Di Uchi.ru, kami mencoba untuk meluncurkan bahkan peningkatan kecil dengan tes A / B, ada lebih dari 250 dari mereka selama tahun akademik ini. Tes A / B adalah alat pengujian perubahan yang kuat, yang tanpanya sulit membayangkan perkembangan normal dari produk Internet. Pada saat yang sama, meskipun kesederhanaan yang tampak, kesalahan serius dapat dibuat selama tes A / B baik pada tahap desain percobaan dan dalam menyimpulkan hasilnya. Dalam artikel ini saya akan berbicara tentang beberapa aspek teknis dari tes: bagaimana kita menentukan periode pengujian, meringkas dan bagaimana menghindari hasil yang salah ketika tes selesai lebih cepat dari jadwal dan ketika menguji beberapa hipotesis sekaligus. Skema pengujian A / B tipikal untuk kami (dan bagi banyak orang) terlihat seperti ini:
Skema pengujian A / B tipikal untuk kami (dan bagi banyak orang) terlihat seperti ini:- Kami sedang mengembangkan fitur, tetapi sebelum meluncurkannya ke seluruh audiens, kami ingin memastikan bahwa itu meningkatkan metrik target, misalnya, keterlibatan.
- Kami menentukan periode pengujian diluncurkan.
- Kami membagi pengguna secara acak menjadi dua grup.
- Kami menunjukkan satu grup versi produk dengan fitur (grup eksperimental), yang lain - yang lama (kontrol).
- Dalam prosesnya, kami memantau metrik untuk menghentikan tes yang gagal pada waktunya.
- Setelah tes berakhir, kami membandingkan metrik dalam kelompok eksperimen dan kontrol.
- Jika metrik pada kelompok eksperimen secara statistik lebih baik daripada kelompok kontrol, kami meluncurkan fitur yang diuji sama sekali. Jika tidak ada signifikansi statistik, kami mengakhiri tes dengan hasil negatif.
Segala sesuatu tampak logis dan sederhana, iblis, seperti biasa, dalam detail.Signifikansi statistik, kriteria dan kesalahan
Ada elemen keacakan dalam tes A / B: metrik grup tidak hanya bergantung pada fungsionalitasnya, tetapi juga pada apa yang pengguna lakukan dan bagaimana mereka berperilaku. Untuk menarik kesimpulan tentang keunggulan suatu kelompok, Anda perlu mengumpulkan cukup pengamatan dalam ujian, tetapi meskipun demikian Anda tidak kebal dari kesalahan. Mereka dibedakan oleh dua jenis:- Kesalahan jenis pertama terjadi jika kita memperbaiki perbedaan antara kelompok, meskipun pada kenyataannya itu tidak ada. Teks juga akan berisi istilah yang setara - hasil positif palsu. Artikel ini dikhususkan untuk kesalahan seperti itu saja.
- Kesalahan jenis kedua terjadi jika kita memperbaiki ketiadaan perbedaan, meskipun faktanya demikian.
Dengan sejumlah besar percobaan, penting bahwa kemungkinan kesalahan jenis pertama kecil. Itu dapat dikontrol menggunakan metode statistik. Misalnya, kami ingin bahwa dalam setiap percobaan probabilitas kesalahan jenis pertama tidak melebihi 5% (ini hanya nilai yang mudah digunakan, Anda dapat mengambil yang lain untuk kebutuhan Anda sendiri). Kemudian kami akan melakukan percobaan pada tingkat signifikansi 0,05:- Ada tes A / B dengan kelompok kontrol A dan kelompok eksperimen B. Tujuannya adalah untuk memverifikasi bahwa kelompok B berbeda dari kelompok A dalam beberapa metrik.
- Kami merumuskan hipotesis nol statistik: kelompok A dan B tidak berbeda, dan perbedaan yang diamati dijelaskan oleh kebisingan. Secara default, kami selalu berpikir bahwa tidak ada perbedaan sampai hal yang sebaliknya terbukti.
- Kami memeriksa hipotesis dengan aturan matematika yang ketat - kriteria statistik, misalnya, kriteria siswa.
- Hasilnya, kami mendapatkan nilai-p. Itu terletak pada kisaran dari 0 hingga 1 dan berarti probabilitas untuk melihat perbedaan saat ini atau yang lebih ekstrem di antara kelompok-kelompok, asalkan hipotesis nol itu benar, yaitu, dengan tidak adanya perbedaan di antara kelompok-kelompok tersebut.
- Nilai p dibandingkan dengan tingkat signifikansi 0,05. Jika lebih besar, kami menerima hipotesis nol bahwa tidak ada perbedaan, jika tidak kami percaya bahwa ada perbedaan yang signifikan secara statistik antara kelompok.
