Kebetulan sistemnya bermasalah, melambat, rusak. Semakin besar sistem, semakin sulit untuk menemukan penyebabnya. Untuk mencari tahu mengapa sesuatu tidak berfungsi seperti yang diharapkan, untuk memperbaiki atau mencegah masalah di masa depan, Anda perlu mencari ke dalam. Untuk ini, sistem harus memiliki sifat dapat diamati , yang dicapai dengan instrumentasi dalam arti luas.Di HighLoad ++, Peter Zaitsev (Percona) meninjau infrastruktur yang tersedia untuk pelacakan di Linux dan berbicara tentang bpfTrace, yang (sesuai namanya) menawarkan banyak keuntungan. Kami membuat versi teks dari laporan tersebut, sehingga akan lebih mudah bagi Anda untuk meninjau detail dan materi tambahan selalu tersedia.Instrumentasi dapat dibagi menjadi dua blok besar:- Statis , ketika pengumpulan informasi ditransfer ke dalam kode: rekaman log, penghitung, waktu, dll.
- Dinamis , ketika kode tidak diinstrumentasi dengan sendirinya, tetapi dimungkinkan untuk melakukannya bila perlu.
Opsi klasifikasi lain didasarkan pada pendekatan untuk merekam data:- Tracing - peristiwa dihasilkan jika kode tertentu berhasil.
- Pengambilan sampel - status sistem diperiksa, misalnya, 100 kali per detik dan menentukan apa yang terjadi di dalamnya.
Instrumentasi statis telah ada selama bertahun-tahun dan hampir semuanya. Di Linux, banyak alat standar seperti Vmstat atau yang teratas menggunakannya. Mereka membaca data dari procfs, di mana, secara kasar, penghitung waktu dan penghitung yang berbeda ditulis dari kode kernel.Tapi Anda tidak bisa memasukkan terlalu banyak penghitung ini, Anda tidak bisa menutupi semuanya di dunia dengan mereka. Oleh karena itu, instrumentasi dinamis dapat berguna, yang memungkinkan Anda untuk menonton apa yang Anda butuhkan. Misalnya, jika ada masalah dengan tumpukan TCP / IP, maka Anda bisa masuk sangat dalam dan menginstruksikan detail tertentu.
Dtrace
DTrace adalah salah satu kerangka kerja pelacakan dinamis pertama yang diketahui yang dibuat oleh Sun Microsystems. Itu mulai dibuat kembali pada tahun 2001, dan untuk pertama kalinya dirilis di Solaris 10 pada tahun 2005. Pendekatan itu ternyata sangat populer dan kemudian pergi ke banyak distribusi lainnya.Menariknya, DTrace memungkinkan Anda untuk memasukkan ruang kernel dan ruang pengguna. Anda dapat meletakkan jejak pada panggilan fungsi apa pun dan secara khusus menginstruksikan program: memperkenalkan jalur jejak DTrace khusus, yang bagi pengguna dapat lebih dimengerti daripada nama fungsi.Ini sangat penting bagi Solaris, karena ini bukan sistem operasi terbuka. Itu tidak mungkin untuk hanya melihat ke dalam kode dan memahami bahwa tracepoint perlu diletakkan pada fungsi seperti itu, karena sekarang dapat dilakukan dalam perangkat lunak Linux open source baru.Salah satu keunikan, terutama pada saat itu, fitur DTrace adalah meskipun pelacakan tidak diaktifkan, tidak ada biaya apa pun . Ini bekerja sedemikian rupa sehingga hanya menggantikan beberapa instruksi CPU dengan panggilan DTrace, yang mengeksekusi instruksi ini ketika kembali.Dalam DTrace, instrumentasi ditulis dalam bahasa D khusus, mirip dengan C dan Awk.Kemudian DTrace muncul hampir di mana-mana kecuali Linux: pada MacOS pada 2007, pada FreeBSD pada 2008, di NetBSD pada 2010. Oracle pada 2011 menyertakan DTrace di Oracle Unbreakable Linux. Tetapi beberapa orang menggunakan Oracle Linux, dan DTrace tidak pernah memasuki Linux utama.Menariknya, pada tahun 2017, Oracle akhirnya melisensikan DTrace di bawah GPLv2, yang pada prinsipnya memungkinkan untuk memasukkannya ke Linux arus utama tanpa kesulitan perizinan, tetapi sudah terlambat. Pada saat itu, Linux memiliki BPF yang baik, yang terutama digunakan untuk standardisasi.DTrace bahkan akan dimasukkan dalam Windows, sekarang sudah tersedia di beberapa versi uji.Pelacakan Linux
