Dalam artikel ini saya akan memberi tahu dan menunjukkan contoh bagaimana seseorang dengan pengalaman Ilmu Data minimal mampu mengumpulkan data dari forum dan membuat pemodelan tematik posting menggunakan model LDA, dan mengungkapkan topik menyakitkan bagi orang-orang dengan intoleransi seliaka.Tahun lalu saya perlu segera meningkatkan pengetahuan saya di bidang pembelajaran mesin. Saya seorang manajer produk untuk Ilmu Data, Pembelajaran Mesin dan AI, atau dengan cara lain Manajer Produk Teknis AI / ML. Keterampilan bisnis dan kemampuan untuk mengembangkan produk, seperti biasanya dalam proyek yang ditujukan untuk pengguna yang tidak berada di bidang teknis, tidak cukup. Anda perlu memahami konsep teknis dasar industri ML, dan jika perlu, dapat menulis sendiri contoh untuk mendemonstrasikan produk.Selama sekitar 5 tahun saya telah mengembangkan proyek-proyek Front-end, mengembangkan aplikasi web yang kompleks pada JS dan React, tetapi saya tidak pernah berurusan dengan pembelajaran mesin, laptop dan algoritma. Karena itu, ketika saya melihat berita dari Otus bahwa mereka membuka kursus eksperimental lima bulan tentang Pembelajaran Mesin , tanpa ragu-ragu, saya memutuskan untuk menjalani uji coba dan melanjutkan kursus.Selama lima bulan, setiap minggu ada kuliah dan pekerjaan rumah selama dua jam untuk mereka. Di sana saya belajar tentang dasar-dasar ML: berbagai algoritma regresi, klasifikasi, ansambel model, peningkatan gradien, dan bahkan teknologi cloud yang sedikit terpengaruh. Pada prinsipnya, jika Anda mendengarkan dengan seksama setiap ceramah, maka ada cukup banyak contoh dan penjelasan untuk pekerjaan rumah. Tapi tetap saja, kadang-kadang, seperti dalam proyek pengkodean lainnya, saya harus beralih ke dokumentasi. Mengingat pekerjaan penuh waktu saya, cukup mudah untuk belajar, karena saya selalu dapat merevisi catatan kuliah online.Pada akhir pelatihan kursus ini, semua orang harus mengambil tugas akhir. Gagasan untuk proyek tersebut muncul secara spontan, pada saat itu saya memulai pelatihan kewirausahaan di Stanford, di mana saya bergabung dengan tim yang mengerjakan proyek untuk orang-orang dengan intoleransi seliaka. Selama riset pasar, saya tertarik untuk mengetahui kekhawatiran apa, apa yang mereka bicarakan, keluhan orang-orang dengan fitur ini.Ketika penelitian berlanjut, saya menemukan forum di celiac.comdengan sejumlah besar bahan pada penyakit celiac. Jelas bahwa menggulir secara manual dan membaca lebih dari 100 ribu posting tidak praktis. Maka muncul ide bagi saya, untuk menerapkan pengetahuan yang saya terima dalam kursus ini: untuk mengumpulkan semua pertanyaan dan komentar dari forum dari topik tertentu dan membuat pemodelan tematik dengan kata-kata yang paling umum di masing-masingnya.Langkah 1. Pengumpulan data dari forum
Forum ini terdiri dari banyak topik dengan berbagai ukuran. Secara total, forum ini memiliki sekitar 115.000 topik dan sekitar satu juta posting, dengan komentar tentangnya. Saya tertarik pada subtopik khusus "Mengatasi Penyakit Celiac" , yang secara harfiah berarti "Mengatasi penyakit Celiac", jika dalam bahasa Rusia, itu berarti lebih "melanjutkan hidup dengan diagnosis penyakit celiac dan entah bagaimana mengatasi kesulitan". Sub-topik ini berisi sekitar 175.000 komentar.Pengunduhan data terjadi dalam dua tahap. Untuk memulainya, saya harus membaca semua halaman di bawah topik dan mengumpulkan semua tautan ke semua posting, sehingga pada langkah berikutnya, saya sudah bisa mengumpulkan komentar.url_coping = 'https://www.celiac.com/forums/forum/5-coping-with-celiac-disease/'
Karena forum ini ternyata sudah sangat tua, saya sangat beruntung dan situsnya tidak memiliki masalah keamanan, jadi untuk mengumpulkan data, cukup menggunakan kombinasi Agen-Pengguna dari fake_useragent , perpustakaan Beautiful Soup untuk bekerja dengan markup html dan mengetahui jumlah halaman:
def get_pages_count(url):
response = requests.get(url, headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
last_page_section = soup.find('li', attrs = {'class':'ipsPagination_last'})
if (last_page_section):
count_link = last_page_section.find('a')
return int(count_link['data-page'])
else:
return 1
coping_pages_count = get_pages_count(url_coping)
Dan kemudian unduh HTML DOM dari setiap halaman untuk dengan mudah dan mudah menarik data dari mereka menggunakan pustaka BeautifulSoup Python .