Hipotesis dapat diuji dengan kriteria parametrik atau nonparametrik. Yang parametrik bergantung pada parameter distribusi sampel dari variabel acak dan memiliki lebih banyak kekuatan (mereka membuat kesalahan jenis kedua lebih jarang), tetapi mereka memaksakan persyaratan pada distribusi variabel acak yang diteliti.Tes parametrik yang paling umum adalah tes Siswa. Untuk dua sampel independen (kasus uji A / B), kadang-kadang disebut kriteria Welch. Kriteria ini bekerja dengan benar jika jumlah yang diteliti didistribusikan secara normal. Mungkin terlihat bahwa pada data nyata, persyaratan ini hampir tidak pernah dipenuhi, tetapi pada kenyataannya tes tersebut membutuhkan distribusi rata-rata sampel yang normal, bukan sampel itu sendiri. Dalam praktiknya, ini berarti bahwa kriteria dapat diterapkan jika Anda memiliki banyak pengamatan dalam tes Anda (puluhan hingga ratusan) dan tidak ada ekor yang sangat panjang dalam distribusi. Sifat distribusi pengamatan awal tidak penting. Pembaca dapat secara independen memverifikasi bahwa kriteria Siswa berfungsi dengan benar bahkan pada sampel yang dihasilkan dari Bernoulli atau distribusi eksponensial.Dari kriteria nonparametrik, kriteria Mann-Whitney populer. Ini harus digunakan jika sampel Anda sangat kecil atau memiliki outlier besar (metode ini membandingkan median, oleh karena itu tahan terhadap outlier). Juga, agar kriteria berfungsi dengan benar, sampel harus memiliki beberapa nilai yang cocok. Dalam praktiknya, kami tidak pernah menerapkan kriteria nonparametrik, dalam tes kami, kami selalu menggunakan kriteria siswa.Masalah pengujian hipotesis berganda
Masalah yang paling jelas dan paling sederhana: jika dalam tes, di samping kelompok kontrol, ada beberapa yang eksperimental, kemudian meringkas hasil dengan tingkat signifikansi 0,05 akan menyebabkan peningkatan ganda dalam proporsi kesalahan jenis pertama. Ini karena, dengan setiap penerapan kriteria statistik, probabilitas kesalahan jenis pertama adalah 5%. Dengan jumlah kelompok dan tingkat signifikansi probabilitas bahwa beberapa kelompok eksperimen akan menang secara kebetulan adalah:
