Clustering adalah hal yang sangat ajaib: mengubah sejumlah besar data yang tidak terstruktur menjadi kumpulan cluster yang berpotensi terlihat, analisis yang memungkinkan kita untuk menarik kesimpulan tentang konten data ini.
Ada banyak aplikasi untuk metode pengelompokan. Misalnya, kami mengelompokkan kueri penelusuran untuk meningkatkan kemampuan generalisasi algoritme peringkat: statistik apa pun yang dihitung dari grup kueri serupa lebih dapat diandalkan daripada statistik yang sama yang dihitung untuk satu kueri terpisah. Clustering memungkinkan Anda untuk meningkatkan kualitas kueri dengan formulasi yang jarang ditemui. Contoh jelas lainnya adalah Yandex.News, yang secara otomatis menghasilkan berita.
Kembali pada tahun 2013, saya beruntung dapat berpartisipasi dalam pengembangan algoritma pengelompokan yang sangat kompleks. Itu perlu untuk mengelompokkan ratusan ribu objek dengan kualitas sangat tinggi dan melakukannya dengan cepat: dalam puluhan detik pada satu mesin. Langkah pertama adalah membangun sistem penilaian kualitas, dan dalam artikel ini saya akan membicarakannya.

, , , .
, : , , , /- . , . — .
1.
, . .
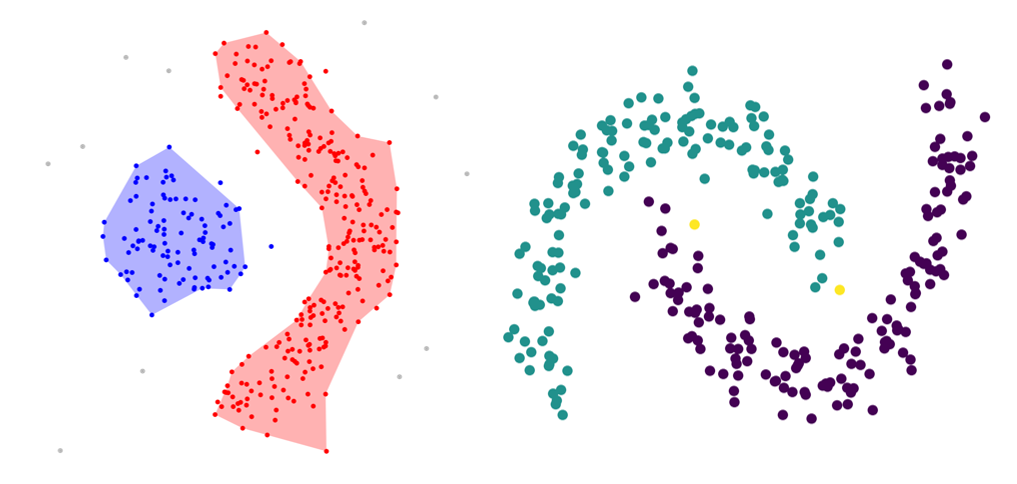
, . Amigo et. al, 2009. A comparison of Extrinsic Clustering Evaluation Metrics based on Formal Constraints , , .
1.1. Cluster Homogeneity,

