 Halo, habrozhiteli! Paul dan Harvey Daytels menawarkan pandangan baru pada Python dan menggunakan pendekatan unik untuk dengan cepat menyelesaikan masalah yang dihadapi orang-orang TI modern.Anda siap membantu lebih dari lima ratus tugas nyata - mulai dari fragmen hingga 40 skenario besar dan contoh dengan implementasi penuh. IPython dengan Jupyter Notebooks memungkinkan Anda mempelajari idiom pemrograman Python modern dengan cepat. Bab 1–5 dan fragmen bab 6–7 akan membuat contoh yang jelas untuk menyelesaikan masalah kecerdasan buatan dari bab 11–16. Anda akan belajar tentang pemrosesan bahasa alami, analisis emosi di Twitter, komputasi kognitif IBM Watson, pembelajaran mesin dengan guru dalam masalah klasifikasi dan regresi, pembelajaran mesin tanpa guru dalam pengelompokan, pengenalan pola dengan pembelajaran mendalam dan jaringan saraf convolutional, jaringan saraf berulang, besar data dari Hadoop, Spark dan NoSQL, IoT, dan lainnya. Anda akan bekerja (langsung atau tidak langsung) dengan layanan cloud, termasuk Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub, dll.
Halo, habrozhiteli! Paul dan Harvey Daytels menawarkan pandangan baru pada Python dan menggunakan pendekatan unik untuk dengan cepat menyelesaikan masalah yang dihadapi orang-orang TI modern.Anda siap membantu lebih dari lima ratus tugas nyata - mulai dari fragmen hingga 40 skenario besar dan contoh dengan implementasi penuh. IPython dengan Jupyter Notebooks memungkinkan Anda mempelajari idiom pemrograman Python modern dengan cepat. Bab 1–5 dan fragmen bab 6–7 akan membuat contoh yang jelas untuk menyelesaikan masalah kecerdasan buatan dari bab 11–16. Anda akan belajar tentang pemrosesan bahasa alami, analisis emosi di Twitter, komputasi kognitif IBM Watson, pembelajaran mesin dengan guru dalam masalah klasifikasi dan regresi, pembelajaran mesin tanpa guru dalam pengelompokan, pengenalan pola dengan pembelajaran mendalam dan jaringan saraf convolutional, jaringan saraf berulang, besar data dari Hadoop, Spark dan NoSQL, IoT, dan lainnya. Anda akan bekerja (langsung atau tidak langsung) dengan layanan cloud, termasuk Twitter, Google Translate, IBM Watson,Microsoft Azure, OpenMapQuest, PubNub, dll.9.12.2. Membaca file CSV di pustaka koleksi DataFrame perpustakaan
Bagian "Pengantar ilmu data" dari dua bab sebelumnya memperkenalkan dasar-dasar bekerja dengan panda. Sekarang kita akan mendemonstrasikan alat panda untuk mengunduh file CSV, dan kemudian melakukan operasi analisis data dasar.Kumpulan data
Dalam contoh-contoh ilmu data praktis, berbagai set data gratis dan terbuka akan digunakan untuk menunjukkan konsep pembelajaran mesin dan pemrosesan bahasa alami. Berbagai set data gratis tersedia di Internet. Repositori Rdatasets yang populer berisi tautan ke lebih dari 1.100 set data CSV gratis. Kit ini awalnya dilengkapi dengan bahasa pemrograman R untuk menyederhanakan studi dan pengembangan program statistik, namun, mereka tidak terkait dengan bahasa R. Sekarang set data ini tersedia di GitHub di:https://vincentarelbundock.imtqy.com/Rdatasets/ datasetets.htmlRepositori ini sangat populer sehingga ada modul pydataset yang dirancang khusus untuk mengakses Rdatasets. Untuk instruksi tentang menginstal pydataset dan mengakses dataset, kunjungi:https://github.com/iamaziz/PyDataset
