Catatan perev. : Meskipun ulasan ini tidak mengklaim sebagai perbandingan teknis yang dirancang dengan cermat dari solusi yang ada untuk penyimpanan data permanen di Kubernetes, ini bisa menjadi titik awal yang baik untuk administrator yang relevan dengan masalah ini. Perhatian terbesar diberikan pada solusi Piraeus, keakraban dengan yang tidak hanya akan menguntungkan pecinta Linstor, tetapi juga mereka yang belum pernah mendengar proyek ini. Ini adalah ikhtisar tidak ilmiah dari solusi penyimpanan untuk Kubernetes. Pernyataan masalah: membutuhkan kemampuan untuk membuat Volume Persisten pada disk node, data yang akan disimpan jika terjadi kerusakan atau restart node.Motivasi untuk perbandingan ini adalah kebutuhan untuk memigrasikan armada server perusahaan dari beberapa server bare metal khusus ke kluster Kubernetes.Perusahaan saya adalah startup Escavador Brasil dengan kebutuhan komputasi besar (terutama CPU) dan anggaran yang sangat terbatas. Kami mengembangkan solusi NLP untuk menyusun data hukum.
Ini adalah ikhtisar tidak ilmiah dari solusi penyimpanan untuk Kubernetes. Pernyataan masalah: membutuhkan kemampuan untuk membuat Volume Persisten pada disk node, data yang akan disimpan jika terjadi kerusakan atau restart node.Motivasi untuk perbandingan ini adalah kebutuhan untuk memigrasikan armada server perusahaan dari beberapa server bare metal khusus ke kluster Kubernetes.Perusahaan saya adalah startup Escavador Brasil dengan kebutuhan komputasi besar (terutama CPU) dan anggaran yang sangat terbatas. Kami mengembangkan solusi NLP untuk menyusun data hukum. Karena krisis dengan COVID-19, real Brasil jatuh ke rekor terendah terhadap dolar ASMata uang nasional kami sebenarnya sangat diremehkan, sehingga gaji rata-rata pengembang senior hanya 2.000 USD per bulan. Dengan demikian, kami tidak mampu membayar kemewahan untuk mengeluarkan jumlah yang signifikan pada layanan cloud. Ketika saya terakhir membuat perhitungan, [terima kasih untuk menggunakan server saya] kami menghemat 75% dibandingkan dengan yang harus saya bayar untuk AWS. Dengan kata lain, pengembang lain dapat disewa untuk menghemat uang - saya pikir ini adalah penggunaan dana yang jauh lebih rasional.Terinspirasi oleh serangkaian publikasi dari Vito Botta, saya memutuskan untuk membuat cluster K8 menggunakan Rancher (dan sejauh ini bagus ...). Vito juga melakukan analisis yang sangat baik dari berbagai solusi penyimpanan. Pemenang yang jelas adalah Linstor (dia bahkan memilihnyaliga khusus ). Spoiler: Saya setuju dengannya.Untuk beberapa waktu saya telah mengikuti lalu lintas di sekitar Kubernetes, tetapi baru-baru ini memutuskan untuk berpartisipasi di dalamnya. Hal ini terutama disebabkan oleh kenyataan bahwa penyedia memiliki jajaran prosesor Ryzen yang baru. Dan kemudian saya sangat terkejut melihat bahwa banyak solusi masih dalam pengembangan atau keadaan belum matang (terutama untuk kluster logam kosong: virtualisasi VM, MetalLB, dll). Kubah pada bare metal masih dalam tahap matang, meskipun mereka diwakili oleh banyak solusi komersial dan Open Source. Saya memutuskan untuk membandingkan solusi utama yang menjanjikan dan gratis (secara bersamaan menguji satu produk komersial untuk memahami apa yang saya kehilangan). Berbagai Solusi