Misalnya, untuk tiga kelompok eksperimen, kami mendapatkan 14,3%, bukannya 5% yang diharapkan. Masalahnya dipecahkan oleh koreksi Bonferroni untuk pengujian hipotesis berganda: Anda hanya perlu membagi tingkat signifikansi dengan jumlah perbandingan (mis. Kelompok) dan bekerja dengannya. Untuk contoh di atas, tingkat signifikansi, dengan mempertimbangkan amandemen, akan menjadi 0,05 / 3 = 0,0167 dan probabilitas setidaknya satu kesalahan dari jenis pertama akan dapat diterima 4,9%.Metode Bukit - Bonferroni— , , , .
p-value ,
:
P-value
. , p-value
, . - , . ( , ) p-value, . A/B- — , — .
Tegasnya, perbandingan kelompok dengan berbagai metrik atau bagian audiens juga tunduk pada masalah beberapa pengujian. Secara formal, cukup sulit untuk memperhitungkan semua cek, karena jumlah mereka sulit untuk diprediksi sebelumnya dan kadang-kadang mereka tidak independen (terutama dalam hal metrik yang berbeda, bukan irisan). Tidak ada resep universal, bergantung pada akal sehat dan ingat bahwa jika Anda memeriksa banyak irisan menggunakan metrik yang berbeda, maka dalam tes apa pun Anda dapat melihat hasil yang signifikan secara statistik. Jadi, seseorang harus berhati-hati, misalnya, terhadap peningkatan yang signifikan dalam retensi hari kelima pengguna ponsel baru dari kota besar.Mengintip masalah
Kasus tertentu dari pengujian hipotesis berganda adalah masalah mengintip. Intinya adalah bahwa nilai-p selama tes dapat secara tidak sengaja jatuh di bawah tingkat signifikansi yang diterima. Jika Anda memantau eksperimen dengan cermat, Anda dapat menangkap momen ini dan membuat kesalahan tentang signifikansi statistik.Misalkan kita