 Beberapa tahun terakhir di waktu senggang saya, saya telah melakukan triathlon. Olahraga ini sangat populer di banyak negara di dunia, terutama di Amerika Serikat, Australia dan Eropa. Saat ini semakin populer di Rusia dan negara-negara CIS. Ini tentang melibatkan amatir, bukan profesional. Tidak seperti hanya berenang di kolam renang, bersepeda dan jogging di pagi hari, triathlon melibatkan partisipasi dalam kompetisi dan persiapan sistematis untuk mereka, bahkan tanpa menjadi seorang profesional. Tentunya di antara teman-teman Anda sudah ada setidaknya satu "pria besi" atau seseorang yang berencana untuk menjadi satu. Massiveness, berbagai jarak dan kondisi, tiga olahraga dalam satu - semua ini memiliki potensi untuk pembentukan sejumlah besar data. Setiap tahun, beberapa ratus kompetisi triathlon berlangsung di dunia, di mana beberapa ratus ribu orang berpartisipasi.Kompetisi diadakan oleh beberapa penyelenggara. Masing-masing dari mereka, tentu saja, mempublikasikan hasilnya dalam haknya sendiri. Tetapi untuk atlet dari Rusia dan beberapa negara CIS, timtristats.ru mengumpulkan semua hasil di satu tempat - di situs webnya dengan nama yang sama. Ini membuatnya sangat nyaman untuk mencari hasil, baik milik Anda maupun teman dan saingan Anda, atau bahkan idola Anda. Tetapi bagi saya itu juga memberi kesempatan untuk menganalisis sejumlah besar hasil secara terprogram. Hasil yang dipublikasikan di trilife: baca .Ini adalah proyek pertama saya seperti ini, karena baru-baru ini saya mulai melakukan analisis data pada prinsipnya, serta menggunakan python. Oleh karena itu, saya ingin memberi tahu Anda tentang implementasi teknis dari pekerjaan ini, terutama karena dalam prosesnya, berbagai nuansa muncul, kadang-kadang membutuhkan pendekatan khusus. Ini akan tentang memo, parsing, jenis dan format casting, mengembalikan data yang tidak lengkap, membuat sampel yang representatif, visualisasi, vektorisasi, dan bahkan komputasi paralel.Volumenya ternyata besar, jadi saya membagi semuanya menjadi lima bagian sehingga saya bisa menghitung informasi dan mengingat di mana harus memulai setelah istirahat.Sebelum melanjutkan, lebih baik membaca artikel saya terlebih dahulu dengan hasil penelitian, karena di sini pada dasarnya dijelaskan dapur untuk pembuatannya. Dibutuhkan 10-15 menit.Sudahkah Anda membaca? Ayo pergi!
Beberapa tahun terakhir di waktu senggang saya, saya telah melakukan triathlon. Olahraga ini sangat populer di banyak negara di dunia, terutama di Amerika Serikat, Australia dan Eropa. Saat ini semakin populer di Rusia dan negara-negara CIS. Ini tentang melibatkan amatir, bukan profesional. Tidak seperti hanya berenang di kolam renang, bersepeda dan jogging di pagi hari, triathlon melibatkan partisipasi dalam kompetisi dan persiapan sistematis untuk mereka, bahkan tanpa menjadi seorang profesional. Tentunya di antara teman-teman Anda sudah ada setidaknya satu "pria besi" atau seseorang yang berencana untuk menjadi satu. Massiveness, berbagai jarak dan kondisi, tiga olahraga dalam satu - semua ini memiliki potensi untuk pembentukan sejumlah besar data. Setiap tahun, beberapa ratus kompetisi triathlon berlangsung di dunia, di mana beberapa ratus ribu orang berpartisipasi.Kompetisi diadakan oleh beberapa penyelenggara. Masing-masing dari mereka, tentu saja, mempublikasikan hasilnya dalam haknya sendiri. Tetapi untuk atlet dari Rusia dan beberapa negara CIS, timtristats.ru mengumpulkan semua hasil di satu tempat - di situs webnya dengan nama yang sama. Ini membuatnya sangat nyaman untuk mencari hasil, baik milik Anda maupun teman dan saingan Anda, atau bahkan idola Anda. Tetapi bagi saya itu juga memberi kesempatan untuk menganalisis sejumlah besar hasil secara terprogram. Hasil yang dipublikasikan di trilife: baca .Ini adalah proyek pertama saya seperti ini, karena baru-baru ini saya mulai melakukan analisis data pada prinsipnya, serta menggunakan python. Oleh karena itu, saya ingin memberi tahu Anda tentang implementasi teknis dari pekerjaan ini, terutama karena dalam prosesnya, berbagai nuansa muncul, kadang-kadang membutuhkan pendekatan khusus. Ini akan tentang memo, parsing, jenis dan format casting, mengembalikan data yang tidak lengkap, membuat sampel yang representatif, visualisasi, vektorisasi, dan bahkan komputasi paralel.Volumenya ternyata besar, jadi saya membagi semuanya menjadi lima bagian sehingga saya bisa menghitung informasi dan mengingat di mana harus memulai setelah istirahat.Sebelum melanjutkan, lebih baik membaca artikel saya terlebih dahulu dengan hasil penelitian, karena di sini pada dasarnya dijelaskan dapur untuk pembuatannya. Dibutuhkan 10-15 menit.Sudahkah Anda membaca? Ayo pergi!Bagian 1. Menggores dan parsing
Diberikan: Situs web tristats.ru . Ada dua jenis tabel di atasnya yang menarik minat kita. Ini sebenarnya adalah tabel ringkasan dari semua ras dan protokol hasil masing-masing.
 Tugas nomor satu adalah mendapatkan data ini secara terprogram dan menyimpannya untuk diproses lebih lanjut. Kebetulan saat itu saya baru mengenal teknologi web dan karena itu tidak segera tahu bagaimana melakukan ini. Saya mulai sesuai dengan apa yang saya tahu - lihat kode halaman. Ini dapat dilakukan dengan menggunakan tombol kanan mouse atau tombol F12 .
Tugas nomor satu adalah mendapatkan data ini secara terprogram dan menyimpannya untuk diproses lebih lanjut. Kebetulan saat itu saya baru mengenal teknologi web dan karena itu tidak segera tahu bagaimana melakukan ini. Saya mulai sesuai dengan apa yang saya tahu - lihat kode halaman. Ini dapat dilakukan dengan menggunakan tombol kanan mouse atau tombol F12 . Menu di Chrome berisi dua opsi: Lihat kode halaman dan Lihat kode . Bukan divisi yang paling jelas. Secara alami, mereka memberikan hasil yang berbeda. Yang melihat kode, itu sama dengan F12 - representasi html langsung dari apa yang ditampilkan di browser adalah elemen-bijaksana.
Menu di Chrome berisi dua opsi: Lihat kode halaman dan Lihat kode . Bukan divisi yang paling jelas. Secara alami, mereka memberikan hasil yang berbeda. Yang melihat kode, itu sama dengan F12 - representasi html langsung dari apa yang ditampilkan di browser adalah elemen-bijaksana.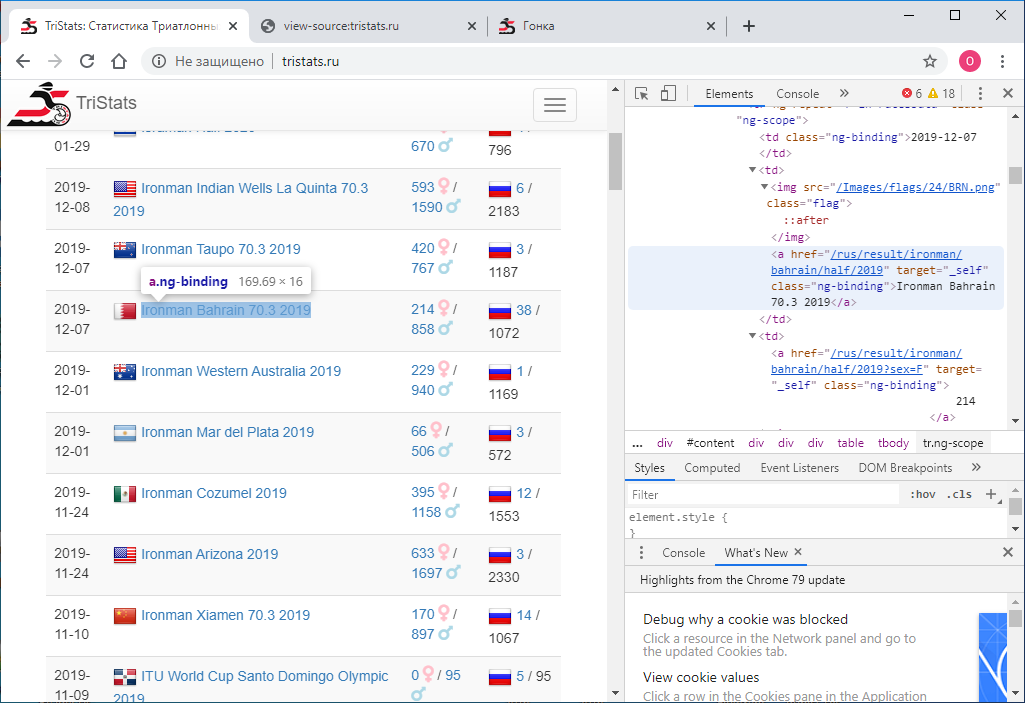 Pada gilirannya, melihat kode halaman memberikan kode sumber halaman. Juga html , tetapi tidak ada data di sana, hanya nama-nama skrip JS yang membongkar mereka. Baik.
Pada gilirannya, melihat kode halaman memberikan kode sumber halaman. Juga html , tetapi tidak ada data di sana, hanya nama-nama skrip JS yang membongkar mereka. Baik. Sekarang kita perlu memahami cara menggunakan python untuk menyimpan kode setiap halaman sebagai file teks terpisah. Saya coba ini:
Sekarang kita perlu memahami cara menggunakan python untuk menyimpan kode setiap halaman sebagai file teks terpisah. Saya coba ini:import requests
r = requests.get(url='http://tristats.ru/')
print(r.content)
Dan saya mendapatkan ... kode sumbernya. Tapi saya butuh hasil eksekusi. Setelah mempelajari, mencari, dan bertanya-tanya, saya menyadari bahwa saya memerlukan alat untuk mengotomatiskan tindakan peramban, misalnya selenium . Saya taruh itu. Dan juga ChromeDriver untuk bekerja dengan Google Chrome . Kemudian saya menggunakannya sebagai berikut:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
print(driver.page_source)
driver.quit()
Kode ini meluncurkan jendela browser dan membuka halaman di dalamnya di url yang ditentukan. Akibatnya, kami mendapatkan kode html dengan data yang diinginkan. Tapi ada satu halangan. Hasilnya hanya 100 entri, dan jumlah total balapan hampir 2000. Bagaimana bisa? Faktanya adalah bahwa awalnya hanya 100 entri pertama yang ditampilkan di browser, dan hanya jika Anda menggulir ke bagian paling bawah halaman, 100 entri berikutnya dimuat, dan seterusnya. Oleh karena itu, perlu menerapkan pengguliran secara terprogram. Untuk melakukan ini, gunakan perintah:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
Dan dengan setiap pengguliran, kami akan memeriksa apakah kode halaman yang dimuat telah berubah atau tidak. Jika belum berubah, kami akan memeriksa beberapa kali untuk keandalan, misalnya 10, maka seluruh halaman dimuat dan Anda dapat berhenti. Di antara gulungan, kami mengatur batas waktu ke satu detik sehingga halaman memiliki waktu untuk memuat. (Bahkan jika dia tidak punya waktu, kami memiliki cadangan - sembilan detik lagi).Dan kode lengkapnya akan terlihat seperti ini:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
prev_html = ''
scroll_attempt = 0
while scroll_attempt < 10:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
if prev_html == driver.page_source:
scroll_attempt += 1
else:
prev_html = driver.page_source
scroll_attempt = 0
with open(r'D:\tri\summary.txt', 'w') as f:
f.write(prev_html)
driver.quit()
Jadi, kami memiliki file html dengan tabel ringkasan semua ras. Perlu menguraikannya. Untuk melakukan ini, gunakan perpustakaan lxml .from lxml import html
Pertama-tama kita menemukan semua baris tabel. Untuk menentukan tanda string, lihat saja file html di editor teks. Itu bisa, misalnya, “tr ng-repeat = 'r in racesData' class = 'ng-scope'” atau beberapa fragmen yang tidak lagi ditemukan dalam tag apa pun.
Itu bisa, misalnya, “tr ng-repeat = 'r in racesData' class = 'ng-scope'” atau beberapa fragmen yang tidak lagi ditemukan dalam tag apa pun.with open(r'D:\tri\summary.txt', 'r') as f:
sum_html = f.read()
tree = html.fromstring(sum_html)
rows = tree.findall(".//*[@ng-repeat='r in racesData']")
kemudian kita mulai bingkai data panda dan setiap elemen dari setiap baris tabel ditulis ke kerangka data ini.import pandas as pd
rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows)))
Untuk mengetahui di mana setiap elemen tertentu disembunyikan, Anda hanya perlu melihat kode html dari salah satu elemen baris kami di editor teks yang sama.<tr ng-repeat="r in racesData" class="ng-scope">
<td class="ng-binding">2015-04-26</td>
<td>
<img src="/Images/flags/24/USA.png" class="flag">
<a href="/rus/result/ironman/texas/half/2015" target="_self" class="ng-binding">Ironman Texas 70.3 2015</a>
</td>
<td>
<a href="/rus/result/ironman/texas/half/2015?sex=F" target="_self" class="ng-binding">605</a>
<i class="fas fa-venus fa-lg" style="color:Pink"></i>
/
<a href="/rus/result/ironman/texas/half/2015?sex=M" target="_self" class="ng-binding">1539</a>
<i class="fas fa-mars fa-lg" style="color:LightBlue"></i>
</td>
<td class="ng-binding">
<img src="/Images/flags/24/rus.png" class="flag">
<a ng-if="r.CountryCount > 0" href="/rus/result/ironman/texas/half/2015?country=rus" target="_self" class="ng-binding ng-scope">2</a>
/ 2144
</td>
</tr>
Cara termudah untuk navigasi hardcode untuk anak-anak di sini adalah tidak banyak dari mereka.for i in range(len(rows)):
rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip()
rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip()
rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip()
rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip()
rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip()
rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip()
rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
Inilah hasilnya: Simpan bingkai data ini ke file. Saya menggunakan acar , tetapi bisa juga csv , atau yang lainnya.import pickle as pkl
with open(r'D:\tri\summary.pkl', 'wb') as f:
pkl.dump(df,f)
Pada tahap ini, semua data adalah tipe string. Kami akan mengonversi nanti. Yang paling penting yang kita butuhkan sekarang adalah tautan. Kami akan menggunakannya untuk menghapus protokol semua ras. Kami membuatnya dalam gambar dan rupa tentang bagaimana hal itu dilakukan untuk tabel pivot. Dalam siklus untuk semua ras untuk masing-masing, kami akan membuka halaman dengan referensi, gulir dan dapatkan kode halaman. Dalam tabel ringkasan, kami memiliki informasi tentang jumlah total peserta dalam lomba - total, kami akan menggunakannya untuk memahami sampai titik mana Anda perlu terus menggulir. Untuk melakukan ini, kami akan secara langsung dalam proses pengikisan setiap halaman menentukan jumlah catatan dalam tabel dan membandingkannya dengan nilai total yang diharapkan. Begitu sama, maka kami gulir ke akhir dan Anda dapat melanjutkan ke balapan berikutnya. Kami juga menetapkan batas waktu 60 detik. Makan selama ini, kita tidak bisa total , pergi ke balapan berikutnya. Kode halaman akan disimpan ke file. Kami akan menyimpan file semua ras dalam satu folder, dan beri nama dengan nama ras, yaitu dengan nilai pada kolom acara di tabel ringkasan. Untuk menghindari konflik nama, semua ras harus memiliki nama yang berbeda di tabel pivot. Periksa ini:df[df.duplicated(subset = 'event', keep=False)]
service.start()
driver = webdriver.Remote(service.service_url)
timeout = 60
for index, row in df.iterrows():
try:
driver.get('http://www.tristats.ru' + row['link'])
start = time.time()
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
race_html = driver.page_source
tree = html.fromstring(race_html)
race_rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
if len(race_rows) == int(row['total']):
break
if time.time() - start > timeout:
print('timeout')
break
with open(os.path.join(r'D:\tri\races', row['event'] + '.txt'), 'w') as f:
f.write(race_html)
except:
traceback.print_exc()
time.sleep(1)
driver.quit()
Ini proses yang panjang. Tetapi ketika semuanya sudah diatur dan mekanisme berat ini mulai berputar, menambahkan file data satu demi satu, perasaan kegembiraan yang menyenangkan datang. Hanya sekitar tiga protokol yang dimuat per menit, sangat lambat. Dibiarkan berputar untuk malam ini. Butuh sekitar 10 jam. Pada pagi hari, sebagian besar protokol sudah diunggah. Seperti yang biasanya terjadi ketika bekerja dengan jaringan, beberapa gagal. Cepat melanjutkan mereka dengan upaya kedua. Jadi, kami memiliki 1.922 file dengan total kapasitas hampir 3 GB. Keren! Tetapi menangani hampir 300 balapan berakhir dengan batas waktu. Apa masalahnya? Secara selektif memeriksa, ternyata memang total nilai dari tabel pivot dan jumlah entri dalam protokol balapan yang kami periksa mungkin tidak bersamaan. Ini menyedihkan karena tidak jelas apa alasan perbedaan ini. Entah ini karena fakta bahwa tidak semua orang akan selesai, atau semacam bug dalam database. Secara umum, sinyal pertama ketidaksempurnaan data. Bagaimanapun, kami memeriksa orang-orang di mana jumlah entri adalah 100 atau 0, ini adalah kandidat yang paling mencurigakan. Mereka ada delapan. Unduh lagi di bawah kontrol dekat. Omong-omong, di dua dari mereka sebenarnya ada 100 entri.Kami memiliki semua data. Kami lulus untuk parsing. Sekali lagi, dalam satu siklus kita akan menjalankan setiap balapan, membaca file dan menyimpan konten dalam panda DataFrame . Kami akan menggabungkan frame data ini menjadi dict , di mana nama-nama ras akan menjadi kunci - yaitu, nilai acara dari tabel pivot atau nama file dengan kode html dari halaman perlombaan, mereka bertepatan.