Karena krisis dengan COVID-19, real Brasil jatuh ke rekor terendah terhadap dolar ASMata uang nasional kami sebenarnya sangat diremehkan, sehingga gaji rata-rata pengembang senior hanya 2.000 USD per bulan. Dengan demikian, kami tidak mampu membayar kemewahan untuk mengeluarkan jumlah yang signifikan pada layanan cloud. Ketika saya terakhir membuat perhitungan, [terima kasih untuk menggunakan server saya] kami menghemat 75% dibandingkan dengan yang harus saya bayar untuk AWS. Dengan kata lain, pengembang lain dapat disewa untuk menghemat uang - saya pikir ini adalah penggunaan dana yang jauh lebih rasional.Terinspirasi oleh serangkaian publikasi dari Vito Botta, saya memutuskan untuk membuat cluster K8 menggunakan Rancher (dan sejauh ini bagus ...). Vito juga melakukan analisis yang sangat baik dari berbagai solusi penyimpanan. Pemenang yang jelas adalah Linstor (dia bahkan memilihnyaliga khusus ). Spoiler: Saya setuju dengannya.Untuk beberapa waktu saya telah mengikuti lalu lintas di sekitar Kubernetes, tetapi baru-baru ini memutuskan untuk berpartisipasi di dalamnya. Hal ini terutama disebabkan oleh kenyataan bahwa penyedia memiliki jajaran prosesor Ryzen yang baru. Dan kemudian saya sangat terkejut melihat bahwa banyak solusi masih dalam pengembangan atau keadaan belum matang (terutama untuk kluster logam kosong: virtualisasi VM, MetalLB, dll). Kubah pada bare metal masih dalam tahap matang, meskipun mereka diwakili oleh banyak solusi komersial dan Open Source. Saya memutuskan untuk membandingkan solusi utama yang menjanjikan dan gratis (secara bersamaan menguji satu produk komersial untuk memahami apa yang saya kehilangan). Berbagai Solusi Penyimpanan di Landscape CNCFTapi pertama-tama, saya ingin memperingatkan Anda bahwa saya baru mengenal K8.Untuk percobaan, 4 pekerja digunakan dengan konfigurasi berikut: Prosesor Ryzen 3700X, memori ECC 64 GB, ukuran NVMe 2 TB. Benchmark dibuat menggunakan gambar
Penyimpanan di Landscape CNCFTapi pertama-tama, saya ingin memperingatkan Anda bahwa saya baru mengenal K8.Untuk percobaan, 4 pekerja digunakan dengan konfigurasi berikut: Prosesor Ryzen 3700X, memori ECC 64 GB, ukuran NVMe 2 TB. Benchmark dibuat menggunakan gambar sotoaster/dbench:latest(on fio) dengan bendera O_DIRECT.Longhorn
Saya sangat menyukai Longhorn. Ini sepenuhnya terintegrasi dengan Rancher dan Anda dapat menginstalnya melalui Helm dengan satu klik. Menginstal Longhorn dari RancherIni adalah alat sumber terbuka dengan status proyek kotak pasir dari Cloud Native Computing Foundation (CNCF). Pengembangannya didanai oleh Rancher - perusahaan yang cukup sukses dengan produk [eponim] yang terkenal.
Menginstal Longhorn dari RancherIni adalah alat sumber terbuka dengan status proyek kotak pasir dari Cloud Native Computing Foundation (CNCF). Pengembangannya didanai oleh Rancher - perusahaan yang cukup sukses dengan produk [eponim] yang terkenal. Antarmuka grafis yang sangat baik juga tersedia - semuanya dapat dilakukan darinya. Dengan kinerja, semuanya teratur. Proyek ini masih dalam versi beta, yang dikonfirmasi oleh masalah pada GitHub.Saat menguji, saya meluncurkan benchmark menggunakan 2 replika dan Longhorn 0.8.0:
Antarmuka grafis yang sangat baik juga tersedia - semuanya dapat dilakukan darinya. Dengan kinerja, semuanya teratur. Proyek ini masih dalam versi beta, yang dikonfirmasi oleh masalah pada GitHub.Saat menguji, saya meluncurkan benchmark menggunakan 2 replika dan Longhorn 0.8.0:- Baca / tulis acak, IOPS: 28.2k / 16.2k;
- Bandwidth baca / tulis: 205 Mb / s / 108 Mb / s;
- Rata-rata latensi baca / tulis (usec): 593.27 / 644.27;
- Baca / tulis berurutan: 201 Mb / s / 108 Mb / s;
- Baca / tulis acak campuran, IOPS: 14.7k / 4904.