Apa yang ada di Linux, bukan DTrace? Bahkan, di Linux ada banyak hal dalam manifestasi terbaik (atau terburuk) dari semangat open source, banyak kerangka kerja penelusuran yang berbeda telah terakumulasi selama ini. Karena itu, cari tahu apa yang tidak begitu sederhana.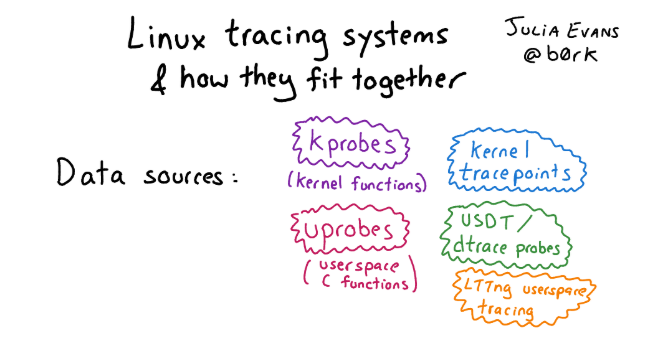 Jika Anda ingin berkenalan dengan varietas ini dan tertarik pada sejarah, lihat artikel dengan gambar dan deskripsi terperinci tentang pendekatan pelacakan di Linux.Jika kita berbicara tentang infrastruktur untuk pelacakan di Linux secara umum, ada tiga tingkatan:
Jika Anda ingin berkenalan dengan varietas ini dan tertarik pada sejarah, lihat artikel dengan gambar dan deskripsi terperinci tentang pendekatan pelacakan di Linux.Jika kita berbicara tentang infrastruktur untuk pelacakan di Linux secara umum, ada tiga tingkatan:- Antarmuka untuk instrumentasi kernel: Kprobe, Uprobe, probe Dtrace, dll.
- «», . , probe, , user space . : , user space, Kernel Module, - , eBPF.
- -, , : Perf, SystemTap, SysDig, BCC .. bpfTtrace , , .
eBPF — Linux
Dengan semua kerangka kerja ini, eBPF telah menjadi standar di Linux dalam beberapa tahun terakhir. Ini adalah alat yang lebih canggih, sangat fleksibel dan efektif yang memungkinkan hampir semuanya.Apa itu eBPF dan dari mana asalnya? Faktanya, eBPF adalah Extended Berkeley Packet Filter, dan BPF dikembangkan pada tahun 1992 sebagai mesin virtual untuk penyaringan paket yang efisien oleh firewall. Awalnya, ia tidak memiliki hubungan dengan pemantauan, pengamatan, atau penelusuran.Dalam versi yang lebih modern, eBPF telah diperluas (karena itu kata ini diperluas), sebagai kerangka kerja umum untuk menangani acara . Versi saat ini terintegrasi dengan JIT compiler untuk efisiensi yang lebih besar.Perbedaan eBPF dari BPF klasik:- register ditambahkan;
- tumpukan telah muncul;
- Ada struktur data tambahan (peta).
 Sekarang orang paling sering lupa bahwa ada BPF lama, dan eBPF hanya disebut BPF. Dalam kebanyakan ungkapan modern, eBPF dan BPF adalah satu dan sama. Oleh karena itu, alat ini disebut bpfTrace, bukan eBpfTrace.eBPF telah dimasukkan dalam arus utama Linux sejak 2014 dan secara bertahap termasuk dalam banyak alat Linux, termasuk Perf, SystemTap, SysDig. Ada standarisasi.Menariknya, pengembangan masih berlangsung. Kernel modern mendukung eBPF dengan lebih baik dan lebih baik.
Sekarang orang paling sering lupa bahwa ada BPF lama, dan eBPF hanya disebut BPF. Dalam kebanyakan ungkapan modern, eBPF dan BPF adalah satu dan sama. Oleh karena itu, alat ini disebut bpfTrace, bukan eBpfTrace.eBPF telah dimasukkan dalam arus utama Linux sejak 2014 dan secara bertahap termasuk dalam banyak alat Linux, termasuk Perf, SystemTap, SysDig. Ada standarisasi.Menariknya, pengembangan masih berlangsung. Kernel modern mendukung eBPF dengan lebih baik dan lebih baik. Anda dapat melihat versi kernel modern apa yang muncul di sini .
