Dalam sistem ERP yang kompleks, banyak entitas memiliki sifat hierarkis , ketika objek homogen berbaris dalam pohon hubungan leluhur-keturunan - ini adalah struktur organisasi perusahaan (semua cabang, departemen dan kelompok kerja ini), dan katalog produk, dan area kerja, dan geografi titik penjualan, ... Bahkan, tidak ada satu bidang otomatisasi bisnis di mana setidaknya beberapa hierarki tidak akan menjadi hasilnya. Tetapi bahkan jika Anda tidak bekerja "untuk bisnis," Anda masih dapat dengan mudah menemukan hubungan hierarkis. Basi, bahkan skema pohon atau lantai keluarga Anda dari tempat di pusat perbelanjaan adalah struktur yang sama. Ada banyak cara untuk menyimpan pohon seperti itu dalam DBMS, tetapi hari ini kita akan fokus hanya pada satu opsi:
CREATE TABLE hier(
id
integer
PRIMARY KEY
, pid
integer
REFERENCES hier
, data
json
);
CREATE INDEX ON hier(pid);
Dan sementara Anda mengintip ke kedalaman hierarki, itu dengan sabar menunggu bagaimana [non] efektif cara "naif" Anda bekerja dengan struktur seperti itu akan berubah.Mari kita menganalisis tugas-tugas baru yang muncul, penerapannya dalam SQL dan mencoba untuk meningkatkan kinerja mereka.# 1. Seberapa dalam lubang kelinci?
Mari kita lihat, secara pasti, bahwa struktur ini akan mencerminkan subordinasi departemen dalam struktur organisasi: departemen, divisi, sektor, cabang, kelompok kerja ... apa pun sebutan Anda.Pertama, kami menghasilkan 'pohon' elemen 10K kamiINSERT INTO hier
WITH RECURSIVE T AS (
SELECT
1::integer id
, '{1}'::integer[] pids
UNION ALL
SELECT
id + 1
, pids[1:(random() * array_length(pids, 1))::integer] || (id + 1)
FROM
T
WHERE
id < 10000
)
SELECT
pids[array_length(pids, 1)] id
, pids[array_length(pids, 1) - 1] pid
FROM
T;
Mari kita mulai dengan tugas yang paling sederhana - untuk menemukan semua karyawan yang bekerja dalam sektor tertentu, atau dalam hal hierarki - untuk menemukan semua keturunan suatu simpul . Akan lebih baik untuk mendapatkan "kedalaman" keturunan ... Semua ini mungkin diperlukan, misalnya, untuk membangun semacam seleksi kompleks dari daftar ID karyawan ini .Semuanya akan baik-baik saja jika hanya ada beberapa tingkat keturunan ini dan secara kuantitatif dalam selusin, tetapi jika ada lebih dari 5 tingkat, dan sudah ada puluhan keturunan, mungkin ada masalah. Mari kita lihat bagaimana opsi pencarian "down the tree" tradisional ditulis (dan berfungsi). Tapi pertama-tama, kami menentukan node mana yang paling menarik untuk penelitian kami.The "terdalam" sub pohon:WITH RECURSIVE T AS (
SELECT
id
, pid
, ARRAY[id] path
FROM
hier
WHERE
pid IS NULL
UNION ALL
SELECT
hier.id
, hier.pid
, T.path || hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T ORDER BY array_length(path, 1) DESC;
id | pid | path
---------------------------------------------
7624 | 7623 | {7615,7620,7621,7622,7623,7624}
4995 | 4994 | {4983,4985,4988,4993,4994,4995}
4991 | 4990 | {4983,4985,4988,4989,4990,4991}
...
The "terluas" sub pohon:...