Openebs
Proyek ini juga memiliki status sandbox CNCF. Dengan sejumlah besar bintang di GitHub, sepertinya ini solusi yang sangat menjanjikan. Dalam ulasannya, Vito Botta mengeluh tentang kinerja yang tidak memadai. Di sini dia berada di kata CEO Mayadata:Informasi sudah sangat ketinggalan zaman. OpenEBS digunakan untuk mendukung 3, tetapi sekarang mendukung 4 mesin, jika Anda mengaktifkan penyediaan dinamis dan orkestrasi PV lokal, yang dapat berjalan pada kecepatan NVMe. Selain itu, mesin MayaStor sekarang terbuka dan sudah menerima ulasan positif (meskipun memiliki status alfa).
Pada halaman proyek OpenEBS terdapat penjelasan tentang statusnya:OpenEBS — Kubernetes. OpenEBS sandbox- CNCF 2019- , - (local, nfs, zfs, nvme) on-premise, . OpenEBS - stateful- — Litmus Project, — OpenEBS. OpenEBS production 2018 ; 2,5 docker pull'.
Ini memiliki banyak mesin, dan yang terakhir tampaknya cukup menjanjikan dalam hal kinerja: "MayaStor - mesin alpha dengan NVMe over Fabrics". Sayangnya, saya tidak mengujinya karena status versi alpha.Dalam tes, versi 1.8.0 digunakan pada mesin jiva. Selain itu, saya sebelumnya memeriksa cStor, tetapi tidak menyimpan hasilnya, yang ternyata sedikit lebih lambat dari jiva. Untuk tolok ukur, bagan Helm dipasang dengan semua pengaturan default dan Kelas Penyimpanan, yang dibuat secara standar oleh Helm ( openebs-jiva-default), digunakan. Kinerja ternyata menjadi yang terburuk dari semua solusi yang dipertimbangkan (saya akan berterima kasih atas saran untuk memperbaikinya).OpenEBS 1.8.0 dengan mesin jiva (3 replika?):- Baca / tulis acak, IOPS: 2182/1527;
- Bandwidth baca / tulis: 65.0 Mb / s / 41.9 Mb / s;
- / (usec): 1825.49 / 2612.87;
- /: 95.5 / / 37.8 /;
- /, IOPS: 2607 / 856.
. Evan Powell, OpenEBS ( , StackStorm Nexenta):, Bruno! OpenEBS . Jiva, ARM overhead' . Bloomberg DynamicLocal PV OpenEBS. Elastic , . , OpenEBS Director (https://account.mayadata.io/signup). — , .
StorageOS
Ini adalah solusi komersial yang gratis saat menggunakan ruang hingga 110 GB. Lisensi pengembang gratis dapat diperoleh dengan mendaftar melalui antarmuka pengguna produk; Ini memberikan ruang hingga 500 GB. Di Rancher, terdaftar sebagai mitra, jadi pemasangan menggunakan Helm mudah dan tanpa beban.Pengguna ditawari panel kontrol dasar. Pengujian produk ini terbatas karena bersifat komersial dan tidak sesuai dengan nilai kami. Tapi saya masih ingin melihat apa proyek komersial yang mampu.Tes ini menggunakan Kelas Penyimpanan yang ada yang disebut "Cepat" (Templat 0.2.19, 1 Master + 0 Replika?). Hasilnya luar biasa. Mereka secara signifikan melebihi solusi sebelumnya.- Baca / tulis acak, IOPS: 117k / 90,4k;
- Bandwidth baca / tulis: 2124 Mb / s / 457 Mb / s;
- Rata-rata latensi baca / tulis (usec): 63.44 / 86.52;
- Baca / tulis berurutan: 1907 Mb / s / 448 Mb / s;
- Campuran baca / tulis acak, IOPS: 81.9k / 27.3k.
Piraeus (berdasarkan Linstor)
Lisensi: GPLv3Vito Botta yang sudah disebutkan akhirnya memutuskan menggunakan Linstor, yang merupakan alasan tambahan untuk mencoba solusi ini. Sepintas, proyek ini terlihat agak aneh. Hampir tidak ada bintang di GitHub, nama yang tidak biasa dan bahkan tidak ada di CNCF Landscape. Tetapi setelah diperiksa lebih dekat, semuanya tidak begitu menakutkan, karena:- DRBD digunakan sebagai mekanisme replikasi dasar (pada kenyataannya, itu dikembangkan oleh orang yang sama). Pada saat yang sama, DRBD 8.x telah menjadi bagian dari kernel Linux resmi selama lebih dari 10 tahun. Dan kita berbicara tentang teknologi yang telah diasah selama lebih dari 20 tahun.