Anda dapat melihat versi kernel modern apa yang muncul di sini .Program EBPF
Jadi apa eBPF dan mengapa itu menarik?eBPF adalah program dalam bytecode khusus , yang dimasukkan langsung ke dalam kernel dan melakukan pemrosesan jejak peristiwa. Selain itu, fakta bahwa itu dibuat dalam bytecode khusus memungkinkan kernel untuk melakukan verifikasi tertentu bahwa kode tersebut cukup aman. Sebagai contoh, periksa apakah ia tidak menggunakan loop, karena loop di bagian kritis di kernel dapat menggantung seluruh sistem.Tetapi ini tidak memungkinkan untuk sepenuhnya aman. Sebagai contoh, jika Anda menulis program eBPF yang sangat kompleks, masukkan ke acara di kernel yang terjadi 10 juta kali per detik, maka semuanya dapat melambat sangat banyak. Tetapi pada saat yang sama, eBPF jauh lebih aman daripada pendekatan yang lama, ketika hanya beberapa Modul Kernel yang dimasukkan melalui insmod, dan apa saja bisa ada dalam modul ini. Jika seseorang melakukan kesalahan, atau hanya karena ketidakcocokan biner, seluruh inti bisa jatuh.Kode eBPF dapat dikompilasi oleh LLVM Clang, yaitu, pada umumnya, menggunakan subset C untuk membuat program eBPF, yang, tentu saja, cukup rumit. Dan penting kompilasi tergantung pada kernel: header digunakan untuk memahami struktur apa yang digunakan dan untuk apa mereka digunakan, dll. Ini sangat tidak nyaman dalam arti bahwa beberapa modul yang terkait dengan inti tertentu selalu disediakan, atau perlu dikompilasi ulang.Diagram