SELECT
path[1] id
, count(*)
FROM
T
GROUP BY
1
ORDER BY
2 DESC;
id | count
------------
5300 | 30
450 | 28
1239 | 27
1573 | 25
Untuk kueri ini, kami menggunakan GABUNGAN rekursif yang khas :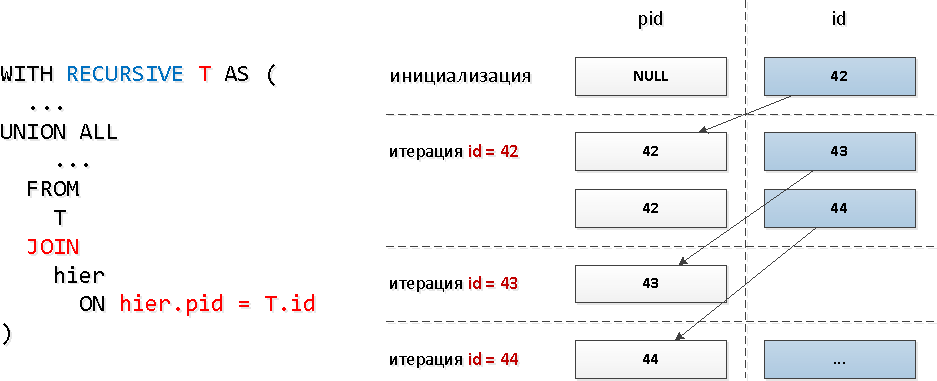 Jelas, dengan model kueri ini, jumlah iterasi akan bertepatan dengan jumlah total keturunan (dan ada beberapa lusin dari mereka), dan ini dapat mengambil sumber daya yang cukup besar, dan, sebagai akibatnya, waktu.Mari kita periksa subtree "terluas":
Jelas, dengan model kueri ini, jumlah iterasi akan bertepatan dengan jumlah total keturunan (dan ada beberapa lusin dari mereka), dan ini dapat mengambil sumber daya yang cukup besar, dan, sebagai akibatnya, waktu.Mari kita periksa subtree "terluas":WITH RECURSIVE T AS (
SELECT
id
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
hier.id
FROM
T
JOIN
hier
ON hier.pid = T.id
)
TABLE T;
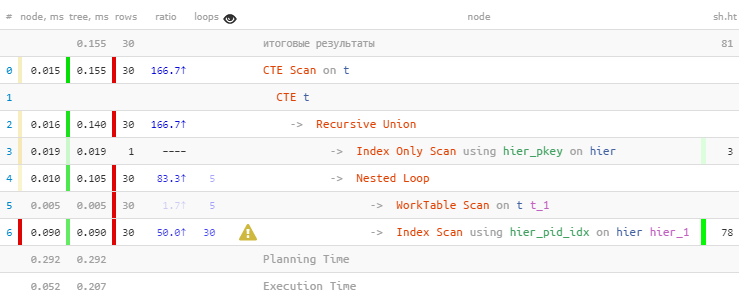 [lihat menjelaskan.tensor.ru]Seperti yang diharapkan, kami menemukan semua 30 entri. Tetapi mereka menghabiskan 60% dari seluruh waktu untuk ini - karena mereka melakukan 30 pencarian pada indeks. Dan kurang - apakah mungkin?
[lihat menjelaskan.tensor.ru]Seperti yang diharapkan, kami menemukan semua 30 entri. Tetapi mereka menghabiskan 60% dari seluruh waktu untuk ini - karena mereka melakukan 30 pencarian pada indeks. Dan kurang - apakah mungkin?Pengoreksian massal dengan indeks
Dan untuk setiap node, apakah kita perlu membuat permintaan indeks yang terpisah? Ternyata tidak - kita dapat membaca dari indeks pada beberapa tombol sekaligus dengan satu panggilan= ANY(array) .Dan di setiap grup pengidentifikasi tersebut, kami dapat mengambil semua ID yang ditemukan pada langkah sebelumnya dengan "node". Artinya, pada setiap langkah selanjutnya kita akan segera mencari semua keturunan dari tingkat tertentu sekaligus .Tapi, itu nasib buruk, dalam pilihan rekursif, Anda tidak dapat merujuk diri Anda sendiri dalam sub-kueri , tetapi kami hanya perlu entah bagaimana memilih dengan tepat apa yang ditemukan di tingkat sebelumnya ... Ternyata Anda tidak dapat membuat sub-kueri ke seluruh sampel, tetapi ke bidang spesifiknya - bisa. Dan bidang ini juga bisa berupa array - yang harus kita gunakanANY.Kedengarannya sedikit liar, tetapi pada diagram - semuanya sederhana.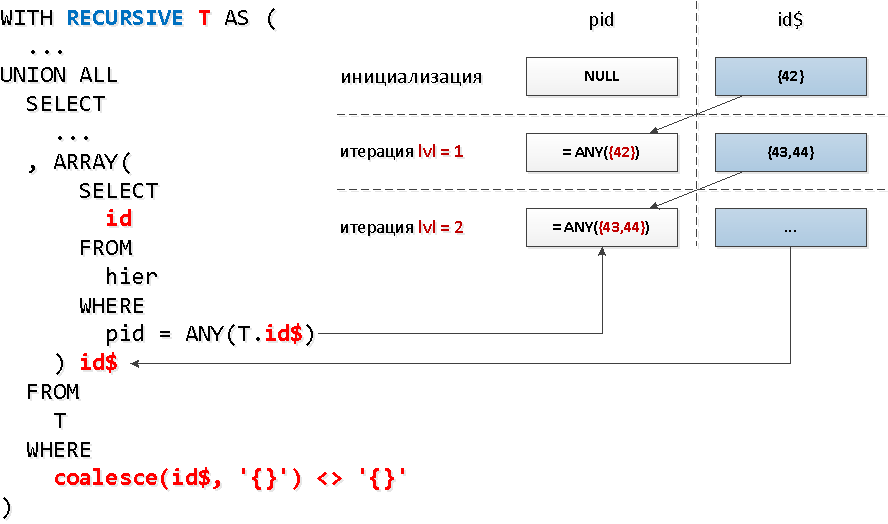