def retrieve_pages(pages_count, url):
pages = []
for page in range(pages_count):
response = requests.get('{}page/{}'.format(url, page), headers={'User-Agent': UserAgent().chrome})
soup = BeautifulSoup(response.content, 'html.parser')
pages.append(soup)
return pages
coping_pages = retrieve_pages(coping_pages_count, url_coping)
Untuk mengunduh data, saya perlu menentukan bidang yang diperlukan untuk analisis: menemukan nilai bidang ini di DOM dan menyimpannya dalam kamus. Saya sendiri datang dari latar belakang Front-end, jadi bekerja dengan rumah dan benda-benda sepele bagi saya.def collect_post_info(pages):
posts = []
for page in pages:
posts_list_soup = page.find('ol', attrs = {'class': 'ipsDataList'}).findAll('li', attrs = {'class': 'ipsDataItem'})
for post_soup in posts_list_soup:
post = {}
post['id'] = uuid.uuid4()
title_section = post_soup.find('span', attrs = {'class':'ipsType_break ipsContained'})
if (title_section):
title_section_a = title_section.find('a')
post['title'] = title_section_a['title']
post['url'] = title_section_a['data-ipshover-target']
author_section = post_soup.find('div', attrs = {'class':'ipsDataItem_meta'})
if (author_section):
author_section_a = post_soup.find('a')
author_section_time = post_soup.find('time')
post['author'] = author_section_a['data-ipshover-target']
post['last_action'] = author_section_time['datetime']
stats_section = post_soup.find('ul', attrs = {'class':'ipsDataItem_stats'})
if (stats_section):
stats_section_replies = post_soup.find('span', attrs = {'class':'ipsDataItem_stats_number'})
if (stats_section_replies):
post['replies'] = stats_section_replies.getText()
stats_section_views = post_soup.find('li', attrs = {'class':'ipsType_light'})
if (stats_section_views):
post['views'] = stats_section_views.find('span', attrs = {'class':'ipsDataItem_stats_number'}).getText()
posts.append(post)
return posts
Secara total, saya mengumpulkan sekitar 15.450 posting dalam topik ini.coping_posts_info = collect_post_info(coping_pages)
Sekarang mereka dapat ditransfer ke DataFrame sehingga mereka berbaring di sana dengan indah, dan pada saat yang sama menyimpannya dalam file csv sehingga Anda tidak perlu menunggu lagi ketika data dikumpulkan dari situs jika notebook secara tidak sengaja rusak atau saya secara tidak sengaja mendefinisikan ulang variabel di mana.df_coping = pd.DataFrame(coping_posts_info,
columns =['title', 'url', 'author', 'last_action', 'replies', 'views'])