menunjukkan cara kerja eBPF. http://www.brendangregg.com/ebpf.htmlPengguna membuat program eBPF. Lebih lanjut, kernel, untuk bagiannya, memeriksa dan memuatnya. Setelah itu, eBPF dapat terhubung ke berbagai alat untuk melacak, memproses informasi, menyimpannya di peta (struktur data untuk penyimpanan sementara). Kemudian program pengguna dapat membaca statistik, menerima acara, dll.Ini menunjukkan fitur eBPF mana di dalam versi kernel Linux.
http://www.brendangregg.com/ebpf.htmlPengguna membuat program eBPF. Lebih lanjut, kernel, untuk bagiannya, memeriksa dan memuatnya. Setelah itu, eBPF dapat terhubung ke berbagai alat untuk melacak, memproses informasi, menyimpannya di peta (struktur data untuk penyimpanan sementara). Kemudian program pengguna dapat membaca statistik, menerima acara, dll.Ini menunjukkan fitur eBPF mana di dalam versi kernel Linux.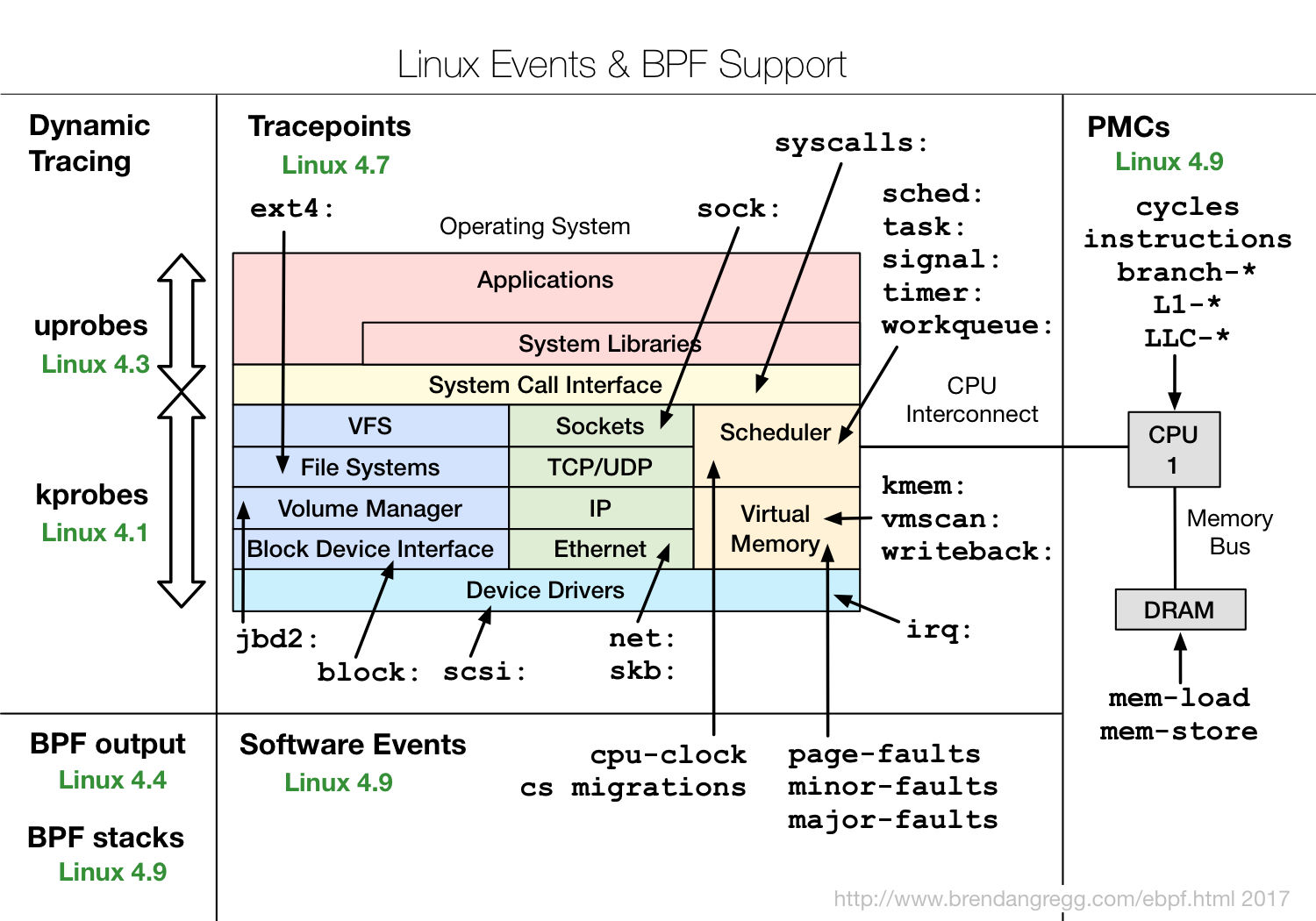 Dapat dilihat bahwa hampir semua subsistem kernel Linux dicakup, ditambah ada integrasi yang baik dengan data perangkat keras, eBPF memiliki akses ke semua jenis cache miss atau prediksi miss cabang, dll.Jika Anda tertarik dengan eBPF, lihat proyek IO Visor, itu berisi sebagian besar alat. Perusahaan IO Visor terlibat dalam pengembangan mereka, mereka akan memiliki versi terbaru dan dokumentasi yang sangat baik. Semakin banyak alat eBPF muncul di distribusi Linux, jadi saya akan merekomendasikan agar Anda selalu menggunakan versi terbaru yang tersedia.
