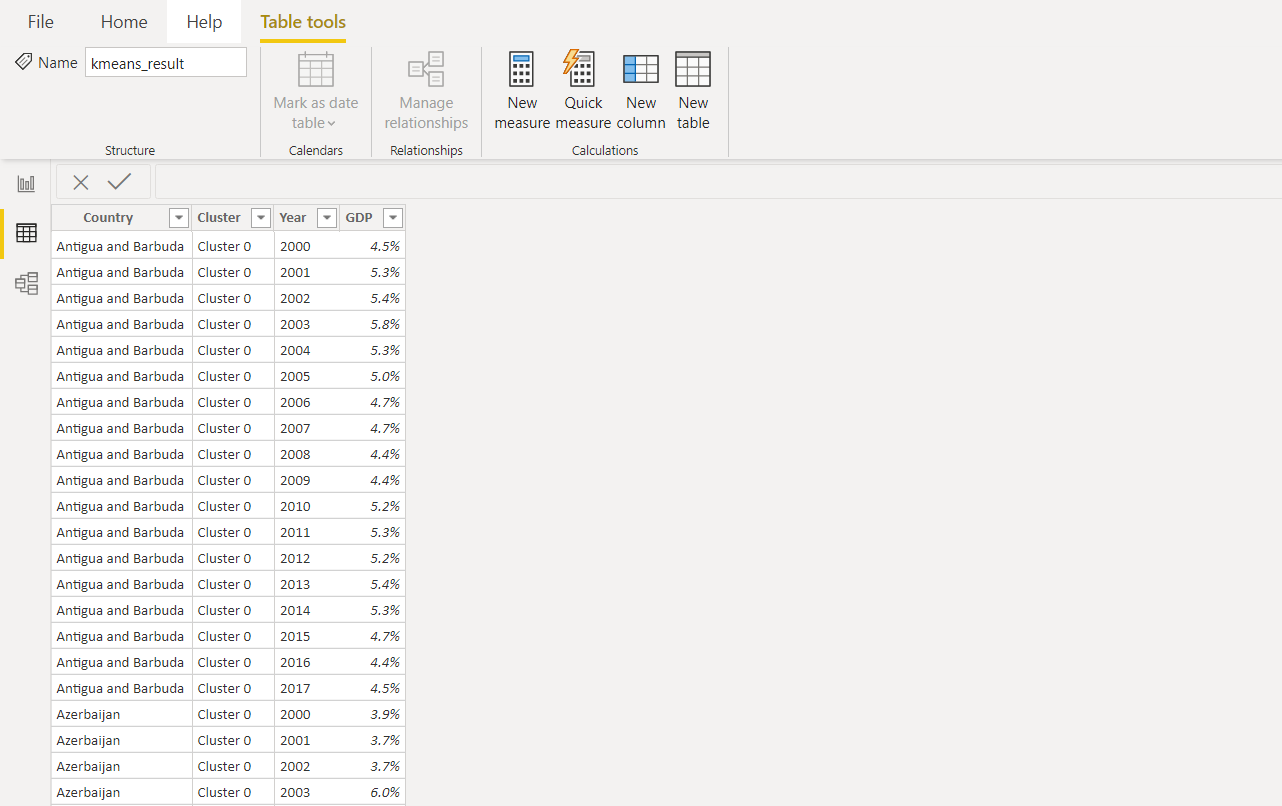
3. Dasbor
Ketika Anda mendapat label klaster di Power BI, Anda bisa memvisualisasikannya di dasbor di Power BI