Halo semuanya! Seperti yang telah Anda ketahui, kami di SE terlibat dalam pengenalan teks (dan tidak hanya) pada dokumen yang berbeda. Hari ini kami ingin membicarakan masalah lain ketika mengenali teks pada latar belakang yang kompleks - tentang mengenali ruang. Secara umum, kita akan berbicara tentang nama pada kartu bank, tetapi pertama-tama, sebuah contoh dengan "hantu" surat itu. Seperti yang Anda lihat, di sini, di sebelah kanan D, distorsi dan latar belakang membentuk fairly yang cukup jelas. Apalagi, jika Anda menunjukkan sel ini secara terpisah dari yang lain, orang tersebut (atau jaringan saraf) pasti akan mengatakan bahwa ada surat.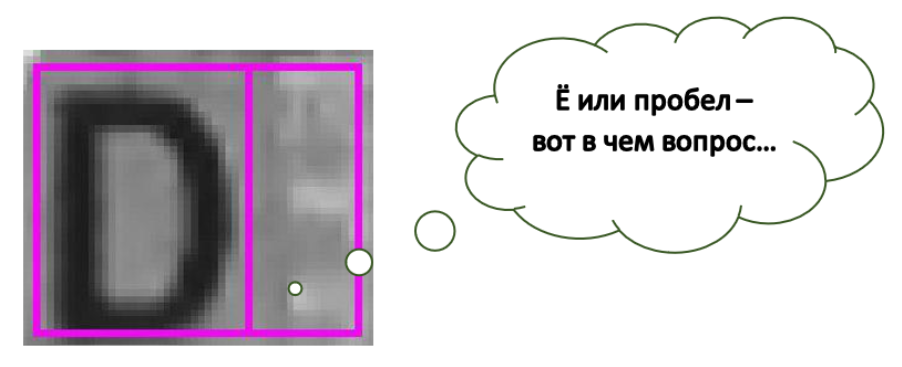 Seperti yang dapat Anda lihat dalam gambar, kami sedang mengerjakan gambar asli dengan latar belakang yang kompleks, sehingga ruang kami sangat beragam. Mereka datang dalam pola, logo, dan kadang-kadang teks. Misalnya, VISA atau MAESTRO pada kartu. Dan kami hanya tertarik pada "ruang kompleks" seperti itu, dan bukan hanya persegi panjang putih. Dan dalam sistem kami, kami menganggap secara terpisah tepat memotong persegi panjang simbol [1].
Seperti yang dapat Anda lihat dalam gambar, kami sedang mengerjakan gambar asli dengan latar belakang yang kompleks, sehingga ruang kami sangat beragam. Mereka datang dalam pola, logo, dan kadang-kadang teks. Misalnya, VISA atau MAESTRO pada kartu. Dan kami hanya tertarik pada "ruang kompleks" seperti itu, dan bukan hanya persegi panjang putih. Dan dalam sistem kami, kami menganggap secara terpisah tepat memotong persegi panjang simbol [1].Dan apa kesulitannya?
Ruang adalah simbol tanpa tanda-tanda khusus. Pada latar belakang yang kompleks, seperti pada gambar, ruang yang terpotong secara terpisah mungkin sulit dibedakan bahkan untuk seseorang.Di sisi lain, pada dasarnya, ruang berbeda dari karakter lain. Jika ABIA diakui atas nama alih-alih ASIA, maka ada peluang untuk memperbaikinya dengan pasca-pemrosesan. Tetapi, jika A IA muncul di sana, tidak mungkin sesuatu akan membantu.Metode tidak digunakan oleh kami
Seringkali spasi difilter menggunakan statistik yang dihitung dari gambar. Sebagai contoh, mereka mempertimbangkan nilai absolut rata-rata dari gradien dalam gambar atau varians dari intensitas piksel dan membagi gambar menjadi spasi dan huruf dengan nilai ambang. Namun, seperti yang dapat dilihat dari grafik, metode tersebut tidak cocok untuk gambar abu-abu dengan latar belakang yang kompleks. Dan karena korelasi eksplisit dari nilai-nilai, bahkan kombinasi metode ini tidak akan berfungsi.Binarisasi favorit semua orang juga tidak akan membantu di sini. Misalnya, dalam gambar ini:Jadi, bagaimana pengakuan dapat ditingkatkan?
Karena seseorang membutuhkan lingkungan ruang untuk melihatnya, adalah logis bagi jaringan untuk menunjukkan setidaknya dua karakter tetangga. Kami tidak ingin menambah input dari jaringan pengenalan, yang, secara umum, bekerja dengan baik (dan mengenali banyak celah). Jadi kita akan mendapatkan jaringan lain - lebih sederhana. Jaringan baru akan memprediksi apa yang ada dalam gambar: dua spasi, dua huruf, spasi dan huruf, atau huruf dan spasi. Dengan demikian, jaringan semacam itu digunakan bersama dengan jaringan pengenalan. Gambar menunjukkan arsitektur yang digunakan: di sebelah kiri adalah arsitektur dari jaringan yang mengenali, di sebelah kanan adalah arsitektur dari jaringan yang diusulkan. Jaringan pengenalan beroperasi pada gambar dengan satu karakter, dan yang baru bekerja pada gambar lebar ganda yang berisi dua karakter yang berdekatan.Sebuah tes?
Untuk pengujian, kami memiliki 4320 baris dengan nama yang mengandung 130.149 karakter, dengan 68.246 spasi. Sebagai permulaan, kami memiliki dua metode. Metode dasar: kami memotong string menjadi karakter dan mengenali setiap karakter secara individual. Metode baru: kami juga memotong serangkaian karakter, menemukan semua spasi dengan jaringan baru, dan mengenali karakter yang tersisa seperti biasa. Tabel tersebut menunjukkan bahwa kualitas pengenalan ruang, serta kualitas keseluruhan, sedang tumbuh, tetapi kualitas pengenalan huruf sedikit melorot.Namun, jaringan inti kami juga mengenali ruang (meskipun lebih buruk dari yang kita inginkan). Dan kita dapat mencoba mengambil keuntungan dari ini. Mari kita lihat kesalahan kedua metode. Dan juga - pada kualitas metode baru berdasarkan kesalahan dasar dan sebaliknya.Untuk metode dasar:Untuk metode baru:Dari tiga tabel terakhir dapat dilihat bahwa untuk meningkatkan sistem perlu menggunakan kombinasi yang seimbang dari peringkat jaringan. Pada saat yang sama, kualitas karakter demi karakter itu menarik, tetapi baris demi baris lebih menarik.Kesimpulan
Ruang - masalah besar dalam perjalanan ke kualitas 100% pengakuan dokumen =) Pada contoh ruang terlihat jelas betapa pentingnya untuk melihat tidak hanya pada karakter individu, tetapi juga pada kombinasi mereka. Namun, jangan langsung memegang artileri berat dan mempelajari jaringan raksasa yang memproses seluruh string. Terkadang hanya jaringan kecil lainnya sudah cukup.Posting ini dibuat menggunakan bahan-bahan dari laporan Konferensi Eropa tentang Pemodelan ECMS 2015 (Bulgaria, Varna): Sheshkus, A. & Arlazarov, VL (2015). Deteksi simbol ruang pada latar belakang kompleks menggunakan konteks visual.Daftar sumber yang digunakan1. YS Chernyshova, AV Sheshkus dan VV Arlazarov, “Kerangka CNN dua langkah untuk pengenalan garis teks dalam gambar yang ditangkap kamera,” IEEE Access, vol. 8, hlm. 32587-32600, 2020, DOI: 10.1109 / ACCESS.2020.2974051.