Dapat dilihat bahwa hampir semua subsistem kernel Linux dicakup, ditambah ada integrasi yang baik dengan data perangkat keras, eBPF memiliki akses ke semua jenis cache miss atau prediksi miss cabang, dll.Jika Anda tertarik dengan eBPF, lihat proyek IO Visor, itu berisi sebagian besar alat. Perusahaan IO Visor terlibat dalam pengembangan mereka, mereka akan memiliki versi terbaru dan dokumentasi yang sangat baik. Semakin banyak alat eBPF muncul di distribusi Linux, jadi saya akan merekomendasikan agar Anda selalu menggunakan versi terbaru yang tersedia.Kinerja EBPF
Dalam hal kinerja, eBPF cukup efektif. Untuk memahami berapa banyak dan apakah ada overhead, Anda bisa menambahkan probe, yang berkedut beberapa kali per detik, dan periksa berapa lama untuk menjalankannya.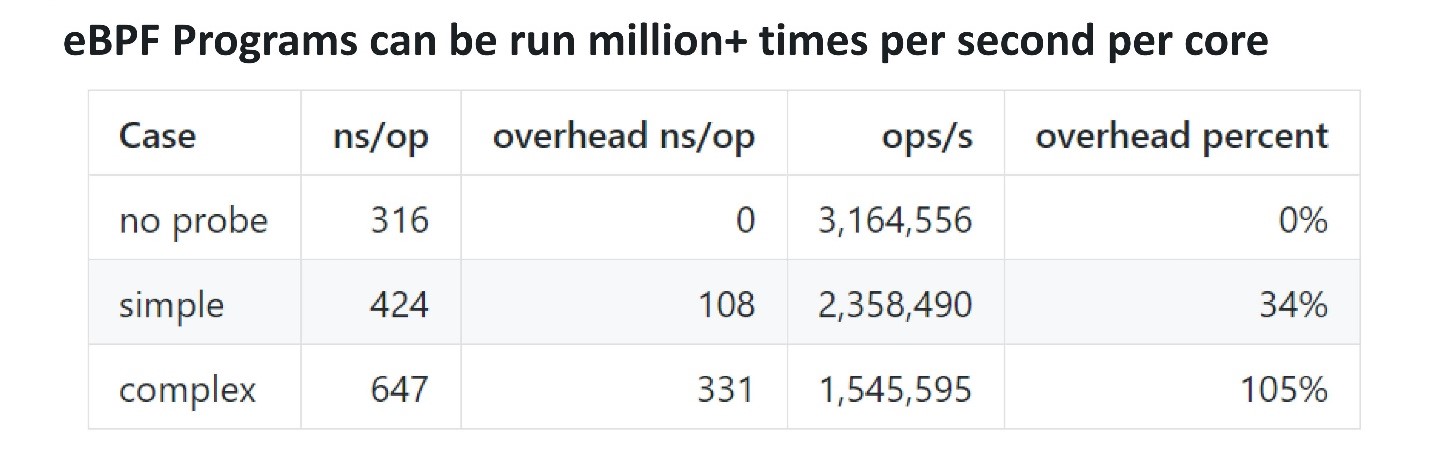 Orang-orang dari Cloudflare membuat patokan . Probe eBPF sederhana membawa mereka sekitar 100 ns, sementara yang lebih kompleks mengambil 300 ns. Ini berarti bahwa bahkan sebuah probe kompleks dapat dipanggil pada satu inti sekitar 3 juta kali per detik. Jika probe tersentak 100 ribu atau jutaan kali per detik pada prosesor multi-core, maka ini tidak akan terlalu mempengaruhi kinerja.
Orang-orang dari Cloudflare membuat patokan . Probe eBPF sederhana membawa mereka sekitar 100 ns, sementara yang lebih kompleks mengambil 300 ns. Ini berarti bahwa bahkan sebuah probe kompleks dapat dipanggil pada satu inti sekitar 3 juta kali per detik. Jika probe tersentak 100 ribu atau jutaan kali per detik pada prosesor multi-core, maka ini tidak akan terlalu mempengaruhi kinerja.Frontend untuk eBPF
Jika Anda tertarik dengan eBPF dan topik Observabilitas secara umum, Anda mungkin pernah mendengar tentang Brendan Gregg. Dia menulis dan berbicara banyak tentang ini dan membuat gambar yang sangat indah yang menunjukkan alat untuk eBPF. Di sini Anda dapat melihat bahwa, misalnya, Anda dapat menggunakan BPF Mentah - cukup tulis bytecode - ini akan memberikan berbagai fitur, tetapi akan sangat sulit untuk bekerja dengannya. BPF mentah adalah tentang bagaimana menulis aplikasi web dalam assembler - pada prinsipnya adalah mungkin, tetapi tanpa perlu melakukannya.Menariknya, bpfTrace, di satu sisi, memungkinkan Anda mendapatkan hampir semuanya dari BCC dan BPF mentah, tetapi jauh lebih mudah digunakan.Menurut pendapat saya, dua alat paling berguna:
Di sini Anda dapat melihat bahwa, misalnya, Anda dapat menggunakan BPF Mentah - cukup tulis bytecode - ini akan memberikan berbagai fitur, tetapi akan sangat sulit untuk bekerja dengannya. BPF mentah adalah tentang bagaimana menulis aplikasi web dalam assembler - pada prinsipnya adalah mungkin, tetapi tanpa perlu melakukannya.Menariknya, bpfTrace, di satu sisi, memungkinkan Anda mendapatkan hampir semuanya dari BCC dan BPF mentah, tetapi jauh lebih mudah digunakan.Menurut pendapat saya, dua alat paling berguna:- BCC. Terlepas dari kenyataan bahwa menurut skema Gregg, BCC adalah kompleks, ia mencakup banyak fungsi siap pakai yang dapat dengan mudah diluncurkan dari baris perintah.