WITH RECURSIVE T AS (
SELECT
ARRAY[id] id$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
ARRAY(
SELECT
id
FROM
hier
WHERE
pid = ANY(T.id$)
) id$
FROM
T
WHERE
coalesce(id$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [lihat menjelaskan.tensor.ru]Dan di sini hal yang paling penting adalah bahkan tidak menang 1,5 kali , tetapi kami mengurangi lebih sedikit buffer, karena kami hanya memiliki 5 panggilan ke indeks, bukan 30!Bonus tambahan adalah kenyataan bahwa setelah pengidentifikasi yang paling tidak akhir akan tetap dipesan oleh "level".
[lihat menjelaskan.tensor.ru]Dan di sini hal yang paling penting adalah bahkan tidak menang 1,5 kali , tetapi kami mengurangi lebih sedikit buffer, karena kami hanya memiliki 5 panggilan ke indeks, bukan 30!Bonus tambahan adalah kenyataan bahwa setelah pengidentifikasi yang paling tidak akhir akan tetap dipesan oleh "level".Tag simpul
Pertimbangan berikutnya yang akan membantu meningkatkan produktivitas adalah bahwa "daun" tidak dapat memiliki anak , yaitu, mereka tidak perlu melihat ke bawah untuk apa pun. Dalam perumusan tugas kami, ini berarti bahwa jika kami mengikuti rantai departemen dan mencapai karyawan, maka tidak perlu mencari lebih jauh di cabang ini.Mari kita masukkan bidang tambahanboolean ke dalam tabel kita , yang akan segera memberi tahu kita apakah entri khusus di pohon kita ini adalah "simpul" —yaitu , jika bisa memiliki anak sama sekali.ALTER TABLE hier
ADD COLUMN branch boolean;
UPDATE
hier T
SET
branch = TRUE
WHERE
EXISTS(
SELECT
NULL
FROM
hier
WHERE
pid = T.id
LIMIT 1
);
Baik! Ternyata hanya sedikit lebih dari 30% elemen pohon yang memiliki keturunan.Sekarang LATERALkita akan menerapkan mekanika yang sedikit berbeda - menghubungkan ke bagian rekursif melalui , yang akan memungkinkan kita untuk segera mengakses bidang "tabel" rekursif, dan menggunakan fungsi agregat dengan kondisi penyaringan berdasarkan pada simpul untuk mengurangi set kunci: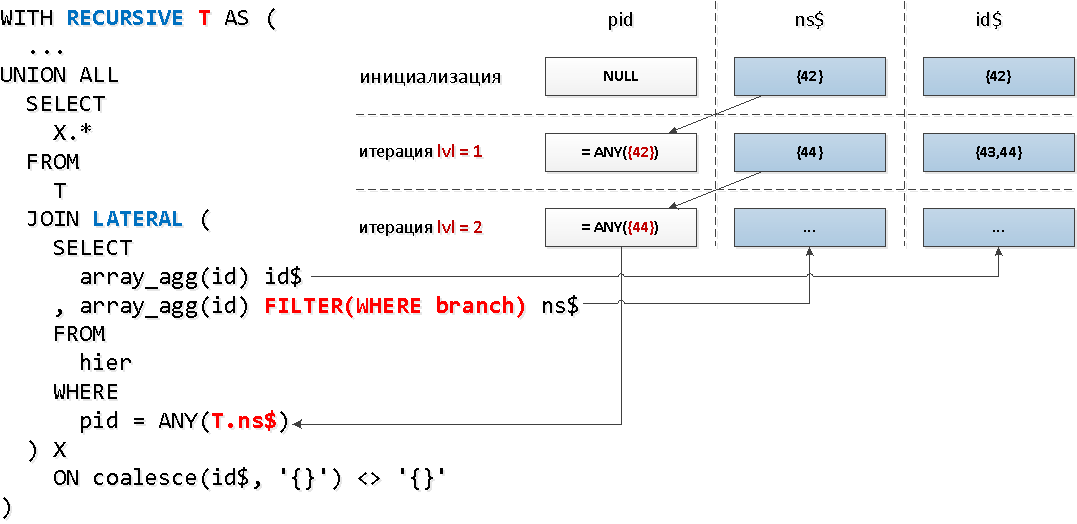
WITH RECURSIVE T AS (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
id = 5300