pindah dari pengaturan tes yang dijelaskan di awal posting dan memutuskan untuk mengambil stok pada tingkat signifikansi 5% setiap hari (atau hanya lebih dari satu kali selama pengujian). Dengan menyimpulkan, saya mengerti bahwa tes ini positif jika p-value di bawah 0,05, dan kelanjutannya sebaliknya. Dengan strategi ini, pangsa hasil positif palsu akan sebanding dengan jumlah cek dan pada bulan pertama akan mencapai 28%. Perbedaan yang sangat besar tampaknya berlawanan dengan intuisi, oleh karena itu kami beralih ke metodologi pengujian A / A, yang sangat diperlukan untuk mengembangkan skema pengujian A / B.Gagasan tes A / A sederhana: untuk mensimulasikan banyak tes A / B pada data acak dengan pengelompokan acak. Jelas tidak ada perbedaan antara kelompok, sehingga Anda dapat secara akurat memperkirakan proporsi kesalahan jenis pertama dalam skema pengujian A / B Anda. Gif di bawah ini menunjukkan bagaimana nilai-p berubah setiap hari untuk empat tes tersebut. Level signifikansi 0,05 yang sama ditunjukkan oleh garis putus-putus. Ketika nilai-p jatuh di bawah ini, kami mewarnai plot tes dengan warna merah. Jika saat ini hasil tes disimpulkan, itu akan dianggap berhasil.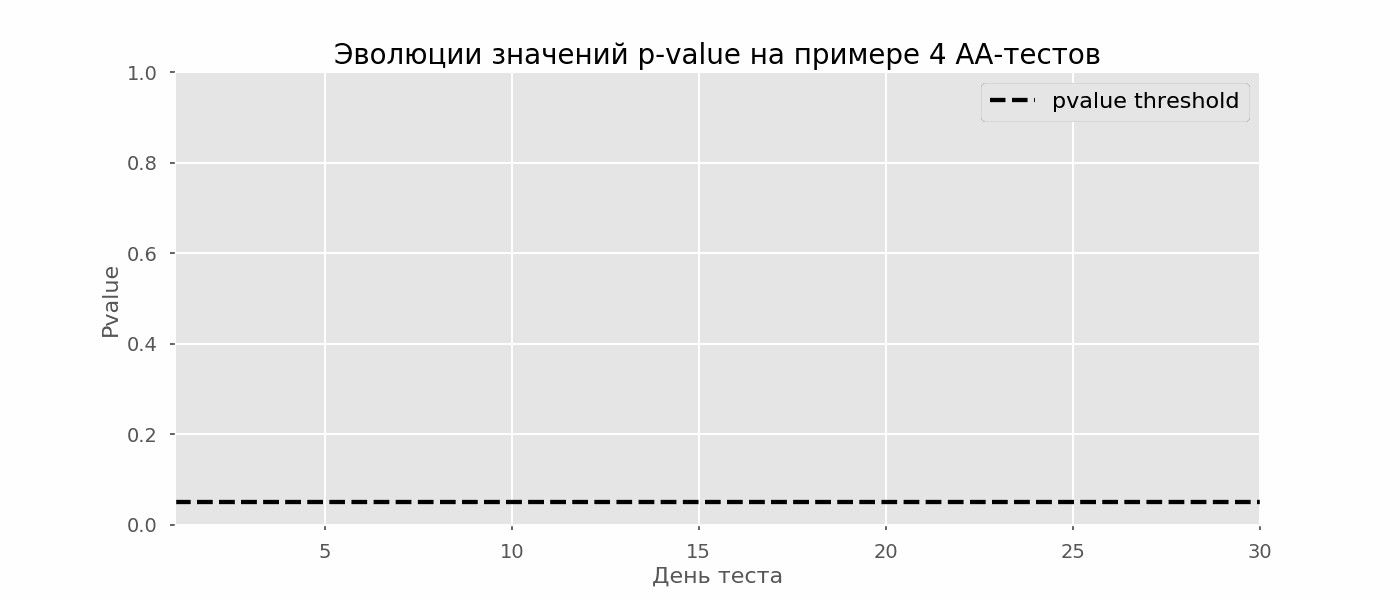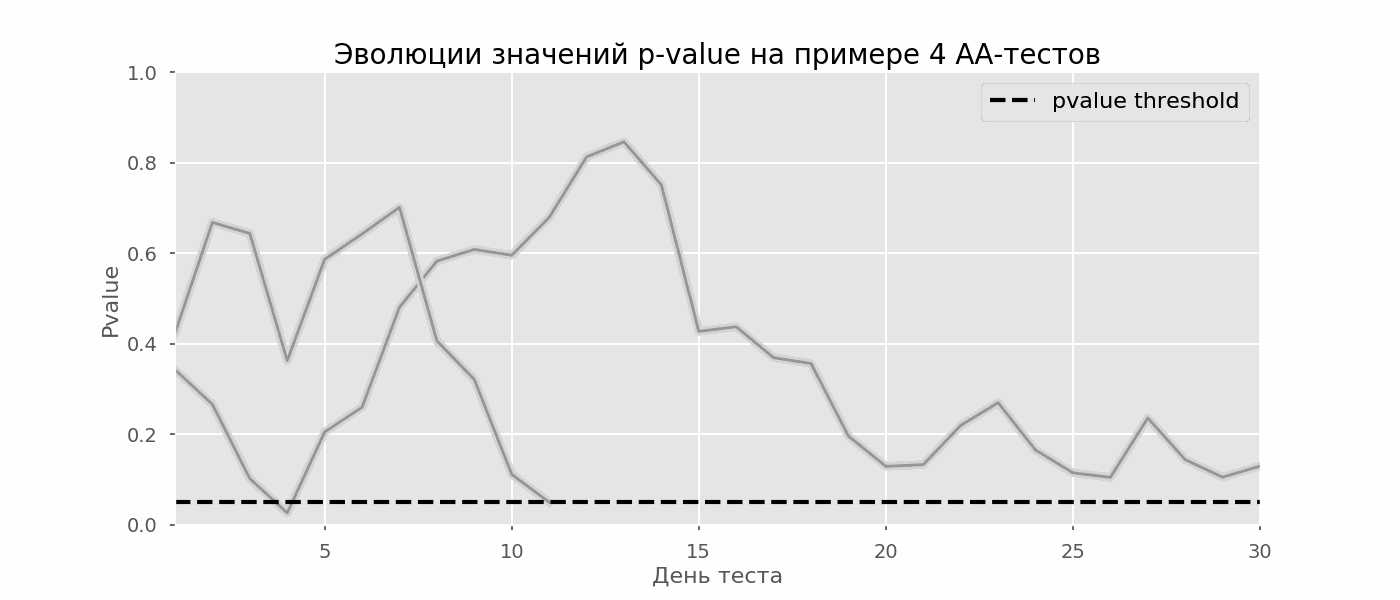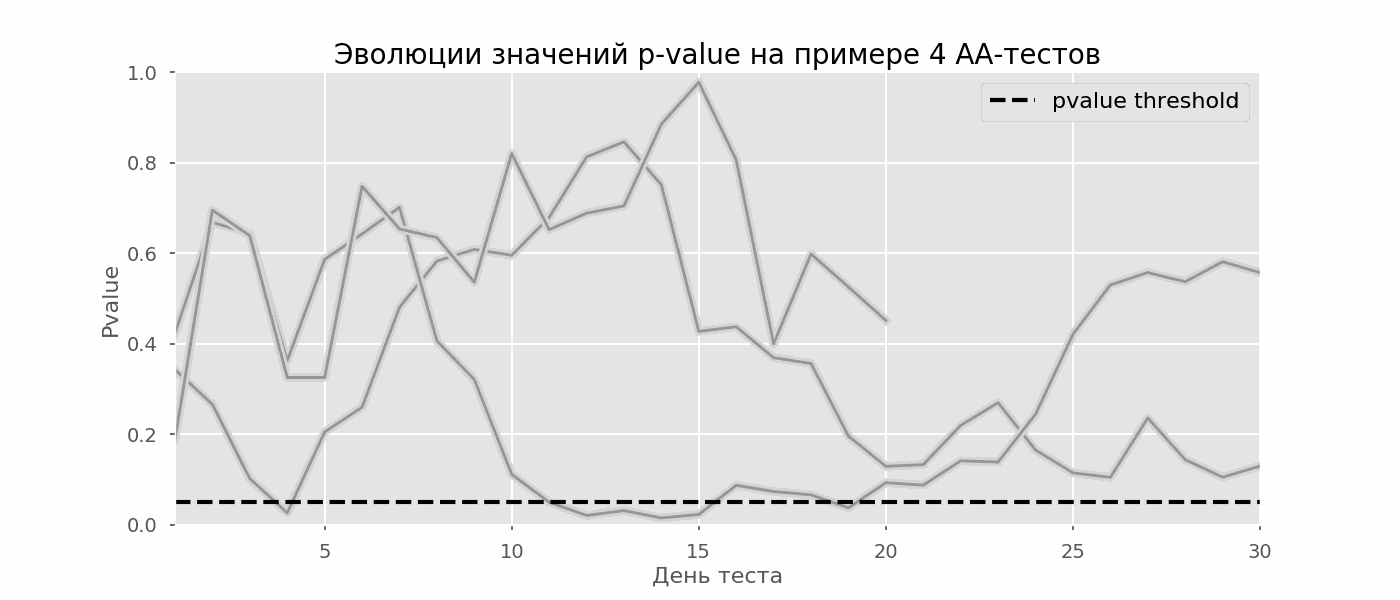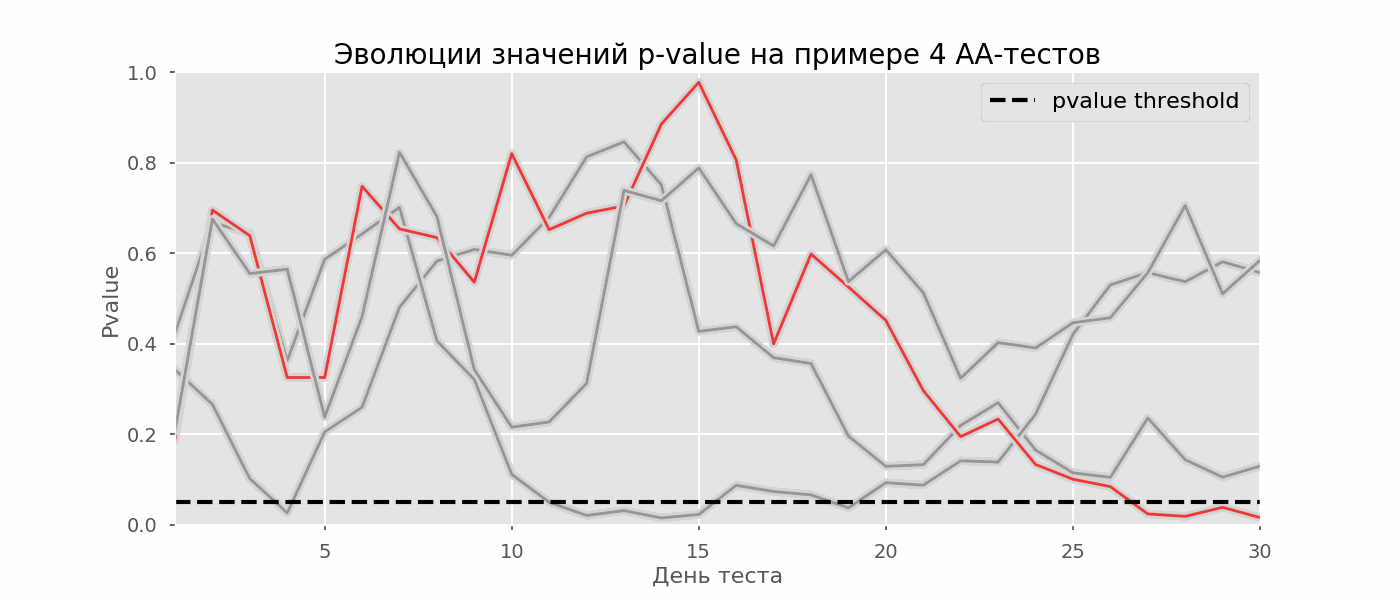 Demikian pula, kami menghitung 10 ribu tes A / A yang berlangsung satu bulan dan membandingkan fraksi hasil positif palsu dalam skema dengan menjumlahkan pada akhir istilah dan setiap hari. Untuk kejelasan, berikut adalah jadwal p-value wandering pada hari pertama untuk 100 simulasi pertama. Setiap baris adalah nilai p dari satu tes, lintasan tes disorot dengan warna merah, yang pada akhirnya keliru dianggap berhasil (semakin kecil semakin baik), garis putus-putus adalah nilai p yang diperlukan untuk mengenali tes sebagai berhasil.