- BpfTrace . Ini memungkinkan Anda untuk hanya menulis alat Anda sendiri atau menggunakan solusi yang sudah jadi.
Anda dapat membayangkan betapa mudahnya menulis di bpfTrace jika Anda melihat kode alat yang sama dalam dua versi.
DTrace vs bpfTrace
Secara umum, DTrace dan bpfTrace digunakan untuk hal yang sama. http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlPerbedaannya adalah bahwa ada juga BCC dalam ekosistem BPF yang dapat digunakan untuk alat yang kompleks. Tidak ada setara BCC dalam DTrace, oleh karena itu, untuk membuat toolkit kompleks, biasanya menggunakan bundel Shell + DTrace.Saat membuat bpfTrace, tidak ada tugas untuk sepenuhnya meniru DTrace. Artinya, Anda tidak dapat mengambil skrip DTrace dan menjalankannya di bpfTrace. Tetapi ini tidak masuk akal, karena logika pada alat level bawah cukup sederhana. Biasanya lebih penting untuk memahami tracepoint yang perlu Anda sambungkan, dan nama-nama sistem panggilan dan apa yang mereka lakukan secara langsung pada tingkat rendah berbeda di Linux, Solaris, FreeBSD. Di situlah perbedaan muncul.Dalam hal ini, bpfTrace dibuat 15 tahun setelah DTrace. Ini memiliki beberapa fitur tambahan yang tidak dimiliki DTrace. Misalnya, dia bisa melakukan stack trace.Tapi tentu saja, banyak yang diwarisi dari DTrace. Misalnya, nama fungsi dan sintaksis mirip , meskipun tidak sepenuhnya sama.Skrip DTrace dan bpfTrace memiliki ukuran kode yang hampir sama dan memiliki kompleksitas dan kemampuan bahasa yang serupa.
http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlPerbedaannya adalah bahwa ada juga BCC dalam ekosistem BPF yang dapat digunakan untuk alat yang kompleks. Tidak ada setara BCC dalam DTrace, oleh karena itu, untuk membuat toolkit kompleks, biasanya menggunakan bundel Shell + DTrace.Saat membuat bpfTrace, tidak ada tugas untuk sepenuhnya meniru DTrace. Artinya, Anda tidak dapat mengambil skrip DTrace dan menjalankannya di bpfTrace. Tetapi ini tidak masuk akal, karena logika pada alat level bawah cukup sederhana. Biasanya lebih penting untuk memahami tracepoint yang perlu Anda sambungkan, dan nama-nama sistem panggilan dan apa yang mereka lakukan secara langsung pada tingkat rendah berbeda di Linux, Solaris, FreeBSD. Di situlah perbedaan muncul.Dalam hal ini, bpfTrace dibuat 15 tahun setelah DTrace. Ini memiliki beberapa fitur tambahan yang tidak dimiliki DTrace. Misalnya, dia bisa melakukan stack trace.Tapi tentu saja, banyak yang diwarisi dari DTrace. Misalnya, nama fungsi dan sintaksis mirip , meskipun tidak sepenuhnya sama.Skrip DTrace dan bpfTrace memiliki ukuran kode yang hampir sama dan memiliki kompleksitas dan kemampuan bahasa yang serupa.
bpfTrace
Mari kita lihat lebih detail apa yang ada di bpfTrace, bagaimana ini bisa digunakan dan apa yang dibutuhkan untuk ini.Persyaratan Linux untuk menggunakan bpfTrace: Untuk menggunakan semua fitur, Anda memerlukan versi minimal 4,9. BpfTrace memungkinkan Anda membuat banyak probe berbeda, mulai dengan uprobe untuk menginstruksikan pemanggilan fungsi di aplikasi pengguna, kernel-probe, dll.