Jadi, kami memiliki 1.922 file dengan total kapasitas hampir 3 GB. Keren! Tetapi menangani hampir 300 balapan berakhir dengan batas waktu. Apa masalahnya? Secara selektif memeriksa, ternyata memang total nilai dari tabel pivot dan jumlah entri dalam protokol balapan yang kami periksa mungkin tidak bersamaan. Ini menyedihkan karena tidak jelas apa alasan perbedaan ini. Entah ini karena fakta bahwa tidak semua orang akan selesai, atau semacam bug dalam database. Secara umum, sinyal pertama ketidaksempurnaan data. Bagaimanapun, kami memeriksa orang-orang di mana jumlah entri adalah 100 atau 0, ini adalah kandidat yang paling mencurigakan. Mereka ada delapan. Unduh lagi di bawah kontrol dekat. Omong-omong, di dua dari mereka sebenarnya ada 100 entri.Kami memiliki semua data. Kami lulus untuk parsing. Sekali lagi, dalam satu siklus kita akan menjalankan setiap balapan, membaca file dan menyimpan konten dalam panda DataFrame . Kami akan menggabungkan frame data ini menjadi dict , di mana nama-nama ras akan menjadi kunci - yaitu, nilai acara dari tabel pivot atau nama file dengan kode html dari halaman perlombaan, mereka bertepatan.rd = {}
for e in rs['event']:
place = []
... sex = [], name=..., country, group, place_in_group, swim, t1, bike, t2, run
result = []
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r')
race_html = f.read()
tree = html.fromstring(race_html)
rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
for j in range(len(rows)):
row = rows[j]
parts = row.text_content().split('\n')
parts = [r.strip() for r in parts if r.strip() != '']
place.append(parts[0])
if len([a for a in row.findall('.//i')]) > 0:
sex.append([a for a in row.findall('.//i')][0].attrib['ng-if'][10:-1])
else:
sex.append('')
name.append(parts[1])
if len(parts) > 10:
country.append(parts[2].strip())
k=0
else:
country.append('')
k=1
group.append(parts[3-k])
... place_in_group.append(...), swim.append ..., t1, bike, t2, run
result.append(parts[10-k])
race = pd.DataFrame()
race['place'] = place
... race['sex'] = sex, race['name'] = ..., 'country', 'group', 'place_in_group', 'swim', ' t1', 'bike', 't2', 'run'
race['result'] = result
rd[e] = race
with open(r'D:\tri\details.pkl', 'wb') as f:
pkl.dump(rd,f)
for index, row in rs.iterrows():
e = row['event']
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') as f:
race_html = f.read()
tree = html.fromstring(race_html)
header_elem = [tb for tb in tree.findall('.//tbody') if tb.getchildren()[0].getchildren()[0].text == ''][0]
location = header_elem.getchildren()[1].getchildren()[1].text.strip()
rs.loc[index, 'loc'] = location
with open(r'D:\tri\summary1.pkl', 'wb') as f:
pkl.dump(df,f)
Bagian 2. Ketik casting dan pemformatan
Jadi, kami mengunduh semua data dan memasukkannya ke dalam bingkai data. Namun, semua nilai bertipe str . Ini berlaku untuk tanggal, dan ke hasil, dan ke lokasi, dan ke semua parameter lainnya. Semua parameter harus dikonversi ke tipe yang sesuai.Mari kita mulai dengan tabel pivot.tanggal dan waktu
acara , loc dan link yang akan ditinggalkan sebagaimana adanya. tanggal konversi menjadi datama panda sebagai berikut:rs['date'] = pd.to_datetime(rs['date'])
Sisanya dilemparkan ke tipe integer:cols = ['males', 'females', 'rus', 'total']
rs[cols] = rs[cols].astype(int)
Semuanya berjalan lancar, tidak ada kesalahan muncul. Jadi semuanya baik-baik saja - simpan:with open(r'D:\tri\summary2.pkl', 'wb') as f:
pkl.dump(rs, f)
Sekarang memacu dataframe. Karena semua ras yang lebih nyaman dan lebih cepat untuk proses sekaligus, dan tidak satu per satu, kami akan mengumpulkan mereka ke dalam satu besar ar frame data (singkat untuk semua catatan ) menggunakan concat metode .ar = pd.concat(rd)
ar berisi 1.416.365 entri.Sekarang, konversi tempat dan tempat dalam grup ke nilai integer.ar[['place', 'place in group']] = ar[['place', 'place in group']].astype(int))
Selanjutnya, kami memproses kolom dengan nilai sementara. Kami akan melemparkan mereka dalam jenis Timedelta dari panda . Tetapi agar konversi berhasil, Anda perlu menyiapkan data dengan benar. Anda dapat melihat bahwa beberapa nilai yang kurang dari satu jam berlalu tanpa menentukan ujungnya. Perlu menambahkannya.for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
strlen = ar[col].str.len()
ar.loc[strlen==5, col] = '0:' + ar.loc[strlen==5, col]
ar.loc[strlen==4, col] = '0:0' + ar.loc[strlen==4, col]
Sekarang kali, masih tersisa string, terlihat seperti ini: Konversikan ke Timedelta :for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
ar[col] = pd.to_timedelta(ar[col])
Lantai
Berpindah. Periksa bahwa di kolom seks hanya ada nilai M dan F :ar['sex'].unique()
Out: ['M', 'F', '']
Bahkan, masih ada string kosong, yaitu gender tidak ditentukan. Mari kita lihat berapa banyak kasus seperti ini:len(ar[ar['sex'] == ''])
Out: 2538
Tidak banyak yang baik. Di masa mendatang, kami akan mencoba untuk mengurangi nilai ini lebih jauh. Sementara itu, biarkan kolom seks seperti dalam bentuk garis. Kami akan menyimpan hasilnya sebelum beralih ke transformasi yang lebih serius dan berisiko. Dalam rangka mempertahankan kontinuitas antara file, kita mengubah frame data gabungan ar kembali ke kamus data frame rd :for event in ar.index.get_level_values(0).unique():
rd[event] = ar.loc[event]
with open(r'D:\tri\details1.pkl', 'wb') as f:
pkl.dump(rd,f)
Omong-omong, karena konversi jenis beberapa kolom, ukuran file menurun dari 367 KB menjadi 295 KB untuk tabel pivot dan dari 251 MB menjadi 168 MB untuk protokol balap.Kode negara
Sekarang mari kita lihat negaranya.ar['country'].unique()
Out: ['CRO', 'CZE', 'SLO', 'SRB', 'BUL', 'SVK', 'SWE', 'BIH', 'POL', 'MK', 'ROU', 'GRE', 'FRA', 'HUN', 'NOR', 'AUT', 'MNE', 'GBR', 'RUS', 'UAE', 'USA', 'GER', 'URU', 'CRC', 'ITA', 'DEN', 'TUR', 'SUI', 'MEX', 'BLR', 'EST', 'NED', 'AUS', 'BGI', 'BEL', 'ESP', 'POR', 'UKR', 'CAN', 'IRL', 'JPN', 'HKG', 'JEY', 'SGP', 'BRA', 'QAT', 'LUX', 'RSA', 'NZL', 'LAT', 'PHI', 'KSA', 'SEY', 'MAS', 'OMA', 'ARG', 'ECU', 'THA', 'JOR', 'BRN', 'CIV', 'FIN', 'IRN', 'BER', 'LBA', 'KUW', 'LTU', 'SRI', 'HON', 'INA', 'LBN', 'PAN', 'EGY', 'MLT', 'WAL', 'ISL', 'CYP', 'DOM', 'IND', 'VIE', 'MRI', 'AZE', 'MLD', 'LIE', 'VEN', 'ALG', 'SYR', 'MAR', 'KZK', 'PER', 'COL', 'IRQ', 'PAK', 'CZK', 'KAZ', 'CHN', 'NEP', 'ISR', 'MKD', 'FRO', 'BAN', 'ARU', 'CPV', 'ALB', 'BIZ', 'TPE', 'KGZ', 'BNN', 'CUB', 'SNG', 'VTN', 'THI', 'PRG', 'KOR', 'RE', 'TW', 'VN', 'MOL', 'FRE', 'AND', 'MDV', 'GUA', 'MON', 'ARM', 'F.I.TRI.', 'BAHREIN', 'SUECIA', 'REPUBLICA CHECA', 'BRASIL', 'CHI', 'MDA', 'TUN', 'NDL', 'Danish(Dane)', 'Welsh', 'Austrian', 'Unknown', 'AFG', 'Argentinean', 'Pitcairn', 'South African', 'Greenland', 'ESTADOS UNIDOS', 'LUXEMBURGO', 'SUDAFRICA', 'NUEVA ZELANDA', 'RUMANIA', 'PM', 'BAH', 'LTV', 'ESA', 'LAB', 'GIB', 'GUT', 'SAR', 'ita', 'aut', 'ger', 'esp', 'gbr', 'hun', 'den', 'usa', 'sui', 'slo', 'cze', 'svk', 'fra', 'fin', 'isr', 'irn', 'irl', 'bel', 'ned', 'sco', 'pol', 'SMR', 'mex', 'STEEL T BG', 'KINO MANA', 'IVB', 'TCH', 'SCO', 'KEN', 'BAS', 'ZIM', 'Joe', 'PUR', 'SWZ', 'Mark', 'WLS', 'MYA', 'BOT', 'REU', 'NAM', 'NCL', 'BOL', 'GGY', 'ISV', 'TWN', 'GUM', 'FIJ', 'COK', 'NGR', 'IRI', 'GAB', 'ANT', 'GEO', 'COG', 'sue', 'SUD', 'BAR', 'CAY', 'BO', 'VE', 'AX', 'MD', 'PAR', 'UM', 'SEN', 'NIG', 'RWA', 'YEM', 'PLE', 'GHA', 'ITU', 'UZB', 'MGL', 'MAC', 'DMA', 'TAH', 'TTO', 'AHO', 'JAM', 'SKN', 'GRN', 'PRK', 'NFK', 'SOL', 'Sandy', 'SAM', 'PNG', 'SGS', 'Suchy, Jorg', 'SOG', 'GEQ', 'BVT', 'DJI', 'CHA', 'ANG', 'YUG', 'IOT', 'HAI', 'SJM', 'CUW', 'BHU', 'ERI', 'FLK', 'HMD', 'GUF', 'ESH', 'sandy', 'UMI', 'selsmark, 'Alise', 'Eddie', '31/3, Colin', 'CC', '', '', '', '', '', ' ', '', '', '', '-', '', 'GRL', 'UGA', 'VAT', 'ETH', 'ASA', 'PYF', 'ATA', 'ALA', 'MTQ', 'ZZ', 'CXR', 'AIA', 'TJK', 'GUY', 'KR', 'PF', 'BN', 'MO', 'LA', 'CAM', 'NCA', 'ZAM', 'MAD', 'TOG', 'VIR', 'ATF', 'VAN', 'SLE', 'GLP', 'SCG', 'LAO', 'IMN', 'BUR', 'IR', 'SY', 'CMR', 'GBS', 'SUR', 'MOZ', 'BLM', 'MSR', 'CAF', 'BEN', 'COD', 'CCK', 'TUV', 'TGA', 'GI', 'XKX', 'NRU', 'NC', 'LBR', 'TAN', 'VIN', 'SSD', 'GP', 'PS', 'IM', 'JE', '', 'MLI', 'FSM', 'LCA', 'GMB', 'MHL', 'NH', 'FL', 'CT', 'UT', 'AQ', 'Korea', 'Taiwan', 'NewCaledonia', 'Czech Republic', 'PLW', 'BRU', 'RUN', 'NIU', 'KIR', 'SOM', 'TKM', 'SPM', 'BDI', 'COM', 'TCA', 'SHN', 'DO2', 'DCF', 'PCN', 'MNP', 'MYT', 'SXM', 'MAF', 'GUI', 'AN', 'Slovak republic', 'Channel Islands', 'Reunion', 'Wales', 'Scotland', 'ica', 'WLF', 'D', 'F', 'I', 'B', 'L', 'E', 'A', 'S', 'N', 'H', 'R', 'NU', 'BES', 'Bavaria', 'TLS', 'J', 'TKL', 'Tirol"', 'P', '?????', 'EU', 'ES-IB', 'ES-CT', '', 'SOO', 'LZE', '', '', '', '', '', '']
412 nilai unik.Pada dasarnya, suatu negara ditandai dengan kode huruf tiga digit dalam huruf besar. Namun ternyata, tidak selalu. Bahkan, ada standar internasional ISO 3166 , di mana untuk semua negara, termasuk bahkan yang tidak ada lagi, kode tiga digit dan dua digit yang sesuai ditentukan. Untuk python, salah satu implementasi dari standar ini dapat ditemukan dalam paket pycountry . Begini cara kerjanya:import pycountry as pyco
pyco.countries.get(alpha_3 = 'RUS')
Out: Country(alpha_2='RU', alpha_3='RUS', name='Russian Federation', numeric='643')
Dengan demikian, kami akan memeriksa semua kode tiga digit, yang mengarah ke huruf besar, yang memberikan respons di countries.get (...) dan historical_countries.get (...) :valid_a3 = [c for c in ar['country'].unique() if pyco.countries.get(alpha_3 = c.upper()) != None or pyco.historic_countries.get(alpha_3 = c.upper()) != None])
Ada 190 dari 412 di antaranya, yaitu kurang dari setengah.Untuk 222 (kami menunjukkan daftar mereka dengan sisa tofix ), kita akan membuat fix kamus yang cocok , di mana kunci akan menjadi nama asli, dan nilai adalah kode tiga digit sesuai dengan standar ISO.tofix = list(set(ar['country'].unique()) - set(valid_a3))
Pertama, periksa kode dua digit dengan pycountry.countries.get (alpha_2 = ...) , mengarah ke huruf besar:for icc in tofix:
if pyco.countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.countries.get(alpha_2 = icc.upper()).alpha_3
else:
if pyco.historic_countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.historic_countries.get(alpha_2 = icc.upper()).alpha_3
Kemudian nama lengkap melalui pycountry.countries.get (name = ...), pycountry.countries.get (common_name = ...) , menuntun mereka ke form str.title () :for icc in tofix:
if pyco.countries.get(common_name = icc.title()) != None:
fix[icc] = pyco.countries.get(common_name = icc.title()).alpha_3
else:
if pyco.countries.get(name = icc.title()) != None:
fix[icc] = pyco.countries.get(name = icc.title()).alpha_3
else:
if pyco.historic_countries.get(name = icc.title()) != None:
fix[icc] = pyco.historic_countries.get(name = icc.title()).alpha_3
Dengan demikian, kami mengurangi jumlah nilai yang tidak dikenali menjadi 190. Masih cukup banyak: Anda mungkin memperhatikan di antara mereka masih ada banyak kode tiga digit, tetapi ini bukan ISO. Lalu bagaimana? Ternyata ada standar lain - Olimpiade . Sayangnya, implementasinya tidak termasuk dalam pycountry dan Anda harus mencari yang lain. Solusinya ditemukan dalam bentuk file csv di datahub.io . Tempatkan isi file ini dalam panda DataFrame yang disebut cdf . ioc - Komite Olimpiade Internasional (IOC)['URU', '', 'PAR', 'SUECIA', 'KUW', 'South African', '', 'Austrian', 'ISV', 'H', 'SCO', 'ES-CT', ', 'GUI', 'BOT', 'SEY', 'BIZ', 'LAB', 'PUR', ' ', 'Scotland', '', '', 'TCH', 'TGA', 'UT', 'BAH', 'GEQ', 'NEP', 'TAH', 'ica', 'FRE', 'E', 'TOG', 'MYA', '', 'Danish (Dane)', 'SAM', 'TPE', 'MON', 'ger', 'Unknown', 'sui', 'R', 'SUI', 'A', 'GRN', 'KZK', 'Wales', '', 'GBS', 'ESA', 'Bavaria', 'Czech Republic', '31/3, Colin', 'SOL', 'SKN', '', 'MGL', 'XKX', 'WLS', 'MOL', 'FIJ', 'CAY', 'ES-IB', 'BER', 'PLE', 'MRI', 'B', 'KSA', '', '', 'LAT', 'GRE', 'ARU', '', 'THI', 'NGR', 'MAD', 'SOG', 'MLD', '?????', 'AHO', 'sco', 'UAE', 'RUMANIA', 'CRO', 'RSA', 'NUEVA ZELANDA', 'KINO MANA', 'PHI', 'sue', 'Tirol"', 'IRI', 'POR', 'CZK', 'SAR', 'D', 'BRASIL', 'DCF', 'HAI', 'ned', 'N', 'BAHREIN', 'VTN', 'EU', 'CAM', 'Mark', 'BUL', 'Welsh', 'VIN', 'HON', 'ESTADOS UNIDOS', 'I', 'GUA', 'OMA', 'CRC', 'PRG', 'NIG', 'BHU', 'Joe', 'GER', 'RUN', 'ALG', '', 'Channel Islands', 'Reunion', 'REPUBLICA CHECA', 'slo', 'ANG', 'NewCaledonia', 'GUT', 'VIE', 'ASA', 'BAR', 'SRI', 'L', '', 'J', 'BAS', 'LUXEMBURGO', 'S', 'CHI', 'SNG', 'BNN', 'den', 'F.I.TRI.', 'STEEL T BG', 'NCA', 'Slovak republic', 'MAS', 'LZE', '-', 'F', 'BRU', '', 'LBA', 'NDL', 'DEN', 'IVB', 'BAN', 'Sandy', 'ZAM', 'sandy', 'Korea', 'SOO', 'BGI', '', 'LTV', 'selsmark, Alise', 'TAN', 'NED', '', 'Suchy, Jorg', 'SLO', 'SUDAFRICA', 'ZIM', 'Eddie', 'INA', '', 'SUD', 'VAN', 'FL', 'P', 'ITU', 'ZZ', 'Argentinean', 'CHA', 'DO2', 'WAL']
len(([x for x in tofix if x.upper() in list(cdf['ioc'])]))
Out: 82
Di antara kode tiga digit dari tofix, 82 IOC yang sesuai ditemukan. Tambahkan mereka ke kamus kami yang cocok.for icc in tofix:
if icc.upper() in list(cdf['ioc']):
ind = cdf[cdf['ioc'] == icc.upper()].index[0]
fix[icc] = cdf.loc[ind, 'iso3']
108 nilai mentah tersisa. Mereka selesai secara manual, kadang-kadang beralih ke Google untuk meminta bantuan. Tetapi bahkan kontrol manual tidak sepenuhnya menyelesaikan masalah. Masih ada 49 nilai yang sudah mustahil untuk ditafsirkan. Sebagian besar nilai-nilai ini mungkin hanya kesalahan data.{'BGI': 'BRB', 'WAL': 'GBR', 'MLD': 'MDA', 'KZK': 'KAZ', 'CZK': 'CZE', 'BNN': 'BEN', 'SNG': 'SGP', 'VTN': 'VNM', 'THI': 'THA', 'PRG': 'PRT', 'MOL': 'MDA', 'FRE': 'FRA', 'F.I.TRI.': 'ITA', 'BAHREIN': 'BHR', 'SUECIA': 'SWE', 'REPUBLICA CHECA': 'CZE', 'BRASIL': 'BRA', 'NDL': 'NLD', 'Danish (Dane)': 'DNK', 'Welsh': 'GBR', 'Austrian': 'AUT', 'Argentinean': 'ARG', 'South African': 'ZAF', 'ESTADOS UNIDOS': 'USA', 'LUXEMBURGO': 'LUX', 'SUDAFRICA': 'ZAF', 'NUEVA ZELANDA': 'NZL', 'RUMANIA': 'ROU', 'sco': 'GBR', 'SCO': 'GBR', 'WLS': 'GBR', '': 'IND', '': 'IRL', '': 'ARM', '': 'BGR', '': 'SRB', ' ': 'BLR', '': 'GBR', '': 'FRA', '': 'HND', '-': 'CRI', '': 'AZE', 'Korea': 'KOR', 'NewCaledonia': 'FRA', 'Czech Republic': 'CZE', 'Slovak republic': 'SVK', 'Channel Islands': 'FRA', 'Reunion': 'FRA', 'Wales': 'GBR', 'Scotland': 'GBR', 'Bavaria': 'DEU', 'Tirol"': 'AUT', '': 'KGZ', '': 'BLR', '': 'BLR', '': 'BLR', '': 'RUS', '': 'BLR', '': 'RUS'}