- Media dikendalikan oleh LINSTOR, juga teknologi yang matang dari perusahaan yang sama. Versi pertama Linstor-server muncul di GitHub pada Februari 2018. Ini kompatibel dengan berbagai teknologi / sistem seperti Proxmox, OpenNebula dan OpenStack.
- Rupanya, Linbit secara aktif mengembangkan proyek, terus-menerus memperkenalkan fitur-fitur baru dan perbaikan ke dalamnya. Versi 10 dari DRBD masih memiliki status alfa , tetapi sudah menawarkan beberapa fitur unik, seperti pengkodean penghapusan (mirip dengan fungsi dari RAID5 / 6 - approx. Terjemahan.) .
- Perusahaan mengambil langkah-langkah tertentu untuk menjadi salah satu proyek CNCF.
Oke, proyek ini terlihat cukup meyakinkan untuk mempercayakan kepadanya dengan data yang berharga. Tetapi apakah dia dapat memutar ulang alternatif? Mari kita lihat.Instalasi
Vito berbicara tentang menginstal Linstor di sini . Namun, dalam komentar, salah satu pengembang Linstor merekomendasikan proyek baru yang disebut Piraeus. Seperti yang saya pahami, Piraeus menjadi proyek Linbit Open Source, yang menggabungkan semua yang terkait dengan K8. Tim sedang bekerja pada operator yang sesuai , tetapi untuk saat ini, Piraeus dapat diinstal menggunakan file YAML ini:kubectl apply -f https://raw.githubusercontent.com/bratao/piraeus/master/deploy/all.yaml
Perhatian! Anda mengambil konfigurasi dari repositori pribadi saya. Lihat repositori resmi! Saya memperbarui versi gambar untuk memecahkan kesalahan yang terjadi ketika menggunakan di Ubuntu.Repositori Piraeus resmi tersedia di sini .Anda juga dapat menggunakan repositori kvaps (sepertinya lebih dinamis daripada repositori piraeus resmi): https://github.com/kvaps/kube-linstor ( gunakan kesempatan ini untuk menyapa Andreykvaps- kira-kira. perev.) . Semua node bekerja setelah instalasi
Semua node bekerja setelah instalasiAdministrasi
Administrasi dilakukan menggunakan baris perintah. Akses ke sana dimungkinkan dari shell perintah dari node piraeus-controller. Node pengontrol menjalankan linstor-server. Ini adalah lapisan abstraksi di atas drbd, yang mampu mengelola seluruh armada node. Tangkapan layar di bawah ini menunjukkan beberapa perintah yang berguna untuk tugas paling populer, misalnya:
Node pengontrol menjalankan linstor-server. Ini adalah lapisan abstraksi di atas drbd, yang mampu mengelola seluruh armada node. Tangkapan layar di bawah ini menunjukkan beberapa perintah yang berguna untuk tugas paling populer, misalnya:linstor node list - menampilkan daftar node yang terhubung dan statusnya;linstor volume list - menunjukkan daftar volume yang dibuat dan lokasinya;linstor node info - menunjukkan kemampuan masing-masing node.
 Perintah LinstorDaftar lengkap perintah tersedia di dokumentasi resmi: Panduan Pengguna LINSTOR .Jika terjadi situasi seperti otak terpecah, drbd dapat diakses langsung melalui node.
Perintah LinstorDaftar lengkap perintah tersedia di dokumentasi resmi: Panduan Pengguna LINSTOR .Jika terjadi situasi seperti otak terpecah, drbd dapat diakses langsung melalui node.Pemulihan bencana
Saya melakukan yang terbaik untuk menjatuhkan kluster saya, termasuk hard reset pada node. Tapi ternyata linstor ulet.Drbd dengan sempurna mengenali masalah yang disebut split brain. Dalam situasi saya, simpul sekunder jatuh dari replikasi.Split brain — , - , - Primary, «» . , . , , .
Split brain DRBD , , Heartbeat.