Untuk menggunakan semua fitur, Anda memerlukan versi minimal 4,9. BpfTrace memungkinkan Anda membuat banyak probe berbeda, mulai dengan uprobe untuk menginstruksikan pemanggilan fungsi di aplikasi pengguna, kernel-probe, dll. Menariknya, ada setara uretprobe untuk fungsi pakaian khusus. Untuk kernel, hal yang sama adalah kprobe dan kretprobe. Ini berarti bahwa sebenarnya dalam kerangka penelusuran Anda dapat menghasilkan peristiwa ketika fungsi dipanggil dan setelah menyelesaikan fungsi ini - ini sering digunakan untuk penentuan waktu. Atau Anda dapat menganalisis nilai-nilai yang dikembalikan fungsi dan mengelompokkannya sesuai dengan parameter yang dipanggil fungsi. Jika Anda menangkap panggilan fungsi dan kembali darinya, Anda dapat melakukan banyak hal keren.Di dalam bpfTrace berfungsi seperti ini: kita menulis program bpf yang diuraikan, dikonversi ke C, kemudian diproses melalui Dentang, yang menghasilkan kode byte bpf, setelah itu program dimuat.
Menariknya, ada setara uretprobe untuk fungsi pakaian khusus. Untuk kernel, hal yang sama adalah kprobe dan kretprobe. Ini berarti bahwa sebenarnya dalam kerangka penelusuran Anda dapat menghasilkan peristiwa ketika fungsi dipanggil dan setelah menyelesaikan fungsi ini - ini sering digunakan untuk penentuan waktu. Atau Anda dapat menganalisis nilai-nilai yang dikembalikan fungsi dan mengelompokkannya sesuai dengan parameter yang dipanggil fungsi. Jika Anda menangkap panggilan fungsi dan kembali darinya, Anda dapat melakukan banyak hal keren.Di dalam bpfTrace berfungsi seperti ini: kita menulis program bpf yang diuraikan, dikonversi ke C, kemudian diproses melalui Dentang, yang menghasilkan kode byte bpf, setelah itu program dimuat. Prosesnya cukup sulit, sehingga ada batasannya. Pada server yang kuat, bpfTrace berfungsi dengan baik. Tapi menyeret Dentang ke perangkat tertanam kecil untuk mencari tahu apa yang terjadi bukanlah ide yang baik. Ply cocok untuk ini . Tentu saja, ia tidak memiliki semua fitur bpfTrace, tetapi ia menghasilkan bytecode secara langsung.
Prosesnya cukup sulit, sehingga ada batasannya. Pada server yang kuat, bpfTrace berfungsi dengan baik. Tapi menyeret Dentang ke perangkat tertanam kecil untuk mencari tahu apa yang terjadi bukanlah ide yang baik. Ply cocok untuk ini . Tentu saja, ia tidak memiliki semua fitur bpfTrace, tetapi ia menghasilkan bytecode secara langsung.Dukungan Linux
Versi stabil bpfTrace dirilis sekitar setahun yang lalu, sehingga tidak tersedia di distribusi Linux yang lebih lama. Yang terbaik adalah mengambil paket atau menyusun versi terbaru yang didistribusikan IO Visor.Menariknya, Ubuntu LTS 18.04 terbaru tidak memiliki bpfTrace, tetapi dapat dikirimkan menggunakan paket snap. Di satu sisi, ini nyaman, tetapi di sisi lain, karena cara paket snap dibuat dan diisolasi, tidak semua fungsi akan berfungsi. Untuk penelusuran kernel, paket dengan snap berfungsi dengan baik, untuk penelusuran pengguna, mungkin tidak berfungsi dengan benar.
Contoh Penelusuran Proses
Pertimbangkan contoh paling sederhana yang memungkinkan Anda mendapatkan statistik tentang permintaan IO:bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
Di sini kita terhubung ke fungsi vfs_read, baik kretprobe dan kprobe. Selanjutnya untuk setiap ID utas (tid), yaitu, untuk setiap permintaan, kami melacak awal dan akhir pelaksanaannya. Data dapat dikelompokkan tidak hanya oleh totalitas seluruh sistem, tetapi juga oleh berbagai proses. Di bawah ini adalah output IO untuk MySQL. Distribusi I / O bimodal klasik terlihat. Sejumlah besar permintaan cepat adalah data yang dibaca dari cache. Puncak kedua adalah membaca data dari disk, di mana latensi jauh lebih tinggi.Anda dapat menyimpan ini sebagai skrip (ekstensi bt biasanya digunakan), menulis komentar, memformatnya dan menggunakannya lebih lanjut
Distribusi I / O bimodal klasik terlihat. Sejumlah besar permintaan cepat adalah data yang dibaca dari cache. Puncak kedua adalah membaca data dari disk, di mana latensi jauh lebih tinggi.Anda dapat menyimpan ini sebagai skrip (ekstensi bt biasanya digunakan), menulis komentar, memformatnya dan menggunakannya lebih lanjut #bpftrace read.bt.// read.bt file
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid]/
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}
Konsep umum bahasa ini cukup sederhana.- Sintaks: pilih probe untuk dihubungkan
probe[,probe,...] /filter/ { action }. - Filter: tentukan filter, misalnya, hanya data pada proses tertentu dari Pid yang diberikan.