UNION ALL
SELECT
X.*
FROM
T
JOIN LATERAL (
SELECT
array_agg(id) id$
, array_agg(id) FILTER(WHERE branch) ns$
FROM
hier
WHERE
pid = ANY(T.ns$)
) X
ON coalesce(T.ns$, '{}') <> '{}'
)
SELECT
unnest(id$) id
FROM
T;
 [lihat menjelaskan.tensor.ru]Kami dapat mengurangi daya tarik lain ke indeks dan memenangkan lebih dari 2 kali dalam hal jumlah yang dikurangkan.
[lihat menjelaskan.tensor.ru]Kami dapat mengurangi daya tarik lain ke indeks dan memenangkan lebih dari 2 kali dalam hal jumlah yang dikurangkan.# 2 Kembali ke akar
Algoritma ini akan berguna jika Anda perlu mengumpulkan catatan untuk semua elemen “up the tree”, sambil mempertahankan informasi tentang lembar sumber mana (dan dengan indikator mana) yang menyebabkannya jatuh ke dalam sampel - misalnya, untuk menghasilkan laporan ringkasan dengan agregasi ke node.Selanjutnya harus diambil secara eksklusif sebagai bukti konsep, karena permintaan sangat rumit. Tetapi jika itu mendominasi database Anda - ada baiknya mempertimbangkan penggunaan teknik-teknik tersebut.Mari kita mulai dengan beberapa pernyataan sederhana:- Lebih baik membaca catatan yang sama dari database hanya sekali .
- Entri dari database lebih efisien dibaca dalam "bundel" daripada secara individual.
Sekarang mari kita coba mendesain query yang kita butuhkan.Langkah 1
Jelas, pada inisialisasi rekursi (di mana tanpa itu!) Kita harus mengurangi catatan daun sendiri dari set pengidentifikasi sumber:WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
...
Jika terasa aneh bagi seseorang bahwa "set" disimpan dalam string, bukan array, maka ada penjelasan sederhana. Untuk string, ada fungsi "mengelem" agregat bawaan string_agg, tetapi untuk array, no. Meskipun tidak sulit untuk mengimplementasikannya sendiri .Langkah 2
Sekarang kita akan mendapatkan satu set ID bagian yang perlu dikurangi lebih lanjut. Hampir selalu, mereka akan digandakan dalam catatan berbeda dari set sumber - jadi kami akan mengelompokkannya , sambil menjaga informasi tentang sumber meninggalkan.Tapi di sini tiga masalah menunggu kita:- Bagian "sub-rekursif" dari kueri tidak dapat berisi fungsi agregat c
GROUP BY. - Panggilan ke "tabel" rekursif tidak bisa dalam subquery bersarang.