Detailnya dapat ditemukan di dokumentasi resmi drbd . Node sekunder gagal replikasi.Dalam kasus saya, untuk menyelesaikan masalah, saya menjatuhkan data sekunder dan memulai sinkronisasi dengan node primer. Karena saya lebih suka antarmuka grafis, saya menggunakan utilitas drbdtop untuk ini. Dengan bantuannya, Anda dapat secara visual memonitor status dan menjalankan perintah dalam node.Saya perlu masuk ke konsol pada piraues simpul masalah (itu
Node sekunder gagal replikasi.Dalam kasus saya, untuk menyelesaikan masalah, saya menjatuhkan data sekunder dan memulai sinkronisasi dengan node primer. Karena saya lebih suka antarmuka grafis, saya menggunakan utilitas drbdtop untuk ini. Dengan bantuannya, Anda dapat secara visual memonitor status dan menjalankan perintah dalam node.Saya perlu masuk ke konsol pada piraues simpul masalah (itu worker2-gpu): Pergi ke nodeDi sana saya menginstal drdbtop. Unduh utilitas ini di sini:
Pergi ke nodeDi sana saya menginstal drdbtop. Unduh utilitas ini di sini:wget https://github.com/LINBIT/drbdtop/releases/download/v0.2.2/drbdtop-linux-amd64
chmod +x drbdtop-linux-amd64
./drbdtop-linux-amd64
 Menjalankan utilitas drbdtopLihatlah panel bawah. Ada perintah di atasnya yang dapat digunakan untuk memperbaiki otak yang terbelah:
Menjalankan utilitas drbdtopLihatlah panel bawah. Ada perintah di atasnya yang dapat digunakan untuk memperbaiki otak yang terbelah: Setelah itu, node-node terhubung dan disinkronkan secara otomatis.
Setelah itu, node-node terhubung dan disinkronkan secara otomatis.Bagaimana cara meningkatkan kecepatan?
Secara default, Piraeus / Linstor / drbd menunjukkan kinerja yang sangat baik (Anda dapat melihat ini di bawah). Pengaturan standarnya masuk akal dan aman. Namun, kecepatan tulisnya agak lemah. Karena server dalam kasus saya tersebar di berbagai pusat data (walaupun secara fisik mereka relatif dekat), saya memutuskan untuk mencoba menyesuaikan kinerjanya.Titik awal untuk optimasi adalah mendefinisikan protokol replikasi. Secara default, Protokol C digunakan, yang menunggu konfirmasi penulisan pada node sekunder jarak jauh. Berikut ini adalah deskripsi protokol yang mungkin:- Protocol A — . , , TCP- . , TCP . .