untuk analitik: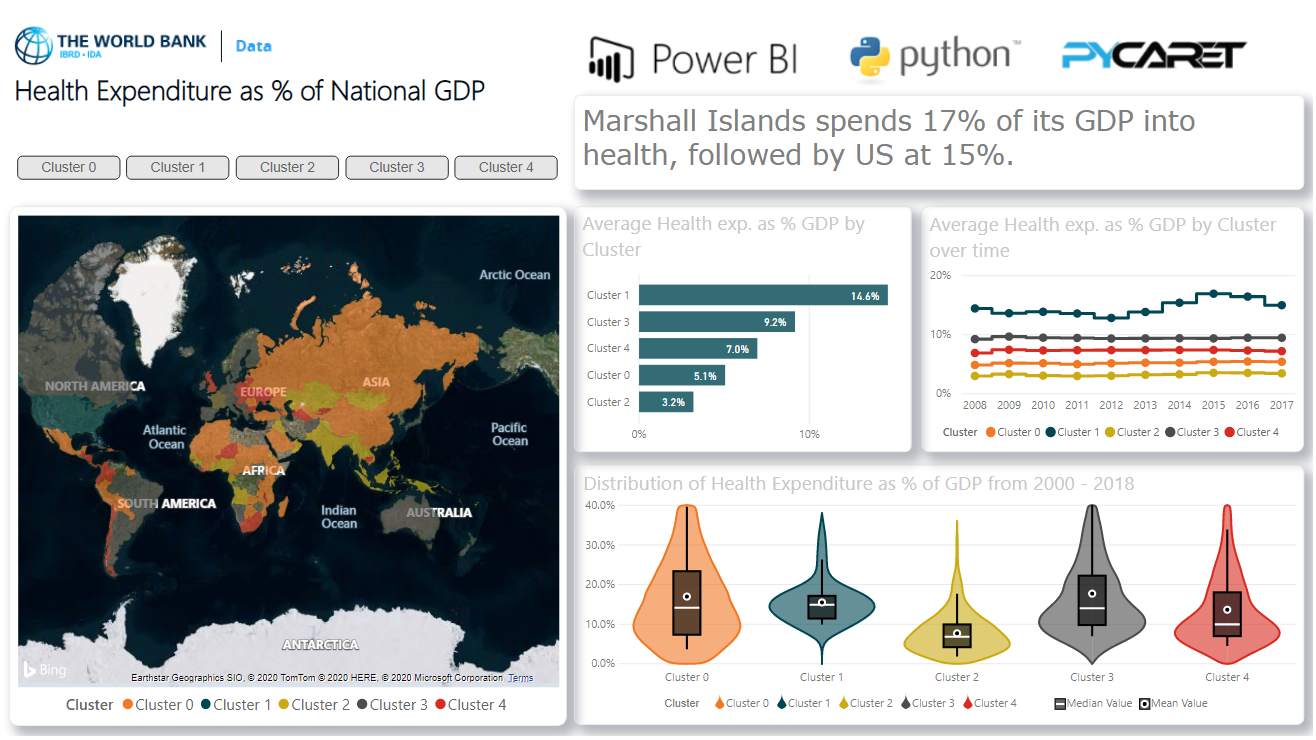
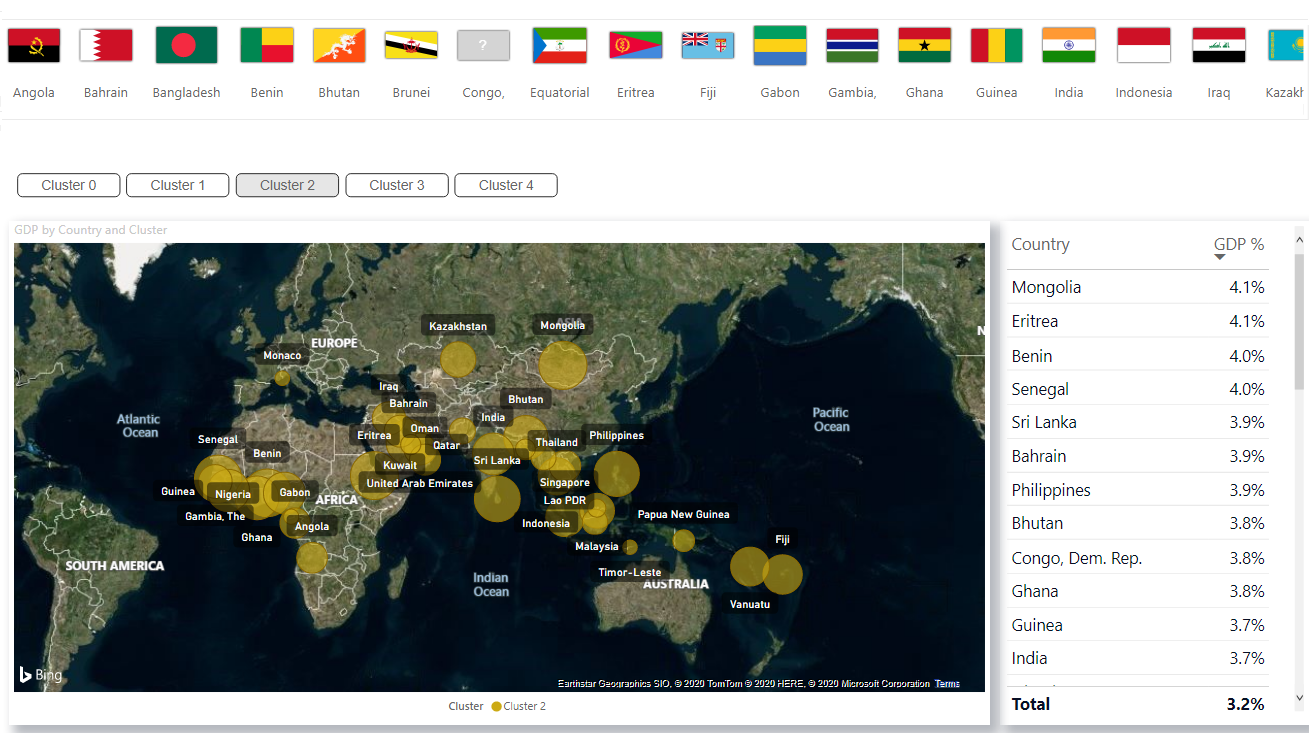 Anda dapat mengunduh file dan dataset PBIX dari GitHub .