.
1.2. Cluster Completeness,
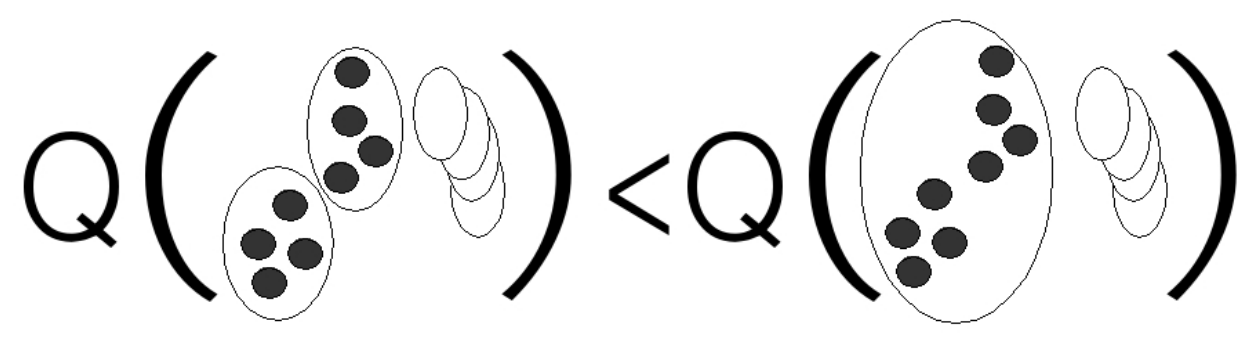
, . .
1.3. Rag Bag
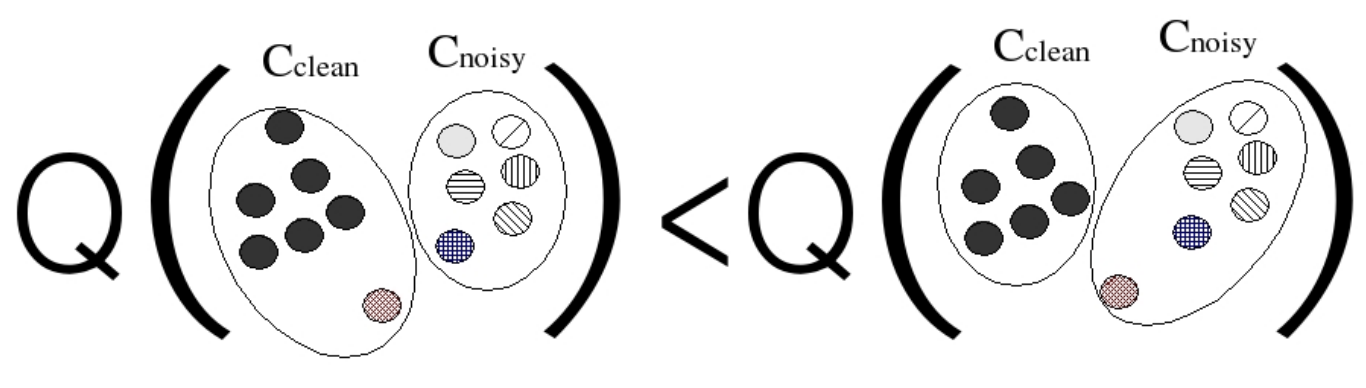
: , , («»), . , , , .
, . , . «» : , .
1.4. Size vs Quantity

.
2.
.
D={d1,...,dN}. . , E⊆2D — ,
∀e1,e2∈E:(e1∩e2≠∅)⇔(e1=e2)
: . , .
, : T={t1,...,tn} C={c1,...,cm}. t(d) c(d) , , , d.
2.1. , ()
. , . , .
. 3 («»), 3 («») 2 («»). : «» , «» «».

8⋅8=64 , :
— 3⋅3+3⋅3+2⋅2=22 ;
— 64−22=42 .
«» «» , - «» .
, :
— TP=18 ;
— FP=6 , ;
— TN=36 ;
— FN=4 , .
, :
P=TP/(TP+FP)=0.75
R=TP/(TP+FN)=0.82
F1=2PRP+R=0.78
, : .
. , : .
pairwise- — . - pairwise- .
2.2. ,
:
P(c,t)=|c∩t||c|
R(c,t)=|c∩t||t|
: «» (y) «» (v). 25 10 . 25/35, — 10/35. . , 30 12 , 25/30, — 10/12.