- Protocol B — . , , .
- Protocol C ( ) — . .
Karena itu, dalam Linstor saya juga menggunakan protokol asinkron (mendukung replikasi sinkron / semi-sinkron / asinkron). Anda dapat mengaktifkannya dengan perintah berikut:linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 1085760 --rcvbuf-size 1085760 --c-max-rate 4194304 --c-fill-target 1048576
Hasil implementasinya adalah aktivasi protokol asinkron dan peningkatan buffer hingga 1 MB. Itu relatif aman. Atau Anda dapat menggunakan perintah berikut (mengabaikan disk flush dan secara signifikan meningkatkan buffer):linstor c drbd-options --protocol A --after-sb-0pri=discard-zero-changes --after-sb-1pri=discard-secondary --after-sb-2pri=disconnect --max-buffers 131072 --sndbuf-size 10485760 --rcvbuf-size 10485760 --disk-barrier no --disk-flushes no --c-max-rate 4194304 --c-fill-target 1048576
Perhatikan bahwa jika simpul utama gagal, sebagian kecil data mungkin tidak mencapai replika.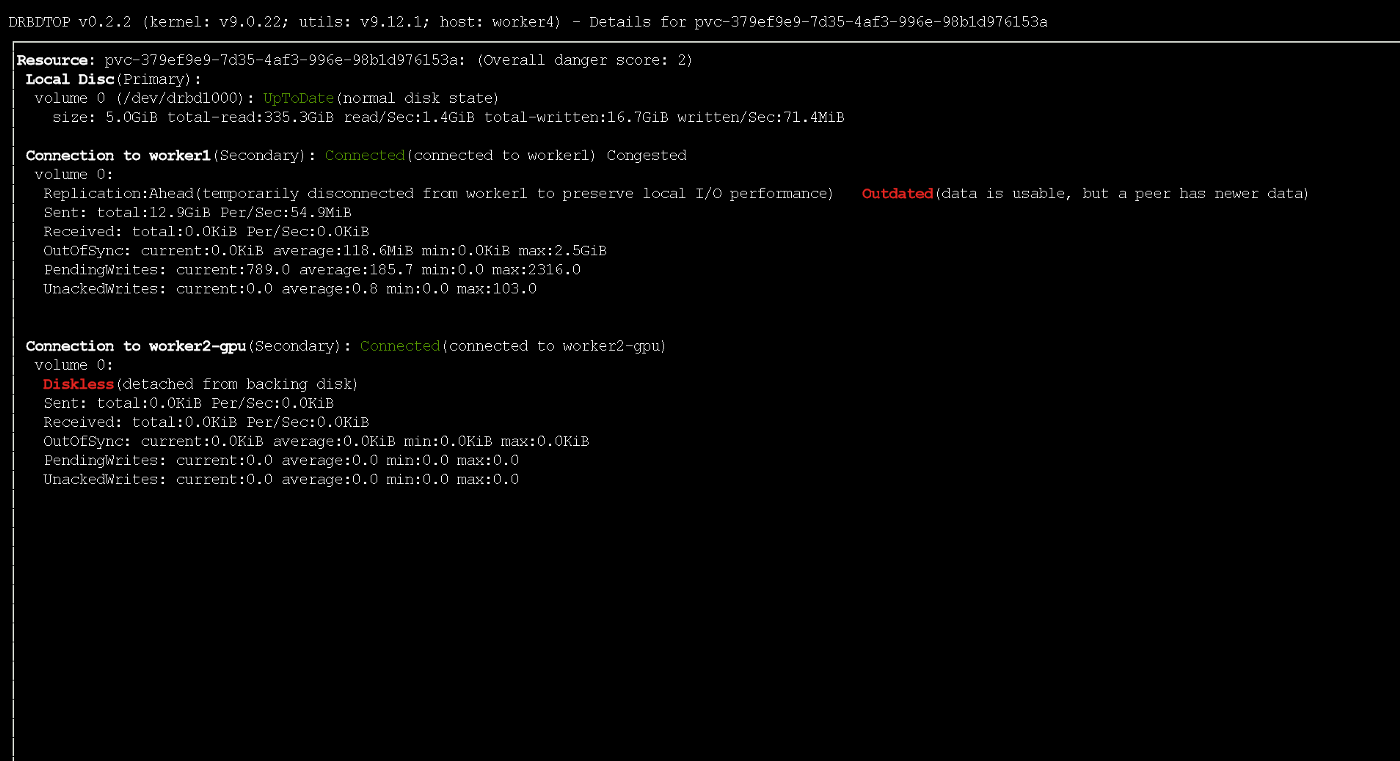 Selama perekaman aktif, node sementara menerima status kedaluwarsa menggunakan protokol ASYNC
Selama perekaman aktif, node sementara menerima status kedaluwarsa menggunakan protokol ASYNCPengujian
Semua tolok ukur dilakukan menggunakan Pekerjaan berikut:kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: dbench
spec:
storageClassName: STORAGE_CLASS
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
---
apiVersion: batch/v1
kind: Job
metadata:
name: dbench
spec:
template:
spec:
containers:
- name: dbench
image: sotoaster/dbench:latest
imagePullPolicy: IfNotPresent
env:
- name: DBENCH_MOUNTPOINT
value: /data
- name: FIO_SIZE
value: 1G
volumeMounts:
- name: dbench-pv
mountPath: /data
restartPolicy: Never
volumes:
- name: dbench-pv
persistentVolumeClaim:
claimName: dbench
backoffLimit: 4