Anda dapat mengunduh file dan dataset PBIX dari GitHub .Implementasi Clustering
Di atas, kami menunjukkan implementasi pengelompokan paling sederhana di Power BI. Saya perhatikan bahwa metode ini melatih model pengelompokan setiap kali dataset diperbarui di Power BI. Ini bisa menjadi masalah karena alasan berikut:- Ketika model dilatih ulang tentang data baru, label cluster dapat berubah (yaitu, jika sebelumnya beberapa titik data ditugaskan ke cluster pertama, maka ketika dilatih ulang, mereka dapat ditugaskan ke cluster kedua);
- Anda tidak akan ingin menghabiskan beberapa jam setiap kali melatih ulang model.
Cara yang lebih efektif untuk menerapkan pengelompokan dalam Power BI alih-alih belajar berulang kali adalah dengan menggunakan model pra-terlatih untuk membuat label klaster.Pelatihan Model Awal
Anda dapat menggunakan lingkungan pengembangan terintegrasi (IDE) atau Notebook apa pun untuk melatih model. Dalam contoh ini, kami melatih model pengelompokan dalam Visual Studio Code.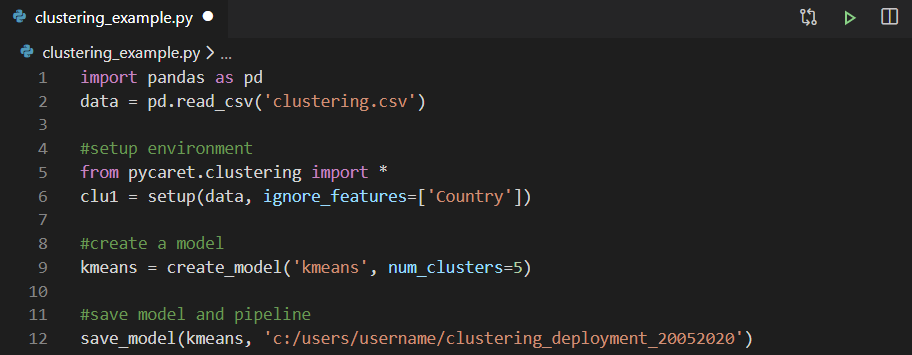 Kemudian, model yang terlatih disimpan sebagai file acar dan diimpor ke Power Query untuk menghasilkan label kluster.
Kemudian, model yang terlatih disimpan sebagai file acar dan diimpor ke Power Query untuk menghasilkan label kluster. Jika Anda ingin mempelajari lebih lanjut tentang menerapkan analisis kluster di notebook Jupyter dengan PyCaret, tonton video berdurasi dua menit ini.
Jika Anda ingin mempelajari lebih lanjut tentang menerapkan analisis kluster di notebook Jupyter dengan PyCaret, tonton video berdurasi dua menit ini.Menggunakan model pra-terlatih
Jalankan kode di bawah ini untuk menghasilkan tag dari model pra-terlatih:from pycaret.clustering import *
dataset = predict_model('c:/.../clustering_deployment_20052020, data = dataset)
Hasilnya akan sama dengan yang kami amati sebelumnya. Satu-satunya perbedaan adalah bahwa ketika menggunakan model pra-dilatih, tag akan dihasilkan berdasarkan kumpulan data baru menggunakan model lama, dan bukan pada model yang telah dilatih ulang.Bekerja dengan Layanan Power BI
Setelah Anda mengunggah file .pbix ke layanan Power BI, Anda harus mengikuti beberapa langkah lagi untuk memastikan integrasi yang mulus dari pipa pembelajaran mesin ke dalam pipa data Anda. Langkah-langkahnya adalah sebagai berikut:- Aktifkan pembaruan terjadwal dataset - ini akan memungkinkan Anda untuk menjadwalkan buku kerja dengan dataset Anda untuk diperbarui menggunakan skrip Python, lihat bagian Mengonfigurasi dijadwalkan penyegaran terjadwal , yang juga berisi informasi tentang Gerbang Pribadi.
- Instal Personal Gateway - Anda akan membutuhkan Personal Gateway, yang harus diinstal di direktori yang sama di mana Python diinstal. Layanan Power BI harus memiliki akses ke lingkungan Python. Di sini Anda dapat mempelajari lebih lanjut tentang cara menginstal dan mengkonfigurasi Personal Gateway.
Jika Anda ingin tahu lebih banyak tentang analisis klaster, Anda dapat membiasakan diri dengan panduan kami di buku catatan ini .
Ikuti saja.