Demikian pula, kami menghitung 10 ribu tes A / A yang berlangsung satu bulan dan membandingkan fraksi hasil positif palsu dalam skema dengan menjumlahkan pada akhir istilah dan setiap hari. Untuk kejelasan, berikut adalah jadwal p-value wandering pada hari pertama untuk 100 simulasi pertama. Setiap baris adalah nilai p dari satu tes, lintasan tes disorot dengan warna merah, yang pada akhirnya keliru dianggap berhasil (semakin kecil semakin baik), garis putus-putus adalah nilai p yang diperlukan untuk mengenali tes sebagai berhasil.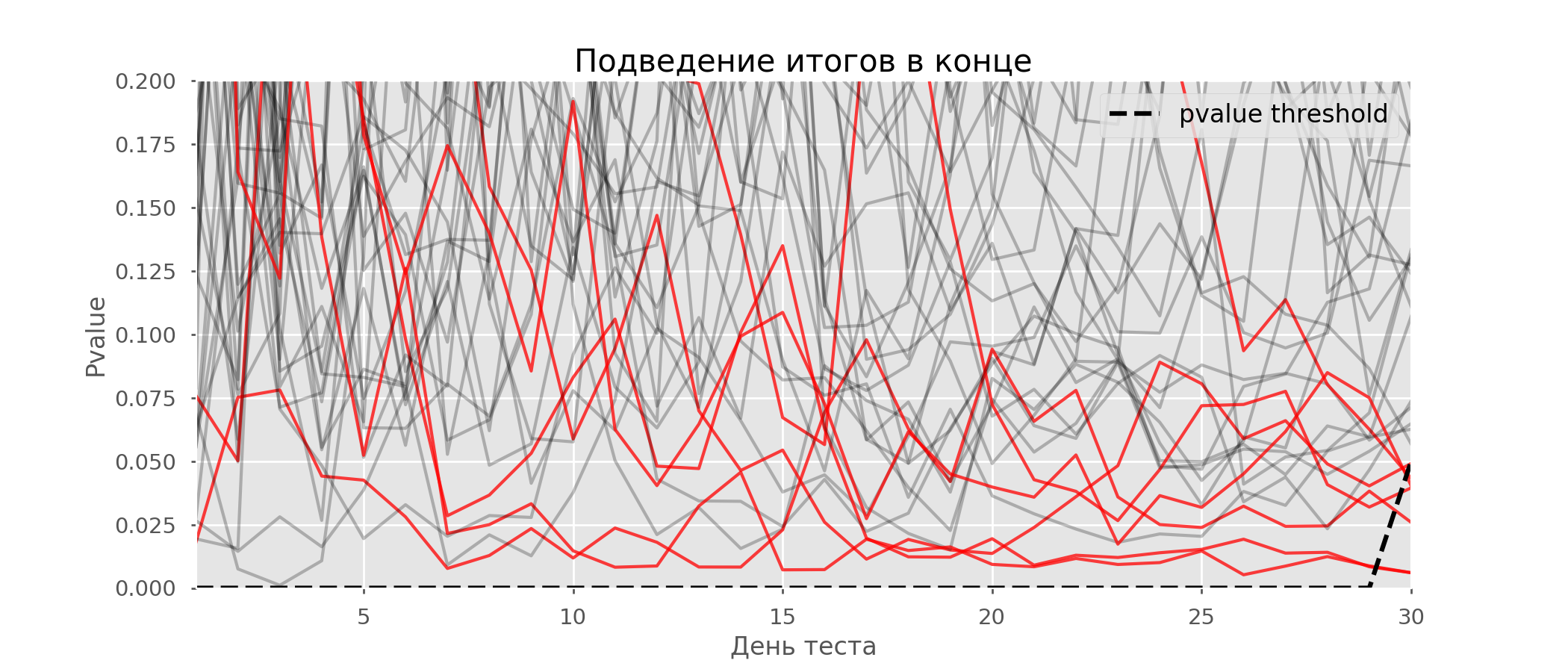 Pada grafik, Anda dapat menghitung 7 tes positif palsu, dan secara total di antara 10 ribu ada 502, atau 5%. Perlu dicatat bahwa nilai p dari banyak tes selama pengamatan turun di bawah 0,05, tetapi pada akhir pengamatan melampaui tingkat signifikansi. Sekarang mari kita evaluasi skema pengujian dengan tanya jawab setiap hari:
Pada grafik, Anda dapat menghitung 7 tes positif palsu, dan secara total di antara 10 ribu ada 502, atau 5%. Perlu dicatat bahwa nilai p dari banyak tes selama pengamatan turun di bawah 0,05, tetapi pada akhir pengamatan melampaui tingkat signifikansi. Sekarang mari kita evaluasi skema pengujian dengan tanya jawab setiap hari: Ada begitu banyak garis merah yang tidak ada yang jelas. Kami akan menggambar ulang dengan memutus garis uji segera setelah nilai-p mereka mencapai nilai kritis:
Ada begitu banyak garis merah yang tidak ada yang jelas. Kami akan menggambar ulang dengan memutus garis uji segera setelah nilai-p mereka mencapai nilai kritis: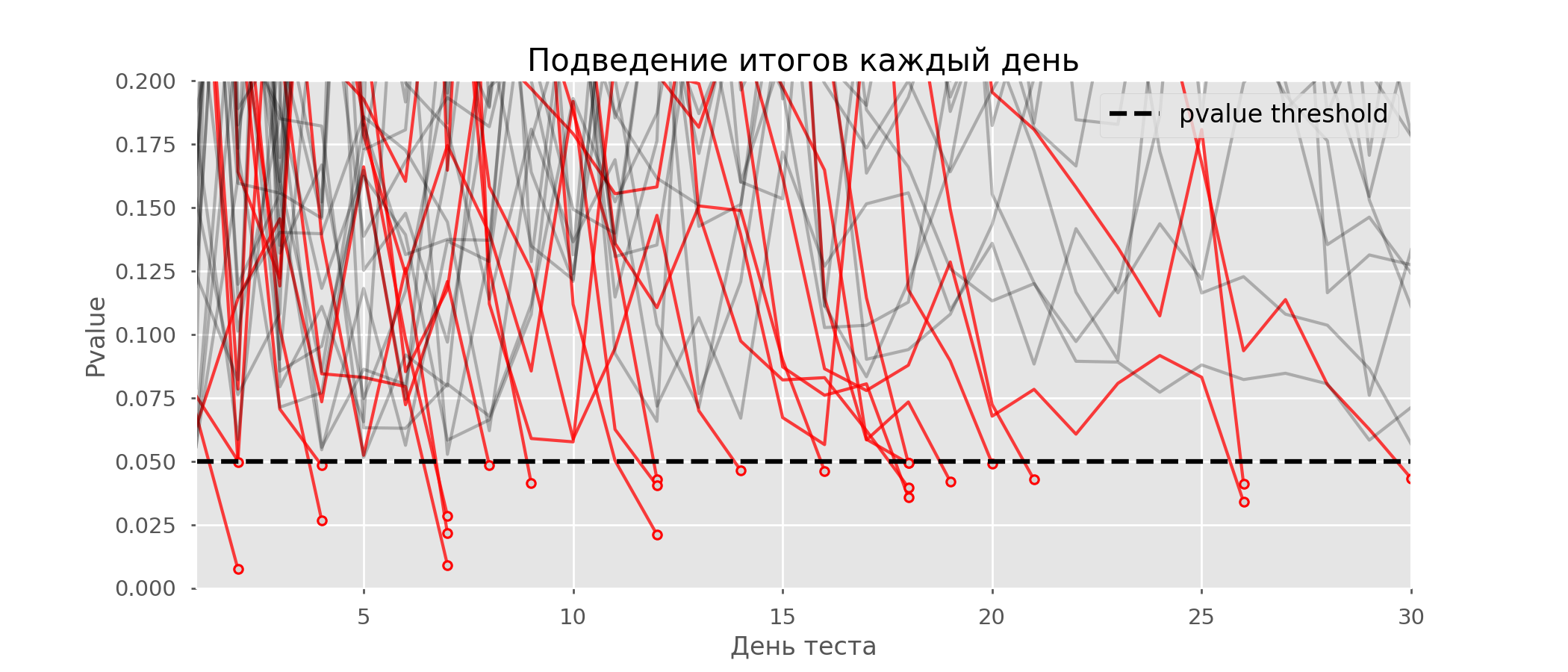 Akan ada total 2813 tes positif palsu dari 10 ribu, atau 28%. Jelas bahwa skema seperti itu tidak dapat dijalankan.Meskipun masalah mengintip adalah kasus khusus pengujian berganda, tidak ada gunanya menerapkan koreksi standar (Bonferroni dan lainnya) karena mereka akan berubah menjadi terlalu konservatif. Grafik di bawah ini menunjukkan persentase hasil positif palsu tergantung pada jumlah kelompok yang diuji (garis merah) dan jumlah peeps (garis hijau).