: , . :
P(c,t)=R(t,c)
F-:
F1(c,t)=2⋅P(c,t)⋅R(c,t)P(c,t)+R(c,t)
. «» , Purity:
Pkamursayaty=m∑saya=1|csaya|mmaks1≤j≤nP(csaya,tj)
, :
sayaversePkamursayaty=n∑j=1|tj|nmaks1≤saya≤mP(csaya,tj)
Pkamursayaty , . sayaversePkamursayaty — . , ? , . :
|c2|≈|t2|≫|t1|≫|c1|
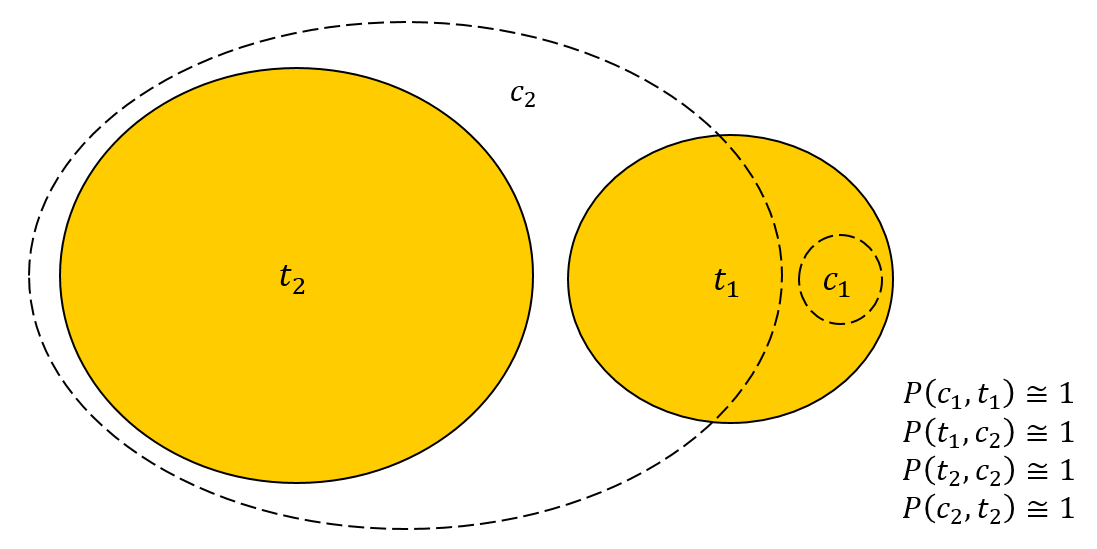
|c2|=1000, |c1|=2, |t1|=dua puluh, |t2|=982. c1 t1, :
|c1∩t1|=2,|c1∩t2|=0,
|c2∩t1|=delapan belas,|c2∩t2|=982
:
P(c1,t1)=|c1∩t1|/|c1|=2/2=1
P(c2,t2)=|c2∩t2|/|c2|=982/1000=0,982
P(t1,c2)=|t1∩c2|/|t1|=delapan belas/dua puluh=0,9
P(t2,c2)=|c2∩t2|/|t2|=982/982=1
, Purity InversePurity . :
Pkamursayaty=0,9982
sayaversePkamursayaty=0,9823
, t1 . , . . Purity t1 c1, InversePurity — c2. !
F-:
F=n∑j=1|tj|nmaks1≤saya≤mF(csaya,tj)
, , . , , , .
2.3. BCubed-
. , . , , ? ?
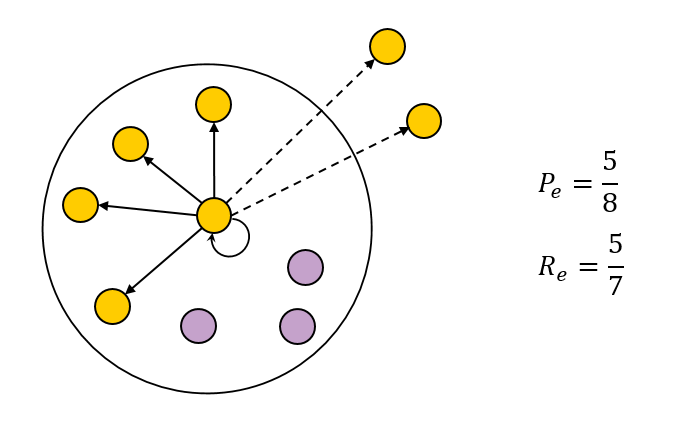
, BCubed- . :
BCP(d)=|c(d)∩t(d)||c(d)|
BCR(d)=|c(d)∩t(d)||t(d)|
:
BCP=1N∑d∈DBCP(d)
BCR=1N∑d∈DBCR(d)
BCubed Precision Cluster Homogeneity Rag Bag, BCubed Recall — Cluster Completeness Size vs Quantity. — F- — :
BCF=2⋅BCP⋅BCRBCP+BCR
3.
, . , .
, , . D={Sebuah,b,c,d,e,f,g,h,saya} , t1={Sebuah,b,c,d,e} t2={f,g,h,saya} («» «» ).
: c1={Sebuah,b,c,d,g}, c2={e,f,h,saya}.