unfixed = [x for x in tofix if x not in fix.keys()]
Out: ['', 'H', 'ES-CT', 'LAB', 'TCH', 'UT', 'TAH', 'ica', 'E', 'Unknown', 'R', 'A', '31/3, Colin', 'XKX', 'ES-IB','B','SOG','?????','KINO MANA','sue','SAR','D', 'DCF', 'N', 'EU', 'Mark', 'I', 'Joe', 'RUN', 'GUT', 'L', 'J', 'BAS', 'S', 'STEEL T BG', 'LZE', 'F', 'Sandy', 'DO2', 'sandy', 'SOO', 'LTV', 'selsmark, Alise', 'Suchy, Jorg' 'Eddie', 'FL', 'P', 'ITU', 'ZZ']
Kunci-kunci ini akan memiliki string kosong di kamus yang cocok.for cc in unfixed:
fix[cc] = ''
Akhirnya, kami menambahkan ke kode kamus yang cocok yang valid tetapi ditulis dalam huruf kecil.for cc in valid_a3:
if cc.upper() != cc:
fix[cc] = cc.upper()
Sekarang saatnya menerapkan pengganti yang ditemukan. Untuk menyimpan data awal untuk perbandingan lebih lanjut, salin negara kolom untuk negara mentah . Kemudian, menggunakan kamus yang cocok yang dibuat, kami mengoreksi nilai - nilai di kolom negara yang tidak sesuai dengan ISO.for cc in fix:
ind = ar[ar['country'] == cc].index
ar.loc[ind,'country'] = fix[cc]
Di sini, tentu saja, seseorang tidak dapat melakukannya tanpa vektorisasi, tabel tersebut memiliki hampir satu setengah juta baris. Tetapi menurut kamus kami melakukan siklus, tapi bagaimana lagi? Periksa berapa banyak catatan yang diubah:len(ar[ar['country'] != ar['country raw']])
Out: 315955
yaitu, lebih dari 20% dari total.ar[ar['country'] != ar['country raw']].sample(10)
len(ar[ar['country'] == ''])
Out: 3221
Ini adalah jumlah catatan tanpa negara atau dengan negara informal. Jumlah negara unik menurun dari 412 menjadi 250. Inilah mereka: Sekarang tidak ada penyimpangan. Kami menyimpan hasilnya dalam file details2.pkl baru , setelah mengubah bingkai data gabungan kembali ke kamus frame data, seperti yang dilakukan sebelumnya.['', 'ABW', 'AFG', 'AGO', 'AIA', 'ALA', 'ALB', 'AND', 'ANT', 'ARE', 'ARG', 'ARM', 'ASM', 'ATA', 'ATF', 'AUS', 'AUT', 'AZE', 'BDI', 'BEL', 'BEN', 'BES', 'BGD', 'BGR', 'BHR', 'BHS', 'BIH', 'BLM', 'BLR', 'BLZ', 'BMU', 'BOL', 'BRA', 'BRB', 'BRN', 'BTN', 'BUR', 'BVT', 'BWA', 'CAF', 'CAN', 'CCK', 'CHE', 'CHL', 'CHN', 'CIV', 'CMR', 'COD', 'COG', 'COK', 'COL', 'COM', 'CPV', 'CRI', 'CTE', 'CUB', 'CUW', 'CXR', 'CYM', 'CYP', 'CZE', 'DEU', 'DJI', 'DMA', 'DNK', 'DOM', 'DZA', 'ECU', 'EGY', 'ERI', 'ESH', 'ESP', 'EST', 'ETH', 'FIN', 'FJI', 'FLK', 'FRA', 'FRO', 'FSM', 'GAB', 'GBR', 'GEO', 'GGY', 'GHA', 'GIB', 'GIN', 'GLP', 'GMB', 'GNB', 'GNQ', 'GRC', 'GRD', 'GRL', 'GTM', 'GUF', 'GUM', 'GUY', 'HKG', 'HMD', 'HND', 'HRV', 'HTI', 'HUN', 'IDN', 'IMN', 'IND', 'IOT', 'IRL', 'IRN', 'IRQ', 'ISL', 'ISR', 'ITA', 'JAM', 'JEY', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM', 'KIR', 'KNA', 'KOR', 'KWT', 'LAO', 'LBN', 'LBR', 'LBY', 'LCA', 'LIE', 'LKA', 'LTU', 'LUX', 'LVA', 'MAC', 'MAF', 'MAR', 'MCO', 'MDA', 'MDG', 'MDV', 'MEX', 'MHL', 'MKD', 'MLI', 'MLT', 'MMR', 'MNE', 'MNG', 'MNP', 'MOZ', 'MSR', 'MTQ', 'MUS', 'MYS', 'MYT', 'NAM', 'NCL', 'NER', 'NFK', 'NGA', 'NHB', 'NIC', 'NIU', 'NLD', 'NOR', 'NPL', 'NRU', 'NZL', 'OMN', 'PAK', 'PAN', 'PCN', 'PER', 'PHL', 'PLW', 'PNG', 'POL', 'PRI', 'PRK', 'PRT', 'PRY', 'PSE', 'PYF', 'QAT', 'REU', 'ROU', 'RUS', 'RWA', 'SAU', 'SCG', 'SDN', 'SEN', 'SGP', 'SGS', 'SHN', 'SJM', 'SLB', 'SLE', 'SLV', 'SMR', 'SOM', 'SPM', 'SRB', 'SSD', 'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SXM', 'SYC', 'SYR', 'TCA', 'TCD', 'TGO', 'THA', 'TJK', 'TKL', 'TKM', 'TLS', 'TON', 'TTO', 'TUN', 'TUR', 'TUV', 'TWN', 'TZA', 'UGA', 'UKR', 'UMI', 'URY', 'USA', 'UZB', 'VAT', 'VCT', 'VEN', 'VGB', 'VIR', 'VNM', 'VUT', 'WLF', 'WSM', 'YEM', 'YUG', 'ZAF', 'ZMB', 'ZWE']
Lokasi
Sekarang ingat bahwa menyebutkan negara-negara juga di tabel pivot, di loc kolom . Itu juga perlu dibawa ke tampilan standar. Ini adalah cerita yang sedikit berbeda: ISO atau kode Olimpiade tidak terlihat. Semuanya dijelaskan dalam bentuk yang cukup bebas. Kota, negara, dan komponen alamat lainnya tercantum dengan koma, dan dalam urutan acak. Di suatu tempat di tempat pertama, di suatu tempat di tempat terakhir. pycountry tidak akan membantu di sini. Dan ada banyak catatan - untuk balapan 1922 525 lokasi unik (dalam bentuk aslinya). Tapi di sini alat yang cocok ditemukan. Ini adalah geopy , yaitu geolocator Nominatim . Ini berfungsi seperti ini:from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='triathlon results researcher')
geolocator.geocode(' , , ', language='en')
Out: Location( , – , , Altaysky District, Altai Krai, Siberian Federal District, Russia, (51.78897945, 85.73956296106752, 0.0))
Atas permintaan, dalam bentuk acak, itu memberikan jawaban terstruktur - alamat dan koordinat. Jika Anda mengatur bahasa, seperti di sini - Bahasa Inggris, maka apa yang bisa - akan diterjemahkan. Pertama-tama, kita memerlukan nama standar negara untuk terjemahan selanjutnya ke dalam kode ISO. Ini hanya mengambil tempat terakhir di properti alamat . Karena geolocator mengirim permintaan ke server setiap kali, proses ini tidak cepat dan membutuhkan 500 menit untuk 500 catatan. Apalagi kebetulan jawabannya tidak datang. Dalam hal ini, permintaan kedua terkadang membantu. Dalam tanggapan pertama saya tidak sampai 130 permintaan. Kebanyakan dari mereka diproses dengan dua percobaan ulang. Namun, 34 nama tidak diproses bahkan oleh beberapa percobaan ulang lebih lanjut. Di sini mereka:['Tongyeong, Korea, Korea, South', 'Constanta, Mamaia, Romania, Romania', 'Weihai, China, China', '. , .', 'Odaiba Marin Park, Tokyo, Japan, Japan', 'Sweden, Smaland, Kalmar', 'Cholpon-Ata city, Resort Center "Kapriz", Kyrgyzstan', 'Luxembourg, Region Moselle, Moselle', 'Chita Peninsula, Japan', 'Kraichgau Region, Germany', 'Jintang, Chengdu, Sichuan Province, China, China', 'Madrid, Spain, Spain', 'North American Pro Championship, St. George, Utah, USA', 'Milan Idroscalo Linate, Italy', 'Dexing, Jiangxi Province, China, China', 'Mooloolaba, Australia, Australia', 'Nathan Benderson Park (NBP), 5851 Nathan Benderson Circle, Sarasota, FL 34235., United States', 'Strathclyde Country Park, North Lanarkshire, Glasgow, Great Britain', 'Quijing, China', 'United States of America , Hawaii, Kohala Coast', 'Buffalo City, East London, South Africa', 'Spain, Vall de Cardener', ', . ', 'Asian TriClub Championship, Hefei, China', 'Taizhou, Jiangsu Province, China, China', ', , «»', 'Buffalo, Gallagher Beach, Furhmann Blvd, United States', 'North American Pro Championship | St. George, Utah, USA', 'Weihai, Shandong, China, China', 'Tarzo - Revine Lago, Italy', 'Lausanee, Switzerland', 'Queenstown, New Zealand, New Zealand', 'Makuhari, Japan, Japan', 'Szombathlely, Hungary']
Dapat dilihat bahwa di banyak negara disebutkan dua kali, dan ini benar-benar mengganggu. Secara umum, saya harus secara manual memproses sisa nama dan alamat standar ini diperoleh untuk semua. Selanjutnya, dari alamat ini saya memilih negara dan menulis negara ini di kolom baru di tabel pivot. Karena, seperti yang saya katakan, bekerja dengan geopy tidak cepat, saya memutuskan untuk segera menyimpan koordinat lokasi - lintang dan bujur. Mereka akan berguna nanti untuk visualisasi pada peta. Setelah itu, menggunakan pyco.countries.get (name = '...'). Alpha_3 mencari negara dengan nama dan mengalokasikan kode tiga digit.Jarak
Tindakan penting lain yang perlu dilakukan pada tabel pivot adalah menentukan jarak untuk setiap balapan. Ini berguna bagi kami untuk menghitung kecepatan di masa depan. Dalam triathlon, ada empat jarak utama - sprint, Olympic, semi-iron dan iron. Anda dapat melihat bahwa dalam nama-nama ras biasanya ada indikasi jarak - ini adalah Sprint , Olympic , Half , Full Words . Selain itu, penyelenggara yang berbeda memiliki penunjukan jarak mereka sendiri. Setengah dari Ironman, misalnya, ditetapkan sebagai 70,3 - dengan jumlah mil di kejauhan, Olimpiade - 5150 dengan jumlah kilometer (51,5), dan setrika dapat ditetapkan sebagai Penuhatau, secara umum, karena kurangnya penjelasan - misalnya, Ironman Arizona 2019 . Ironman - dia besi! Dalam Tantangan, jarak besi ditetapkan sebagai Panjang , dan jarak semi- besi ditetapkan sebagai Tengah . IronStar Rusia kami berarti penuh sebagai 226 , dan setengah sebagai 113 - dengan jumlah kilometer, tetapi biasanya kata-kata Penuh dan Setengah juga hadir. Sekarang terapkan semua pengetahuan ini dan tandai semua balapan sesuai dengan kata kunci yang ada dalam nama.sprints = rs.loc[[i for i in rs.index if 'sprint' in rs.loc[i, 'event'].lower()]]
olympics1 = rs.loc[[i for i in rs.index if 'olympic' in rs.loc[i, 'event'].lower()]]
olympics2 = rs.loc[[i for i in rs.index if '5150' in rs.loc[i, 'event'].lower()]]
olympics = pd.concat([olympics1, olympics2])
rsd = pd.concat([sprints, olympics, halfs, fulls])
Dalam rsd ternyata 1 925 catatan, yaitu, tiga lebih dari jumlah total balapan, sehingga beberapa jatuh di bawah dua kriteria. Mari kita lihat mereka:rsd[rsd.duplicated(keep=False)]['event'].sort_index()
olympics.drop(65)
Kami akan melakukan hal yang sama dengan memotong Ironman Dun Laoghaire Full Swim 70.3 2019 Ini adalah waktu terbaik 4:00. Ini khas untuk setengahnya. Hapus catatan dengan indeks 85 dari fulls .fulls.drop(85)
Sekarang kami akan menuliskan informasi jarak dalam bingkai data utama dan melihat apa yang terjadi:rs['dist'] = ''
rs.loc[sprints.index,'dist'] = 'sprint'
rs.loc[olympics.index,'dist'] = 'olympic'
rs.loc[halfs.index,'dist'] = 'half'
rs.loc[fulls.index,'dist'] = 'full'
rs.sample(10)
len(rs[rs['dist'] == ''])
Out: 0
Dan periksa yang bermasalah, ambigu kami:rs.loc[[38,65,82],['event','dist']]
pkl.dump(rs, open(r'D:\tri\summary5.pkl', 'wb'))
Kelompok umur
Sekarang kembali ke protokol balap.Kami telah menganalisis jenis kelamin, negara, dan hasil peserta, dan membawanya ke bentuk standar. Namun ada dua kolom lagi - grup dan, pada kenyataannya, nama itu sendiri. Mari kita mulai dengan grup. Dalam triathlon, adalah kebiasaan untuk membagi peserta berdasarkan kelompok umur. Sekelompok profesional juga sering menonjol. Faktanya, penggantian kerugian dilakukan di masing-masing grup secara terpisah - tiga tempat pertama dalam setiap grup diberikan. Dalam kelompok, kualifikasi dipilih untuk kejuaraan, misalnya, di Konu.Gabungkan semua catatan dan lihat kelompok apa yang secara umum ada.rd = pkl.load(open(r'D:\tri\details2.pkl', 'rb'))
ar = pd.concat(rd)
ar['group'].unique()
Ternyata ada sejumlah besar kelompok - 581. Seratus kelihatannya dipilih secara acak seperti ini: Mari kita lihat yang mana di antara mereka yang paling banyak:['MSenior', 'FAmat.', 'M20', 'M65-59', 'F25-29', 'F18-22', 'M75-59', 'MPro', 'F24', 'MCORP M', 'F21-30', 'MSenior 4', 'M40-50', 'FAWAD', 'M16-29', 'MK40-49', 'F65-70', 'F65-70', 'M12-15', 'MK18-29', 'M50up', 'FSEMIFINAL 2 PRO', 'F16', 'MWhite', 'MOpen 25-29', 'F', 'MPT TRI-2', 'M16-24', 'FQUALIFIER 1 PRO', 'F15-17', 'FSEMIFINAL 2 JUNIOR', 'FOpen 60-64', 'M75-80', 'F60-69', 'FJUNIOR A', 'F17-18', 'FAWAD BLIND', 'M75-79', 'M18-29', 'MJUN19-23', 'M60-up', 'M70', 'MPTS5', 'F35-40', "M'S PT1", 'M50-54', 'F65-69', 'F17-20', 'MP4', 'M16-29', 'F18up', 'MJU', 'MPT4', 'MPT TRI-3', 'MU24-39', 'MK35-39', 'F18-20', "M'S", 'F50-55', 'M75-80', 'MXTRI', 'F40-45', 'MJUNIOR B', 'F15', 'F18-19', 'M20-29', 'MAWAD PC4', 'M30-37', 'F21-30', 'Mpro', 'MSEMIFINAL 1 JUNIOR', 'M25-34', 'MAmat.', 'FAWAD PC5', 'FA', 'F50-60', 'FSenior 1', 'M80-84', 'FK45-49', 'F75-79', 'M<23', 'MPTS3', 'M70-75', 'M50-60', 'FQUALIFIER 3 PRO', 'M9', 'F31-40', 'MJUN16-19', 'F18-19', 'M PARA', 'F35-44', 'MParaathlete', 'F18-34', 'FA', 'FAWAD PC2', 'FAll Ages', 'M PARA', 'F31-40', 'MM85', 'M25-39']
ar['group'].value_counts()[:30]
Out:
M40-44 199157
M35-39 183738
M45-49 166796
M30-34 154732
M50-54 107307
M25-29 88980
M55-59 50659
F40-44 48036
F35-39 47414
F30-34 45838
F45-49 39618
MPRO 38445
F25-29 31718
F50-54 26253
M18-24 24534
FPRO 23810
M60-64 20773
M 12799
F55-59 12470
M65-69 8039
F18-24 7772
MJUNIOR 6605
F60-64 5067
M20-24 4580
FJUNIOR 4105
M30-39 3964
M40-49 3319
F 3306
M70-74 3072
F20-24 2522
Anda dapat melihat bahwa ini adalah kelompok lima tahun, secara terpisah untuk pria dan terpisah untuk wanita, serta kelompok profesional MPRO dan FPRO .Jadi standar kita adalah:ag = ['MPRO', 'M18-24', 'M25-29', 'M30-34', 'M35-39', 'M40-44', 'M45-49', 'M50-54', 'M55-59', 'M60-64', 'M65-69', 'M70-74', 'M75-79', 'M80-84', 'M85-90', 'FPRO', 'F18-24', 'F25-29', 'F30-34', 'F35-39', 'F40-44', 'F45-49', 'F50-54', 'F55-59', 'F60-64', 'F65-69', 'F70-74', 'F75-79', 'F80-84', 'F85-90']
Set ini mencakup hampir 95% dari semua finishers.Tentu saja, kami tidak akan dapat membawa semua kelompok ke standar ini. Tetapi kami mencari mereka yang mirip dengan mereka dan memberikan setidaknya sebagian. Pertama, kami akan membawa ke huruf besar dan menghapus spasi. Inilah yang terjadi: Konversikan ke standar kami.['F25-29F', 'F30-34F', 'F30-34-34', 'F35-39F', 'F40-44F', 'F45-49F', 'F50-54F', 'F55-59F', 'FAG:FPRO', 'FK30-34', 'FK35-39', 'FK40-44', 'FK45-49', 'FOPEN50-54', 'FOPEN60-64', 'MAG:MPRO', 'MK30-34', 'MK30-39', 'MK35-39', 'MK40-44', 'MK40-49', 'MK50-59', 'M40-44', 'MM85-89', 'MOPEN25-29', 'MOPEN30-34', 'MOPEN35-39', 'MOPEN40-44', 'MOPEN45-49', 'MOPEN50-54', 'MOPEN70-74', 'MPRO:', 'MPROM', 'M0-44"']
fix = { 'F25-29F': 'F25-29', 'F30-34F' : 'F30-34', 'F30-34-34': 'F30-34', 'F35-39F': 'F35-39', 'F40-44F': 'F40-44', 'F45-49F': 'F45-49', 'F50-54F': 'F50-54', 'F55-59F': 'F55-59', 'FAG:FPRO': 'FPRO', 'FK30-34': 'F30-34', 'FK35-39': 'F35-39', 'FK40-44': 'F40-44', 'FK45-49': 'F45-49', 'FOPEN50-54': 'F50-54', 'FOPEN60-64': 'F60-64', 'MAG:MPRO': 'MPRO', 'MK30-34': 'M30-34', 'MK30-39': 'M30-39', 'MK35-39': 'M35-39', 'MK40-44': 'M40-44', 'MK40-49': 'M40-49', 'MK50-59': 'M50-59', 'M40-44': 'M40-44', 'MM85-89': 'M85-89', 'MOPEN25-29': 'M25-29', 'MOPEN30-34': 'M30-34', 'MOPEN35-39': 'M35-39', 'MOPEN40-44': 'M40-44', 'MOPEN45-49': 'M45-49', 'MOPEN50-54': 'M50-54', 'MOPEN70-74': 'M70- 74', 'MPRO:' :'MPRO', 'MPROM': 'MPRO', 'M0-44"' : 'M40-44'}
Sekarang kita menerapkan transformasi untuk frame data utama ar , tapi pertama menyimpan asli kelompok nilai-nilai ke baru baku kelompok kolom .ar['group raw'] = ar['group']
Di kolom grup , kami hanya menyisakan nilai-nilai yang sesuai dengan standar kami.Sekarang kita bisa menghargai upaya kita:len(ar[(ar['group'] != ar['group raw'])&(ar['group']!='')])
Out: 273
Hanya sedikit di level satu setengah juta. Tetapi Anda tidak akan tahu sampai Anda mencobanya.Pilihan 10 terlihat seperti ini: Simpan versi baru dari bingkai data, setelah mengubahnya kembali ke kamus rd .pkl.dump(rd, open(r'D:\tri\details3.pkl', 'wb'))
Nama
Sekarang mari kita urus nama-namanya. Mari kita lihat secara selektif 100 nama dari berbagai ras:list(ar['name'].sample(100))
Out: ['Case, Christine', 'Van der westhuizen, Wouter', 'Grace, Scott', 'Sader, Markus', 'Schuller, Gunnar', 'Juul-Andersen, Jeppe', 'Nelson, Matthew', ' ', 'Westman, Pehr', 'Becker, Christoph', 'Bolton, Jarrad', 'Coto, Ricardo', 'Davies, Luke', 'Daniltchev, Alexandre', 'Escobar Labastida, Emmanuelle', 'Idzikowski, Jacek', 'Fairaislova Iveta', 'Fisher, Kulani', 'Didenko, Viktor', 'Osborne, Jane', 'Kadralinov, Zhalgas', 'Perkins, Chad', 'Caddell, Martha', 'Lynaire PARISH', 'Busing, Lynn', 'Nikitin, Evgeny', 'ANSON MONZON, ROBERTO', 'Kaub, Bernd', 'Bank, Morten', 'Kennedy, Ian', 'Kahl, Stephen', 'Vossough, Andreas', 'Gale, Karen', 'Mullally, Kristin', 'Alex FRASER', 'Dierkes, Manuela', 'Gillett, David', 'Green, Erica', 'Cunnew, Elliott', 'Sukk, Gaspar', 'Markina Veronika', 'Thomas KVARICS', 'Wu, Lewen', 'Van Enk, W.J.J', 'Escobar, Rosario', 'Healey, Pat', 'Scheef, Heike', 'Ancheta, Marlon', 'Heck, Andreas', 'Vargas Iii, Raul', 'Seferoglou, Maria', 'chris GUZMAN', 'Casey, Timothy', 'Olshanikov Konstantin', 'Rasmus Nerrand', 'Lehmann Bence', 'Amacker, Kirby', 'Parks, Chris', 'Tom, Troy', 'Karlsson, Ulf', 'Halfkann, Dorothee', 'Szabo, Gergely', 'Antipov Mikhail', 'Von Alvensleben, Alvo', 'Gruber, Peter', 'Leblanc, Jean-Philippe', 'Bouchard, Jean-Francois', 'Marchiotto MASSIMO', 'Green, Molly', 'Alder, Christoph', 'Morris, Huw', 'Deceur, Marc', 'Queenan, Derek', 'Krause, Carolin', 'Cockings, Antony', 'Ziehmer Chris', 'Stiene, John', 'Chmet Daniela', 'Chris RIORDAN', 'Wintle, Mel', ' ', 'GASPARINI CHRISTIAN', 'Westbrook, Christohper', 'Martens, Wim', 'Papson, Chris', 'Burdess, Shaun', 'Proctor, Shane', 'Cruzinha, Pedro', 'Hamard, Jacques', 'Petersen, Brett', 'Sahyoun, Sebastien', "O'Connell, Keith", 'Symoshenko, Zhan', 'Luternauer, Jan', 'Coronado, Basil', 'Smith, Alex', 'Dittberner, Felix', 'N?sman, Henrik', 'King, Malisa', 'PUHLMANN Andre']
Ini rumit. Ada berbagai opsi untuk entri: Nama Depan Nama Belakang, Nama Belakang, Nama Belakang, Nama Belakang, Nama Belakang, Nama Belakang , dll. Yaitu, urutan berbeda, register berbeda, di suatu tempat terdapat pemisah - koma. Ada juga banyak protokol di mana Cyrillic berjalan. Juga tidak ada keseragaman, dan format seperti itu dapat ditemukan: "Nama belakang Nama depan", "Nama depan Nama belakang", "Nama depan Nama tengah Nama belakang", "Nama belakang Nama depan Nama tengah". Meski sebenarnya, nama tengahnya juga ditemukan dalam ejaan Latin. Dan di sini, omong-omong, satu masalah lagi muncul - transliterasi. Perlu juga dicatat bahwa meskipun tidak ada nama tengah, catatan tersebut mungkin tidak terbatas pada dua kata. Misalnya, untuk Hispanik, nama plus nama biasanya terdiri dari tiga atau empat kata. Belanda memiliki awalan Van, orang Cina dan Korea juga memiliki nama majemuk yang biasanya terdiri dari tiga kata. Secara umum, Anda perlu menguraikan seluruh rebus ini dan membakukannya secara maksimal. Sebagai aturan, dalam satu ras, format nama adalah sama untuk semua orang, tetapi bahkan di sini ada kesalahan yang tidak akan kami tangani. Mari kita mulai dengan menyimpan nilai yang ada di nama kolom baru mentah :ar['name raw'] = ar['name']
Sebagian besar protokol dalam bahasa Latin, jadi hal pertama yang ingin saya lakukan adalah transliterasi. Mari kita lihat karakter apa yang dapat dimasukkan dalam nama peserta.set( ''.join(ar['name'].unique()))
Out: [' ', '!', '"', '#', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', 'µ', '¶', '·', '»', '', 'І', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', 'є', 'і', 'ў', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Apa yang ada di sana saja! Selain huruf dan spasi yang sebenarnya, masih ada banyak karakter aneh yang berbeda. Dari semua ini, periode '.', Tanda hubung '-', dan apostrof “'” dapat dianggap sah, yaitu, tidak ada karena kesalahan. Selain itu, diketahui bahwa di banyak nama dan nama keluarga Jerman dan Norwegia ada tanda tanya '?'. Mereka, tampaknya, mengganti karakter dari alfabet Latin yang diperluas - '?', 'A', 'o', 'u',? dan lain-lain: Berikut ini adalah contohnya: Koma, meskipun sering terjadi, hanyalah pemisah yang diadopsi pada ras tertentu, sehingga juga termasuk dalam kategori tidak dapat diterima. Angka juga tidak boleh muncul dalam nama.Pierre-Alexandre Petit, Jean-louis Lafontaine, Faris Al-Sultan, Jean-Francois Evrard, Paul O'Mahony, Aidan O'Farrell, John O'Neill, Nick D'Alton, Ward D'Hulster, Hans P.J. Cami, Luis E. Benavides, Maximo Jr. Rueda, Prof. Dr. Tim-Nicolas Korf, Dr. Boris Scharlowsk, Eberhard Gro?mann, Magdalena Wei?, Gro?er Axel, Meyer-Szary Krystian, Morten Halkj?r, RASMUSSEN S?ren Balle
bs = [s for s in symbols if not (s.isalpha() or s in " . - ' ? ,")]
bs
Out: ['!', '"', '#', '&', '(', ')', '*', '+', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '@', '[', '\\', ']', '^', '_', '`', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', '¶', '·', '»', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Kami sementara akan menghapus semua karakter ini untuk mencari tahu berapa banyak entri mereka hadir:for s in bs:
ar['name'] = ar['name'].str.replace(s, '')
corr = ar[ar['name'] != ar['name raw']]
Ada 2.184 catatan seperti itu, yaitu, hanya 0,15% dari jumlah total - sangat sedikit. Mari kita lihat 100 di antaranya:list(corr['name raw'].sample(100))
Out: ['Scha¶ffl, Ga?nter', 'Howard, Brian &', 'Chapiewski, Guilherme (Gc)', 'Derkach 1svd_mail_ru', 'Parker H1 Lauren', 'Leal le?n, Yaneri', 'TencA, David', 'Cortas La?pez, Alejandro', 'Strid, Bja¶rn', '(Crutchfield) Horan, Katie', 'Vigneron, Jean-Michel.Vigneron@gmail.Com', '\xa0', 'Telahr, J†rgen', 'St”rmer, Melanie', 'Nagai B1 Keiji', 'Rinc?n, Mariano', 'Arkalaki, Angela (Evangelia)', 'Barbaro B1 Bonin Anna G:Charlotte', 'Ra?esch, Ja¶rg', "CAVAZZI NICCOLO\\'", 'D„nzel, Thomas', 'Ziska, Steffen (Gerhard)', 'Kobilica B1 Alen', 'Mittelholcz, Bala', 'Jimanez Aguilar, Juan Antonio', 'Achenza H1 Giovanni', 'Reppe H2 Christiane', 'Filipovic B2 Lazar', 'Machuca Ka?hnel, Ruban Alejandro', 'Gellert (Silberprinz), Christian', 'Smith (Guide), Matt', 'Lenatz H1 Benjamin', 'Da¶llinger, Christian', 'Mc Carthy B1 Patrick Donnacha G:Bryan', 'Fa¶llmer, Chris', 'Warner (Rivera), Lisa', 'Wang, Ruijia (Ray)', 'Mc Carthy B1 Donnacha', 'Jones, Nige (Paddy)', 'Sch”ler, Christoph', '\xa0', 'Holthaus, Adelhard (Allard)', 'Mi;Arro, Ana', 'Dr: Koch Stefan', '\xa0', '\xa0', 'Ziska, Steffen (Gerhard)', 'Albarraca\xadn Gonza?lez, Juan Francisco', 'Ha¶fling, Imke', 'Johnston, Eddie (Edwin)', 'Mulcahy, Bob (James)', 'Gottschalk, Bj”rn', '\xa0', 'Gretsch H2 Kendall', 'Scorse, Christopher (Chris)', 'Kiel‚basa, Pawel', 'Kalan, Magnus', 'Roderick "eric" SIMBULAN', 'Russell;, Mark', 'ROPES AND GRAY TEAM 3', 'Andrade, H?¦CTOR DANIEL', 'Landmann H2 Joshua', 'Reyes Rodra\xadguez, Aithami', 'Ziska, Steffen (Gerhard)', 'Ziska, Steffen (Gerhard)', 'Heuza, Pierre', 'Snyder B1 Riley Brad G:Colin', 'Feldmann, Ja¶rg', 'Beveridge H1 Nic', 'FAGES`, perrine', 'Frank", Dieter', 'Saarema¤el, Indrek', 'Betancort Morales, Arida–y', 'Ridderberg, Marie_Louise', '\xa0', 'Ka¶nig, Johannes', 'W Van(der Klugt', 'Ziska, Steffen (Gerhard)', 'Johnson, Nick26', 'Heinz JOHNER03', 'Ga¶rg, Andra', 'Maruo B2 Atsuko', 'Moral Pedrero H1 Eva Maria', '\xa0', 'MATUS SANTIAGO Osc1r', 'Stenbrink, Bja¶rn', 'Wangkhan, Sm1.Thaworn', 'Pullerits, Ta¶nu', 'Clausner, 8588294149', 'Castro Miranda, Josa Ignacio', 'La¶fgren, Pontuz', 'Brown, Jann ( Janine )', 'Ziska, Steffen (Gerhard)', 'Koay, Sa¶ren', 'Ba¶hm, Heiko', 'Oleksiuk B2 Vita', 'G Van(de Grift', 'Scha¶neborn, Guido', 'Mandez, A?lvaro', 'Garca\xada Fla?rez, Daniel']
Akibatnya, setelah banyak penelitian, diputuskan: untuk mengganti semua karakter alfabet, serta spasi, tanda hubung, tanda kutip dan tanda tanya, dengan tanda koma, titik, dan simbol serta spasi '\ xa0', dan ganti semua karakter lain dengan string kosong, yaitu, hapus saja.ar['name'] = ar['name raw']
for s in symbols:
if s.isalpha() or s in " - ? '":
continue
if s in ".,\xa0":
ar['name'] = ar['name'].str.replace(s, ' ')
else:
ar['name'] = ar['name'].str.replace(s, '')
Kemudian singkirkan ruang ekstra:ar['name'] = ar['name'].str.split().str.join(' ')
ar['name'] = ar['name'].str.strip()
Mari kita lihat apa yang terjadi:ar.loc[corr.index].sample(10)
qmon = ar[(ar['name'].str.replace('?', '').str.strip() == '')&(ar['name']!='')]
Ada 3.429 di antaranya, terlihat seperti ini: Tujuan kami membawa nama ke standar yang sama adalah untuk membuat nama yang sama terlihat sama, tetapi berbeda dengan cara yang berbeda. Dalam hal nama yang hanya terdiri dari tanda tanya, mereka hanya berbeda dalam jumlah karakter, tetapi ini tidak memberikan keyakinan penuh bahwa nama dengan nomor yang sama benar-benar sama. Oleh karena itu, kami mengganti semuanya dengan string kosong dan tidak akan dipertimbangkan di masa mendatang.ar.loc[qmon.index, 'name'] = ''
Jumlah total entri dengan nama string kosong adalah 3.454. Tidak terlalu banyak - kita akan selamat. Sekarang kita telah menyingkirkan karakter yang tidak perlu, kita dapat melanjutkan ke transliterasi. Untuk melakukan ini, pertama bawa semuanya ke huruf kecil agar tidak melakukan pekerjaan ganda.ar['name'] = ar['name'].str.lower()
Selanjutnya, buat kamus:trans = {'':'a', '':'b', '':'v', '':'g', '':'d', '':'e', '':'e', '':'zh', '':'z', '':'i', '':'y', '':'k', '':'l', '':'m', '':'n', '':'o', '':'p', '':'r', '':'s', '':'t', '':'u', '':'f', '':'kh', '':'ts', '':'ch', '':'sh', '':'shch', '':'', '':'y', '':'', '':'e', '':'yu', '':'ya', 'є':'e', 'і': 'i','ў':'w','µ':'m'}
Ini juga termasuk surat-surat dari alfabet Cyrillic yang diperluas - 'є', 'in', 'ў' , yang digunakan dalam bahasa Belarusia dan Ukraina, serta huruf Yunani 'µ' . Terapkan transformasi:for s in trans:
ar['name'] = ar['name'].str.replace(s, trans[s])
Sekarang, dari huruf kecil yang berfungsi, kami akan menerjemahkan semuanya ke dalam format yang familier, di mana nama depan dan belakang dimulai dengan huruf kapital:ar['name'] = ar['name'].str.title()
Mari kita lihat apa yang terjadi.ar[ar['name raw'].str.lower().str[0].isin(trans.keys())].sample(10)
set( ''.join(ar['name'].unique()))
Out: [' ', "'", '-', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
Semuanya benar. Akibatnya, koreksi mempengaruhi 1.253.882 atau 89% dari catatan, jumlah nama unik menurun dari 660.207 menjadi 599.186, yaitu, 61 ribu atau hampir 10%. Wow! Simpan ke file baru, setelah menerjemahkan gabungan rekaman ar ke kamus protokol rd .pkl.dump(rd, open(r'D:\tri\details4.pkl', 'wb'))
Sekarang kita perlu memulihkan ketertiban. Artinya, semua rekaman akan terlihat seperti - Nama Depan Nama Belakang atau Nama Belakang Nama Depan . Yang mana yang harus ditentukan. Benar, selain nama dan nama keluarga, beberapa protokol juga mengandung nama tengah. Dan mungkin terjadi bahwa orang yang sama ditulis secara berbeda dalam protokol yang berbeda - di suatu tempat dengan nama tengah, di suatu tempat tanpa. Ini akan mengganggu identitasnya, jadi cobalah untuk menghapus nama tengah. Patronimik untuk pria biasanya memiliki akhiran "hiv" , dan untuk wanita - "vna" . Namun ada beberapa pengecualian. Misalnya - Ilyich, Ilyinichna, Nikitich, Nikitichna. Benar, ada beberapa pengecualian seperti itu. Seperti yang telah dicatat, format nama dalam satu protokol dapat dianggap permanen. Karena itu, untuk menghilangkan patronimik, Anda perlu menemukan ras tempat mereka hadir. Untuk melakukan ini, cari jumlah total fragmen "vich" dan "vna" dalam nama kolomdan membandingkannya dengan jumlah total entri di setiap protokol. Jika angka-angka ini dekat, maka ada nama tengah, kalau tidak, tidak. Tidak masuk akal untuk mencari pasangan yang ketat, karena bahkan dalam balapan di mana nama tengah dicatat, misalnya, orang asing dapat mengambil bagian, dan mereka akan dicatat tanpa dia. Kebetulan peserta lupa atau tidak mau menyebutkan nama tengahnya. Di sisi lain, ada juga nama keluarga yang diakhiri dengan "vich", ada banyak dari mereka di Belarus dan negara-negara lain dengan bahasa kelompok Slavia. Selain itu, kami melakukan transliterasi. Dimungkinkan untuk melakukan analisis ini sebelum transliterasi, tetapi kemudian ada kesempatan untuk melewatkan protokol di mana ada nama tengah, tetapi pada awalnya itu sudah dalam bahasa Latin. Jadi semuanya baik-baik saja.Jadi, kita akan mencari semua protokol di mana jumlah fragmen "vich" dan "vna" di kolomnama lebih dari 50% dari total jumlah entri dalam protokol.wp = {}
for e in rd:
nvich = (''.join(rd[e]['name'])).count('vich')
nvna = (''.join(rd[e]['name'])).count('vna')
if nvich + nvna > 0.5*len(rd[e]):
wp[e] = rd[e]
Ada 29 protokol seperti itu. Sangat menarik bahwa jika alih-alih 50% kita ambil 20% atau sebaliknya 70%, hasilnya tidak akan berubah, akan ada 29 yang sama. Jadi kita membuat pilihan yang tepat. Dengan demikian, kurang dari 20% - efek nama keluarga, lebih dari 70% - efek catatan individu tanpa nama tengah. Setelah memeriksa negara itu dengan bantuan meja pivot, ternyata 25 di antaranya ada di Rusia, 4 di Abkhazia. Bergerak. Kami hanya akan memproses catatan dengan tiga komponen, yaitu orang-orang di mana ada (mungkin) nama keluarga, nama, nama tengah.sum_n3w = 0
sum_nnot3w = 0
for e in wp:
sum_n3w += len([n for n in wp[e]['name'] if len(n.split()) == 3])
sum_nnot3w += len(wp[e]) - n3w
Mayoritas catatan tersebut adalah 86%. Sekarang komponen-komponen di mana tiga komponen dibagi menjadi kolom name0, name1, name2 :for e in wp:
ind3 = [i for i in rd[e].index if len(rd[e].loc[i,'name'].split()) == 3]
rd[e]['name0'] = ''
rd[e]['name1'] = ''
rd[e]['name2'] = ''
rd[e].loc[ind3, 'name0'] = rd[e].loc[ind3,'name'].str.split().str[0]
rd[e].loc[ind3, 'name1'] = rd[e].loc[ind3,'name'].str.split().str[1]
rd[e].loc[ind3, 'name2'] = rd[e].loc[ind3,'name'].str.split().str[2]
Begini salah satu protokolnya: Di sini, khususnya, jelas bahwa rekaman kedua komponen belum diproses. Sekarang, untuk setiap protokol, Anda perlu menentukan kolom mana yang memiliki nama tengah. Hanya ada dua opsi - name1, name2 , karena tidak bisa di tempat pertama. Setelah ditentukan, kami akan mengumpulkan nama baru tanpa itu.for e in wp:
n1=(''.join(rd[e]['name1'])).count('vich')+(''.join(rd[e]['name1'])).count('vna')
n2=(''.join(rd[e]['name2'])).count('vich')+(''.join(rd[e]['name2'])).count('vna')
if (n1 > n2):
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name2']
else:
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name1']
for e in wp:
ind = rd[e][rd[e]['new name'].str.strip() != ''].index
rd[e].loc[ind, 'name'] = rd[e].loc[ind, 'new name']
rd[e] = rd[e].drop(columns = ['name0','name1','name2','new name'])
pkl.dump(rd, open(r'D:\tri\details5.pkl', 'wb'))
Sekarang Anda perlu membawa nama ke urutan yang sama. Artinya, perlu bahwa dalam semua protokol nama diikuti pertama dengan nama belakang, atau sebaliknya - pertama nama belakang, lalu nama depan, juga di semua protokol. Tergantung mana yang lebih, sekarang kita akan mencari tahu. Situasi ini sedikit rumit oleh fakta bahwa nama lengkap dapat terdiri dari lebih dari dua kata, bahkan setelah kami menghapus nama tengahnya.ar['nwin'] = ar['name'].str.count(' ') + 1
ar.loc[ar['name'] == '','nwin'] = 0
100*ar['nwin'].value_counts()/len(ar)
Jumlah kata dalam nama Jumlah catatan Berbagi catatan (%) Tentu saja, sebagian besar (91%) adalah dua kata - hanya nama dan nama keluarga. Tetapi entri dengan tiga dan empat kata juga sangat banyak. Mari kita lihat kebangsaan dari catatan semacam itu:ar[ar['nwin'] >= 3]['country'].value_counts()[:12]
Out:
ESP 28435
MEX 10561
USA 7608
DNK 7178
BRA 6321
NLD 5748
DEU 4310
PHL 3941
ZAF 3862
ITA 3691
BEL 3596
FRA 3323
Nah, yang pertama adalah Spanyol, yang kedua - Meksiko, sebuah negara Hispanik, lebih jauh dari Amerika Serikat, di mana secara historis banyak juga kaum Hispanik. Brasil dan Filipina juga merupakan nama Spanyol (dan Portugis). Denmark, Belanda, Jerman, Afrika Selatan, Italia, Belgia, dan Prancis adalah masalah lain, kadang-kadang muncul semacam awalan untuk nama keluarga, oleh karena itu ada lebih dari dua kata. Namun, dalam semua kasus ini, biasanya nama itu sendiri terdiri dari satu kata, dan nama belakang dua, tiga. Tentu saja, ada pengecualian untuk aturan ini, tetapi kami tidak akan memprosesnya lagi. Pertama, untuk setiap protokol, Anda perlu menentukan jenis pesanan apa yang ada: nama-nama atau sebaliknya. Bagaimana cara melakukannya? Gagasan berikut muncul di benak saya: pertama, ragam nama keluarga biasanya jauh lebih besar daripada ragam nama. Itu harus bahkan dalam kerangka satu protokol. Kedua,panjang nama biasanya kurang dari panjang nama keluarga (bahkan untuk nama keluarga non-komposit). Kami akan menggunakan kombinasi kriteria ini untuk menentukan urutan awal.Pilih kata pertama dan terakhir dalam nama lengkap:ar['new name'] = ar['name']
ind = ar[ar['nwin'] < 2].index
ar.loc[ind, 'new name'] = '. .'
ar['wfin'] = ar['new name'].str.split().str[0]
ar['lwin'] = ar['new name'].str.split().str[-1]
Konversi bingkai data ar yang dikombinasikan kembali ke kamus rd sehingga kolom baru nwin, ns0, ns jatuh ke dalam kerangka data setiap balapan. Selanjutnya, kami menentukan jumlah protokol dengan urutan "Nama Depan Nama Belakang" dan jumlah protokol dengan urutan terbalik sesuai dengan kriteria kami. Kami hanya akan mempertimbangkan entri yang nama lengkapnya terdiri dari dua kata. Pada saat yang sama, simpan nama (nama depan) di kolom baru:name_surname = {}
surname_name = {}
for e in rd:
d = rd[e][rd[e]['nwin'] == 2]
if len(d['fwin'].unique()) < len(d['lwin'].unique()) and len(''.join(d['fwin'])) < len(''.join(d['lwin'])):
name_surname[e] = d
rd[e]['first name'] = rd[e]['fwin']
if len(d['fwin'].unique()) > len(d['lwin'].unique()) and len(''.join(d['fwin'])) > len(''.join(d['lwin'])):
surname_name[e] = d
rd[e]['first name'] = rd[e]['lwin']
Ternyata yang berikut: urutan Nama Depan Nama Belakang - 244 protokol, urutan Nama Belakang Pertama - 1,508 protokol.Dengan demikian, kita akan mengarah pada format yang lebih umum. Jumlahnya ternyata kurang dari jumlah total, karena kami memeriksa pemenuhan dua kriteria pada saat yang sama, dan bahkan dengan ketimpangan yang ketat. Ada protokol di mana hanya satu kriteria terpenuhi, atau itu mungkin, tetapi tidak mungkin terjadi kesetaraan. Tetapi ini sama sekali tidak penting karena formatnya didefinisikan.Sekarang, dengan asumsi bahwa kami telah menentukan pesanan dengan akurasi yang cukup tinggi, sementara tidak lupa bahwa itu tidak 100% akurat, kami akan menggunakan informasi ini. Temukan nama paling populer dari kolom nama depan :vc = ar['first name'].value_counts()
ambil orang-orang yang telah bertemu lebih dari seratus kali:pfn=vc[vc>100]
ada 1.673 di antaranya. Berikut ini adalah seratus di antaranya, disusun dalam urutan popularitas yang menurun: Sekarang, menggunakan daftar ini, kita akan menjalankan semua protokol dan membandingkan di mana ada lebih banyak kecocokan - dalam kata pertama nama atau yang terakhir. Kami hanya akan mempertimbangkan nama dua kata. Jika ada lebih banyak kecocokan dengan kata terakhir, maka urutannya benar, jika dengan kata pertama, itu berarti sebaliknya. Selain itu, di sini kami sudah lebih percaya diri, sehingga Anda dapat menggunakan pengetahuan ini, dan kami akan menambahkan daftar nama protokol berikutnya ke daftar awal nama-nama populer dengan setiap pass. Kami menyortir protokol berdasarkan frekuensi kemunculan nama-nama dari daftar awal untuk menghindari kesalahan acak dan menyiapkan daftar yang lebih luas untuk protokol-protokol itu di mana ada beberapa kecocokan dan yang akan diproses menjelang akhir siklus.['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Patrick', 'Scott', 'Kevin', 'Stefan', 'Jason', 'Eric', 'Christopher', 'Alexander', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Andrea', 'Jonathan', 'Markus', 'Marco', 'Adam', 'Ryan', 'Jan', 'Tom', 'Marc', 'Carlos', 'Jennifer', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Sarah', 'Alex', 'Jose', 'Andrey', 'Benjamin', 'Sebastian', 'Ian', 'Anthony', 'Ben', 'Oliver', 'Antonio', 'Ivan', 'Sean', 'Manuel', 'Matthias', 'Nicolas', 'Dan', 'Craig', 'Dmitriy', 'Laura', 'Luis', 'Lisa', 'Kim', 'Anna', 'Nick', 'Rob', 'Maria', 'Greg', 'Aleksey', 'Javier', 'Michelle', 'Andre', 'Mario', 'Joseph', 'Christoph', 'Justin', 'Jim', 'Gary', 'Erik', 'Andy', 'Joe', 'Alberto', 'Roberto', 'Jens', 'Tobias', 'Lee', 'Nicholas', 'Dave', 'Tony', 'Olivier', 'Philippe']
sbpn = pd.DataFrame(columns = ['event', 'num pop names'], index=range(len(rd)))
for i in range(len(rd)):
e = list(rd.keys())[i]
sbpn.loc[i, 'event'] = e
sbpn.loc[i, 'num pop names'] = len(set(pfn).intersection(rd[e]['first name']))
sbnp=sbnp.sort_values(by = 'num pop names',ascending=False)
sbnp = sbnp.reset_index(drop=True)
tofix = []
for i in range(len(rd)):
e = sbpn.loc[i, 'event']
if len(set(list(rd[e]['fwin'])).intersection(pfn)) > len(set(list(rd[e]['lwin'])).intersection(pfn)):
tofix.append(e)
pfn = list(set(pfn + list(rd[e]['fwin'])))
else:
pfn = list(set(pfn + list(rd[e]['lwin'])))
Ada 235 protokol. Artinya, hampir sama dengan apa yang terjadi pada perkiraan pertama (244). Yang pasti, saya selektif melihat tiga catatan pertama dari masing-masing, memastikan semuanya benar. Juga periksa bahwa tahap pertama penyortiran memberikan 36 entri salah dari Nama Nama Kelas dan 2 salah dari Nama Nama Kelas . Saya melihat tiga catatan pertama dari masing-masing, memang, tahap kedua bekerja dengan sempurna. Sekarang, pada kenyataannya, itu masih untuk memperbaiki protokol-protokol tersebut di mana urutan yang salah ditemukan:for e in tofix:
ind = rd[e][rd[e]['nwin'] > 1].index
rd[e].loc[ind,'name'] = rd[e].loc[ind,'name'].str.split(n=1).str[1] + ' ' + rd[e].loc[ind,'name'].str.split(n=1).str[0]
Di sini di split, kami membatasi jumlah potongan menggunakan parameter n . Logikanya adalah ini: nama adalah satu kata, yang pertama dengan nama lengkap. Segala sesuatu yang lain adalah nama keluarga (dapat terdiri dari beberapa kata). Tukar saja.Sekarang kita singkirkan kolom yang tidak perlu dan simpan:for e in rd:
rd[e] = rd[e].drop(columns = ['new name', 'first name', 'fwin','lwin', 'nwin'])
pkl.dump(rd, open(r'D:\tri\details6.pkl', 'wb'))
Periksa hasilnya. Selusin catatan tetap acak: Sebanyak 108 ribu catatan diperbaiki. Jumlah nama lengkap yang unik berkurang dari 598 menjadi 547 ribu. Baik! Dengan pemformatan selesai.Bagian 3. Pemulihan data yang tidak lengkap
Sekarang beralih ke memulihkan data yang hilang. Dan ada semacam itu.Negara
Mari kita mulai dengan negara. Temukan semua catatan di mana negara tidak ditunjukkan:arnc = ar[ar['country'] == '']
Ada 3.221 di antaranya. Berikut ini 10 acak:nnc = arnc['name'].unique()
Jumlah nama unik di antara catatan tanpa negara adalah 3 051. Mari kita lihat apakah jumlah ini dapat dikurangi.Faktanya adalah bahwa dalam triathlon orang jarang membatasi diri hanya untuk satu balapan, mereka biasanya berpartisipasi dalam kompetisi secara berkala, beberapa kali dalam satu musim, dari tahun ke tahun, terus berlatih. Oleh karena itu, untuk banyak nama dalam data, kemungkinan besar ada lebih dari satu catatan. Untuk memulihkan informasi tentang negara, cobalah untuk menemukan catatan dengan nama yang sama di antara yang di mana negara tersebut ditunjukkan.arwc = ar[ar['country'] != '']
nwc = arwc['name'].unique()
tofix = set(nnc).intersection(nwc)
Out: ['Kleber-Schad Ute Cathrin', 'Sellner Peter', 'Pfeiffer Christian', 'Scholl Thomas', 'Petersohn Sandra', 'Marchand Kurt', 'Janneck Britta', 'Angheben Riccardo', 'Thiele Yvonne', 'Kie?Wetter Martin', 'Schymik Gerhard', 'Clark Donald', 'Berod Brigitte', 'Theile Markus', 'Giuliattini Burbui Margherita', 'Wehrum Alexander', 'Kenny Oisin', 'Schwieger Peter', 'Grosse Bianca', 'Schafter Carsten', 'Breck Dirk', 'Mautes Christoph', 'Herrmann Andreas', 'Gilbert Kai', 'Steger Peter', 'Jirouskova Jana', 'Jehrke Michael', 'Valentine David', 'Reis Michael', 'Wanka Michael', 'Schomburg Jonas', 'Giehl Caprice', 'Zinser Carsten', 'Schumann Marcus', 'Magoni Livio', 'Lauden Yann', 'Mayer Dieter', 'Krisa Stefan', 'Haberecht Bernd', 'Schneider Achim', 'Gibanel Curto Antonio', 'Miranda Antonio', 'Juarez Pedro', 'Prelle Gerrit', 'Wuste Kay', 'Bullock Graeme', 'Hahner Martin', 'Kahl Maik', 'Schubnell Frank', 'Hastenteufel Marco', …]
Ada 2.236 dari mereka, yaitu hampir tiga perempat. Sekarang, untuk setiap nama dari daftar ini, Anda perlu menentukan negara dengan catatan di mana itu. Tetapi kebetulan nama yang sama ditemukan di beberapa catatan dan di berbagai negara. Entah itu senama, atau mungkin orang tersebut pindah. Karena itu, kami pertama-tama memproses hal-hal yang semuanya unik.fix = {}
for n in tofix:
nr = arwc[arwc['name'] == n]
if len(nr['country'].unique()) == 1:
fix[n] = nr['country'].iloc[0]
Dibuat dalam satu lingkaran. Tapi, terus terang, itu berhasil untuk waktu yang lama - sekitar tiga menit. Jika ada urutan lebih banyak entri, Anda mungkin harus membuat implementasi vektor. Ada 2.013 entri, atau 90% dari potensi.Nama di mana negara yang berbeda dapat muncul dalam catatan yang berbeda, ambil negara yang paling sering muncul.if n not in fix:
nr = arwc[arwc['name'] == n]
vc = nr['country'].value_counts()
if vc[0] > vc[1]:
fix[n] = vc.index[0]
Dengan demikian, kecocokan ditemukan untuk 2.208 nama, atau 99% dari semua yang potensial. Kami menerapkan korespondensi ini:{'Kleber-Schad Ute Cathrin': 'DEU', 'Sellner Peter': 'AUT', 'Pfeiffer Christian': 'AUT', 'Scholl Thomas': 'DEU', 'Petersohn Sandra': 'DEU', 'Marchand Kurt': 'BEL', 'Janneck Britta': 'DEU', 'Angheben Riccardo': 'ITA', 'Thiele Yvonne': 'DEU', 'Kie?Wetter Martin': 'DEU', 'Clark Donald': 'GBR', 'Berod Brigitte': 'FRA', 'Theile Markus': 'DEU', 'Giuliattini Burbui Margherita': 'ITA', 'Wehrum Alexander': 'DEU', 'Kenny Oisin': 'IRL', 'Schwieger Peter': 'DEU', 'Schafter Carsten': 'DEU', 'Breck Dirk': 'DEU', 'Mautes Christoph': 'DEU', 'Herrmann Andreas': 'DEU', 'Gilbert Kai': 'DEU', 'Steger Peter': 'AUT', 'Jirouskova Jana': 'CZE', 'Jehrke Michael': 'DEU', 'Wanka Michael': 'DEU', 'Giehl Caprice': 'DEU', 'Zinser Carsten': 'DEU', 'Schumann Marcus': 'DEU', 'Magoni Livio': 'ITA', 'Lauden Yann': 'FRA', 'Mayer Dieter': 'DEU', 'Krisa Stefan': 'DEU', 'Haberecht Bernd': 'DEU', 'Schneider Achim': 'DEU', 'Gibanel Curto Antonio': 'ESP', 'Juarez Pedro': 'ESP', 'Prelle Gerrit': 'DEU', 'Wuste Kay': 'DEU', 'Bullock Graeme': 'GBR', 'Hahner Martin': 'DEU', 'Kahl Maik': 'DEU', 'Schubnell Frank': 'DEU', 'Hastenteufel Marco': 'DEU', 'Tedde Roberto': 'ITA', 'Minervini Domenico': 'ITA', 'Respondek Markus': 'DEU', 'Kramer Arne': 'DEU', 'Schreck Alex': 'DEU', 'Bichler Matthias': 'DEU', …}
for n in fix:
ind = arnc[arnc['name'] == n].index
ar.loc[ind, 'country'] = fix[n]
pkl.dump(rd, open(r'D:\tri\details7.pkl', 'wb'))
Lantai
Seperti dalam kasus negara, ada catatan di mana jenis kelamin peserta tidak ditunjukkan.ar[ar['sex'] == '']
Ada 2.538 di antaranya, relatif sedikit, tapi sekali lagi kami akan mencoba membuatnya lebih sedikit. Simpan nilai asli di kolom baru.ar['sex raw'] =ar['sex']
Tidak seperti negara tempat kami mengambil informasi berdasarkan nama dari protokol lain, semuanya sedikit lebih rumit di sini. Faktanya adalah bahwa data penuh dengan kesalahan dan ada banyak nama (total 2 101) yang ditemukan dengan tanda-tanda kedua jenis kelamin.arws = ar[(ar['sex'] != '')&(ar['name'] != '')]
snds = arws[arws.duplicated(subset='name',keep=False)]
snds = snds.drop_duplicates(subset=['name','sex'], keep = 'first')
snds = snds.sort_values(by='name')
snds = snds[snds.duplicated(subset = 'name', keep=False)]
snds
rss = [rd[e] for e in rd if len(rd[e][rd[e]['sex'] != '']['sex'].unique()) == 1]
Jumlah mereka ada 633. Tampaknya ini sangat mungkin, hanya sebuah protokol yang terpisah untuk wanita, secara terpisah untuk pria. Tetapi kenyataannya adalah bahwa hampir semua protokol ini mengandung kelompok usia dari kedua jenis kelamin (kelompok usia laki-laki dimulai dengan huruf M , perempuan - dengan huruf F ). Misalnya: Diharapkan bahwa nama kelompok umur dimulai dengan huruf M untuk pria dan dengan huruf F untuk wanita. Dalam dua contoh sebelumnya, meskipun ada kesalahan di kolom seks'ITU World Cup Tiszaujvaros Olympic 2002'
, nama kelompok itu tampaknya menggambarkan dengan benar jenis kelamin anggota tersebut. Berdasarkan beberapa contoh sampel, kami membuat asumsi bahwa kelompok tersebut diindikasikan dengan benar, dan gender dapat diindikasikan secara keliru. Temukan semua entri di mana huruf pertama dalam nama grup tidak cocok dengan gender. Kami akan mengambil nama awal grup grup mentah , karena selama standardisasi banyak catatan dibiarkan tanpa grup, tetapi sekarang kita hanya perlu huruf pertama, jadi standarnya tidak penting.ar['grflc'] = ar['group raw'].str.upper().str[0]
grncs = ar[(ar['grflc'].isin(['M','F']))&(ar['sex']!=ar['grflc'])]
Ada 26 161 catatan seperti itu. Nah, mari kita koreksi jenis kelamin sesuai dengan nama kelompok umur:ar.loc[grncs.index, 'sex'] = grncs['grflc']
Mari kita lihat hasilnya: Bagus. Berapa banyak catatan yang tersisa tanpa jenis kelamin?ar[(ar['sex'] == '')&(ar['name'] != '')]
Ternyata persis satu! Ya, grup ini tidak benar-benar diindikasikan, tetapi, ternyata, ini adalah wanita. Emily adalah nama perempuan, selain peserta ini (atau namanya) selesai setahun sebelumnya, dan dalam protokol tersebut gender dan kelompok ditunjukkan. Pulihkan di sini secara manual * dan lanjutkan.ar.loc[arns.index, 'sex'] = 'F'
Sekarang semua catatan dengan gender.* Secara umum, tentu saja, itu salah untuk melakukan ini - dengan berjalan berulang, jika sesuatu dalam rantai berubah sebelum, misalnya, dalam konversi nama, maka mungkin ada lebih dari satu catatan tanpa jenis kelamin, dan tidak semua dari mereka akan menjadi perempuan, kesalahan akan terjadi. Oleh karena itu, Anda harus memasukkan logika berat untuk mencari peserta dengan nama dan jenis kelamin yang sama dalam protokol lain, seperti memulihkan negara, dan entah bagaimana mengujinya, atau, agar tidak menyulitkan, tambahkan logika ini tanda centang bahwa hanya satu catatan yang ditemukan dan namanya begini dan begitu, jika tidak ada pengecualian yang akan menghentikan seluruh laptop, Anda bisa melihat penyimpangan dari rencana dan campur tangan.if len(arns) == 1 and arns['name'].iloc[0] == 'Stather Emily':
ar.loc[arns.index, 'sex'] = 'F'
else:
raise Exception('Different scenario!')
Tampaknya ini bisa tenang. Tetapi kenyataannya adalah bahwa koreksi didasarkan pada asumsi bahwa kelompok tersebut ditunjukkan dengan benar. Dan memang benar. Hampir selalu. Hampir. Namun, beberapa inkonsistensi tidak sengaja diketahui, jadi sekarang mari kita coba untuk menentukan semuanya, baik, atau sebanyak mungkin. Seperti yang telah disebutkan, pada contoh pertama, justru fakta bahwa gender tidak sesuai dengan nama berdasarkan ide-idenya sendiri tentang nama-nama pria dan wanita menjaga kami.Temukan semua nama pada catatan pria dan wanita. Di sini, nama dipahami sebagai nama, dan bukan nama lengkap, yaitu, tanpa nama keluarga, apa yang disebut nama depan dalam bahasa Inggris .ar['fn'] = ar['name'].str.split().str[-1]
mfn = list(ar[ar['sex'] == 'M']['fn'].unique())
Sebanyak 32.508 nama pria terdaftar. Inilah 50 yang paling populer:['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Kevin', 'Patrick', 'Scott', 'Stefan', 'Jason', 'Eric', 'Alexander', 'Christopher', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Jonathan', 'Marco', 'Markus', 'Adam', 'Ryan', 'Tom', 'Jan', 'Marc', 'Carlos', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Andrey', 'Benjamin', 'Jose']
ffn = list(ar[ar['sex'] == 'F']['fn'].unique())
Kurang wanita - 14.423. Paling populer: Bagus, sepertinya terlihat logis. Mari kita lihat apakah ada persimpangan.['Jennifer', 'Sarah', 'Laura', 'Lisa', 'Anna', 'Michelle', 'Maria', 'Andrea', 'Nicole', 'Jessica', 'Julie', 'Elizabeth', 'Stephanie', 'Karen', 'Christine', 'Amy', 'Rebecca', 'Susan', 'Rachel', 'Anne', 'Heather', 'Kelly', 'Barbara', 'Claudia', 'Amanda', 'Sandra', 'Julia', 'Lauren', 'Melissa', 'Emma', 'Sara', 'Katie', 'Melanie', 'Kim', 'Caroline', 'Erin', 'Kate', 'Linda', 'Mary', 'Alexandra', 'Christina', 'Emily', 'Angela', 'Catherine', 'Claire', 'Elena', 'Patricia', 'Charlotte', 'Megan', 'Daniela']
mffn = set(mfn).intersection(ffn)
Ada. Dan ada 2.811 di antaranya, mari kita lihat lebih dekat. Untuk mulai dengan, kami mencari tahu berapa banyak catatan dengan nama-nama ini:armfn = ar[ar['fn'].isin(mffn)]
Ada 725 562. Itu setengah! Ini luar biasa! Ada hampir 37.000 nama unik, tetapi setengah dari catatan memiliki total 2.800. Mari kita lihat apa nama-nama ini, yang merupakan yang paling populer. Untuk melakukan ini, buat bingkai data baru di mana nama-nama ini akan menjadi indeks:df = pd.DataFrame(armfn['fn'].value_counts())
df = df.rename(columns={'fn':'total'})
Kami menghitung berapa catatan pria dan wanita dengan masing-masing.df['M'] = armfn[armfn['sex'] == 'M']['fn'].value_counts()
df['F'] = armfn[armfn['sex'] == 'F']['fn'].value_counts()
df.sort_values(by = 'F', ascending=False)
import gender_guesser.detector as gg
d = gg.Detector()
d.get_gender(u'Oleg')
Out: 'male'
d.get_gender(u'Evgeniya')
Out: 'female'
Semuanya baik-baik saja. Tetapi jika Anda memeriksa nama Andrea , maka ia juga memberi tahu wanita , yang tidak sepenuhnya benar. Benar, ada jalan keluar. Jika Anda melihat properti nama - nama detektor, maka semua ambiguitas menjadi terlihat di sana.d.names['Andrea']
Out: {'female': ' 4 4 3 4788 64 579 34 1 7 ',
'mostly_female': '5 6 7 ',
'male': ' 7 '}
Ya, yaitu, get_gender hanya memberi Anda opsi yang paling mungkin, tetapi pada kenyataannya itu bisa jauh lebih rumit. Periksa nama lain:d.names['Maria']
Out: {'female': '686 6 A 85986 A BA 3B98A75457 6 ',
'mostly_female': ' BBC A 678A9 '}
d.names['Oleg']
Out: {'male': ' 6 2 99894737 3 '}
Artinya, daftar nama untuk setiap nama sesuai dengan satu atau lebih pasangan nilai kunci, di mana kunci - itu adalah jenis kelamin: laki-laki, PEREMPUAN, most_male, most_female, andy , dan nilai - daftar nilai-nilai negara yang sesuai: 1,2,3 ... .. 9ABC . Negara-negara tersebut adalah:d.COUNTRIES
Out: ['great_britain', 'ireland', 'usa', 'italy', 'malta', 'portugal', 'spain', 'france', 'belgium', 'luxembourg', 'the_netherlands', 'east_frisia', 'germany', 'austria', 'swiss', 'iceland', 'denmark', 'norway', 'sweden', 'finland', 'estonia', 'latvia', 'lithuania', 'poland', 'czech_republic', 'slovakia', 'hungary', 'romania', 'bulgaria', 'bosniaand', 'croatia', 'kosovo', 'macedonia', 'montenegro', 'serbia', 'slovenia', 'albania', 'greece', 'russia', 'belarus', 'moldova', 'ukraine', 'armenia', 'azerbaijan', 'georgia', 'the_stans', 'turkey', 'arabia', 'israel', 'china', 'india', 'japan', 'korea', 'vietnam', 'other_countries']
Saya tidak sepenuhnya mengerti apa arti alfanumerik atau ketidakhadiran mereka dalam daftar secara khusus. Tapi ini tidak penting, karena saya memutuskan untuk membatasi diri hanya menggunakan nama-nama yang memiliki interpretasi yang jelas. Yaitu, untuk yang hanya ada satu pasangan nilai kunci dan kuncinya adalah laki - laki atau perempuan . Untuk setiap nama dari kerangka data kami, tulis interpretasinya tentang penebak gender :df['sex from gg'] = ''
for n in df.index:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1 and options[0] == 'male':
df.loc[n, 'sex from gg'] = 'M'
if len(options) == 1 and options[0] == 'female':
df.loc[n, 'sex from gg'] = 'F'
Ternyata 1.150 nama. Berikut ini adalah yang paling populer yang telah dibahas di atas: Ya, tidak buruk. Sekarang terapkan logika ini ke semua rekaman.all_names = ar['fn'].unique()
male_names = []
female_names = []
for n in all_names:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1:
if options[0] == 'male':
male_names.append(n)
if options[0] == 'female':
female_names.append(n)
Ditemukan 7 091 nama pria dan 5 054 wanita. Terapkan transformasi:tofixm = ar[ar['fn'].isin(male_names)]
ar.loc[tofixm.index, 'sex'] = 'M'
tofixf = ar[ar['fn'].isin(female_names)]
ar.loc[tofixf.index, 'sex'] = 'F'
Kami melihat hasilnya:ar[ar['sex']!=ar['sex raw']]
Entri dikoreksi 30.352 (bersama-sama dengan koreksi dengan nama grup). Seperti biasa, 10 yang acak: Sekarang kami yakin bahwa kami telah mengidentifikasi gender dengan benar, kami juga akan membawa kelompok standar sejalan. Mari kita lihat di mana mereka tidak cocok:ar['gfl'] = ar['group'].str[0]
gncws = ar[(ar['sex'] != ar['gfl']) & (ar['group']!='')]
4.248 entri. Ganti huruf pertama:ar.loc[gncws.index, 'group'] = ar.loc[gncws.index, 'sex'] + ar.loc[gncws.index, 'group'].str[1:].index, 'sex']
pkl.dump(rd, open(r'D:\tri\details8.pkl', 'wb'))
Itu saja, dengan pemulihan data yang tidak lengkap.Pembaruan Buletin
Tetap memperbarui tabel ringkasan dengan data yang diperbarui tentang jumlah pria dan wanita, dll.rs['total raw'] = rs['total']
rs['males raw'] = rs['males']
rs['females raw'] = rs['females']
rs['rus raw'] = rs['rus']
for i in rs.index:
e = rs.loc[i,'event']
rs.loc[i,'total'] = len(rd[e])
rs.loc[i,'males'] = len(rd[e][rd[e]['sex'] == 'M'])
rs.loc[i,'females'] = len(rd[e][rd[e]['sex'] == 'F'])
rs.loc[i,'rus'] = len(rd[e][rd[e]['country'] == 'RUS'])
len(rs[rs['total'] != rs['total raw']])
Out: 288
len(rs[rs['males'] != rs['males raw']])
Out:962
len(rs[rs['females'] != rs['females raw']])
Out: 836
len(rs[rs['rus'] != rs['rus raw']])
Out: 8
pkl.dump(rs, open(r'D:\tri\summary6.pkl', 'wb'))
Bagian 4. Pengambilan sampel
Sekarang triathlon sangat populer. Selama musim, ada banyak kompetisi terbuka di mana sejumlah besar atlet, terutama amatir, ambil bagian. Tetapi tidak selalu demikian. Ada catatan dalam data kami sejak 1990. Menggulir melalui tristats.ru, saya perhatikan bahwa ada lebih banyak balapan dalam beberapa tahun terakhir, dan sangat sedikit pada yang pertama. Tetapi sekarang karena data kami telah disiapkan, Anda dapat melihatnya dengan lebih cermat.Periode sepuluh tahun
Hitung jumlah balapan dan finishers di setiap tahun:rs['year'] = pd.DatetimeIndex(rs['date']).year
years = range(rs['year'].min(),rs['year'].max())
rsy = pd.DataFrame(columns = ['races', 'finishers', 'rus', 'RUS'], index = years)
for y in rsy.index:
rsy.loc[y,'races'] = len(rs[rs['year'] == y])
rsy.loc[y,'finishers'] = sum(rs[rs['year'] == y]['total'])
rsy.loc[y,'rus'] = sum(rs[rs['year'] == y]['rus'])
rsy.loc[y,'RUS'] = len(rs[(rs['year'] == y)&(rs['country'] == 'RUS')])
 Dapat dilihat bahwa jumlah ras dan peserta pada awal periode dan pada akhirnya tidak dapat dibandingkan. Peningkatan signifikan dalam jumlah total balapan dimulai pada 2011, sementara jumlah permulaan di Rusia juga meningkat. Selain itu, peningkatan jumlah peserta dapat diamati pada tahun 2009. Ini mungkin menunjukkan peningkatan minat di antara para peserta, yaitu, peningkatan permintaan, setelah itu pasokan dua tahun kemudian meningkat, yaitu, jumlah permulaan. Namun, jangan lupa bahwa data mungkin tidak lengkap dan sebagian, dan mungkin banyak ras yang hilang. Termasuk karena fakta bahwa proyek untuk mengumpulkan data ini baru dimulai pada 2010, yang juga dapat menjelaskan lompatan signifikan dalam grafik saat ini. Karena itu, untuk analisis lebih lanjut, saya memutuskan untuk mengambil 10 tahun terakhir. Ini adalah periode yang cukup panjang,untuk melacak tren selama beberapa tahun, sementara cukup pendek untuk tidak sampai di sana, terutama kompetisi profesional dari tahun 90-an dan awal 2000-an.
Dapat dilihat bahwa jumlah ras dan peserta pada awal periode dan pada akhirnya tidak dapat dibandingkan. Peningkatan signifikan dalam jumlah total balapan dimulai pada 2011, sementara jumlah permulaan di Rusia juga meningkat. Selain itu, peningkatan jumlah peserta dapat diamati pada tahun 2009. Ini mungkin menunjukkan peningkatan minat di antara para peserta, yaitu, peningkatan permintaan, setelah itu pasokan dua tahun kemudian meningkat, yaitu, jumlah permulaan. Namun, jangan lupa bahwa data mungkin tidak lengkap dan sebagian, dan mungkin banyak ras yang hilang. Termasuk karena fakta bahwa proyek untuk mengumpulkan data ini baru dimulai pada 2010, yang juga dapat menjelaskan lompatan signifikan dalam grafik saat ini. Karena itu, untuk analisis lebih lanjut, saya memutuskan untuk mengambil 10 tahun terakhir. Ini adalah periode yang cukup panjang,untuk melacak tren selama beberapa tahun, sementara cukup pendek untuk tidak sampai di sana, terutama kompetisi profesional dari tahun 90-an dan awal 2000-an.rs = rs[(rs['year']>=2010)&(rs['year']<= 2019)]
 Pada periode yang dipilih, omong-omong, 84% ras dan 94% finishers jatuh.
Pada periode yang dipilih, omong-omong, 84% ras dan 94% finishers jatuh.Amatir dimulai
Jadi, sebagian besar peserta dalam start yang dipilih adalah atlet amatir, sehingga statistik yang baik dapat diperoleh dari mereka. Sejujurnya, ini merupakan minat utama saya, karena saya sendiri berpartisipasi dalam permulaan seperti itu, tetapi di level itu sangat jauh dari juara Olimpiade. Namun, kompetisi profesional jelas juga terjadi pada periode yang dipilih. Agar tidak mencampur indikator untuk balapan amatir dan profesional, diputuskan untuk menghapus yang terakhir dari pertimbangan. Bagaimana cara mengidentifikasi mereka? Dengan kecepatan. Kami menghitungnya. Pada salah satu tahap awal persiapan data, kami telah menentukan jenis jarak apa pada setiap perlombaan - sprint, Olympic, half, iron. Untuk masing-masing dari mereka, jarak tempuh panggung didefinisikan dengan jelas - berenang, bersepeda dan berlari. Ini adalah 0,75 + 20 + 5 untuk sprint, 1,5 + 40 + 10 untuk Olimpiade, 1,9 + 90 + 21,1 untuk setengah dan 3.8 + 180 + 42.2 untuk besi. Tentu saja, pada kenyataannya, untuk jenis apa pun, bilangan real dapat bervariasi dari satu ras ke ras bersyarat hingga satu persen, tetapi tidak ada informasi tentang ini, jadi kami menganggap bahwa semuanya akurat.rs['km'] = ''
rs.loc[rs['dist'] == 'sprint', 'km'] = 0.75+20+5
rs.loc[rs['dist'] == 'olympic', 'km'] = 1.5+40+10
rs.loc[rs['dist'] == 'half', 'km'] = 1.9+90+21.1
rs.loc[rs['dist'] == 'full', 'km'] = 3.8+180+42.2
Kami menghitung kecepatan rata-rata dan maksimum untuk setiap balapan. Maksimum di sini mengacu pada kecepatan rata-rata atlet yang memenangkan tempat pertama.for index, row in rs.iterrows():
e = row['event']
rd[e]['th'] = pd.TimedeltaIndex(rd[e]['result']).seconds/3600
rd[e]['v'] = rs.loc[i, 'km'] / rd[e]['th']
for index, row in rs.iterrows():
e = row['event']
rs.loc[index,'vmax'] = rd[e]['v'].max()
rs.loc[index,'vavg'] = rd[e]['v'].mean()
 Nah, Anda dapat melihat bahwa sebagian besar kecepatan berkumpul dalam tumpukan antara sekitar 15 km / jam dan 30 km / jam, tetapi ada sejumlah nilai "kosmik". Urutkan berdasarkan kecepatan rata-rata dan lihat berapa banyak di antaranya:
Nah, Anda dapat melihat bahwa sebagian besar kecepatan berkumpul dalam tumpukan antara sekitar 15 km / jam dan 30 km / jam, tetapi ada sejumlah nilai "kosmik". Urutkan berdasarkan kecepatan rata-rata dan lihat berapa banyak di antaranya:rs = rs.sort_values(by='vavg')
 Di sini kami mengubah skala dan kami dapat memperkirakan rentang lebih akurat. Untuk kecepatan rata-rata dari 17 km / jam hingga 27 km / jam, maksimum - dari 18 km / jam hingga 32 km / jam. Plus ada "ekor" dengan kecepatan rata-rata yang sangat rendah dan sangat tinggi. Kecepatan rendah kemungkinan besar berhubungan dengan kompetisi ekstrem seperti Norseman , dan kecepatan tinggi bisa dalam kasus renang yang dibatalkan, di mana alih-alih sprint ada sprint super, atau data yang salah. Poin penting lainnya adalah langkah mulus di area 1200 di sepanjang sumbu X, dan nilai kecepatan rata-rata yang lebih tinggi setelahnya. Di sana Anda dapat melihat perbedaan yang jauh lebih kecil antara kecepatan rata-rata dan maksimum daripada di dua pertiga pertama grafik. Rupanya, ini adalah kompetisi profesional. Untuk membedakannya lebih jelas, kami menghitung rasio kecepatan maksimum terhadap rata-rata. Dalam kompetisi profesional di mana tidak ada orang acak dan semua peserta memiliki tingkat kebugaran fisik yang sangat tinggi, rasio ini harus minimal.
Di sini kami mengubah skala dan kami dapat memperkirakan rentang lebih akurat. Untuk kecepatan rata-rata dari 17 km / jam hingga 27 km / jam, maksimum - dari 18 km / jam hingga 32 km / jam. Plus ada "ekor" dengan kecepatan rata-rata yang sangat rendah dan sangat tinggi. Kecepatan rendah kemungkinan besar berhubungan dengan kompetisi ekstrem seperti Norseman , dan kecepatan tinggi bisa dalam kasus renang yang dibatalkan, di mana alih-alih sprint ada sprint super, atau data yang salah. Poin penting lainnya adalah langkah mulus di area 1200 di sepanjang sumbu X, dan nilai kecepatan rata-rata yang lebih tinggi setelahnya. Di sana Anda dapat melihat perbedaan yang jauh lebih kecil antara kecepatan rata-rata dan maksimum daripada di dua pertiga pertama grafik. Rupanya, ini adalah kompetisi profesional. Untuk membedakannya lebih jelas, kami menghitung rasio kecepatan maksimum terhadap rata-rata. Dalam kompetisi profesional di mana tidak ada orang acak dan semua peserta memiliki tingkat kebugaran fisik yang sangat tinggi, rasio ini harus minimal.rs['vmdbva'] = rs['vmax']/rs['vavg']
rs = rs.sort_values(by='vmdbva')
 Pada grafik ini, kuartal pertama terlihat sangat jelas: rasio kecepatan maksimum dengan rata-rata kecil, kecepatan rata-rata tinggi, sejumlah kecil peserta. Ini adalah kompetisi profesional. Langkah pada kurva hijau adalah sekitar 1,2. Kami hanya akan meninggalkan catatan dengan nilai rasio lebih besar dari 1,2 dalam sampel kami.
Pada grafik ini, kuartal pertama terlihat sangat jelas: rasio kecepatan maksimum dengan rata-rata kecil, kecepatan rata-rata tinggi, sejumlah kecil peserta. Ini adalah kompetisi profesional. Langkah pada kurva hijau adalah sekitar 1,2. Kami hanya akan meninggalkan catatan dengan nilai rasio lebih besar dari 1,2 dalam sampel kami.rs = rs[rs['vmdbva'] > 1.2]
Kami juga menghapus catatan dengan kecepatan rendah dan tinggi yang tidak lazim. Dalam Apa "catatan dunia" triathlon untuk setiap jarak? menerbitkan catatan waktu melewati jarak yang berbeda untuk 2019. Jika Anda menghitungnya dengan kecepatan sedang, Anda dapat melihat bahwa itu tidak bisa lebih tinggi dari 33 km / jam bahkan untuk yang tercepat. Jadi kami akan mempertimbangkan protokol di mana kecepatan rata-rata lebih tinggi, tidak valid, dan menghapusnya dari pertimbangan.rs = rs[(rs['vavg'] > 17)&(rs['vmax'] < 33)]
Inilah yang tersisa:
 Sekarang semuanya terlihat cukup homogen dan tidak menimbulkan pertanyaan. Sebagai hasil dari semua pilihan ini, kami kehilangan 777 dari 1922 protokol, atau 40%. Pada saat yang sama, jumlah total pelari tidak berkurang banyak - hanya 13%.Jadi, ada 1.145 balapan tersisa dengan 1.231.772 finishers. Sampel ini menjadi bahan untuk analisis dan visualisasi saya.
Sekarang semuanya terlihat cukup homogen dan tidak menimbulkan pertanyaan. Sebagai hasil dari semua pilihan ini, kami kehilangan 777 dari 1922 protokol, atau 40%. Pada saat yang sama, jumlah total pelari tidak berkurang banyak - hanya 13%.Jadi, ada 1.145 balapan tersisa dengan 1.231.772 finishers. Sampel ini menjadi bahan untuk analisis dan visualisasi saya.Bagian 5. Analisis dan visualisasi
Dalam karya ini, analisis dan visualisasi yang tepat adalah bagian yang paling sederhana. Ujung gunung es, bagian bawah lautnya hanyalah persiapan data. Analisis, pada kenyataannya, adalah operasi aritmatika sederhana pada Seri panda , perhitungan rata-rata, penyaringan - semua ini dilakukan oleh alat panda dasar dan kode di atas penuh dengan contoh. Visualisasi, pada gilirannya, terutama dilakukan dengan menggunakan matplotlib paling standar . Plot, bar, pie bekas . Namun, di beberapa tempat, saya harus mengotak-atik tanda tangan kapak, dalam hal kurma dan piktogram, tetapi ini bukan sesuatu yang menarik untuk penjelasan rinci di sini. Satu-satunya hal yang layak dibicarakan adalah presentasi geodata. Setidaknya tidakmatplotlib .Geodata
Untuk setiap balapan, kami memiliki informasi tentang venue. Pada awalnya, menggunakan geopy, kami menghitung koordinat untuk setiap lokasi. Banyak balapan diadakan setiap tahun di tempat yang sama. Alat yang sangat berguna untuk merender geodata dengan python adalah folium . Begini cara kerjanya:import folium
m = folium.Map()
folium.Marker(['55.7522200', '37.6155600'], popup='').add_to(m)
Dan kami mendapatkan peta interaktif tepat di laptop Jupiter. Sekarang, ke data kami. Pertama, kami akan memulai kolom baru dari kombinasi koordinat kami:
Sekarang, ke data kami. Pertama, kami akan memulai kolom baru dari kombinasi koordinat kami:rs['coords'] = rs['latitude'].astype(str) + ', ' + rs['longitude'].astype(str)
Koordinat unik coords adalah 291. Dan yang unik lokasi loc adalah 324, yang berarti bahwa beberapa nama yang sedikit berbeda, sementara pada saat yang sama mereka sesuai dengan titik yang sama. Itu tidak menakutkan, kami akan mempertimbangkan keunikan dengan koordinasi . Kami menghitung berapa banyak peristiwa yang telah berlalu sepanjang waktu di setiap lokasi (dengan koordinat unik):vc = rs['coords'].value_counts()
vc
Out:
43.7009358, 7.2683912 22
43.5854823, 39.723109 20
29.03970805, -13.636291 16
47.3723941, 8.5423328 16
59.3110918, 24.420907 15
51.0834196, 10.4234469 15
54.7585694, 38.8818137 14
20.4317585, -86.9202745 13
52.3727598, 4.8936041 12
41.6132925, 2.6576102 12
... ...
Sekarang buat peta, dan tambahkan spidol dalam bentuk lingkaran, jari-jarinya akan tergantung pada jumlah acara yang diadakan di lokasi. Tambahkan spidol dengan nama lokasi ke spidol.m = folium.Map(location=[25,10], zoom_start=2)
for c in rs['coords'].unique():
row = [r[1] for r in rs.iterrows() if r[1]['coords'] == c][0]
folium.Circle([row['latitude'], row['longitude']],
popup=(row['location']+'\n('+str(vc[c])+' races)'),
radius = 10000*int(vc[c]),
color='darkorange',
fill=True,
stroke=True,
weight=1).add_to(m)
Selesai Anda dapat melihat hasilnya:
Kemajuan Peserta
Bahkan, selain membimbing, mengerjakan jadwal lain juga tidak sepele. Ini adalah grafik perkembangan terbaru dari para peserta. Ini dia: Mari kita menganalisisnya, pada saat yang sama saya akan memberikan kode untuk rendering, sebagai contoh menggunakan matplotlib :
Mari kita menganalisisnya, pada saat yang sama saya akan memberikan kode untuk rendering, sebagai contoh menggunakan matplotlib :fig = plt.figure()
fig.set_size_inches(10, 6)
ax = fig.add_axes([0,0,1,1])
b = ax.bar(exp,numrecs, color = 'navajowhite')
ax1 = ax.twinx()
for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
p, = ax1.plot(exp, vpm, 'o-',markersize=8, linewidth=2, color='C0')
for i in range(len(exp)):
if i < len(exp)-1 and (vpm[i] < vpm[i+1]):
ax1.text(x = exp[i]+0.1, y = vpm[i]-0.2, s = '{0:3.1f}%'.format(vpm[i]),size=12)
else:
ax1.text(x = exp[i]+0.1, y = vpm[i]+0.1, s = '{0:3.1f}%'.format(vpm[i]),size=12)
ax.legend((b,p), (' ', ''),loc='center right')
ax.set_xlabel(' ')
ax.set_ylabel('')
ax1.set_ylabel('% ')
ax.set_xticks(np.arange(1, 11, step=1))
ax.set_yticks(np.arange(0, 230000, step=25000))
ax1.set_ylim(97.5,103.5)
ax.yaxis.set_label_position("right")
ax.yaxis.tick_right()
ax1.yaxis.set_label_position("left")
ax1.yaxis.tick_left()
plt.show()
Sekarang tentang bagaimana data dihitung untuknya. Pertama, Anda harus memilih nama-nama peserta yang menyelesaikan setidaknya dalam dua balapan, dan dalam tahun kalender yang berbeda, dan pada saat yang sama bukan profesional.Pertama, untuk setiap protokol, isi kolom baru yang disebut tanggal , yang akan menunjukkan tanggal balapan. Kami juga akan membutuhkan satu tahun dari tanggal ini, kami akan membuat tahun kolom . Karena kita akan menganalisis kecepatan masing-masing atlet relatif terhadap kecepatan rata-rata dalam perlombaan, kami segera menghitung kecepatan ini di kolom vproc baru - kecepatan sebagai persentase dari rata-rata.for index, row in rs.iterrows():
e = row['event']
rd[e]['date'] = row['date']
rd[e]['year'] = row['year']
rd[e]['vproc'] = 100 * rd[e]['v'] / rd[e]['v'].mean()
Begini tampilannya protokol: Selanjutnya, gabungkan semua protokol menjadi satu bingkai data.' Sprint 2019'ar = pd.concat(rd)
Untuk setiap peserta, kami hanya akan meninggalkan satu entri di setiap tahun kalender:ar1 = ar.drop_duplicates(subset = ['name','year'], keep='first')
Selanjutnya, dari semua nama unik dari entri ini, kami menemukan yang muncul setidaknya dua kali:nvc = ar1['name'].value_counts()
names = list(nvc[nvc > 1].index)
ada 219.890 di antaranya. Mari kita singkirkan nama-nama atlet pro dari daftar ini:pro_names = ar[ar['group'].isin(['MPRO','FPRO'])]['name'].unique()
names = list(set(names) - set(pro_names))
Serta nama-nama atlet yang mulai tampil sebelum 2010. Untuk melakukan ini, unggah data yang disimpan sebelum kami mencicipi dalam 10 tahun terakhir. Tempatkan mereka di rsa (ringkasan semua ras) dan objek rda (detail ras semua).rdo = {}
for e in rda:
if rsa[rsa['event'] == e]['year'].iloc[0] < 2010:
rdo[e] = rda[e]
aro = pd.concat(rdo)
old_names = aro['name'].unique()
names = list(set(names) - set(old_names))
Dan akhirnya, kami menemukan nama yang muncul lebih dari satu kali pada hari yang sama. Oleh karena itu, kami meminimalkan keberadaan namama lengkap dalam sampel kami.namesakes = ar[ar.duplicated(subset = ['name','date'], keep = False)]['name'].unique()
names = list(set(names) - set(namesakes))
Jadi ada 198.075 nama yang tersisa. Dari seluruh dataset, kami hanya memilih catatan dengan nama-nama yang ditemukan:ars = ar[ar['name'].isin(names)]
Sekarang, untuk setiap catatan, Anda perlu menentukan tahun apa dalam karir atlet yang berhubungan dengan - pertama, kedua, ketiga, atau kesepuluh. Kami membuat lingkaran dengan semua nama dan menghitung.ars['exp'] = ''
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
Berikut adalah contoh dari apa yang terjadi: Rupanya, senama itu masih ada. Ini diharapkan, tetapi tidak menakutkan, karena kami akan meratakan segalanya, dan seharusnya tidak begitu banyak. Selanjutnya, kami membuat array untuk grafik:exp = []
vpm = []
numrecs = []
for x in range(ars['exp'].min(), ars['exp'].max() + 1):
exp.append(x)
vpm.append(ars[ars['exp'] == x]['vproc'].mean())
numrecs.append(len(ars[ars['exp'] == x]))
Itu dia, ada dasarnya: Sekarang, untuk menghiasnya dengan poin yang sesuai dengan hasil tertentu, kita akan memilih 1000 nama acak dan membangun array dengan hasil untuk mereka.
Sekarang, untuk menghiasnya dengan poin yang sesuai dengan hasil tertentu, kita akan memilih 1000 nama acak dan membangun array dengan hasil untuk mereka.names_samp = random.sample(names,1000)
ars_samp = ars[ars['name'].isin(names_samp)]
ars_samp = ars_samp.reset_index(drop = True)
exp_samp = []
vproc_samp = []
for n in names_samp:
nr = ars_samp[ars_samp['name'] == n]
nr = nr.sort_values('exp')
exp_samp.append(list(nr['exp']))
vproc_samp.append(list(nr['vproc']))
Tambahkan lingkaran untuk membuat grafik dari sampel acak ini.for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
Sekarang semuanya sudah siap: Secara umum, tidak sulit. Tapi ada satu masalah. Untuk menghitung pengalaman exp dalam satu siklus, semua nama, yang hampir 200 ribu, membutuhkan waktu delapan jam. Saya harus men-debug algoritma pada sampel kecil, dan kemudian menjalankan perhitungan untuk malam itu. Pada prinsipnya, ini bisa dilakukan sekali, tetapi jika Anda menemukan beberapa jenis kesalahan atau ingin mengubah sesuatu, dan Anda perlu menceritakannya lagi, itu mulai tegang. Jadi, ketika saya akan menerbitkan sebuah laporan di malam hari, ternyata sekali lagi perlu untuk menceritakan semuanya lagi. Menunggu sampai pagi bukan bagian dari rencanaku, dan aku mulai mencari cara untuk membuat perhitungan lebih cepat. Memutuskan untuk memparalelkan.Menemukan cara untuk melakukan ini dengan multiprocessing. Agar dapat bekerja di Windows, kami perlu menempatkan logika utama dari setiap tugas paralel ke file pekerja.py yang terpisah :
Secara umum, tidak sulit. Tapi ada satu masalah. Untuk menghitung pengalaman exp dalam satu siklus, semua nama, yang hampir 200 ribu, membutuhkan waktu delapan jam. Saya harus men-debug algoritma pada sampel kecil, dan kemudian menjalankan perhitungan untuk malam itu. Pada prinsipnya, ini bisa dilakukan sekali, tetapi jika Anda menemukan beberapa jenis kesalahan atau ingin mengubah sesuatu, dan Anda perlu menceritakannya lagi, itu mulai tegang. Jadi, ketika saya akan menerbitkan sebuah laporan di malam hari, ternyata sekali lagi perlu untuk menceritakan semuanya lagi. Menunggu sampai pagi bukan bagian dari rencanaku, dan aku mulai mencari cara untuk membuat perhitungan lebih cepat. Memutuskan untuk memparalelkan.Menemukan cara untuk melakukan ini dengan multiprocessing. Agar dapat bekerja di Windows, kami perlu menempatkan logika utama dari setiap tugas paralel ke file pekerja.py yang terpisah :import pickle as pkl
def worker(args):
names = args[0]
ars=args[1]
num=args[2]
ars = ars.sort_values(by='name')
ars = ars.reset_index(drop=True)
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
with open(r'D:\tri\par\prog' + str(num) + '.pkl', 'wb') as f:
pkl.dump(ars,f)
Prosedur tersebut dipindahkan ke sebagian dari nama-nama nama , bagian datafreyma ar hanya dengan nama-nama ini, dan nomor seri tugas paralel - num . Komputasi ditulis ke frame data dan, pada akhirnya, frame data ditulis ke file. Di laptop yang memanggil pekerja ini , kami menyiapkan argumen yang sesuai:num_proc = 8
args = []
for i in range(num_proc):
step = int(len(names_samp)/num_proc) + 1
names_i = names_samp[i*step:min((i+1)*step, len(names_samp))]
ars_i = ars[ars['name'].isin(names_i)]
args.append([names_i, ars_i, i])
Kami memulai komputasi paralel:from multiprocessing import Pool
import workers
if __name__ == '__main__':
p=Pool(processes = num_proc)
p.map(workers.worker,args)
Dan pada akhirnya kami membaca hasil dari file dan mengumpulkan potongan-potongan kembali ke seluruh kerangka data:ars=pd.DataFrame(columns = ars.columns)
for i in range(num_proc):
with open(r'D:\tri\par\prog'+str(i)+'.pkl', 'rb') as f:
arsi = pkl.load(f)
print(len(arsi))
ars = pd.concat([ars, arsi])
Dengan demikian, dimungkinkan untuk mendapatkan akselerasi 40 kali, dan bukannya 8 jam untuk menyelesaikan perhitungan dalam 11 menit dan menerbitkan laporan malam itu. Pada saat yang sama saya belajar bagaimana memparalelkannya dengan python , saya pikir itu akan berguna. Di sini, akselerasi ternyata lebih dari 8 kali jumlah inti, karena setiap tugas menggunakan kerangka data kecil, yang membuat pencarian menjadi lebih cepat. Pada prinsipnya, perhitungan berurutan dapat dipercepat dengan cara ini, tetapi pertanyaannya adalah, bagaimana menurut Anda?Namun, saya tidak bisa tenang dan bahkan setelah publikasi saya terus-menerus berpikir tentang bagaimana melakukan perhitungan menggunakan vektorisasi, yaitu operasi pada seluruh kolom bingkai data Seri panda. Perhitungan semacam itu adalah urutan besarnya lebih cepat daripada siklus paralel, bahkan pada superkluster. Dan muncul dengan. Ternyata untuk setiap nama untuk menemukan tahun awal karir, perlu sebaliknya - untuk setiap tahun untuk menemukan peserta yang memulai di dalamnya. Untuk melakukan ini, Anda harus terlebih dahulu menentukan semua nama untuk tahun pertama dari sampel kami, ini adalah 2010. Karenanya, kami memproses semua catatan dengan nama-nama ini menggunakan tahun ini. Selanjutnya, kami mengambil tahun berikutnya - 2011.Sekali lagi kami menemukan semua nama dengan entri tahun ini, tetapi kami hanya mengambil dari mereka yang tidak diproses, yaitu yang tidak terpenuhi pada 2010 dan diproses menggunakan mereka pada 2011. Dan seterusnya untuk sisa tahun ini. Siklus yang sama, tetapi bukan dua ratus ribu iterasi, tetapi totalnya sembilan.for y in range(ars['year'].min(),ars['year'].max()):
arsynp = ars[(ars['exp'] == '') & (ars['year'] == y)]
namesy = arsynp['name'].unique()
ind = ars[ars['name'].isin(namesy)].index
ars.loc[ind, 'exp'] = ars.loc[ind,'year'] - y + 1
Siklus ini dipenuhi hanya dalam beberapa detik. Dan kodenya ternyata jauh lebih ringkas.Kesimpulan
Yah, akhirnya, banyak pekerjaan telah selesai. Bagi saya, ini sebenarnya adalah proyek pertama dari jenisnya. Ketika saya mengambilnya, tujuan utamanya adalah berlatih menggunakan python dan pustaka-pustaka nya. Tugas ini lebih dari selesai. Dan hasilnya sendiri cukup rapi. Apa kesimpulan yang saya buat untuk diri saya setelah selesai?Pertama: Data tidak sempurna. Ini mungkin benar untuk hampir semua tugas analisis. Bahkan jika mereka sepenuhnya terstruktur, dan itu sering terjadi secara berbeda, Anda harus siap untuk bermain-main dengan mereka sebelum Anda mulai menghitung karakteristik dan mencari tren - menemukan kesalahan, outlier, penyimpangan dari standar, dll.Kedua:Tugas apa pun memiliki solusi. Ini lebih seperti slogan, tetapi sering kali itu slogan. Hanya saja solusi ini mungkin tidak begitu jelas dan tidak terletak pada data itu sendiri, tetapi di luar kotak, untuk berbicara. Sebagai contoh - pemrosesan nama-nama peserta yang dijelaskan di atas, atau pengikisan situs web.Ketiga: Pengetahuan domain sangat penting. Ini akan memungkinkan untuk menyiapkan data dengan lebih baik, menghapus data yang jelas tidak valid atau tidak standar, menghindari kesalahan interpretasi, menggunakan informasi yang tidak ada dalam data, misalnya jarak dalam proyek ini, menyajikan hasil dalam bentuk yang diterima di masyarakat, sambil menghindari kesimpulan yang bodoh dan salah.Keempat: Bekerja dengan pythonAda seperangkat alat yang kaya. Kadang-kadang tampaknya ada baiknya memikirkan sesuatu, Anda mulai mencari - itu sudah ada. Ini bagus sekali! Terima kasih banyak kepada para pencipta atas kontribusi ini, terutama untuk alat-alat yang berguna di sini: selenium untuk memo, pycountry untuk menentukan kode negara sesuai dengan standar ISO, kode negara (datahub) untuk kode Olimpiade, geopy untuk menentukan koordinat pada alamat, folium - untuk visualisasi geodata, penebak gender - untuk analisis nama, multi - pemrosesan - untuk komputasi paralel, matplotlib , numpy , dan tentu saja panda - tanpa itu tidak ada tempat untuk pergi.Kelima: Vektorisasi adalah segalanya bagi kami. Sangat penting untuk dapat menggunakan alat panda bawaan , ini sangat efektif. Saya kira, dalam banyak kasus, ketika jumlah catatan diukur mulai dari puluhan ribu, keterampilan ini menjadi sangat diperlukan.Keenam:Menangani data adalah ide yang buruk. Penting untuk mencoba meminimalkan intervensi manual - pertama, itu tidak skala, yaitu, ketika jumlah data meningkat beberapa kali, waktu untuk pemrosesan manual akan meningkat ke nilai yang tidak dapat diterima, dan kedua, akan ada pengulangan yang buruk - Anda akan melupakan sesuatu, Anda akan membuat kesalahan di suatu tempat . Semuanya hanya terprogram, jika ada sesuatu yang keluar dari standar umum untuk solusi perangkat lunak, yah, tidak apa-apa, Anda dapat mengorbankan beberapa bagian dari data, masih akan ada lebih banyak plus.Ketujuh:Kode harus disimpan agar berfungsi. Tampaknya itu bisa lebih jelas! Bahkan, ketika datang ke kode untuk penggunaan Anda sendiri, yang tujuannya adalah untuk mempublikasikan hasil kode ini, semuanya tidak begitu ketat di sini. Saya bekerja di Jupiter Notebooks, dan lingkungan ini, menurut pendapat saya, tidak perlu membuat produk perangkat lunak integral. Ini dikonfigurasikan untuk peluncuran baris demi baris, secara bersamaan, ini memiliki kelebihan - cepat: pengembangan, debugging, dan eksekusi pada saat yang sama. Tetapi seringkali godaannya adalah hanya mengedit beberapa baris dan dengan cepat mendapatkan hasil baru, alih-alih menduplikasi atau membungkus def. Tentu saja godaan seperti itu harus dihindari. Seseorang harus berjuang untuk kode yang baik, bahkan "untuk diri sendiri", setidaknya karena bahkan untuk satu pekerjaan analisis peluncuran dilakukan berkali-kali, dan menginvestasikan waktu pada awalnya pasti akan terbayar di masa depan. Dan Anda dapat menambahkan tes, bahkan pada laptop, dalam bentuk pemeriksaan parameter kritis dan melemparkan pengecualian - ini sangat berguna.Kedelapan: Simpan lebih sering. Di setiap langkah, saya menyimpan versi file yang baru. Secara total, mereka ternyata sekitar 10. Ini nyaman, karena ketika kesalahan terdeteksi itu membantu untuk dengan cepat menentukan pada tahap apa itu terjadi. Plus, saya menyimpan data sumber di kolom bertanda mentah - ini memungkinkan Anda untuk dengan cepat memeriksa hasilnya dan melihat perbedaannya.Kesembilan:Penting untuk mengukur investasi waktu dan hasilnya. Di beberapa tempat, saya membutuhkan waktu sangat lama untuk memulihkan data, yang merupakan sebagian kecil dari total. Sebenarnya, ini tidak masuk akal, Anda hanya perlu membuangnya, dan itu saja. Dan saya akan melakukannya jika itu adalah proyek komersial, bukan pelatihan otomatis. Ini akan memungkinkan Anda untuk mendapatkan hasilnya lebih cepat. Prinsip Pareto bekerja di sini - 80% dari hasilnya dicapai dalam 20% dari waktu.Dan yang terakhir:Bekerja pada proyek-proyek semacam itu sangat memperluas cakrawala. Dengan sengaja, Anda mempelajari sesuatu yang baru - misalnya, nama-nama negara asing - seperti Kepulauan Pitcairn, bahwa kode ISO untuk Swiss adalah CHE, dari bahasa Latin "Confoederatio Helvetica", apa nama Spanyol, yah, sebenarnya tentang triathlon itu sendiri - catatan, pemiliknya, tempat balapan, sejarah acara dan sebagainya.Mungkin cukup. Itu saja. Terima kasih kepada semua orang yang membaca sampai akhir!