- Kueri di bagian rekursif tidak dapat berisi CTE.
Untungnya, semua masalah ini cukup mudah dilewati. Mari kita mulai dari akhir.CTE di bagian rekursif
Ini bukan cara kerjanya:WITH RECURSIVE tree AS (
...
UNION ALL
WITH T (...)
SELECT ...
)
Dan itu berhasil, kurung memutuskan!WITH RECURSIVE tree AS (
...
UNION ALL
(
WITH T (...)
SELECT ...
)
)
Permintaan bersarang untuk "tabel" rekursif
Hmm ... Panggilan ke CTE rekursif tidak bisa di subquery. Tapi itu bisa di dalam CTE! Sub-permintaan sudah dapat merujuk ke CTE ini!KELOMPOK OLEH rekursi di dalam
Itu tidak menyenangkan, tapi ... Kami juga memiliki cara sederhana untuk mensimulasikan GROUP BY menggunakan DISTINCT ONfungsi jendela!SELECT
(rec).pid id
, string_agg(chld::text, ',') chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
GROUP BY 1
Dan itu berhasil!SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
Sekarang kita melihat mengapa ID numerik berubah menjadi teks - sehingga mereka dapat direkatkan dengan koma!Langkah 3
Sebagai penutup, kita tidak memiliki apa pun yang tersisa:- kami membaca catatan "bagian" pada satu set ID yang dikelompokkan
- cocokkan bagian yang dikurangi dengan "set" lembar sumber
- "Rentangkan" set string menggunakan
unnest(string_to_array(chld, ',')::integer[])
WITH RECURSIVE tree AS (
SELECT
rec
, id::text chld
FROM
hier rec
WHERE
id = ANY('{1,2,4,8,16,32,64,128,256,512,1024,2048,4096,8192}'::integer[])
UNION ALL
(
WITH prnt AS (
SELECT DISTINCT ON((rec).pid)
(rec).pid id
, string_agg(chld::text, ',') OVER(PARTITION BY (rec).pid) chld
FROM
tree
WHERE
(rec).pid IS NOT NULL
)
, nodes AS (
SELECT
rec
FROM
hier rec
WHERE
id = ANY(ARRAY(
SELECT
id
FROM
prnt
))
)
SELECT
nodes.rec
, prnt.chld
FROM
prnt
JOIN
nodes
ON (nodes.rec).id = prnt.id
)
)
SELECT
unnest(string_to_array(chld, ',')::integer[]) leaf
, (rec).*
FROM
tree;
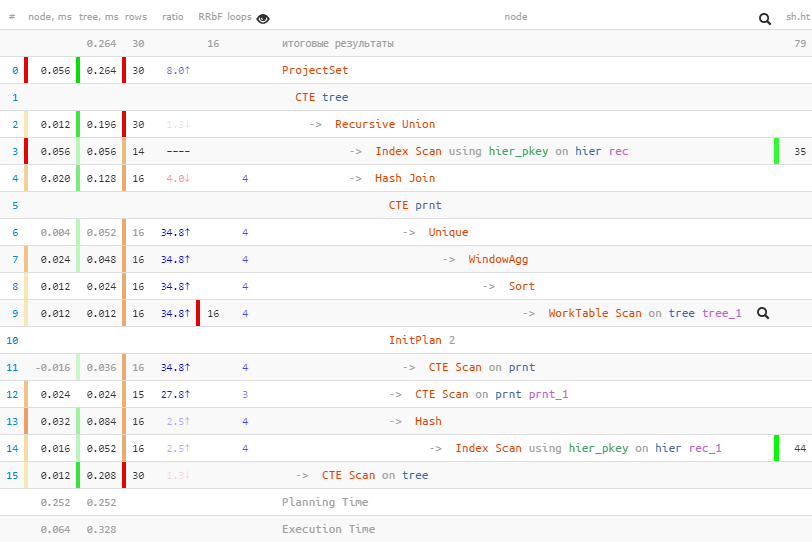 [ explain.tensor.ru]
[ explain.tensor.ru]