Akan ada total 2813 tes positif palsu dari 10 ribu, atau 28%. Jelas bahwa skema seperti itu tidak dapat dijalankan.Meskipun masalah mengintip adalah kasus khusus pengujian berganda, tidak ada gunanya menerapkan koreksi standar (Bonferroni dan lainnya) karena mereka akan berubah menjadi terlalu konservatif. Grafik di bawah ini menunjukkan persentase hasil positif palsu tergantung pada jumlah kelompok yang diuji (garis merah) dan jumlah peeps (garis hijau).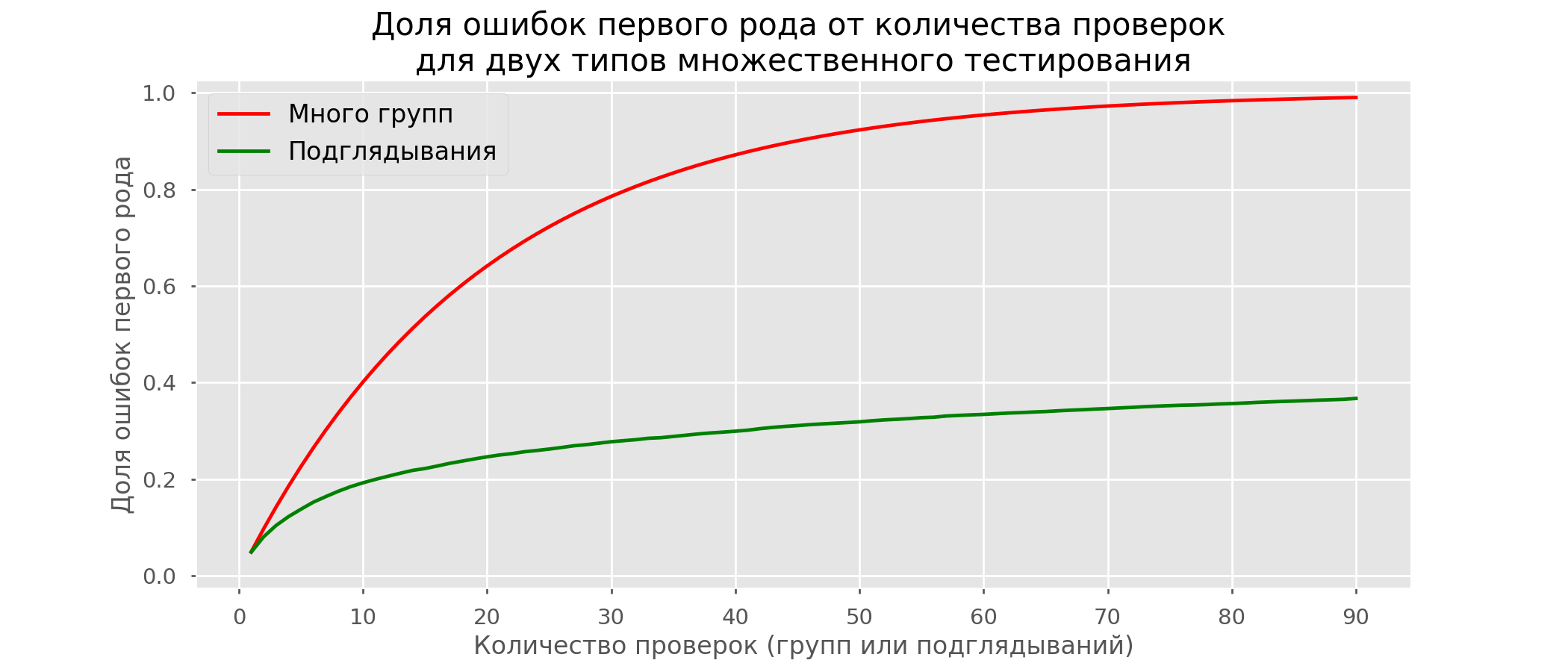 Meskipun pada infinity dan mengintip kita mendekati 1, proporsi kesalahan tumbuh jauh lebih lambat. Ini karena perbandingan dalam hal ini tidak lagi independen.