Sumber hebat lainnya untuk dataset:https://github.com/awesomedata/awesome-public-datasetsSatu set data pembelajaran mesin yang biasa digunakan untuk pemula adalah set data tabrakan Titanic, yang mencantumkan semua penumpang dan apakah mereka selamat ketika Titanic bertabrakan dengan gunung es dan tenggelam 14–15 April 1912. Kami akan menggunakan set ini untuk menunjukkan cara memuat kumpulan data, melihat datanya, dan memperoleh statistik deskriptif. Kumpulan data populer lainnya akan dieksplorasi dalam bab contoh sains data di buku ini.Bekerja dengan file CSV lokalUntuk memuat dataset CSV ke dalam DataFrame, Anda dapat menggunakan fungsi read_csv library panda. Cuplikan berikut ini mengunduh dan menampilkan file CSV accounts.csv yang dibuat sebelumnya dalam bab ini:In [1]: import pandas as pd
In [2]: df = pd.read_csv('accounts.csv',
...: names=['account', 'name', 'balance'])
...:
In [3]: df
Out[3]:
account name balance
0 100 Jones 24.98
1 200 Doe 345.67
2 300 White 0.00
3 400 Stone -42.16
4 500 Rich 224.62
Argumen nama menentukan nama kolom dari DataFrame. Tanpa argumen ini, read_csv menganggap baris pertama file CSV berisi daftar nama kolom yang dipisahkan koma.Untuk menyimpan data DataFrame dalam file CSV, panggil metode to_csv dari koleksi DataFrame:In [4]: df.to_csv('accounts_from_dataframe.csv', index=False)
Indeks argumen kunci = Salah berarti bahwa nama-nama baris (0–4 di sisi kiri output DataFrame dalam fragmen [3]) tidak boleh ditulis ke file. Baris pertama dari file yang dihasilkan berisi nama kolom:account,name,balance
100,Jones,24.98
200,Doe,345.67
300,White,0.0
400,Stone,-42.16
500,Rich,224.62
9.12.3. Membaca Dataset Bencana Titanic
Kumpulan data bencana Titanic adalah salah satu dataset pembelajaran mesin yang paling populer dan tersedia dalam banyak format, termasuk CSV.Unduh Dataset Bencana Titanic di URL
Jika Anda memiliki URL yang mewakili dataset dalam format CSV, maka Anda dapat memuatnya ke dalam DataFrame dengan fungsi read_csv - misalnya, dari GitHub:In [1]: import pandas as pd
In [2]: titanic = pd.read_csv('https://vincentarelbundock.imtqy.com/' +
...: 'Rdatasets/csv/carData/TitanicSurvival.csv')
...:
Melihat beberapa baris dari set data bencana Titanic Set databerisi lebih dari 1.300 baris, setiap baris mewakili satu penumpang. Menurut Wikipedia, ada sekitar 1317 penumpang, dan 815 di antaranya meninggal1. Untuk set data besar, hanya 30 baris pertama yang ditampilkan ketika DataFrame adalah output, kemudian ellipsis "..." dan 30 baris terakhir ditampilkan. Untuk menghemat ruang, kita akan melihat lima baris pertama dan terakhir menggunakan metode kepala dan ekor koleksi DataFrame. Kedua metode mengembalikan lima baris secara default, tetapi jumlah baris yang ditampilkan dapat diteruskan dalam argumen:Dalam [3]: pd.set_option ('presisi', 2) # Format untuk nilai-nilai titik-mengambangHarap dicatat: panda menyesuaikan lebar setiap kolom berdasarkan nilai terluas dalam nama kolom atau kolom (tergantung yang memiliki lebar terbesar); di kolom usia baris 1305 adalah NaN - tanda nilai yang hilang dalam kumpulan data.Mengatur nama kolom Nama kolompertama dalam dataset terlihat agak aneh ('Tidak Dinamai: 0'). Masalah ini dapat diatasi dengan menyesuaikan nama kolom. Ganti 'Tanpa Nama: 0' dengan 'nama' dan kurangi 'passengerClass' menjadi 'class':

9.12.4. Analisis data sederhana menggunakan dataset bencana Titanic sebagai contoh