3.1. BCubed
BCubed- :
BCP(tsaya)=1|tsaya|∑d∈tsayaBCP(d)
BCR(tsaya)=1|tsaya|∑d∈tsayaBCR(d)
:
BCP(Sebuah)=BCP(b)=BCP(c)=BCP(d)=|t1∩c1||c1|=0.8,BCP(e)=|t1∩c2||c2|=0,25
BCP(f)=BCP(h)=BCP(saya)=|t2∩c2||c2|=0,75,BCP(g)=|t2∩c1||c1|=0,2
:
BCP(t1)=BCP(Sebuah)+BCP(b)+BCP(c)+BCP(d)+BCP(e)5=4⋅0.8+0,255=0,69
BCP(t2)=BCP(f)+BCP(g)+BCP(h)+BCP(saya)4=3⋅0,75+0,24=0,6125
:
BCR(Sebuah)=BCR(b)=BCR(c)=BCR(d)=|t1∩c1||t1|=0.8,BCR(e)=|t1∩c2||t1|=0,2
BCR(f)=BCR(h)=BCR(saya)=|t2∩c2||t2|=0,75,BCP(g)=|t2∩c1||t2|=0,25
BCR(t1)=BCR(Sebuah)+BCR(b)+BCR(c)+BCR(d)+BCR(e)5=4⋅0.8+0,25=0,68
BCR(t2)=BCR(f)+BCR(g)+BCR(h)+BCR(saya)4=3⋅0,75+0,254=0,625
BCP BCR :
BCP=BCP(t1)+BCP(t2)2=0,65125
BCR=BCR(t1)+BCR(t2)2=0,6525
.
3.2. Expected Cluster Completeness
. , , , , - .
— F- — . , ? .
, , «». . — . : , , .
— :
f:C→T
f (cluster completeness):
CCf(t)=maksc∈f-1(t)|c∩t||t|
:
CCf(T)=1T∑t∈TCCf(t)
— , f. : .
. , f(c)=t,
P(f(c)=t)=P(c,t)=|c∩t||c|
f :
P(f)=∏c∈C|c∩f(c)||c|
:
ECC(t)=∑f:C→TP(f)⋅CCf(t)
:
ECC=1|T|∑t∈TECC(t)
:
ECC=∑f:C→TP(f)⋅CCf(T)
. t c1, c2, ..., ck, :
|t∩c1|≥|t∩c2|≥...≥|t∩ck|
c1 t
P(f(c1)=t)=|c1∩t||c1|
R(c1,t)=|c1∩t||t|
, , . R(c1,t).
c1 , hal(c2,t) t c2. R(c2,t). , ,
P(c1,t)⋅R(c1,t)+P(c2,t)⋅R(c2,t)⋅(1-P(c1,t))+...
ECC . sortedMatchings , , . Precision() Recall() . :
double ExpectedClusterCompleteness(const TMatchings& sortedMatchings) {
double expectedClusterCompleteness = 0.;
double probability = 1.;
for (const TMatching& matching : sortedMatchings) {
expectedClusterCompleteness += matching.Recall() * matching.Precision() * probability;
probability *= 1. - matching.Precision();
}
return expectedClusterCompleteness;
}
, F1-, !
ECC , 3. t1 c1, t2 — c2. :
ECC(t1)=R(c1,t2)⋅P(c1,t1)+R(c2,t1)⋅P(c2,t1)⋅(1-P(c1,t1))
ECC(t1)=0.82+0,2⋅0,25⋅(1-0.8)=0,65
ECC(t2)=R(c2,t2)⋅P(c2,t2)+R(c1,t2)⋅P(c1,t2)⋅(1-P(c2,t2))
ECC(t2)=0,752+0,25⋅0,2⋅(1-0,75)=0,575
, :
ECC=ECC(t1)+ECC(t2)2=0,6125
4.
, 3, C++ MIT GitHub. Linux, Windows.
:
git clone https://github.com/yandex/cluster_metrics/ .
cmake .
cmake --build .
, 3. !
./cluster_metrics samples/sample_markup.tsv samples/sample_clusters.tsv
ECC 0.61250 (0.61250)
BCP 0.65125 (0.65125)
BCR 0.65250 (0.65250)
BCF1 0.65187 (0.65187)
«» , , . , , . , , . — .
5. ,
, , , .
. , , . , , :

: , . , , . , , , — . — ECC!
, , — . .
, , , . .
, , , ECC! ECC - , , , 100% . .
, 1 . : — .

Cluster Completeness
, , . , Cluster Homogeneity, Cluster Completeness, Rag Bag , Size vs Quantity .
, : , , , .
, 3, , .
, , : . , , .