Meskipun pada infinity dan mengintip kita mendekati 1, proporsi kesalahan tumbuh jauh lebih lambat. Ini karena perbandingan dalam hal ini tidak lagi independen.Pendekatan Bayesian dan Masalah Mengintip Metode Tes Awal
Ada opsi tes yang memungkinkan Anda untuk mengikuti tes secara prematur. Saya akan berbicara tentang mereka berdua: dengan tingkat signifikansi yang konstan (koreksi Pocock) dan tergantung pada jumlah peeps (koreksi O'Brien-Fleming). Sebenarnya, untuk kedua koreksi yang perlu Anda ketahui terlebih dahulu periode tes maksimum dan jumlah pemeriksaan antara awal dan akhir tes. Selain itu, pemeriksaan harus dilakukan pada interval waktu yang kira-kira sama (atau dengan jumlah pengamatan yang sama).Pocock
Metodenya adalah kami merangkum hasil tes setiap hari, tetapi dengan tingkat signifikansi yang berkurang (lebih ketat). Misalnya, jika kita tahu bahwa kita akan melakukan tidak lebih dari 30 cek, maka level signifikansi harus ditetapkan sama dengan 0,006 (dipilih tergantung pada jumlah peeps menggunakan metode Monte Carlo, mis. Secara empiris). Dalam simulasi kami, kami mendapatkan 4% hasil positif palsu - tampaknya, ambang batas dapat ditingkatkan. Meskipun terlihat naif, beberapa perusahaan besar menggunakan metode khusus ini. Ini sangat sederhana dan dapat diandalkan jika Anda membuat keputusan tentang metrik sensitif dan banyak lalu lintas. Misalnya, di Avito, secara default , level signifikansi diatur ke 0,005 .
Meskipun terlihat naif, beberapa perusahaan besar menggunakan metode khusus ini. Ini sangat sederhana dan dapat diandalkan jika Anda membuat keputusan tentang metrik sensitif dan banyak lalu lintas. Misalnya, di Avito, secara default , level signifikansi diatur ke 0,005 .O'Brien-Fleming
Dalam metode ini, tingkat signifikansi bervariasi tergantung pada nomor verifikasi. Penting untuk menentukan terlebih dahulu jumlah langkah (atau mengintip) dalam tes dan menghitung tingkat signifikansi untuk masing-masing langkah. Semakin cepat kami mencoba menyelesaikan tes, semakin ketat kriteria yang akan diterapkan. Ambang statistik siswa (termasuk nilai pada langkah terakhir ), sesuai dengan tingkat signifikansi yang diinginkan, tergantung pada jumlah verifikasi (mengambil nilai dari 1 hingga jumlah total cek inklusif) dan dihitung menurut rumus yang diperoleh secara empiris:
Kode peluangfrom sklearn.linear_model import LinearRegression
from sklearn.metrics import explained_variance_score
import matplotlib.pyplot as plt
total_steps = [
2, 3, 4, 5, 6, 8, 10, 15, 20, 25, 30, 50, 60
]
last_z = [
1.969, 1.993, 2.014, 2.031, 2.045, 2.066, 2.081,
2.107, 2.123, 2.134, 2.143, 2.164, 2.17
]
features = [
[1/t, 1/t**0.5] for t in total_steps
]
lr = LinearRegression()
lr.fit(features, last_z)
print(lr.coef_)
print(lr.intercept_)
print(explained_variance_score(lr.predict(features), last_z))
total_steps_extended = np.arange(2, 80)
features_extended = [ [1/t, 1/t**0.5] for t in total_steps_extended ]
plt.plot(total_steps_extended, lr.predict(features_extended))
plt.scatter(total_steps, last_z, s=30, color='black')
plt.show()
Tingkat signifikansi yang relevan dihitung melalui persentil distribusi standar yang sesuai dengan nilai statistik siswa :perc = scipy.stats.norm.cdf(Z)
pval_thresholds = (1 − perc) * 2
Pada simulasi yang sama, kelihatannya seperti ini: Hasil positif palsu adalah 501 dari 10 ribu, atau diharapkan 5%. Harap dicatat bahwa tingkat signifikansi tidak mencapai nilai 5% bahkan pada akhirnya, karena 5% ini harus "diolesi" oleh semua cek. Di perusahaan, kami menggunakan koreksi ini jika kami menjalankan tes dengan kemungkinan berhenti lebih awal. Anda dapat membaca tentang amandemen yang sama dan lainnya di sini .
Hasil positif palsu adalah 501 dari 10 ribu, atau diharapkan 5%. Harap dicatat bahwa tingkat signifikansi tidak mencapai nilai 5% bahkan pada akhirnya, karena 5% ini harus "diolesi" oleh semua cek. Di perusahaan, kami menggunakan koreksi ini jika kami menjalankan tes dengan kemungkinan berhenti lebih awal. Anda dapat membaca tentang amandemen yang sama dan lainnya di sini .Metode yang OptimalOptimizely , , . , . , . O'Brien-Fleming’a .
Kalkulator Uji A / B
Spesifikasi produk kami adalah sedemikian rupa sehingga distribusi metrik apa pun sangat bervariasi tergantung pada audiens tes (misalnya, nomor kelas) dan waktu tahun. Oleh karena itu, tidak akan mungkin untuk menerima aturan untuk tanggal akhir tes dalam semangat "tes akan berakhir ketika 1 juta pengguna diketik dalam setiap kelompok" atau "tes akan berakhir ketika jumlah tugas yang diselesaikan mencapai 100 juta". Artinya, ini akan berhasil, tetapi dalam praktiknya, untuk ini, perlu dipertimbangkan terlalu banyak faktor:- kelas apa yang akan diuji;
- tes didistribusikan ke guru atau siswa;
- waktu tahun akademik;
- uji untuk semua pengguna atau hanya untuk yang baru.