Sekarang kita akan menggunakan panda untuk melakukan analisis data sederhana menggunakan beberapa karakteristik statistik deskriptif sebagai contoh. Saat Anda menelepon uraikan untuk koleksi DataFrame yang berisi kolom numerik dan non-numerik, jelaskan hitung karakteristik statistik hanya untuk kolom numerik - dalam hal ini, hanya untuk kolom usia: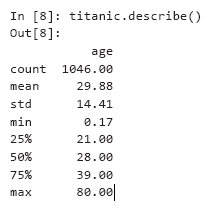 Perhatikan perbedaan dalam nilai hitungan (1046) dan jumlah baris data dalam kumpulan data (1309 - saat memanggil ekor, indeks baris terakhir adalah 1308). Hanya 1046 baris data (nilai hitung) berisi nilai usia. Hasil yang tersisa hilang dan ditandai dengan NaN, seperti pada baris 1305. Saat melakukan perhitungan, panda perpustakaan mengabaikan data yang hilang (NaN) secara default. Untuk 1046 penumpang dengan usia yang valid, usia rata-rata (harapan) adalah 29,88 tahun. Penumpang termuda (min) baru berusia dua bulan (0,17 * 12 memberi 2,04), dan yang tertua (maks) berusia 80 tahun. Usia rata-rata adalah 28 (ditunjukkan oleh kuartil 50 persen). Kuartil 25 persen menggambarkan usia rata-rata di paruh pertama penumpang (diperingkat berdasarkan usia),dan kuartil 75 persen adalah median di paruh kedua penumpang.Misalkan Anda ingin menghitung statistik tentang penumpang yang selamat. Kita dapat membandingkan kolom yang selamat dengan nilai 'ya' untuk mendapatkan koleksi Seri baru dengan nilai Benar / Salah, dan kemudian gunakan uraikan untuk menggambarkan hasil:
Perhatikan perbedaan dalam nilai hitungan (1046) dan jumlah baris data dalam kumpulan data (1309 - saat memanggil ekor, indeks baris terakhir adalah 1308). Hanya 1046 baris data (nilai hitung) berisi nilai usia. Hasil yang tersisa hilang dan ditandai dengan NaN, seperti pada baris 1305. Saat melakukan perhitungan, panda perpustakaan mengabaikan data yang hilang (NaN) secara default. Untuk 1046 penumpang dengan usia yang valid, usia rata-rata (harapan) adalah 29,88 tahun. Penumpang termuda (min) baru berusia dua bulan (0,17 * 12 memberi 2,04), dan yang tertua (maks) berusia 80 tahun. Usia rata-rata adalah 28 (ditunjukkan oleh kuartil 50 persen). Kuartil 25 persen menggambarkan usia rata-rata di paruh pertama penumpang (diperingkat berdasarkan usia),dan kuartil 75 persen adalah median di paruh kedua penumpang.Misalkan Anda ingin menghitung statistik tentang penumpang yang selamat. Kita dapat membandingkan kolom yang selamat dengan nilai 'ya' untuk mendapatkan koleksi Seri baru dengan nilai Benar / Salah, dan kemudian gunakan uraikan untuk menggambarkan hasil:In [9]: (titanic.survived == 'yes').describe()
Out[9]:
count 1309
unique 2
top False
freq 809
Name: survived, dtype: object
Untuk data non-numerik, jelaskan tampilan berbagai karakteristik statistik deskriptif:- hitung - jumlah total elemen dalam hasil;
- unik - jumlah nilai unik (2) sebagai hasilnya - Benar (penumpang selamat) atau Salah (penumpang meninggal);
- top - nilai yang paling sering ditemui sebagai hasilnya;
- Frek - jumlah kemunculan nilai atas.
9.12.5. Grafik batang usia penumpang
Visualisasi adalah cara yang baik untuk mengenal data dengan lebih baik. Panda mengandung banyak alat visualisasi built-in berdasarkan Matplotlib. Untuk menggunakannya, pertama-tama aktifkan dukungan Matplotlib di IPython:In [10]: %matplotlib
Histogram dengan jelas menunjukkan distribusi data numerik pada rentang nilai. Metode hist koleksi DataFrame secara otomatis menganalisis data setiap kolom numerik dan membuat histogram yang sesuai. Untuk melihat histogram untuk setiap kolom data numerik, hubungi histori untuk koleksi DataFrame Anda:In [11]: histogram = titanic.hist()
Kumpulan data bencana Titanic hanya berisi satu kolom data numerik, sehingga grafik menunjukkan histogram untuk distribusi usia. Untuk dataset dengan beberapa kolom numerik, hist membuat histogram terpisah untuk setiap kolom numerik.»Informasi lebih lanjut tentang buku ini dapat ditemukan di situs web penerbit» Isi» KutipanUntuk Khabrozhiteley Diskon kupon 25% - PythonSetelah pembayaran versi kertas buku (tanggal rilis - 5 Juni ), sebuah buku elektronik dikirim melalui email.