df_coping['replies'] = df_coping['replies'].astype(int)
df_coping['views'] = df_coping['views'].apply(lambda x: int(x.replace(',','')))
df_coping.to_csv('celiac_forum_coping.csv', sep=',')
Setelah mengumpulkan koleksi posting, saya melanjutkan untuk mengumpulkan komentar sendiri.def collect_postpage_details(pages, df):
comments = []
for i, page in enumerate(pages):
articles = page.findAll('article')
for k, article in enumerate(articles):
comment = {
'url': df['url'][i]
}
if(k == 0):
comment['question'] = 1
else:
comment['question'] = 0
comment_section = article.find('div', attrs = {'class':'ipsComment_content'})
if (comment_section):
comment_section_p = comment_section.find('p')
if(comment_section_p):
comment['comment'] = comment_section_p.getText()
comment['date'] = comment_section.find('time')['datetime']
author_section = article.find('strong')
if (author_section):
author_section_url = author_section.find('a')
if (author_section_url):
comment['author'] = author_section_url['data-ipshover-target']
comments.append(comment)
return comments
coping_data = collect_postpage_details(coping_comments_pages, df_coping)
df_coping_comments.to_csv('celiac_forum_coping_comments_1.csv', sep=',')
LANGKAH 2 Analisis Data dan Pemodelan Tematik
Pada langkah sebelumnya, kami mengumpulkan data dari forum dan menerima data akhir dalam bentuk 153777 baris pertanyaan dan komentar.Tetapi data yang dikumpulkan tidak menarik, jadi hal pertama yang ingin saya lakukan adalah analitik yang sangat sederhana: Saya memperoleh statistik untuk 30 topik yang paling banyak dilihat dan 30 topik yang paling banyak dikomentari.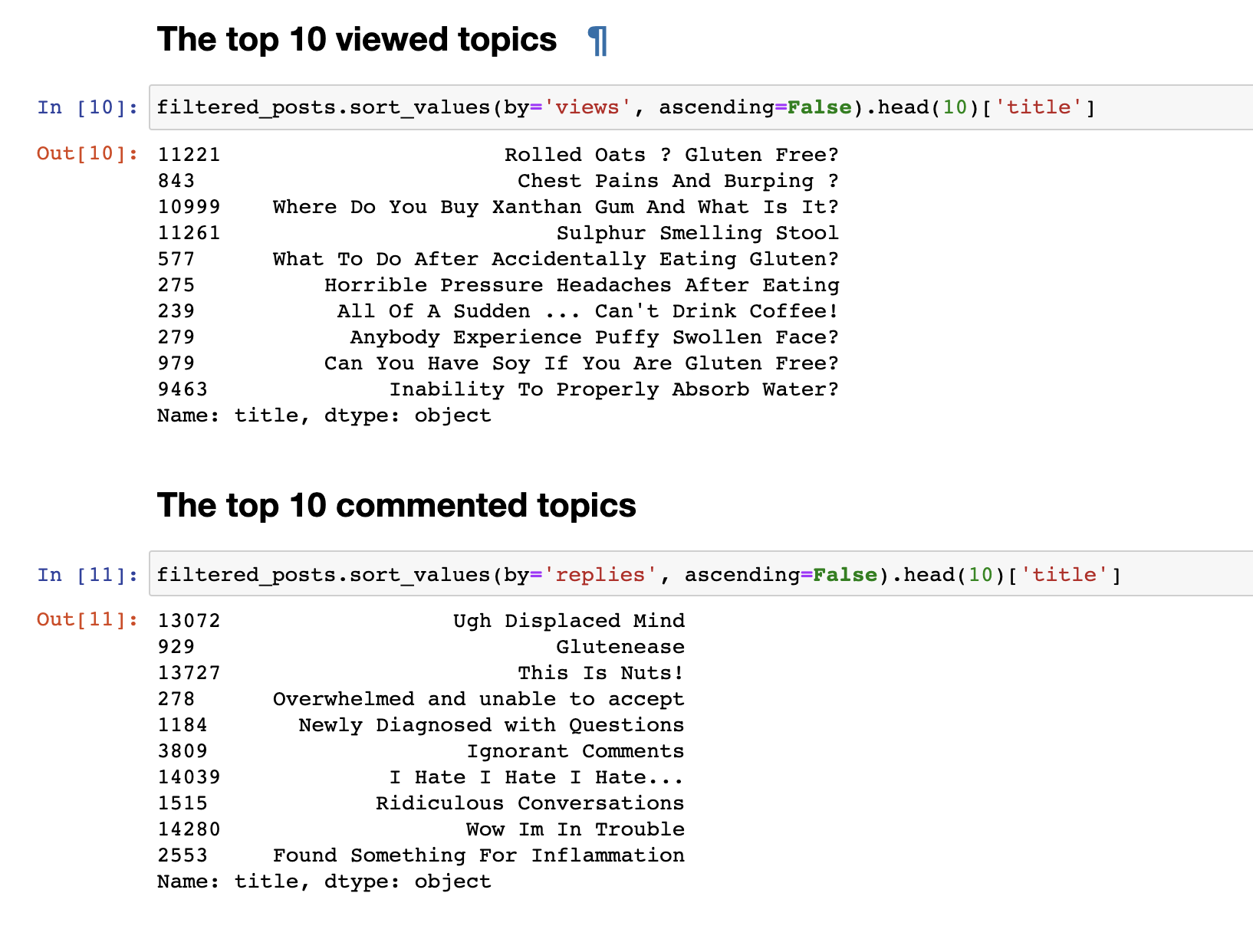 Posting yang paling banyak dilihat tidak sesuai dengan yang paling banyak dikomentari. Judul posting yang dikomentari, bahkan pada pandangan pertama, terlihat. Nama mereka lebih emosional: "Aku benci, aku benci, aku benci" atau " komentar sombong" atau "Wow, aku dalam masalah . " Dan yang paling banyak ditonton memiliki format pertanyaan: "Bisakah saya makan kedelai?", "Mengapa saya tidak bisa menyerap air dengan baik?"lain.Kami melakukan analisis teks sederhana. Untuk langsung ke analisis yang lebih kompleks, Anda perlu menyiapkan data itu sendiri sebelum mengirimkannya ke input model LDA untuk pengelompokan berdasarkan topik. Untuk melakukan ini, singkirkan komentar yang mengandung kurang dari 30 kata, untuk menyaring spam dan komentar pendek yang tidak berarti. Kami membawanya ke huruf kecil.