Namun, dalam skema pengujian A / B kami, Anda harus selalu memperbaiki tanggal akhir sebelumnya. Untuk memperkirakan durasi tes, kami mengembangkan aplikasi internal - Kalkulator uji A / B. Berdasarkan aktivitas pengguna dari segmen yang dipilih selama setahun terakhir, aplikasi menghitung periode di mana Anda perlu menjalankan tes untuk memperbaiki secara signifikan pengangkatan di X% dari metrik yang dipilih. Koreksi untuk beberapa pengujian juga secara otomatis diperhitungkan dan tingkat signifikansi ambang dihitung untuk penghentian pengujian awal.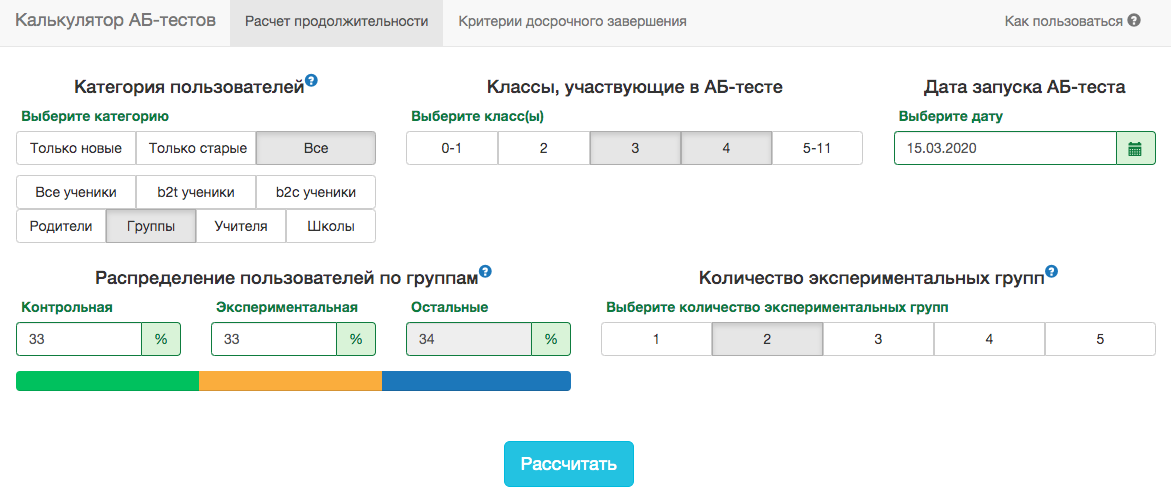 Semua metrik dihitung pada tingkat objek uji. Jika metrik adalah jumlah masalah yang dipecahkan, maka dalam ujian di tingkat guru ini akan menjadi jumlah dari masalah yang dipecahkan oleh murid-muridnya. Karena kita menggunakan kriteria siswa, kita dapat menghitung awal unit yang dibutuhkan oleh kalkulator untuk semua kemungkinan irisan. Untuk setiap hari sejak awal ujian, Anda perlu mengetahui jumlah orang yang mengikuti ujian, nilai rata-rata metrik dan variansnya . Memperbaiki bagian-bagian dari kelompok kontrolkelompok eksperimen dan hasil yang diharapkan dari tes dalam persen, Anda dapat menghitung nilai yang diharapkan dari statistik siswa dan nilai p yang sesuai untuk setiap hari tes:
Semua metrik dihitung pada tingkat objek uji. Jika metrik adalah jumlah masalah yang dipecahkan, maka dalam ujian di tingkat guru ini akan menjadi jumlah dari masalah yang dipecahkan oleh murid-muridnya. Karena kita menggunakan kriteria siswa, kita dapat menghitung awal unit yang dibutuhkan oleh kalkulator untuk semua kemungkinan irisan. Untuk setiap hari sejak awal ujian, Anda perlu mengetahui jumlah orang yang mengikuti ujian, nilai rata-rata metrik dan variansnya . Memperbaiki bagian-bagian dari kelompok kontrolkelompok eksperimen dan hasil yang diharapkan dari tes dalam persen, Anda dapat menghitung nilai yang diharapkan dari statistik siswa dan nilai p yang sesuai untuk setiap hari tes:
Selanjutnya, mudah untuk mendapatkan nilai-p untuk setiap hari:pvalue = (1 − scipy.stats.norm.cdf(ttest_stat_value)) * 2
Mengetahui nilai p dan tingkat signifikansi, dengan mempertimbangkan semua koreksi untuk setiap hari tes, untuk setiap durasi tes, Anda dapat menghitung peningkatan minimum yang dapat dideteksi (dalam literatur bahasa Inggris - MDE, efek minimal yang terdeteksi). Setelah itu, mudah untuk memecahkan masalah terbalik - untuk menentukan jumlah hari yang diperlukan untuk mengidentifikasi peningkatan yang diharapkan.Kesimpulan
Sebagai kesimpulan, saya ingin mengingat pesan utama artikel:- Jika Anda membandingkan nilai rata-rata metrik dalam grup, kemungkinan besar, kriteria Siswa akan cocok untuk Anda. Pengecualian adalah ukuran sampel yang sangat kecil (puluhan pengamatan) atau distribusi metrik abnormal (dalam praktiknya, saya belum melihat itu).
- Jika ada beberapa kelompok dalam pengujian, gunakan koreksi untuk pengujian hipotesis berganda. Koreksi Bonferroni yang paling sederhana akan dilakukan.
- .
- . .
- . , , , , O'Brien-Fleming.
- A/B-, A/A-.
Terlepas dari semua hal di atas, bisnis dan akal sehat tidak boleh menderita demi ketelitian matematika. Terkadang dimungkinkan untuk menjalankan fungsional untuk semua yang tidak menunjukkan peningkatan signifikan dalam tes, beberapa perubahan pasti terjadi tanpa pengujian sama sekali. Tetapi jika Anda melakukan ratusan tes setahun, analisis akurat mereka sangat penting. Kalau tidak, ada risiko bahwa jumlah tes positif palsu akan sebanding dengan yang benar-benar bermanfaat.