- Tindakan: program mini yang mengkonversi langsung ke program bpf dan berjalan ketika bpfTrace dipanggil.
Rincian lebih lanjut dapat ditemukan di sini .Alat Bpftrace
BpfTrace juga memiliki kotak alat. Banyak alat yang cukup sederhana tentang BCC sekarang diimplementasikan di bpfTrace. Koleksinya masih kecil, tetapi ada sesuatu yang tidak ada di BCC. Misalnya, killsnoop memungkinkan Anda melacak sinyal yang disebabkan oleh kill ().Jika Anda tertarik untuk melihat kode bpf, maka di bpfTrace Anda dapat
Koleksinya masih kecil, tetapi ada sesuatu yang tidak ada di BCC. Misalnya, killsnoop memungkinkan Anda melacak sinyal yang disebabkan oleh kill ().Jika Anda tertarik untuk melihat kode bpf, maka di bpfTrace Anda dapat -vmelihat kode byte yang dihasilkan. Ini berguna jika Anda ingin memahami probe yang berat atau tidak. Setelah melihat kode dan hanya memperkirakan ukurannya (satu atau dua halaman), Anda dapat memahami betapa rumitnya itu.
Contoh penelusuran MySQL
Mari saya tunjukkan contoh dari MySQL, cara kerjanya. MySQL memiliki fungsi dispatch_commanddi mana semua eksekusi query MySQL terjadi.bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
failed to stat uprobe target file /usr/sbin/mysqld: No such file or directory
Saya hanya ingin menghubungkan jubah untuk mencetak teks pertanyaan yang datang ke MySQL - tugas primitif. Punya masalah - mengatakan bahwa tidak ada file seperti itu. Seperti tidak ketika di sini:root@mysql1:/# ls -la /usr/sbin/mysqld
-rwxr-xr-x 1 root root 60718384 Oct 25 09:19 /usr/sbin/mysqld
Ini hanya kejutan dengan cepat. Jika diatur melalui snap, maka mungkin ada masalah di level aplikasi.Kemudian saya menginstal melalui versi apt, Ubuntu yang lebih baru, mulai lagi:root@mysql1:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
Could not resolve symbol: /usr/sbin/mysqld:dispatch_command
"Tidak ada simbol seperti itu" - bagaimana tidak ?! Saya melihat nmapakah ada simbol seperti itu atau tidak:root@mysql1:~# nm -D /usr/sbin/mysqld | grep dispatch_command
00000000005af770 T
_Z16dispatch_command19enum_server_commandP3THDPcjbb
root@localhost:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcjbb { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
select @@version_comment limit 1
select 1
Ada simbol seperti itu, tetapi karena MySQL dikompilasi dari C ++, mangling digunakan di sana. Bahkan, nama yang sekarang fungsi yang digunakan dalam perintah ini, sebagai berikut: _Z16dispatch_command19enum_server_commandP3THDPcjbb. Jika Anda menggunakannya dalam suatu fungsi, maka Anda dapat terhubung dan mendapatkan hasilnya. Dalam ekosistem perf, banyak alat membuat unmangling otomatis, dan bpfTrace belum bisa.Juga perhatikan bendera -Duntuk nm. Ini penting karena MySQL, dan sekarang banyak paket lain, datang tanpa simbol dinamis (simbol debug) - mereka datang dalam paket lain. Jika Anda ingin menggunakan karakter-karakter ini, Anda memerlukan sebuah flag -D, jika tidak nm tidak akan melihatnya.: ++ 25–26 , . , , .
: ++ Online . 5 900 , , -.
: DevOpsConf 2019 HighLoad++ 2019 — , .
— , .