Posting yang paling banyak dilihat tidak sesuai dengan yang paling banyak dikomentari. Judul posting yang dikomentari, bahkan pada pandangan pertama, terlihat. Nama mereka lebih emosional: "Aku benci, aku benci, aku benci" atau " komentar sombong" atau "Wow, aku dalam masalah . " Dan yang paling banyak ditonton memiliki format pertanyaan: "Bisakah saya makan kedelai?", "Mengapa saya tidak bisa menyerap air dengan baik?"lain.Kami melakukan analisis teks sederhana. Untuk langsung ke analisis yang lebih kompleks, Anda perlu menyiapkan data itu sendiri sebelum mengirimkannya ke input model LDA untuk pengelompokan berdasarkan topik. Untuk melakukan ini, singkirkan komentar yang mengandung kurang dari 30 kata, untuk menyaring spam dan komentar pendek yang tidak berarti. Kami membawanya ke huruf kecil.
def filter_text_words(text, min_words = 30):
text = str(text)
return len(text.split()) > 30
filtered_comments = filtered_comments[filtered_comments['comment'].apply(filter_text_words)]
comments_only = filtered_comments['comment']
comments_only= comments_only.apply(lambda x: x.lower())
comments_only.head()
Hapus kata berhenti yang tidak perlu untuk menghapus pilihan teks kamistop_words = stopwords.words('english')
def remove_stop_words(tokens):
new_tokens = []
for t in tokens:
token = []
for word in t:
if word not in stop_words:
token.append(word)
new_tokens.append(token)
return new_tokens
tokens = remove_stop_words(data_words)
Kami juga menambahkan bigrams dan membentuk sekumpulan kata untuk menyorot frasa stabil, misalnya, seperti gluten_free, support_group , dan frasa lain yang, ketika dikelompokkan, memiliki arti tertentu.
bigram = gensim.models.Phrases(tokens, min_count=5, threshold=100)
bigram_mod = gensim.models.phrases.Phraser(bigram)
bigram_mod.save('bigram_mod.pkl')
bag_of_words = [bigram_mod[w] for w in tokens]
with open('bigrams.pkl', 'wb') as f:
pickle.dump(bag_of_words, f)
Sekarang kami akhirnya siap untuk langsung melatih model LDA itu sendiri.
id2word = corpora.Dictionary(bag_of_words)
id2word.save('id2word.pkl')
id2word.filter_extremes(no_below=3, no_above=0.4, keep_n=3*10**6)
corpus = [id2word.doc2bow(text) for text in bag_of_words]
lda_model = gensim.models.ldamodel.LdaModel(
corpus,
id2word=id2word,
eval_every=20,
random_state=42,
num_topics=30,
passes=5
)
lda_model.save('lda_default_2.pkl')
topics = lda_model.show_topics(num_topics=30, num_words=100, formatted=False)
Di akhir pelatihan, kami akhirnya mendapatkan hasil dari topik yang terbentuk. Yang saya lampirkan di akhir posting ini.for t in range(lda_model.num_topics):
plt.figure(figsize=(15, 10))
plt.imshow(WordCloud(background_color="white", max_words=100, width=900, height=900, collocations=False)
.fit_words(dict(topics[t][1])))
plt.axis("off")
plt.title("Topic #" + themes_headers[t])
plt.show()
Karena mungkin terlihat, topik ternyata cukup berbeda dalam konten satu sama lain. Menurut mereka, menjadi jelas apa yang orang bicarakan dengan intoleransi seliaka. Pada dasarnya, tentang makanan, pergi ke restoran, makanan yang terkontaminasi dengan gluten, rasa sakit yang mengerikan, perawatan, pergi ke dokter, keluarga, kesalahpahaman dan hal-hal lain yang harus dihadapi setiap hari sehubungan dengan masalah mereka.Itu saja. Terima kasih atas perhatiannya. Saya harap Anda menemukan bahan ini menarik dan bermanfaat. Namun, karena saya bukan pengembang DS, jangan menilai dengan ketat. Jika ada sesuatu untuk ditambahkan atau ditingkatkan, saya selalu menerima kritik membangun, tulis.Untuk melihat 30 topik