Penundaan antara mesin adalah sebagai berikut: ttl=61 time=0.211 ms. Throughput yang diukur di antara mereka adalah 943 Mbps. Semua node menjalankan Ubuntu 18.04. Hasil ( tabel di sheetsu.com )
Seperti dapat dilihat dari tabel, Piraeus dan StorageOS menunjukkan hasil terbaik. Pemimpinnya adalah Piraeus dengan dua replika dan protokol asinkron.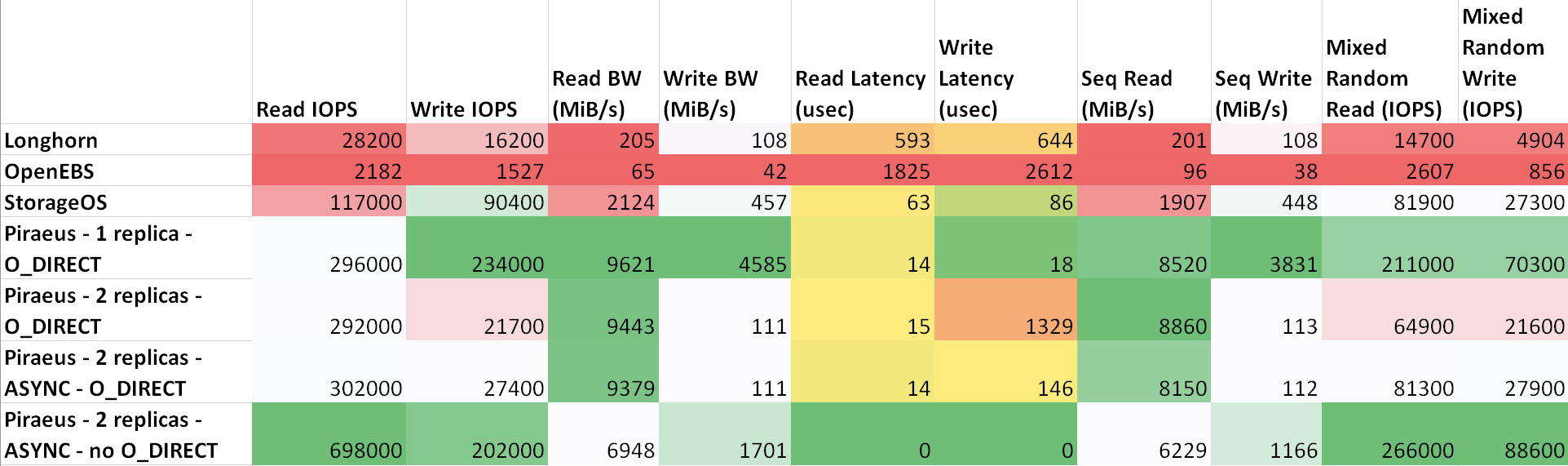
temuan
Saya membuat perbandingan sederhana dan mungkin tidak terlalu benar dari beberapa solusi penyimpanan di Kubernetes.Kebanyakan saya menyukai Longhorn karena GUI yang bagus dan integrasi dengan Rancher. Namun, hasilnya tidak menginspirasi. Jelas, pengembang terutama berfokus pada keamanan dan kebenaran, meninggalkan kecepatan untuk nanti.Untuk beberapa waktu sekarang saya telah menggunakan Linstor / Piraeus di lingkungan produksi beberapa proyek. Sejauh ini, semuanya baik-baik saja: disk dibuat dan dihapus, node di-restart tanpa downtime ...Menurut saya, Piraeus cukup siap untuk digunakan dalam produksi, tetapi perlu ditingkatkan. Saya menulis tentang beberapa bug di saluran proyek di Slack, tetapi sebagai tanggapan mereka hanya menyarankan saya untuk mengajar Kubernetes (dan ini benar, karena saya masih belum memahaminya dengan baik). Setelah korespondensi sedikit, saya masih berhasil meyakinkan para penulis bahwa ada bug dalam skrip init mereka. Kemarin, setelah memperbarui kernel dan me-reboot, node menolak untuk boot. Ternyata kompilasi skrip yang mengintegrasikan modul drbd ke dalam kernel gagal . Kembalikan ke versi kernel sebelumnya menyelesaikan masalah.Itu saja, secara umum. Mengingat bahwa mereka menerapkannya di atas drbd, itu ternyata menjadi solusi yang sangat andal dengan kinerja yang sangat baik. Jika ada masalah, Anda dapat langsung menghubungi manajemen drbd dan memperbaikinya. Di Internet ada banyak pertanyaan dan contoh tentang topik ini.Jika saya melakukan sesuatu yang salah, jika sesuatu dapat diperbaiki atau Anda perlu bantuan, hubungi saya di Twitter atau di GitHub .PS dari penerjemah
Baca juga di blog kami: